







索引是帮助Mysql高效获取数据的排好序的数据结构
索引存储在文件里
索引结构:
- 二叉树
- 红黑树
- HASH : 一次HASH计算就可以找到对应数据的磁盘指针,进而定位到数据,但不适用范围查找
- BTREE
如图中的数据

若 字段clo1和clo2都没有建立索引,当我们 'sellet * from t where t.clo2 = 89;' 时, 会全盘由上至下扫描, 查询6次才能找到我们需要的数据,若数据量巨大,由此可见效率是极低的
二叉树
二叉树的顺序排列结构是每个节点分为两个岔路, 左边小于节点, 右边大于节点
二叉树的每个节点存储的是 key:value 的存储形式, key为字段值, value是该值对应在磁盘上的位置指针

若将clo2字段设置二叉树结构的索引, 当我们 'sellet * from t where t.clo2 = 89;' 时, 在第二步就可以找到89, 然后根据指针到磁盘找到我们需要的数据
缺点:
1.深度问题, 当数据量大时候,二叉树的深度会很深, IO次数(层数)就会增加,查询效率也就低了,
如 500w条数据,就是 2的n次方 = 500w, n就是树的高度(层数),
2.由于二叉树的顺序排列结构的特点, 不适应值为'线性'的情况
如: clo1字段, 经过二叉树排序后的索引结构如图

当我们 'sellet * from t where t.clo1 = 6;' 时, 还是要查询6次,没有起到加速查询的效果
红黑树(平衡二叉树):
红黑树的索引结构解决了二叉树的缺点, 针对'线性'问题, 红黑树做了优化排序,如图:
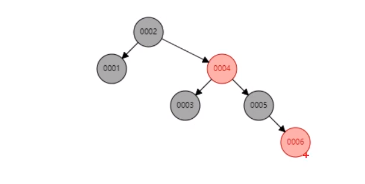
当我们 'sellet * from t where t.clo1 = 6;' 时 在第四步就能找到需要的数据,相对于二叉树提高了效率
缺点:
与二叉树一样 深度问题, 当数据量大时候,二叉树的深度会很深, IO次数就会增加,查询效率也就低了,
BTREE
B-TREE
- 度: 节点数据存储的个数, 一个节点整体尽量小,内存存储的数据个数尽量多
- 叶节点具有相同的深度
- 叶节点的指针为空
- 节点中的数据key从左到右递增排列
BTREE的索引结构解决了 深度问题,
BTREE使每个节点由存储一个数据,变成存储多个数据, 这样树的高度就会降低, IO次数减少
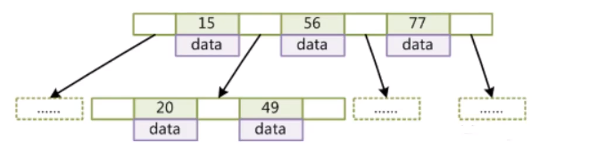
补充: data 是指向磁盘数据位置的指针
当查询数据的时候, 会将节点读取到内存中,在内存中进行比对, 找下一个节点,再将节点读取到内存,最终找到需要的数据
问: 既然可以横向扩展,为什么不把所有的数据都放到一个节点,然后读到内存中,在内存中查找呢?
答: 若数据量巨大,会是内存溢出
B+TREE
非叶子节点不存储data, 只存储key, 就可以增大'度',

Mysql不同的存储引擎使用了不同的索引存储结构
- MyISAM 索引的实现(非聚集)
索引文件(.MYI)与数据文件(.MYD)是分离的

当我们 'sellet * from t where t.clo1 = 49;' 时, 会先去.MYI索引文件中找到49对应的指针,根据指针到.MYD数据文件中找到对应的一行数据
- InnoDB索引的实现(聚集)
表数据文件本身就是按照B+Tree组织的一个索引结构文件(.ibd)
聚集索引(也叫主键索引)-叶子节点包含了完整的数据记录
非聚集索引(其他索引)-叶子节点包含了主键值, 找到主键值,再在primary key中找到数据
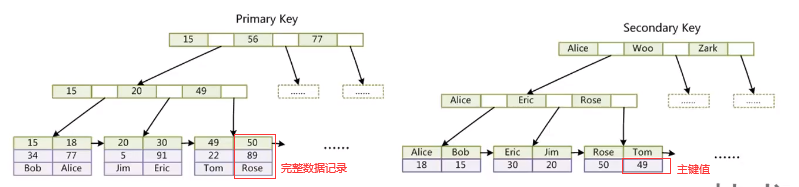
问: InnoDB类型的表创建时为什么一定要有主键?
答: 因为InnoDB类型的表的主键和数据存储在一个文件中,数据结构是根据主键来构建的,若没有创建主键,则找一个非空且唯一的字段来差创建结构,若以上都没有,会自动创建一个rowid(7个字节)的隐藏字段来构建结构,但因此会失去加速查询的功能
问: 为什么主键推荐使用整形,且自增的?
答: 整形所占用的空间小,使节点可以存储更多的'度', 叶子结点数据是一次递增的, 新增加的数据可以依次向后排列,若不是增的,可能会打乱之前叶子结点的结构,影响效率
问: 叶子结点之间的指针的作用?
答: 可以方便找范围查找















 3741
3741











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









