






实验环境搭建
创建hadoop用户
sudo useradd -m hadoop -s /bin/bash
sudo passwd hadoop
sudo adduser hadoop sudo
更改用户
登录hadoop (直接关机,再打开)
更改代码界面文字大小
代码界面右击===》profiles==》profile preference
更新apt
sudo apt-get update
点击左侧任务栏的【系统设置】(齿轮图标),选择【软件和更新】
点击 “下载自” 右侧的方框,选择【其他节点】
在列表中选中【mirrors.aliyun.com】,并点击右下角的【选择服务器】,会要求输入用户密码,输入即可。
接着点击关闭。
此时会提示列表信息过时,点击【重新载入】,
vim安装
sudo apt-get install vim
安装SSH、配置SSH无密码登陆
sudo apt-get install openssh-server
ssh localhost
此时会有如下提示(SSH首次登陆提示),输入 yes 。然后按提示输入密码 hadoop,这样就登陆到本机了。
SSH无密码登陆
首先退出刚才的 ssh,就回到了我们原先的终端窗口,然后利用 ssh-keygen 生成密钥,并将密钥加入到授权中:
exit
cd ~/.ssh/
ssh-keygen -t rsa //回车
cat ./id_rsa.pub >> ./authorized_keys
此时再用 ssh localhost 命令,无需输入密码就可以直接登陆了
可以用secureCRT
winscp上传软件到home/hadoop/Downloads目录下
安装Java环境
cd /usr/lib
sudo mkdir jvm
cd ~
cd Downloads
sudo tar -zxvf ./jdk-8u371-linux-x64.tar.gz -C /usr/lib/jvm
DK文件解压缩以后,可以执行如下命令到/usr/lib/jvm目录查看一下:
cd /usr/lib/jvm
ls
设置环境变量:
cd ~
vim ~/.bashrc //注意这里是一个文档,不为空,如果是空就说明前边有错误
在这个文件的开头位置,添加如下几行内容:
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_371
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
保存.bashrc文件并退出vim编辑器。然后,继续执行如下命令让.bashrc文件的配置立即生效:
source ~/.bashrc
可以使用如下命令查看是否安装成功:
java -version
如果能够在屏幕上返回如下信息,则说明安装成功:
hadoop@ubuntu:~$ java -version
java version "1.8.0_371"
Java(TM) SE Runtime Environment (build 1.8.0_371-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.162-b12, mixed mode)
安装 Hadoop3.3.5
cd ~
cd Downloads
sudo tar -zxvf ~/Downloads/hadoop-3.3.5.tar.gz -C /usr/local
cd /usr/local/
sudo mv ./hadoop-3.3.5/ ./hadoop
sudo chown -R hadoop ./hadoop
Hadoop 解压后即可使用。输入如下命令来检查 Hadoop 是否可用,成功则会显示 Hadoop 版本信息:
cd /usr/local/hadoop
./bin/hadoop version
Hadoop伪分布式配置
cd /usr/local/hadoop/etc/hadoop/
修改配置文件 core-site.xml
vim core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
修改配置文件 hdfs-site.xml:
vim hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>
配置完成后,执行 NameNode 的格式化:
cd /usr/local/hadoop
./bin/hdfs namenode -format
成功的话,会看到 "successfully formatted" 的提示,
接着开启 NameNode 和 DataNode 守护进程。
cd /usr/local/hadoop
./sbin/start-dfs.sh
若出现如下SSH提示,输入yes即可。
如果启动 Hadoop 时遇到输出非常多“ssh: Could not resolve hostname xxx”的异常情况,可通过设置 Hadoop 环境变量来解决。
然后在 ~/.bashrc 中,增加如下两行内容
vim ~/.bashrc
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
保存后,务必执行 source ~/.bashrc 使变量设置生效,
然后再次执行 ./sbin/start-dfs.sh 启动 Hadoop。
jps 来判断是否成功启动
若成功启动则会列出如下进程: "NameNode"、"DataNode" 和 "SecondaryNameNode",SecondaryNameNode
安装HBase
1.1 解压安装包hbase-2.5.4-bin.tar.gz至路径 /usr/local
cd ~
cd Downloads
sudo tar -zxvf ~/Downloads/hbase-2.5.4-bin.tar.gz -C /usr/local
1.2 将解压的文件名hbase-2.5.4改为hbase
cd /usr/local
sudo mv ./hbase-2.5.4 ./hbase
把hbase目录权限赋予给hadoop用户:
cd /usr/local
sudo chown -R hadoop ./hbase
1.3 配置环境变量
vim ~/.bashrc
如果没有引入过PATH请在~/.bashrc文件尾行添加如下内容:
export PATH=$PATH:/usr/local/hbase/bin
编辑完成后,再执行source命令使上述配置在当前终端立即生效,
source ~/.bashrc
1.4 添加HBase权限
cd /usr/local
sudo chown -R hadoop ./hbase
1.5 查看HBase版本,确定hbase安装成功,命令如下:
/usr/local/hbase/bin/hbase version
伪分布式模式配置
1.配置/usr/local/hbase/conf/hbase-env.sh。命令如下:
vim /usr/local/hbase/conf/hbase-env.sh
配置JAVA_HOME,HBASE_CLASSPATH,HBASE_MANAGES_ZK.
HBASE_CLASSPATH设置为本机HBase安装目录下的conf目录(即/usr/local/hbase/conf)
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_371
export HBASE_CLASSPATH=/usr/local/hbase/conf
export HBASE_MANAGES_ZK=true
2.配置/usr/local/hbase/conf/hbase-site.xml
用命令vi打开并编辑hbase-site.xml,命令如下:
vim /usr/local/hbase/conf/hbase-site.xml
修改hbase.rootdir,指定HBase数据在HDFS上的存储路径;
将属性hbase.cluter.distributed设置为true。
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://localhost:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
</configuration>
3. 接下来测试运行HBase。
第一步:首先登陆ssh,之前设置了无密码登陆,因此这里不需要密码;再切换目录至/usr/local/hadoop ;再启动hadoop,如果已经启动hadoop请跳过此步骤。命令如下:
ssh localhost
cd /usr/local/hadoop
./sbin/start-dfs.sh
输入命令jps,能看到NameNode,DataNode和SecondaryNameNode都已经成功启动,表示Hadoop启动成功.
