







文章目录
概要
BERT,全称Bidirectional Encoder Representation of Transformer,基于Transformer的Encoder部分,摒弃了Decoder,通过堆叠多层Encoder(如BERT-base为12层,BERT-large为24层)捕捉上下文信息。此外,利用Self-Attention机制,每个位置能同时关注整个输入序列,突破传统单向模型的局限性。
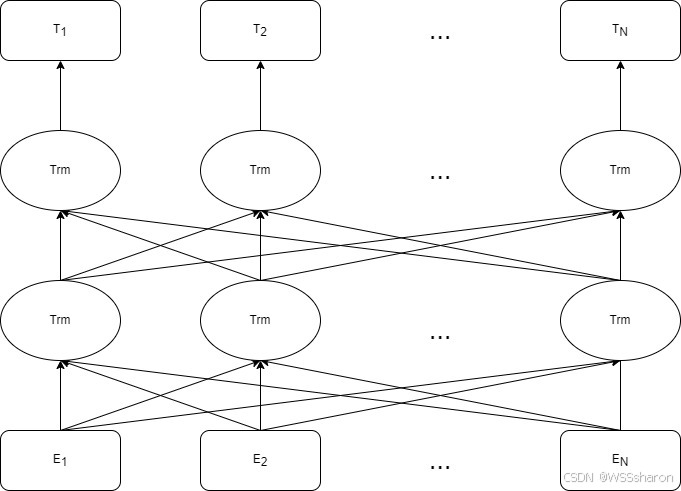
结构
1.输入与嵌入
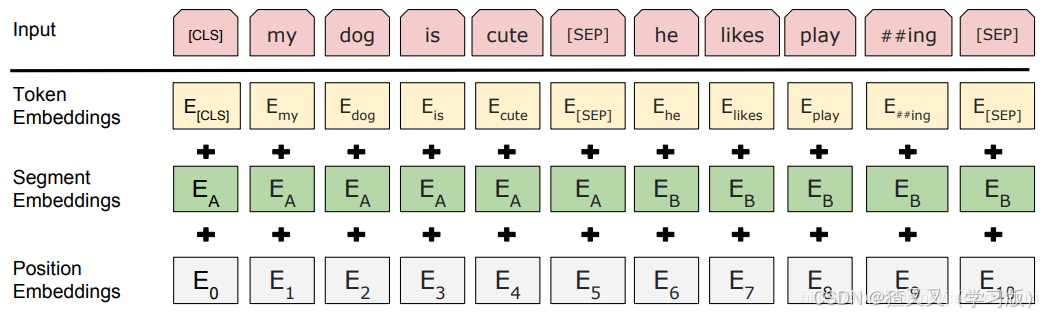
-
词嵌入(Token Embeddings):将单词映射为向量。
每个token需要转化为词嵌入的结构化数据,才适合作为模型的输入。token embedding的初始化有两种方式。第一种是在预训练时,会生成一个随机初始化的token embedding矩阵。第二种则是更为常见的在预训练模型上微调,在这种情况下就会读取预训练模型预先训练好的embedding矩阵,并且在训练过程中进行微调。token embedding的大小是21128*768(中文),30522*768(英文)。
-
段嵌入(Segment Embeddings):区分句子对中的不同句子,如
[SEP]分隔。
用于区分输入中的不同句子(或文本段),尤其是在处理句子对任务时。例如:输入可能是两个句子:[CLS] Sentence A [SEP] Sentence B [SEP]。段嵌入会明确标记哪些token属于Sentence A,哪些属于Sentence B。第一个句子(Sentence A)的所有token使用段嵌入 E_A。第二个句子(Sentence B)的所有token使用段嵌入 E_B。单句任务(如文本分类)中,所有token可能使用 E_A。
-
位置嵌入(Position Embeddings):可学习的向量,表示词的位置信息。
Transformer架构本身没有内置的序列顺序感知能力,因此需要通过位置嵌入显式地为模型注入词的位置信息。BERT使用可学习的绝对位置编码,即每个位置(如第0位、第1位…第511位)对应一个独立的向量。
2.encoder模型
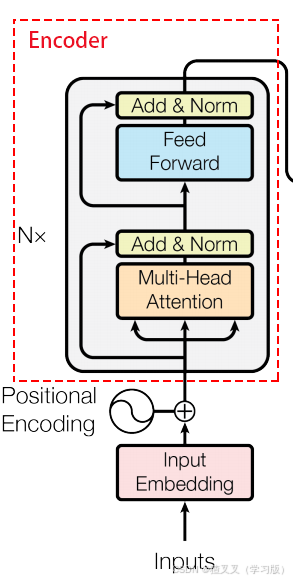
输入 → 多头自注意力 → 残差连接 + 层归一化 → 前馈网络 → 残差连接 + 层归一化 → 输出
多头自注意力(Multi-Head Attention)
通过并行多个独立的注意力头,增强模型捕捉不同子空间信息的能力。
实现方式
-
将 Q、K、V 拆分为 h 个头。
-
每个头独立计算注意力,得到 h 个输出。
-
将多个头的输出拼接后通过线性变换合并。
前馈神经网络(Feed-Forward Network, FFN)
对每个位置的表示进行非线性变换,增强模型表达能力。
实现方式
-
两个线性变换层 + 中间的非线性激活函数(如 ReLU 或 GELU):
-
逐位置计算:每个位置的向量独立通过 FFN,不跨位置交互.
