







CUDA编程中的内存模型是理解如何高效编写并行程序的关键部分。它定义了不同类型内存的层次结构和使用方式,以优化数据访问速度和计算效率。
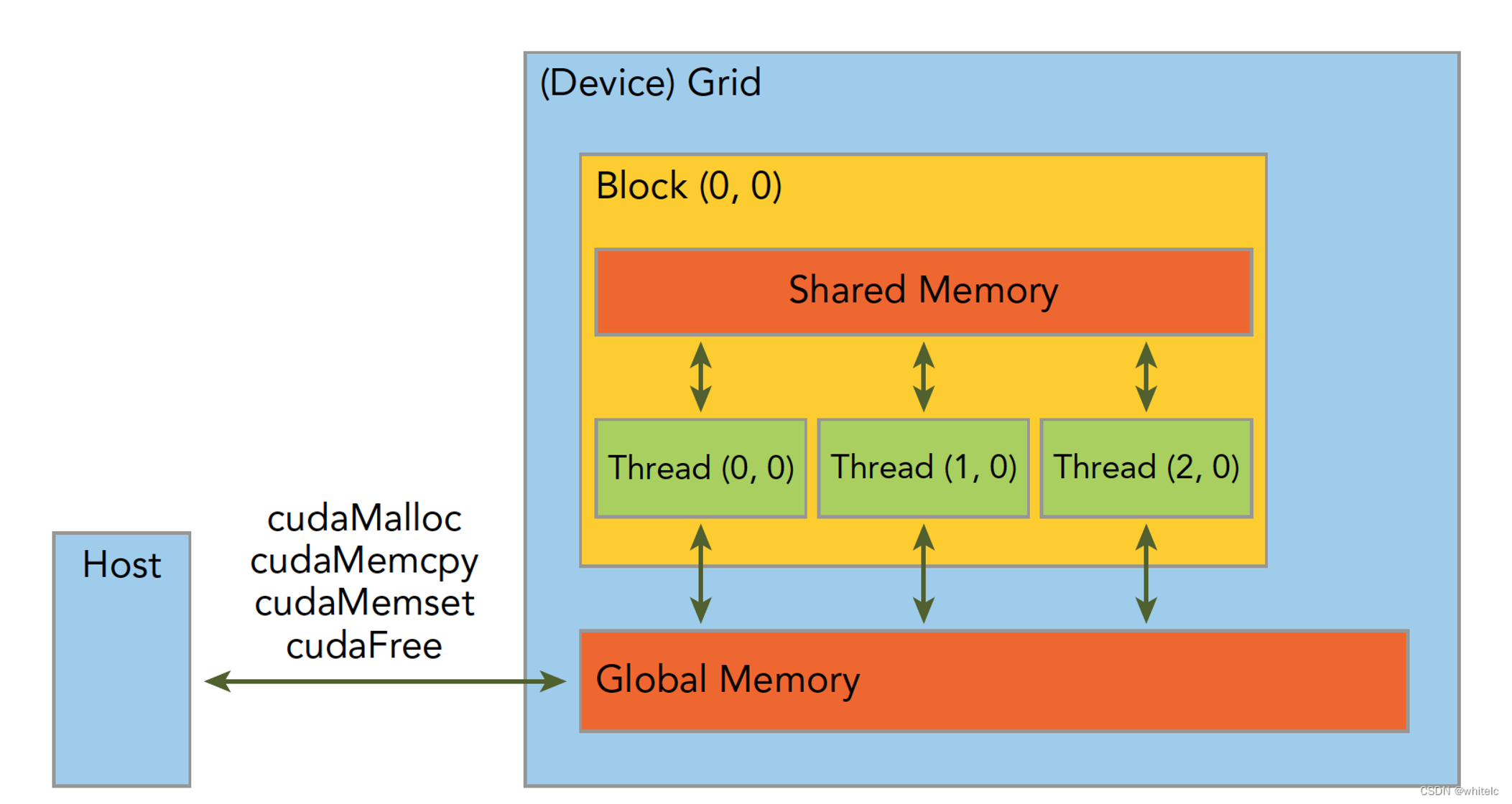
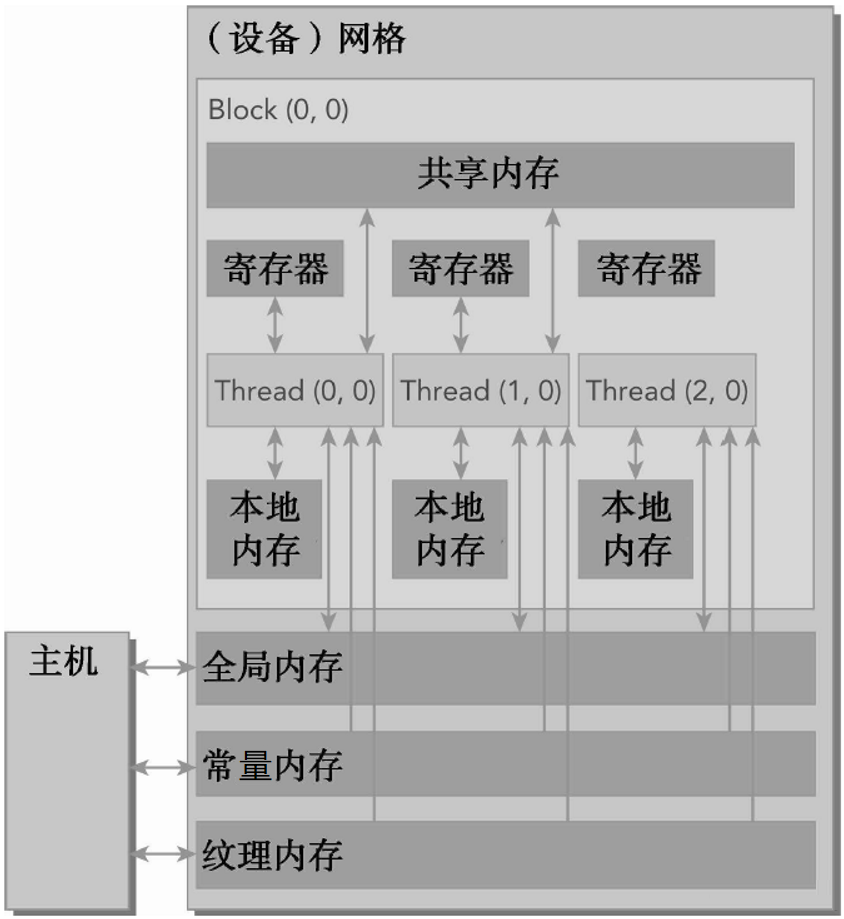
CUDA内存模型的主要组成
-
寄存器(Registers):这是每个线程私有的最快内存空间。变量通常会首先分配到这里,前提是它们的使用范围足够小且生命周期不会跨越太多的线程块。
-
共享内存(Shared Memory):位于每个线程块内,是所有线程块中的线程可以共同访问的内存区域。它的速度非常快,但容量有限。主要用于在线程间共享数据、协作计算等场景中。共享内存进一步分为普通共享内存和常量共享内存。
-
全局内存(Global Memory):对网格内的所有线程可见,并且在kernel执行期间保持有效。其容量较大,但访问速度较慢。为了提高性能,通常需要确保全局内存访问是合并的。
-
常量内存(Constant Memory):用于存储在kernel执行期间不会改变的数据。虽然大小限制为64KB,但由于具有缓存机制,对于广播到所有线程的数据来说,访问效率很高。
-
纹理内存(Texture Memory):一种只读内存,通过纹理拾取操作进行访问。特别适合于特定类型的读模式,比如二维空间局部性良好的情况,以及需要过滤或寻址模式的情况。
-
本地内存(Local Memory):当编译器确定变量不适合放入寄存器时,会将其放置在本地内存中。本地内存实际上是在全局内存中实现的,因此访问速度较慢。
-
固定内存(Pinned Memory)
主机内存,但映射到GPU地址空间
允许异步传输
提高主机-设备传输速度
理解和合理利用这些不同的内存类型,可以帮助开发者优化CUDA应用程序的性能。例如,尽量减少全局内存的访问次数,充分利用共享内存和寄存器,避免银行冲突等,都是提高CUDA程序性能的有效策略.
