







引言
由于单链表的缺点是无法快速地在给定节点之前插入或删除节点,因为无法直接访问前一个节点,需要从头开始遍历链表找到前一个节点。这样的操作效率较低。
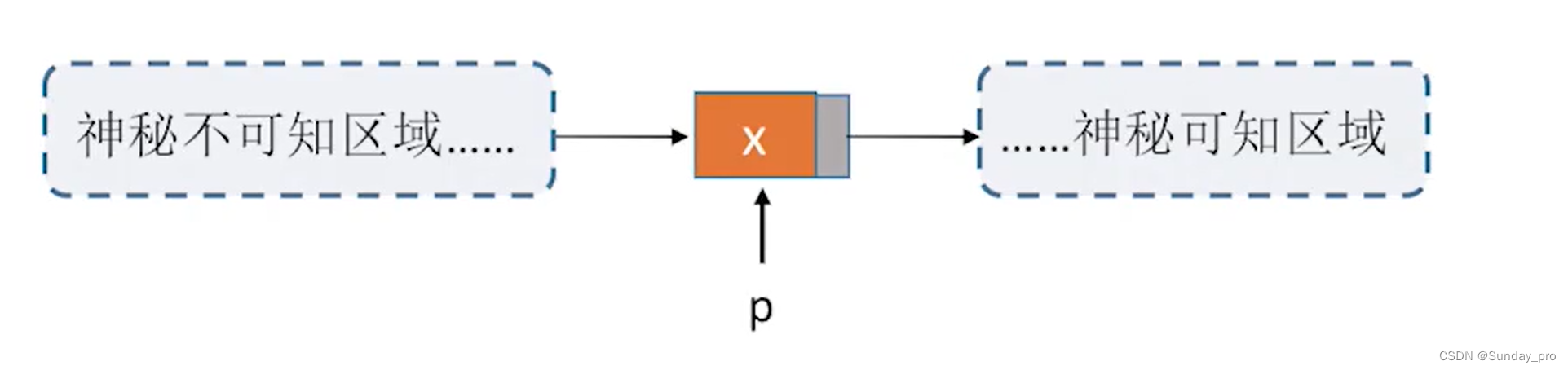
所以我们引入双链表的主要目的是解决单链表的这个缺点。双链表中的每个节点除了指向下一个节点的指针外,还有指向前一个节点的指针。这样在双链表中可以快速地在给定节点之前或之后插入或删除节点,因为可以直接访问前一个节点和后一个节点。这样可以提高插入和删除操作的效率。
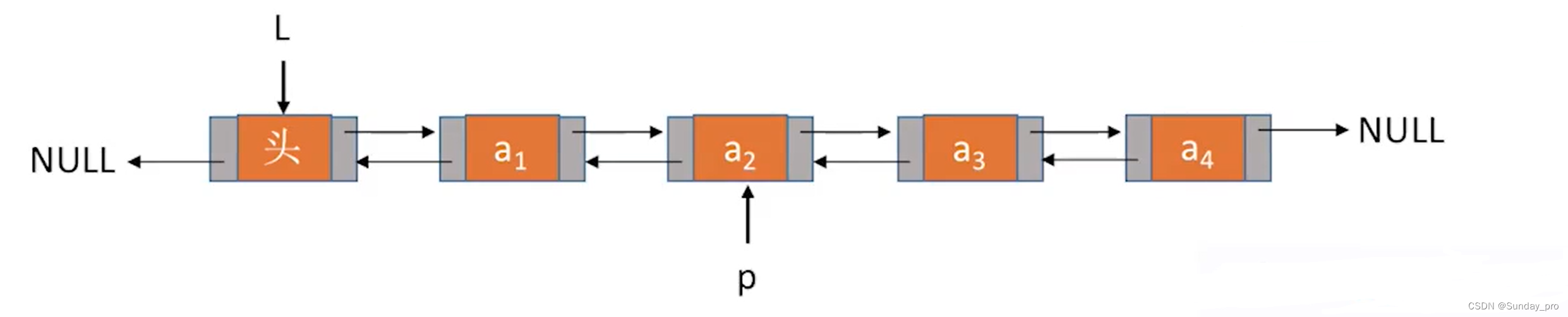
双链表的定义
双链表的结点中有两个指针prior和next,分别指向前驱结点和后继结点。
typedef struct DNode {
Elemtype data; //数据域
