







XPath表达式
XPath 全称XML Path Language 即XML路劲语言,是一门在xml文档中查找数据信息的语言。最初是用来搜寻XML文档的,但同样适用于HTML文档,所以在做爬虫的时候完全可由XPath提取信息。

1. lxml模块安装
lxml是一个HTML/XML的解析器,主要的功能是如何解析和提取HTML/XML数据。
lxml和正则一样,也是用C实现的,是一款高性能的解析器,不过在Python中属于是第三方模块,需要进行安装。 pip install lxml
2. 获取特殊的HTML
from lxml import etree
# 从lxml中导入etree模块
text = '''
<div>
<ul>
<li calss = "item01">这是一个li标签</a></li>
<li calss = "item02"><a href="https://www.baidu.com/">小张</a></li>
<li calss = "item03"><a href="https://www.baidu.com/">小王</a></li>
<li calss = "item04">
<span>小王</span>
</li>
</ul>
</div>
'''
html = etree.HTML(text) # 这个对象是特殊的html
'''
将用来解析字符串格式的HTML文档对象转变为特殊的HTML文档,
特殊包含3处:
1. 会额外添加一些标签(补充标签)
2. 转化为二进制字节码(中文转化为二进制字节码)
3. 对格式进行处理(将格式进行对其)
'''
result = etree.tostring(html,encoding="utf-8").decode()
print(result)
# 返回输出
<html><body><div>
<ul>
<li calss="item01">这是一个li标签</li>
<li calss="item02"><a href="https://www.baidu.com/">小张</a></li>
<li calss="item03"><a href="https://www.baidu.com/">小王</a></li>
<li calss="item04">
<span>小王</span>
</li>
</ul>
</div>
</body></html>3. 获取标签内容
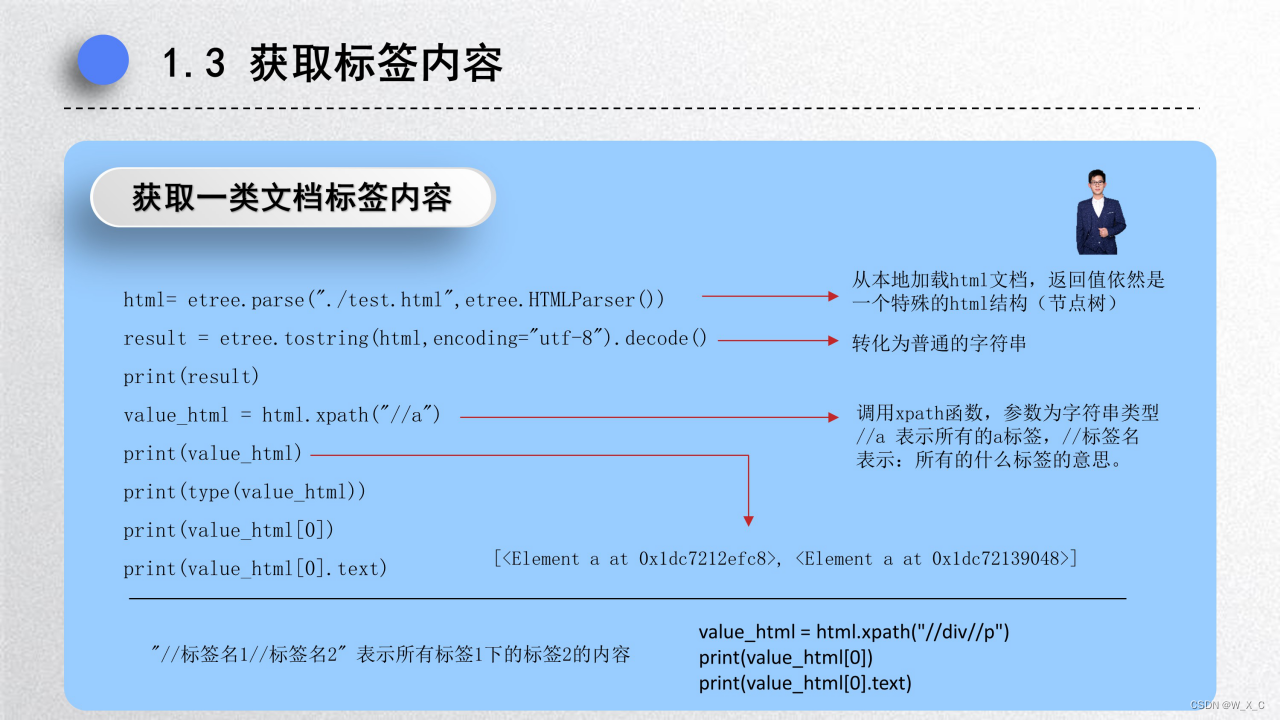

3. 获取标签属性

from lxml import etree
html = etree.parse("./test.html", etree.HTMLParser())
result = etree.tostring(html, encoding="utf-8").decode()
# print(result)
value_html = html.xpath("//div")
#print(value_html)
print(type(value_html))
print(value_html[0])
print(value_html[0].text)
value_html = html.xpath("//div//p")
print(value_html[0])
print(value_html[0].text)
value_html = html.xpath("//div/span[@class='span01']")
print(value_html[0])
print(value_html[0].text)
value_html = html.xpath("//div/span/@class")
print(value_html)
value_html = html.xpath("//a/@href")
print(value_html)注:源自51CTO课堂 Python网络爬虫















 2454
2454











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









