







现实世界中,事物之间的关系是错综复杂的,最简单的是线性关系(线性表,至多有一个前驱一个后继),稍微复杂一些的是树关系(每个元素至多有一个前驱,可能有零个或多个后继)。
这片博客我讲一种更为复杂的数据结构——图结构。特征是:每个元素可以有多个前驱、多个后继。
1.图逻辑结构
(1)定义:图是一种数据结构,它由顶点(Vertex)集合(即数据元素)及顶点间的边(Edge)集合(即元素之间的关系)组成。
(2)结构化定义:
Graph = (D,R) = (V,E)
其中 V = {x|x∈D0},即V是顶点的有 穷非空集合
E = {(x,y)|x,y∈V} 或 E = {<x,y>|x,y∈V&&Path(x,y)},即E是顶点之间关系的有穷集合,也叫做边集合。Path(x,y)表示从x到y的一条单向通路,它是有方向的。
(3)基本概念
1)顶点(Vertex):数据元素;
2)边(Edge):数据元素之间的关系;
3)有向边:数据元素之间的关系有序,即x与y的关系不同于y与x的关系,用尖括号表示,<x,y>≠<y,x>

4)无向边:数据元素之间的关系无序,即x与y的关系等价于y与x的关系,用圆括号表示,(x,y)=(y,x)

5)权 Weight:图赋予了一种含义,边具有一个关联的数值,这个数值称为权。(根据这个定义,图可分为带权图、不带权图)
6)邻接:无向图,若(u,v)∈E,则称u,v相互邻接;有向图,若<u,v>∈E,则称u邻接到v,或v临接于u。
7)关联(依附):若(u,v)∈E或<u,v>∈E,则称边依附于顶点u,v或顶点u,v与边相关联。
8)顶点的度(Degree):与顶点相关联的边的数目,记作Td(v);入度:与顶点相关联的引入边的数目,记作Id(v);出度:与顶点相关联的出入边的数目,记作Od(v)。Td(v)=Id(v)+Od(v)
9)路径:在图 G=(V, E) 中, 若从顶点 vi 出发, 沿一些边经 过一些顶点 vp1, vp2, …, vpm,到达顶点vj。则称顶点序列 (vi vp1 vp2 ... vpm vj) 为从顶点vi 到顶点 vj 的路径。它经过的边(vi, vp1)、 (vp1, vp2)、...、(vpm, vj) 应是属于E的边。
10)路径长度:带权路径长度、非带权路径长度
简单路径:若路径上各顶点 v1, v2, ..., vm 均不互相重复, 则 称这样的路径为简单路径。
回路:若路径上第一个顶点 v1 与最后一个顶点vm 重合, 则 称这样的路径为回路或环。
简单回路:路径上除起点与终点相同外,其余顶点都不相同;
11)子图:设有两个图G=(V,E)和G'=(V',E')。若V'包含于V且E'包含于E,则称图G'是图G的子图。
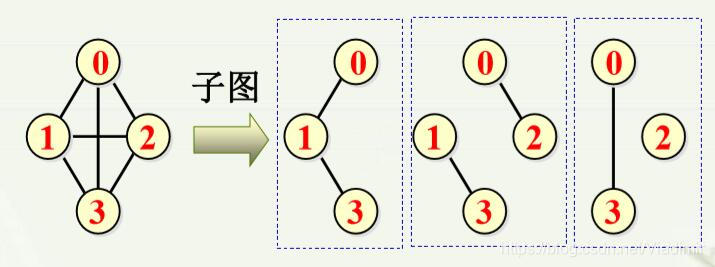
