







项目总结
实现了一个功能完善的在线论坛,旨在为校园内提供一个“畅所欲言”的论坛环境,项目分别实现了用户模块、登录模块、发帖模块、和点赞关注模块等。
主要的技术点:
1.登录注册功能:使用kaptcha去生成验证码,使用SpringMail完成注册
2.Redis优化验证码的保存,解决分布式session问题
3.使用拦截器拦截用户请求,将用户信息绑定在ThreadLocal上
4.构建Trie数据结构,实现对发表帖子评论的敏感词过滤
5.支持对帖子评论,也支持对评论进行回复
6.利用Redis的zset并结合Redis实现点赞关注的功能
7.用户点赞关注后,使用kafka实现异步的发送系统通知
8.使用ElasticSearch实现对帖子的搜索功能,以及结果的高亮显示
9.利用SpringSecurity实现认证和授权
10.利用HyperLogLog、Bitmap分别实现网站UV和DAU的统计
11.利用Quartz实现了任务调度功能,实现定时计算帖子分数
12.利用Caffeine+Redis实现了两级缓存,优化了热门帖子的访问
开发环境
构建工具:Apache Maven
集成开发工具: IntelliJ IDEA 2021
数据库:MySQL、Redis
应用服务器:Apache Tomcat
框架:Spring、SpringMVC、Mybatis、SpringBoot
版本控制工具:Git
一、注册与登录功能的实现
注册和登录功能是每个项目最基本的功能,实现的主要难点在于怎么解决分布式Session问题,密码安全问题,以及怎么优化登录的问题。
用户表实现
| id | username | password | salt | type | status | activation_code | header_url | create_time |
|---|
密码实现
为了保证安全,密码不能明文的在网络中进行传输,也不能以明文的形式存到数据库中。
存在数据库的密码 = MD5( 密码 + salt ) 防止密码泄露,salt为随机字符串
// MD5 加密
public static String md5(String key) {
if (StringUtils.isBlank(key)) {
return null;
}
return DigestUtils.md5DigestAsHex(key.getBytes());
}
SpringMail配置及发送注册邮件
application.properties对SpringMail进行配置
# mailProperties
spring.mail.host=smtp.sina.com
spring.mail.port=465
spring.mail.username=wfb18324952938@sina.cn
spring.mail.password=4681082336c1****
spring.mail.protocol=smtps
spring.mail.properties.mail.smtp.ssl.enable=true
MailClient实现方法,进行发送邮件操作
public void sendMail(String to, String subject, String content) {
try {
MimeMessage message = mailSender.createMimeMessage();
MimeMessageHelper helper = new MimeMessageHelper(message);
helper.setFrom(from);
helper.setTo(to);
helper.setSubject(subject);
helper.setText(content, true);
mailSender.send(helper.getMimeMessage());
} catch (MessagingException e) {
logger.error("发送邮件失败: " + e.getMessage());
}
}
会话管理
由于Http是无状态的,每次的http请求之间信息不共享,为了保证用户每次请求不用重新输入账号密码,保存用户的登录状态,就会有session和cookie这样的机制,去保存用户登录信息,但是在分布式部署的时候就会存在session共享的一个问题。
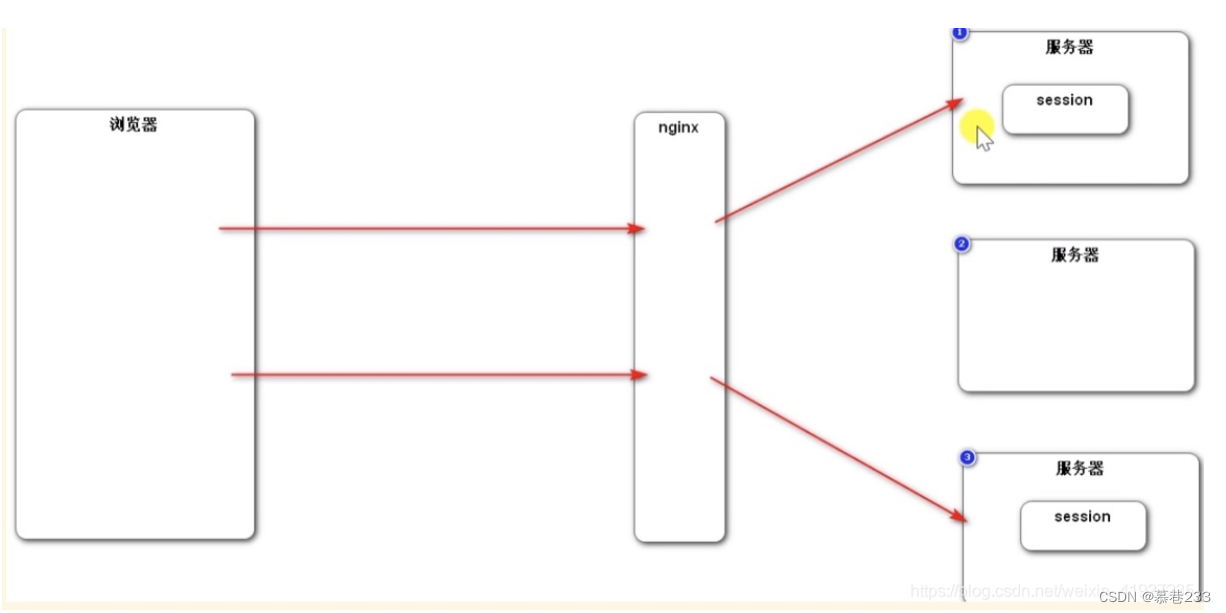
现在网站基本是多台服务器分布式部署的,如果将用户信息存到session中,而session是存到服务器上,在分布式环境下,由于各个服务器主机之间的信息并不共享,将用户信息存到服务器1上,同一个用户的下一个请求过来的时候,由于nginx的负载均衡策略,去请求了服务器2,就找不到之前的session了。
解决办法:
将客户端会话数据不存到Session中而是存到数据库中
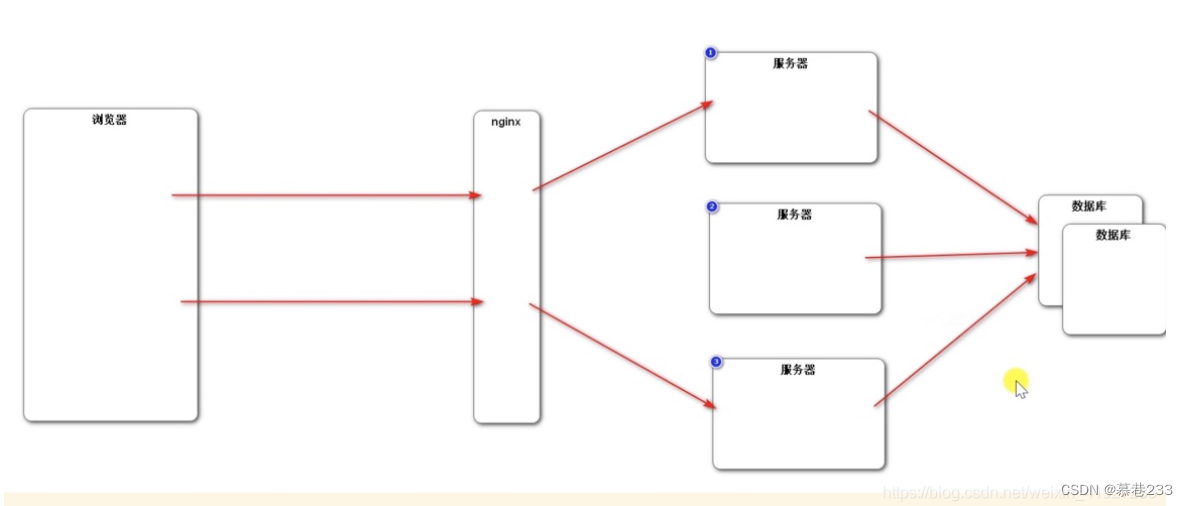
考虑到关系型数据库性能较慢,项目中采用的方式是存到redis中
Kaptcha生成验证码
利用Kaptcha类实现生成随机字符,生成图片(验证码功能)
public Producer kaptchaProducer(){
Properties properties = new Properties();
properties.setProperty("kaptcha.image.width","100");
properties.setProperty("kaptcha.image.height","40");
properties.setProperty("kaptcha.textproducer.font.size","32");
properties.setProperty("kaptcha.textproducer.font.color","black");
properties.setProperty("kaptcha.textproducer.char.string","0123456789ABCDEFGHJKLMNOPQRSTUVWXYZ");
properties.setProperty("kaptcha.textproducer.char.length","4");
properties.setProperty("kaptcha.noise.impl","com.google.code.kaptcha.impl.NoNoise");
DefaultKaptcha kaptcha = new DefaultKaptcha();
Config config = new Config(properties);
kaptcha.setConfig(config);
return kaptcha;
}
Loginticket生成凭证 记录登录状态
本项目中先采用将用户登录信息存到数据库的login_ticket表中,后续采用存到redis中优化。
V1 将用户登录凭证ticket存到mysql的login_ticket表中
