







📋 个人简介
💖 作者简介:大家好,我是W_chuanqi,一个编程爱好者
📙 个人主页:W_chaunqi
😀 支持我:点赞👍+收藏⭐️+留言📝
💬 愿你我共勉:“若身在泥潭,心也在泥潭,则满眼望去均是泥潭;若身在泥潭,而心系鲲鹏,则能见九万里天地。”✨✨✨

parsel 的使用
1.简介
parsel这个库可以解析 HTML 和XML,并支持使用 XPath 和 CSS 选择器对内容进行提取和修改,同时还融合了正则表达式的提取功能。parsel灵活且强大,同时也是 Python 最流行的爬虫框架 Scrapy的底层支持。
2.准备工作
在开始之前,请确保已经安装好了 parsel 库,如尚未安装,使用 pip3 进行安装即可:
pip install parsel
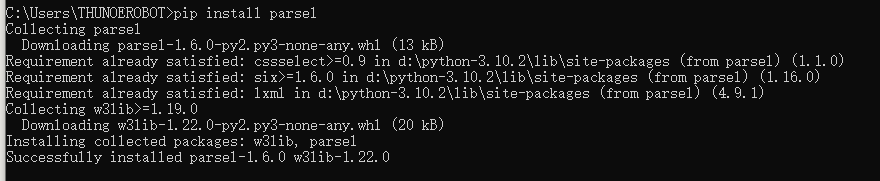
安装好之后,我们便可以开始本节的学习了。
3.初始化
首先,声明 html 变量如下:
html = '''
<div>
<ul>
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
'''
接着,一般我们会用 parsel 库里的 Selector 这个类声明一个 Selector 对象,写法如下:
from parsel import Selector
selector = Selector(text=html)
这样我们就创建了一个 Selector 对象,向其中传人 text 参数,内容就是刚才声明的 HTML 字符串,然后把创建的对象赋值为 selector 变量。
有了 Selector 对象之后,我们可以使用 css 和 xpath 方法分别传入 CSS 选择器和 XPath 进行内容提取,例如这里我们要提取 class 包含 item-0 的节点,写法如下:
items = selector.css('.item-0')
print(len(items), type(items), items)
items2 = selector.xpath('//li[contains(@class,"item-0")]')
print(len(items2), type(items), items2)
先是用 css 方法进行节点提取,然后输出了提取结果的长度和内容。xpath方法也是一样的写法,运行结果如下:

可以看到两个结果都是 SelectorList 对象,这其实是一个可迭代对象。用 len 方法获取了结果的长度,都是 3。另外,提取结果代表的节点也是一样的,都是第 1、3、5 个 1i 节点,每个节点还是以Selector 对象的形式返回,其中每个 Selector 对象的 data 属性里包含对应提取节点的 HTML 代码。
这里大家可能会有个疑问,第一次不是用 css 方法提取的节点吗?为什么结果中的 Selector 对象输出的是 xpath 属性而不是 css 属性?这是因为在 css 方法的背后,我们传人的 CSS 选择器首先是被转成了 XPath,真正用于节点提取的是 XPath。其中 CSS 选择器转换为 XPath 的过程是由底层的 csselect这个库实现的,例如.item-0 这个 CSS 选择器转换为 XPath 的结果就是 descendant-or-self:😗[@class and contains(concat(‘’, normalize-space(@class),‘’),‘item-0’)],因此输出的 Selector 对象就有了 xpath 属性。不过不用担心,这个对提取结果是没有影响的,仅仅是换了一个表示方法而已。
4.提取文本
既然刚才提取的结果是一个可迭代对象 Selectorlist,那么要想获取提取到的所有 1i 节点的文本内容,就要对结果进行遍历了,写法如下:
from parsel import Selector
html = '''
<div>
<ul>
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
'''
selector = Selector(text=html)
items = selector.css('.item-0')
for item in items:
text = item.xpath('.//text()').get()
print(text)
这里我们遍历了 items 变量,并赋值为 item,于是这里的 item 变成了一个 Selector 对象,此时又可以调用其 css 或 xpath 方法进行内容提取了。这里我们是用.//text()这个 XPath 写法提取了当前节点的所有内容,此时如果不再调用其他方法,那么返回结果应该依然为Selector构成的可迭代对象Selectorlist。Selectorlist 中有一个 get方法,可以将 SelectorList 包含的 Selector 对象中的内容提取出来。
运行结果如下:
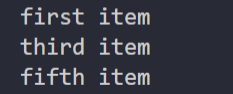
get方法的作用是从 Solectortuist 里面提取第一个Selector对象,然后输出此中的结果。
我们再看一个实例:
from parsel import Selector
html = '''
<div>
<ul>
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
'''
selector = Selector(text=html)
result = selector.xpath('//li[contains(@class,"item-0")]//text()').get()
print(result)
输出结果如下:

这里我们使用 //li[contains(@class,“item-0”)]//text() 选取了所有 class 包含item-0的节点的文本内容。准确来说,返回结果 SelectorList 应该对应三个li 对象,而这里 get 方法仅仅返回了第一个li 对象的文本内容。因为它其实只会提取第一个Selector对象的结果。
那有没有能够提取所有 Selector 对应内容的方法呢?有,那就是 getall 方法。所以如果要提取所有对应的 li 节点的文本内容,写法可以改写为如下内容:
result = selector.xpath('//li[contains(@class,"item-0")]//text()').getall()
print(result)
输出结果如下:

这时候,我们得到的就是列表类型的结果,其中的每一项和 Selector 对象是——对应的。因此,如果要提取 Selectorlist 里面对应的结果,可以使用 get 或 getall 方法,前者会获取第一个Selector 对象里面的内容,后者会依次获取每个 Selector 对象对应的结果。
另外在上述案例中,如果把 xpath 方法改写成css 方法,可以这么实现:
result = selector.css('.item-0 *::text').getall()
print(result)
这里*用来提取所有子节点(包括纯文本节点),提取文本需要再加上::text,最终的运行结果和上面是一样的。
到这里,我们就简单了解了提取文本的方法。
5.提取属性
刚才我们演示了 HTML 中的文本提取,直接在 XPath 中加入 //text()即可,那提取属性怎么实现呢?方式是类似的,也是直接在 XPath 或者 CSS 选择器中表示出来就可以了。
例如我们提取第三个 li 节点内部的a节点的 href 属性,写法如下:
from parsel import Selector
html = '''
<div>
<ul>
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
'''
selector = Selector(text=html)
result = selector.css('.item-0.active a::attr(href)').get()
print(result)
result = selector.xpath(
'//li[contains(@class,"item-0") and contains(@class,"active")]/a/@href').get()
print(result)
这里我们实现了两种写法,分别用css 和 xpath 方法实现。我们以同时包含 item-0 和 active两个class 为依据,来选取第三个 li 节点,然后进一步选取了里面的 a 节点。对于 CSS 选择器,选取属性需要加 ::attr(),并传人对应的属性各称才可选取;对于 XPath,直接用/@再加属性名称即可选取。最后统一用get 方法提取结果。
运行结果如下:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-lgNFIv53-1658841983527)(https://s2.loli.net/2022/07/23/UrVHAl5iMGvIzNe.png)]
可以看到两种方法都正确提取到了对应的 href 属性。
6.正则提取
除了常用的 css 和xpath 方法,Selector 对象还提供了正则表达式提取方法,我们用一个实例来了解下:
from parsel import Selector
html = '''
<div>
<ul>
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
'''
selector = Selector(text=html)
result = selector.css('.item-0').re('link.*')
print(result)
运行结果如下:

可以看到,re 方法在这里遍历了所有提取到的 Selector 对象,然后根据传入的正则表达式,查找出符合规则的节点源码并以列表形式返回。
当然,如果在调用 css 方法时,已经提取了进一步的结果,例如提取了节点文本值,那么 re 方法就只会针对节点文本值进行提取:
from parsel import Selector
html = '''
<div>
<ul>
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
'''
selector = Selector(text=html)
result = selector.css('.item-0 *::text').re('.*item')
print(result)
运行结果如下:

我们也可以利用 re_first 方法来提取第一个符合规则的结果:
from parsel import Selector
html = '''
<div>
<ul>
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
'''
selector = Selector(text=html)
result = selector.css('.item-0').re_first('<span class="bold">(.*?)</span>')
print(result)
这里调用了 re_ first 方法,提取的是被 Span 标签包含的文本值,提取结果用小括号括起来表示一个提取分组,最后输出的结果就是小括号包围的部分,运行结果如下:

通过这几个例子,我们知道了正则匹配的一些使用方法,re对应多个结果,re_first对应单个结果,在不同情况下可以选择合适的方法进行提取。















 2037
2037











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