第二步:切换目录至/usr/local/hbase;再启动HBase.命令如下:
cd /usr/local/hbase
bin/start-hbase.sh
进入shell界面:
bin/hbase shell
4.停止HBase运行,命令如下:
bin/stop-hbase.sh
安装Hive
1.找到apache-hive-3.1.3-bin.tar.gz文件,下载到本地。
cd Downloads
sudo tar -zxvf ./apache-hive-3.1.3-bin.tar.gz -C /usr/local
cd /usr/local/
sudo mv apache-hive-3.1.3-bin hive
sudo chown -R hadoop hive
2. 配置环境变量
vim ~/.bashrc
在该文件最前面一行添加如下内容:
export HIVE_HOME=/usr/local/hive
export PATH=$PATH:$HIVE_HOME/bin
export HADOOP_HOME=/usr/local/hadoop
保存退出后,运行如下命令使配置立即生效:
source ~/.bashrc
3. 修改/usr/local/hive/conf下的hive-site.xml
cd /usr/local/hive/conf
mv hive-default.xml.template hive-default.xml
使用vim编辑器新建一个配置文件hive-site.xml,
cd /usr/local/hive/conf
vim hive-site.xml
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true&useSSL=false</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hive</value>
<description>password to use against metastore database</description>
</property>
</configuration>
把上面的hive-site.xml配置信息拷贝到本地以后jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true&useSSL=false
这行配置信息里面的连接符&,需要替换成“&加上amp加上英文分号”这四个字符
安装MySQL
1。使用以下命令即可进行mysql安装,注意安装前先更新一下软件源以获得最新版本:
sudo apt update
sudo apt search mysql-server
sudo apt install -y mysql-server
启动和关闭mysql服务器:
service mysql start
service mysql stop
确认是否启动成功,mysql节点处于LISTEN状态表示启动成功:
sudo netstat -tap | grep mysql
进入mysql shell界面:
mysql -u root -p
解决利用sqoop导入MySQL中文乱码的问题
编辑配置文件。
sudo vi /etc/mysql/mysql.conf.d/mysqld.cnf
(2)在[mysqld的lc-messages-dir]下添加一行character_set_server=utf8
(3)重启MySQL服务。service mysql restart
(4)登陆MySQL,并查看MySQL目前设置的编码。
show variables like "char%";
2.下载MySQL JDBC连接驱动JAR包,
cd Downloads
sudo tar -zxvf mysql-connector-java-5.1.40.tar.gz
cp mysql-connector-java-5.1.40/mysql-connector-java-5.1.40-bin.jar /usr/local/hive/lib
3. 启动并登陆MySQL Shell
service mysql start
mysql -u root -p
4. 新建Hive数据库。
mysql> create database hive;
5. 配置MySQL允许Hive接入:
mysql> grant all on *.* to hive@localhost identified by 'hive';
mysql> flush privileges;
mysql>exit;
6. 升级元数据:
cd /usr/local/hive
./bin/schematool -initSchema -dbType mysql
7. 启动Hive
启动hive之前
cd /usr/local/hadoop
./sbin/start-dfs.sh
cd /usr/local/hive
./bin/hive
安装Eclipse
cd /usr/local
sudo tar -zxvf ~/Downloads/eclipse-4.7.0-linux.gtk.x86_64.tar.gz -C /usr/local
安装Spark(Local模式)
sudo tar -zxvf ~/Downloads/spark-3.4.0-bin-without-hadoop.tgz -C /usr/local/
cd /usr/local
sudo mv ./spark-3.4.0-bin-without-hadoop/ ./spark
sudo chown -R hadoop:hadoop ./spark
安装后,还需要修改Spark的配置文件spark-env.sh
cd /usr/local/spark
cp ./conf/spark-env.sh.template ./conf/spark-env.sh
编辑spark-env.sh文件(vim ./conf/spark-env.sh),在第一行添加以下配置信息:
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath)
通过运行Spark自带的示例,验证Spark是否安装成功。
cd /usr/local/spark
bin/run-example SparkPi 2>&1 | grep "Pi is"
过滤后的运行结果如下图示,可以得到π 的 5 位小数近似值:
启动Spark Shell
cd /usr/local/spark
bin/spark-shell
出现spark图形
淘宝双11数据分析与预测课程案例
步骤一:本地数据集上传到数据仓库Hive
数据的导入
本案例采用的数据集压缩包为data_format.zip
cd /home/hadoop/Downloads
ls
建立一个用于运行本案例的目录dbtaobao
cd /usr/local
ls
sudo mkdir dbtaobao
//这里会提示你输入当前用户(本教程是hadoop用户名)的密码
//下面给hadoop用户赋予针对dbtaobao目录的各种操作权限
sudo chown -R hadoop:hadoop ./dbtaobao
cd dbtaobao
//下面创建一个dataset目录,用于保存数据集
mkdir dataset
//下面就可以解压缩data_format.zip文件
cd ~ //表示进入hadoop用户的目录
cd Downloads
ls
unzip data_format.zip -d /usr/local/dbtaobao/dataset
cd /usr/local/dbtaobao/dataset
ls
现在你就可以看到在dataset目录下有三个文件:
test.csv、train.csv、user_log.csv
我们执行下面命令取出user_log.csv前面5条记录看一下
head -5 user_log.csv
可以看到,前5行记录如下:
user_id,item_id,cat_id,merchant_id,brand_id,month,day,action,age_range,gender,province
328862,323294,833,2882,2661,08,29,0,0,1,内蒙古
328862,844400,1271,2882,2661,08,29,0,1,1,山西
328862,575153,1271,2882,2661,08,29,0,2,1,山西
328862,996875,1271,2882,2661,08,29,0,1,1,内蒙古
数据集的预处理
1.删除文件第一行记录,即字段名称
cd /usr/local/dbtaobao/dataset
//下面删除user_log.csv中的第1行
sed -i '1d' user_log.csv //这个命令慢
//1d表示删除第1行,同理,3d表示删除第3行,nd表示删除第n行
//下面再用head命令去查看文件的前5行记录,就看不到字段名称这一行了
head -5 user_log.csv
2.获取数据集中双11的前100000条数据
cd /usr/local/dbtaobao/dataset
vim predeal.sh
使用vim编辑器新建了一个predeal.sh脚本文件,请在这个脚本文件中加入下面代码:
#!/bin/bash
#下面设置输入文件,把用户执行predeal.sh命令时提供的第一个参数作为输入文件名称
infile=$1
#下面设置输出文件,把用户执行predeal.sh命令时提供的第二个参数作为输出
文件名称
outfile=$2
#注意!!最后的$infile > $outfile必须跟在}’这两个字符的后面
awk -F "," 'BEGIN{
id=0;
}
{
if($6==11 && $7==11){
id=id+1;
print $1","$2","$3","$4","$5","$6","$7","$8","$9","$10","$11
if(id==10000){
exit
}
}
}' $infile > $outfile
下面就可以执行predeal.sh脚本文件,截取数据集中在双11的前10000条交易数
据集small_user_log.csv,命令如下:
chmod +x ./predeal.sh
//第二条
./predeal.sh ./user_log.csv ./small_user_log.csv
3.导入数据库
a.启动HDFS
cd /usr/local/hadoop
./sbin/start-dfs.sh
执行jps命令看一下当前运行的进程:
jps
如果出现下面这些进程,说明Hadoop启动成功了。
3765 NodeManager
3639 ResourceManager
3800 Jps
3261 DataNode
3134 NameNode
3471 SecondaryNameNode
b.把user_log.csv上传到HDFS中
cd /usr/local/hadoop
./bin/hdfs dfs -mkdir -p /dbtaobao/dataset/user_log
把Linux本地文件系统中的small_user_log.csv上传到分布式文件系统HDFS的
