







基本数据管理
1.创建新变量
(1)$符号
> mydata<-data.frame(x1=c(2,2,6,4),x2=c(3,4,5,8))
> mydata$sumx<-mydata$x1+mydata$x2
> mydata$meanx<-(mydata$x1+mydata$x2)/2
> mydata
x1 x2 sumx meanx
1 2 3 5 2.5
2 2 4 6 3.0
3 6 5 11 5.5
4 4 8 12 6.0
- $引用某个数据框中的某列用
- $ 符号访问对象不是非常的方便
- 我们希望直接调用列表或者数据框的分量,可以通过它们的名字。而且这种调用是暂时性的,没有必要每次都显式的引用列表名字。
(2)attach函数
> mydata<-data.frame(x1=c(2,2,6,4),x2=c(3,4,5,8))
> attach(mydata)
> mydata$sumx<-x1+x2
> mydata$meanx<-(x1+x2)/2
> detach(mydata)
> mydata
x1 x2 sumx meanx
1 2 3 5 2.5
2 2 4 6 3.0
3 6 5 11 5.5
4 4 8 12 6.0
(3)transform函数
transform()函数
transform(`_data`, ...)
参数说明:
| 属性 | 功能 |
|---|---|
_data | 要被转换的数据 |
| … | 要新增加的属性 |
示例:
> mydata<-data.frame(x1=c(2,2,6,4),x2=c(3,4,5,8))
> mydata<-transform(mydata,sumx=x1+x2,meanx=(x1+x2)/2)
> mydata
x1 x2 sumx meanx
1 2 3 5 2.5
2 2 4 6 3.0
3 6 5 11 5.5
4 4 8 12 6.0
注意事项:
- transform()函数可以为原数据框添加新列,改变原列值,通过赋值NULL删除列变量
- transform()只能修改data.frame类型

2.变量的重编码
在分析数据时我们经常会遇到将变量值转换成其他的值的情况(如:将连续变量转成分类变量),这时我们就需要我们对原有数据进行重新编码。重编码即根据某一个变量或者多个变量的现有值通过逻辑运算符创建新值的过程。
| 逻辑运算符 | 描述 |
|---|---|
| < | 小于 |
| <= | 小于或等于 |
| > | 大于 |
| >= | 大于或等于 |
| == | 严格等于 |
| != | 不等于 |
| !x | 非x |
| x|yx | x或y |
| x&y | x和y |
| isTRUE(x) | 测试x是否为TRUE |
(1)使用逻辑判断式编码
> x <- c(4,12,50,18,50,22,23,46,8,46,36,18,10,14,35,48,23,17,29,30)
> x2<-1*(x<=10)+2*(x>10&x<=20)+3*(x>20)
> x2
[1] 1 2 3 2 3 3 3 3 1 3 3 2 1 2 3 3 3 2 3 3
#将上面的连续型变量x按照数值10和20分成3组,新的组名称为1,2,3
> labels<-c("A","B","C")
> x3<-labels[x2]
> x3
[1] "A" "B" "C" "B" "C" "C" "C" "C" "A" "C" "C" "B" "A" "B" "C" "C" "C" "B" "C" "C"
#将上述变量的数字编码改为字符编码
#利用变量x2中的数值作为另一个变量的位置信息这样不同的值就取到另一个字符变量不同的变量
逻辑型变量与数值型数据进行算术运算
> income <- c(130065,82961,33076,123028,108945,173466,17477)
> income
[1] 130065 82961 33076 123028 108945 173466 17477
> newcodes <- c("低收入","中等收入","高收入")
> index=1*(income < 20000) + 2*(income >=20000 & income <= 60000) + 3*(income >60000)
> income <- newcodes[index]
> income
[1] "高收入" "高收入" "中等收入" "高收入" "高收入" "高收入" "低收入"
根据年收入进行分组:<20000,编码为1,20000-60000,编码为2,否则为3
(2)使用ifelse函数进行重编码
基本语法:ifelse(逻辑判断式,TRUE - 表达式,FALSE-表达式)