登陆成功的时候生成登录凭证,生成Loginticket往数据库login_ticket存,并且被设置为cookie,下次用户登录的时候会带上这个ticket,ticket是个随机的UUID字符串,有过期的时间expired和有效的状态status
LoginTicket表
| id | user_id | ticket | status | expired |
|---|
V2: 使用Redis优化登录模块
- 使用Redis存储验证码
- 验证码需要频繁的访问与刷新,对性能要求比较高
- 验证码不需要永久保存,通常在很短的时间后就会失效(redis设置失效时间)
- 分布式部署的时候,存在Session共享的问题(之前验证码是存到session里面,使用redis避免session共享问题)
| Key | Value |
|---|---|
| Kaptcha:owner | String |
直接将验证码字符串存到session当中,每次都是从session中获取验证码字符串的值在进行判断会出现分布式session的问题,比如说刷新验证码是一次请求,此次请求将验证码存到了服务器A的session当中,但在点击登录按钮,去触发登录请求s时,将此次请求转到了服务器B,而服务器B并没有存储验证码的session,就会出现无法判断的问题。
// 验证码的归属
String kaptchaOwner = CommunityUtil.generateUUID();
Cookie cookie = new Cookie("kaptchaOwner", kaptchaOwner);
cookie.setMaxAge(60);
cookie.setPath(contextPath);
response.addCookie(cookie);
// 将验证码存入Redis
String redisKey = RedisKeyUtil.getKaptchaKey(kaptchaOwner);
redisTemplate.opsForValue().set(redisKey, text, 60, TimeUnit.SECONDS);
- 使用Redis存储登录凭证,作废login_ticket
- 处理每次请求的时候,都要从请求的cookie中取出登录凭证并与从数据库mysql中查询用户的登录凭证作比对,访问的频率非常高,ticket如果用redis存,mysql就可以不用存了,login_ticket可以作废
// 生成登录凭证
LoginTicket loginTicket = new LoginTicket();
loginTicket.setUserId(user.getId());
loginTicket.setTicket(CommunityUtil.generateUUID());
loginTicket.setStatus(0);
loginTicket.setExpired(new Date(System.currentTimeMillis() + expiredSeconds * 1000));
// 舍弃将LoginTicket通过Mapper存入MySQL,转而放入Redis里
// loginTicketMapper.insertLoginTicket(loginTicket);
String redisKey = RedisKeyUtil.getTicketKey(loginTicket.getTicket());
// loginTicket会序列化为JSON字符串
redisTemplate.opsForValue().set(redisKey, loginTicket);
map.put("ticket", loginTicket.getTicket());
return map;
-
使用Redis缓存用户信息
-
处理每次请求的时候,都要根据登录凭证查询用户信息,访问的频率非常高(每次请求的时候需要根据凭证中的用户id查询用户)
-
查询User的时候,先尝试从缓存中取值,如果没有的话,就需要初始化,有些地方会改变用户数据,需要更新缓存,可以直接把该用户的缓存删除,下一次请求的时候发现没有用户的信息,就会重新查一次再放到缓存中
-
// 1.有限从缓存中取值
private User getCache(int userId) {
String redisKey = RedisKeyUtil.getUserKey(userId);
return (User) redisTemplate.opsForValue().get(redisKey);
}
// 2.取不到时初始化缓存数据
private User initCache(int userId) {
User user = userMapper.selectById(userId);
String redisKey = RedisKeyUtil.getUserKey(userId);
redisTemplate.opsForValue().set(redisKey, user, 3600, TimeUnit.SECONDS);
return user;
}
// 3.当数据变更时,清除缓存数据
private void clearCache(int userId) {
String redisKey = RedisKeyUtil.getUserKey(userId);
redisTemplate.delete(redisKey);
}
显示登录信息
声明拦截器(实现HandleInterceptor)并在spring注解@Configuration中配置拦截信息
- 在请求开始时查询登录用户
- 在本次请求中持有用户数据
@Configuration
public class WebMvcConfig implements WebMvcConfigurer {
@Autowired
private LoginTicketInterceptor loginTicketInterceptor;
@Override
public void addInterceptors(InterceptorRegistry registry) {
registry.addInterceptor(loginTicketInterceptor)
.excludePathPatterns("/**/*.css", "/**/*.js", "/**/*.png", "/**/*.jpg", "/**/*.jpeg");
}
}
使用拦截器Interceptor来拦截所有的用户请求,判断请求中的cookie是否存在有效的ticket,如果有的话就将查询用户信息并将用户的信息写入ThreadLocal在本次请求中持有用户,将每个线程的threadLocal都存到一个叫做hostHolder的实例中,根据这个实例就可以在本次请求中全局任意的位置获取用户信息。
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
// 从cookie中获取凭证
String ticket = CookieUtil.getValue(request, "ticket");
