








大侠幸会,在下全网同名「算法金」 0 基础转 AI 上岸,多个算法赛 Top 「日更万日,让更多人享受智能乐趣」
今日 215/10000
为模型找到最好的超参数是机器学习实践中最困难的部分之一
1. 超参数调优的基本概念
机器学习模型中的参数通常分为两类:模型参数和超参数。模型参数是模型通过训练数据自动学习得来的,而超参数则是在训练过程开始前需要人为设置的参数。理解这两者的区别是进行有效模型调优的基础。
1.1 超参数与模型参数的区别
模型参数是在模型训练过程中通过优化算法学习得来的。例如,线性回归中的权重系数、神经网络中的权重和偏置都是模型参数。这些参数直接影响模型的预测能力,是模型从数据中提取到的信息。
超参数则是由用户在训练模型之前手动设定的参数,不能通过数据自动学习得来。例如,决策树的最大深度、支持向量机的核函数类型、神经网络的学习率和隐藏层数量等都是超参数。超参数的选择直接影响模型的性能和训练效率,因此需要进行仔细调优。
1.2 为什么超参数调优很重要
超参数调优的目的是找到最优的超参数组合,使模型在验证集上的表现最佳。合适的超参数能显著提升模型的性能,而不合适的超参数则可能导致模型的欠拟合或过拟合。
例如,在神经网络中,过高的学习率可能导致模型参数在训练过程中剧烈波动,无法收敛到一个稳定的值;过低的学习率则可能使模型收敛速度过慢,训练时间过长。同样,决策树中过大的树深度可能导致模型过拟合,过小的树深度则可能导致欠拟合。
超参数调优需要结合具体的问题、数据集和模型类型进行选择,通常包括以下几个步骤:
- 定义要调优的超参数及其可能的取值范围
- 选择调优策略(如网格搜索、随机搜索等)
- 使用交叉验证或验证集评估模型性能
- 根据评估结果选择最优的超参数组合
通过这些步骤,可以有效地提升模型的性能,使其在新数据上的预测更准确。
防失联,进免费知识星球,直达算法金 AI 实验室 https://t.zsxq.com/ckSu3
2. 网格搜索 (Grid Search)
2.1 基本原理
