










淘宝双11数据分析与预测
一、 案例简介
Spark课程实验案例:淘宝双11数据分析与预测课程案例,由厦门大学数据库实验室团队开发,旨在满足全国高校大数据教学对实验案例的迫切需求。本案例涉及数据预处理、存储、查询和可视化分析等数据处理全流程所涉及的各种典型操作,涵盖Linux、MySQL、Hadoop、Hive、Sqoop、Eclipse、ECharts、Spark等系统和软件的安装和使用方法。案例适合高校(高职)大数据教学,可以作为学生学习大数据课程后的综合实践案例。通过本案例,将有助于学生综合运用大数据课程知识以及各种工具软件,实现数据全流程操作。各个高校可以根据自己教学实际需求,对本案例进行补充完善。
二、 案例目的
- 熟悉Linux系统、MySQL、Hadoop、Hive、Sqoop、Spark等系统和软件的安装和使用;
- 了解大数据处理的基本流程;
- 熟悉数据预处理方法;
- 熟悉在不同类型数据库之间进行数据相互导入导出;
- 熟悉使用JSP语言搭建动态Web工程;
- 熟悉使用Spark MLlib进行简单的分类操作。
三、 实验环境准备
| 所需知识储备 | Windows操作系统、Linux操作系统、大数据处理架构Hadoop的关键技术及其基本原理、列族数据库HBase概念及其原理、数据仓库概念与原理、关系型数据库概念与原理 |
|---|---|
| 训练技能 | 双操作系统安装、虚拟机安装、Linux基本操作、Hadoop安装、HBase安装、Sqoop安装、Eclipse安装 |
| 任务清单 | 1. 安装Linux系统;2. 安装Hadoop;3. 安装MySQL;4. 安装Hive;5. 安装Sqoop;6. 安装Spark;7. 安装Eclipse |
| 3.1 数据集 | |
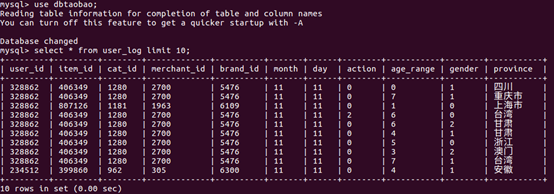
| 本案例采用的数据集压缩包为data_format.zip,该数据集压缩包是淘宝2015年双11前6个月(包含双11,5000万条记录)的交易数据(交易数据有偏移,但是不影响实验的结果),里面包含3个文件,分别是用户行为日志文件user_log.csv 、回头客训练集train.csv 、回头客测试集test.csv. | |
| 从user_log.csv中提取的150万条记录组成Tuser_log.csv【第1~1500000条记录】。 | |
| 数据说明: |
- user_id
买家id - item_id
商品id - cat_id
商品类别id - merchant_id
卖家id - brand_id
品牌id - month
交易时间:月 - day
交易时间:日 - action
行为,取值范围{0,1,2,3};
0表示点击,1表示加入购物车,2表示购买,3表示关注商品 - age_range
买家年龄分段:1表示年龄<18,
2表示年龄在[18,24],
3表示年龄在[25,29],
4表示年龄在[30,34],
5表示年龄在[35,39],
6表示年龄在[40,49],
7和8表示年龄>=50,
0和NULL则表示未知 - gender
性别:
0表示女性,1表示男性,2和NULL表示未知 - province
收获地址省份
回头客训练集train.csv和回头客测试集test.csv,训练集和测试集拥有相同的字段,字段定义如下:
- user_id
买家id - age_range
买家年龄分段:
1表示年龄<18,
2表示年龄在[18,24],
3表示年龄在[25,29],
4表示年龄在[30,34],
5表示年龄在[35,39],
6表示年龄在[40,49],
7和8表示年龄>=50,
0和NULL则表示未知 - gender
性别:0表示女性,1表示男性,2和NULL表示未知 - merchant_id
商家id - label
是否是回头客:
0值表示不是回头客,1值表示回头客,-1值表示该用户已经超出我们所需要考虑的预测范围。NULL值只存在测试集,在测试集中表示需要预测的值。
3.2 案例任务
- 安装Linux操作系统
- 安装关系型数据库MySQL
- 安装大数据处理框架Hadoop
- 安装数据仓库Hive
- 安装Sqoop
- 安装Eclipse
- 安装 Spark
- 对文本文件形式的原始数据集进行预处理
- 把文本文件的数据集导入到数据仓库Hive中
- 对数据仓库Hive中的数据进行查询分析
- 使用Sqoop将数据从Hive导入MySQL
- 利用Eclipse搭建动态Web应用
- 利用ECharts进行前端可视化分析
- 利用Spark MLlib进行回头客行为预测
四、 本地数据集上传到数据仓库Hive
| 所需知识储备 | Linux系统基本命令、Hadoop项目结构、分布式文件系统HDFS概念及其基本原理、数据仓库概念及其基本原理、数据仓库Hive概念及其基本原理 |
|---|---|
| 训练技能 | Hadoop的安装与基本操作、HDFS的基本操作、Linux的安装与基本操作、数据仓库Hive的安装与基本操作、基本的数据预处理方法 |
| 任务清单 | 1. 安装Linux系统;2. 数据集下载与查看;3. 数据集预处理;4. 把数据集导入分布式文件系统HDFS中;5. 在数据仓库Hive上创建数据库 |
| 4.1 数据集的准备 | |
| 因为本教程是采用hadoop用户名登录了Linux系统,所以,下载后的文件会被浏览器默认保存到”/home/hadoop/下载/”这目录下面。 | |
| 现在,请在Linux系统中打开一个终端(可以使用快捷键Ctrl+Alt+T),执行下面命令: | |
 | |
| 通过上面命令,就进入到了data_format.zip文件所在的目录,并且可以看到有个data_format.zip文件。 | |
| 下面需要把data_format.zip进行解压缩,我们需要首先建立一个用于运行本案例的目录dbtaobao,请执行以下命令: | |
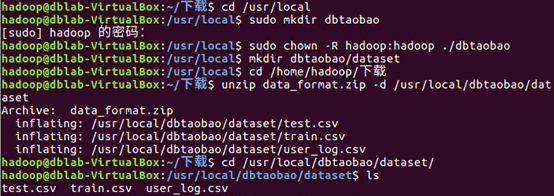 | |
| 就可以看到在dataset目录下有三个文件:test.csv、train.csv、user_log.csv | |
| 我们执行下面命令取出user_log.csv前面5条记录看一下,执行如下命令: | |
 | |
| 4.2 数据集的预处理 |
- 删除文件第一行记录,即字段名称
user_log.csv的第一行都是字段名称,我们在文件中的数据导入到数据仓库Hive中时,不需要第一行字段名称,因此,这里在做数据预处理时,删除第一行