if (ticket != null) {
// 查询凭证
LoginTicket loginTicket = userService.findLoginTicket(ticket);
// 检查凭证是否有效
if (loginTicket != null && loginTicket.getStatus() == 0 && loginTicket.getExpired().after(new Date())) {
// 根据凭证查询用户
User user = userService.findUserById(loginTicket.getUserId());
// 在本次请求中持有用户
hostHolder.setUser(user);
}
}
return true;
}
拦截器的应用:
- 在请求开始时查询登录用户
- 在本次请求中持有用户数据
- 在模板视图上显示用户数据
- 在请求结束时清理用户数据
检查登录状态
使用拦截器:
-
在方法前标注自定义注解
-
拦截所有请求,只处理带有该注解的方法
// 元注解
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
public @interface LoginRequired {
}
在setting和upload等方法上,必须要求用户登录方可进行操作
@LoginRequired
@RequestMapping(path = "/setting", method = RequestMethod.GET)
public String getSettingPage() {
return "/site/setting";
}
@LoginRequired
@RequestMapping(path = "/upload", method = RequestMethod.POST)
public String uploadHeader(MultipartFile headerImage, Model model) {
二、社区核心功能
前缀树过滤
前缀树:
- 名称:Trie、字典树、查找树
- 特点:查找效率高,消耗内存大
- 应用:字符串检索、词频统计、字符串排序等
发布帖子的时候需要对帖子的标题和内容进行敏感词,通过Trie实现敏感词过滤算法,过滤敏感词首先需要建立一颗字典树,并且读取一份保存敏感词的文本文件,并用文件初始化字典树,最后将敏感词作为一个服务,让需要过滤敏感词的服务进行调用即可。
// 替换符
private static final String REPLACEMENT = "***";
// 初始化根节点
private TrieNode rootNode = new TrieNode();
@PostConstruct // 标识这是初始化方法
public void init() {
try (
InputStream is = this.getClass().getClassLoader().getResourceAsStream("sensitive-words.txt");
BufferedReader reader = new BufferedReader(new InputStreamReader(is));
) {
String keyword;
while ((keyword = reader.readLine()) != null) {
// 添加敏感词到前缀树
this.addKeyword(keyword);
}
} catch (IOException e) {
logger.error("加载敏感词文件失败" + e.getMessage());
}
}
AJAX异步发帖
AJAX
- Asynchronous JavaScript and XML
- 异步的JavaScript与XML
- 使用AJAX,网页能够增量更新呈现在页面上,而不需要刷新整个页面
- 虽然X代表XML,但是目前JSON的使用比XML更加普遍
使用HTMLUtils的方法来防止xss注入
发表评论以及私信
评论表:
| id | user_id | entity_type | entity_id | target_id | content | status | create_time |
|---|
其中:
- Entity_type 评论的目标的类别 1:帖子 2: 评论 支持回复评论
- entity_id 评论具体的目标
- target_id 记录回复指向的人 (只会发生在回复中 判断target_id==0)
- user_id 评论的作者
添加评论:
(将添加评论和更新评论数量放在一个事务中)使用spring声明式事务管理@Transactional实现
Spring AOP记录日志
Aop实现对service层所有的业务方法记录日志
- Aop是一种编程思想,是对OOP的补充,可以进一步提升效率
- Aop解决纵向切面的问题,主要实现日志和权限控制的功能
- aspect实现切面,并且使用Logger来记录日志。用该切面的切面方法来监听controller
- 拦截器主要针对的是控制层controller
三、使用Redis实现点赞关注
Redis入门
Redis是一款基于键值对的NoSQL数据库,它的值支持多种数据结构:字符串(strings)、哈希(hashes)、列表(lists)、集合(sets)、有序集合(sorted sets)等。
Redis将所有的数据都存放在内存中,所以它的读写性能十分惊人。 同时,Redis还可以将内存中的数据以快照或日志的形式保存到硬盘上,以保证数据的安全性。
Redis典型的应用场景包括:缓存、排行榜、计数器、社交网络、消息队列等。
点赞功能
- 支持对帖子、评论点赞
- 第一次点赞,第2次取消点赞(判断userId在不在set集合中,就可以判断用户有否点过赞,如果已经点过赞了,就将用户从集合中删除)
- 在查询某人对某实体的点在状态时,用可以用boolean作为返回值,但项目中使用int(支持业务扩展,可以支持是否点踩)
访问Redis:
redisTemplate.opsForValue()
redisTemplate.opsForHash()
redisTemplate.opsForList()
redisTemplate.opsForSet()
redisTemplate.opsForZSet()
| Key | Value |
|---|---|
| like:entity:entityType:entityId | Stringset(userId) |
value使用set集合存放userId是为了能看对谁点了赞。
我收到的赞
点赞时同样需要记录点赞实体的用户id
某个用户收到的赞
| Key | Value |
|---|---|
| like:user:userId | int |
关注、取消关注功能
使用Redis实现了每一个用户的粉丝列表,以及每一个用户的关注列表。
Redis set实现共同关注 :取交集 : sinter myset2 myset3