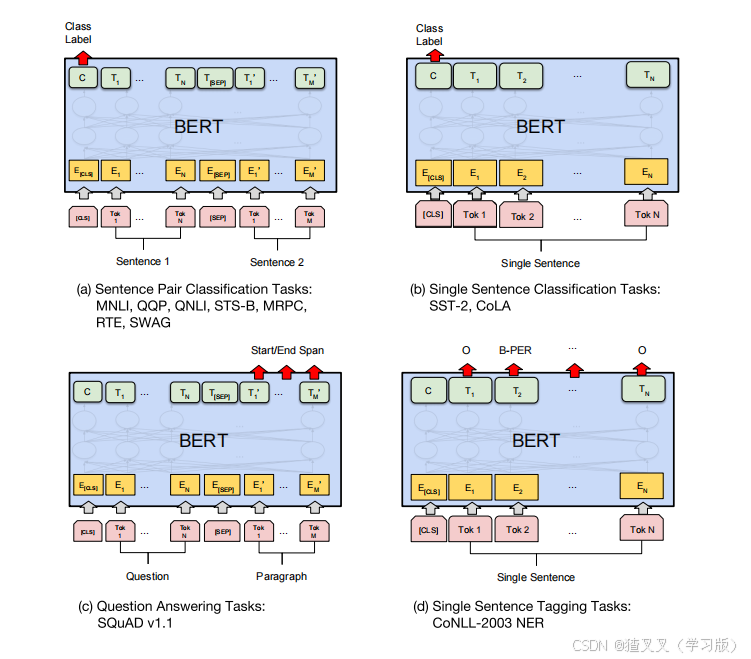
3.输出层
BERT本身的输出的有四个。
- last_hidden_state:这是模型最后一层输出的隐藏状态,shape是[batch_size, seq_len, hidden_dim],而hidden_dim = 768;
- pooler_output:这就是[CLS]字符对应的隐藏状态,它经过了一个线性层和Tanh激活函数进一步的处理。shape是[batch_size, hidden_dim]
- hidden_states:这是可选项,当output_hidden_states = True时会输出。它是一个包含了13个torch.FloatTensor的元组,每一个张量的shape均为[batch_size, seq_len, hidden_dim]。根据文档,这13个张量分别代表了嵌入层和12层encoder的输出。例如hidden_states[0]就代表嵌入层的输出,hidden_states[12]就是最后一层的输出,即last_hidden_state。
- attentions:这是可选项,当output_attentions = True时会输出。它是一个12个torch.FloatTensor元组,包含了每一层注意力权重,即经过自注意力操作中经过Softmax之后得到的矩阵。每一个张量的shape均为[batch_size, num_head, seq_len, seq_len]。
由于BERT是一个预训练模型(Masked Language Model 或 Next Sentence Prediction),因此最终的输出层是根据下游任务不同而变化的。
代码
import torch
from torch import nn
from transformers import BertModel, BertTokenizer
from torch.utils.data import Dataset, DataLoader
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
import pandas as pd
import numpy as np
from tqdm import tqdm
import os
# 设置模型路径
MODEL_PATH = './bert-base-chinese' # 本地模型路径
# 设置随机种子
def set_seed(seed):
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
np.random.seed(seed)
# 自定义数据集类
class TextDataset(Dataset):
def __init__(self, texts, labels, tokenizer, max_len=128):
self.texts = texts
self.labels = labels
self.tokenizer = tokenizer
self.max_len = max_len
def __len__(self):
return len(self.texts)
def __getitem__(self, idx):
text = str(self.texts[idx])
label = self.labels[idx]
encoding = self.tokenizer.encode_plus(
text,
add_special_tokens=True,
max_length=self.max_len,
padding='max_length',
truncation=True,
return_attention_mask=True,
return_tensors='pt'
)
return {
'input_ids': encoding['input_ids'].flatten(),
'attention_mask': encoding['attention_mask'].flatten(),
'labels': torch.tensor(label, dtype=torch.long)
}
# BERT分类器模型
class BertClassifier(nn.Module):
def __init__(self, model_path, n_classes=2):
super(BertClassifier, self).__init__()
self.bert = BertModel.from_pretrained(model_path)
self.dropout = nn.Dropout(0.1)
self.classifier = nn.Linear(self.bert.config.hidden_size, n_classes)
def forward(self, input_ids, attention_mask):
outputs = self.bert(input_ids=input_ids, attention_mask=attention_mask)
pooled_output = outputs[1]
pooled_output = self.dropout(pooled_output)
logits = self.classifier(pooled_output)
return logits
def train_model(model, train_loader, val_loader, device, epochs=3):
optimizer = torch.optim.AdamW(model.parameters(), lr=2e-5)
criterion = nn.CrossEntropyLoss()
best_accuracy = 0
for epoch in range(epochs):
model.train()
total_loss = 0
for batch in tqdm(train_loader, desc=f'Epoch {epoch + 1}/{epochs}'):
input_ids = batch['input_ids'].to(device)
attention_mask = batch['attention_mask'].to(device)
labels = batch['labels'].to(device)
optimizer.zero_grad()
outputs = model(input_ids=input_ids, attention_mask=attention_mask)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