“/dbtaobao/dataset”目录下,命令如下:
cd /usr/local/hadoop
./bin/hdfs dfs -put /usr/local/dbtaobao/dataset/small_user_log.csv /dbtaobao/dataset/user_log
//连着的
下面可以查看一下HDFS中的small_user_log.csv的前10条记录,命令如下:
cd /usr/local/hadoop
./bin/hdfs dfs -cat /dbtaobao/dataset/user_log/small_user_log.csv | head -10
c.在Hive上创建数据库
请首先启动MySQL数据库:
service mysql start #可以在Linux的任何目录下执行该命令
进入Hive:
cd /usr/local/hive
./bin/hive # 启动Hive
在Hive中创建一个数据库dbtaobao
hive> create database dbtaobao;
hive> use dbtaobao;
d.创建外部表
hive> CREATE EXTERNAL TABLE dbtaobao.user_log(user_id INT,item_id INT,cat_id INT,merchant_id INT,brand_id INT,month STRING,day STRING,action INT,age_range INT,gender INT,province STRING) COMMENT 'Welcome to xmu dblab,Now create dbtaobao.user_log!' ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS TEXTFILE LOCATION '/dbtaobao/dataset/user_log';
e.查询数据
上面已经成功把HDFS中的“/dbtaobao/dataset/user_log”目录下的small_user_log.csv数据加载到了数据仓库Hive中,我们现在可以使用下面命令
查询一下:
hive> select * from user_log limit 10;
步骤二:Hive数据分析
一、操作Hive
启动MySQL数据库
service mysql start # 可以在Linux的任何目录下执行该命令
启动Hadoop
cd /usr/local/hadoop
./sbin/start-dfs.sh
执行jps命令看一下当前运行的进程:
jps
如果出现下面这些进程,说明Hadoop启动成功了。
3765 NodeManager
3639 ResourceManager
3800 Jps
3261 DataNode
3134 NameNode
3471 SecondaryNameNode
启动进入Hive:
cd /usr/local/hive
./bin/hive //启动Hive
在“hive>”命令提示符状态下执行下面命令:
hive> use dbtaobao; -- 使用dbtaobao数据库
hive> show tables; -- 显示数据库中所有表。
hive> show create table user_log; -- 查看user_log表的各种属性;
执行结果如下:
OK
CREATE EXTERNAL TABLE `user_log`(
`user_id` int,
`item_id` int,
`cat_id` int,
`merchant_id` int,
`brand_id` int,
`month` string,
`day` string,
`action` int,
`age_range` int,
`gender` int,
`province` string)
COMMENT 'Welcome to xmu dblab,Now create dbtaobao.user_log!'
ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SERDEPROPERTIES (
'field.delim'=',',
'serialization.format'=',')
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
'hdfs://localhost:9000/dbtaobao/dataset/user_log'
TBLPROPERTIES (
'numFiles'='1',
'totalSize'='4729522',
'transient_lastDdlTime'='1487902650')
Time taken: 0.084 seconds, Fetched: 28 row(s)
可以执行下面命令查看表的简单结构:
hive> desc user_log;
执行结果如下:
OK
user_id int
item_id int
cat_id int
merchant_id int
brand_id int
month string
day string
action int
age_range int
gender int
province string
Time taken: 0.029 seconds, Fetched: 11 row(s)
二、简单查询分析
先测试一下简单的指令:
hive> select brand_id from user_log limit 10; -- 查看日志前10个交易日志的商品品牌
执行结果如下:
OK
5476
5476
6109
5476
5476
5476
5476
5476
5476
6300
如果要查出每位用户购买商品时的多种信息,输出语句格式为 select 列1,列2,….,列n from 表名;
比如我们现在查询前20个交易日志中购买商品时的时间和商品的种类
hive> select month,day,cat_id from user_log limit 20;
执行结果如下:
OK
11 11 1280
11 11 1280
11 11 1181
11 11 1280
11 11 1280
11 11 1280
11 11 1280
11 11 1280
11 11 1280
11 11 962
11 11 81
11 11 1432
11 11 389
11 11 1208
11 11 1611
11 11 420
11 11 1611
11 11 1432
11 11 389
11 11 1432
有时我们在表中查询可以利用嵌套语句,如果列名太复杂可以设置该列的别名,以简化我们操作的难度,以下我们可以举个例子:
hive> select ul.at, ul.ci from (select action as at, cat_id as ci from user_log) as ul limit 20;
执行结果如下:
OK
0 1280
0 1280
0 1181
2 1280
0 1280
0 1280
0 1280
0 1280
0 1280
0 962
2 81
2 1432
0 389
2 1208
0 1611
0 420
0 1611
0 1432
0 389
0 1432
三、查询条数统计分析
1)用聚合函数count()计算出表内有多少条行数据
hive> select count(*) from user_log; -- 用聚合函数count()计算出表内有多少条行数据
hive
执行结果如下:
WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
Query ID = hadoop_20170224103108_d6361e99-e76a-43e6-94b5-3fb0397e3ca6
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Job running in-process (local Hadoop)
2017-02-24 10:31:10,085 Stage-1 map = 100%, reduce = 100%
Ended Job = job_local792612260_0001
MapReduce Jobs Launched:
Stage-Stage-1: HDFS Read: 954982 HDFS Write: 0 SUCCESS
Total MapReduce CPU Time Spent: 0 msec
OK
10000
Time taken: 1.585 seconds, Fetched: 1 row(s)
(2)在函数内部加上distinct,查出uid不重复的数据有多少条
下面继续执行操作:
hive> select count(distinct user_id) from user_log; -- 在函数内部加上distinct,查出user_id不重复的数据有多少条
hive
执行结果如下:
WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
Query ID = hadoop_20170224103141_47682fd4-132b-4401-813a-0ed88f0fb01f
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Job running in-process (local Hadoop)
2017-02-24 10:31:42,501 Stage-1 map = 100%, reduce = 100%
Ended Job = job_local1198900757_0002
MapReduce Jobs Launched:
Stage-Stage-1: HDFS Read: 1901772 HDFS Write: 0 SUCCESS
Total MapReduce CPU Time Spent: 0 msec
OK
358
Time taken: 1.283 seconds, Fetched: 1 row(s)
(3)查询不重复的数据有多少条(为了排除客户刷单情况) **
hive> select count(*) from (select user_id,item_id,cat_id,merchant_id,brand_id,month,day,action from user_log group by user_id,item_id,cat_id,merchant_id,brand_id,month,day,action having count(*)=1)a;
hive
执行结果如下:
WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
Query ID = hadoop_20170224103334_3391e361-c710-4162-b022-2658f41fc228
Total jobs = 2
Launching Job 1 out of 2
