







Map接口
Collection集合是存放单一元素的容器,在JDK中还有Map集合也是用来存放数据的容器,Map中存放的元素是键值对,称为key-value,其中key不能重复。
在Set集合中,它的底层实现是通过Map对象实现的,Map对象中的value是一个Object对象
private static final Object PRESENT = new Object();Map集合的key不能重复,所以Set集合中的每个元素是唯一的。
此接口取代 Dictionary 类,后者完全是一个抽象类,而不是一个接口。
Map 接口提供三种collection 视图,允许以键集、值集或键-值映射关系集的形式查看某个映射的内容
Map中常用的方法:
int size();//返回键值映射关系的数目。如果值超过了Integer.MAX_VALUE((2^31)-1),就返回Integer_MAX_VALUE;
boolean isEmpty();//判断集合中包含的映射关系是否为空;
boolean containsKey(Object key);//判断是否包含某个key键的映射关系;
boolean containsValue(Object value);//判断是否包含某个value值的映射关系;
V get(Object key);//获得指定的键映射的value,如果存在指定key对应的value,再进一步判断value是否为空,不为空返回value的值,否则返回null;
V put(K key, V value);//将指定的键和指定的值相关联,如果以前key没有value没有关联,则返回null,如果关联过其他value,那么后面的value会覆盖掉之前的value并返回之前的value;
V remove(Object key);//如果存在指定的key值,返回key值对应的value,否则返回null;
void putAll(Map<? extends K, ? extends V> m);//将其他集合中的所有映射关系复制到这个集合中
void clear();//清空这个集合映射中所有的映射关系
Set<K> keySet();//将Map集合中的所有key键存到Set集合中,Set集合具备迭代器,可以通过迭代的方式取出所有的键,再通过get方式取出每一个键对应的value值。set 支持元素移除,通过 Iterator.remove、Set.remove、removeAll、retainAll 和 clear 操作可从映射中移除相应的映射关系。它不支持 add 或 addAll 操作。
Collection<V> values();//将Map集合中所有的键存入到Collection集合中,和Set集合一样,它也可以通过迭代器对数据进行操作,并且Collection集合允许重复。collection 支持元素移除,通过 Iterator.remove、Collection.remove、removeAll、retainAll 和 clear 操作可从映射中移除相应的映射关系。它不支持 add 或 addAll 操作。
Set<Map.Entry<K, V>> entrySet();//将Map中映射关系存入到Set集合中,这个关系的数据类型是Map.Entry。set 支持元素移除,通过 Iterator.remove、Set.remove、removeAll、retainAll 和 clear 操作可从映射中移除相应的映射关系。它不支持 add 或 addAll 操作。
boolean equals(Object o);//比较指定的对象与此映射是否相等。如果给定的对象也是一个映射,并且这两个映射表示相同的映射关系,则返回 true。更确切地讲,如果 m1.entrySet().equals(m2.entrySet()),则两个映射 m1 和 m2 表示相同的映射关系。这可以确保 equals 方法在不同的 Map 接口实现间运行正常。
int hashCode();//返回此映射的哈希码值。映射的哈希码定义为此映射 entrySet() 视图中每个项的哈希码之和。这确保 m1.equals(m2) 对于任意两个映射 m1 和 m2 而言,都意味着 m1.hashCode()==m2.hashCode(),正如 Object.hashCode() 常规协定的要求Map接口的实现类HashMap

HashMap是基于哈希表的Map接口实现,允许使用 null 值和 null 键。(除了非同步和允许使用 null 之外,HashMap 类与 Hashtable 大致相同。)此类不保证映射的顺序(按照一定的规则进行排序,所以可以自定义排序规则,需要重写hashcode()和equals()方法),特别是它不保证该顺序恒久不变,而且HashMap不是同步的。
例1:
HashMap<String, Integer> map = new HashMap<String, Integer>();
map.put("Teemo", 1);
map.put("Fizz", 1);
map.put("Teemo", 2);
Set<String> keySet = map.keySet();
Iterator<String> iterator = keySet.iterator();
while(iterator.hasNext()){
String next = iterator.next();
System.out.println(next+":"+map.get(next));
}输出结果:
Fizz:1
Teemo:2源码分析:
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
static final float DEFAULT_LOAD_FACTOR = 0.75f;
public HashMap() {
this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR);
}创建一个空的HashMap对象,默认初始容量16,加载因子0.75,初始容量只是哈希表在创建时的容量。加载因子 是哈希表在其容量自动增加之前可以达到多满的一种尺度。当哈希表中的条目数超出了加载因子与当前容量的乘积时,则要对该哈希表进行 rehash 操作(即重建内部数据结构),从而哈希表将具有大约两倍的容量。
其他的构造方法:
/*构造一个指定初始容量和加载因子的HashMap集合*/
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
threshold = initialCapacity;
init();
}
/*构造一个指定初始容量,默认加载因子的HashMap集合*/
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
/*构造一个存放Map集合的HashMap*/
public HashMap(Map<? extends K, ? extends V> m) {
this(Math.max((int) (m.size() / DEFAULT_LOAD_FACTOR) + 1,
DEFAULT_INITIAL_CAPACITY), DEFAULT_LOAD_FACTOR);
inflateTable(threshold);
putAllForCreate(m);
}继续看put方法:
static final Entry<?,?>[] EMPTY_TABLE = {};
transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE;//临时的Entry对象
public V put(K key, V value) {
if (table == EMPTY_TABLE) {
inflateTable(threshold);//创建空的哈希表,大小和初始容量和加载因子有关。
}
if (key == null)
return putForNullKey(value);//key为null时,创建空的哈希表。