某个用户关注的实体
| Key | Value |
|---|---|
| followee:userId:entityType | int |
使用zset以当前时间作为分数排序
某个实体拥有的粉丝
| Key | Value |
|---|---|
| follower:entityType:entityId | zset(userId,now) |
四、Kafka,实现异步消息系统
在项目中,会有一些不需要实时执行但是是非常频繁的操作或者任务,为了提升网站的性能,可以使用异步消息的形式进行发送,再次消息队列服务器kafka来实现。
kafka和zookeeper的启动
在kafka安装目录下,输入命令:
bin\windows\zookeeper-server-start.bat config\zookeeper.properties
启动zookeeper服务
输入命令:
bin\windows\kafka-server-start.bat config\server.properties
启动kafka服务
发送系统通知
评论,点赞,关注等事件是非常频繁的操作,发送关系其的系统通知却并不是需要立刻执行的。主要实现分为下面几步:
- 触发事件
- 评论后,发布通知
- 点赞后,发布通知
- 关注后,发布通知
- 处理事件
- 封装事件对象(Event)
// Event类
private String topic;
private int userId;
private int entityType;
private int entityUserId;
private Map<String,object> data;
- 开发事件的生产者
向特定的主题(评论,点赞,关注)发送事件
//处理事件(发送事件)
public void fireEvent(Event event){
//将事件发布到指定的主题
kafkaTemplate.send(event.getTopic(), JSONObject.toJSONString(event));
}
- 开发事件的消费者
使用@KafkaListener注解监听事件,如果监听成果并进行相应的处理,最后调用messageService添加到数据库中,下次用户显示消息列表的时候就可以看到系统消息了。
@KafkaListener(topics = {TOPIC_COMMENT, TOPIC_LIKE, TOPIC_FOLLOW})
public void handleCommentMessage(ConsumerRecord record) {
Event event = JSONObject.parseObject(record.value().toString(), Event.class);
//发送站内的通知
Message message = new Message();
message.setFromId(SYSTEM_USER_ID);
message.setToId(event.getEntityUserId());
message.setConversationId(event.getTopic());//comment like follow
message.setCreateTime(new Date());
message.setContent(JSONObject.toJSONString(content));
System.out.println(content);
//调用messageService添加到数据库中
messageService.addMessage(message);
}
五、Elasticsearch 实现搜索功能
Elasticsearch 的简单入门
ES简介:
- 一个分布式的,Restful风格的搜索引擎
- 支持对各种类型的数据的检索
- 搜于速度快,可以提供实时的搜索服务
- 便于水平扩展,每秒可以处理PB级别的海量数据
1.ES配置:
更改配置config目录下的elasticsearch.yml ,配置集群名字,编程时需要指定的集群名字:
cluster.name: muxiang
更改es存储数据的目录,日志存放的目录,运行的时候会自动创建
path.data: d:\JAVA\data\elasticsearch-6.4.3\data
配置中文分词插件"ik"
2.安装postman,模拟http请求,往ES中存取数据
Spring整合ES
导包
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
配置 ElasticsearchProperties
# ElasticsearchProperties
spring.data.elasticsearch.cluster-name=wfb
spring.data.elasticsearch.cluster-nodes=127.0.0.1:9300
给帖子实体类增加注解
@Document(indexName = "discusspost", type = "_doc", shards = 6, replicas = 3)
public class DiscussPost {
@Id
private int id;
@Field(type = FieldType.Integer)
private int userId;
// 互联网校招
@Field(type = FieldType.Text, analyzer = "ik_max_word", searchAnalyzer = "ik_smart")
private String title;
@Field(type = FieldType.Text, analyzer = "ik_max_word", searchAnalyzer = "ik_smart")
private String content;
@Field(type = FieldType.Integer)
private int type; //'0-普通; 1-置顶;',
@Field(type = FieldType.Integer)
private int status; //'0-正常; 1-精华; 2-拉黑;',
@Field(type = FieldType.Date)
private Date createTime;
@Field(type = FieldType.Integer)
private int commentCount;
@Field(type = FieldType.Double)
private double score;
}
定义访问接口
@Repository
public interface DiscussPostRepository extends ElasticsearchRepository<DiscussPost,Integer> {
}
实现搜索功能
四个关键点构造查询条件
- 搜索关键词 QueryBuilders
- 分页方式PageRequest
- 排序SortBuilders