- 获取数据集中双11的前1500000条数据
由于数据集中交易数据太大,这里只截取数据集中在双11的前1500000条交易数据作为小数据集small_user_log.csv
下面我们建立一个脚本文件完成上面截取任务,请把这个脚本文件放在dataset目录下和数据集user_log.csv:

上面使用vim编辑器新建了一个predeal.sh脚本文件,请在这个脚本文件中加入下面代码:

下面就可以执行predeal.sh脚本文件,截取数据集中在双11的前1500000条交易数据作为小数据集small_user_log.csv,命令如下:

- 导入数据库
下面要把small_user_log.csv中的数据最终导入到数据仓库Hive中。为了完成这个操作,我们会首先把这个文件上传到分布式文件系统HDFS中,然后,在Hive中创建两个个外部表,完成数据的导入。
a. 启动HDFS

然后,执行jps命令看一下当前运行的进程,如果出现下面这些进程,说明Hadoop启动成功了。

b. 把user_log.csv上传到HDFS中
现在,我们要把Linux本地文件系统中的user_log.csv上传到分布式文件系统HDFS中,存放在HDFS中的“/dbtaobao/dataset”目录下。
首先,请执行下面命令,在HDFS的根目录下面创建一个新的目录dbtaobao,并在这个目录下创建一个子目录dataset,如下:

然后,把Linux本地文件系统中的small_user_log.csv上传到分布式文件系统HDFS的“/dbtaobao/dataset”目录下,命令如下:

下面可以查看一下HDFS中的small_user_log.csv的前10条记录,命令如下:
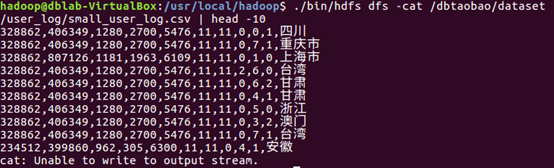
c.在Hive上创建数据库
因为需要借助于MySQL保存Hive的元数据,所以,请首先启动MySQL数据库:

