







问答总结
- AlexNet网络中的LRN机制是怎样的?
- VGGNet网络的特点是什么,他为什么使用多层 3 × 3 3 \times 3 3×3卷积核的卷积层串联而不直接使用更大的卷积核。
- GoogleNet中的Inception和辅助分支是怎样的,如何理解它们的作用?
- 残差网络问答总结
文章目录
一、LeNet-5
1、模型结构

LeNet-5在1998年提出,是第一个较为成功应用的卷积神经网络。其结构如下:
- 输入层: 32 × 32 32 \times 32 32×32
- 卷积层1:
6
6
6个
5
×
5
5 \times 5
5×5的卷积核,卷积核步长
s
t
r
i
d
e
=
1
stride=1
stride=1. 因此输出为
28
×
28
×
6
28 \times 28 \times 6
28×28×6 +
激活函数 - 池化层1: 2 × 2 2\times 2 2×2,池化步长 s t r i d e = 2 stride=2 stride=2. 因此输出为 14 × 14 × 6 14 \times 14 \times 6 14×14×6.
- 卷积层2:
6
6
6个
5
×
5
5 \times 5
5×5的卷积核,卷积核步长
s
t
r
i
d
e
=
1
stride=1
stride=1. 因此输出为
10
×
10
×
16
10 \times 10 \times 16
10×10×16 +
激活函数 - 池化层2: 2 × 2 2 \times 2 2×2, 池化步长 s t r i d e = 2 stride=2 stride=2.因此输出为 5 × 5 × 16 5 \times 5 \times 16 5×5×16.
- 全连接层1:
W
∈
R
400
×
120
W \in R^{400 \times 120}
W∈R400×120+
激活函数 - 全连接层2:
W
∈
R
120
×
84
W \in R^{120 \times 84}
W∈R120×84+
激活函数 - 全连接层3: W ∈ R 84 × 10 W \in R^{84 \times 10} W∈R84×10
- softMax层
2、一些说明
- LeNet-5参数数量大约
6W个 - 最开始提出LeNet-5最后不使用softMax,但是现在softMax成为了分类任务的标准配置。
- 刚开始激活函数使用sigmoid,但是现在使用relu.
二、AlexNet
1、模型结构

- 输入层: 227 × 227 × 3 227 \times 227 \times 3 227×227×3
- 卷积层1:
96
96
96个
11
×
11
11 \times 11
11×11的卷积核,步长
s
t
r
i
d
e
=
4
stride = 4
stride=4. 因此输出
55
×
55
×
96
55 \times 55 \times 96
55×55×96 +
relu+局部响应归一化(local size=5) - 池化层1: 3 × 3 3 \times 3 3×3, 步长 s t r i d e = 2 stride=2 stride=2, 因此输出为 27 × 27 × 96 27 \times 27 \times 96 27×27×96.
- 卷积层2: 256个
5
×
5
5 \times 5
5×5的卷积核,步长
s
t
r
i
d
e
=
1
stride=1
stride=1, 填充Same Padding, 使得前后大小不变. 因此输出为
27
×
27
×
256
27 \times 27 \times 256
27×27×256. +
relu+局部响应归一化(local size = 5) - 池化层2: 3 × 3 3 \times 3 3×3, 步长 s t r i d e = 2 stride = 2 stride=2, 因此输出为 13 × 13 × 256 13 \times 13 \times 256 13×13×256
- 卷积层3: 384个
3
×
3
3 \times 3
3×3的卷积核, 步长
s
t
r
i
d
e
=
1
stride=1
stride=1, 填充Same Padding. 因此输出为
13
×
13
×
384
13 \times 13 \times 384
13×13×384 .+
relu - 卷积层4: 384个
3
×
3
3 \times 3
3×3的卷积核, 步长
s
t
r
i
d
e
=
1
stride=1
stride=1, 填充Same Padding. 因此输出为
13
×
13
×
384
13 \times 13 \times 384
13×13×384. +
relu - 卷积层5:
256
256
256个
3
×
3
3 \times 3
3×3的卷积核,步长
s
t
r
i
d
e
=
1
stride=1
stride=1, 填充Same Padding. 因此输出为
13
×
13
×
256
13 \times 13 \times 256
13×13×256 +
relu - 池化层3: 3 × 3 3\times3 3×3, 步长 s t r i d e = 2 stride =2 stride=2, 因此输出为 6 × 6 × 256 6 \times 6 \times 256 6×6×256.
- 全连接层1:
W
∈
R
9216
×
4096
W \in R^{9216 \times 4096}
W∈R9216×4096 +
relu+dropout - 全连接层2:
W
∈
R
4096
×
4096
W \in R^{4096 \times 4096}
W∈R4096×4096 +
relu+dropout - 全连接层3: W ∈ R 4096 × 1000 W \in R^{4096 \times 1000} W∈R4096×1000
- softMax层
2、一些说明
-
局部响应归一化机制(实践中发现,作用很小):
AlexNet网络引入了局部响应归一化机制,模拟神经生物学上一个叫做侧抑制的功能:即被激活的神经元会抑制相邻神经元。其计算方法如下:
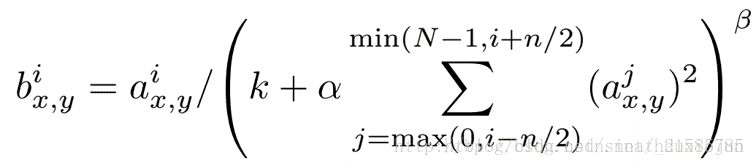
其中 a i ( x , y ) a^i(x,y) ai(x,y)表示第 a a a张图片,第 i i i个通道, 位置为 ( x , y ) (x,y) (x,y)。 一般 k = 2 , α = 1 e − 4 , b e t a = 0.75 k=2, \alpha=1e-4, beta=0.75 k=2,α=1e−4,beta=0.75.

