






主要记录一下目前进度。
1.后端更新
历史记录查询
我们的项目中提供了用户的查询功能,同时保留了用户的查询历史记录。对于我们的项目来说,查询历史记录功能能够追踪用户活动、提高用户体验、确保法律合规、支持数据分析与优化,并在需要时提供数据恢复与备份,从而提升整体系统的功能性和用户满意度。
查询历史记录功能没有独立的接口,其主要功能与药品查询和疾病查询功能相耦合。查询过程会将历史记录插入到数据库里。
登录与注册
我们的项目由于是一个需要验证用户注册信息的在线网站,因此有必要实现邮件验证的功能。而Spring Framework 提供了简单且强大的邮件发送功能,我们的发送邮件验证码功能正是基于此开发。
实现登录拦截器。如果用户没有登录,则会重定向到登录页面;如果用户已经登录,则允许请求继续处理。通过登录拦截器确保了未登录的用户不能访问受保护的资源或页面,以实现权限控制。
一些细节类
常量类规范用户操作类型:定义用户操作类型
通用的响应结果封装类:统一处理HTTP请求的响应,封装结果,便于前后端交互调试
异常响应类:发生异常时返回详细信息
断言工具类:判断是否为空
复制工具类:提升拷贝性能
变量名工具类:快速命名风格转换
实体类
存储和管理疾病信息、用户信息、药物信息等等的实体类和接口设计
2.前端
使用流行的 Java 模板引擎 —— Thymeleaf,以在 Spring 框架中生成动态网页
common-bar.html——导航栏,
add-illness.html——添加疾病,
add-medical.html——添加药品,
all-feedback.html——个人信息中全部反馈,
all-illness.html——个人信息中全部疾病,
all-medical.html——个人信息中全部药品,
doctor.html——智慧医生,
feedback.html——添加反馈,
illness.html——全部疾病,
illness-reviews.html——疾病,
我们将不同大模型API放入两个界面中,使得登录用户可以选择更高效的大模型。
3.大模型尝试
Ming
在前述文章里面,我们成功地把MING部署在了AutoDL服务器上,但有一个问题在于,MING的开发者们并没有尝试过使用REStfulAPI的形式对大模型进行访问,提供的api服务组件也是不全的。因此我们根据现有代码,写了针对ming-moe模型的一套简易model_worker、controller和api服务。
MING-MOE模型是基于Qwen的Moe模型,这意味着需要Qwen作为对应的模型基座,做一个合并才能正常使用。
部署代码如下:
import argparse
import asyncio
import dataclasses
import logging
import json
import time
import threading
import uuid
from fastapi import FastAPI, Request, BackgroundTasks
from fastapi.responses import StreamingResponse, JSONResponse
import requests
try:
from transformers import AutoTokenizer, AutoModelForCausalLM, LlamaTokenizer, AutoModel
except ImportError:
from transformers import AutoTokenizer, AutoModelForCausalLM, LLaMATokenizer, AutoModel
import torch
import uvicorn
from ming.serve.inference import load_molora_pretrained_model, load_pretrained_model, generate_stream
from ming.conversations import conv_templates, get_default_conv_template, SeparatorStyle
from fastchat.utils import (build_logger, pretty_print_semaphore)
from fastchat.constants import ErrorCode, SERVER_ERROR_MSG, WORKER_HEART_BEAT_INTERVAL
GB = 1 << 30
worker_id = str(uuid.uuid4())[:6]
logger = build_logger("model_worker", f"model_worker_{worker_id}.log")
global_counter = 0
model_semaphore = None
CONTROLLER_HEART_BEAT_EXPIRATION = 90
WORKER_HEART_BEAT_INTERVAL = 30
def heart_beat_worker(controller):
while True:
time.sleep(WORKER_HEART_BEAT_INTERVAL)
controller.send_heart_beat()
class ModelWorker:
def __init__(self, controller_addr, worker_addr,
worker_id, no_register, model_path, model_name, model_base,
device, num_gpus, max_gpu_memory, load_8bit=False):
self.controller_addr = controller_addr
self.worker_addr = worker_addr
self.worker_id = worker_id
self.beam_size = 1
self.conv = conv_templates["qwen"].copy()
if model_path.endswith("/"):
model_path = model_path[:-1]
self.model_name = model_name or model_path.split("/")[-1]
self.device = device
logger.info(f"Loading the model {self.model_name} on worker {worker_id} ...")