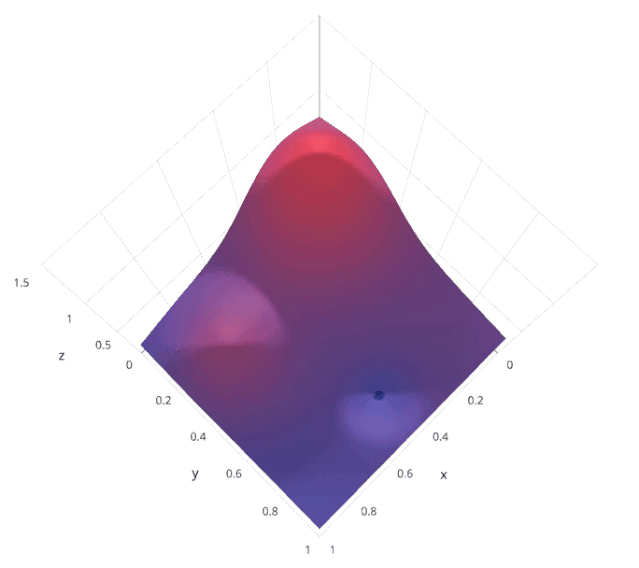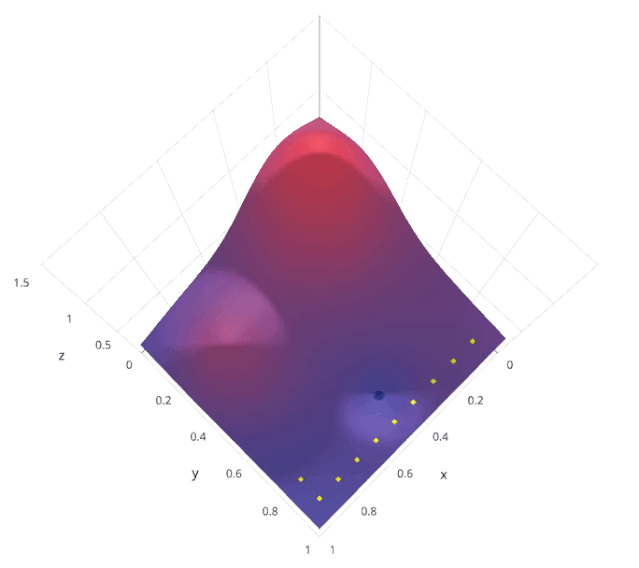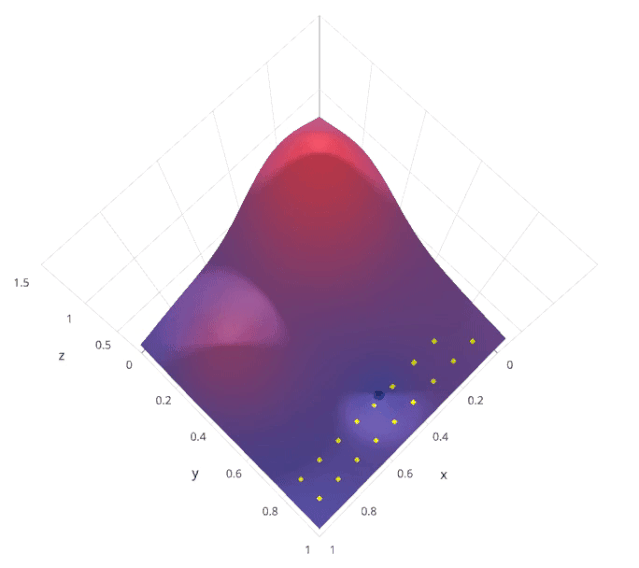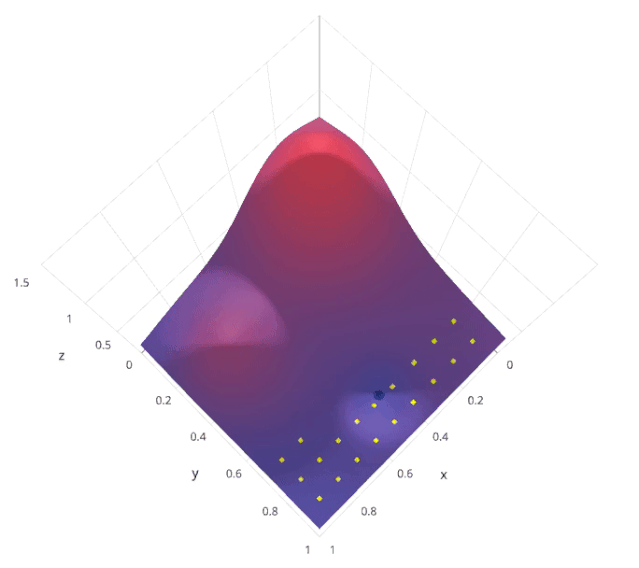
网格搜索是一种系统的超参数调优方法,通过穷举搜索预定义的超参数空间,找到最佳的超参数组合。具体来说,网格搜索会列出所有可能的超参数组合,然后对每个组合进行模型训练和评估,最后选择在验证集上表现最好的组合。
假设我们有两个超参数 𝛼 和 𝛽,每个超参数都有三个可能的取值。网格搜索会尝试所有可能的 (𝛼,𝛽) 组合
通过这种方法,可以保证找到在给定超参数空间内的最优组合。
by Lavanya Gupta
2.2 优缺点分析
优点:
- 简单易理解:网格搜索方法直观且易于实现,不需要复杂的数学背景知识。
- 全面性:通过穷举搜索,可以确保找到预定义超参数空间内的全局最优解。
缺点:
- 计算成本高:随着超参数数量和取值范围的增加,组合数目会呈指数增长,导致计算成本急剧增加。
- 效率低:在很多情况下,部分超参数对模型性能影响较小,浪费了计算资源。
2.3 实践示例
以下是一个使用 Python 和 scikit-learn 库进行网格搜索的示例代码:
from sklearn.model_selection import GridSearchCV
from sklearn.ensemble import RandomForestClassifier
# 定义模型和参数空间
model = RandomForestClassifier()
param_grid = {
'n_estimators': [10, 50, 100],
'max_depth': [None, 10, 20],
'min_samples_split': [2, 5, 10]
}