实例1:
> x <- c(4,12,50,18,50,22,23,46,8,46,36,18,10,14,35,48,23,17,29,30)
> x2<-ifelse(x<=30,1,2)
> x2
[1] 1 1 2 1 2 1 1 2 1 2 2 1 1 1 2 2 1 1 1 1
实例2:
#搭配%in%运算符,将"A","C"重编码为"Group1","B","D"重编码为Group2
> y <- c("B","A","C","C","B","A","D","B","C","D")
> y2 <- ifelse(y %in% c("A","C"),"Group1","Group2")
> y2
[1] "Group2" "Group1" "Group1" "Group1" "Group2" "Group1" "Group2" "Group2" "Group1" "Group2"
补充%in%
%in%相当于match()函数的一个缩写。用来判断一个数组或矩阵是否包含在另一个数组或矩阵里。
#判断前面一个向量内的元素是否在后面一个向量中,返回布尔值 > a<-c(1,3,5,7,9,11,13) > b<-c(1,2,3,4,5) > a%in%b [1] TRUE TRUE TRUE FALSE FALSE FALSE FALSE #提取向量b中包含向量a中元素的值并保存在a1中 > a1<-a[a%in%b] > a1 [1] 1 3 5
实例3:
#当编码成三个或者三个以上的组时需要多次使用ifelse函数(相当于Excel中的嵌套if函数)
#将x按照10与20两个分隔点分成1,2,3三组
x <- c(4,12,50,18,50,22,23,46,8,46,36,18,10,14,35,48,23,17,29,30)
x2 <- ifelse(x<=10,1,ifelse(x>20,3,2))
x2
[1] 1 2 3 2 3 3 3 3 1 3 3 2 1 2 3 3 3 2 3 3
(3)使用cut函数进行重编码 (数值数据类别化)
cut函数可以根据我们设置的分割点(breaks)将数据重编码,将一个数值向量变量转换为分组形态的factors变量。
基本语法:
cut(x,breaks,labels,include.lowest=F,right=T)
参数说明:
| 参数 | 说明 |
|---|---|
| x | x为数值向量 |
| breaks | breaks为分割点信息。若breaks为向量,则根据向量中的数字进行分割。若breaks为大于1正整数k,则将x分成均等的k组。 |
| labels | labels为分割后各组的名称,若为null,则输出数字向量,否则输出factor变量。 |
| include.lowest | include.lowest=FALSE表示分割时不含各区间端点的最小值。 |
| right | right=T表示各区间为左端open,右端closed的区间 |
实例1 使用cut函数将x向量依照0、10、20,max(x)分成3组
> x<-round(runif(10,0,50),0)
> x
[1] 39 14 14 30 18 38 21 46 5 33
> x1<-cut(x,breaks = c(0,10,20,max(x)))
> x1
[1] (20,46] (10,20] (10,20] (20,46] (10,20] (20,46] (20,46] (20,46] (0,10] (20,46]
Levels: (0,10] (10,20] (20,46]
设置标签
> x<-round(runif(10,0,50),0)
> x
[1] 39 14 14 30 18 38 21 46 5 33
> x1<-cut(x,breaks = c(0,10,20,max(x)),labels = c(1,2,3))
> x1
[1] 3 2 2 3 2 3 3 3 1 3
Levels: 1 2 3
> x<-round(runif(10,0,50),0)
> x
[1] 39 14 14 30 18 38 21 46 5 33
> x1<-cut(x,breaks = c(0,10,20,max(x)),labels = c("C","B","A"))
> x1
[1] A B B A B A A A C A
Levels: C B A
> x2<-cut(x,breaks = 3)#breaks为大于1的值,将x分成均等的3组
> x2
[1] (32.3,46] (4.96,18.7] (4.96,18.7] (18.7,32.3] (4.96,18.7] (32.3,46] (18.7,32.3] (32.3,46] (4.96,18.7]