一个图的子图包括其自身,就像一个集合的子集包括其本身一样。
12)顶点连通:(无向图)两个顶点vi,vj之间有路径;
顶点强连通:(有向图)两个顶点vi到vj,vj到vi之间都有有向路径;
连通图:如果图中任意一对顶点都是连通的, 则称此 图是连通图;
连通分量:(非)连通图的极大连通子图(连通图的连通分量只有一个,那就是它本身;非连通图的连通分量有多个);
强连通图:在有向图中, 若对于每一对顶点vi和vj, 都存在 一条从vi到vj和从vj到vi的路径, 则称此图是强连通图;
强连通分量:非强连通图的极大强连通子图。
13)生成树:连通图的极小连通子图,它包含图的所有n个顶点,(n-1)条边;
有向树:一个有向图恰有一个入度为0的顶点,其余顶点的入度均为1;
生成树森林:
无向图:各个连通分量的生成树;
有向图:由若干有向树组成,含有图中全部顶点,但只有足以构成若干棵不相交的有向树的边;
(4)图的种类
①有向图( Undirected Graph or Undigraph):由有向边构成的图。
②无向图( Directed Graph or Digraph):由无向边构成的图。
③简单图:若图满足:任一边(u,v)或<u,v>,有u≠v,即自己不能与自己有关系;一条边不允许重复出现,即两个元素不能有相同的多个关系。
④完全图(Conplete Graph):包括所有可能边的简单图,即具有最大边数的简单图。
有n个顶点的无向完全图有n*(n-1)/2条边(意思就是任意两个结点之间都有边相连)。
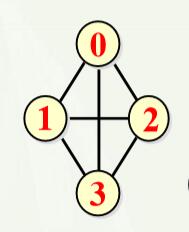
有n个顶点的有向完全图有n*(n-1)条边(意思就是任意两个结点之间都有双向的两条边)。
⑤稠密图(Sparse Graph):边数远远少于完全图的图。
⑥稠密图(Dense Graph):与稀疏图相反的图。
⑦平面图:存在一种画法,使各条边仅在顶点处相交。
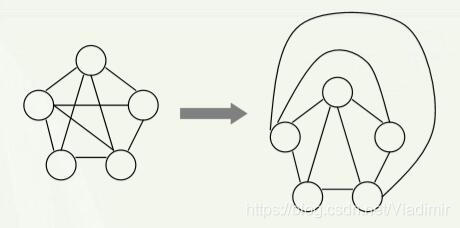
⑧非平面图:无论怎么画,都有边在非定点处相交。
2.图结构上定义的操作
| 图初始化 | Init_Graph(g) |
| 求顶点在图中的位置 | Loc_vertex(g,v) |
| 访问图的顶点 | Get_vertex(g,i) |
| 求图中v的第一个邻接点 | First_adj(g,v) |
| 求图中v的w后的下一个邻接点 | Next_adj(g,v,w) |
| 插入顶点 | Ins_vertex(g,u) |
| 插入边 | Ins_edge(g,u1,u2) |
| 删除顶点 | Del_vertex(g,u) |
| 删除边 | Del_edge(g,u1,u2) |
| 图的遍历 | Traversal_g(g,u) |