归一化过程如上图所示,红色点可表示为 a i ( x , y ) a^i(x,y) ai(x,y), 其使用虚线上的所有点进行归一化。top5和top-1错误率分别降低了1.4%和1.2%。 -
重叠池化机制:
令池化过程中卷积核移动步长为 s s s,卷积核大小为 k k k, 重叠池化操作即 s ≤ k s \le k s≤k, 在AleNet中, s = 2 , z = 3 s=2, z=3 s=2,z=3.关于为什么使用重叠池化机制,可能是AlexNet模型采用Max Pooling, 即一个区域只保留了一个位置的结果,普通最大池化或许会丢掉很多信息,重叠池化一定程度上可以保留一些信息。这个方案分别减少了top-5和top-1错误率的0.4%和0.3%
-
现在流行的Dropout、relu激活函数都是该模型首发的。
-
模型总体的参数大概为240M。
三、VGGNet
1、模型结构

2、一些说明
-
VGG模型有两个比较明显的特点: (1) 网络深度加深。(2) 只使用 3 × 3 3 \times 3 3×3的卷积核,且步长 s t r i d e = 1 stride=1 stride=1, p a d = 1 pad=1 pad=1(保持形状), M a x P o o l s t r i d e = 2 Max \ Pool \ stride=2 Max Pool stride=2.
-
使用 3 × 3 3 \times 3 3×3的卷积核,两层串联相当于感知野为 5 × 5 5 \times 5 5×5, 三层串联相当于感知野为 7 × 7 7 \times 7 7×7
-
为什么要用三层 3 × 3 3 \times 3 3×3的卷积层串联不使用一层 7 × 7 7 \times 7 7×7的卷积层呢? 是因为前者参数较少, 3 ( 3 2 C ) < 7 2 C 3(3^2C) < 7^2C 3(32C)<72C, 其中 C C C为通道数。
-
VGG中不再采用LRN机制
-
共包含参数约为550M。
四、GoogleNet
1、模型结构

- GoogleNet有22层深,且有两个辅助分支。
2、一些说明
-
GoogleNet也被称作Inception V1. 参数为5M.
-
Inception Module:

-
核心思想: 采用多种尺寸卷积核提取图像不同尺度信息最后进行融合,以得到图像更好的表示

直观上理解,比如上方两只猫,我们提取猫脸的信息,但是两个猫脸大小不一样,就需要不同尺寸卷积核。 -
改进版理解:加入了 1 × 1 1 \times 1 1×1 的卷积核的卷积层, 是为了进行降维,减少Inception模块输出通道数量.
-
-
辅助SoftMax分支:

- 训练时: l o s s = l o s s 2 + 0.3 l o s s 1 + 0.3 l o s s 0 loss = loss_2+0.3loss_1 + 0.3loss_0 loss=loss2+0.3loss1+0.3loss0, 这样可以一定程度上避免梯度消失。
- 将辅助输出作为分类,起到模型融合作用。
- 测试时: 辅助分支会被去掉
- 辅助分支对模型的提升主要体现在训练后期
五、ResNet(重点)

残差网络可以说是引起了深度学习的革命,笔者在以前读NLP相关论文时,便有很多模型借用了残差机制,因此特地写一篇博客了解残差网络。
六、模型复杂度

- 横轴代表时间复杂度
- 纵轴代表准确率
- 圆大小代表模型大小
参考资料
[1] 经典卷积神经网络结构——LeNet-5、AlexNet、VGG-16
[2] 常见的视觉现象
[3] GoogLeNet中的inception结构,你看懂了吗
[4] 你必须要知道CNN模型:ResNet
[5] cs231n课程pdf















 421
421











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