内存访问深度优化
CUDA内存系统的优化是GPU编程性能调优的核心。将从全局内存、共享内存、寄存器使用等关键方面,提供一套系统化的优化策略。
一、全局内存优化进阶
1. 合并访问模式强化
-
理想访问模式:warp内32个线程访问连续128字节对齐内存块
-
矩阵转置优化案例:
// 优化后的转置内核(避免非合并访问)
__global__ void transpose(float *odata, const float *idata, int width) {
__shared__ float tile[BLOCK_DIM][BLOCK_DIM+1]; // 添加padding
int x = blockIdx.x * BLOCK_DIM + threadIdx.x;
int y = blockIdx.y * BLOCK_DIM + threadIdx.y;
if (x < width) {
// 合并读取
tile[threadIdx.y][threadIdx.x] = idata[y*width + x];
}
__syncthreads();
x = blockIdx.y * BLOCK_DIM + threadIdx.x;
y = blockIdx.x * BLOCK_DIM + threadIdx.y;
if (x < width) {
// 合并写入
odata[y*width + x] = tile[threadIdx.x][threadIdx.y];
}
}2. 向量化内存操作
-
使用float4/int4等宽数据类型:
float4 *vec_data = (float4*)global_data;
float4 val = vec_data[threadIdx.x]; // 单指令加载4个float3. 常量内存优化策略
-
适合频繁读取的只读数据
-
自动广播机制(同一warp读取相同地址只需一次操作)
__constant__ float cos_table[1024];
// 初始化使用cudaMemcpyToSymbol二、共享内存极致优化
Bank冲突是CUDA共享内存性能优化的关键问题之一。当同一warp(32个线程)中的多个线程访问同一个共享内存bank时,会导致这些访问被串行化,从而降低性能。
共享内存Bank结构
-
共享内存被划分为32个bank(计算能力3.x及以上设备)
-
每个bank每个时钟周期只能服务一个内存请求
-
连续32位字分配到连续的bank(默认4字节间隔)
Bank冲突的类型
-
无冲突:同一warp中的所有线程访问不同的bank或同一个地址
-
n-way冲突:同一warp中n个线程访问同一个bank的不同地址
避免Bank冲突的方法
1. 改变访问模式
// 可能导致bank冲突的访问模式
__shared__ float sharedArray[32][32];
float value = sharedArray[threadIdx.y][threadIdx.x]; // 同一warp中的threadIdx.y相同
// 修改为无冲突的访问模式
float value = sharedArray[threadIdx.x][threadIdx.y]; // 现在threadIdx.x不同2. 使用填充(Padding)
// 原始定义可能有bank冲突
__shared__ int sharedArray[32][32];
// 添加padding避免冲突
__shared__ int sharedArray[32][33]; // 每行多一个元素3. 调整数据布局
// 原始结构可能有bank冲突
struct Data {
float x, y, z;
};
__shared__ Data sharedData[32];
// 修改为结构体数组转数组结构体(SOA)
__shared__ float sharedX[32], sharedY[32], sharedZ[32];4. 使用广播
当多个线程需要读取同一个值时:
__shared__ float sharedValue; float value = sharedValue; // 广播读取,不会造成bank冲突
5. 使用不同的bank宽度
对于计算能力3.x及以上设备,可以改变bank宽度:
cudaDeviceSetSharedMemConfig(cudaSharedMemBankSizeEightByte); // 8字节bank
检测Bank冲突
-
使用Nsight Compute或Nsight Profiler分析工具
-
查看shared_load/store_transactions_per_request指标
-
理想值为1
-
大于1表示存在bank冲突
-
矩阵转置中的bank冲突解决方案
__global__ void transpose(float *odata, const float *idata, int width, int height) {
__shared__ float block[BLOCK_DIM][BLOCK_DIM+1]; // 添加padding
int x = blockIdx.x * BLOCK_DIM + threadIdx.x;
int y = blockIdx.y * BLOCK_DIM + threadIdx.y;
if (x < width && y < height) {
block[threadIdx.y][threadIdx.x] = idata[y * width + x];
}
__syncthreads();
x = blockIdx.y * BLOCK_DIM + threadIdx.x; // 转置后的坐标
y = blockIdx.x * BLOCK_DIM + threadIdx.y;
if (x < height && y < width) {
odata[y * height + x] = block[threadIdx.x][threadIdx.y];
}
}6. 共享内存分块策略
-
根据计算需求调整分块大小(典型16x16或32x32)
-
考虑寄存器压力与共享内存使用的平衡
三、寄存器优化技巧
1. 寄存器压力控制
-
使用
-maxrregcount编译选项限制寄存器使用 -
复杂算法分阶段计算减少同时使用的寄存器数量
2. 变量复用策略
float tmp = a * b; result1 = tmp + c; result2 = tmp * d; // 复用tmp变量
四、内存访问模式检测
1. 使用NVVP分析工具
-
检查"Global Memory Load Efficiency"指标
-
分析"Shared Memory Bank Conflicts"报告
2. 代码级检测方法
// 在代码中插入内存访问检查
#if __CUDA_ARCH__ >= 200
if ((size_t)ptr % 128 != 0) {
printf("Unaligned memory access!\n");
}
#endif五、统一内存(UM)优化
1. 预取策略
cudaMemPrefetchAsync(umem, size, device); // 显式预取
2. 建议访问模式
cudaMemAdvise(ptr, size, cudaMemAdviseSetPreferredLocation, device);
六、高级优化技术
1. 异步内存操作
__global__ void kernel(float *out, const float *in) {
__shared__ float smem[256];
// 异步拷贝全局内存到共享内存
__pipeline_memcpy_async(smem, in, 256*sizeof(float));
__pipeline_commit();
__pipeline_wait_prior(0);
// 处理数据...