self.tokenizer, self.model, self.context_len, _ = load_molora_pretrained_model(model_path, model_base,
model_name, load_8bit,
None,
use_logit_bias=None,
only_load=None,
expert_selection=None)
if hasattr(self.model.config, "max_sequence_length"):
self.context_len = self.model.config.max_sequence_length
elif hasattr(self.model.config, "max_position_embeddings"):
self.context_len = self.model.config.max_position_embeddings
else:
self.context_len = 3072
self.generate_stream_func = generate_stream
if not no_register:
self.register_to_controller()
self.heart_beat_thread = threading.Thread(
target=heart_beat_worker, args=(self,))
self.heart_beat_thread.start()
def register_to_controller(self):
logger.info("Register to controller")
url = self.controller_addr + "/register_worker"
data = {
"worker_name": self.worker_addr,
"check_heart_beat": True,
"worker_status": self.get_status()
}
r = requests.post(url, json=data)
assert r.status_code == 200
def send_heart_beat(self):
logger.info(f"Send heart beat. Models: {[self.model_name]}. "
f"Semaphore: {pretty_print_semaphore(model_semaphore)}. "
f"global_counter: {global_counter}")
url = self.controller_addr + "/receive_heart_beat"
while True:
try:
ret = requests.post(url, json={
"worker_name": self.worker_addr,
"queue_length": self.get_queue_length()}, timeout=5)
exist = ret.json()["exist"]
break
except requests.exceptions.RequestException as e:
logger.error(f"heart beat error: {e}")
time.sleep(5)
if not exist:
self.register_to_controller()
def get_queue_length(self):
if model_semaphore is None or model_semaphore._value is None or model_semaphore._waiters is None:
return 0
else:
return args.limit_model_concurrency - model_semaphore._value + len(
model_semaphore._waiters)
def get_status(self):
return {
"model_names": [self.model_name],
"speed": 1,
"queue_length": self.get_queue_length(),
}
def get_conv_template(self):
return {"conv": self.conv}
def generate_stream_gate(self, params):
try:
output = self.generate_stream_func(self.model, self.tokenizer,params, self.device, self.beam_size, self.context_len,args.stream_interval)
ret = {
"text": output,
"error_code": 0,
}
yield json.dumps(ret).encode() + b"\0"
except torch.cuda.OutOfMemoryError as e:
ret = {
"text": f"{SERVER_ERROR_MSG}\n\n({e})",
"error_code": ErrorCode.CUDA_OUT_OF_MEMORY,
}
yield json.dumps(ret).encode() + b"\0"
except (ValueError, RuntimeError) as e:
ret = {
"text": f"{SERVER_ERROR_MSG}\n\n({e})",
"error_code": ErrorCode.INTERNAL_ERROR,
}
yield json.dumps(ret).encode() + b"\0"
def generate_gate(self, params):
for x in self.generate_stream_gate(params):
pass
return json.loads(x)
app = FastAPI()
def release_model_semaphore():
model_semaphore.release()
@app.post("/worker_generate_stream")
async def api_generate_stream(request: Request):
global model_semaphore, global_counter
global_counter += 1
params = await request.json()
if model_semaphore is None:
model_semaphore = asyncio.Semaphore(args.limit_model_concurrency)
await model_semaphore.acquire()
generator = worker.generate_stream_gate(params)
background_tasks = BackgroundTasks()
background_tasks.add_task(release_model_semaphore)
return StreamingResponse(generator, background=background_tasks)
@app.post("/worker_generate")
async def api_generate(request: Request):
global model_semaphore, global_counter
global_counter += 1
params = await request.json()
if model_semaphore is None:
model_semaphore = asyncio.Semaphore(args.limit_model_concurrency)
await model_semaphore.acquire()
output = await asyncio.to_thread(worker.generate_gate, params)