[10] (32.3,46]
Levels: (4.96,18.7] (18.7,32.3] (32.3,46]
实例2 随机产生10个N(60,10)的随机成绩,并用cut函数将其分为5组
> score<-round(rnorm(10,60,10))
> score
[1] 50 67 49 43 44 61 70 73 57 60
> score.cut<-cut(score,breaks = 5)
> score.cut
[1] (49,55] (61,67] (43,49] (43,49] (43,49] (55,61] (67,73] (67,73] (55,61] (55,61]
Levels: (43,49] (49,55] (55,61] (61,67] (67,73]
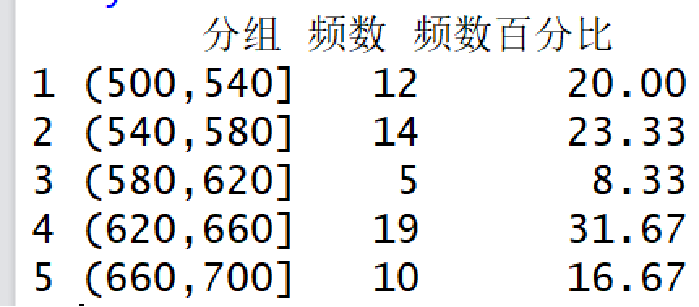
实例3 已知有一家购物网站连续60天的销售额数据。生成一张频数分布表,并计算各组频数的百分比。
- 生成随机数
> x<-trunc(runif(60,500,700))
> x
[1] 596 685 549 570 673 636 502 699 639 587 514 567 601 547 600 690 633 667 625 536 518 582 556 614 584 699 581 622 585
[30] 561 507 538 601 690 689 546 571 693 550 541 644 575 594 512 614 648 566 692 596 693 666 573 677 649 610 517 550 550
[59] 550 525
- 分成间隔为40的组
d<-cut(x,breaks=c(500,540,580,620,660,700))

- 列出频数分布表
> d<-table(d)
> d
d
(500,540] (540,580] (580,620] (620,660] (660,700]
9 16 14 8 13
- 将频数分布表组织成数据框形式
> dd<-data.frame(d)
> dd
d Freq
1 (500,540] 9
2 (540,580] 16
3 (580,620] 14
4 (620,660] 8
5 (660,700] 13
- 计算频数百分比,结果保留2位小数
> percent<-round(dd$Freq/sum(dd$Freq)*100,2)
> percent
[1] 15.00 26.67 23.33 13.33 21.67
- 将percent作为一列,添加到数据框中
> dd<-data.frame(dd,percent)
> dd
d Freq percent
1 (500,540] 9 15.00
2 (540,580] 16 26.67
3 (580,620] 14 23.33
4 (620,660] 8 13.33
5 (660,700] 13 21.67
这一步有多种方式。。。
- 为数据框的各个属性重新命名
> mytable<-data.frame(分组=dd$d,频数=dd$Freq,频数百分比=dd$percent)
> mytable
分组 频数 频数百分比
1 (500,540] 9 15.00
2 (540,580] 16 26.67
3 (580,620] 14 23.33
4 (620,660] 8 13.33
5 (660,700] 13 21.67
结论:频数分布表显示,销售额集中在540-580万元的时间最多,为16填,占总天数的26.67%
(4)使用car程序包中的recode函数
car(Companion to Applied Regression )程序包的recode函数可以将数值或者字符向量、factor变量重新编码。
基本语法:
recode(x,recodes,as.factor.result,levels)
参数说明:
| 参数 | 说明 |
|---|---|
| x | x为数值向量,字符向量或者factor 变量。 |
| recodes | recode为设定重新编码规则的字符串。 |
| as.factor.result | as.factor.result为是否输出factor变量。若是则为TRUE,不是为FALSE。 |
| levels | levels为排序向量。指定新的编码分组的顺序(默认是按照分组名称排序)。 |
recodes参数编码规则的写法
recodes参数的值是一个字符串,字符串里面是以分号分隔的编码规则:recodes=“规则1;规则2…”
每一个编码规则的格式为旧码列表=新码,“旧码列表”部分可用lo代表旧码的最小值(low)、hi代表旧码的最大值(high)撰写规则如下:
(1)旧码=新码 旧码只有单一数值。例如:“0=NA”表示将0改为NA。
(2)旧码向量=新码 多个旧码改为一个新码。例如:“c(7,8,9)=‘high’”,将7,8,9改为high。
(3)start:end=新码 有序数字改码。例如:“l0:19=‘C’”。
(4)else=新码 所有其他情况。例如:“else=NA”。
实例1
>library(carData)
>library(car)
> x<-rep(1:3,times=3)
> x
[1] 1 2 3 1 2 3 1 2 3
> recode(x,"c(1,2)='A';else='B'")
[1] "A" "A" "B" "A" "A" "B" "A" "A" "B"
实例2
将成绩0~40分之间的分数编码为1,41-60分之间为2,61-80分为3,81以上为4,其他情况为NA
> library(carData)
> library(car)
> score<-round(rnorm(10,60,10))
> score
[1] 76 76 65 63 61 49 83 57 47 65
> recode(score,"lo:40=1;41:60=2;61:80=3;81:hi=4;else=NA")
[1] 3 3 3 3 3 2 4 2 2 3
3.变量的重命名
变量的重命名主要针对数据框(data.frame)而言
fix()函数
可以通过fix()函数手动修改。
> x1<-c(1,3,5,7)
> x2<-c(2,4,6,8)
> df<-data.frame(x1,x2)
> df
x1 x2
1 1 2
2 3 4
3 5 6
4 7 8
> fix(df)
names()函数
格式:names(x)<-value。需要指定对第几个变量名进行修改。
> names(df)
[1] "x1" "x2"
> names(df)[1]<-"z1"
> df
z1 x2
1 1 2
2 3 4
3 5 6
4 7 8
当然rownames()和colnames()也可以对行和列进行命名。
> colnames(df)<-c('a','b')
> df
a b
1 1 2
2 3 4
3 5 6
4 7 8
4.缺失值
缺失值:表示该数据集中的数据遗失。在R中,以符号NA(Not Available,不可用)表示。一个完整的处理方法通常包含以下几个步骤:(1) 识别缺失数据;
(2) 检查导致数据缺失的原因;
(3) 删除包含缺失值的实例或用合理的数值代替(插补)缺失值。
说明:
但遗憾的是,仅有识别缺失数据是最清晰明确的步骤。知道数据为何缺失依赖于你对数据生成过程的理解,而决定如何处理缺失值则需要判断哪种方法的结果最为可靠和精确。
NA:表示存在但是未知的值
NULL:表示不存在的值
识别缺失值
> data=data.frame(y=c(1,2,3,NA,5,6),x1=c(6,NA,4,3,2,1),x2=c(1,3,6,9,12,NA))
> data
y x1 x2
1 1 6 1
2 2 NA 3
3 3 4 6
4 NA 3 9
5 5 2 12
6 6 1 NA
> complete.cases(data)
[1] TRUE FALSE TRUE FALSE TRUE FALSE
> is.na(data)
y x1 x2
[1,] FALSE FALSE FALSE
[2,] FALSE TRUE FALSE
[3,] FALSE FALSE FALSE
[4,] TRUE FALSE FALSE
[5,] FALSE FALSE FALSE
[6,] FALSE FALSE TRUE
> sum(is.na(data))
[1] 3
complete.cases()可以查看样本数据是否完整,is.na()用来判断数据是否为NA,sum()统计缺失值个数
处理缺失值
方法1:只选择无缺失值的样本数据
> data1<-data[complete.cases(data),]
> data1
y x1 x2
1 1 6 1
3 3 4 6
5 5 2 12
方法2:删除所有包含缺失值的记录
> data2<-na.omit(data)
> data2
y x1 x2
1 1 6 1
3 3 4 6
5 5 2 12
方法3:替换缺失值。
通过一定的统计方法计算出相应值来替换缺失值。一般的方法有:平均值法(最常用)、多重插补法、随机模拟法回归预测(较复杂)。平均值法如下:
#使用已有值的平均值来代替缺失数据
attach(data)
y[is.na(y)]<-mean(y,na.rm=T)
x1[is.na(x1)]<-mean(x1,na.rm=T)
