







 该博客介绍了如何使用MATLAB的ReinforcementLearningToolbox进行强化学习,分别展示了Q-learning和SARSA算法在二维网格环境中的简单训练实现。通过创建环境、设置奖励和障碍,然后初始化并训练代理,最终展示训练结果和模拟过程。
该博客介绍了如何使用MATLAB的ReinforcementLearningToolbox进行强化学习,分别展示了Q-learning和SARSA算法在二维网格环境中的简单训练实现。通过创建环境、设置奖励和障碍,然后初始化并训练代理,最终展示训练结果和模拟过程。
MATLAB提供了Reinforcement Learning Toolbox可以方便地建立二维基础网格环境、设置起点、目标、障碍,以及各种agent模型
1.Q-learning的训练简单实现
%% 布置环境硬件
GW = createGridWorld(6,6);
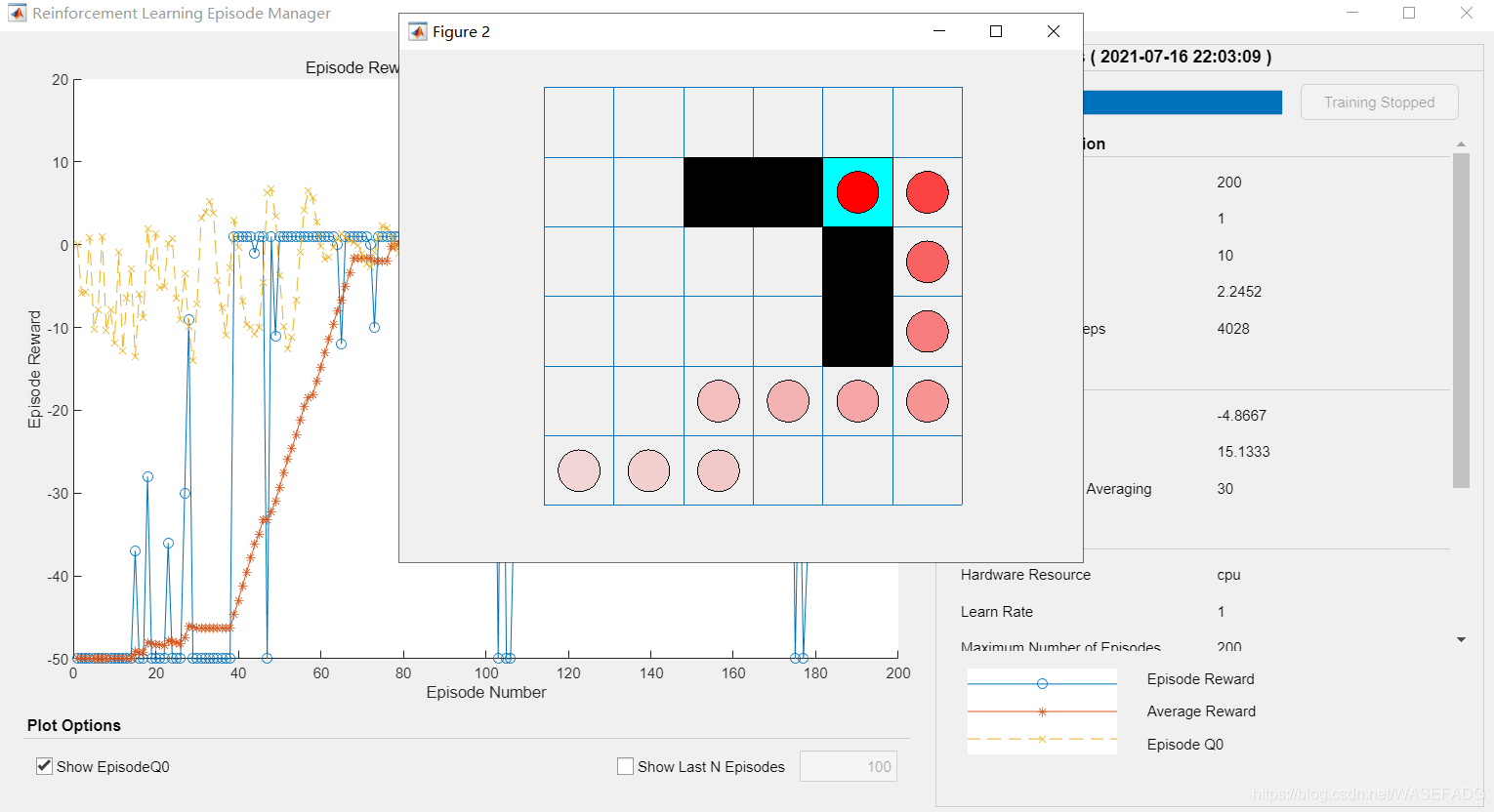
GW.CurrentState = '[6,1]';
GW.TerminalStates = '[2,5]';
GW.ObstacleStates = ["[2,3]";"[2,4]";"[3,5]";"[4,5]"];
%% 根据障碍设置可否行进
updateStateTranstionForObstacles(GW)
%% 设置reward
nS = numel(GW.States);
nA = numel(GW.Actions);
GW.R = -1*ones(nS,nS,nA);
GW.R(:,state2idx(GW,GW.TerminalStates),:) = 10;
%% 生成环境及初始位置
env = rlMDPEnv(GW);
plot(env)
env.ResetFcn = @() 6;
%% Q-learning训练参数初始化
qTable = rlTable(getObservationInfo(env),getActionInfo(env));
tableRep = rlRepresentation(qTable);
tableRep.Options.LearnRate = 1;
agentOpts = rlQAgentOptions;
agentOpts.EpsilonGreedyExploration.Epsilon = .04;
qAgent = rlQAgent(tableRep,agentOpts);
trainOpts = rlTrainingOptions;
trainOpts.MaxStepsPerEpisode = 50;
trainOpts.MaxEpisodes= 200;
trainOpts.StopTrainingCriteria = "AverageReward";
trainOpts.StopTrainingValue = 11;
trainOpts.ScoreAveragingWindowLength = 30;
%% 训练
rng(0)
