






hadoop_hdfs_maven安装
复制maven文件夹的路径》来到桌面选择此电脑右键》属性》高级》环境变量》新建》
变量名:MAVEN_HOME
变量值:粘贴maven文件夹路劲确定》双击path在里面添加》
%MAVEN_HOME%/bin依次点击确定》来到maven/conf文件夹下双击settingzai将里面的文件替换掉》
<?xml version="1.0" encoding="UTF-8"?>
<settings xmlns="http://maven.apache.org/SETTINGS/1.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/SETTINGS/1.0.0 http://maven.apache.org/xsd/settings-1.0.0.xsd">
<!-- 我本地的仓库地址 -->
<localRepository>D:\Hadoopruanjian\mavenwenjian</localRepository>
<pluginGroups></pluginGroups>
<proxies></proxies>
<servers></servers>
<mirrors>
<!-- 阿里云中央仓库镜像地址 -->
<mirror>
<id>aliyunmaven</id>
<mirrorOf>*</mirrorOf>
<name>阿里云公共仓库</name>
<url>https://maven.aliyun.com/repository/public</url>
</mirror>
<mirror>
<id>aliyunmaven</id>
<mirrorOf>*</mirrorOf>
<name>阿里云谷歌仓库</name>
<url>https://maven.aliyun.com/repository/google</url>
</mirror>
<mirror>
<id>aliyunmaven</id>
<mirrorOf>*</mirrorOf>
<name>阿里云阿帕奇仓库</name>
<url>https://maven.aliyun.com/repository/apache-snapshots</url>
</mirror>
<mirror>
<id>aliyunmaven</id>
<mirrorOf>*</mirrorOf>
<name>阿里云spring仓库</name>
<url>https://maven.aliyun.com/repository/spring</url>
</mirror>
<mirror>
<id>aliyunmaven</id>
<mirrorOf>*</mirrorOf>
<name>阿里云spring插件仓库</name>
<url>https://maven.aliyun.com/repository/spring-plugin</url>
</mirror>
<!-- 腾讯云中央仓库 -->
<mirror>
<id>tencent</id>
<name>tencent maven mirror</name>