由于Hive是基于Hadoop的数据仓库,使用HiveQL语言撰写的查询语句,最终都会被Hive自动解析成MapReduce任务由Hadoop去具体执行,因此,需要启动Hadoop,然后再启动Hive。由于前面我们已经启动了Hadoop,所以,这里不需要再次启动Hadoop。下面,在这个新的终端中执行下面命令进入Hive:
下面,我们要在Hive中创建一个数据库dbtaobao,命令如下:

d. 创建外部表
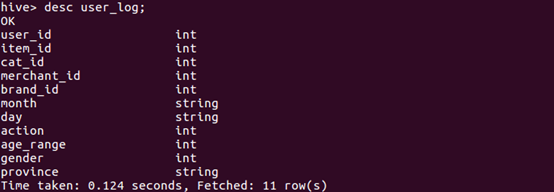
这里我们要分别在数据库dbtaobao中创建一个外部表user_log,它包含字段(user_id,item_id,cat_id,merchant_id,brand_id,month,day,action,age_range,gender,province),请在hive命令提示符下输入如下命令:

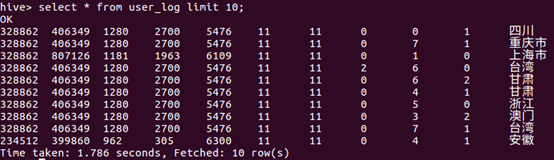
e. 查询数据
上面已经成功把HDFS中的“/dbtaobao/dataset/user_log”目录下的small_user_log.csv数据加载到了数据仓库Hive中,我们现在可以使用下面命令查询一下:
五、 Hive数据分析
| 所需知识储备 | 数据仓库Hive概念及其基本原理、SQL语句、数据库查询分析 |
|---|---|
| 训练技能 | 数据仓库Hive基本操作、创建数据库和表、使用SQL语句进行查询分析 |
| 任务清单 | 1. 启动Hadoop和Hive;2. 创建数据库和表;3. 简单查询分析;4. 查询条数统计分析;5. 关键字条件查询分析;6. 根据用户行为分析;7. 用户实时查询分析 |
| 5.1 基础操作Hive | |
| 在“hive>”命令提示符状态下执行下面命令: | |
 | |
 | |
| 可以执行下面命令查看表的简单结构: | |
 | |
| 5.2 简单查询分析 | |
| 简单的指令: | |
 | |
| 查询前20个交易日志中购买商品时的时间和商品的种类 | |
 | |
| 在表中查询可以利用嵌套语句,如果列名太复杂可以设置该列的别名,以简化我们操作的难度,以下我们可以举个例子: | |
 | |
| 5.3 查询条数统计分析 | |
| (1)用聚合函数count()计算出表内有多少条行数据 | |
 | |
| (2)在函数内部加上distinct,查出uid不重复的数据有多少条 | |
 | |
| (3)查询不重复的数据有多少条(为了排除客户刷单情况) | |
 | |
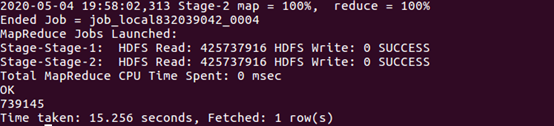 | |
| 可以看出,排除掉重复信息以后,只有739145条记录 | |
| 5.4 关键字条件查询分析 | |
| 1.以关键字的存在区间为条件的查询 | |
| (1)查询双11那天有多少人购买了商品 | |
 | |
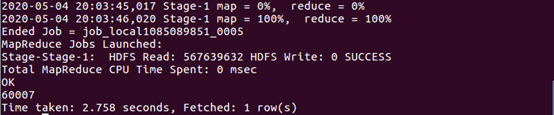 | |
| 2.关键字赋予给定值为条件,对其他数据进行分析 | |
| 取给定时间和给定品牌,求当天购买的此品牌商品的数量 | |
 | |
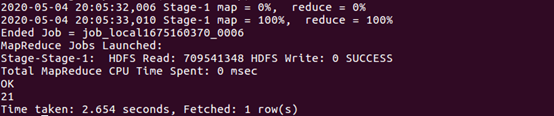 | |
| 5.5 根据用户行为分析 | |
| 1.查询一件商品在某天的购买比例或浏览比例 | |
| 查询有多少用户在双11购买了商品 | |
 | |
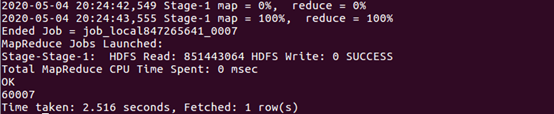 | |
| 查询有多少用户在双11点击了该店 | |
 | |
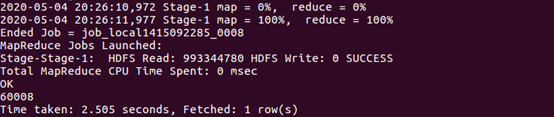 | |
| 根据上面语句得到购买数量和点击数量,两个数相除即可得出当天该商品的购买率 | |
| 2.查询双11那天,男女买家购买商品的比例 | |
| 查询双11那天女性购买商品的数量 | |
 | |
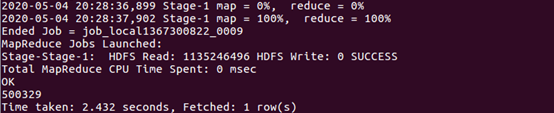 | |
| 查询双11那天男性购买商品的数量 | |
 | |
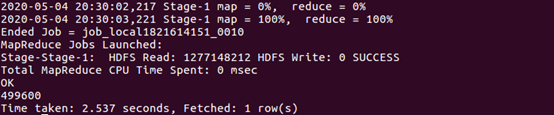 | |
| 上面两条语句的结果相除,就得到了要要求的比例。 | |
| 3.给定购买商品的数量范围,查询某一天在该网站的购买该数量商品的用户id |
查询某一天在该网站购买商品超过5次的用户id


