







好玩的点
- 3.3 explain
- 3.5 对象大小
- 3.6.1 使用具体字段+覆盖索引
- 4 额外优化-TLAB
1. 背景
用户查询三个月内会议记录时,返回结果的平均时延高达三四秒。
1.1 优化目标
降低接口时延,响应时间要在200ms以内
优化有三个维度:分别是吞吐量、时延、系统容量。
- 吞吐量:指的是单位时间内系统能完成多少操作
- 时延:指的是操作的响应时间,比如说搜索商品的结果必须在200ms内展示给用户
- 系统容量:指的是在吞吐量和时延达标的情况下,对硬件环境的额外约束
1.2 涉及优化点
网络IO、SQL优化、对象大小、TLAB
1.3 涉及分析工具/命令
arthas、top、jstack、explain
1.4 调优步骤
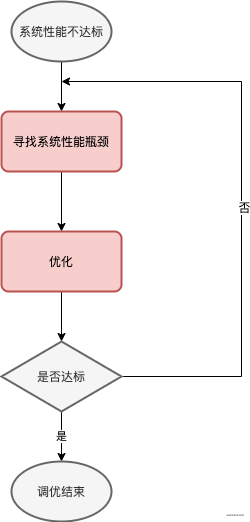
我在分析的时候,喜欢先从系统层面去排查分析,比如从CPU、内存、网络、磁盘这几个维度上寻找,从而定位有问题的代码,自上而下。
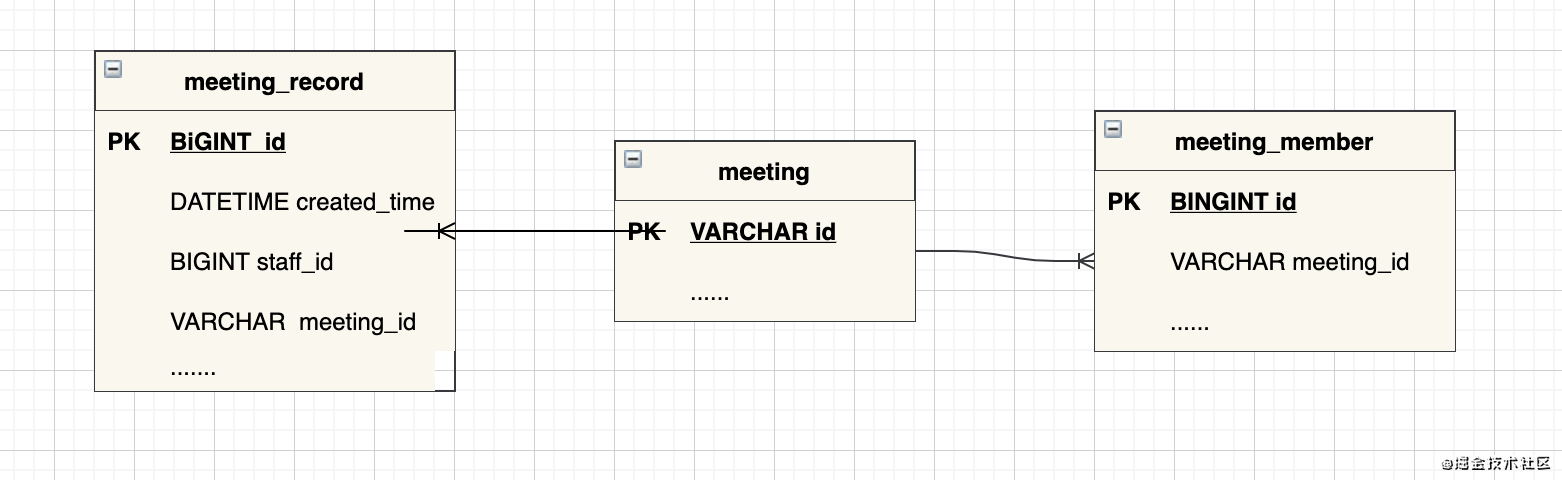
1.5 压测数据准备
模拟线上用户最大的数据记录,三个月内一共有200条会议记录,每条会议记录平均有十个参会人
数据关系如下
2. 寻找接口瓶颈(循环HTTP请求)
2.1 top
压测时用top命令查看CPU的使用率

发现四核的机子,我们的应用占的CPU只有120%,不太合理,这时候可以用jstack命令看看Java进程里面的线程都在干嘛
2.2 jstack
我们可以用 top -Hp PID来显示进程内所有线程的情况,再把线程对应的PID转成十六进制,再用jstack命令查看该线程的工作情况,但是我觉得这样要一个一个地会比较麻烦
我比较喜欢直接用 jstack -l Java进程的PID > stack.txt,然后把文件拉下来分析。
只jstack一次可能是不准确的,jstack是打印线程快照,那么有可能在某一时刻打印出来的快照是正常的,所以应该多jstack几次来分析
结果发现,有大量线程被阻塞在了java.net.SocketInputStream.socketRead0(Native Method)这上面,根据堆栈信息发现,是代码里面一个循环体里面进行了第三方的接口调用导致的
for (MeetingRecord meetingRecord : MeetingRecords) {
// 到其他应用获取某些信息,好家伙!!!
getVirtualRoomById(meetingRecord.getId());
}
当时就想看看这里的耗时有多久,就用arthas的trace命令看下
2.3 arthas
trace class-pattern method-pattern查看方法内部调用路径,并输出方法路径上的每个节点上耗时

这次请求的循环体里,耗时最小的一次调用为7ms,最大1069ms,一共22秒。

2.4 解决
知道原因就好办了,改成批量查询就好,再用arthas看看

好的,这个大头解决了。
不过时延还没达标,平均时延虽然降到了300ms,但是还没达标呢,只能继续优化
苦笑.png
3. 寻找系统瓶颈(SQL优化)
还是老样子,先用top命令看下CPU的使用率
3.1 top

好了,这时候看到CPU的使用
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1405
1405











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