Number of reduce tasks not specified. Estimated from input data size: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Job running in-process (local Hadoop)
2017-02-24 10:33:35,890 Stage-1 map = 100%, reduce = 100%
Ended Job = job_local1670662918_0003
Launching Job 2 out of 2
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Job running in-process (local Hadoop)
2017-02-24 10:33:37,026 Stage-2 map = 100%, reduce = 100%
Ended Job = job_local2041177199_0004
MapReduce Jobs Launched:
Stage-Stage-1: HDFS Read: 2848562 HDFS Write: 0 SUCCESS
Stage-Stage-2: HDFS Read: 2848562 HDFS Write: 0 SUCCESS
Total MapReduce CPU Time Spent: 0 msec
OK
4754
Time taken: 2.478 seconds, Fetched: 1 row(s)
执行中如果出现错误:
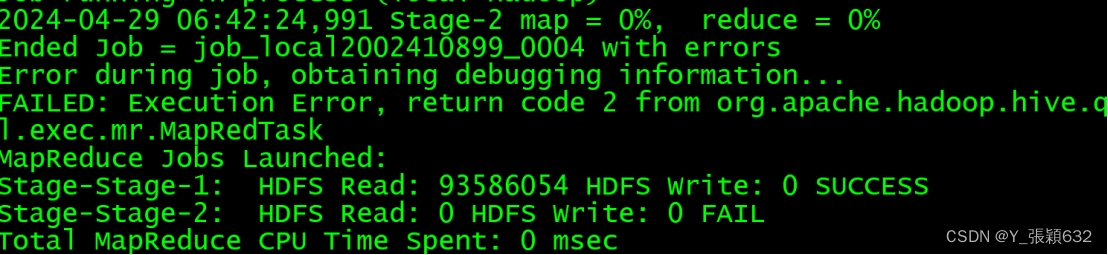
出现该问题的原因:是jvm的虚拟内存不够,做以下更改,每次错误之后都需要进行重启hadoop--mysql--hive,释放内存空间
解决办法:
开启stage
cd /usr/local/hive/conf
vim hive-site.xml
<property>
<name>hive.exec.mode.local.auto</name>
<value>true</value>
</property>
hive --service metastore
cd /usr/local/hadoop/etc/hadoop
hadoop@ubuntu:/usr/local/hadoop/etc/hadoop$ vim yarn-site.xml
修改配置文件yarn-site.xml ,参数不固定
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>2.1</value>
</property>
<property>
<name>mapred.child.java.opts</name>
<value>-Xmx1024m</value>
</property>
cd /usr/local/hadoop/etc/hadoop/hadoop-env.sh
export HADOOP_CLIENT_OPTS="-Xmx2048m $HADOOP_CLIENT_OPTS"
必须重新启动hadoop
启动MySQL数据库
service mysql start # 可以在Linux的任何目录下执行该命令
重启动Hadoop
cd /usr/local/hadoop
./sbin/start-dfs.sh
执行jps命令看一下当前运行的进程:
jps
并且需要重启hive
cd /usr/local/hive
./bin/hive //启动Hive
hive> use dbtaobao; -- 使用dbtaobao数据库
如果上述问题解决不成功,可以继续尝试下边的命令
hive> set hive.support.concurrency=false;
hive> set hive.auto.convert.join=false;
hive> set hive.exec.dynamic.partition.mode=nonstrict;
hive> set hive.exec.dynamic.partition=true;
hive> set hive.exec.parallel=true;
hive> set hive.support.concurrency=false;
hive> set mapreduce.map.memory.mb=4128;
hive> set mapreduce.map.memory.mb=10150;
hive> set mapreduce.map.java.opts=-Xmx6144m;
hive> set mapreduce.reduce.memory.mb=10150;
hive> set mapreduce.reduce.java.opts=-Xmx8120m;
hive> set hive.exec.max.dynamic.partitions=50000;
hive> set hive.exec.max.dynamic.partitions.pernode=10000;
free -m
四.关键字条件查询分析
1.以关键字的存在区间为条件的查询
使用where可以缩小查询分析的范围和精确度,下面用实例来测试一下。
(1)查询双11那天有多少人购买了商品
hive> select count(distinct user_id) from user_log where action='2';
hive
执行结果如下:
WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
Query ID = hadoop_20170224103500_44e669ed-af51-4856-8963-002d85112f32
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Job running in-process (local Hadoop)
2017-02-24 10:35:01,940 Stage-1 map = 100%, reduce = 100%
Ended Job = job_local1951453719_0005
MapReduce Jobs Launched:
Stage-Stage-1: HDFS Read: 3795352 HDFS Write: 0 SUCCESS
Total MapReduce CPU Time Spent: 0 msec
OK
358
Time taken: 1.231 seconds, Fetched: 1 row(s)
2.关键字赋予给定值为条件,对其他数据进行分析
取给定时间和给定品牌,求当天购买的此品牌商品的数量
hive> select count(*) from user_log where action='2' and brand_id=2661;
hive
执行结果如下:
WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
Query ID = hadoop_20170224103541_4640ca81-1d25-48f8-8d9d-6027f2befdb9
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Job running in-process (local Hadoop)
2017-02-24 10:35:42,457 Stage-1 map = 100%, reduce = 100%
Ended Job = job_local1749705881_0006
MapReduce Jobs Launched:
Stage-Stage-1: HDFS Read: 4742142 HDFS Write: 0 SUCCESS
Total MapReduce CPU Time Spent: 0 msec
OK
3
Time taken: 1.258 seconds, Fetched: 1 row(s)
五.根据用户行为分析
从现在开始,我们只给出查询语句,将不再给出执行结果。
1.查询一件商品在某天的购买比例或浏览比例
hive> select count(distinct user_id) from user_log where action='2'; -- 查询有多少用户在双11购买了商品
执行结果如下:
WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
Query ID = hadoop_20170224103500_44e669ed-af51-4856-8963-002d85112f32
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Job running in-process (local Hadoop)
2017-02-24 10:35:01,940 Stage-1 map = 100%, reduce = 100%
Ended Job = job_local1951453719_0005
MapReduce Jobs Launched:
Stage-Stage-1: HDFS Read: 3795352 HDFS Write: 0 SUCCESS
Total MapReduce CPU Time Spent: 0 msec
OK
358
Time taken: 1.231 seconds, Fetched: 1 row(s)
2.关键字赋予给定值为条件,对其他数据进行分析
取给定时间和给定品牌,求当天购买的此品牌商品的数量
hive> select count(*) from user_log where action='2' and brand_id=2661;
执行结果如下:
WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
Query ID = hadoop_20170224103541_4640ca81-1d25-48f8-8d9d-6027f2befdb9
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Job running in-process (local Hadoop)
2017-02-24 10:35:42,457 Stage-1 map = 100%, reduce = 100%
Ended Job = job_local1749705881_0006
MapReduce Jobs Launched:
Stage-Stage-1: HDFS Read: 4742142 HDFS Write: 0 SUCCESS
Total MapReduce CPU Time Spent: 0 msec
OK
3
Time taken: 1.258 seconds, Fetched: 1 row(s)
五.根据用户行为分析
从现在开始,我们只给出查询语句,将不再给出执行结果。
1.查询一件商品在某天的购买比例或浏览比例
hive> select count(distinct user_id) from user_log where action='2'; -- 查询有多少用户在双11购买了商品
hive> select count(distinct user_id) from user_log; -- 查询有多少用户在双11点击了该店
