









综述--------------------------------------------------------------------
1. 问题
使用Transformer中PNS-Net代码 ( 论文 | 数据集及代码) ,其要求环境是python3.6,pytorch=1.1.0,重点来了,对服务器环境外的要求是这样的:
·Mark 1 ↓
Our core design is built on CUDA OP with torchlib. Please ensure the base CUDA toolkit version is 10.x (not at conda env), and then build the NS Block:
cd ./lib/PNS
python setup.py build develop
# setup.py
from setuptools import setup
from torch.utils.cpp_extension import BuildExtension, CUDAExtension
from os.path import join
# project_root = './lib/PNS/PNS_Module'
project_root = 'PNS_Module'
sources = [join(project_root, file) for file in ['sa_ext.cpp',
'sa.cu','reference.cpp']]
nvcc_args = [
'-gencode', 'arch=compute_61,code=sm_61',
'-gencode', 'arch=compute_70,code=sm_70',
'-gencode', 'arch=compute_70,code=compute_70'
]
cxx_args = ['-std=c++11']
setup(
name='self_cuda',
ext_modules=[
CUDAExtension('self_cuda_backend',
sources, extra_compile_args={'cxx': cxx_args,'nvcc': nvcc_args})
],
cmdclass={
'build_ext': BuildExtension
})
·Mark 1 ↑
但是服务器是这样的:
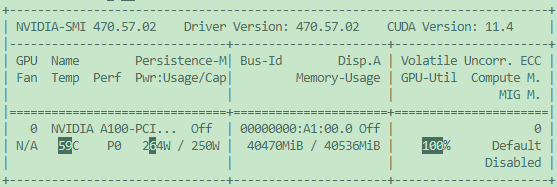
2. 测试本地docker在服务器上是否可用
打包本地PNS-Net的docker环境(py3.6-torch1.1.0-cuda10.1),本地宿主机是

打包镜像上传服务器,打开镜像容器后,经过·Mark 1处的代码,发现编译过程和本地没区别,但是运行代码的时候就会发现并没有调用GPU,GPU占用率为0,nvidia-smi里没有该程序,ps -ax才有相关程序。
升级高本pytorch版本和对应版本的cuda(比如torch1.7.0和cuda11.0),上面的·Mark 1可以运行,但是跑 train.py 时会报错:
ImportError: libcublas.so.10.0: cannot open shared object file: No such file or directory
找了两天,试过了各种问题,终于形成以下升级环境的方案。
方案--------------------------------------------------------------------
1. 为什么在Pytorch和CUDA已经升级的情况下,编译相关.cpp文件也成功了,运行train.py会报错:
> ImportError: libcublas.so.10.0: cannot open shared object file: No such file or directory
因为我之前没学过相关用 torch.utils.cpp_extension 中的 BuildExtension, CUDAExtension 去编译C程序,一开始都没想到,折腾pytorch和cuda版本去了。
最后发现就是因为 setup.py 里面的 nvcc_args 和 cxx_args 内容没匹配升级的cuda版本。
大家有兴趣的可以简单的看一下一下这些文章( pytorch通过torch.utils.cpp_extension构建CUDA/C++拓展 | Pytorch cuda extension的例子有没有简单点的啊…? | pytorch 的 CUDA 编程 CUDAExtension)就知道 setup.py 文件大致干了啥。
2.(可能需要的操作)更换环境内python
反正我这个需要是python3.6,后面报了其他错误就建议你换python3.6试一下。
更换python版本:docker容器内更换python版本以及pip版本。
如果python -V还是显示以前的python,删除软链接并重新建立链接无用的解决方法:
echo alias python=python3 >> ~/.bashrc
source ~/.bashrc
3. 安装CUDA11.0,Pytorch1.7.0 (服务器驱动环境较高,是向下兼容的)
可以直接去Docker Hub拉取镜像,也可以自己安装,主要是别整错安装版本了。
(1)安装Pytorch的过程中cuda一般也会一起安装:
Pytorch官网 有相关下载命令。


我个人嫌弃pip install 的命令太慢了,并且可能断掉报错,所以是直接去官网(torch和torchvision | torchaudio)下的安装包再上传服务器安装的

(2)CUDA自己安装可以参照这个:服务器docker安装多版本cuda
4. 修改nvcc_args
根据这篇文章(【转载】各种 NVIDIA 架构所匹配的 arch 和 gencode)

把 setup.py 中的
nvcc_args = [
'-gencode', 'arch=compute_61,code=sm_61',
'-gencode', 'arch=compute_70,code=sm_70',
'-gencode', 'arch=compute_70,code=compute_70'
]
修为改为:
nvcc_args = [
'-gencode', 'arch=compute_52,code=sm_52',
'-gencode', 'arch=compute_60,code=sm_60',
'-gencode', 'arch=compute_61,code=sm_61',
'-gencode', 'arch=compute_70,code=sm_70',
'-gencode', 'arch=compute_75,code=sm_75',
'-gencode', 'arch=compute_80,code=sm_80',
'-gencode', 'arch=compute_80,code=compute_80'
]
当时我的 cxx_args 还没改:
cxx_args = ['-std=c++11']
然后Mark 1的时候的报错中就有显示C++14的字样,后续就来到了步骤5.
5. 修改cxx_args
这些都是与gcc有关,查询自己的gcc版本:

然后查询gcc,cuda相关性(CUDA版本与Ubuntu 版本,以及GCC版本对应关系),以及GCC -std编译标准一览表




所以呢,我就修改成了这个:
cxx_args = ['-std=c++14']
6. 报错nvcc fatal : A single input file is required for a non-link phase when an outputfile is specified

7. 报错ninja
安装就完事了
pip install ninja
8. CMakeList.txt
### mod by v
get_directory_property(dir_defs DIRECTORY ${CMAKE_SOURCE_DIR} COMPILE_DEFINITIONS)
set(vtk_flags)
foreach(it ${dir_defs})
if(it MATCHES "vtk*")
list(APPEND vtk_flags ${it})
endif()
endforeach()
foreach(d ${vtk_flags})
remove_definitions(-D${d})
endforeach()
# set(CUDA_NVCC_FLAGS ${CUDA_NVCC_FLAGS} "-Xcompiler -D_GLIBCXX_USE_CXX11_ABI=0")
### mod by v
set(CUDA_NVCC_FLAGS ${CUDA_NVCC_FLAGS} "-std=c++14")
# set_property(TARGET SA PROPERTY CXX_STANDARD 11)
### mod by v
set_property(TARGET SA PROPERTY CXX_STANDARD 14)
总结--------------------------------------------------------------------
连续折腾了两三天,之前没学过这些玩意,主要是找到方向才能找到教程,写教程也是为了自己记得和分享解决问题的方法,希望能帮助到大家,让大家做科研的时候不会浪费时间在配置环境上。















 2983
2983











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