x2[is.na(x2)]<-mean(x2,na.rm=T)
data<-data.frame(y,x1,x2)
data
y x1 x2
1 1.0 6.0 1.0
2 2.0 3.2 3.0
3 3.0 4.0 6.0
4 3.4 3.0 9.0
5 5.0 2.0 12.0
6 6.0 1.0 6.2
NA的使用
在R的很多统计函数中,我们要求函数跳过缺失值(NA)
> x<-c(88,NA,12,168,13)
> x
[1] 88 NA 12 168 13
> mean(x)
[1] NA
> mean(x,na.rm = T)
[1] 70.25
> x<-NULL
> y<-NA
> length(x)
[1] 0
> length(y)
[1] 1
R语言会自动跳过NULL值,NULL不考虑,得到的值是其他四个数的平均值,NULL是R的一种特殊对象,它没有模式。
4.日期值
在R语言中,日期值通常是以字符串的形式进行存储,通过转换函数,将其转化为以数值形式存储的日期变量。
as.Date(x,”input_format”)
其中,x是字符型数据
| 符号 | 含义 | 示例 |
|---|---|---|
| %d | 数字表示的日期(0~31) | 01~31 |
| %a | 缩写的星期名 | Mon |
| %A | 非缩写的星期名 | Monday |
| %m | 月份(00~12) | 00~12 |
| %b | 缩写的月份 | Jan |
| %B | 非缩写的月份 | January |
| %y | 两位数的年份 | 07 |
| %Y | 四位数的年份 | 2007 |
> x<-c("2022-10-22")
> y<-as.Date(x)
> y
[1] "2022-10-22"
> format(y,"%d")
[1] "22"
> format(y,"%a")
[1] "周六"
> format(y,"%m")
[1] "10"
> format(y,"%y")
[1] "22"
- 提取当前日期和时间
Sys.Date():返回系统当前日期
> Sys.Date()
[1] "2022-10-22"
date():返回系统的日期与时间
> date()
[1] "Sat Oct 22 14:58:15 2022"
- 在R中日期实际是double类型,是从1970年1月1日以来的天数
> typeof(Sys.Date())
[1] "double"
- 用as.Date()将字符串转换为日期值,默认格式为yyyy-mm-dd
> as.Date("2020-09-04")
[1] "2020-09-04“ #显示为字符串,但实际是用double存储的
> as.double(Sys.Date())
[1] 18509 #从1970年1月1日以来的天数
- 把默认格式的日期字符串输出为指定格式的日期
> today<-Sys.Date()
> format(today,"%Y年%m月%d日 %a")
[1] "2022年10月22日 周六"
- 计算日期差:由于日期内部是用double存储的天数,所以是可以相减的。
> today<-Sys.Date()
> newyear<-as.Date("2023-01-01")
> newyear-today
Time difference of 71 days
用difftime()函数可以计算相关的秒数、分钟数、小时数、天数、周数
> difftime(newyear,today,units="weeks")
Time difference of 10.14286 weeks
- 通过as.Date()创建日期序列
> as.Date(0:6,"2022-10-22")
[1] "2022-10-22" "2022-10-23" "2022-10-24" "2022-10-25" "2022-10-26" "2022-10-27" "2022-10-28"
- 通过seq()创建日期序列
> seq(as.Date("2022-10-22"),as.Date("2022-11-11"),by="days")
[1] "2022-10-22" "2022-10-23" "2022-10-24" "2022-10-25" "2022-10-26" "2022-10-27" "2022-10-28" "2022-10-29" "2022-10-30"
[10] "2022-10-31" "2022-11-01" "2022-11-02" "2022-11-03" "2022-11-04" "2022-11-05" "2022-11-06" "2022-11-07" "2022-11-08"
[19] "2022-11-09" "2022-11-10" "2022-11-11"
