







Python是一种非常适合用于编写网络爬虫的编程语言。以下是一些Python爬虫的基本步骤:
1、导入所需的库:通常需要使用requests、BeautifulSoup、re等库来进行网络请求、解析HTML页面和正则表达式匹配等操作。
2、发送网络请求:使用requests库发送HTTP请求,获取目标网页的HTML源代码。
3、解析HTML页面:使用BeautifulSoup库解析HTML页面,提取出需要的数据。
4、数据处理:对提取出的数据进行清洗、处理和存储。
5、循环爬取:使用循环结构,对多个页面进行爬取。
6、防止反爬:在爬取过程中,需要注意网站的反爬机制,可以使用代理IP、随机User-Agent等方式来规避反爬。
7、异常处理:在爬取过程中,可能会出现网络连接异常、页面解析异常等情况,需要进行异常处理,保证程序的稳定性。
需要注意的是,在进行网络爬虫时,需要遵守相关法律法规和网站的使用协议,不得进行恶意爬取和侵犯他人隐私等行为。
编写一个通用的Python爬虫模板可以帮助开发者更快速地开始一个新的网络爬虫项目。以下是一个简单的网页抓取模板示例:
import requests
from bs4 import BeautifulSoup
# Step 1: 访问网页并获取响应内容
def get_html_content(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'}
try:
response = requests.get(url, headers=headers)
response.raise_for_status()
response.encoding = response.apparent_encoding
html_content = response.text
return html_content
except Exception as e:
print(f"网络请求异常:{e}")
return None
# Step 2: 解析网页并提取目标数据
def parse_html(html_content):
soup = BeautifulSoup(html_content, 'html.parser')
# TODO:根据需求编写解析代码,并将结果保存到合适的数据结构中
data_list = []
return data_list
# Step 3: 存储数据到本地或其他持久化存储服务器中
def store_data(result_list):
# TODO:编写存储代码,将数据结果保存到本地或其他服务器中
pass
# Step 4: 控制流程,调用上述函数完成数据抓取任务
if __name__ == '__main__':
target_url = "http://www.example.com"
html_content = get_html_content(target_url)
if html_content:
result_list = parse_html(html_content)
store_data(result_list)
else:
print("网页访问失败")
这个模板中主要完成了以下内容:
访问指定的URL并获取响应内容;
解析HTML页面并提取目标数据;
将解析结果存储到本地或其他远程持久化存储服务器中。
开发者可以在模板基础上进行编辑和修改以适应更加具体的项目需求。例如,修改headers变量中的User-Agent字符串以模拟浏览器访问;使用requests等第三方库来发送GET、POST等HTTP请求;使用多线程或异步IO技术提高爬虫的并发处理能力。
关于Python技术储备
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
对于0基础小白入门:
如果你是零基础小白,想快速入门Python是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以找到适合自己的学习方案
包括:Python激活码+安装包、Python web开发,Python爬虫,Python数据分析,Python自动化测试学习等教程。带你从零基础系统性的学好Python!
零基础Python学习资源介绍
- ① Python所有方向的学习路线图,清楚各个方向要学什么东西
- ② 600多节Python课程视频,涵盖必备基础、爬虫和数据分析
- ③ 100多个Python实战案例,含50个超大型项目详解,学习不再是只会理论
- ④ 20款主流手游迫解 爬虫手游逆行迫解教程包
- ⑤ 爬虫与反爬虫攻防教程包,含15个大型网站迫解
- ⑥ 爬虫APP逆向实战教程包,含45项绝密技术详解
- ⑦ 超300本Python电子好书,从入门到高阶应有尽有
- ⑧ 华为出品独家Python漫画教程,手机也能学习
- ⑨ 历年互联网企业Python面试真题,复习时非常方便
👉Python学习路线汇总👈
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。(全套教程文末领取哈)

👉Python必备开发工具👈

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉Python学习视频600合集👈
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。
👉实战案例👈
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉100道Python练习题👈
检查学习结果。

👉面试刷题👈
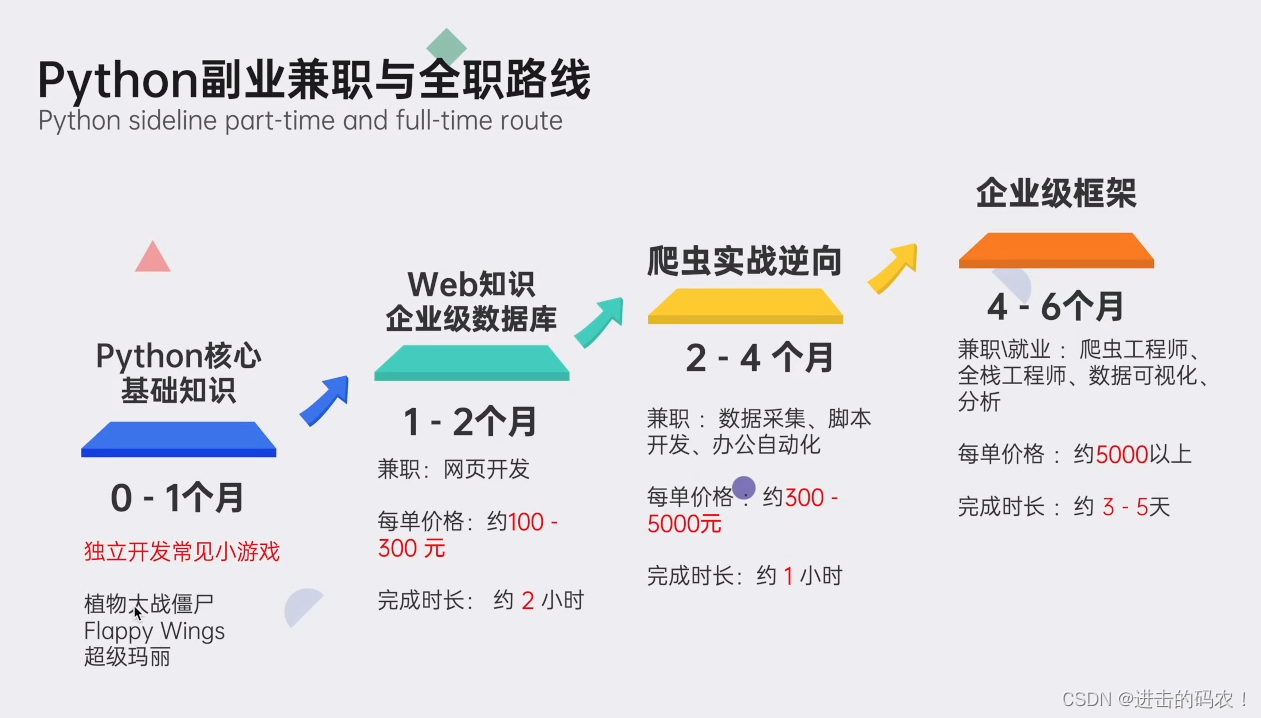
👉python副业兼职与全职路线👈
上述这份完整版的Python全套学习资料已经上传CSDN官方,如果需要可以微信扫描下方CSDN官方认证二维码 即可领取
👉[[CSDN大礼包:《python安装包&全套学习资料》免费分享]](安全链接,放心点击)
















 960
960











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