3.图的ADT定义

4.图存储结构
(1)随着数据结构的复杂,其关系的存储(表示)也越来越麻烦,特别是顺序存储方式是靠物理上的相邻来表示逻辑关系的,表示关系的能力很弱。因此,面对图这种复杂逻辑结构,顺序存储已经不再能满足图的存储需求。所以,图结构没有顺序存储方式。
链式存储方式是靠存储相关元素地址(指针)来表示关系的,表示关系能力很强。应该说可以存储任意复杂的逻辑关系。所以,对图结构来说,最容易想到的就是链式存储结构,即在存储数据元素的同时,用指针表示它们之间的关系。
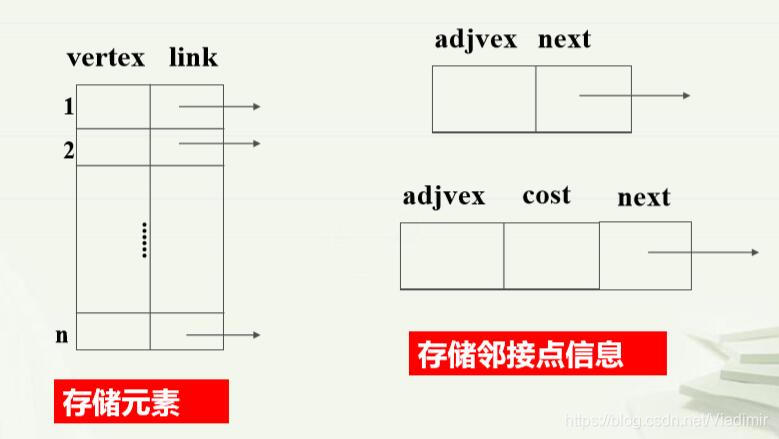
因为每个结点的出度不都相同,所以图的结点存储形式分为定长结点和不定长结点两种,如图所示:
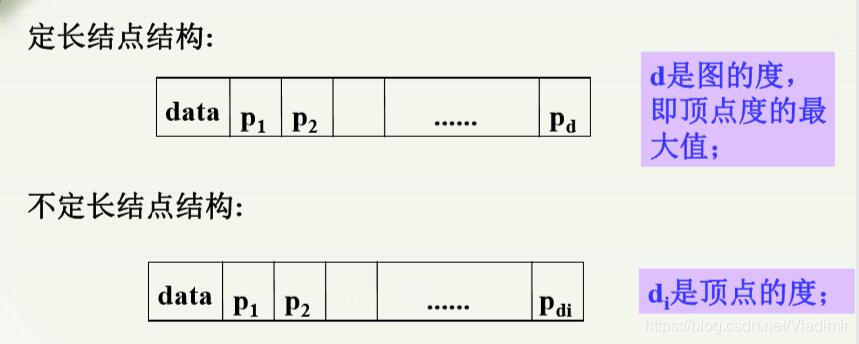
简单来说,定长结点就是规定每个结点出度的大小,因为空间一开始就开辟出来了,所以操作方便,但是容易出现溢出问题和存储空间冗余的问题;不定长结点,出度是多少就开辟多少个空间,所以不会出现溢出和存储空间冗余的问题,但是操作相对较为麻烦。
(2)由于图结构的复杂,其顺序存储方式不存在,而一般的链式存储又存在一些缺点。为此,提出了专门针对图结构的一些存储方式。这些存储方式的基本原则是:
①存储数据元素(一般采用顺序存储方式)
②存储(表示)数据之间的关系
(按照我的理解,就是把图分成两块存储,一块存储所有图结点的数据元素,另一块存储图结点之间的关系。)
对于②中的存储形式,主要有:用二维表表示关系的,例如邻接矩阵和关联矩阵;用指针表示关系的,例如邻接表、十字链表和邻接多重表。
(3)(顺序)存储方式:用连续的地址空间存储图的数据元素及元素之间的关系(邻接关系),如图所示:
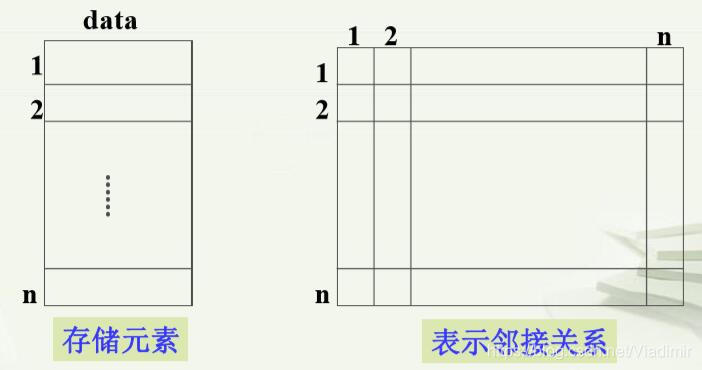
(左边)VerticesList:一维数组,存放数据元素(顶点)
(右边)Edge:二维数组,存放数据之间的关系
至于二维数组中填的内容,如下图所示:

上面是非加权图的计算方法;下面是加权图的计算方法。
给大家稍微解释一下,其实很简单的,对于非加权图,如果两个顶点之间有关联,那么二维数组中相关的空就填1,否则填0;对于加权图,二维数组空格中填的内容为“权”的大小,如果两个顶点之间有关联,那么填二者之间权的大小,否则填无穷,如果是同一个顶点,则填零。
举例:

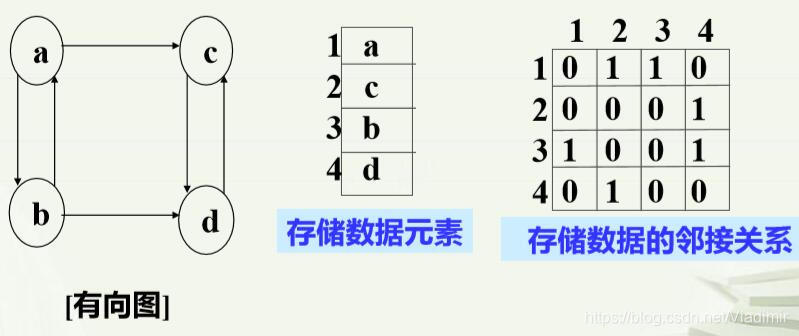
要注意的是,有向图中,如果a、b两点相连,那么二维表中(a,b)与(b,a)的空位中都填1;有向图中,对于a、b两点,如果只有a指向b的箭头而没有b指向a的箭头,那么二维表中(a,b)填1,(b,a)则填0。
对于无向图(非加权):
①矩阵是对称的;
②第i行或第i 列1的个数为顶点vi 的度;