<url>https://mirrors.tencent.com/nexus/repository/maven-public/</url>
<mirrorOf>*</mirrorOf>
</mirror>
</mirrors>
<profiles></profiles>
</settings>》打开idea》这里可以下载中文插件》新建maven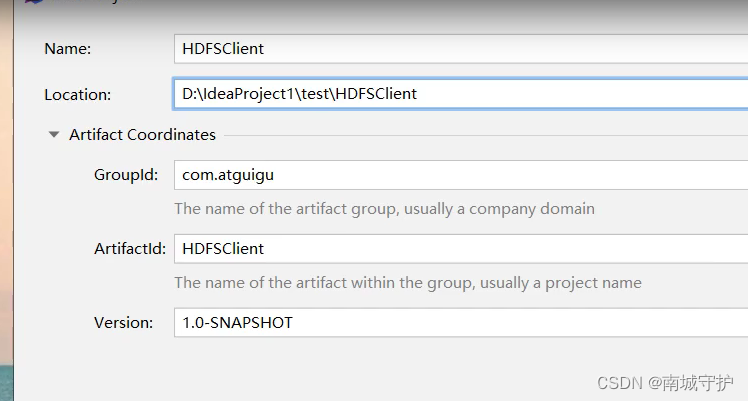 确定》文件》设置》maven》
确定》文件》设置》maven》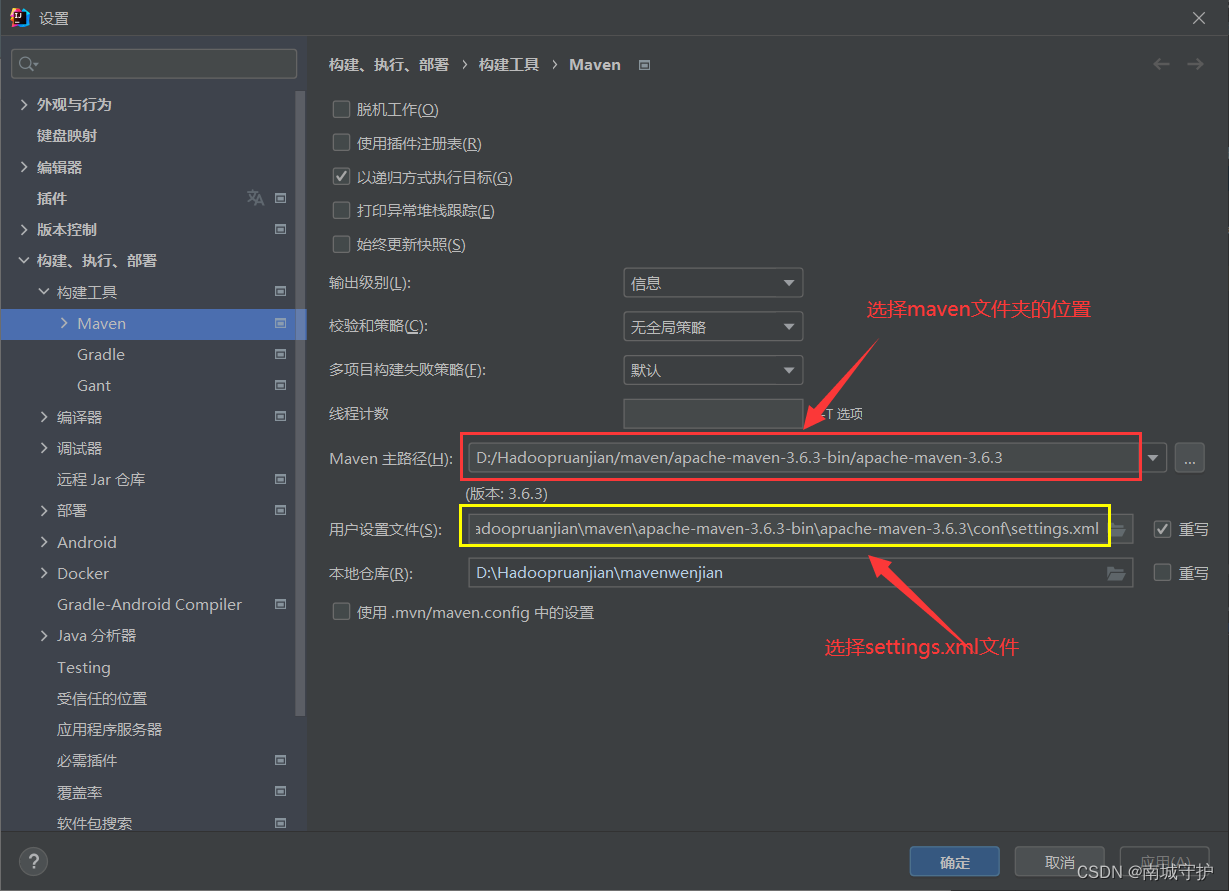
在resources下建一个FXML文件和在Java下建一个包在包下建一个java类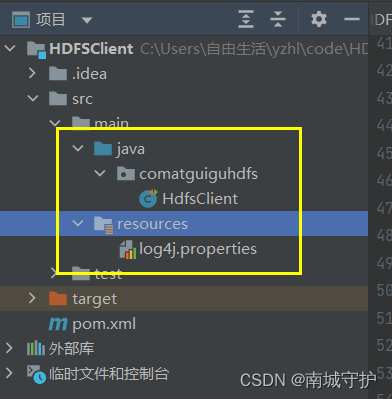
在java类里添加
package comatguiguhdfs;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
public class HdfsClient {
private FileSystem fs;
@Before
//因为一般前面和最后的步骤一样,可以封装起来
public void init() throws URISyntaxException, IOException, InterruptedException {
//连接的集群地址
URI uri = new URI("hdfs://hadoop102:8020");
//创建一个配置文件
Configuration configuration = new Configuration();
//不是对应的用户会报权限不够的错误
String user = "nancheng";
//1.获取到客户端对象
fs = FileSystem.get(uri, configuration, user);
}
@After
public void close() throws IOException {
//3.关闭资源
fs.close();
}
/*
创建目录
*/
@Test
public void testmkdir() throws URISyntaxException, IOException, InterruptedException {
//2.创建一个文件夹
fs.mkdirs(new Path("/xiyou/huaguoshan1"));
}
/*
上传
*/
@Test
public void testPut() throws IOException {
//参数解读:参数1:表示是否删除原数据;参数2:是否允许覆盖;参数3:原数据路径;参数4:目的地路径
fs.copyFromLocalFile(true, false, new Path("D:\\code\\Hadoop\\sunwukong.txt"), new Path("hdfs://hadoop102/xiyou/huaguoshan"));
}
}















 2433
2433











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