- 高亮搜索 HighlightBuilder
利用ES实现网站的搜索功能
- 搜索服务
- 将帖子保存到Elasticsearch服务器
- 从 Elasticsearch 服务器中删除帖子
- 从 Elasticsearch 服务器搜索帖子
- 发布事件(将发帖或者更改帖子的事件存到kafka中,消费事件并将帖子存到es服务器中)
- 发布帖子时,将帖子异步的提交到Elasticsearch服务器
//触发发帖事件
Event event = new Event()
.setTopic(TOPIC_PUBLISH)
.setUserId(user.getId())
.setEntityType(ENTITY_TYPE_POST)
.setEntityId(post.getId());
eventProducer.fireEvent(event);
- 增加评论的时候,将帖子异步的提交到Elasticsearch服务
if(comment.getEntityType() == ENTITY_TYPE_POST) {
// 触发发帖事件
event = new Event()
.setTopic(TOPIC_PUBLISH)
.setUserId(comment.getUserId())
.setEntityType(ENTITY_TYPE_POST)
.setEntityId(discussPostId);
eventProducer.fireEvent(event);
}
- 在kafka消费组件中增加一个方法,消费帖子发布事件
// 消费发帖事件
@KafkaListener(topics = {TOPIC_PUBLISH})
public void handlePublishMessage(ConsumerRecord record) {
if (record == null || record.value() == null) {
logger.error("消息的内容为空");
return;
}
Event event = JSONObject.parseObject(record.value().toString(), Event.class);
if (event == null) {
logger.error("消息格式错误!");
return;
}
DiscussPost post = discussPostService.findDiscussPostById(event.getEntityId());
elasticsearchService.saveDiscussPost(post);
}
- 显示结果
- 在控制器中处理搜索请求,在HTML高亮显示搜索结果
六、构建安全高性能系统
SpringSecurity实现认证和授权
Spring集成SpringSecurity
权限控制
- 登录检查
之前采用拦截器实现了登录检查,这是简单的权限管理方案,现在将其废弃。
// 废弃拦截器,用Security代替
// @Autowired
// private LoginRequiredInterceptor loginRequiredInterceptor;
- 授权配置
对当前系统内包含的所有的请求,分配访问权限(普通用户、版主、管理员)。
// 授权
@Override
protected void configure(HttpSecurity http) throws Exception {
// 访问路径的授权
http.authorizeRequests()
.antMatchers(
"/user/setting",
"/user/upload",
"discuss/add",
"/comment/add/**",
"/letter/**",
"/notice/**",
"/like",
"/follow",
"/unfollow"
)
.hasAnyAuthority(
AUTHORITY_USER, AUTHORITY_ADMIN, AUTHORITY_MODERATOR
)
.anyRequest().permitAll()
.and().csrf().disable();
// 权限不够时的处理
http.exceptionHandling()
.authenticationEntryPoint(new AuthenticationEntryPoint() {
// 没有登录
@Override
public void commence(HttpServletRequest request, HttpServletResponse response, AuthenticationException e) throws IOException, ServletException {
String xRequestedWith = request.getHeader("x-requested-with");
// 异步请求 返回json
if ("XMLHttpRequest".equals(xRequestedWith)) {
response.setContentType("application/plain;charset=utf-8");
PrintWriter writer = response.getWriter();
writer.write(CommunityUtil.getJSONString(403, "你还没有登录"));
} else {
// 非异步请求,重定向到登录页面
response.sendRedirect(request.getContextPath() + "/login");
}
}
})
.accessDeniedHandler(new AccessDeniedHandler() {
// 权限不足
@Override
public void handle(HttpServletRequest request, HttpServletResponse response, AccessDeniedException e) throws IOException, ServletException {
String xRequestedWith = request.getHeader("x-requested-with");
// 异步请求 返回json
if ("XMLHttpRequest".equals(xRequestedWith)) {
response.setContentType("application/plain;charset=utf-8");
PrintWriter writer = response.getWriter();
writer.write(CommunityUtil.getJSONString(403, "你没有访问此功能的权限"));
} else {
// 非异步请求,重定向到登录页面
response.sendRedirect(request.getContextPath() + "/denied");
}
}
});
// Security底层默认会拦截/logout请求,进行退出处理.
