







 本文详细分析了Java爬虫库WebMagic的总体流程,从Spider类的Builder模式开始,逐步讲解了Pipeline、Scheduler、Downloader和PageProcessor四大组件的作用。通过源码解析,阐述了Request如何通过Scheduler进入线程池,Downloader如何下载网页并由PageProcessor解析内容,最后通过Pipeline进行存储。文章适合初学者理解WebMagic的工作原理,并预告了后续将深入探讨各个组件的细节。
本文详细分析了Java爬虫库WebMagic的总体流程,从Spider类的Builder模式开始,逐步讲解了Pipeline、Scheduler、Downloader和PageProcessor四大组件的作用。通过源码解析,阐述了Request如何通过Scheduler进入线程池,Downloader如何下载网页并由PageProcessor解析内容,最后通过Pipeline进行存储。文章适合初学者理解WebMagic的工作原理,并预告了后续将深入探讨各个组件的细节。
写在前面
前一段时间开发【知了】用到了很多技术(可以看我前面的博文http://blog.csdn.net/wsrspirit/article/details/51751568),这段时间抽空把这些整理一下,WebMagic是一个Java的爬虫,中国人写的,代码很模块化,也很利于二次开发,但是我们在使用的过程中也遇到了一些问题,这些问题我会在最后的博客中介绍,最近的博客将详细的走一下WebMagic的主题流程。
这是官方的技术文档,写的很好,就是有点简单了:
https://code4craft.gitbooks.io/webmagic-in-action/content/zh/index.html
走起
我们从一个demo走起:
public static void main(String[] args) {
Spider.create(new GithubRepoPageProcessor())
//从https://github.com/code4craft开始抓
.addUrl("https://github.com/code4craft")
//设置Scheduler,使用Redis来管理URL队列
.setScheduler(new RedisScheduler("localhost"))
//设置Pipeline,将结果以json方式保存到文件
.addPipeline(new JsonFilePipeline("D:\\data\\webmagic"))
//开启5个线程同时执行
.thread(5)
//启动爬虫
.run();
}Builder模式添加了总要的组件,然后设置thread,run。我们可以称之为WebMagic四大组件:Pipeline,Scheduler,Downloader和PageProcesser
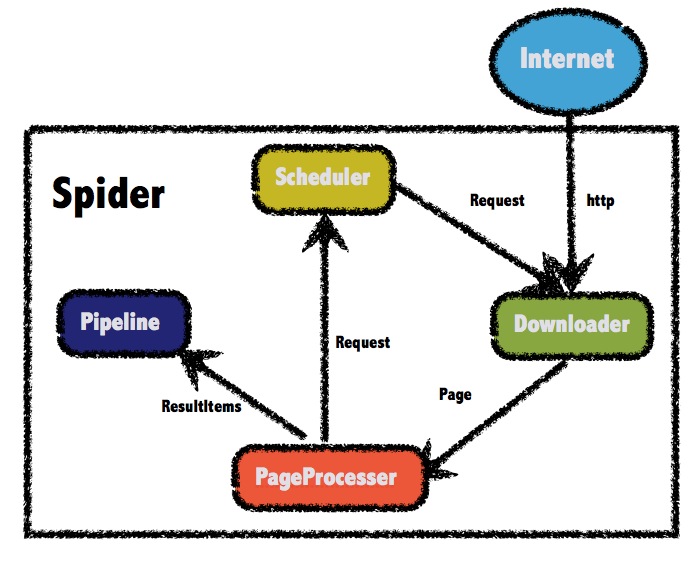
这里的图是官方网站copy的,如果你是初步使用那可能有点误导性,现在我们已经找到了程序的入口Spider类,看一下代码(有点长,没有关系,我会挑重点的说~)
package us.codecraft.webmagic;
import com.google.common.collect.Lists;
import org.apache.commons.collections.CollectionUtils;
import org.apache.http.HttpHost;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import us.codecraft.webmagic.downloader.Downloader;
import us.codecraft.webmagic.downloader.HttpClientDownloader;
import us.codecraft.webmagic.pipeline.CollectorPipeline;
import us.codecraft.webmagic.pipeline.ConsolePipeline;
import us.codecraft.webmagic.pipeline.Pipeline;
import us.codecraft.webmagic.pipeline.ResultItemsCollectorPipeline;
import us.codecraft.webmagic.processor.PageProcessor;
import us.codecraft.webmagic.scheduler.QueueScheduler;
import us.codecraft.webmagic.scheduler.Scheduler;
import us.codecraft.webmagic.thread.CountableThreadPool;
import us.codecraft.webmagic.utils.UrlUtils;
import java.io.Closeable;
import java.io.IOException;
import java.util.*;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.atomic.AtomicInteger;
import java.util.concurrent.atomic.AtomicLong;
import java.util.concurrent.locks.Condition;
import java.util.concurrent.locks.ReentrantLock;
/**
* Entrance of a crawler.<br>
* A spider contains four modules: Downloader, Scheduler, PageProcessor and
* Pipeline.<br>
* Every module is a field of Spider. <br>
* The modules are defined in interface. <br>
* You can customize a spider with various implementations of them. <br>
* Examples: <br>
* <br>
* A simple crawler: <br>
* Spider.create(new SimplePageProcessor("http://my.oschina.net/",
