







一、引文网络的基本概念:

图1-1 准备的引文网络图
该引文网络图的绘制python代码如下,最后两行代码是为了在之后的算法中直接调用该引文网络,把它保存成了.pkl格式的文件:
import networkx as nx
import matplotlib.pyplot as plt
import pickle
# 创建有向图
G = nx.DiGraph()
# 添加路径
path_list = [
['A', 'H', 'J', 'N'],
['A', 'H', 'J', 'L', 'O'],
['B', 'E', 'H', 'J', 'N'],
['B', 'E', 'L', 'O'],
['C', 'E', 'H', 'J', 'N'],
['C', 'E', 'L', 'O'],
['C', 'F', 'I', 'L', 'O'],
['C', 'F', 'I', 'K', 'P'],
['C', 'F', 'K', 'P'],
['C', 'F', 'K', 'M', 'Q'],
['C', 'G', 'M', 'Q'],
['D', 'G', 'M', 'Q']
]
# 构建有向图
for path in path_list:
for i in range(len(path)-1):
G.add_edge(path[i], path[i+1])
# 绘制网络
pos = {
'A': (0, 5),
'B': (0, 4),
'C': (0, 2),
'D': (0, 1),
'H': (2, 5),
'E': (1, 4),
'F': (1, 2),
'G': (1, 1),
'I': (2, 3),
'J': (3, 5),
'L': (4, 4),
'K': (3, 2),
'M': (4, 1),
'N': (5, 5),
'O': (5, 4),
'P': (5, 2),
'Q': (5, 1)
}
plt.figure(figsize=(10, 6))
nx.draw_networkx(G, pos, with_labels=True, node_size=1000, node_color='lightblue', font_size=12, arrowsize=20)
plt.axis('off')
plt.show()
with open('graph_1.pkl', 'wb') as f:
pickle.dump(G, f)二、遍历计数
SPC遍历计数算法:
在引文网络中,构成搜索路径的链路起着至关重要的作用,是知识传递的重要组成部分,因此一系列高权重的链路就构成了一条主路径,而一条链路在引文网络中的重要性可以采用遍历计数来衡量。搜寻路径数 SPC(search pathcount)是指在网络中从源到汇的所有路径中经过此链路的次数。例如,链路C→F的SPC值是5,因为有5条路径C→F→I→L→O,C→F→I→K→P,C→F→I→K→M→Q,C→F→K→P,C→F→K→M→Q 经过链路 C→F。

具体代码:
1.对指定边计算其SPC值:
import networkx as nx
import pickle
# 加载保存的图对象
with open('graph_1.pkl', 'rb') as f:
G = pickle.load(f)
def search_path_count(G, start_node, end_node, edge):
count = 0
for path in nx.all_simple_paths(G, source=start_node, target=end_node):
edge_in_path = list(zip(path, path[1:])) # 获取路径中的所有链路
if edge in edge_in_path:
count += 1
return count
start_nodes = ['A', 'B', 'C', 'D'] # the nodes where the search starts
end_nodes = ['N', 'Q', 'P', 'O'] # the nodes where the search ends
#查找指定边CF