时间序列数据的构造与作图
时间序列数据(time series data)是在不同时间上收集到的数据,用于所描述现象随时间变化的情况。这类数据反映了某一事物、现象等随时间的变化状态或程度。
时间序列数据由两部分构成:一、时间或者日期 二、每个时间点对应的数据。
时间序列是统计学专业课程之一。对时间序列的研究一般要建立在一定的计量经济学基础上,计量经济学已有涉及时间序列模型。
时间序列分析的主要目的是根据已有的历史数据对未来进行预测。经济数据中大多数以时间序列的形式给出。根据观察时间的不同,时间序列中的时间可以是年份、季度、月份或其他任何时间形式。
zoo函数的使用
zoo(x=NULL, order.by=index(x),frequency=NULL)
> x<-zoo(rnorm(5),x.Date)
> x
2019-01-01 2019-01-03 2019-01-07 2019-01-09 2019-01-15
2.762697276 2.100946368 0.004059034 -0.008107582 1.037967446
> class(x)
[1] "zoo“
在R语言中,单独为时间序列数据定义了一种数据类型zoo,zoo是时间序列的基础,也是股票分析的基础。
步骤1:产生时间数据
步骤2:使用zoo函数产生分量zoo类型数据x
步骤3:使用zoo函数产生分量zoo类型数据y
步骤4:使用cbind函数合并x,y
步骤5:使用plot函数作图
mydate<-as.Date(0:20,origin="2019-01-01")
x<-zoo(rnorm(length(mydate)),mydate)
y<-zoo(rnorm(length(mydate)),mydate)
mydata<-cbind(x,y)
plot(mydata,plot.type="single",lty=c(1,3),lwd=2,col=c(2,3))
legend("top",c("x","y"),lty=c(1,3),lwd=2,col=c(2,3),horiz=1)
5.数据类型转换
数据类型相关函数:is族函数用于判断数据类型,返回逻辑值。
| 函数 | 说明 |
|---|---|
| is.numeric() | 判断是否为数值型数据 |
| is.character() | 判断是否为字符型数据 |
| is.vector() | 判断是否为向量 |
| is.matrix() | 判断是否为矩阵 |
| is.data.frame() | 判断是否为数据框 |
| is.factor() | 判断是否为因子 |
| is.logical() | 判断是否为逻辑型数据 |
| is.na() | 判断是否为NA值 |
as族函数用于数据类型转换,返回转换后类型。
| 函数 | 说明 |
|---|---|
| as.numeric() | 将数据转换为数值型 |
| as.character() | 将数据转换为字符型 |
| as.vector() | 将数据转换为向量 |
| as.matrix() | 将数据转换为矩阵 |
| as.data.frame() | 将数据转换为数据框 |
| as.factor() | 将数据转换为因子 |
| as.logical() | 将数据转换为逻辑型变量 |
R中提供了一系列用来判断某个对象的数据类型和将其转换为另一种数据类型的函数。
(1)逻辑型与数值型
> as.numeric(TRUE)
[1] 1
> as.numeric(FALSE)
[1] 0
> as.logical(1)
[1] TRUE
> as.logical(0)
[1] FALSE
> as.logical(30)
[1] TRUE
> as.logical(-30)
[1] TRUE
(2)数值型与字符型
> as.character(3)
[1] "3"
> as.numeric("3")
[1] 3
> as.numeric("hello")
[1] NA
Warning message:
强制改变过程中产生了NA
(3)字符型与因子型
> x<-c("a","b","a","c","b")
> as.factor(x)
[1] a b a c b
Levels: a b c
> as.character(as.factor(x))
[1] "a" "b" "a" "c" "b"
(4)数值型与因子型
> x<-c(1,3,2,5)
> as.factor(x)
[1] 1 3 2 5
Levels: 1 2 3 5
> as.numeric(as.factor(x))
[1] 1 3 2 4
转换后不确定是否成功,可以用typeof或is族函数来验证!