int hash = hash(key);//获取hash值
int i = indexFor(hash, table.length);//返回hash值和哈希表长度-1相与的结果
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;//返回旧的value值
}
}
modCount++;//集合变化次数加1
addEntry(hash, key, value, i);//插入元素,每次放入数据的时候会根据i的值重新创建哈希表,动态扩充容量。
return null;//新添加的映射关系,返回值为null
}
private static int roundUpToPowerOf2(int number) {
// assert number >= 0 : "number must be non-negative";
int rounded = number >= MAXIMUM_CAPACITY
? MAXIMUM_CAPACITY
: (rounded = Integer.highestOneBit(number)) != 0
? (Integer.bitCount(number) > 1) ? rounded << 1 : rounded
: 1;
return rounded;
}
private void inflateTable(int toSize) {
// Find a power of 2 >= toSize
int capacity = roundUpToPowerOf2(toSize);
threshold = (int) Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1);
table = new Entry[capacity];
initHashSeedAsNeeded(capacity);
}
static int indexFor(int h, int length) {
// assert Integer.bitCount(length) == 1 : "length must be a non-zero power of 2";
return h & (length-1);
}例2:HashMap中的key键存放自定义对象(以学号作为唯一标识)。
public static void main(String[] args) {
HashMap<MidStudent,String> map2 = new HashMap<>();
map2.put(new MidStudent("1001"), "张三");
map2.put(new MidStudent("1002"), "李四");
map2.put(new MidStudent("1003"), "王五");
map2.put(new MidStudent("1001"), "李四");
Set<MidStudent> set = map2.keySet();
Iterator<MidStudent> it = set.iterator();
while(it.hasNext()){
MidStudent key = it.next();
System.out.println(key+":"+map2.get(key));
}
}
class MidStudent {
public MidStudent(){}
public MidStudent(String stuNo){
this.setStuNo(stuNo);
}
private String stuNo;
public String getStuNo() {
return stuNo;
}
public void setStuNo(String stuNo) {
this.stuNo = stuNo;
}
@Override
public String toString() {
// TODO Auto-generated method stub
return this.getStuNo();
}
}输出结果:
1001:张三
1002:李四
1001:李四
1003:王五输出的结果会出现两个学号相同的人,这样key键就不唯一了,所以需要重写MidStudent类的hashcode()方法和equals()方法。这两个方法在HashMap集合中的执行顺序是先执行hashcode()方法,获得一个整型值(和hash值有关),比较整型值,如果整型值不同,则放入集合中,如果相同,再调用equals()方法,根据equals的规则(Object默认的规则是比较两者的地址是否相同)比较是否相等,相等就覆盖原有key键对应的value值。不相等就添加新的映射关系。
hashcode()作用:通过hash值会生成一个整型值(也叫散列值),为了提高对哈希表中数据的操作效率,这个整型值会作为数组的下标存放该对象,hashcode()方法还会返回该整型值判断是否相等,然后再调用equals方法。
equals()作用:所有的对象都是继承自Object类,在Object类中的equals()方法比较的是两个对象之间的引用(地址的比较),可以根据自己的需求,重写equals()方法。
重写hashcode()和equals()方法后:
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + ((stuNo == null) ? 0 : stuNo.hashCode());
return result;
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
MidStudent other = (MidStudent) obj;
if (stuNo == null) {
if (other.stuNo != null)
return false;
} else if (!stuNo.equals(other.stuNo))
return false;
return true;
}输出结果:
1003:王五
1001:李四
1002:李四HashMap集合不可以进行排序。如果要对HashMap进行排序,需要借助ArrayList,在ArrayList集合中存放Map.Entry类型,传入Map集合的映射关系。通过Collections的sort(List list, Comparator
List<Map.Entry<MidStudent,String>> list = new ArrayList<Map.Entry<MidStudent,String>>(map2.entrySet());
Collections.sort(list, new Comparator<Map.Entry<MidStudent,String>>(){
//根据HashMap集合的value值进行升序排列
@Override
public int compare(Entry<MidStudent,String> o1,
Entry<MidStudent,String> o2) {
// TODO Auto-generated method stub
return o1.getValue().compareTo(o2.getValue());
}});
for (Map.Entry<MidStudent,String> mapp:list) {
System.out.println(mapp.getKey()+":"+mapp.getValue());
}输出结果:
1001:李四
1002:李四
1003:王五Map接口的实现类TreeMap
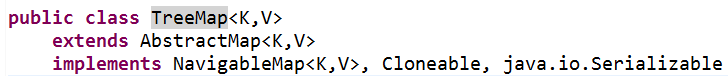
TreeMap是基于红黑树(Red-Black tree)的 NavigableMap 实现。该映射根据其key键的自然顺序(实现Comparable接口,强行对实现它的每个类的对象进行整体排序,这种排序被称为类的自然排序)进行排序,或者根据创建映射时提供的 Comparator 进行排序,具体取决于使用的构造方法。
例1:
public static void main(String[] args) {
TreeMap<String, String> treeMap = new TreeMap<String, String>();
treeMap.put("10001", "zhangsan");
treeMap.put("10004", "lisi");
treeMap.put("10002", "wangwu");
Set<Entry<String,String>> entrySet = treeMap.entrySet();
Iterator<Entry<String, String>> iterator = entrySet.iterator();
while(iterator.hasNext()){
Entry<String, String> next = iterator.next();
System.out.println(next.getKey()+":"+next.getValue());
}
}输出结果:
10001:zhangsan
10002:wangwu
10004:lisi源码分析:
/*使用键的自然顺序构造一个新的、空的树映射。*/
public TreeMap() {
comparator = null;
}另外两个构造方法:
/*构造一个新的、空的树映射,该映射根据给定比较器进行排序。*/
public TreeMap(Comparator<? super K> comparator) {
this.comparator = comparator;
}
/*构造一个与给定映射具有相同映射关系的新的树映射,该映射根据其键的自然顺序 进行排序。*/
public TreeMap(Map<? extends K, ? extends V> m) {
comparator = null;
putAll(m);
}
/*构造一个与指定有序映射具有相同映射关系和相同排序顺序的新的树映射。*/
public TreeMap(SortedMap<K, ? extends V> m) {
comparator = m.comparator();
try {
buildFromSorted(m.size(), m.entrySet().iterator(), null, null);
} catch (java.io.IOException cannotHappen) {
} catch (ClassNotFoundException cannotHappen) {
}
}分析put方法:
public V put(K key, V value) {
Entry<K,V> t = root;//空的Entry对象
if (t == null) {
compare(key, key); // type (and possibly null) check
root = new Entry<>(key, value, null);
size = 1;
modCount++;
return null;
}
int cmp;
Entry<K,V> parent;
// split comparator and comparable paths
Comparator<? super K> cpr = comparator;//传入的比较器
if (cpr != null) {//自然排序
do {
parent = t;
cmp = cpr.compare(key, t.key);
/*值小的放左边,大的放右边*/
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else
return t.setValue(value);//相等则覆盖该value值
} while (t != null);
}
else {//传入比较器
if (key == null)
throw new NullPointerException();
Comparable<? super K> k = (Comparable<? super K>) key;
do {/*根据自定义的规则比较大小*/
parent = t;
cmp = k.compareTo(t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else
return t.setValue(value);
} while (t != null);
}
Entry<K,V> e = new Entry<>(key, value, parent);
if (cmp < 0)
parent.left = e;
else
parent.right = e;
fixAfterInsertion(e);
size++;
modCount++;
return null;
}
/*Entry类*/
static final class Entry<K,V> implements Map.Entry<K,V> {
K key;
V value;
Entry<K,V> left = null;
Entry<K,V> right = null;
Entry<K,V> parent;
boolean color = BLACK;//结点颜色,默认黑色
Entry(K key, V value, Entry<K,V> parent) {
this.key = key;
this.value = value;
this.parent = parent;
}
/*插入新的结点后进行修正操作,使得新的结构仍然是一颗红黑树*/
private void fixAfterInsertion(Entry<K,V> x) {
x.color = RED;
while (x != null && x != root && x.parent.color == RED) {
if (parentOf(x) == leftOf(parentOf(parentOf(x)))) {
Entry<K,V> y = rightOf(parentOf(parentOf(x)));
if (colorOf(y) == RED) {
setColor(parentOf(x), BLACK);
setColor(y, BLACK);
setColor(parentOf(parentOf(x)), RED);
x = parentOf(parentOf(x));
} else {
if (x == rightOf(parentOf(x))) {
x = parentOf(x);
rotateLeft(x);
}
setColor(parentOf(x), BLACK);
setColor(parentOf(parentOf(x)), RED);
rotateRight(parentOf(parentOf(x)));
}
} else {
Entry<K,V> y = leftOf(parentOf(parentOf(x)));
if (colorOf(y) == RED) {
setColor(parentOf(x), BLACK);
setColor(y, BLACK);
setColor(parentOf(parentOf(x)), RED);
x = parentOf(parentOf(x));
} else {
if (x == leftOf(parentOf(x))) {
x = parentOf(x);
rotateRight(x);
}
setColor(parentOf(x), BLACK);
setColor(parentOf(parentOf(x)), RED);
rotateLeft(parentOf(parentOf(x)));
}
}
}
root.color = BLACK;
}
}取出集合中的数据:
TreeMap集合没有实现keySet()方法,只能使用EntrySet()将映射关系存储到Entry中,然后通过迭代器取出。
















 778
778

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