}2. 使用只读数据缓存
__global__ void kernel(const int *__restrict__ input) {
int val = __ldg(&input[threadIdx.x]); // 使用只读缓存
}
性能优化检查清单
-
全局内存访问是否合并
-
共享内存bank冲突是否消除
-
寄存器使用是否在合理范围
-
是否充分利用了常量内存
-
内存访问模式是否适配缓存结构
-
是否使用了合适的预取策略
-
是否考虑过统一内存优化
通过系统化应用这些优化技术,典型CUDA内核可获得3-10倍的性能提升。建议采用增量优化策略,每次修改后使用nsight-compute进行性能分析验证。
内存对齐优化
内存对齐是CUDA性能优化中的关键因素,合理的内存对齐可以显著提高内存访问效率。以下是CUDA内存对齐的详细指南:
一、内存对齐基础概念
1. 对齐原则
-
基本对齐:数据类型应在其大小倍数的地址上存储
-
CUDA特殊要求:全局内存访问需要更严格的对齐(通常128字节)
2. 对齐优势
-
提高内存访问效率
-
实现合并内存访问
-
减少内存事务数量
二、不同内存类型的对齐要求
1. 全局内存对齐
-
计算能力2.0+:推荐128字节对齐
-
合并访问条件:
-
线程访问顺序连续地址
-
首地址对齐128字节
-
访问32/64/128位数据
-
// 手动对齐示例
struct __align__(16) AlignedStruct {
float x, y, z;
};2. 共享内存对齐
-
自动按bank宽度对齐(通常4字节)
-
可通过
__align__指定更大对齐
__shared__ __align__(8) float sharedArray[32];3. 寄存器变量对齐
-
编译器自动处理
-
可通过
__align__提示编译器
三、对齐控制方法
1. 编译器指令
struct __align__(16) MyStruct {
float a, b, c;
};
2. 内存分配函数
// 对齐分配全局内存 cudaMalloc(&devPtr, size); // 自动保证最小256字节对齐 cudaMallocPitch(&devPtr, &pitch, width, height); // 2D对齐分配
3. 内置对齐函数
// 计算对齐偏移 size_t offset = alignUp(ptr, 128);
四、常见场景优化
1. 结构体对齐优化
// 优化前(可能不对齐)
struct Particle {
float x, y, z;
char flags;
};
// 优化后(显式对齐)
struct __align__(16) Particle {
float x, y, z;
char flags;
char padding[3]; // 填充到16字节
};2. 矩阵访问优化
// 分配对齐的2D数组
float* devMatrix;
size_t pitch;
cudaMallocPitch(&devMatrix, &pitch, width*sizeof(float), height);
// 访问时考虑pitch
float* row = (float*)((char*)devMatrix + rowIndex*pitch);
float value = row[colIndex];3. 向量类型使用
// 使用内置向量类型(自动对齐) float4 vec = make_float4(1.0f, 2.0f, 3.0f, 4.0f);
五、对齐检测与验证
1. 地址检查
bool isAligned(const void* ptr, size_t alignment) {
return (uintptr_t)ptr % alignment == 0;
}
2. CUDA错误检查
cudaError_t err = cudaMalloc(&ptr, size);
if (err != cudaSuccess) {
// 处理分配失败(可能包含对齐问题)
}
3. 性能分析工具
-
使用Nsight Compute检查"Global Memory Load/Store Efficiency"
-
分析内存事务数量
六、高级对齐技巧
1. 动态共享内存对齐
extern __shared__ __align__(16) float sharedMem[];
2. 统一内存对齐
cudaMallocManaged(&ptr, size, cudaMemAttachGlobal);
3. 纹理内存对齐
texture<float, 2, cudaReadModeElementType> texRef; cudaChannelFormatDesc desc = cudaCreateChannelDesc<float>(); cudaBindTexture2D(0, texRef, devPtr, desc, width, height, pitch);
七、常见问题解决方案
1. 非对齐访问修复
// 修复非对齐访问的示例
__global__ void kernel(const int* data) {
int offset = threadIdx.x;
int value;
// 非对齐访问(差)
// value = data[offset];
// 修复方案:使用memcpy
memcpy(&value, data+offset, sizeof(int));
}2. 结构体填充策略
struct UnalignedStruct {
char a; // 1字节
int b; // 4字节(在1字节后,不对齐)
};
struct AlignedStruct {
int b; // 4字节(对齐)
char a; // 1字节
char pad[3];// 填充到4字节
};通过合理的内存对齐优化,可以显著提高CUDA程序的性能,特别是在内存密集型应用中。建议开发时始终考虑内存对齐要求,并使用工具验证对齐效果。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









