







下载地址:
https://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-3.2.0/hadoop-3.2.0.tar.gz
wget http://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-3.2.0/hadoop-3.2.0.tar.gz
yum install psmisc
解压tar包
[root@datanode5 soft]# chown -R root:root hadoop-3.2.0/
在Hadoop家目录下创建data文件夹
在data文件夹下创建tmp文件夹和dfs文件夹
在dfs文件夹下创建jn文件夹
hdfs-site.xml==========================
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/data/hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/data/hadoop/hdfs/data</value>
</property>
<property>
<name>dfs.nameservices</name>
<value>ns1</value>
</property>
<property>
<name>dfs.ha.namenodes.ns1</name>
<value>nn1,nn2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ns1.nn1</name>
<value>datanode4:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ns1.nn2</name>
<value>datanode5:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.ns1.nn1</name>
<value>datanode4:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.ns1.nn2</name>
<value>datanode5:50070</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://datanode4:8485;datanode5:8485;datanode6:8485/ns1</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/data1/soft/hadoop-3.2.0/data/dfs/jn</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.ns1</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>shell(/bin/true)</value>
</property>

<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
core-site.xml=====================================
<property>
<name>fs.defaultFS</name>
<value>hdfs://ns1</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/data1/soft/hadoop-3.2.0/data/tmp</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>datanode4:2181,datanode5:2181,datanode6:2181</value>
</property>
mapred-site.xml==========================================
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/data1/soft/hadoop-3.2.0</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/data1/soft/hadoop-3.2.0</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/data1/soft/hadoop-3.2.0</value>
</property>
yarn-site.xml==================================================
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>datanode6</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>106800</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>106496</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>106496</value>
</property>
<property><name>yarn.nodemanager.pmem-check-enabled</name><value>false</value> </property>
<property><name>yarn.nodemanager.vmem-check-enabled</name><value>false</value> </property>
works=========================================================
datanode4
datanode5
datanode6
hadoop-env.sh===================================================
export JAVA_HOME=/usr/local/java
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_JOURNALNODE_USER=root
export HDFS_ZKFC_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
将hadoop分发到其他机器上
[root@datanode4 bin]# scp -r hadoop-3.2.0 datanode5:/data1/soft/
[root@datanode4 bin]# scp -r hadoop-3.2.0 datanode6:/data1/soft/
[root@datanode4 bin]# ./hdfs --daemon start journalnode
[root@datanode5 bin]# ./hdfs --daemon start journalnode
[root@datanode6 bin]# ./hdfs --daemon start journalnode
[root@datanode4 bin]# ./hdfs namenode -format
[root@datanode4 bin]# ./hdfs --daemon start namenode
[root@datanode5 bin]# ./hdfs namenode -bootstrapStandby
[root@datanode5 bin]# ./hdfs --daemon start namenode
[root@datanode5 bin]# ./hdfs haadmin -getAllServiceState
[root@datanode4 bin]# ./hdfs --daemon stop namenode
[root@datanode5 bin]# ./hdfs --daemon stop namenode
[root@datanode4 bin]# ./hdfs --daemon stop journalnode
[root@datanode5 bin]# ./hdfs --daemon stop journalnode
[root@datanode6 bin]# ./hdfs --daemon stop journalnode
[root@datanode4 bin]# ./hdfs zkfc -formatZK
[root@datanode4 sbin]# ./start-dfs.sh
[root@datanode6 sbin]# ./start-yarn.sh
================================================
节点4 namenode format
节点5 namenode 元数据同步
节点4 formateZK



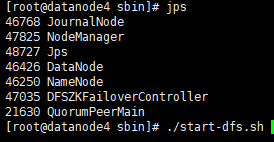
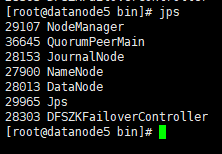
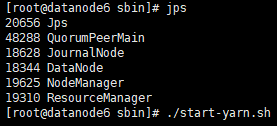

…/bin/hdfs --daemon start journalnode # 三台虚拟机都执行该命令
…/bin/hdfs namenode -format # 在其中一台namenode虚拟机执行即可
启动 master namenode sbin/hadoop-deamon.sh startnamenode
在master2上同步master namenode元数据 bin/hdfs namenode -bootstrapStandby
启动master2 namenode sbin/hadoop-deamon.sh startnamenode
此时进入 50070 web页面,两个namenode都是standby状态,这是可以先强制手动是其中一个节点变为active bin/hdfs haadmin –transitionToActive–forcemanual
手动故障转移已经完成,接下来配置自动故障转移
先把整个集群关闭,zookeeper不关,输入
[root@datanode4 bin]# ./hdfs zkfc -formatZK
格式化ZKFC
-> …/sbin/start-dfs.sh
在一台namenode启动hdfs
-> …/sbin/start-yarn.sh
在resourcemanager启动yarn
[root@datanode5 bin]# ./hdfs haadmin
Usage: haadmin [-ns ]
[-transitionToActive [–forceactive] ]
[-transitionToStandby ]
[-failover [–forcefence] [–forceactive] ]
[-getServiceState ]
[-getAllServiceState]
[-checkHealth ]
[-help ]
[root@datanode5 bin]# ./hdfs haadmin -getAllServiceState
datanode4:8020 active
datanode5:8020 standby
测试:
[root@datanode4 bin]# ./yarn jar /data1/soft/hadoop-3.2.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.0.jar wordcount /test/input /test/output

遇到的问题:
2019-04-25 10:04:24,273 INFO mapreduce.Job: Job job_1556108063572_0001 failed with state FAILED due to: Application application_1556108063572_0001 failed 2 times due to AM Container for appattempt_1556108063572_0001_000002 exited with exitCode: 1
Failing this attempt.Diagnostics: [2019-04-25 10:04:23.821]Exception from container-launch.
Container id: container_1556108063572_0001_02_000001
Exit code: 1
[2019-04-25 10:04:23.864]Container exited with a non-zero exit code 1. Error file: prelaunch.err.
Last 4096 bytes of prelaunch.err :
Last 4096 bytes of stderr :
Error: Could not find or load main class org.apache.hadoop.mapreduce.v2.app.MRAppMaster
Please check whether your etc/hadoop/mapred-site.xml contains the below configuration:
<property>
<name>yarn.app.mapreduce.am.env
<value>HADOOP_MAPRED_HOME=${full path of your hadoop distribution directory}</value>
</property>
<property>
<name>mapreduce.map.env
<value>HADOOP_MAPRED_HOME=${full path of your hadoop distribution directory}</value>
</property>
<property>
<name>mapreduce.reduce.env
<value>HADOOP_MAPRED_HOME=${full path of your hadoop distribution directory}</value>
</property>
解决方案:在mapred-site.xml中加入:
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/data1/soft/hadoop-3.2.0</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/data1/soft/hadoop-3.2.0</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/data1/soft/hadoop-3.2.0</value>
</property>
http://hadoop.apache.org/docs/r3.2.0/hadoop-project-dist/hadoop-hdfs/HDFSHighAvailabilityWithQJM.html















 307
307











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