// 覆盖它默认的逻辑,才能执行我们自己的退出代码
http.logout().logoutUrl("/securitylogout");
}
- 认证方案
绕过Security认证流程,采用系统原来的认证方案。
// Security底层默认会拦截/logout请求,进行退出处理.
// 覆盖它默认的逻辑,才能执行我们自己的退出代码
http.logout().logoutUrl("/securitylogout");
- CSRF配置
防止CSRF 攻击的基本原理,以及表单、AJAX相关的配置。
网站UA和DAU等数据统计
redis高级数据类型
HyperLogLog
- 采用一种基数算法,用于完成独立总数的统计
- 占据空间小,无论统计多少个数据,只占12K的内存空间
- 不精确的统计算法,标准误差为0.81%
// 实测100000个数的统计值大小为99553
redisTemplate.opsForHyperLogLog().add(redisKey, i);//添加数据
Long size = redisTemplate.opsForHyperLogLog().size(redisKey);//查询数据量
Bitmap
- 不是一种独立的数据结构,实际上就是字符串
- 支持按位存取数据,可以将其看成是byte数组
- 适合存储索大量的连续的数据的布尔值
redisTemplate.opsForValue().setBit(redisKey,1,true);//添加
redisTemplate.opsForValue().getBit(redisKey,1);//查询
redisTemplate.execute(new RedisCallback() { //统计
@Override
public Object doInRedis(RedisConnection connection) throws DataAccessException {
return connection.bitCount(redisKey.getBytes());
数据统计
UV (Unique Visitor)
- 独立访客,需通过用户IP排重统计数据
// 将指定的IP计入UV
public void recordUV(String ip) {
String redisKey = RedisKeyUtil.getUVKey(df.format(new Date()));
redisTemplate.opsForHyperLogLog().add(redisKey, ip);
}
- 每次访问都要进行统计
- HyperLogLog,性能好,且存储空间小
DAU (Daily Active User)
- 官活跃用户,需通过用户ID排重统计数据
// 将指定用户计入DAU
public void recordDAU(int userId) {
String redisKey = RedisKeyUtil.getDAUKey(df.format(new Date()));
redisTemplate.opsForValue().setBit(redisKey, userId, true);
}
- 访问过一次,则认为其活跃
- Bitmap,性能好、且可以统计精确的结果
热帖排行
线程池与定时任务
利用Quartz实现热帖排行
概念
- quartz是一个开源项目,完全基于java实现。是一个优秀的开源调度框架。
特点
- 强大的调度功能,例如支持丰富多样的调度方法
- 灵活的应用方式,例如支持任务和调度的多种组合方式
- 分布式和集群能力
专业术语
- scheduler:任务调度器 , scheduler是一个计划调度器容器,容器里面有众多的JobDetail和trigger,当容器启动后,里面的每个JobDetail都会根据trigger按部就班自动去执行
- trigger:触发器,用于定义任务调度时间规则
- job:任务,即被调度的任务, 主要有两种类型的 job:无状态的(stateless)和有状态的(stateful)。一个 job 可以被多个 trigger 关联,但是一个 trigger 只能关联一个 job
- misfire:本来应该被执行但实际没有被执行的任务调度
实现过程
配置指定的JobDetail
// 刷新帖子分数任务
@Bean
public JobDetailFactoryBean postScoreRefreshJobDetail() {
JobDetailFactoryBean factoryBean = new JobDetailFactoryBean();
factoryBean.setJobClass(PostScoreRefreshJob.class);
factoryBean.setName("postScoreRefreshJob");
