







转自:http://blog.csdn.net/google19890102/article/details/50522945
一、分类算法中的损失函数
在分类算法中,损失函数通常可以表示成损失项和正则项的和,即有如下的形式:
其中,L(mi(w))为损失项,R(w)为正则项。mi的具体形式如下:
对于损失项,主要的形式有:
- 0-1损失
- Log损失
- Hinge损失
- 指数损失
- 感知损失
1、0-1损失函数
在分类问题中,可以使用函数的正负号来进行模式判断,函数值本身的大小并不是很重要,0-1损失函数比较的是预测值fw(x(i))与真实值y(i)的符号是否相同,0-1损失的具体形式如下:
以上的函数等价于下述的函数:
0-1损失并不依赖m值的大小,只取决于m的正负号。0-1损失是一个非凸的函数,在求解的过程中,存在很多的不足,通常在实际的使用中将0-1损失函数作为一个标准,选择0-1损失函数的代理函数作为损失函数。
2、Log损失函数
2.1、Log损失
Log损失是0-1损失函数的一种代理函数,Log损失的具体形式如下:
运用Log损失的典型分类器是Logistic回归算法。
2.2、Logistic回归算法的损失函数
对于Logistic回归算法,分类器可以表示为:
为了求解其中的参数w,通常使用极大似然估计的方法,具体的过程如下:
1、似然函数
其中,
2、log似然
3、需要求解的是使得log似然取得最大值的w。将其改变为最小值,可以得到如下的形式:
2.3、两者的等价
由于Log损失的具体形式为:
Logistic回归与Log损失具有相同的形式,故两者是等价的。Log损失与0-1损失的关系可见下图。
3、Hinge损失函数
3.1、Hinge损失
Hinge损失是0-1损失函数的一种代理函数,Hinge损失的具体形式如下:
运用Hinge损失的典型分类器是SVM算法。
3.2、SVM的损失函数
对于软间隔支持向量机,允许在间隔的计算中出现少许的误差ξ⃗ =(ξ1,⋯,ξn),其优化的目标为:
约束条件为:
3.3、两者的等价
对于Hinge损失:
优化的目标是要求:
在上述的函数fw(x(i))中引入截距γ,即:
并在上述的最优化问题中增加L2正则,即变成:
至此,令下面的不等式成立:
约束条件为:
则Hinge最小化问题变成:
约束条件为:
这与软间隔的SVM是一致的,说明软间隔SVM是在Hinge损失的基础上增加了L2正则。
4、指数损失
4.1、指数损失
指数损失是0-1损失函数的一种代理函数,指数损失的具体形式如下:
运用指数损失的典型分类器是AdaBoost算法。
4.2、AdaBoost基本原理
AdaBoost算法是对每一个弱分类器以及每一个样本都分配了权重,对于弱分类器φj的权重为:
其中,R(φj)表示的是误分类率。对于每一个样本的权重为:
最终通过对所有分类器加权得到最终的输出。
4.3、两者的等价
对于指数损失函数:
可以得到需要优化的损失函数:
假设f~表示已经学习好的函数,则有:
而:
通过最小化φ,可以得到:
将其代入上式,进而对θ求最优解,得:
其中,
可以发现,其与AdaBoost是等价的。
5、感知损失
5.1、感知损失
感知损失是Hinge损失的一个变种,感知损失的具体形式如下:
运用感知损失的典型分类器是感知机算法。
5.2、感知机算法的损失函数
感知机算法只需要对每个样本判断其是否分类正确,只记录分类错误的样本,其损失函数为:
5.3、两者的等价
对于感知损失:
优化的目标为:
在上述的函数fw(x(i))中引入截距b,即:
上述的形式转变为:
对于max函数中的内容,可知:
对于错误的样本,有:
类似于Hinge损失,令下式成立:
约束条件为:
则感知损失变成:
即为:
Hinge损失对于判定边界附近的点的惩罚力度较高,而感知损失只要样本的类别判定正确即可,而不需要其离判定边界的距离,这样的变化使得其比Hinge损失简单,但是泛化能力没有Hinge损失强。
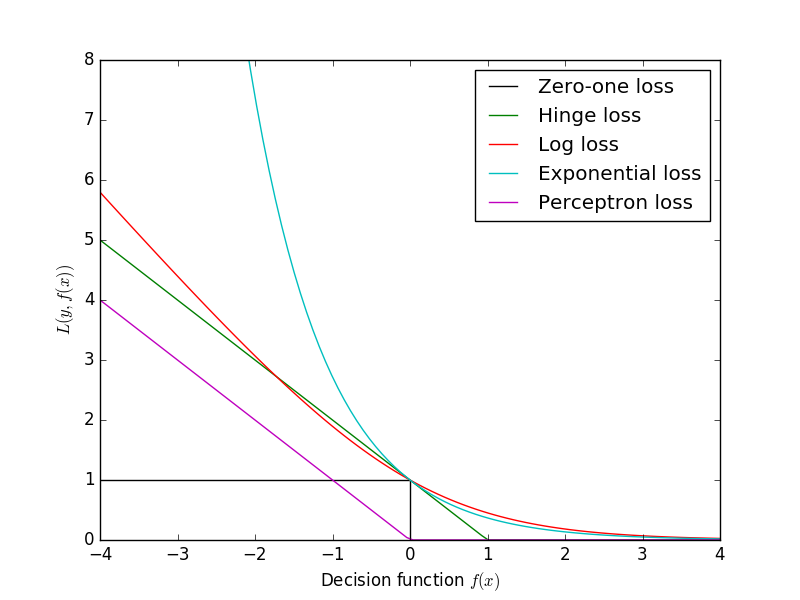
import matplotlib.pyplot as plt
import numpy as np
xmin, xmax = -4, 4
xx = np.linspace(xmin, xmax, 100)
plt.plot([xmin, 0, 0, xmax], [1, 1, 0, 0], 'k-', label="Zero-one loss")
plt.plot(xx, np.where(xx < 1, 1 - xx, 0), 'g-', label="Hinge loss")
plt.plot(xx, np.log2(1 + np.exp(-xx)), 'r-', label="Log loss")
plt.plot(xx, np.exp(-xx), 'c-', label="Exponential loss")
plt.plot(xx, -np.minimum(xx, 0), 'm-', label="Perceptron loss")
plt.ylim((0, 8))
plt.legend(loc="upper right")
plt.xlabel(r"Decision function $f(x)$")
plt.ylabel("$L(y, f(x))$")
plt.show()