total_loss += loss.item()
# 验证
val_accuracy = evaluate_model(model, val_loader, device)
print(f'Epoch {epoch + 1}, Loss: {total_loss/len(train_loader):.4f}, Val Accuracy: {val_accuracy:.4f}')
if val_accuracy > best_accuracy:
best_accuracy = val_accuracy
# 只保存模型权重
torch.save(model.state_dict(), 'best_model.pth')
def evaluate_model(model, data_loader, device):
model.eval()
predictions = []
actual_labels = []
with torch.no_grad():
for batch in data_loader:
input_ids = batch['input_ids'].to(device)
attention_mask = batch['attention_mask'].to(device)
labels = batch['labels'].to(device)
outputs = model(input_ids=input_ids, attention_mask=attention_mask)
_, preds = torch.max(outputs, dim=1)
predictions.extend(preds.cpu().tolist())
actual_labels.extend(labels.cpu().tolist())
accuracy = accuracy_score(actual_labels, predictions)
precision = precision_score(actual_labels, predictions)
recall = recall_score(actual_labels, predictions)
f1 = f1_score(actual_labels, predictions)
print(f'\n评估指标:')
print(f'准确率 (Accuracy): {accuracy:.4f}')
print(f'精确率 (Precision): {precision:.4f}')
print(f'召回率 (Recall): {recall:.4f}')
print(f'F1分数 (F1-Score): {f1:.4f}')
return accuracy
def main():
# 检查模型文件是否存在
if not os.path.exists(MODEL_PATH):
print(f"错误:未找到本地模型文件夹 '{MODEL_PATH}'")
print("请先下载模型到本地,或修改 MODEL_PATH 为正确的模型路径")
return
# 设置设备和随机种子
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f"使用设备: {device}")
set_seed(42)
# 加载数据
df = pd.read_excel('data4.xlsx') # 确保Excel文件包含'text'和'label'列
texts = df['text'].values
labels = df['label'].values
# 划分训练集和测试集
train_texts, test_texts, train_labels, test_labels = train_test_split(
texts, labels, test_size=0.3, random_state=42
)
# 初始化tokenizer和数据集
print("加载本地tokenizer...")
tokenizer = BertTokenizer.from_pretrained(MODEL_PATH)
train_dataset = TextDataset(train_texts, train_labels, tokenizer)
test_dataset = TextDataset(test_texts, test_labels, tokenizer)
# 创建数据加载器
train_loader = DataLoader(train_dataset, batch_size=16, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=16)
# 初始化模型
print("加载本地预训练模型...")
model = BertClassifier(MODEL_PATH)
model.to(device)
# 训练模型
print("开始训练...")
train_model(model, train_loader, test_loader, device)
# 加载最佳模型并评估
print("\n加载最佳模型并进行最终评估...")
# 使用weights_only=True安全加载模型权重
model.load_state_dict(torch.load('best_model.pth', weights_only=True))
evaluate_model(model, test_loader, device)
if __name__ == '__main__':
main() bert-base-chinese文件中要有config.json、pytorch_model.bin、vocab.txt文件。下载链接:https://pan.baidu.com/s/1aEwTtAPRVdivoV_OCkldsA?pwd=mrr9 提取码: mrr9
小结
BERT是一种基于Transformer架构的预训练模型,它通过双向编码器训练上下文嵌入表示。这种表示方法使得BERT能够捕捉到丰富的语义信息,从而在各种NLP任务中表现出色。BERT的优点还包括强大的泛化能力和对未知任务的适应性。
尽管BERT具有显著的优势,但它仍然存在一些局限性。首先,最大输入长度为512个token,超出部分需截断或分段处理,可能丢失长距离依赖。其次,在少样本下游任务中易过拟合。此外,双向注意力机制在生成任务中效率较低。未来的研究可以继续改进和优化BERT模型。

















 6014
6014

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