model_semaphore.release()
return JSONResponse(output)
@app.post("/worker_get_status")
async def api_get_status(request: Request):
return worker.get_status()
@app.post("/worker_get_conv_template")
async def api_get_conv(request: Request):
return worker.get_conv_template()
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--host", type=str, default="localhost")
parser.add_argument("--port", type=int, default=21002)
parser.add_argument("--worker-address", type=str,
default="http://localhost:21002")
parser.add_argument("--controller-address", type=str,
default="http://localhost:21001")
parser.add_argument("--model-path", type=str, default="root/autodl-tmp/MING-MOE-4B",
help="The path to the weights")
parser.add_argument("--model-name", type=str,
help="Optional name")
parser.add_argument("--model-base", type=str, default="/root/autodl-tmp/Qwen1.5-4B-Chat",
help="The base model")
parser.add_argument("--device", type=str, choices=["cpu", "cuda", "mps"], default="cuda")
parser.add_argument("--num-gpus", type=int, default=1)
parser.add_argument("--max-gpu-memory", type=str, default="13GiB")
parser.add_argument("--load-8bit", action="store_true")
parser.add_argument("--limit-model-concurrency", type=int, default=5)
parser.add_argument("--stream-interval", type=int, default=2)
parser.add_argument("--no-register", action="store_true")
args = parser.parse_args()
logger.info(f"args: {args}")
worker = ModelWorker(args.controller_address,
args.worker_address,
worker_id,
args.no_register,
args.model_path,
args.model_name,
args.model_base,
args.device,
args.num_gpus,
args.max_gpu_memory,
args.load_8bit)
uvicorn.run(app, host=args.host, port=args.port, log_level="info")Qwen
AutoDL部署调用Qwen,并编写测试代码、测试函数加载预训练的分词器和模型
from fastapi import FastAPI, Request
from transformers import AutoTokenizer, AutoModelForCausalLM, GenerationConfig
import uvicorn
import json
import datetime
import torch
# 设置设备参数
DEVICE = "cuda" # 使用CUDA
DEVICE_ID = "0" # CUDA设备ID,如果未设置则为空
CUDA_DEVICE = f"{DEVICE}:{DEVICE_ID}" if DEVICE_ID else DEVICE # 组合CUDA设备信息
# 清理GPU内存函数
def torch_gc():
if torch.cuda.is_available(): # 检查是否可用CUDA
with torch.cuda.device(CUDA_DEVICE): # 指定CUDA设备
torch.cuda.empty_cache() # 清空CUDA缓存
torch.cuda.ipc_collect() # 收集CUDA内存碎片
# 创建FastAPI应用
app = FastAPI()
# 处理POST请求的端点
@app.post("/")
async def create_item(request: Request):
global model, tokenizer # 声明全局变量以便在函数内部使用模型和分词器
json_post_raw = await request.json() # 获取POST请求的JSON数据
json_post = json.dumps(json_post_raw) # 将JSON数据转换为字符串
json_post_list = json.loads(json_post) # 将字符串转换为Python对象
prompt = json_post_list.get('prompt') # 获取请求中的提示
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt}
]
# 调用模型进行对话生成
input_ids = tokenizer.apply_chat_template(messages,tokenize=False,add_generation_prompt=True)
model_inputs = tokenizer([input_ids], return_tensors="pt").to('cuda')
generated_ids = model.generate(model_inputs.input_ids,max_new_tokens=512)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
now = datetime.datetime.now() # 获取当前时间
time = now.strftime("%Y-%m-%d %H:%M:%S") # 格式化时间为字符串
# 构建响应JSON
answer = {
"response": response,
"status": 200,
"time": time
}
# 构建日志信息
log = "[" + time + "] " + '", prompt:"' + prompt + '", response:"' + repr(response) + '"'
print(log) # 打印日志
torch_gc() # 执行GPU内存清理
return answer # 返回响应
# 主函数入口
if __name__ == '__main__':
# 加载预训练的分词器和模型
model_name_or_path = '/root/autodl-tmp/qwen/Qwen1.5-1.8B-Chat'
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, use_fast=False)
model = AutoModelForCausalLM.from_pretrained(model_name_or_path, device_map="auto", torch_dtype=torch.bfloat16)
