







《Redis设计与实现》读书笔记
在Redis中的五种键值对里面,没有一个是单独使用基本的数据结构实现的,而是基于这个数据结构创建了一个对象系统,这个系统包含了:String字符串对象,List列表对象,哈希对象,集合对象,有序集合对象。(也是就广义的Redis五种基本数据结构)
Redis在执行命令之前,根据对象的类型来判断一个对象是否可以执行给定的命令。使用对象的另外一个好处是,我们可以针对不同的使用场景,为对象设置多种不同的数据结构实现,从而优化对象在不同环境下的使用效率。
redis是使用c语言来写的,key-value型NoSQL数据库。
Key命名规范,没有什么限制,叫什么都可以,但是有建议:Key不要太长,不要超过2014字节,消耗内存,而且会降低查找的效率。在一个项目中,最好使用统一命名规范。区分大小写。
对象的类型与编码
Redis使用对象来表示数据库中的键和值,每次当我们在Redis的数据库中新创建一个键值对时,我们至少会创建两个对象,键都是string类型的,而value是五种类型之一。
value由结构redisObject表示:
typedef struct redisObject{
unsigned type:4;//类型
unsigned encoding:4;//编码
void *ptr;//指向底层实现数据结构的指针。
...
}robj;-
type:记录对象的类型,值是五个常量中的一个(常说的五种类型),对于键值对来说,键总是字符串,值就是五个中的一个,所以我们只用关心值的类型。
-
ptr:指针指向对象的底层实现数据结构,具体的数据结构由encoding决定
-
encoding:对象所使用的编码,用什么数据结构作为底层实现,也是一个常量,每种类型的对象都至少只有了两种不同的编码:
根据值的不同情况(比如说,小,大,多,少等等情况下)底层的实现数据结构是不同的。
一,字符串 string
对象的编码有三种方式:int,raw,embstr。
1.如果一个字符串对象保存的是整数值,那么可以使用int类型,
2.如果是个字符串,并且长度>32字节,那么就使用SDS来保存(raw),
3.如果字符串<32字节,那么使用embstr优化编码方式,它与第二种情况的不同是:第二种情况会创建两个对象,一个是redisObject(就是上面那个代码),还有一个是SDS(redis封装的字符串),他们两个是分开创建的,用一个指针相连,但是第二种它就节省了,一次性把两个对象的空间都分配好,然后把两个对象放在一起。
利用的是缓存行的概念,一个缓存行64byte,如果数据比较小,可以把redisObject和数据data放在一起。

编码之间的转换:保存一个long double类型的浮点数到redis中,redis是先把它保存为字符串的,在需要使用的时候,会转换为long double类型进行使用(比如基本运算 + - ),然后又保存为字符串。
而且embstr是只读的,如果要修改,redis会把embstr转换为raw,修改完毕,直接保存为raw。
使用: 1.赋值 set key value
2.检验键值是否存在 exists key (返回false或者true)
3.删除键 del key
4.节省网络耗时开销,批量写,读,mget key1 key2 key3 返回一个列表。
5. incr key 自增/自减;
6. append key value 如果key是 字符串,则将value拼接到key后面

应用场景:通常用于保存单个字符串 or json字符串数据。
二进制安全, 所以可以把一个图片作为字符串存储。
计数器(常规计数,粉丝数)使用自增来 投票等等。
三,哈希 hash
编码方式:ziplist,hashtable(字典)
ziplist编码的哈希对象使用压缩列表作为底层实现,当有新的键值对要加入到哈希对象时,程序先将保存了键的压缩列表节点推入到压缩列表表尾,然后再将保存了值的压缩列表节点推入到压缩列表表尾。所:同一个键值对的两个点,总是挨在一起的,先入的哈希对象是在表头的。


编码转换:哈希对象保存的所有键值对的键和值长度都要<64字节,哈希对象保存的键值对数量<512个,不能满足这两个都使用hashtable。
如果超过了这个条件按,ziplist就会转变成为hashtable。
使用:hset name field value hmset也可以多个value。hget
应用场景: 常用来存储一个对象,最接近关系型数据库,使用String序列化增加了编码解码的时间,吧对象转换为hashMap更快。
四,集合 set
编码方式:intset或者hashtable
编码转换:集合对象保存的都是整数,保存的元素数量不超过512个,那么就使用intset来存放,破除了就使用hashtable来存放。

应用场景:对两个集合间的数据计算进行交集,并集,差集运算。
对不同兴趣圈的交集,找到共同关注,还有共同好友。利用唯一性,统计访问完整的所有独立ip,存储当天的活跃用户列表。
五,有序集合 sortSet
编码方式:ziplist或者skiplist,使用跳跃表来实现有序性,而且跳跃表的对象是唯一的,也能实现集合的唯一性。压缩列表实现,使用两个节点来保存一个对象(成员-分值),压缩列表的集合元素也按分值从小到大排序。
跳跃表编码的有序集合使用zset结构作为底层实现,一个zset同时包含一个字典和一个跳跃表。
typedef struct zset{
zskiplist *zsl;
dict *dict;
}zset;每个跳跃表节点都保存了一个集合元素,dict为有序集合创建了以恶搞从成员到分值的映射,键保存元素的成员,值保存分值,通过字典,可以O(1)方式通过成员查找分值,两个结构会共享里面的数据。不会浪费额外空间。

编码转换:当有序集合保存的元素数量<128个,成员长度<64字节,那么就使用ziplist编码,否者使用skiplist编码。
应用场景:积分排行榜。

六,Redis数据库整体认识
1.redis有16个数据库,数据库的真实样子:

里面的结构dict 就是字典
dict:进行索引操作
expires: 过期时间
blocking_keys:阻塞,与client进行交互
字典的结构:

dictht就是一个hashtable
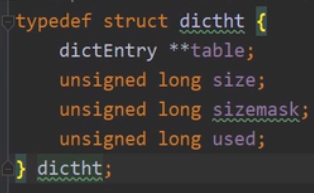
table指向hash数组
数组中的存储节点:

包含了key -value-next 三个重要信息
key永远都是字符串类型
而val,由redisObject进行封装,它具有五种数据类型string ,list,hash,set ,zset.


refcount: c语言自己实现内存管理,使用引用计数法。LRU内存淘汰的时候使用。















 423
423











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









