







目录
Python中数据类型大致可分为基本数据类型和组合数据类型

一、基本数据类型
1、数值型
Python语言提供3种数字类型:整数、浮点数和复数,分别对应数学中的整数、实数和复数。
表示:
- 整数类型:1010, 99,-217;
- 浮点数类型,也就是小数:0.0 -77. -2.17 .23,96e4, 4.3e-3;
- 复数类型:12.3+4j -5.6+0.7j
操作:
- 运算符:+、-、*、/、 //、%、 **;
- 函数:abs(), round(), pow(), sqrt(), floor(),
- ……
2、字符型
表示:加引号 ' ' " " ''' '''
操作:
- 运算符:+、*、[](索引与切片);
- 函数:len(), ord(), chr(), ……;
- 方法:s.strip(), s.count(), s.format(), s.replace(),……
3、逻辑型
表示:逻辑型常量仅有两个数据(True、False)
操作:逻辑型数据一般用作if、while之后的条件,比较运算(运算符:>、<、>=、<=、==、!=)的结果是逻辑型数据。运算符:AND、OR、NOT
二、组合数据类型
计算机不仅对单个变量表示的数据进行处理,更多情况,计算机需要对一组数据进行批量处理。比如:
- 给定一组单词{python, data, function, list, loop},计算每个单词的长度;
- 给定一个学院学生信息,统计一下男女生比例;
- 一次实验产生了很多组数据,对这些大量数据进行分析;
组合数据类型能够将多个同类型或不同类型的数据组织起来,通过单一的表示使数据操作更有序更容易。
根据数据之间的关系,组合数据类型可以分为三类:序列类型、集合类型和映射类型。
- 序列类型是一个元素向量,元素之间存在先后关系,通过序号访问,元素之间不排他。
- 集合类型是一个元素集合,元素之间无序,相同元素在集合中唯一存在。
- 映射类型是“键-值”数据项的集合,每个元素是一个键值对:key:value

三、序列类型
序列类型包括若干个元素的组合,元素之间存在顺序关系,可以通过序号访问,序列中可以有重复元素。序列类型有:str(字符串)、tuple(元组)和list(列表)

- 字符串:可以看做字符的序列,序列元素为字符。由于字符串类型十分常用且单一字符串只表达一个含义也被看做是基本数据类型。
- 元组:任意元素的序列,序列元素可以是任意类型的数据,甚至也可以是组合数据类型;元组一旦生产是固定的,数据元素不能增、删、改
- 列表:任意元素的序列,序列元素可以是任意类型的数据,与元组的不同,列表元素可以增、删、改,使用也更灵活
1.序列类型的表示方式
- 字符串:用引号(’’、 “ ” 、''' ''')引起0个或多个字符 ‘a’、“Hello”、“It’s sunny“、 “”、 “ ”
- 元组:用小括号(圆括号)括起若干个数据元素,元素之间用逗号隔开。在没有歧义的情况下,小括号可以省略(建议尽量不要省略)
creature = "cat", "dog", "tiger", "human"
(“red”, 0x001100, “blue”, creature)、 (‘red’, 4352, ‘blue’, (‘cat’, ‘dog’, ‘tiger’, ‘human’))
- 列表:用中括号(方括号)括起若干个数据元素,元素之间用逗号隔开。
[1, 2, 3]、[425, 'BIT', [10, 'CS'], 425]
2.序列类型的基本操作
序列类型的元素可以通过序号访问,有两种序号体系:正向递增序号和反向递减序号