2.查询双11那天,男女买家购买商品的比例
hive> select count(*) from user_log where gender=0; --查询双11那天女性购买商品的数量
hive> select count(*) from user_log where gender=1; --查询双11那天男性购买商品的数量
3.给定购买商品的数量范围,查询某一天在该网站的购买该数量商品的用户id
hive> select user_id from user_log where action='2' group by user_id having count(action='2')>5; -- 查询某一天在该网站购买商品超过5次的用户id
六.用户实时查询分析
不同的品牌的浏览次数
hive> create table scan(brand_id INT,scan INT) COMMENT 'This is the search of bigdatataobao' ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS TEXTFILE; -- 创建新的数据表进行存储
hive> insert overwrite table scan select brand_id,count(action) from user_log where action='2' group by brand_id; --导入数据
hive> select * from scan; -- 显示结果
步骤三:将数据从Hive导入到MySQL
一、Ubuntu安装Sqoop
1. 下载并解压sqoop1.4.6
cd ~ #进入当前用户的用户目录
cd Downloads #sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz文件下载后就被保存在该目录下面
sudo tar -zxvf sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz -C /usr/local #解压安装文件
cd /usr/local
sudo mv sqoop-1.4.6.bin__hadoop-2.0.4-alpha sqoop #修改文件名
sudo chown -R hadoop:hadoop sqoop #修改文件夹属主,如果你当前登录用户名不是hadoop,请修改成你自己的用户名
2. 修改配置文件sqoop-env.sh
cd sqoop/conf/
cat sqoop-env-template.sh >> sqoop-env.sh #将sqoop-env-template.sh复制一份并命名为sqoop-env.sh
vim sqoop-env.sh #编辑sqoop-env.sh
修改sqoop-env.sh的如下信息
export HADOOP_COMMON_HOME=/usr/local/hadoop
export HADOOP_MAPRED_HOME=/usr/local/hadoop
export HBASE_HOME=/usr/local/hbase
export HIVE_HOME=/usr/local/hive
#export ZOOCFGDIR= #如果读者配置了ZooKeeper,也需要在此配置ZooKeeper的路径
3. 配置环境变量
打开当前用户的环境变量配置文件:
vim ~/.bashrc
在配置文件第一行键入如下信息:
export SQOOP_HOME=/usr/local/sqoop
export PATH=$PATH:$SBT_HOME/bin:$SQOOP_HOME/bin
export CLASSPATH=$CLASSPATH:$SQOOP_HOME/lib
保存该文件,退出vim编辑器。
然后,执行下面命令让配置文件立即生效:
source ~/.bashrc
4. 将mysql驱动包拷贝到SQOOP_HOME/lib
cd ~/Downloads
#切换到下载路径,如果你下载的文件不在这个目录下,请切换到下载文件所保存的目录
sudo tar -zxvf mysql-connector-java-5.1.37.tar.gz
#解压mysql驱动包
ls
#这时就可以看到解压缩后得到的目录mysql-connector-java-5.1.37
cp ./mysql-connector-java-5.1.37/mysql-connector-java-5.1.37-bin.jar /usr/local/sqoop/lib
5. 测试与MySQL的连接
启动mysql服务
service mysql start
测试sqoop与MySQL之间的连接是否成功:
sqoop list-databases --connect jdbc:mysql://127.0.0.1:3306/ --username root -P
mysql的数据库列表显示在屏幕上表示连接成功
二、Hive预操作
启动MySQL数据库
service mysql start # 可以在Linux的任何目录下执行该命令
启动Hadoop
cd /usr/local/hadoop
./sbin/start-all.sh
执行jps命令看一下当前运行的进程:
jps
如果出现下面这些进程,说明Hadoop启动成功了。
3765 NodeManager
3639 ResourceManager
3800 Jps
3261 DataNode
3134 NameNode
3471 SecondaryNameNode
继续执行下面命令启动进入Hive
cd /usr/local/hive
./bin/hive #启动Hive
1、创建临时表inner_user_log和inner_user_info
hive> create table dbtaobao.inner_user_log(user_id INT,item_id INT,cat_id INT,merchant_id INT,brand_id INT,month STRING,day STRING,action INT,age_range INT,gender INT,province STRING) COMMENT 'Welcome to XMU dblab! Now create inner table inner_user_log ' ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS TEXTFILE;
2、将user_log表中的数据插入到inner_user_log,
hive> INSERT OVERWRITE TABLE dbtaobao.inner_user_log select * from dbtaobao.user_log;
查询上面的插入命令是否成功执行:
hive> select * from dbtaobao.inner_user_log limit 10;
三、使用Sqoop将数据从Hive导入MySQL
1、将前面生成的临时表数据从Hive导入到 MySQL 中,包含如下四个步骤。
(1)登录 MySQL
请在Linux系统中新建一个终端,执行下面命令:
mysql -uroot -p
(2)创建数据库
mysql> show databases; #显示所有数据库
mysql> create database dbtaobao; #创建dbtaobao数据库
mysql> use dbtaobao; #使用数据库
请使用下面命令查看数据库的编码:
mysql> show variables like "char%";
+--------------------------+----------------------------+
| Variable_name | Value |
+--------------------------+----------------------------+
| character_set_client | utf8 |
| character_set_connection | utf8 |
| character_set_database | utf8 |
| character_set_filesystem | binary |
| character_set_results | utf8 |
| character_set_server | utf8 |
| character_set_system | utf8 |
| character_sets_dir | /usr/share/mysql/charsets/ |
+--------------------------+----------------------------+
8 rows in set (0.00 sec)
安装前先更新一下软件源以获得最新版本:
sudo apt-get update #更新软件源
sudo apt-get install mysql-server #安装mysql
启动和关闭mysql服务器:
service mysql start
service mysql stop
确认是否启动成功,mysql节点处于LISTEN状态表示启动成功:
sudo netstat -tap | grep mysql
进入mysql shell界面:
mysql -u root -p
(3)创建表
mysql> CREATE TABLE `dbtaobao`.`user_log` (`user_id` varchar(20),`item_id` varchar(20),`cat_id` varchar(20),`merchant_id` varchar(20),`brand_id` varchar(20), `month` varchar(6),`day` varchar(6),`action` varchar(6),`age_range` varchar(6),`gender` varchar(6),`province` varchar(10)) ENGINE=InnoDB DEFAULT CHARSET=utf8;
mysql> exit;
(4)导入数据(执行时间:20秒左右)
cd /usr/local/sqoop
bin/sqoop export --connect jdbc:mysql://localhost:3306/dbtaobao --username root --password root --table user_log --export-dir '/user/hive/warehouse/dbtaobao.db/inner_user_log' --fields-terminated-by ',';
//每个参数根据自己的设置进行更改
./bin/sqoop export ##表示数据从 hive 复制到 mysql 中
--connect jdbc:mysql://localhost:3306/dbtaobao
--username root #mysql登陆用户名
--password root #登录密码
--table user_log #mysql 中的表,即将被导入的表名称