factoryBean.setGroup("communityJobGroup");
factoryBean.setDurability(true);
factoryBean.setRequestsRecovery(true);
return factoryBean;
}
配置指定的Trigger
@Bean
public SimpleTriggerFactoryBean postScoreRefreshTrigger(JobDetail postScoreRefreshJobDetail) {
SimpleTriggerFactoryBean factoryBean = new SimpleTriggerFactoryBean();
factoryBean.setJobDetail(postScoreRefreshJobDetail);
factoryBean.setName("postScoreRefreshTrigger");
factoryBean.setGroup("communityTriggerGroup");
factoryBean.setRepeatInterval(1000 * 60 * 5);
factoryBean.setJobDataMap(new JobDataMap());
return factoryBean;
}
PostScoreRefreshJob实现Job接口
重写execute方法
@Override
public void execute(JobExecutionContext context) throws JobExecutionException {
String redisKey = RedisKeyUtil.getPostScoreKey();
BoundSetOperations operations = redisTemplate.boundSetOps(redisKey);
if (operations.size() == 0) {
logger.info("[任务取消] 没有需要刷新的帖子!");
return;
}
logger.info("[任务开始] 正在刷新帖子分数: " + operations.size());
while (operations.size() > 0) {
this.refresh((Integer) operations.pop());
}
logger.info("[任务结束] 帖子分数刷新完毕!");
}
编写热帖的算法和更新帖子数据
分数=log (精华分+评论数10 +点赞数2+收藏数*2)+(发布时间–系统时间)
private void refresh(int postId) {
DiscussPost post = discussPostService.findDiscussPostById(postId);
if (post == null) {
logger.error("该帖子不存在: id = " + postId);
return;
}
// 是否精华
boolean wonderful = post.getStatus() == 1;
// 评论数量
int commentCount = post.getCommentCount();
// 点赞数量
long likeCount = likeService.findEntityLikeCount(ENTITY_TYPE_POST, postId);
// 计算权重
double w = (wonderful ? 75 : 0) + commentCount * 10 + likeCount * 2;
// 分数 = 帖子权重 + 距离天数
double score = Math.log10(Math.max(w, 1))
+ (post.getCreateTime().getTime() - epoch.getTime()) / (1000 * 3600 * 24);
// 更新帖子分数
discussPostService.updateScore(postId, score);
// 同步搜索数据
post.setScore(score);
elasticsearchService.saveDiscussPost(post);
}
重构查询帖子逻辑,增加一个分数的排序方式
基于Caffeine的本地缓存
本地缓存
- 将数据缓存在应用服务器上,性能最好
- 常用缓存工具:Ehcache、Guava、Caffeine等
定义帖子列表缓存
private LoadingCache<String, List<DiscussPost>> postListCache;
定义帖子综述缓存
private LoadingCache<Integer, Integer> postRowsCache;
