









ChatGPT狂飙160天,世界已经不是之前的样子。
新建了免费的人工智能中文站https://ai.weoknow.com
新建了收费的人工智能中文站https://ai.hzytsoft.cn/
更多资源欢迎关注

MH-MoE 能优化几乎所有专家,实现起来非常简单。
混合专家(MoE)是个好方法,支持着现在一些非常优秀的大模型,比如谷歌家的 Gemini 1.5 以及备受关注的 Mixtral 8x7B。
稀疏混合专家(SMoE)可在不显著增加训练和推理成本的前提下提升模型的能力。比如 Mixtral 8×7B 就是一个 SMoE 模型,其包含 8 个专家(共 7B 参数),而其表现却可以超过或比肩 LLaMA-2 70B 和 GPT-3.5。
但是,它也有两个问题。一是专家激活率低 —— 也就是搞不好会出现下图这种情况:

具体来说,就是在优化时只有一小部分专家会被激活,如图 1a 所示(8.33% 的激活率),这会导致在学习应对复杂任务的大量专家时,会出现性能次优和效果不佳的问题。

二是无法细粒度地分析单个 token 的多重语义概念,比如多义词和具有多重细节的图块。
近日,微软研究院和清华大学提出了多头混合专家(MH-MoE)。顾名思义,MH-MoE 采用了多头机制,可将每个输入 token 分成多个子 token。然后将这些子 token 分配给一组多样化的专家并行处理,之后再无缝地将它们整合进原来的 token 形式。