# 启动FastAPI应用
# 用6006端口可以将autodl的端口映射到本地,从而在本地使用api
uvicorn.run(app, host='0.0.0.0', port=6006, workers=1) # 在指定端口和主机上启动应用
LLaMA Factory 是一个用于微调和部署 LLaMA (Large Language Model Applications) 模型的框架。它旨在简化大语言模型的使用和管理,提供了强大的工具来支持从模型训练、微调到部署的整个流程。在LLaMA下基于Qwen进行微调。
llama factory微调Qwen时,要求的数据集格式如下:
[
{
"instruction": "用户指令(必填)",
"input": "用户输入(选填)",
"output": "模型回答(必填)",
"system": "系统提示词(选填)",
"history": [
["第一轮指令(选填)", "第一轮回答(选填)"],
["第二轮指令(选填)", "第二轮回答(选填)"]
]
}
]
制作数据集格式如下,样本如下:
[
{
"instruction": "If you are a doctor, please answer the medical questions based on the patient's description.",
"input": "Doctor, I have been experiencing sudden and frequent panic attacks. I don't know what to do.",
"output": "Well, based on what you're telling me, it sounds like you may be suffering from panic disorder. The best course of action is to start with psychotherapy and mental health counseling. Additionally, we should conduct an electrocardiogram to make sure that there are no physical issues causing your panic attacks. We will also need to perform a depression screen and a toxicology screen to rule out any other underlying causes. Finally, I would recommend a comprehensive psychological and psychiatric evaluation and therapy to help manage your symptoms."
},
{
"instruction": "If you are a doctor, please answer the medical questions based on the patient's description.",
"input": "Doctor, I have been experiencing a hoarse voice for a few weeks now and it's not getting any better despite taking medication. What could be the problem?",
"output": "It's possible that you have a vocal cord polyp. To confirm this, we need to conduct tracheoscopy and laryngoscopy with a biopsy. We may also need to conduct an occupational therapy assessment such as speech therapy, other diagnostic procedures like an interview or consultation, physical therapy exercises, as well as diagnostic procedures on your nose, mouth, and pharynx to rule out any other underlying conditions. Additionally, we may need to evaluate your eyes and ears for any related conditions, such as ophthalmologic and otologic diagnosis and treatment."
},
{
"instruction": "If you are a doctor, please answer the medical questions based on the patient's description.",
"input": "Hi, Doctor. I think I might have Turner syndrome. ",
"output": "Okay, in that case, you will need to undergo a complete physical skin exam, an ultrasonography, and some other diagnostic procedures such as an interview, evaluation, and consultation. Additionally, we'll need to perform an echocardiography, examine your breast, and check your eyes and ears for any issues. We'll also do a depression screening to assess your mental health."
},
{
"instruction": "If you are a doctor, please answer the medical questions based on the patient's description.",
"input": "Doctor, I've been experiencing a condition called cryptorchidism. My testicles have not descended properly into the scrotum. What medical tests do I need to take?",
"output": "You will need to undergo a complete physical skin exam to see the extent of the undescended testicles. Then, we need to conduct Ultrasonography (Ultrasound) to find out the exact location of the testicles. After that, a pelvis exam and rectal examination will be done to determine if the testicles have descended into the pelvic region. If not, then other OR therapeutic procedures related to male genital or nervous system procedures may be required. We will also do an occupational therapy assessment to assess your speech therapy."
},
...
