







如今获取互联网信息是一种很普遍的需要,用任何语言实现一个由HTTP发起请求获取数据功能都很容易,但要完整地处理可能面对的其他问题就有点麻烦了。因为爬虫涉及的点不少,因此阅读一个开源爬虫能借鉴一些优秀的设计理念,有学习价值。大名鼎鼎的scrapy,只需要编写页面处理的逻辑。我选了个模仿它写的Java系的爬虫学习:webmagic。
架构上webmagic采取了scrapy架构:
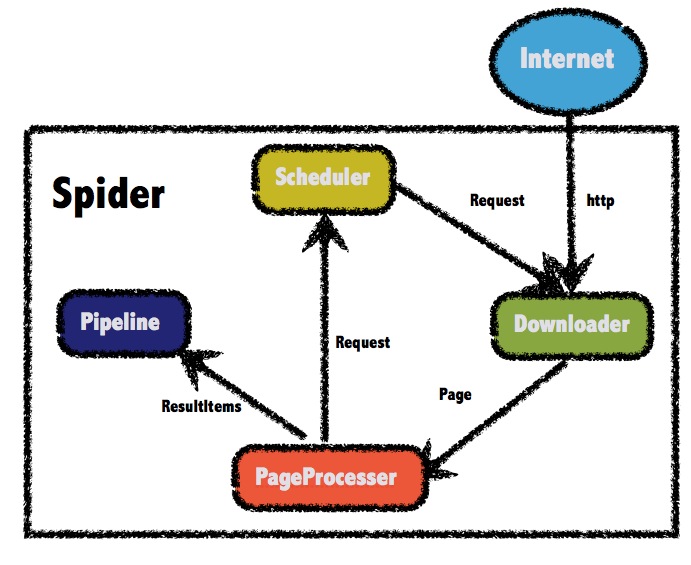
a). PageProcesser,解析抓到的一个Page页面,是否产生新的url继续抓取,或者是解析页面元素存下。
b). Downloader ,下载接口,默认用的HttpClient完成。核心方法:Page download(Request request, Task task);
c). Pipeline 对抓回并解析成结果的数据进行存储, 核心方法:process(ResultItems resultItems, Task task)
d). scheduler 页面解析出的url如何安排到下一次抓取。 要实现push(Request )/poll(Request ) 两个方法。
e). spider 则是串联所有逻辑,发起一次完整的功能
实际上编写爬虫时候,只需要实现PageProcesser这个接口类就行,PageProcesser只有两个方法,核心是process(Page): 产生新的url,则调用page.addTargetPage; 需要存内容的,则调用page.putField。 所以关键是看完成这些功能的代码是怎么串接在一起的。
webmagic中有几个概念串联了上述架构图中的组件功能,在webmagic-core下 us.codecraft.webmagic包下,分别是:
1. Request, 请求,相当于url。 还记录了cookie和header, 重试次数,extra
2. ResultItem, 保存的结果,是一个map。同时也包含一个Request
3. Page: 一个页面,包含 页面抓取情况,页面内容,本页请求Request,页面结果resultItems,后续请求targetRequests 几部分。 都是内容成员,没有什么功能。resultItems的Request正是在page这里完成关联的。
4. Site, 相当于爬虫配置,包含域名,UA,重试参数等
5. Task, 一次爬虫任务,spider实现该接口。
6. SpiderListener 记录每次抓取过程成功失败的类
所以关键是 1,2,3, 串联了架构的a-d组件。
Spider 从run()开始,这里只看简化逻辑,屏蔽多线程
1. 初始化 。
2. 开始进行循环(每次检测爬虫抓取状态):
从scheduler.poll 一个 Request,如果Request没了,则表示抓取结束并跳出;否则进入processRequest(Request) 方法:
3. processRequest 首先用downloader下载Request,得到Page, 此时如果
3.1 失败了,则进行重试,也就是重新把Request添加到scheduler中
3.2 成功了,则调用我们实现的核心 PageProcessor.process(page); 把page中我们需要的更多的url进行再添加到scheduler中;如果resultItems是需要存储的,则调用pipeline进行存储
4. 每次processRequest 触发SpiderListener 记录成功或失败
可以看得出逻辑关系在3步实现,把架构图中的箭头黑线顺序关系理清了。5根箭头顺序分别是:
1). scheduler -> downloader;
2). Internet -> downloader ; 2.x)失败 downloader -> scheduler
3). downloader -> pageProcesser ;
4). pageProcesser -> Pipeline;
5). pageProcesser -> scheduler
这里要提一下scheduler,其实是一个管理url先后次序集合的,webmagic默认的QueueScheduler,实现了去重+队列优先功能。另外Request的extra 为的是不断地PageProcesser.process(Page) 的时候,前后两次page信息进行传递:例如你需要在ajax请求(在后)时候存html(在前)的信息,就要把html的page抽取出的信息putExtra,并在ajax的page解析时拿到getExtra。又比如你详情页要存列表页的信息时候。Spider其中运用了多线程协同,可以看出是webmagic是打磨过多次的。各组件接口和关系都异常简单,十分值得学习。















 795
795

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