-
论文标题:Multi-Head Mixture-of-Experts
-
论文地址:https://arxiv.org/pdf/2404.15045
-
代码地址:https://github.com/yushuiwx/MH-MoE
图 2 展示了 MH-MoE 的工作流程。可以看到,当输入单个 token 时,MH-MoE 会将其分成 4 个子 token,进而激活 4 个专家,而 SMoE 仅激活 1 个专家。
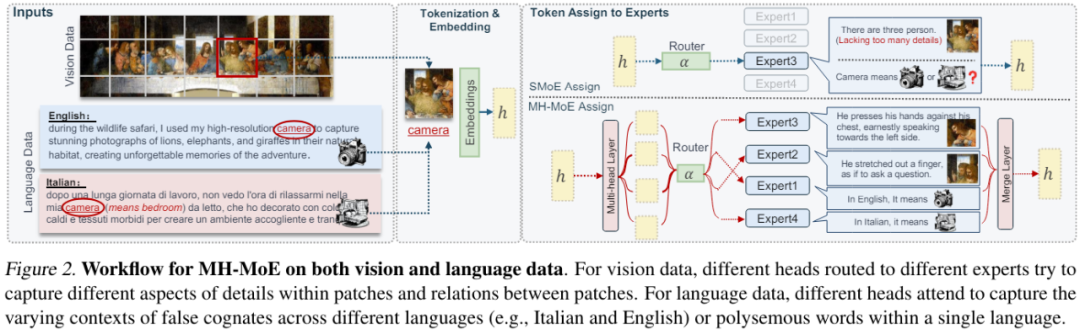
如图 2 所示,分配给专家 3 和 2 的子 token 包含对图块内每个角色动作的详细理解,而分配给专家 1 和 4 的子 token 则显式地建模了错误的同源词「camera」的语义。
专家处理完成后,再将子 token 无缝地重新整合进原来的 token 形式,由此可以避免后续非并行层(例如注意力层)的任何额外计算负担,同时还集成从多个专家捕获的语义信息。
这样的操作可让 MH-MoE 从整体上关注来自不同专家内不同表征空间的信息,从而可以加深上下文理解能力,同时提升专家激活率。该项目的代码也将发布。
MH-MoE 的具有以下优势:
-
专家激活率更高且扩展性更好。MH-MoE 能优化几乎所有专家,从而可以缓解专家激活率低的问题并大幅提升更大专家的使用率,如图 1a 所示实现了 90.71% 的激活率,这能让模型能力获得更高效的扩展。
-
具有更细粒度的理解能力。MH-MoE 采用的多头机制会将子 token 分配给不同的专家,从而可以联合关注来自不同专家的不同表征空间的信息,最终获得更好更细粒度的理解能力。举个例子,如图 1b 的明亮区域所示,子 token 会被分配给更多样化的一组专家,这有助于捕获语义丰富的信息。
-
可实现无缝整合。MH-MoE 实现起来非常简单,而且与其它 SMoE 优化方法(如 GShard)无关,反而可以将它们整合起来一起使用以获得更好的性能。
方法
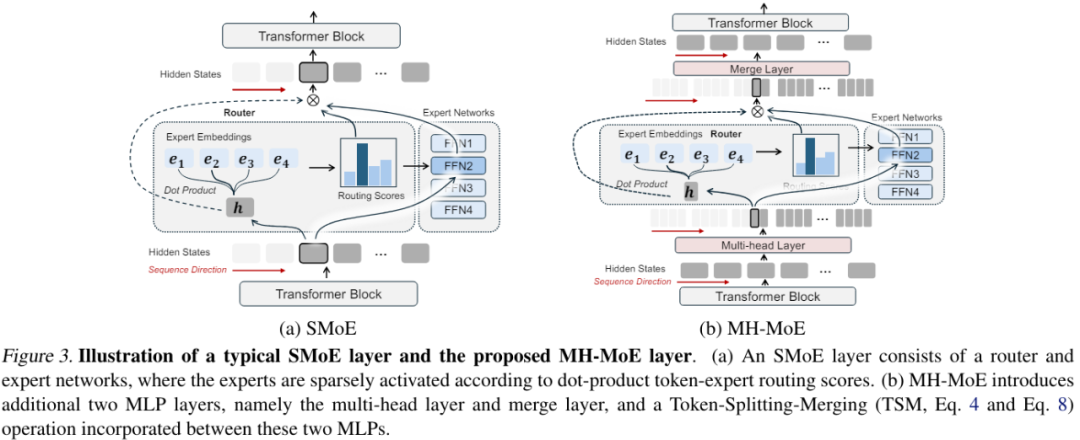
图 3 给出了 MH-MoE 的整体架构,其使用了多头机制将每个 token 分拆为子 token,然后将这些子 token 路由给不同的专家。
多头混合专家
为了能清楚说明,这里仅描述单层 MH-MoE。
首先,通过一个多头层将输入 token 序列投射成一个新序列。
之后,沿 token 维度将新序列中的每个 token 分拆为多个子 token,并根据原始 token 序列并行排布这些子 token,进而构成一个新的特征空间。
然后将所有这些子 token 输送给一个门控函数。将特定子 token 路由到第 p 个专家的门控值的计算方式为:
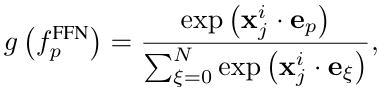
对于路由方法,这篇论文关注的重点方法是 top-k 路由,也就是激活路由分数最大的 k 个专家。然后让这些激活的专家处理子 token。
之后,按子 token 原来的顺序重新排布并整合所得结果。
然后,通过一个 token 合并操作将所得整合结果转换回原始 token 形式。
最后,使用一个融合层将转换后的结果投射成多个特征的有效整合形式,此时这些特征已捕获了不同专家表征空间的详细信息。这样便可得到单层 MH-MoE 的最终输出。
训练目标
MH-MoE 的训练目标是最小化两个损失:针对具体任务的损失和辅助性的负载平衡损失。
![]()
实验
实验设置
为了进行比较,该研究的实验采用了两种基准模型:(1) Dense,这是没有整合稀疏激活的并行模块(SMoE 层)的 Transformer 解码器。(2) X-MoE,基于 Chi et al. (2022) 的论文《On the representation collapse of sparse mixture of experts》提出的方法的实现。
实验中的 MH-MoE 基于 X-MoE 并使用了与其一样的设置。
实验任务有三个:以英语为中心的语言建模、多语言语言建模、掩码式多模态建模。
更多有关数据集和模型架构的设置请参阅原论文。
困惑度评估
他们在两种专家设置(8 个专家和 32 个专家)下研究了所有预训练模型和预训练任务的验证困惑度曲线。图 4 给出了困惑度趋势,表 1 是最终的困惑值。
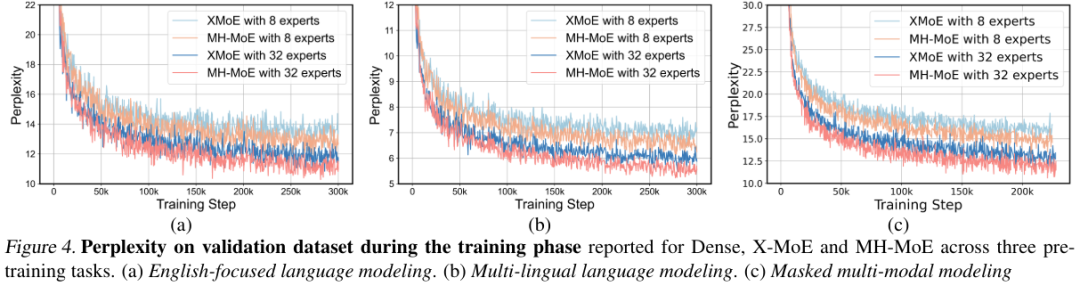
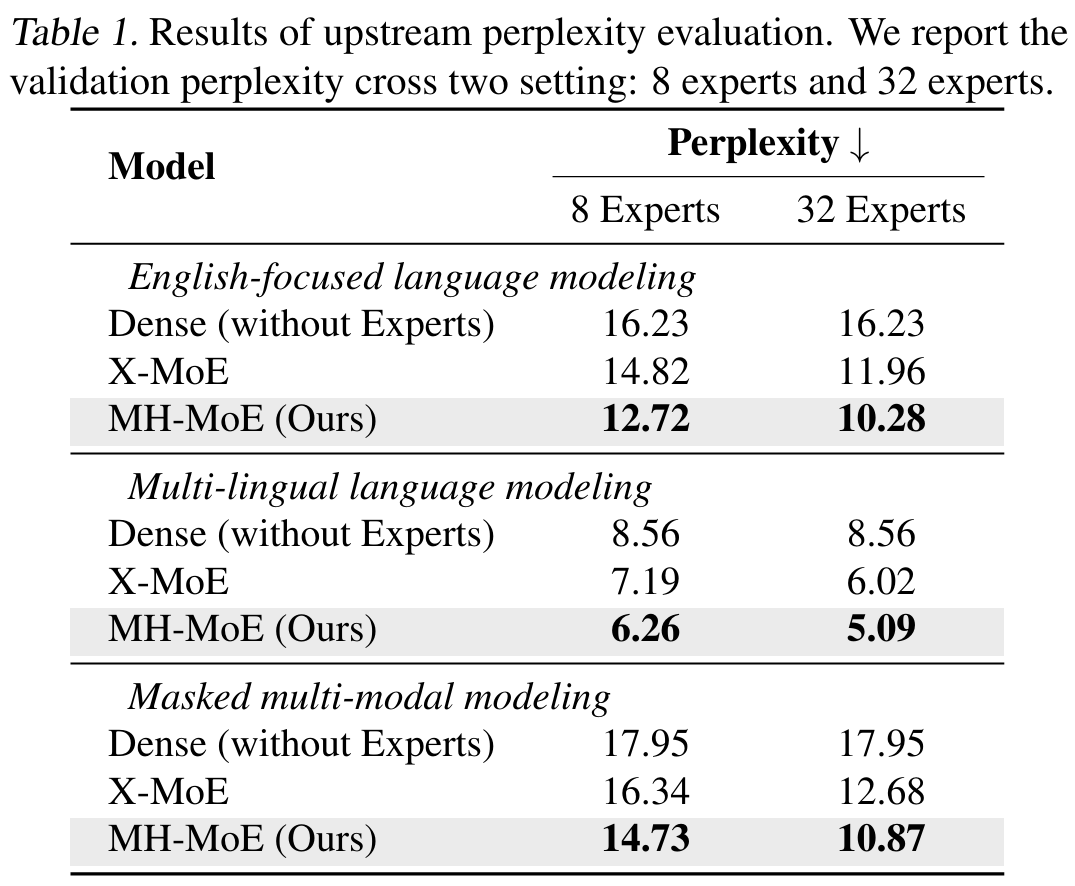
据此可以看出:
-
相比于基准,MH-MoE 的困惑度总是更低,这说明其能更有效地学习;
-
在三个不同的设置中,MH-MoE 的困惑度是最低的;
-
当专家数量增多时,MH-MoE 的困惑度会下降,这说明随着专家数量增多,其表征学习能力会提升,模型也能从中受益。
这些结果表明 MH-MoE 在多种预训练范式下都有更优的学习效率和语言表征能力。
ChatGPT狂飙160天,世界已经不是之前的样子。
新建了免费的人工智能中文站https://ai.weoknow.com
新建了收费的人工智能中文站https://ai.hzytsoft.cn/
更多资源欢迎关注














 172
172











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