]
参考:山大软院创新实训之大模型篇(二)——Llama Factory微调Qwen实践-CSDN博客
最后效果:所微调过的模型对于医疗问答特定任务,效果比原Qwen效果好。
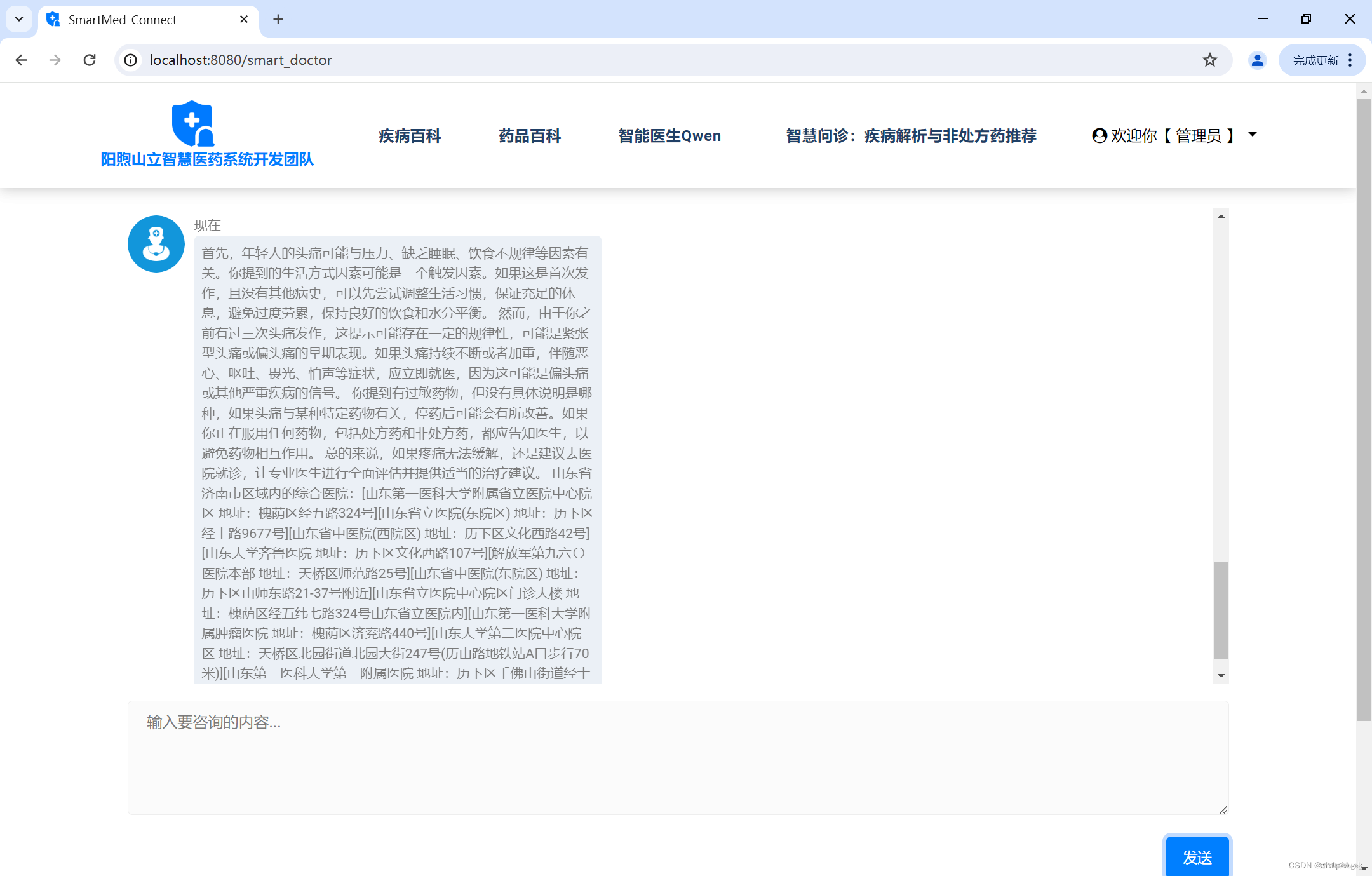
3.定位服务增强服务质量
使用Unirest库发送POST请求。与GET请求类似,返回结果也被解析为JSONObject。此后查找POI,通过调用高德地图API,根据用户提供的地理信息(区域或IP地址)查找附近的医院,并返回医院的名字和地址列表。代码结构清晰,通过HTTP请求获取数据,并利用FastJSON库解析JSON响应。
效果如下:















 363
363

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