③矩阵中1的个数的一半为图中边的数目;
④很容易判断顶点vi 和顶点vj之间是否有边相连;
对于有向图(非加权):
① 矩阵不一定是对称的;
② 第i 行中1的个数为顶点vi 的出度;
③ 第i列中1的个数为顶点 vi的入度;
④ 矩阵中1的个数为图中弧的数目;
⑤ 很容易判断顶点vi 和顶点vj 是否有弧相连;
类定义:
typedef 边类型 E;//边的类型(权值)
typedef 元素类型 T;//元素类型(顶点)
class Graphmtx{
friend istream& operator >> ( istream& in, Graphmtx & G); //输入
friend ostream& operator << (ostream& out, Graphmtx & G); //输出
public:
int maxVertices; //允许图的顶点个数的最大值
int numVertices; //图的顶点数
int numEdges; //图的边数
T *VerticesList; //一维数组,存放元素(顶点)
E **Edge; //二维数组,存放邻接矩阵(关系)
public:
int getVertex(T vertex); //确定元素在图中的存储位置
Graphmtx(int sz=DefaultVertices); //构造函数
~Graphmtx(){ delete [ ]VerticesList; delete [ ]Edge; } //析构函数
T getValue (int i); //取顶点 i 的值
E getWeight (T v1, T v2) ; //取边(v1,v2)上权值
T getFirstNeighbor(T v); //取顶点 v 的第一个邻接顶点
T getNextNeighbor(T v, T w); //取 v 的邻接顶点 w 的下一邻接顶点
bool insertVertex(const T vertex); //插入顶点vertex
bool insertEdge(T v1, T v2, E cost); //插入边(v1, v2),权值为cost
bool removeVertex(T v); //删去顶点 v 和所有与它相关联的边
bool removeEdge(T v1, T v2); //在图中删去边(v1,v2)
BFS_traversal(T v); //图的广度遍历
DFS_traversal(T v); //图的深度遍历
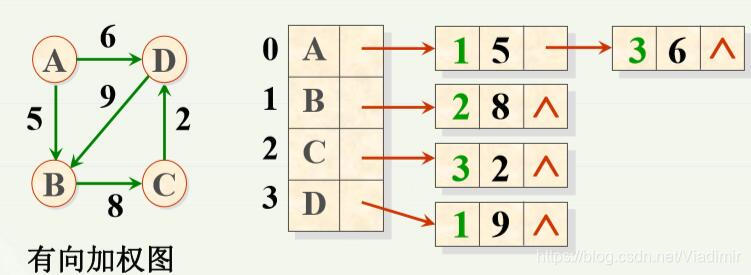
};(4)(链式)存储方式:用连续的地址空间存储图的数据元素,用单链表(非顺序 空间)存储(表示)元素之间的邻接关系;即把元素与哪 些元素有关系通过链表表示出来。如图:
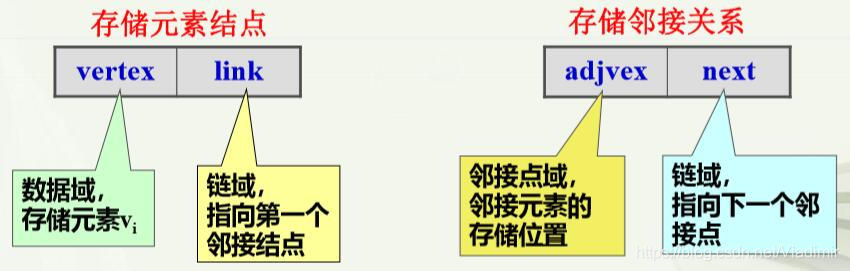
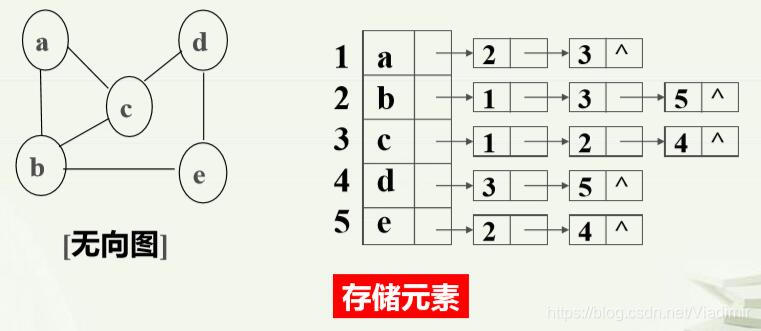
从无向图邻接表可以得到如下结论:
①第i 个链表中结点数目为顶点vi的度;
②所有链表中结点数目的一半为图中边数;
③占用的存储单元数目为n+2e 。
从有向图的邻接表可以得到如下结论:
①第i 个链表中结点数目为顶点vi的出度;
②所有链表中结点数目为图中弧数;
③占用的存储单元数目为n+e 。
类定义:
struct Edge //边结点(邻接点)的定义
{
int dest; //边的另一顶点位置
E cost; //边上的权值
Edge *link; //下一条边链指针
Edge(); //构造函数
Edge(int num,E cost):dest(num),weight(cost),link(NULL){}; //构造函数
bool operator != (Edge& R) const { return dest != R.dest; } //判边等否
};
struct Vertex //顶点的定义
{
T data; //顶点元素
Edge *adj; //边链表的头指针
};
class Graphlnk //图的类定义
{
friend istream& operator >> (istream& in, Graphlnk& G); //输入
friend ostream& operator << (ostream& out,Graphlnk & G); //输出
private:
Vertex *NodeTable; //顶点表(各边链表的头结点)
public:
int getVertexPos(const T vertx);//给出顶点vertex在图中的位置
Graphlnk(int sz=DefaultVertices);//构造函数
~Graphlnk();
T getValue(int i);第i个存储位置的元素值
E getWeight (T v1, T v2); //取边(v1,v2)权值
bool insertVertex (const T& vertex);
bool removeVertex (T v);
bool insertEdge (T v1, T v2, E cost);
bool removeEdge (T v1, T v2);
int getFirstNeighbor(T v);
int getNextNeighbor(T v, T w);
BFS_traversal(T v);
DFS_traversal (T v);
};
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