序列类型有12个通用的操作符和函数
| 操作符 | 描述 |
| x in s | 如果x是s的元素,返回True,否则返回False |
| x not in s | 如果x不是s的元素,返回True,否则返回False |
| s + t | 连接s和t |
| s * n 或 n * s | 将序列s复制n次 |
| s[i] | 索引,返回序列的第i个元素 |
| s[i: j] | 分片,返回包含序列s第i到j个元素的子序列(不包含第j个元素) |
| s[i: j: k] | 步骤分片,返回包含序列s第i到j个元素以k为步数的子序列 |
| len(s) | 序列s的元素个数(长度) |
| min(s) | 序列s中的最小元素 |
| max(s) | 序列s中的最大元素 |
| s.index(x[, i[, j]]) | 序列s中从i开始到j位置中第一次出现元素x的位置 |
| s.count(x) | 序列s中出现x的总次数 |
四、集合类型
集合用大括号( {} ) 表示 , 集合中元素不可重复 ,元素类型只能是固定数据类型 ,例如:整数、浮点数、字符串、元组等 ,列表、字典和集合类型本身都是可变数据类型 ,不能作为集合的元素出现。由于集合是无序组合 ,它没有索引和位置的概念 ,不能分片 ,集合中元素可以动态增加或删除。
>>>S = {425, "BIT", (10, "CS"), 424}>>>S{424, 425, (10, 'CS'), 'BIT'}>>>T = {425, "BIT", (10, "CS"), 424, 425, "BIT"}>>>T{424, 425, (10, 'CS'), 'BIT'}
由于集合元素是无序的 ,集合的打印效果与定义顺序可以 不一致。 由于集合元素独一无二 ,使用集合类型能够过滤掉重复元素。set(x)函数可以用于生成集合。
>>>W = set(‘apple’){'e', 'p', 'a', 'l'}>>>V = set(( "cat", "dog", "tiger", "human" )){'cat', 'human', 'dog', 'tiger'}
【例】文件独特行数
统计附件文件中与其他任何其他行都不同的行的数量,即独特行的数量。
f = open("latex.log")
ls = f.readlines()
s = set(ls)
for i in s:
ls.remove(i)#ls.remove()可以去掉某一个元素,如果该行是独特行,去掉该元素后将不在集合t中出现。
t = set(ls)
print("共{}独特行".format(len(s)-len(t)))
集合类型有10个操作符
| 操作符 | 描述 |
| S – T 或 S.difference(T) | 返回一个新集合,包括在集合S中但不在集合T中的元 素 |
| S-=T或S.difference_update(T) | 更新集合S,包括在集合S中但不在集合T中的元素 |
| S & T或S.intersection(T) | 返回一个新集合,包括同时在集合S和T中的元素 |
| S&=T或S.intersection_update(T) | 更新集合S,包括同时在集合S和T中的元素。 |
| S^T或s.symmetric_difference(T) | 返回一个新集合,包括集合S和T中元素,但不包括同时在其中的元素 |
| S=^T或s.symmetric_difference_update(T) | 更新集合S,包括集合S和T中元素,但不包括同时在其中的元素 |
| S|T或S.union(T) | 返回一个新集合,包括集合S和T中所有元素 |
| S=|T或S.update(T) | 更新集合S,包括集合S和T中所有元素 |
| S<=T或S.issubset(T) | 如果S与T相同或S是T的子集,返回True,否则返回False,可以用S<T判断S是否是T的真子集 |
| S>=T或S.issuperset(T) | 如果S与T相同或S是T的超集,返回True,否则返回False,可以用S>T判断S是否是T的真超集 |

# coding=utf-8
Joe = {"玩游戏", "看足球", "购物", "听音乐"}
Tom = {"打篮球", "玩游戏", "购物", "角色扮演"}
print("共同爱好:{}".format(Joe & Tom))
print("Joe有而Tom没有的爱好{}".format(Joe-Tom))
print("Tom有而Joe没有的爱好{}".format(Tom-Joe))
运行结果:

集合类型有10个操作函数或方法
| 函数或方法 | 描述 |
| S.add(x) | 如果数据项x不在集合S中, 将x增加到s(集合中元素不可重复) |
| S.clear() | 移除S中所有数据项 |
| S.copy() | 返回集合S的一个拷贝 |
| S.pop() | 随机返回集合S中的一个元素, 如果S为空, 产生KeyError异常 |
| S.discard(x) | 如果x在集合S中,移除该元素;如果x不在, 不报错 |
| S.remove(x) | 如果x在集合S中,移除该元素;不在产生KeyError异常 |
| S.isdisjoint(T) | 如果集合S与T没有相同元素, 返回True |
| len(S) | 返回集合S元素个数 |
| x in S | 如果x是S的元素,返回True,否则返回False |
| x not in S | 如果x不是S的元素, 返回True,否则返回False |
>>> "BIT" in {"PYTHON", "BIT", 123, "GOOD"} # 成员关系测试True>>>tup = ( "PYTHON", "BIT", 123, "GOOD", 123) # 元素去重>>>set(tup){123, 'GOOD', 'BIT', 'PYTHON'}>>>newtup = tuple(set(tup)–{ 'PYTHON' }) # 去重同时删除数据项('GOOD', 123, 'BIT')
五、映射类型

六、查看数据类型
前面我们介绍了很多数据类型,那么我们如何查看数据类型呢?
这里我们可以使用Python内置的type()函数来查看数据的类型,如:

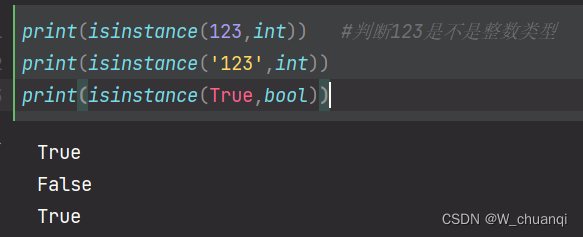
也可以使用 isinstance 来判断数据是不是指定类型:
















 4515
4515











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