--export-dir '/user/hive/warehouse/dbtaobao.db/inner_user_log ' #hive 中被导出的文件
--fields-terminated-by ',' #Hive 中被导出的文件字段的分隔符

解决方法:
当你每次执行失败后,其实在/tmp/sqoop-你的用户名/compile(或者是/tmp/sqoop/compile,可以找找看)文件夹下有许多临时文件夹,文件夹名称为一大串字符,每个文件夹内有对应表名生成的.jar包、.java和.class文件。将这三个文件拷贝到你的sqoop安装目录/lib文件夹下即可解决。
2、查看MySQL中user_log或user_info表中的数据
下面需要再次启动MySQL,进入“mysql>”命令提示符状态:
mysql -uroot -p
查询user_action表中的数据:
mysql> use dbtaobao;
mysql> select * from user_log limit 10;
会得到类似下面的查询结果:
+---------+---------+--------+-------------+----------+-------+------+--------+-----------+--------+-----------+
| user_id | item_id | cat_id | merchant_id | brand_id | month | day | action | age_range | gender | province |
+---------+---------+--------+-------------+----------+-------+------+--------+-----------+--------+-----------+
| 414196 | 1109106 | 1188 | 3518 | 4805 | 11 | 11 | 0 | 4 | 0 | 宁夏 |
| 414196 | 380046 | 4 | 231 | 6065 | 11 | 11 | 0 | 5 | 2 | 陕西 |
| 414196 | 1109106 | 1188 | 3518 | 4805 | 11 | 11 | 0 | 7 | 0 | 山西 |
| 414196 | 1109106 | 1188 | 3518 | 4805 | 11 | 11 | 0 | 6 | 0 | 河南 |
| 414196 | 1109106 | 1188 | 3518 | 763 | 11 | 11 | 2 | 2 | 0 | 四川 |
| 414196 | 944554 | 1432 | 323 | 320 | 11 | 11 | 2 | 7 | 2 | 青海 |
| 414196 | 1110009 | 1188 | 298 | 7907 | 11 | 11 | 2 | 3 | 1 | 澳门 |
| 414196 | 146482 | 513 | 2157 | 6539 | 11 | 11 | 0 | 1 | 0 | 上海市 |
| 414196 | 944554 | 1432 | 323 | 320 | 11 | 11 | 0 | 2 | 1 | 宁夏 |
| 414196 | 1109106 | 1188 | 3518 | 4805 | 11 | 11 | 0 | 7 | 0 | 新疆 |
+---------+---------+--------+-------------+----------+-------+------+--------+-----------+--------+-----------+
10 rows in set (0.03 sec)
步骤四:利用Spark预测回头客行为
预处理test.csv和train.csv数据集
cd /usr/local/dbtaobao/dataset
vim predeal_test.sh
上面使用vim编辑器新建了一个predeal_test.sh脚本文件,请在这个脚本文件中加入下面代码:
#!/bin/bash
#下面设置输入文件,把用户执行predeal_test.sh命令时提供的第一个参数作为输入文件名称
infile=$1
#下面设置输出文件,把用户执行predeal_test.sh命令时提供的第二个参数作为输出文件名称
outfile=$2
#注意!!最后的$infile > $outfile必须跟在}’这两个字符的后面
awk -F "," 'BEGIN{
id=0;
}
{
if($1 && $2 && $3 && $4 && !$5){
id=id+1;
print $1","$2","$3","$4","1
if(id==10000){
exit
}
}
}' $infile > $outfile
下面就可以执行predeal_test.sh脚本文件,截取测试数据集需要预测的数据到test_after.csv,命令如下:
chmod +x ./predeal_test.sh
./predeal_test.sh ./test.csv ./test_after.csv
train.csv的第一行都是字段名称,不需要第一行字段名称,这里在对train.csv做数据预处理时,删除第一行
sed -i '1d' train.csv
然后剔除掉train.csv中字段值部分字段值为空的数据。
cd /usr/local/dbtaobao/dataset
vim predeal_train.sh
上面使用vim编辑器新建了一个predeal_train.sh脚本文件,请在这个脚本文件中加入下面代码:
#!/bin/bash
#下面设置输入文件,把用户执行predeal_train.sh命令时提供的第一个参数作为输入文件名称
infile=$1
#下面设置输出文件,把用户执行predeal_train.sh命令时提供的第二个参数作为输出文件名称
outfile=$2
#注意!!最后的$infile > $outfile必须跟在}’这两个字符的后面
awk -F "," 'BEGIN{
id=0;
}
{
if($1 && $2 && $3 && $4 && ($5!=-1)){
id=id+1;
print $1","$2","$3","$4","$5
if(id==10000){
exit
}
}
}' $infile > $outfile
下面就可以执行predeal_train.sh脚本文件,截取测试数据集需要预测的数据到train_after.csv,命令如下:
chmod +x ./predeal_train.sh
./predeal_train.sh ./train.csv ./train_after.csv
预测回头客
启动hadoop
cd /usr/local/hadoop/
sbin/start-dfs.sh
将两个数据集分别存取到HDFS中
bin/hadoop fs -mkdir -p /dbtaobao/dataset
bin/hadoop fs -put /usr/local/dbtaobao/dataset/train_after.csv /dbtaobao/dataset
bin/hadoop fs -put /usr/local/dbtaobao/dataset/test_after.csv /dbtaobao/dataset
启动MySQL服务
service mysql start
mysql -uroot -p #会提示让你输入数据库密码
输入密码后,你就可以进入“mysql>”命令提示符状态,然后就可以输入下面的SQL语句完成表的创建:
use dbtaobao;
create table rebuy (score varchar(40),label varchar(40));
启动Spark Shell
cd ~/Downloads/
unzip mysql-connector-java-5.1.34.zip -d /usr/local/spark/jars
接下来正式启动spark-shell
cd /usr/local/spark
./bin/spark-shell --jars /usr/local/spark/jars/mysql-connector-java-5.1.34/mysql-connector-java-5.1.34-bin.jar --driver-class-path /usr/local/spark/jars/mysql-connector-java-5.1.34/mysql-connector-java-5.1.34-bin.jar
支持向量机SVM分类器预测回头客
1.导入需要的包
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.mllib.regression.LabeledPoint
import org.apache.spark.mllib.linalg.{Vectors,Vector}
import org.apache.spark.mllib.classification.{SVMModel, SVMWithSGD}
import org.apache.spark.mllib.evaluation.BinaryClassificationMetrics
import java.util.Properties
import org.apache.spark.sql.types._
import org.apache.spark.sql.Row
2.读取训练数据
val train_data = sc.textFile("/dbtaobao/dataset/train_after.csv")
val test_data = sc.textFile("/dbtaobao/dataset/test_after.csv")
3.构建模型
val train= train_data.map{line =>
val parts = line.split(',')
LabeledPoint(parts(4).toDouble,Vectors.dense(parts(1).toDouble,parts
(2).toDouble,parts(3).toDouble))
}
val test = test_data.map{line =>
val parts = line.split(',')
LabeledPoint(parts(4).toDouble,Vectors.dense(parts(1).toDouble,parts(2).toDouble,parts(3).toDouble))
}
通过训练集构建模型SVMWithSGD
val numIterations = 1000
val model = SVMWithSGD.train(train, numIterations)
4.评估模型
model.clearThreshold()
val scoreAndLabels = test.map{point =>
val score = model.predict(point.features)
score+" "+point.label
}
scoreAndLabels.foreach(println)
spark-shell会打印出如下结果
......