struct DNode *prior; //前驱指针
struct DNode *next; //后驱指针
} *DLinkList;双链表的基本操作
一、初始化
双链表与单链表一样,为了操作方便也可以加入头结点,那么初始化双链表其实就是定义一个头结点,然后将指针域置空。只不过双链表需要将前驱指针和后驱指针都置空。
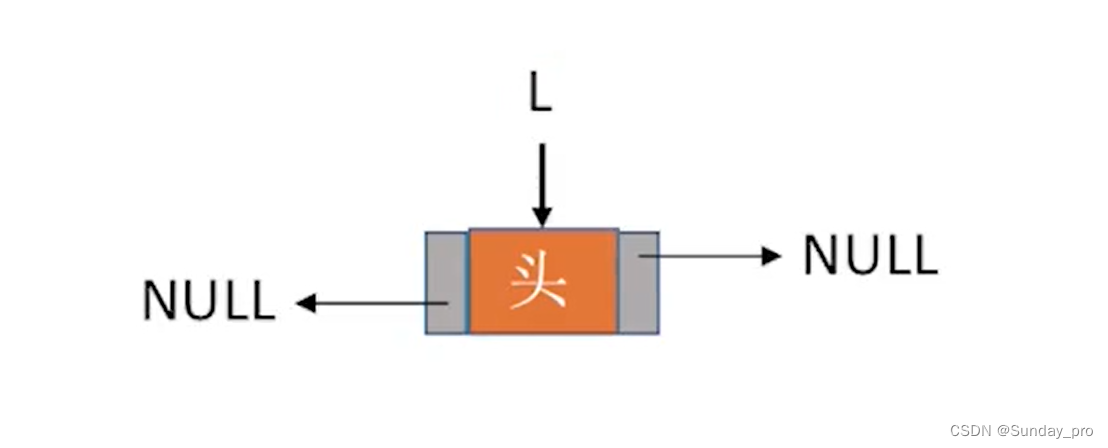
void InitDLinkList(DLinkList L){
//创建一个头结点
DLinkList p = (DLinkList) malloc(sizeof(DLinkList));
p->prior = NULL; //头结点的前驱永远都是NULL
p->next = NULL;
}二、插入操作
在双链表中p所指的结点之后插入结点s,其指针的变化过程如下图所示:

思路分析:
- 将s的next指针指向p的next指针所指的结点,即s的next指针指向p后继结点。
- 将s的prior指针指向p,即s的prior指针指向p所指的结点。
- 将p的next指针指向s,即p的next指针指向s。
- 将p后继结点的prior指针指向s,即p后继结点的prior指针指向s。
若p是最后一个结点,则p后继结点的prior指针指向s操作不需要,因为此时p->next = NULL.
代码实现:
//在p结点之后插入结点s
DLinkList InsertNewNode(DLinkList L) {
DLinkList p = (DLinkList) malloc(sizeof(DLinkList));
p = L;
int j = 0;
int pos;
printf("请输入需要插入新结点的位置:");
scanf("%d", &pos);
while (j < pos - 1 && p != NULL) { //遍历到site - 1结点处
p = p->next;
j++;
}
//创建需要插入的结点s
DLinkList s = (DLinkList) malloc(sizeof(DLinkList));
printf("请输人需要插入的结点:");
scanf("%d", &s->data);
s->next = p->next;
p->next->prior = s;
p->next = s;
s->prior = p;
return p;
}例:在双链表{10,30,40,50}中第一个结点后添加数据域为20的新结点,则插入操作完成之后的链表应为{10,20,30,40,50}

三、建立双链表
双链表的建立同样也有两种方法,分别为头插法和尾插法。
1.头插法
对于每个元素,创建一个新结点,并将其插入到头结点之后,使新结点成为新的头结点。
最后创建成功的双链表的顺序和输入的顺序相反,即为逆序的。
头插法的时间复杂度为O(1)。
代码实现:
//利用头插法创建双链表
DLinkList Init_DLinkList_head() {
//创建一个头结点
DLinkList p = (DLinkList) malloc(sizeof(DLinkList));
p->prior = NULL; //头结点的前驱永远都是NULL
p->next = NULL;
int length = 0; 记录双链表的长度
int val = -1;
while (true) {
printf("请输入要插入链表的元素:");
scanf("%d", &val);
if (val == -1) //输入结束的标志
break;
//创建新的结点
DLinkList s = (DLinkList) malloc(sizeof(DLinkList));
s->data = val; //将元素输入到新结点的数据域中
s->next = p->next;
s->prior = p;
p->next = s;
length++;
}
printf("链表的长度为:%d\n", length);
return p;
}例:输入元素的顺序为10,20,30,40,50;则创建的链表应为{50,40,30,20,10}

2.尾插法
对于每个元素,创建一个新结点,并将其插入到头结点之后的尾部,更新尾结点的next指针和新结点的prior指针。遍历完成后,返回头结点的next指针,即为新链表的头结点。
尾插法的时间复杂度为O(n),因为需要遍历整个双链表找到尾节点。
代码实现:
//利用尾插法创建双链表
DLinkList Init_DLinkList_tail() {
DLinkList head = (DLinkList) malloc(sizeof(DLinkList));
head->prior = NULL;
head->next = NULL;
int val = -1;
int length = 0;
//创建尾结点
DLinkList ptr = (DLinkList) malloc(sizeof(DLinkList));
ptr = head; //初始状态下头结点和尾结点相同
while (true) {
printf("请输入要插入链表的元素:");
scanf("%d", &val);
if (val == -1) // 输入结束的标志
break;
DLinkList s = (DLinkList) malloc(sizeof(DLinkList));
s->data = val;
s->next = NULL; //将新结点的后驱结点置空,目的是保证尾部结点后驱结点始终为NULL
ptr->next = s;
s->prior = ptr;
ptr = s; //更新尾部结点
length++;
}
printf("链表的长度为:%d\n", length);
return head;
}例: 输入元素的顺序为10,20,30,40,50;则创建的链表应为{10,20,30,40,50}

针对于上述两种方法可以根据具体需求选择使用:
头插法适用于需要频繁插入操作的场景;
尾插法适用于需要保持顺序的场景。
四、查找操作
双链表的查找分为按值查找和按位查找。
1.按值查找
此种方法无需用到前驱指针,所以查找方法和单链表的查找一样,可以类比学习。
基本思路:从双链表中的第一个结点出发,顺时针next域逐个往下搜索,直到找到第i个结点为止,否则返回最后一个结点指针域NULL。
平均时间复杂度:O(n)
代码实现:
//按值查找
void SearchList_value(DLinkList L) {
DLinkList p = (DLinkList) malloc(sizeof(DLinkList));
p = L->next; //从头结点下一个结点开始
int j = 1;
int value;
printf("请输入需要查找的值:");
scanf("%d", &value);
while (p != NULL && p->data != value) {
p = p->next;
j++;
}
//如果p结点变为空了则说明还是没有目标元素值
if(p == NULL){
printf("没有找到目标元素!\n");
return;
}
printf("元素%d是链表中第%d位元素。\n", value, j);
}成功查找到目标元素

查找失败!

