







前言
自学python,首次接触到爬虫的东西,整个过程全部自己查找资料,熟悉每个模块功能,最终完成了爬取某排名前250电影名。
后面直接展示的是两种方法的完整代码,就懒得分开写了,有坑的地方也有标注,有问题或者学习交流可以找博主公众号微信都行。
代码肯定不是最优,仅供学习使用,不做其他任何非法用途!
一、用到模块介绍
1、requests
Requests模块是一个用于网络请求的模块,主要用来模拟浏览器发请求。
2、re
Re模块主要是用来调用正则表达式用的。
3、beautifsoup4
Beautiful Soup (简称bs4)是一个可以从HTML或XML文件中提取数据的Python库。提供一些简单的、python式的函数用来处理导航、搜索、修改分析树等功能。
4、xlwings
可以处理Excel文件的Python模块有很多,xlwings模块的功能是最齐全的。它不仅能读写和修改,而且能批量处理多个Excel文件。此外,xlwing模块还能与Exce VBA结合使用。
5、time
time模块包含用于获取当前时间 、操作时间和日期、从字符串中读取日期、将日期格式化为字符串函数。
6、random
Python标准库中的random函数,可以生成随机浮点数、整数、字符串,甚至帮助你随机选择列表序列中的一个元素,打乱一组数据等。
7、模块的安装调用
# 模块安装
pip install 模块名字
# 模块调用
import 模块名字
# 其中beautisoup4调用时用bs4二、爬取某排名前250电影名
1、用整正则表达式获取(方法一)
用正则表达式相对来说没有用标签来的舒服,所以一般建议用第二种方法;
# coding=utf8
# @time:2022/5/16 15:12
import random
import requests,re
# 1.通过正则表达式获取某排名前250的电影名字
url = 'https://movie.XXXX.com/top250'
ua = {'User-Agent':'Mozilla/5.0 (compatible; U; ABrowse 0.6; Syllable) AppleWebKit/420+ (KHTML, like Gecko)'}
r = requests.get(url,headers=ua)
# print(r.status_code)
# print(r.text)
pattern = re.compile(r'\<span class="title"\>.*?\<\/span\>')
print(len(pattern.findall(r.text)))效果展示:
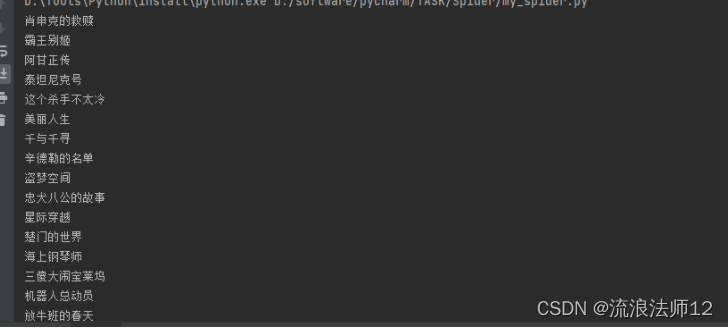
2、通过bs4获取某排名前250的电影名字,并且输入到excle表格中(方法二)
# 将获取的排名250的电影写入到excle表格中(爬取电影)
import requests,bs4,time
import xlwings as xw
# 这里有个坑,成功下载beatifulsoup4,但是导入时不能导入beautisoup4,只能写bs4;
app = xw.App(add_book=False,visible=True)
wb = app.books.open('爬取电影.xlsx')
sht = wb.sheets['sheet1']
span_list = []
for page in range(10):
url = f'https://movie.XXXX.com/top250?start={page*25}' # 加f表示字符串内支持大括号内的python表达式
ua = {'User-Agent':'Mozilla/5.0 (compatible; U; ABrowse 0.6; Syllable) AppleWebKit/420+ (KHTML, like Gecko)'}
r = requests.get(url,headers=ua)
soup = bs4.BeautifulSoup(r.text,'html.parser')
# print(soup)
spans = soup.select('div.hd>a>span:nth-child(1)')
temp_list = []
i = 0
for span in spans:
span_list.append(span.text)
time.sleep(random.randint(3,5))
sht.range('a2').options(transpose=True).value=span_list
wb.save()
wb.close()
app.quit()
效果展示:

更多安全分享,请关注【安全info】微信公众号!

















 557
557











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