-59045.132228013084 1.0
-81550.17634254562 1.0
-87393.69932070676 1.0
-34743.183626268634 1.0
-42541.544145105494 1.0
-75530.22669142077 1.0
-84157.31973688163 1.0
-18673.911440386535 1.0
-43765.52530945006 1.0
-80524.44350315288 1.0
-61709.836501153935 1.0
-37486.854426141384 1.0
-79793.17112276069 1.0
-21754.021986991942 1.0
-50378.971923247285 1.0
-11646.722569368836 1.0
......
如果我们设定了阀值,则会把大于阈值的结果当成正预测,小于阈值的结果当成负预测。
model.setThreshold(0.0)
scoreAndLabels.foreach(println)
1.把结果添加到mysql数据库中
model.clearThreshold()
val scoreAndLabels = test.map{point =>
val score = model.predict(point.features)
score+" "+point.label
}
//设置回头客数据
val rebuyRDD = scoreAndLabels.map(_.split(" "))
/下面要设置模式信息
val schema = StructType(List(StructField("score", StringType, true),StructField("label", StringType, true)))
//下面创建Row对象,每个Row对象都是rowRDD中的一行
val rowRDD = rebuyRDD.map(p => Row(p(0).trim, p(1).trim))
//建立起Row对象和模式之间的对应关系,也就是把数据和模式对应起来
val rebuyDF = spark.createDataFrame(rowRDD, schema)
//下面创建一个prop变量用来保存JDBC连接参数
val prop = new Properties()
prop.put("user", "root") //这个语句执行多遍,知道出现自己应用的object为止
//表示用户名是root,需要更改为自己的用户名
prop.put("password", "zhangying") //这个语句执行多遍,知道出现自己应用的object为止
//表示密码是zhangying,需要更改为自己的密码
prop.put("driver","com.mysql.jdbc.Driver")//这个语句执行多遍,知道出现自己应用的Driver为止
//表示驱动程序是com.mysql.jdbc.Driver
//下面就可以连接数据库,采用append模式,表示追加记录到数据库dbtaobao的rebuy表中
rebuyDF.write.mode("append").jdbc("jdbc:mysql://localhost:3306/dbtaobao", "dbtaobao.rebuy", prop)
