







讲过二分已经一段时间,现在老师又找一道二分题来练手#A#,起初就是对两个大大的西格玛有点兴趣,做起来发现这题出题人还是很心机的啊啊!
现在来一波题目:
2.聪明的质监员
(qc.cpp/c/pas)
【问题描述】
小 T 是一名质量监督员,最近负责检验一批矿产的质量。这批矿产共有 n 个矿石,从 1
到 n 逐一编号,每个矿石都有自己的重量 wi 以及价值 vi。检验矿产的流程是:
1、给定 m个区间[Li,Ri];
2、选出一个参数 W;
3、对于一个区间[Li,Ri],计算矿石在这个区间上的检验值 Yi :
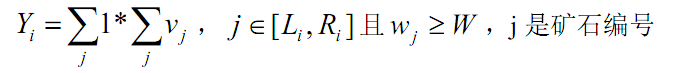
这批矿产的检验结果Y为各个区间的检验值之和。即:
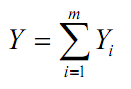
若这批矿产的检验结果与所给标准值 S 相差太多,就需要再去检验另一批矿产。小T不想费时间去检验另一批矿产,所以他想通过调整参数 W 的值,让检验结果尽可能的靠近标准值 S,即使得 S-Y的绝对值最小。请你帮忙求出这个最小值。
【输入】
输入文件 qc.in。
第一行包含三个整数 n,m,S,分别表示矿石的个数、区间的个数和标准值。
接下来的 n行,每行 2个整数,中间用空格隔开,第 i+1 行表示 i 号矿石的重量 wi 和价
值 vi 。
接下来的 m行,表示区间,每行 2个整数,中间用空格隔开,第 i+n+1 行表示区间[Li, Ri]的两个端点 Li 和 Ri。注意:不同区间可能重合或相互重叠。
【输出】
输出文件名为 qc.out。
输出只有一行,包含一个整数,表示所求的最小值。
【输入输出样例】
qc.in
5 3 15
1 5
2 5
3 5
4 5
5 5
1 5
2 4
3 3
qc.out
10
【输入输出样例说明】
当 W 选 4 的时候,三个区间上检验值分别为 20、5、0,这批矿产的检验结果为 25,此时与标准值 S相差最小为 10。
【数据范围】
对于 10%的数据,有 1≤n,m≤10;
对于 30%的数据,有 1≤n,m≤500;
对于 50%的数据,有 1≤n,m≤5,000;
对于 70%的数据,有 1≤n,m≤10,000;
对于 100%的数据,有 1≤n,m≤200,000,0 < wi, vi≤10^6,0 < S≤10^12,1≤Li≤Ri≤n。
题目就是这些啊,至于本人只是水水题也就不写文件操作了。
#include<iostream>
#include<cmath>
using namespace std;
const int N = 200005;
int n,m,maxw=0,w[N],v[N],L[N],R[N];
long long s,ans,sum[N],sumv[N];//毕竟有10^12
//尽是些按题目声明的变量,感觉就是看到什么就写什么hh
long long f(int W)//这个函数用来求Y
{
sum[0]=sumv[0]=0;
for(int i=1;i<=n;i++)
if(w[i]>W)
sum[i]=sum[i-1]+1,sumv[i]=sumv[i-1]+v[i];
else sum[i]=sum[i-1],sumv[i]=sumv[i-1];
long long y=0;
for(int i=1;i<=m;i++)
y+=(sum[R[i]]-sum[L[i]-1])*(sumv[R[i]]-sumv[L[i]-1]);
return y;
}
/*关键在于重量和的时候。应该用求差的方式去解决计算次数问题。即算
区间[a,b]内符合矿石的重量和时,要用区间[0,b]的重量和减去[0,a]的重量和*/
void solve()
{
int low,mid,high;
long long Y;
for(low=0,high=maxw;low<=high;)
{
mid=(low+high)/2;
Y=f(mid); //检验值之和
if(Y<s) high=mid-1; //二分瞎找
else low=mid+1;
}
long long x,y;
x=abs(f(low)-s); y=abs(f(high)-s);
ans=x<y?x:y;
}
int main()
{
cin>>n>>m>>s; //矿石个数、区间个数、标准值
for(int i=1;i<=n;i++){
cin>>w[i]>>v[i]; // 重量、价值
if(w[i]>maxw) maxw=w[i]; //maxw最大重量
}
for(int i=1;i<=m;i++) cin>>L[i]>>R[i]; //各区间
solve();
cout<<ans<<endl;
return 0;
}此题在codeup上可以通过。
但是到这是否就完了呢?看上去运行都是正常了,但对于那些数据规模非常大的数据呢?我们无法手输,不知道具体的运行情况如何(即有没有超时)。然后我找了一下各大OJ,毕竟是真题,OJ上基本都有。比如说洛谷和TYVJ,这两个网站上的本题都有20个点,可以提交一次试试看。

通过思考题目时的计算,其计算量应该不会导致程序超时,该从何找问题呢?
换用scanf输入,scanf和cin的差异实在是大,一个只能无比,但耗时是个问题,尤其是在面对100000个以上的数据输入时。这种时候我一般采用scanf输入(多打几个字又不会死……)。
于是我们发现情况变得无比乐观:

这就是庞大数据面前cin和scanf的效率差异啊!!!使用scanf最多只用200+ms,是cin的五分之一都不到。















 315
315

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









