







2.H264
本文参考:https://blog.csdn.net/garrylea/article/details/78536775 https://maxwellqi.github.io/ios-h264-summ/ https://blog.csdn.net/andywang201001/article/details/80274886
H264视频压缩算法是现在所有视频压缩技术中使用最广泛,最流行的。
H264压缩技术采用以下方法对视频数据进行压缩:
1.帧内预测,解决空域数据冗余问题。
2.帧间预测,解决时域数据冗余问题。
3.整数离散余弦编码(DCT),将空域相关性变换到频域上然后量化。
4.CABAC压缩。
原来图像的帧经过压缩后可分为:I帧,P帧,B帧。
I帧:关键帧。
P帧:向前参考帧,在压缩时,只参考前面已经处理的帧。
B帧:双向参考帧,在压缩时,即参考前面的帧,又参考后面的帧。
H264采用的核心算法是帧内预测和帧间预测。帧内预测是生成I帧的算法,帧间预测是生成B帧与P帧的算法。
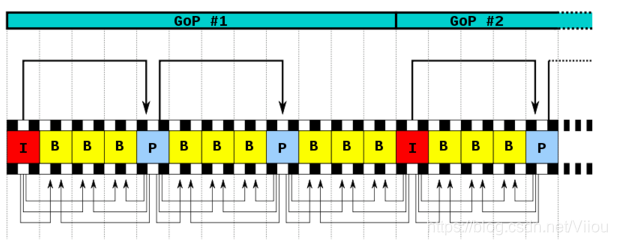
I帧,P帧,B帧的组合构成了图像序列GOP。
GOP:两个I帧构成一个图像序列,在一个图像序列中只有一个I帧。GOP如下图所示:
H264压缩算法其实很简单,它与我们直觉上压缩数据的思路是一样的,只不过更巧妙,更规范。
H264先将一幅图像划分为很多个宏块,默认采用16X16大小作为一个宏块,也可以是8X8大小。
以下图为例:

获得一个8*8大小的宏块。

H264对比较平坦的图像使用 16X16 大小的宏块。但为了更高的压缩率,还可以在 16X16 的宏块上更划分出更小的子块。子块的大小可以是 8X16、 16X8、 8X8、 4X8、 8X4、 4X4,非常的灵活。
在下图中是一个16X16的宏块,三只鹰的部分区域被划分在了宏块中,为了更好的处理三只鹰的部分图像,可以在宏块中划分出多个子块。

至此,H264的基础框架已经搭完了,剩下的就是运用想象力,达成目的。
在视频文件中,主要会有两种数据冗余,一种是时间上的数据冗余,另外一种是空间上的数据冗余。
时间上的数据冗余是最大的。比如说一部视频,在一段时间内,这些帧的内容是相关联的。对于这些关联密切的帧,我们只需要一帧的数据,其它帧的数据可以预测出来。所以在时间上数据冗余是最多的。
我们看这样一个例子,在一段视频中,台球从左下角滚到了右上角。



H264编码器会按照时间顺序,取出相邻的帧进行宏块比较,计算这两帧的关联度。
H264编码器如果发现这两个帧的关联度是非常高的,进而发现这一组帧关联度都是非常高的,就会将这几帧划分为一组。关联度判断的依据是:在相邻帧中,像素差别不超过10%,亮度差别不超过2%,色度差值不超过1%,这样的帧便可以分到一组。
在这样的一组帧中,我们只需要保留第一帧的完整数据,后面帧的内容可以根据第一帧的内容预测出来。所以我们称第一帧为I帧,其它的帧为P/B帧,这样的数据帧组称为GOP。
在将帧分组之后,便可以计算帧组内物体的运动矢量了。H264编码器首先取出帧组中前两帧的数据,然后进行宏块扫描,在一幅帧中有物体时,就在相邻另一个帧的邻近位置中搜索,如果在另一个帧中找到了物体,便得到了物体的运动矢量。