5.6 用户实时查询分析
不同的品牌的浏览次数
- 创建新的数据表进行存储

- 导入数据

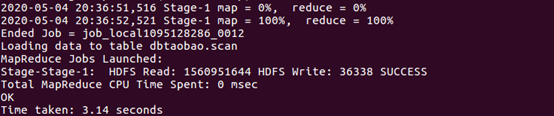
- 显示结果(显示前20条)

六、 将数据从Hive导入到MySQL
| 所需知识储备 | 数据仓库Hive概念与基本原理、关系数据库概念与基本原理、SQL语句 |
|---|---|
| 训练技能 | 数据仓库Hive的基本操作、关系数据库MySQL的基本操作、Sqoop工具的使用方法 |
| 任务清单 | 1. Hive预操作;2. 使用Sqoop将数据从Hive导入MySQL |
| 6.1 Hive预操作 | |
| 1、创建临时表inner_user_log和inner_user_info | |
 | |
| 这个命令执行完以后,Hive会自动在HDFS文件系统中创建对应的数据文件“/user/hive/warehouse/dbtaobao.db/inner_user_log”。 | |
| 2、将user_log表中的数据插入到inner_user_log, | |
| 在[大数据案例-步骤一:本地数据集上传到数据仓库Hive(待续)]中,我们已经在Hive中的dbtaobao数据库中创建了一个外部表user_log。下面把dbtaobao.user_log数据插入到dbtaobao.inner_user_log表中,命令如下 | |
 | |
 | |
| 请执行下面命令查询上面的插入命令是否成功执行: | |
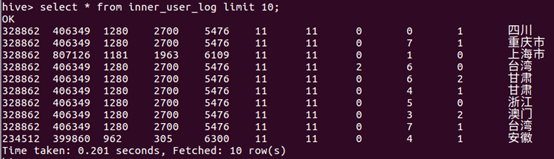 | |
| 6.2 使用Sqoop将数据从Hive导入MySQL | |
| 1、启动Hadoop集群、MySQL服务 | |
| 前面我们已经启动了Hadoop集群和MySQL服务。这里请确认已经按照前面操作启动成功。 | |
| 2、将前面生成的临时表数据从Hive导入到 MySQL 中,包含如下四个步骤。 |
(1)登录 MySQL
请在Linux系统中新建一个终端,执行下面命令:

执行上面命令以后,就进入了“mysql>”命令提示符状态。
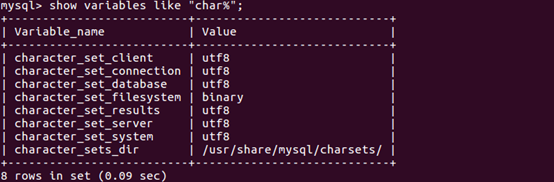
(2)创建数据库

下面命令查看数据库的编码,确认当前编码为utf8,没有问题,
(3)创建表
下面在MySQL的数据库dbtaobao中创建一个新表user_log,并设置其编码为utf-8:

sqoop抓数据的时候会把类型转为string类型,所以mysql设计字段的时候,设置为varchar。
创建成功后,输入下面命令退出MySQL:

(4)导入数据(执行时间:20秒左右)
注意,刚才已经退出MySQL,回到了Shell命令提示符状态。下面就可以执行数据导入操作,
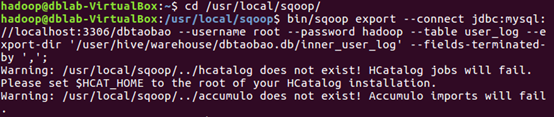

字段解释:
./bin/sqoop export ##表示数据从 hive 复制到 mysql 中
–connect jdbc:mysql://localhost:3306/dbtaobao
–username root #mysql登陆用户名
–password hadoop#登录密码
–table user_log #mysql 中的表,即将被导入的表名称
–export-dir ‘/user/hive/warehouse/dbtaobao.db/user_log ‘ #hive 中被导出的文件
–fields-terminated-by ‘,’ #Hive 中被导出的文件字段的分隔符
3、查看MySQL中user_log或user_info表中的数据
下面需要再次启动MySQL,进入“mysql>”命令提示符状态:
然后执行下面命令查询user_action表中的数据:
从Hive导入数据到MySQL中,成功!
七、 利用Spark预测回头客行为
| 所需知识储备 | Spark、机器学习 |
|---|---|
| 训练技能 | Spark的安装与基本操作、利用Spark 自带的MLlib库,对数据集进行分类预测 |
| 任务清单 | 1. 安装Spark 2.预处理训练集和测试集3.使用支持向量机SVM分类器预测回客行为 |
| 7.1 预处理test.csv和train.csv数据集 | |
| 这里列出test.csv和train.csv中字段的描述,字段定义如下: |
- user_id
买家id - age_range
买家年龄分段:
1表示年龄<18,2表示年龄在[18,24],
3表示年龄在[25,29],4表示年龄在[30,34],
5表示年龄在[35,39],6表示年龄在[40,49],
7和8表示年龄>=50,0和NULL则表示未知 - gender
性别:0表示女性,1表示男性,2和NULL表示未知 - merchant_id
商家id - label
是否是回头客,0值表示不是回头客,1值表示回头客,-1值表示该用户已经超出我们所需要考虑的预测范围。NULL值只存在测试集,在测试集中表示需要预测的值。
这里需要预先处理test.csv数据集,把这test.csv数据集里label字段表示-1值剔除掉,保留需要预测的数据.并假设需要预测的数据中label字段均为1.

上面使用vim编辑器新建了一个predeal_test.sh脚本文件,请在这个脚本文件中加入下面代码:

下面就可以执行predeal_test.sh脚本文件,截取测试数据集需要预测的数据到test_after.csv,命令如下:

train.csv的第一行都是字段名称,不需要第一行字段名称,这里在对train.csv做数据预处理时,删除第一行

然后剔除掉train.csv中字段值部分字段值为空的数据。

下面就可以执行predeal_train.sh脚本文件,截取测试数据集需要预测的数据到train_after.csv,命令如下:

7.2 预测回头客 - 启动Hadoop后,将两个数据集分别存取到HDFS中

进入“mysql>”命令提示符状态,然后就可以输入下面的SQL语句完成表的创建:

- 启动Spark Shell
mysql-connector-java-*.zip是Java连接MySQL的驱动包,默认会下载到”~/下载/”目录
执行如下命令:


7.3 支持向量机SVM分类器预测回头客
1.导入需要的包
首先,我们导入需要的包:

2.读取训练数据
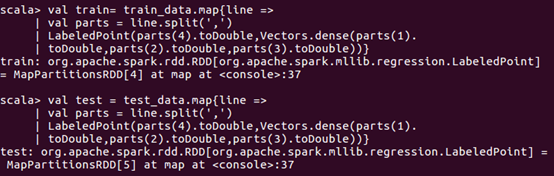
首先,读取训练文本文件;然后,通过map将每行的数据用“,”隔开,在数据集中,每行被分成了5部分,前4部分是用户交易的3个特征(age_range,gender,merchant_id),最后一部分是用户交易的分类(label)。把这里我们用LabeledPoint来存储标签列和特征列。LabeledPoint在监督学习中常用来存储标签和特征,其中要求标签的类型是double,特征的类型是Vector。