trainingStats = train(qAgent,env,trainOpts);
%% 结果展示
plot(env)
env.Model.Viewer.ShowTrace = true;
env.Model.Viewer.clearTrace;
sim(qAgent,env)
2.SARSA的训练简单实现
%% 布置环境硬件
GW = createGridWorld(6,6);
GW.CurrentState = '[6,1]';
GW.TerminalStates = '[2,5]';
GW.ObstacleStates = ["[2,3]";"[2,4]";"[3,5]";"[4,5]"];
%% 设置可否行进
updateStateTranstionForObstacles(GW)
%% 设置reward
nS = numel(GW.States);
nA = numel(GW.Actions);
GW.R = -1*ones(nS,nS,nA);
GW.R(:,state2idx(GW,GW.TerminalStates),:) = 10;
%% 生成环境及初始位置
env = rlMDPEnv(GW);
plot(env)
env.ResetFcn = @() 6;
%% %% SARSA参数初始化
rng(0)
qTable = rlTable(getObservationInfo(env),getActionInfo(env));
tableRep = rlRepresentation(qTable);
tableRep.Options.LearnRate = 1;
agentOpts = rlSARSAAgentOptions;
agentOpts.EpsilonGreedyExploration.Epsilon = 0.04;
sarsaAgent = rlSARSAAgent(tableRep,agentOpts);
trainOpts = rlTrainingOptions;
trainOpts.MaxStepsPerEpisode = 50;
trainOpts.MaxEpisodes= 200;
trainOpts.StopTrainingCriteria = "AverageReward";
trainOpts.StopTrainingValue = 11;
trainOpts.ScoreAveragingWindowLength = 30;
%% 训练
trainingStats = train(sarsaAgent,env,trainOpts);
%% 结果展示
plot(env)
env.Model.Viewer.ShowTrace = true;
env.Model.Viewer.clearTrace;
sim(sarsaAgent,env)



















 3006
3006

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