转自:http://blog.csdn.net/u014313009/article/details/51043064
交叉熵代价函数(Cross-entropy cost function)是用来衡量人工神经网络(ANN)的预测值与实际值的一种方式。与二次代价函数相比,它能更有效地促进ANN的训练。在介绍交叉熵代价函数之前,本文先简要介绍二次代价函数,以及其存在的不足。
1. 二次代价函数的不足
ANN的设计目的之一是为了使机器可以像人一样学习知识。人在学习分析新事物时,当发现自己犯的错误越大时,改正的力度就越大。比如投篮:当运动员发现自己的投篮方向离正确方向越远,那么他调整的投篮角度就应该越大,篮球就更容易投进篮筐。同理,我们希望:ANN在训练时,如果预测值与实际值的误差越大,那么在反向传播训练的过程中,各种参数调整的幅度就要更大,从而使训练更快收敛。然而,如果使用二次代价函数训练ANN,看到的实际效果是,如果误差越大,参数调整的幅度可能更小,训练更缓慢。
以一个神经元的二类分类训练为例,进行两次实验(ANN常用的激活函数为sigmoid函数,该实验也采用该函数):输入一个相同的样本数据x=1.0(该样本对应的实际分类y=0);两次实验各自随机初始化参数,从而在各自的第一次前向传播后得到不同的输出值,形成不同的代价(误差):
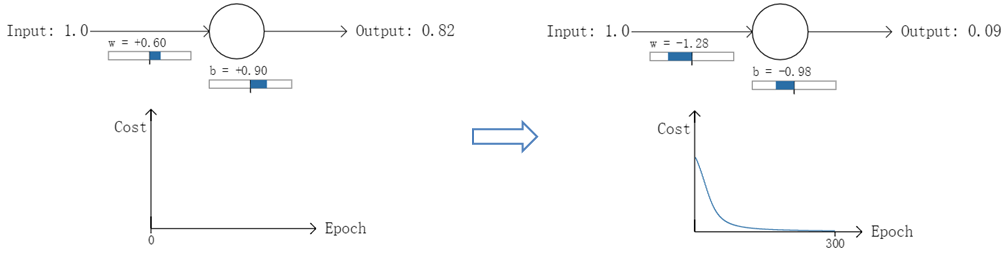
实验1:第一次输出值为0.82