3.构建模型
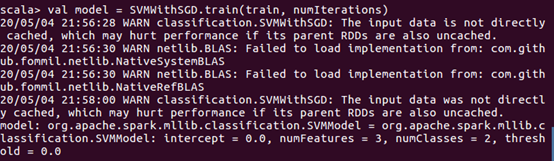
接下来,通过训练集构建模型SVMWithSGD。这里的SGD即著名的随机梯度下降算法(Stochastic Gradient Descent)。设置迭代次数为1000,除此之外还有stepSize(迭代步伐大小),regParam(regularization正则化控制参数),miniBatchFraction(每次迭代参与计算的样本比例),initialWeights(weight向量初始值)等参数可以进行设置。
4.评估模型
接下来,我们清除默认阈值,这样会输出原始的预测评分,即带有确信度的结果。
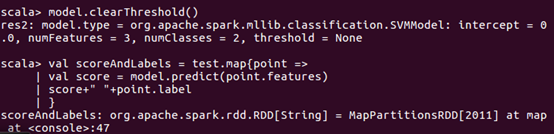

结果内容太长了,截取最后一部分。

如果我们设定了阀值,则会把大于阈值的结果当成正预测,小于阈值的结果当成负预测


把结果添加到mysql数据库中
现在我们上面没有设定阀值的测试集结果存入到MySQL数据中。


八、 利用ECharts进行数据可视化分析
| 所需知识储备 | 数据可视化、Java、JSP、JavaScript、HTML |
|---|---|
| 训练技能 | 利用JSP语言获取MySQL中的数据、搭建一个简单的动态Web应用、ECharts可视化应用 |
| 任务清单 | 1. 搭建tomcat+mysql+JSP开发环境2. 利用Eclipse新建可视化Web应用3. 前后端代码编写, 并添加ECharts可视化分析 |
| 8.1 搭建tomcat+mysql+JSP开发环境 |
- 下载tomcat
Tomcat 服务器是一个免费的开放源代码的Web 应用服务器,属于轻量级应用服务器,在中小型系统和并发访问用户不是很多的场合下被普遍使用,是开发和调试JSP 程序的首选。
查看Linux系统的Java版本,执行如下命令:

可以看出Linux系统中的Java版本是1.8版本,那么下载的tomcat也要对应Java的版本。这里下载apache-tomcat-8.5.24.zip

解压apache-tomcat-8.5.24.zip到用户目录~下,执行如下命令:
启动mysql
![[外链图片转存失败,源站可能有防盗在这里插入!链机制,建描述]议将图片上https://传(imblog.csdnimg-/2020050522093rvM1581.png75)(https//img-blog.csdnimg.cn/2020050522091581.png)]](https://img-blog.csdnimg.cn/20200505220937982.png)
8.2 利用Eclipse 新建可视化Web应用
1.打开Eclipse,点击“File”菜单,或者通过工具栏的“New”创建Dynamic Web Project,弹出向导对话框,填入Project name后,并点击”New Runtime”,如下图所示:


2.出现New Server Runtime Environment向导对话框,选择“Apache Tomcat v8.5”,点击next按钮,如下图:

3.选择Tomcat安装文件夹,如下图:


4.返回New Server Runtime Environment向导对话框,点击finish即可。如下图:

5.返回Dynamic Web Project向导对话框,点击finish即可。如下图:

6.这样新建一个Dynamic Web Project就完成了。在Eclipse中展开新建的MyWebApp项目,初始整个项目框架如下:

src文件夹用来存放Java服务端的代码,例如:读取数据库MySQL中的数据
WebContent文件夹则用来存放前端页面文件,例如:前端页面资源css、img、js,前端JSP页面


8.3 利用Eclipse 开发Dynamic Web Project应用
src目录用来存放服务端Java代码,WebContent用来存放前端页面的文件资源与代码。其中css目录用来存放外部样式表文件、font目录用来存放字体文件、img目录存放图片资源文件、js目录存放JavaScript文件,lib目录存放Java与mysql的连接库。

创建完所有的文件后,运行MyWebApp,查看我的应用。
首次运行MyWebApp,请按照如下操作,才能启动项目:
双击打开index.jsp文件,然后顶部Run菜单选择:Run As–>Run on Server

出现如下对话框,直接点击finish即可。

8.4 可视化结果
8.4.1 所有买家各消费行为对比

8.4.2 男女买家交易对比

8.4.3 男女买家各个年龄段交易对比

8.4.4 商品类别交易额对比

8.4.5 各省份的总成交量对比
















 4453
4453











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









