







一、scroll说明和使用场景
scroll的使用场景:大数据量的检索和操作
scroll顾名思义,就是游标的意思,核心的应用场景就是遍历 elasticsearch中的数据;
通常我们遍历数据采用的是分页,elastcisearch还支持from size的方式进行分页查询,使用 from and size 的深度分页,比如说 ?size=10&from=10000,因为 100,000 排序的结果必须从每个分片上取出并重新排序最后返回 10 条。这个过程需要对每个请求页重新进行提取+排序,效率很低,消耗很大,所以默认的最大可分页的数据是10000,超过10000是不建议的;
使用
通过在url末尾带上scroll=1m表示开启一个游标,1m表示游标的有效期为1分钟
POST /record/_search?scroll=1m
{
"from": 0,
"size": 20
}
返回结果中会把scroll的id带上,再次查询的时候,直接用scroll id查询即可
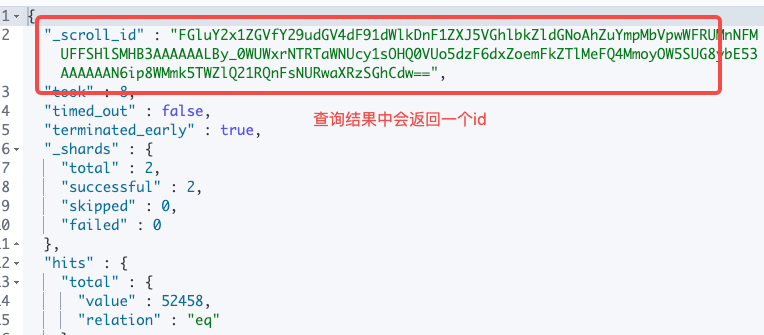
POST /_search/scroll
{
"scroll" : "1m",
"scroll_id" : "FGluY2x1ZGVfY29udGV4dF91dWlkDnF1ZXJ5VGhlbkZldGNoAhZuYmpMbVpwWFRUMnNFMUFFSHlSMHB3AAAAAALBy_0WUWxrNTRTaWNUcy1sOHQ0VUo5dzF6dxZoemFkZTlMeFQ4MmoyOW5SUG8ybE53AAAAAAN6ip8WMmk5TWZlQ21RQnFsNURwaXRzSGhCdw=="
}
二、基于ElasticsearchRestTemplate的实现
这里我们定义了一个template如下,主要作用就是实现一个基于scroll的数据遍历模板,屏蔽开启scroll 以及 scroll遍历所有数据,通过Consumer<T>钩子函数进行数据处理
import lombok.extern.slf4j.Slf4j;
import org.elasticsearch.index.query.BoolQueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.springframework.data.domain.PageRequest;
import org.springframework.data.elasticsearch.core.ElasticsearchRestTemplate;
import org.springframework.data.elasticsearch.core.SearchHit;
import org.springframework.data.elasticsearch.core.SearchScrollHits;
imp 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