edge = ('C', 'F')
total_count = 0
for start_node in start_nodes:
for end_node in end_nodes:
SPC = search_path_count(G, start_node, end_node, edge)
print(f"SPC from {start_node} to {end_node} through {edge} is {SPC}")
total_count += SPC
print(f"The total SPC through {edge} is {total_count}")2.遍历整个例图,计算每个边的SPC值,并可视化:
import matplotlib.pyplot as plt
import networkx as nx
import pickle
# 加载保存的图对象
with open('graph_1.pkl', 'rb') as f:
G = pickle.load(f)
def search_path_count(G, start_node, end_node, edge):
count = 0
for path in nx.all_simple_paths(G, source=start_node, target=end_node):
edge_in_path = list(zip(path, path[1:])) # 获取路径中的所有链路
if edge in edge_in_path:
count += 1
return count
# 遍历图中的所有边并计算它们的SPC值
all_edges = list(G.edges())
start_nodes = ['A', 'B', 'C', 'D'] # the nodes where the search starts
end_nodes = ['N', 'Q', 'P', 'O'] # the nodes where the search ends
# 创建绘图对象
pos = {
'A': (0, 5),
'B': (0, 4),
'C': (0, 2),
'D': (0, 1),
'H': (2, 5),
'E': (1, 4),
'F': (1, 2),
'G': (1, 1),
'I': (2, 3),
'J': (3, 5),
'L': (4, 4),
'K': (3, 2),
'M': (4, 1),
'N': (5, 5),
'O': (5, 4),
'P': (5, 2),
'Q': (5, 1)
}
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei'] # 指定默认字体
plt.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
# 创建绘图对象
fig, ax = plt.subplots()
nx.draw(G, pos, with_labels=True, node_size=500, node_color='skyblue', font_size=10, ax=ax)
# 绘制边并标记SPC值
for edge in all_edges:
total_count = 0
for start_node in start_nodes:
for end_node in end_nodes:
SPC = search_path_count(G, start_node, end_node, edge)
total_count += SPC
# 添加边的标签(SPC值)
if total_count > 0:
label = total_count
nx.draw_networkx_edge_labels(G, pos, edge_labels={(edge[0], edge[1]): label}, font_color='red', ax=ax)
# 添加标题
plt.title("搜索路径数SPC(search path count)", loc='center', pad=20)
plt.show()
SPLC遍历计数算法:
搜寻路径计数SPLC(search path link count)指从一条链路的尾节点及尾节点的父节点到汇点的所有路径中经过此链路的次数。例如,链路F→I的SPLC值是6,因为有6条路径C→F→I→L→Ο,C→F→I→K→P,C→F→I→K→M→Q,F→I→L→О,F→I→K→P,F→I→>K→M→O 通过链路 F→I,因此链路F→I的 SPLC值为6。这6条路径的起点是链路F→I的尾节点F及尾节点的父节点C。
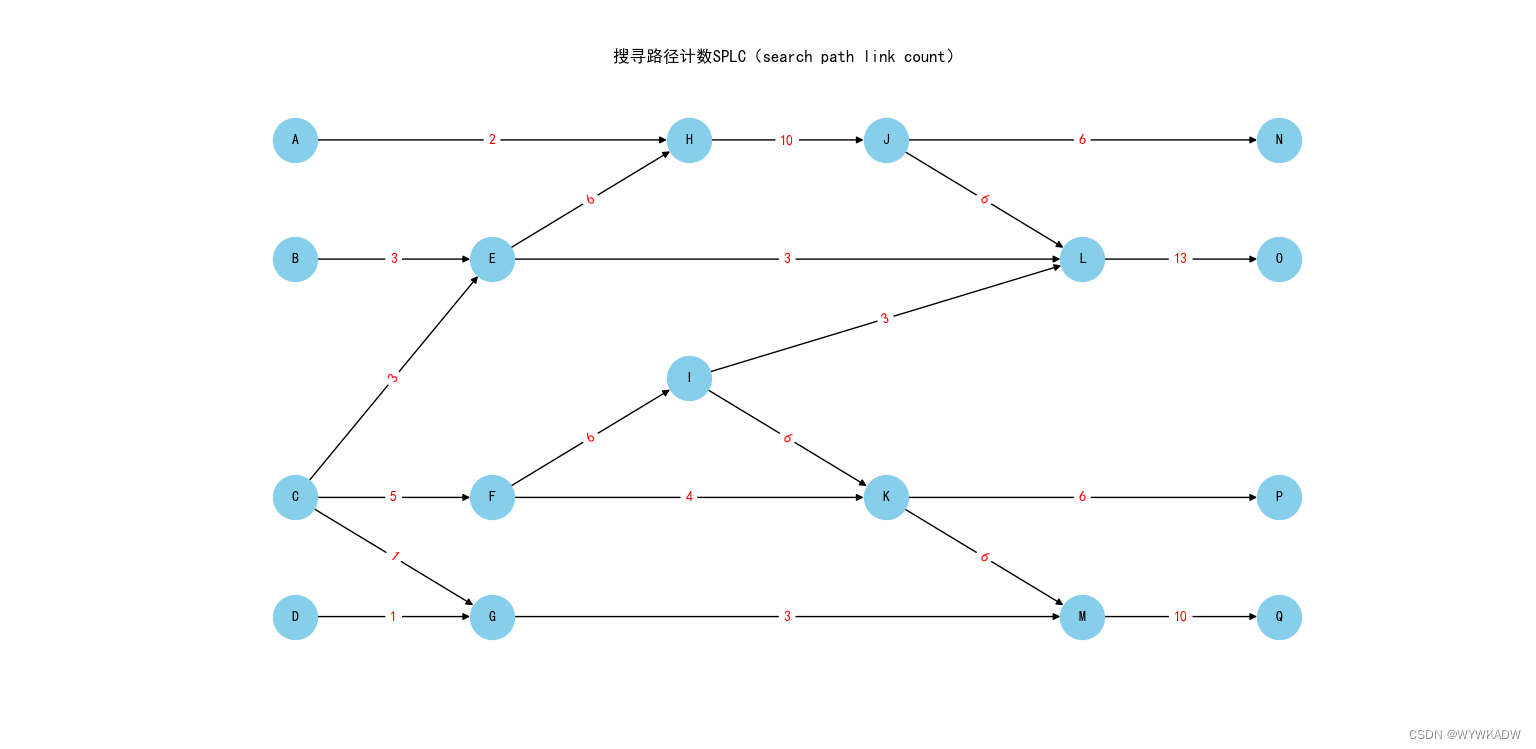 具体代码:
具体代码:
1.对指定边计算其SPLC值:
import networkx as nx
import pickle
def get_parents(G, node):
"""返回一个包含所有可以到达指定节点的节点的集合."""
parents = set()
for start_node in G:
if node_in_path(G, start_node, node):
parents.add(start_node)
print(f"The parent nodes of {node} are {parents}")
return parents
def node_in_path(G, start, end):
"""在图G中检查是否存在一条从'start'到'end'的路径."""
visited_nodes = {start}
nodes_to_visit = [start]
while nodes_to_visit:
current_node = nodes_to_visit.pop(0)
if current_node == end:
return True
for neighbor in G[current_node]:
if neighbor not in visited_nodes:
visited_nodes.add(neighbor)
nodes_to_visit.append(neighbor)
return False
# 深度优先搜索路径
def dfs_paths(G, start, goal, target_edge):
stack = [(start, [start])]
while stack:
(vertex, path) = stack.pop()
for next in set(G.neighbors(vertex)) - set(path):
if next == goal:
new_path = path + [next]
if target_edge in zip(new_path, new_path[1:]):
yield new_path
else:
stack.append((next, path + [next]))
# 创建图并添加节点和边
with open('graph_1.pkl', 'rb') as f:
G = pickle.load(f)
# 尾节点及其所有父节点到汇点的所有路径
tail_node = 'L'
parent_nodes = get_parents(G, tail_node)
target_nodes = parent_nodes.union(set([tail_node]))
target_edge = ('L', 'O')
end_node = ('N','O','P','Q')
splc = 0
for start_node in target_nodes:
for end_node_single in end_node:
for path in dfs_paths(G, start_node, end_node_single, target_edge):
print('Path:', path)
splc += 1
print('Search Path Link Count (SPLC):', splc)2.遍历整个例图,计算每个边的SPLC值,并可视化:
import networkx as nx
import pickle
import matplotlib.pyplot as plt
def get_parents(G, node):
"""返回一个包含所有可以到达指定节点的节点的集合."""