实验2:第一次输出值为0.98
在实验1中,随机初始化参数,使得第一次输出值为0.82(该样本对应的实际值为0);经过300次迭代训练后,输出值由0.82降到0.09,逼近实际值。而在实验2中,第一次输出值为0.98,同样经过300迭代训练,输出值只降到了0.20。
从两次实验的代价曲线中可以看出:实验1的代价随着训练次数增加而快速降低,但实验2的代价在一开始下降得非常缓慢;直观上看,初始的误差越大,收敛得越缓慢。
其实,误差大导致训练缓慢的原因在于使用了二次代价函数。二次代价函数的公式如下:
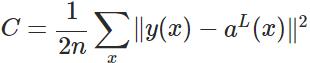
其中,C表示代价,x表示样本,y表示实际值,a表示输出值,n表示样本的总数。为简单起见,同样一个样本为例进行说明,此时二次代价函数为:
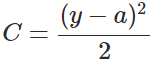
目前训练ANN最有效的算法是反向传播算法。简而言之,训练ANN就是通过反向传播代价,以减少代价为导向,调整参数。参数主要有:神经元之间的连接权重w,以及每个神经元本身的偏置b。调参的方式是采用梯度下降算法(Gradient descent),沿着梯度方向调整参数大小。w和b的梯度推导如下:
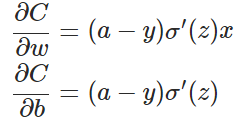
其中,z表示神经元的输入,
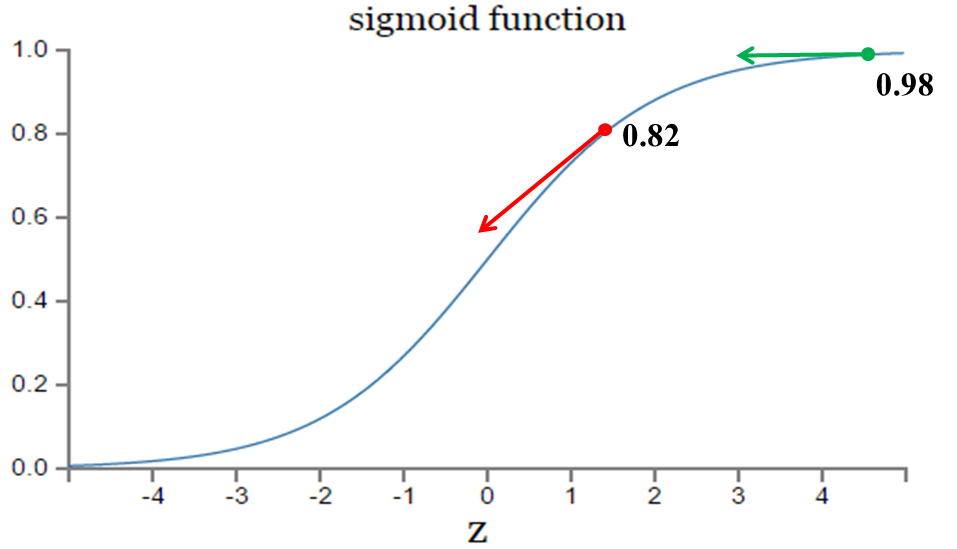
如图所示,实验2的初始输出值(0.98)对应的梯度明显小于实验1的输出值(0.82),因此实验2的参数梯度下降得比实验1慢。这就是初始的代价(误差)越大,导致训练越慢的原因。与我们的期望不符,即:不能像人一样,错误越大,改正的幅度越大,从而学习得越快。
可能有人会说,那就选择一个梯度不变化或变化不明显的激活函数不就解决问题了吗?图样图森破,那样虽然简单粗暴地解决了这个问题,但可能会引起其他更多更麻烦的问题。而且,类似sigmoid这样的函数(比如tanh函数)有很多优点,非常适合用来做激活函数,具体请自行google之。
2. 交叉熵代价函数
换个思路,我们不换激活函数,而是换掉二次代价函数,改用交叉熵代价函数:
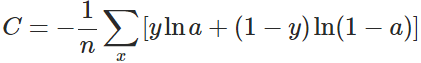
其中,x表示样本,n表示样本的总数。那么,重新计算参数w的梯度:
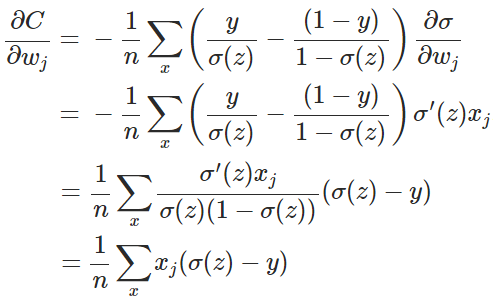
其中(具体证明见附录):
因此,w的梯度公式中原来的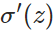

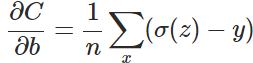
实际情况证明,交叉熵代价函数带来的训练效果往往比二次代价函数要好。
3. 交叉熵代价函数是如何产生的?
以偏置b的梯度计算为例,推导出交叉熵代价函数:
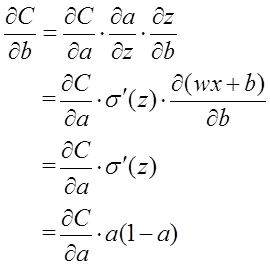
在第1小节中,由二次代价函数推导出来的b的梯度公式为:
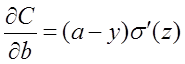
为了消掉该公式中的
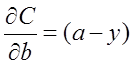
即:
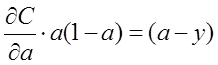
对两侧求积分,可得:
而这就是前面介绍的交叉熵代价函数。
附录:
sigmoid函数为:

可证:
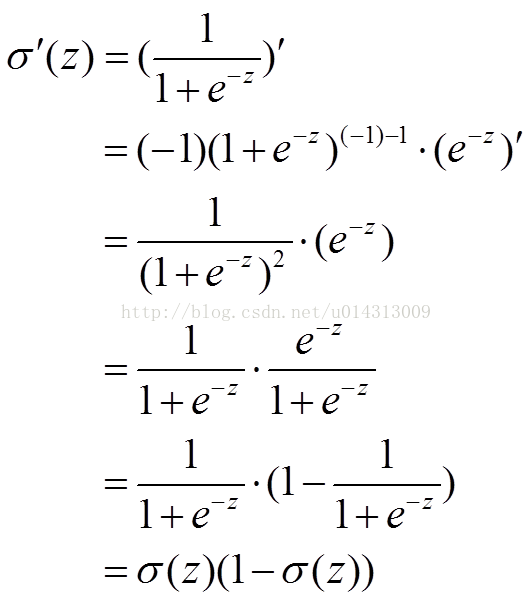
更系统的回答:
在之前的内容中,我们用的损失函数都是平方差函数,即
其中y是我们期望的输出,a为神经元的实际输出(a=σ(Wx+b)。也就是说,当神经元的实际输出与我们的期望输出差距越大,代价就越高。想法非常的好,然而在实际应用中,我们知道参数的修正是与∂C∂W和∂C∂b成正比的,而根据
我们发现其中都有σ′(a)这一项。因为sigmoid函数的性质,导致σ′(z)在z取大部分值时会造成饱和现象,从而使得参数的更新速度非常慢,甚至会造成离期望值越远,更新越慢的现象。那么怎么克服这个问题呢?我们想到了交叉熵函数。我们知道,熵的计算公式是
而在实际操作中,我们并不知道y的分布,只能对y的分布做一个估计,也就是算得的a值, 这样我们就能够得到用a来表示y的交叉熵
如果有多个样本,则整个样本的平均交叉熵为
其中n表示样本编号,i表示类别编。 如果用于logistic分类,则上式可以简化成
与平方损失函数相比,交叉熵函数有个非常好的特质,
可以看到其中没有了σ′这一项,这样一来也就不会受到饱和性的影响了。当误差大的时候,权重更新就快,当误差小的时候,权重的更新就慢。这是一个很好的性质。
3.总结
-
当我们用sigmoid函数作为神经元的激活函数时,最好使用交叉熵代价函数来替代方差代价函数,以避免训练过程太慢。
-
不过,你也许会问,为什么是交叉熵函数?导数中不带σ′(z)项的函数有无数种,怎么就想到用交叉熵函数?这自然是有来头的,更深入的讨论就不写了,少年请自行了解。
-
另外,交叉熵函数的形式是−[ylna+(1−y)ln(1−a)]而不是 −[alny+(1−a)ln(1−y)],为什么?因为当期望输出的y=0时,lny没有意义;当期望y=1时,ln(1-y)没有意义。而因为a是sigmoid函数的实际输出,永远不会等于0或1,只会无限接近于0或者1,因此不存在这个问题。
4.还要说说:log-likelihood cost
对数似然函数也常用来作为softmax回归的代价函数,在上面的讨论中,我们最后一层(也就是输出)是通过sigmoid函数,因此采用了交叉熵代价函数。而深度学习中更普遍的做法是将softmax作为最后一层,此时常用的是代价函数是log-likelihood cost。
In fact, it’s useful to think of a softmax output layer with log-likelihood cost as being quite similar to a sigmoid output layer with cross-entropy cost。
其实这两者是一致的,logistic回归用的就是sigmoid函数,softmax回归是logistic回归的多类别推广。log-likelihood代价函数在二类别时就可以化简为交叉熵代价函数的形式。
参考文章
补充一个困扰我很久的问题:
http://blog.csdn.net/liujiandu101/article/details/55103326
由于我用的是Torch,一直在纠结该用那个损失函数,上面这篇文章简单介绍了下。
另外:https://zhuanlan.zhihu.com/p/21432547?refer=dlclass
总结:
softmax 损失函数,适合单标签多分类问题
欧式损失函数(就是均方误差),适合实数值回归问题
sigmod 交叉熵,适合多标签分类问题,这里上面说是主要用在二分类,暂时理解为多标签二分类问题。
contrastive loss,适合深度测度学习,就是siamese网络的相似度学习。















 3058
3058

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