6.数据排序
在R中,可以使用Order()函数对一个矩阵或者数据框进行排序。默认的排序顺序是升序。
在排序变量的前面加一个减号即可得到降序的排序结果。
> a <- matrix( c(5, 3, 4, 2, 2, 6, 8, 9, 7, 6, 12, 10, 11, 14, 13), 5)
> a
[,1] [,2] [,3]
[1,] 5 6 12
[2,] 3 8 10
[3,] 4 9 11
[4,] 2 7 14
[5,] 2 6 13
按照第一列升序
> b<-a[order(a[,1]),]
> b
[,1] [,2] [,3]
[1,] 2 7 14
[2,] 2 6 13
[3,] 3 8 10
[4,] 4 9 11
[5,] 5 6 12
按照第一列升序,第二列升序
> b<-a[order(a[,1],a[,2]),]
> b
[,1] [,2] [,3]
[1,] 2 6 13
[2,] 2 7 14
[3,] 3 8 10
[4,] 4 9 11
[5,] 5 6 12
按照第一列升序,第二列降序
> b<-a[order(a[,1],-a[,2]),]
> b
[,1] [,2] [,3]
[1,] 2 7 14
[2,] 2 6 13
[3,] 3 8 10
[4,] 4 9 11
[5,] 5 6 12
7. 数据集的合并
merge()函数
total=merge(dataframeA, dataframeB,by=“ID”)
> per1 <- data.frame(name = c("张三","李四","王五","赵六"), q1 = c(23,45,34,1000))
> per2 <- data.frame(name = c("张三","李四","王五","赵六"), q2 = c(34,56,34,43))
> per1
name q1
1 张三 23
2 李四 45
3 王五 34
4 赵六 1000
> per2
name q2
1 张三 34
2 李四 56
3 王五 34
4 赵六 43
> per <- merge(per1,per2,by = "name")
> per
name q1 q2
1 李四 45 56
2 王五 34 34
3 张三 23 34
4 赵六 1000 43
在多数情况下,两个数据框是通过一个或者多个共有变量进行联结的
cbind()函数
total=cbind(dataframeA, dataframeB)
> per1 <- data.frame(name = c("张三","李四","王五","赵六"), q1 = c(23,45,34,1000))
> per2 <- data.frame(name = c("张三","李四","王五","赵六"), q2 = c(34,56,34,43))
> per <- cbind(per1,per2)
> per
name q1 name q2
1 张三 23 张三 34
2 李四 45 李四 56
3 王五 34 王五 34
4 赵六 1000 赵六 43
直接横向合并两个矩阵或者数据框,不需要指定一个公共索引。
rbind()函数
rbind函数根据行进行合并,就是行的叠加,m行的矩阵与n行的矩阵rbind()最后变成m+n行,合并前提:rbind(a, b)中矩阵a、b的列数必需相符。
> a <- matrix(1:12, 3, 4)
> b <- matrix(-1:-12, 3, 4)
> a
[,1] [,2] [,3] [,4]
[1,] 1 4 7 10
[2,] 2 5 8 11
[3,] 3 6 9 12
> b
[,1] [,2] [,3] [,4]
[1,] -1 -4 -7 -10
[2,] -2 -5 -8 -11
[3,] -3 -6 -9 -12
> c <- rbind(a,b)
> c
[,1] [,2] [,3] [,4]
[1,] 1 4 7 10
[2,] 2 5 8 11
[3,] 3 6 9 12
[4,] -1 -4 -7 -10
[5,] -2 -5 -8 -11
[6,] -3 -6 -9 -12
直接纵向合并两个矩阵或者数据框,不需要指定一个公共索引。
8.数据集取子集(筛选 filtering)
在用R处理数据的过程中,大部分时候,你并不需要访问整个数据集,而是选取数据中的的一部分。又比如你在处理数据时遇到缺失的值,这些缺失的值需要去掉,这就需要使用一个索引去找出我们需要的数据或者剔除缺失值或者不需要的数据,学会了以下的方法可以对大部分的数据进行子集处理。筛选:提取向量中满足一定条件的元素
1 单层方括号索引
单层方括号索引包含数值型索引和逻辑型索引,使用符号[]来对数据进行子集处理。单层方括号索引返回的值的类型和源对象的类型相同。
1 .1 数值型索引:即括号内采用数值进行运算
> x<-1:5
> m<-x[2:4]
> n<-x[c(1,5)]
> m
[1] 2 3 4
> n
[1] 1 5