在上两幅图中,H264依次把每一帧中球移动的距离与方向都记录下来,得到了台球的运动矢量。
运动矢量计算后,再将相同部分也就是绿色部分减去,便得到了补偿数据。然后对补偿数据进行压缩保存,只需要记录很少一点数据。
在时域上的压缩是符合我们直觉的,将一段视频根据关联度分成多个数据帧组,然后计算出一组帧中变化的部分,不变的部分加上变化的部分便得到了P/B帧。帧间预测的主体思想还是很简单的。
帧间预测已经差不多了,接下来是帧内预测。
人眼对图像有一个识别度,对低频的亮度敏感,对高频的亮度不太敏感。基于这样的研究,可以将图像中人眼不敏感的数据去除,这样就形成了帧内预测技术。
H264的帧内预测与JPEG很相似。一幅图像划分好宏块后,对每个宏块进行9种模式的预测,找出最接近的一种预测模式。
下图是九种模式:

下面这张图是对整幅图中每个宏块预测的过程:

帧内预测后的图像与原始图像的对比:

然后,将原始图像与帧内预测后的图像相减得残差值:

然后再将我们之前得到的预测模式信息一起保存起来,在解码时就可以恢复原图了:

我们已经实现了帧内预测和帧间预测,还有优化的空间吗?有。
我们得到的残差数据也可以压缩,可以对残差数据做整数离散余弦变换,去掉数据的相关性,从而进一步压缩数据。
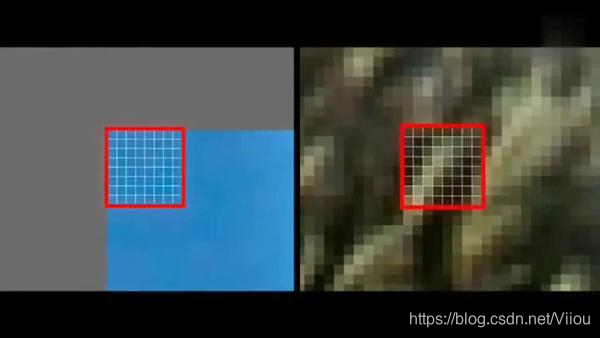
在下图中,左侧为原数据的宏块,右侧为残差数据的宏块。
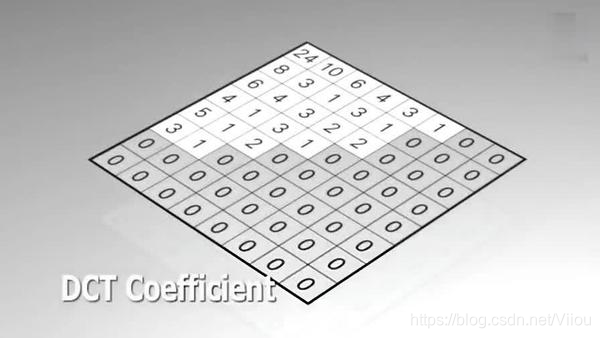
残差数据宏块数字化后如下图所示:

然后对这些数据进行DCT变换。DCT变换是离散余弦变换。DCT变换会舍弃高频的系数,然后对剩下的系数进行量化以进一步减少数据量。

去除掉关联的数据后,可以看到数据被进一步压缩了。
上面的帧内压缩属于有损压缩技术,图像被压缩后,无法完全复原。而CABAC属于无损压缩技术。CABAC的思想与霍夫曼编码相似,它给高频数据短码,给低频数据长码,同时根据上下文相关性进行压缩。
至此,H264的编码原理就差不多了,但这只是大体思想,许多地方我还似懂非懂,我想结合具体的实现深入理解一下。
上面是大体思想,而下面的就是H264的一些细节,对于帮助我们理解还是很有用的。
H264中内容从大到小依次是:序列,图像,片组,片,NALU,宏块,亚宏块,块,像素。















 1481
1481











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