# 进行网格搜索
grid_search = GridSearchCV(estimator=model, param_grid=param_grid, cv=5, scoring='accuracy')
grid_search.fit(X_train, y_train)
# 输出最佳参数和得分
print("Best parameters found: ", grid_search.best_params_)
print("Best cross-validation score: ", grid_search.best_score_)
在这个示例中,我们对随机森林模型的三个超参数进行了网格搜索,找到了在验证集上表现最好的超参数组合。通过这种方法,我们可以显著提升模型的性能。
点击 ↑ 领取
3. 随机搜索 (Random Search)
3.1 基本原理
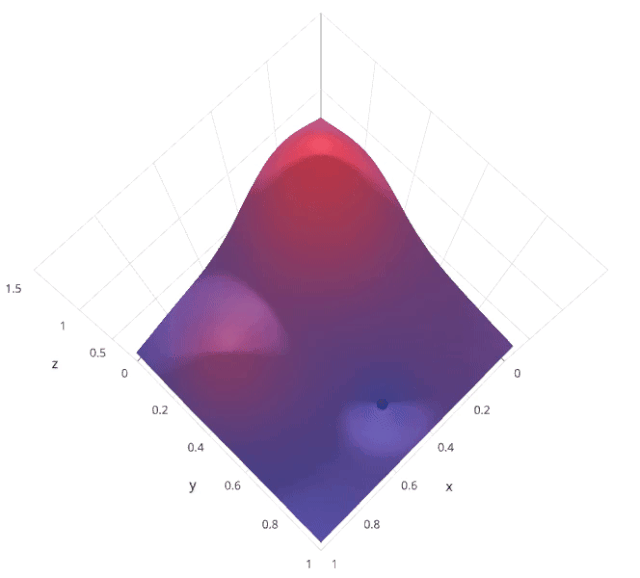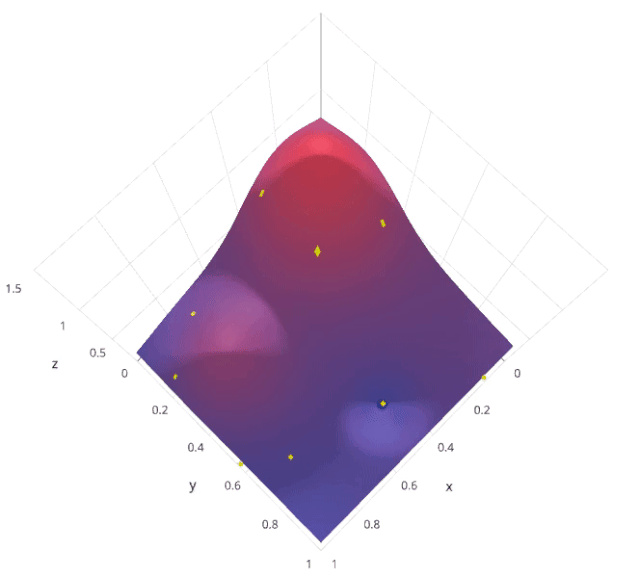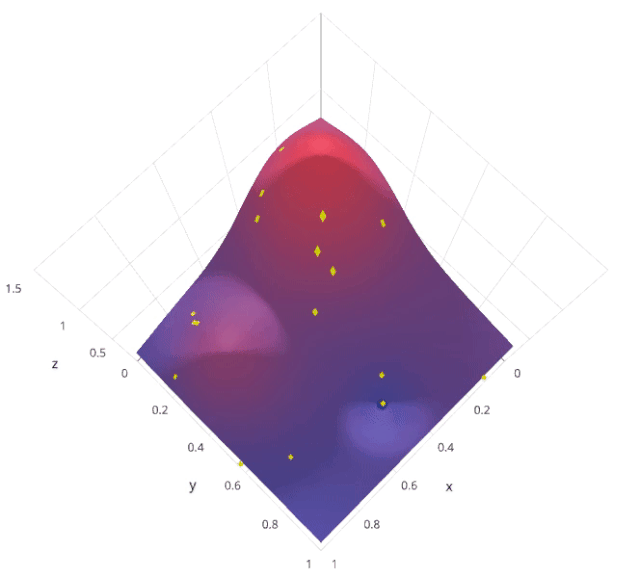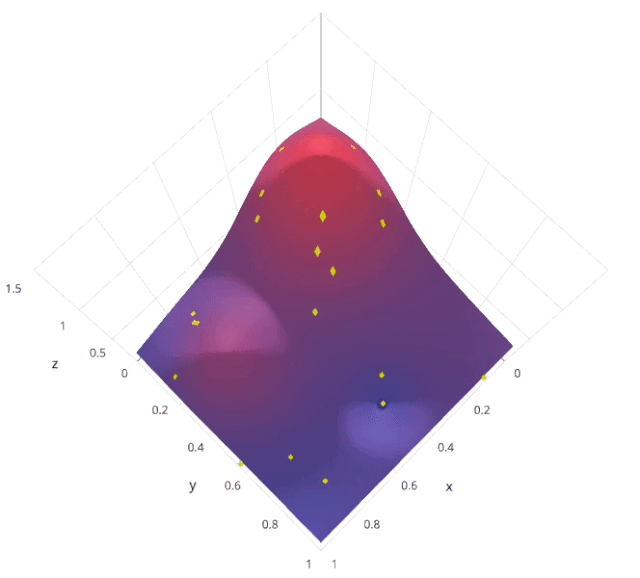
随机搜索是一种超参数调优方法,通过在预定义的超参数空间内随机采样多个超参数组合,对每个组合进行模型训练和评估,找到表现最佳的超参数组合。与网格搜索不同,随机搜索不是穷举所有可能的组合,而是随机选择一部分组合进行评估。
假设我们有两个超参数 𝛼 和 𝛽,每个超参数都有多个可能的取值。随机搜索会在这些取值中随机采样若干个 (𝛼,𝛽) 组合,评估每个组合的模型性能,然后选择最优的组合。
3.2 优缺点分析
优点:
- 计算成本低:随机搜索只评估部分超参数组合,计算成本比网格搜索低得多。
- 效率高:在高维超参数空间中,随机搜索通常能更快找到接近最优的超参数组合。
缺点:
- 不确定性:由于随机搜索的随机性,不同次运行可能会得到不同的结果。
- 覆盖不全面:随机搜索可能会遗漏一些表现较好的超参数组合。
3.3 实践示例
以下是一个使用 Python 和 scikit-learn 库进行随机搜索的示例代码:
from sklearn.model_selection import RandomizedSearchCV
from sklearn.ensemble import RandomForestClassifier
from scipy.stats import randint
# 定义模型和参数空间
model = RandomForestClassifier()
param_dist = {
'n_estimators': randint(10, 100),
'max_depth': [None, 10, 20],
'min_samples_split': randint(2, 11)
}
# 进行随机搜索
random_search = RandomizedSearchCV(estimator=model, param_distributions=param_dist, n_iter=50, cv=5, scoring='accuracy')
random_search.fit(X_train, y_train)
# 输出最佳参数和得分
print("Best parameters found: ", random_search.best_params_)
print("Best cross-validation score: ", random_search.best_score_)
在这个示例中,我们对随机森林模型的三个超参数进行了随机搜索,通过随机采样的方式找到在验证集上表现最好的超参数组合。随机搜索可以在计算资源有限的情况下,快速找到接近最优的超参数组合。
防失联,进免费知识星球,直达算法金 AI 实验室 https://t.zsxq.com/ckSu3
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