> mymatrix<-matrix(1:6,nrow=2,ncol=3)
> mymatrix
[,1] [,2] [,3]
[1,] 1 3 5
[2,] 2 4 6
> sub1<-mymatrix[2,]
> sub2<-mymatrix[-2,1:2]
> sub1
[1] 2 4 6
> sub2
[1] 1 3
1 .2 逻辑型索引:逻辑型索引即采用逻辑判断来对数据子集进行操作。
> data<-c(2,4,6,9,4,8,19)
> data[data>6]
[1] 9 8 19
2 双层方括号索引
双层方括号被用来列表或者数据框中提取元素,但返回的对象不一定是列表或数据框。
> num=1:4
> names=c("lliy","lucy","ziggs","ben")
> sex=c("F","F","M","M")
> score=c(75,89,90,68)
> stu=data.frame(number=num,name=names,sex=sex,score=score,)
> stu
number name sex score
1 1 lliy F 75
2 2 lucy F 89
3 3 ziggs M 90
4 4 ben M 68
> stu[["sex"]]
[1] F F M M
Levels: F M
> stu[[1]]
[1] 1 2 3 4
使用双层方括号索引仅提取一个元素。
> x<-list(a=c(1,34,6),b=c(3.14,1.732,2.256))
> x
$a
[1] 1 34 6
$b
[1] 3.140 1.732 2.256
> x[[c(1,3)]]
[1] 6
> x[[c(2,1)]]
[1] 3.14
注意:这里要使用c()函数
3. $符号索引
美元$索引可以从有命名的列表或者数据框中提取元素,在一定程度上美元符号和双层中括号的用途一样。
> number<-1:4
> name<-c("lily","lucy","ziggs","ben")
> sex<-c("F","F","M","M")
> score<-c(75,89,90,68)
> stu<-data.frame(number,name,sex,score)
> stu
number name sex score
1 1 lily F 75
2 2 lucy F 89
3 3 ziggs M 90
4 4 ben M 68
> stu$name
[1] "lily" "lucy" "ziggs" "ben"
或是$和[]同时索引。
> stu$name[score>80]
[1] "lucy" "ziggs"
> stu$name[sex=="M"]
[1] "ziggs" "ben"
4.subset()函数
从R自带airquality数据集中取出Temp值大于80 的Ozone、Temp列的值。
(1)
attach(airquality)
subset(airquality[,c(1,4)],Temp>80)
detach(airquality)
(2)
attach(airquality)
subset(airquality,airquality$Temp>80,select = c(Ozone,Temp))
5. NA值得移除
它也有不同的类型:数值型或字符型,数值型NA对应数值缺失值,字符型对应字符型缺失值
> x<-c(1,2,NA,NA,5)
> m<-is.na(x)
> m
[1] FALSE FALSE TRUE TRUE FALSE
> x[!m]
[1] 1 2 5
$b
[1] 3.140 1.732 2.256
x[[c(1,3)]]
[1] 6
x[[c(2,1)]]
[1] 3.14
注意:这里要使用c()函数
### 3. $符号索引
美元$索引可以从有命名的列表或者数据框中提取元素,在一定程度上美元符号和双层中括号的用途一样。
```R
> number<-1:4
> name<-c("lily","lucy","ziggs","ben")
> sex<-c("F","F","M","M")
> score<-c(75,89,90,68)
> stu<-data.frame(number,name,sex,score)
> stu
number name sex score
1 1 lily F 75
2 2 lucy F 89
3 3 ziggs M 90
4 4 ben M 68
> stu$name
[1] "lily" "lucy" "ziggs" "ben"
或是$和[]同时索引。
> stu$name[score>80]
[1] "lucy" "ziggs"
> stu$name[sex=="M"]
[1] "ziggs" "ben"
















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