2.按位查找
从头节点开始,依次访问每个节点,直到找到目标位置的节点。
如果目标位置是第 i 个节点,需要访问 i−1 次 next 指针,或者访问n−i 次 prior 指针(n 为链表长度)。
按位查找的时间复杂度为 O(n)
代码实现:
//按位查找
void SearchList_position(DLinkList L) {
DLinkList p = (DLinkList) malloc(sizeof(DLinkList));
p = L->next; //从头结点下一个结点开始
int j = 1;
int pos;
printf("请输入需要查找结点的位置:");
scanf("%d", &pos);
while (p != NULL && j < pos) {
p = p->next;
j++;
}
if (p == NULL) {
printf("没有找到目标结点!\n");
return;
}
printf("第%d位结点的元素是%d\n", pos, p->data);
}成功查找到目标位置元素!

查找失败!

思考
对于链表长度很大的双链表,在使用按位查找位序较为靠后的元素时我们还可以考虑从尾结点开始查找,因为双链表可以通过前驱指针找到上一个结点,这个是单链表所没有的。虽然首先会遍历到双链表的尾部然后再从尾部开始查找,那么可能会疑问这个首先还要遍历到尾部,这个消耗的时间是不是更长?其实不然,链表遍历的时间是很短的,相较于每个结点的查找遍历的时间性价比很高。
如果从尾结点开始查找的位置是 k,而链表的长度为 n,那么从头结点开始查找的位置就是 n−k−1。
五、删除操作
双链表删除结点时,只需遍历链表找到要删除的结点,然后将该节点从表中摘除即可。

代码实现:
//删除结点操作
void DeleteNode(DLinkList L) {
DLinkList p = (DLinkList) malloc(sizeof(DLinkList));
p = L; //指向头指针
int j = 0;
int site;
printf("请输入需要删除结点的位置:");
scanf("%d", &site);
while (p != NULL && j < site - 1) {
p = p->next;
j++;
}
if (NULL == p) {
printf("要删除的结点超过链表的长度!\n");
return;
}
DLinkList s = (DLinkList) malloc(sizeof(DLinkList));
s = p->next; // 存储要删除的结点
int num = s->data;
DLinkList q = (DLinkList) malloc(sizeof(DLinkList));
q = s->next; //q指向要删除的结点下一个结点
//将要删除的结点从双链表中摘除
q->prior = p;
p->next = q;
free(s); // 释放被删除结点的空间
printf("删除的结点数据为:%d\n", num);
}成功删除操作

删除失败!

六、遍历打印链表操作
从单链表的第一个结点开始,依次遍历输出结点的数据直到最后一个结点。
代码实现:
//遍历并打印双链表
void PrintDLinkList(DLinkList L) {
int i;
DLinkList p = (DLinkList) malloc(sizeof(DLinkList));
p = L->next;
while (p != NULL) {
printf("%d ", p->data);
p = p->next;
}
}
总结
单链表:
- 单链表中的每个节点包含一个数据元素和一个指向下一个节点的指针。
- 单链表只能从头结点开始依次遍历到尾节点,不能直接访问前一个节点。
- 删除节点时,需要找到待删除节点的前一个节点,进行指针调整。
- 插入节点时,只需要调整指针即可。
- 单链表相对于双链表占用的内存空间更小。
双链表:
- 双链表中的每个节点包含一个数据元素,一个指向前一个节点的指针和一个指向下一个节点的指针。
- 双链表可以从头结点或尾节点开始遍历,也可以直接访问前一个节点。
- 删除节点时,不需要找到待删除节点的前一个节点,可以直接根据前后指针进行删除。
- 插入节点时,需要调整前后指针。
- 双链表相对于单链表占用的内存空间更大,因为每个节点需要存储额外的指针。
总的来说,单链表适合在内存空间有限的情况下使用,而双链表适合需要频繁进行节点的插入和删除操作的情况下使用。选择使用哪种链表取决于具体的应用场景和需求。















 5747
5747











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