parents = set()
for start_node in G:
if nx.has_path(G, start_node, node):
parents.add(start_node)
print(f"节点 {node} 的父节点为 {parents}")
return parents
# 创建图并添加节点和边
with open('graph_1.pkl', 'rb') as f:
G = pickle.load(f)
# 计算整个网络所有边的SPLC值
splc_dict = {}
end_nodes = ('N', 'O', 'P', 'Q')
for u, v in G.edges():
target_edge = (u, v)
splc = sum(1 for start_node in G.nodes() for end_node in end_nodes
for path in nx.all_simple_paths(G, start_node, end_node)
if target_edge in zip(path, path[1:]))
splc_dict[target_edge] = splc
# 创建绘图对象
pos = {
'A': (0, 5),
'B': (0, 4),
'C': (0, 2),
'D': (0, 1),
'H': (2, 5),
'E': (1, 4),
'F': (1, 2),
'G': (1, 1),
'I': (2, 3),
'J': (3, 5),
'L': (4, 4),
'K': (3, 2),
'M': (4, 1),
'N': (5, 5),
'O': (5, 4),
'P': (5, 2),
'Q': (5, 1)
}
plt.figure(figsize=(12, 8))
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.title("搜寻路径计数SPLC(search path link count)", loc='center', pad=20)
nx.draw(G, pos, with_labels=True, node_size=1000, node_color='skyblue', font_size=10)
edge_labels = {(u, v): splc_dict[(u, v)] for u, v in G.edges()}
nx.draw_networkx_edge_labels(G, pos, edge_labels=edge_labels, font_color='red')
plt.show()
SPNP遍历计数算法:
搜寻路径节点对数 SPNP(search path node pair)是指从一条链路的首节点及首节点的子节点到尾节点及尾节点的父节点的所有路径中经过此链路的次数。例如,链路E-L的SPNP值是6,因为有6条路径的起点是链路-L的尾节点E和E的父节点B、C,终点是链路E→L的首节点L和L 的子节点O。这6条路径为 B→E→L→O,B→E→L,C→E→L→O,E→L→O,E→L,C→E→L。

具体代码:
1.对指定边计算其SPNP值:
import networkx as nx
import pickle
# 加载保存的图对象
with open('graph_1.pkl', 'rb') as f:
G = pickle.load(f)
def dfs_nodepair_paths(G, start_nodes, goal_nodes, target_edge):
spnp_paths = []
for start in start_nodes:
stack = [(start, [start])]
while stack:
(vertex, path) = stack.pop()
for next_node in set(G.neighbors(vertex)) - set(path):
next_path = path + [next_node]
if next_node in goal_nodes:
if target_edge in zip(next_path, next_path[1:]):
spnp_paths.append(next_path)
else:
spnp_paths.append(next_path)
stack.append((next_node, next_path))
return spnp_paths
# 获取节点及其所有子节点
def get_all_descendants(G, node):
descendants = set()
stack = [node]
while stack:
current = stack.pop()
for successor in G.successors(current):
if successor not in descendants:
descendants.add(successor)
stack.append(successor)
return descendants
# 获取节点及其所有父节点
def get_all_ancestors(G, node):
ancestors = set()
stack = [node]
while stack:
current = stack.pop()
for predecessor in G.predecessors(current):
if predecessor not in ancestors:
ancestors.add(predecessor)
stack.append(predecessor)
return ancestors
# 计算链路 E→L 的 SPNP 路径
head_node = 'I'
tail_node = 'F'
head_descendants = get_all_descendants(G, head_node)
tail_ancestors = get_all_ancestors(G, tail_node)
# 包括自己
head_descendants.add(head_node)
tail_ancestors.add(tail_node)
target_edge = ('F', 'I')
spnp_paths = dfs_nodepair_paths(G, tail_ancestors, head_descendants, target_edge)
# 过滤掉不包含目标边的路径
spnp_paths = [path for path in spnp_paths if target_edge in zip(path, path[1:])]
# 打印结果
print('SPNP paths for edge {}:'.format(target_edge))
for path in spnp_paths:
print(' -> '.join(path))
print('SPNP value for edge {}: {}'.format(target_edge, len(spnp_paths)))2.遍历整个例图,计算每个边的SPNP值,并可视化:
import networkx as nx
import pickle
import matplotlib.pyplot as plt
# 加载保存的图对象
with open('graph_1.pkl', 'rb') as f:
G = pickle.load(f)
# 深度优先搜索函数,查找所有路径
def dfs_nodepair_paths(G, start_nodes, goal_nodes, target_edge):
spnp_paths = []
for start in start_nodes:
stack = [(start, [start])]
while stack:
(vertex, path) = stack.pop()
for next_node in set(G.neighbors(vertex)) - set(path):
next_path = path + [next_node]
if next_node in goal_nodes:
spnp_paths.append(next_path)
stack.append((next_node, next_path))
return spnp_paths
# 获取节点及其所有子节点
def get_all_descendants(G, node):
descendants = set()
stack = [node]
while stack:
current = stack.pop()
for successor in G.successors(current):
if successor not in descendants:
descendants.add(successor)
stack.append(successor)
return descendants
# 获取节点及其所有父节点
def get_all_ancestors(G, node):
ancestors = set()
stack = [node]
while stack:
current = stack.pop()
for predecessor in G.predecessors(current):
if predecessor not in ancestors:
ancestors.add(predecessor)
stack.append(predecessor)
return ancestors
# 计算图中所有边的 SPNP 值
def calculate_all_spnp_values(G):
spnp_values = {}
for edge in G.edges():
tail_node, head_node = edge
head_descendants = get_all_descendants(G, head_node)
tail_ancestors = get_all_ancestors(G, tail_node)
# 包括自己
head_descendants.add(head_node)
tail_ancestors.add(tail_node)
# 计算所有路径
spnp_paths = dfs_nodepair_paths(G, tail_ancestors, head_descendants, edge)
# 过滤包含目标边的路径
spnp_paths = [path for path in spnp_paths if edge in zip(path, path[1:])]
# 存储SPNP值
spnp_values[edge] = len(spnp_paths)
return spnp_values
# 获取所有边的SPNP值
all_spnp_values = calculate_all_spnp_values(G)
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 可视化图及SPNP值
def draw_graph_with_spnp(G, spnp_values):
pos = {
'A': (0, 5),
'B': (0, 4),
'C': (0, 2),
'D': (0, 1),
'H': (2, 5),
'E': (1, 4),
'F': (1, 2),
'G': (1, 1),
'I': (2, 3),
'J': (3, 5),
'L': (4, 4),
'K': (3, 2),
'M': (4, 1),
'N': (5, 5),
'O': (5, 4),
'P': (5, 2),
'Q': (5, 1)
}
plt.title("搜寻路径节点对数SPNP(search path node pair)", loc='center', pad=20)
# 绘制节点和边
nx.draw(G, pos, with_labels=True, node_color='lightblue', edge_color='gray', node_size=500, font_size=10)
# 为每条边添加SPNP值
edge_labels = {edge: spnp_values[edge] for edge in G.edges()}
nx.draw_networkx_edge_labels(G, pos, edge_labels=edge_labels, font_color='red')
# 显示图
plt.show()
# 绘制包含SPNP值的图
draw_graph_with_spnp(G, all_spnp_values)本篇文章主要针对代码实现部分进行分享,其余理论部分来自这篇博士论文:
[1]万小萍.基于引文网络分析的知识主路径研究[D].华中师范大学,2020.DOI:10.27159/d.cnki.ghzsu.2020.004048.
论文中关于SPLC和SPNP算法给的例图有个别边计算错误,本文已经纠正。
首图来自论文:
Chen, Liang, et al. "A semantic main path analysis method to identify multiple developmental trajectories." Journal of Informetrics 16.2 (2022): 101281.
下一篇分享关于基于SPC、SPLC、SPNP遍历计数算法的局域搜索主路径和全局搜索主路径相关代码。
















 1341
1341

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