初始化缓存
@PostConstruct
public void init() {
// 初始化帖子列表缓存
postListCache = Caffeine.newBuilder()
.maximumSize(maxSize)
.expireAfterWrite(expireSeconds, TimeUnit.SECONDS)
.build(new CacheLoader<String, List<DiscussPost>>() {
@Nullable
@Override
public List<DiscussPost> load(@NonNull String key) throws Exception {
if (key == null || key.length() == 0) {
throw new IllegalArgumentException("参数错误!");
}
String[] params = key.split(":");
if (params == null || params.length != 2) {
throw new IllegalArgumentException("参数错误!");
}
int offset = Integer.valueOf(params[0]);
int limit = Integer.valueOf(params[1]);
// 二级缓存: Redis -> mysql
logger.debug("load post list from DB.");
return discussPostMapper.selectDiscussPosts(0, offset, limit, 1);
}
});
// 初始化帖子总数缓存
postRowsCache = Caffeine.newBuilder()
.maximumSize(maxSize)
.expireAfterWrite(expireSeconds, TimeUnit.SECONDS)
.build(new CacheLoader<Integer, Integer>() {
@Nullable
@Override
public Integer load(@NonNull Integer key) throws Exception {
logger.debug("load post rows from DB.");
return discussPostMapper.selectDiscussPostRows(key);
}
});
}
使用缓存读取热帖
public List<DiscussPost> findDiscussPosts(int userId, int offset, int limit, int orderMode) {
if (userId == 0 && orderMode == 1) {
return postListCache.get(offset + ":" + limit);
}
logger.debug("load post list from DB.");
return discussPostMapper.selectDiscussPosts(userId, offset, limit, orderMode);
}
使用缓存读取帖子总数
public int findDiscussPostRows(int userId) {
if (userId == 0) {
return postRowsCache.get(userId);
}
logger.debug("load post rows from DB.");
return discussPostMapper.selectDiscussPostRows(userId);
}
分布式缓存
- 将数据缓存在NoSQL数据库上,跨服务器。
- 常用缓存工具:MemCache、Redis等
多级缓存
- 一级缓存(本地缓存)>二级缓存(分布式缓存)>DB
- 避免缓存雪崩(缓存失效,大量请求直达DB),提高系统的可用性。
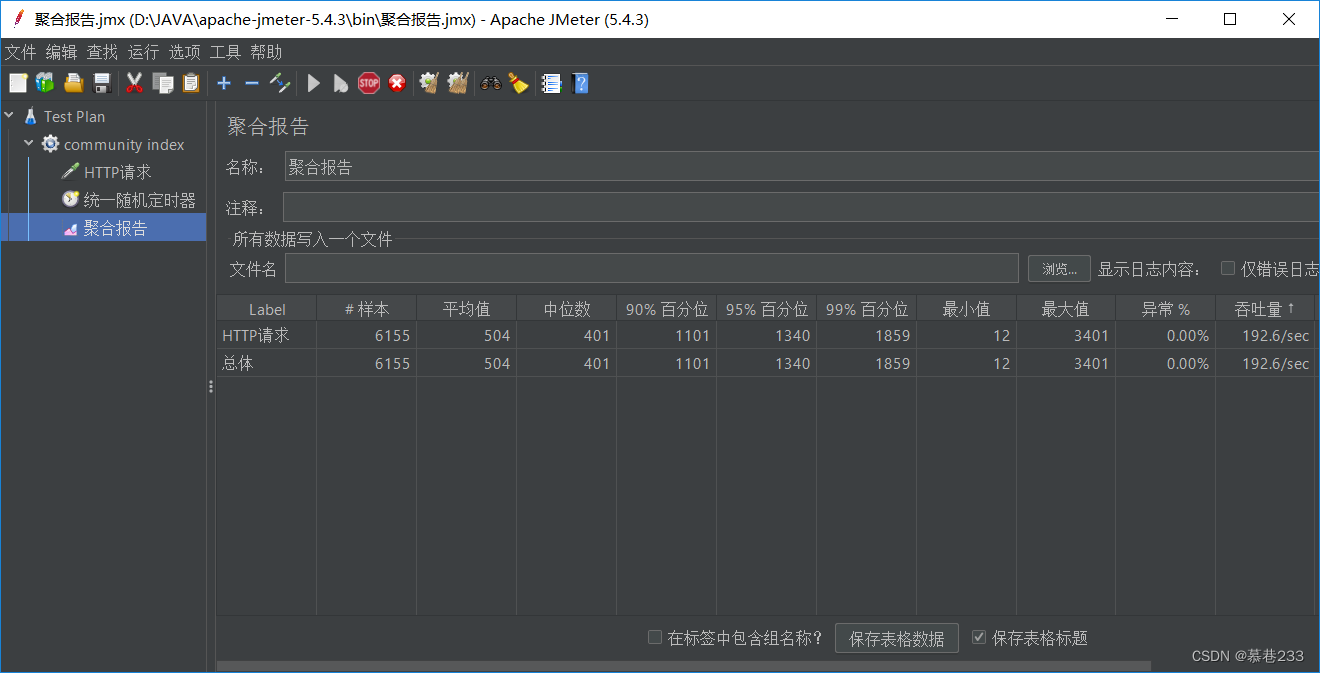
Jmeter性能测试
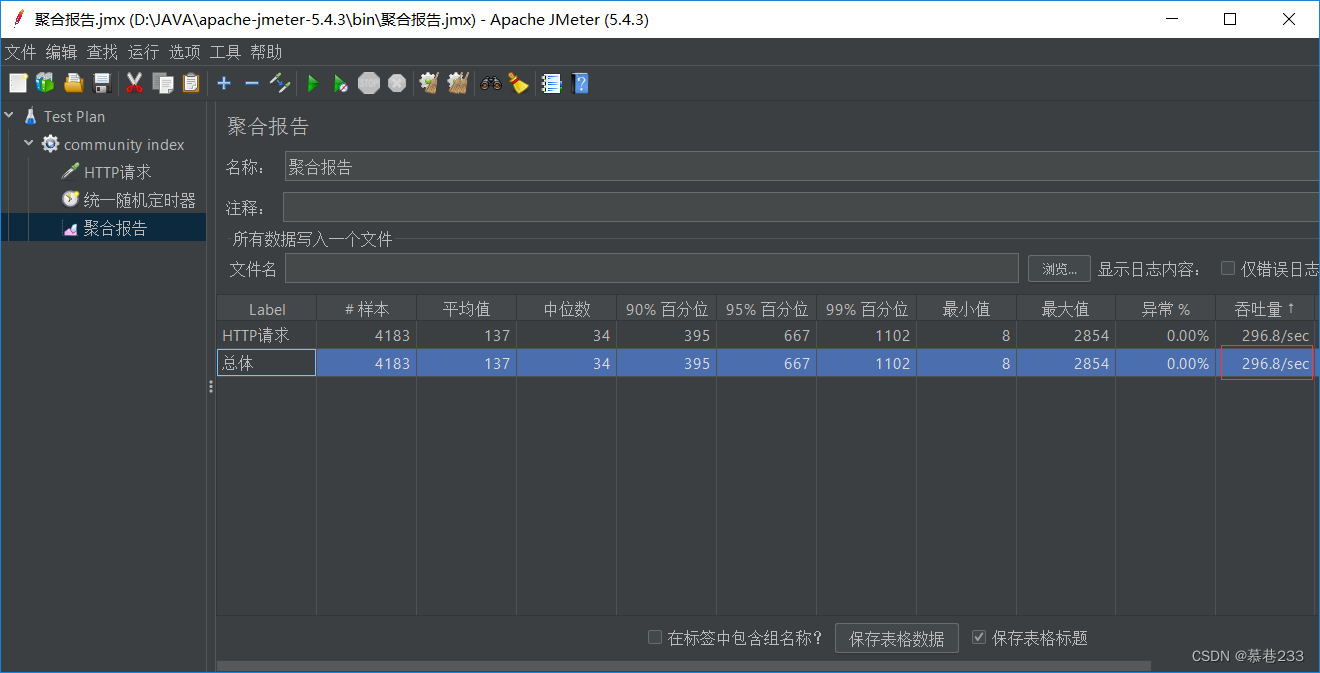
caffeine缓存前吞吐量: 18/sec
caffeine缓存后吞吐量: 296.8/sec
结语
以上对本项目的相对比较重要的功能进行了总结,总体实现了用户模块、登录模块、发帖模块、和点赞关注模块等,部分功能进行了性能优化,使用技术栈比较适中。















 458
458











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