* "http://my.oschina.net/*blog/*")).run();<br>
* <br>
* Store results to files by FilePipeline: <br>
* Spider.create(new SimplePageProcessor("http://my.oschina.net/",
* "http://my.oschina.net/*blog/*")) <br>
* .pipeline(new FilePipeline("/data/temp/webmagic/")).run(); <br>
* <br>
* Use FileCacheQueueScheduler to store urls and cursor in files, so that a
* Spider can resume the status when shutdown. <br>
* Spider.create(new SimplePageProcessor("http://my.oschina.net/",
* "http://my.oschina.net/*blog/*")) <br>
* .scheduler(new FileCacheQueueScheduler("/data/temp/webmagic/cache/")).run(); <br>
*
* @author code4crafter@gmail.com <br>
* @see Downloader
* @see Scheduler
* @see PageProcessor
* @see Pipeline
* @since 0.1.0
*/
public class Spider implements Runnable, Task {
protected Downloader downloader;
protected List<Pipeline> pipelines = new ArrayList<Pipeline>();
protected PageProcessor pageProcessor;
protected List<Request> startRequests;
protected Site site;
protected String uuid;
protected Scheduler scheduler = new QueueScheduler();
protected Logger logger = LoggerFactory.getLogger(getClass());
protected CountableThreadPool threadPool;
protected ExecutorService executorService;
protected int threadNum = 1;
protected AtomicInteger stat = new AtomicInteger(STAT_INIT);
protected boolean exitWhenComplete = true;
protected final static int STAT_INIT = 0;
protected final static int STAT_RUNNING = 1;
protected final static int STAT_STOPPED = 2;
protected boolean spawnUrl = true;
protected boolean destroyWhenExit = true;
private ReentrantLock newUrlLock = new ReentrantLock();
private Condition newUrlCondition = newUrlLock.newCondition();
private List<SpiderListener> spiderListeners;
private final AtomicLong pageCount = new AtomicLong(0);
private Date startTime;
private int emptySleepTime = 30000;
/**
* create a spider with pageProcessor.
*
* @param pageProcessor pageProcessor
* @return new spider
* @see PageProcessor
*/
public static Spider create(PageProcessor pageProcessor) {
return new Spider(pageProcessor);
}
/**
* create a spider with pageProcessor.
*
* @param pageProcessor pageProcessor
*/
public Spider(PageProcessor pageProcessor) {
this.pageProcessor = pageProcessor;
this.site = pageProcessor.getSite();
this.startRequests = pageProcessor.getSite().getStartRequests();
}
/**
* Set startUrls of Spider.<br>
* Prior to startUrls of Site.
*
* @param startUrls startUrls
* @return this
*/
public Spider startUrls(List<String> startUrls) {
checkIfRunning();
this.startRequests = UrlUtils.convertToRequests(startUrls);
return this;
}
/**
* Set startUrls of Spider.<br>
* Prior to startUrls of Site.
*
* @param startRequests startRequests
* @return this
*/
public Spider startRequest(List<Request> startRequests) {
checkIfRunning();
this.startRequests = sta 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 404
404

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