步骤五:利用ECharts进行数据可视化分析
搭建tomcat+mysql+JSP开发环境
下载tomcat
查看Linux系统的Java版本,执行如下命令:
java -version
结果如下:
java version "1.8.0_371"
Java(TM) SE Runtime Environment (build 1.8.0_371-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.162-b12, mixed mode)
解压apache-tomcat-8.0.41.zip到用户目录~下,执行如下命令:
cd ~/Downloads/
unzip apache-tomcat-8.0.41.zip -d ~
启动mysql
service mysql start
利用Eclipse 新建可视化Web应用
ubuntu终端
cd /usr/local
./eclipse/eclipse
1.打开Eclipse,点击“File”菜单,通过工具栏的“New”创建Dynamic Web Project
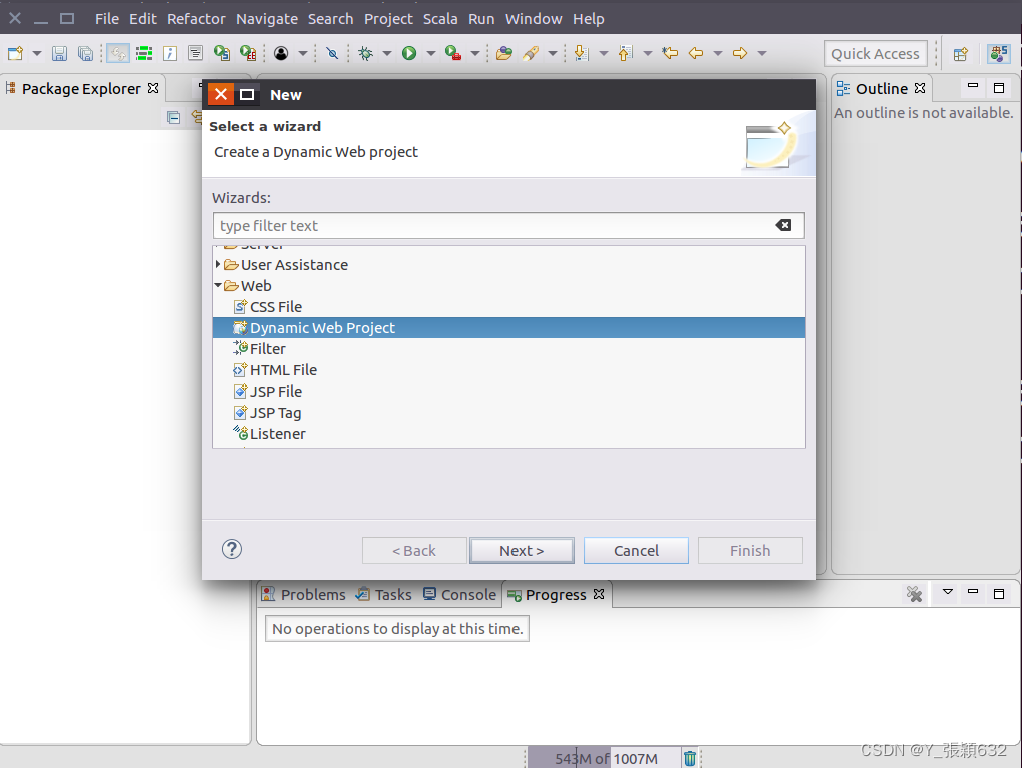
eclipse中没有Dynamic Web Project的解决方法:
为当前的eclipse安装Java EE开发插件。如下:
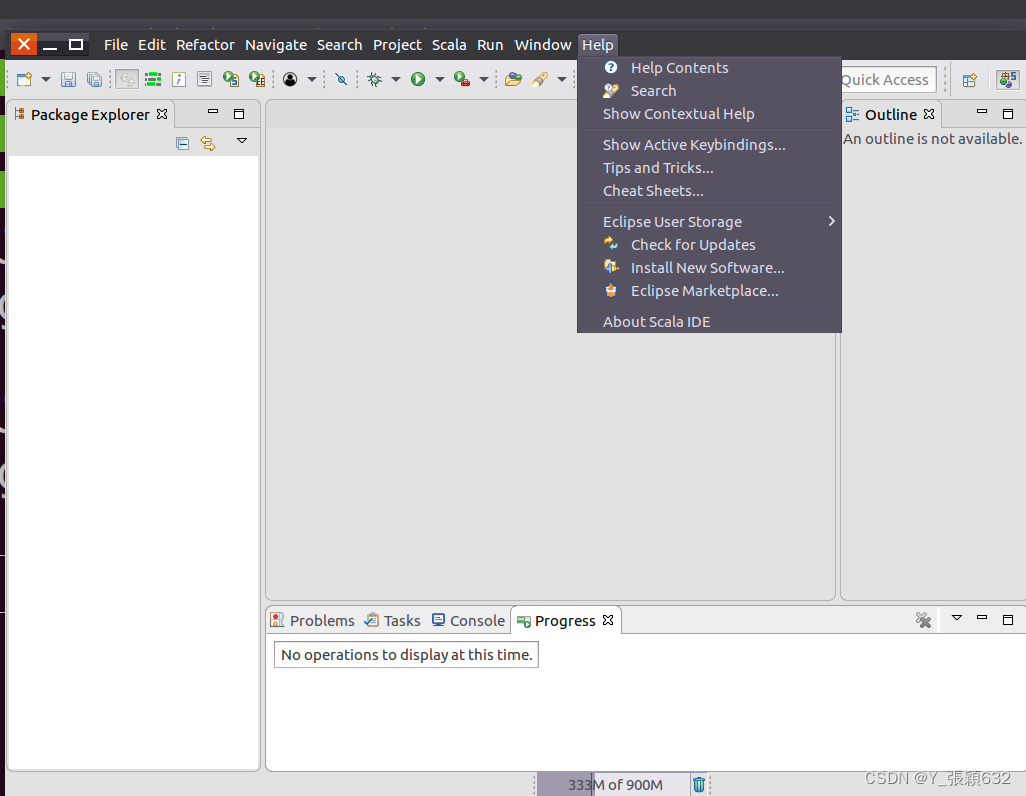
选择install new software
安装向导被打开。在安装向导的窗口, 点击”Work
With”下拉,根据你的eclipse版本名选择
“http://download.eclipse.org/releases/oxygen“(如果你是 Eclipse oxygen版本)
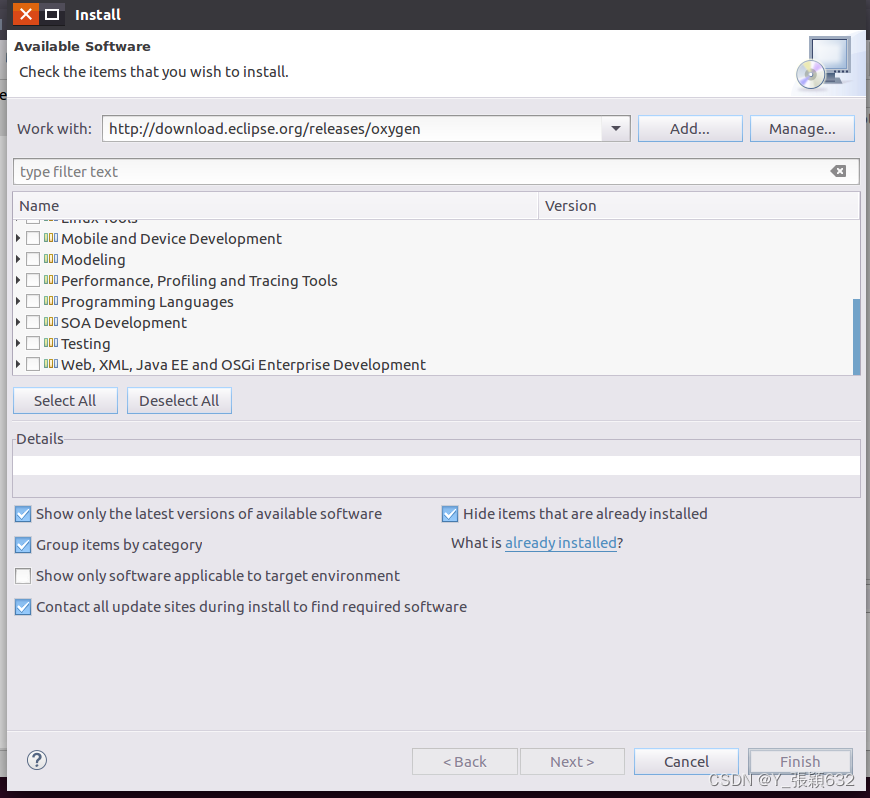
加载出来后如图:
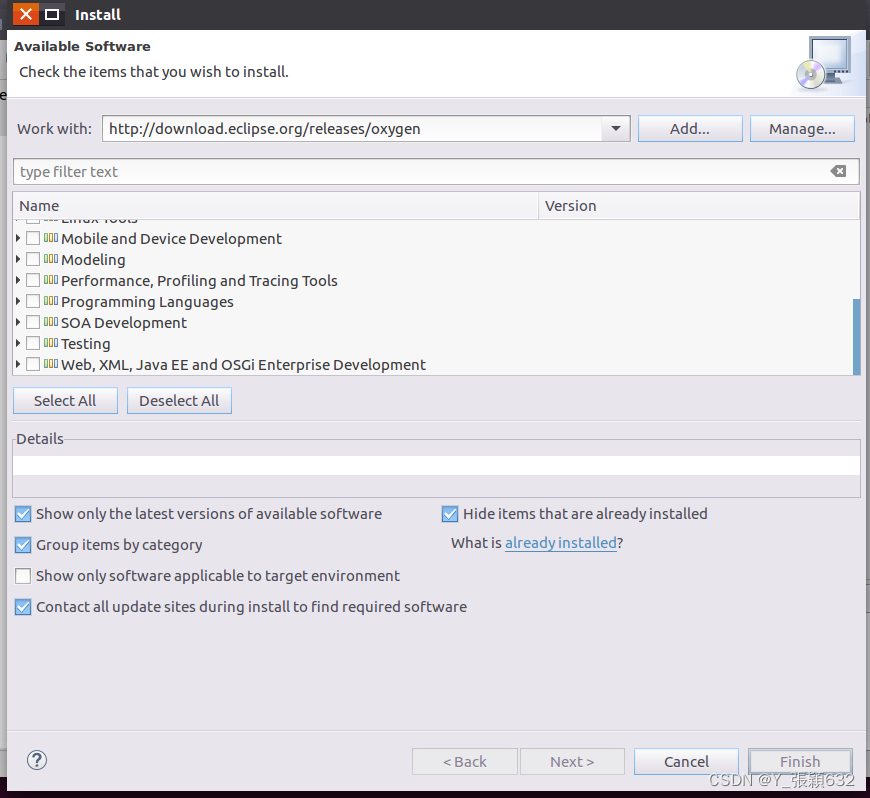
eclipse会搜寻这个网址的所有软件,并且显示到下面的列表(建议使用代理,否则可能要花很长时间显示和下载插件,至于如何设置eclipse代理,请自行google)。
展开 “Web, XML, Java EE and OSGi Enterprise Development” 选项,并且将下面四个选项打上勾:
Eclipse Java EE Developer Tools
Eclipse Java Web Developer Tools
Eclipse Web Developer Tools
Eclipse XML Editors and Tools
然后点击”Next“。
依次点击“Next ”知道你看到 “ Review licences”的窗口。在这个窗口选择 “I accept the terms of the licence agreement” 并且点击“Finish”。
eclipse会开始安装新的软件.
安装完插件之后, Eclipse会要求你重启eclipse,选“yes”。
重启eclipse之后, 打开新建项目的面板,就可以看到 Web文件夹 和 “DynamicWeb Project” 选项了。
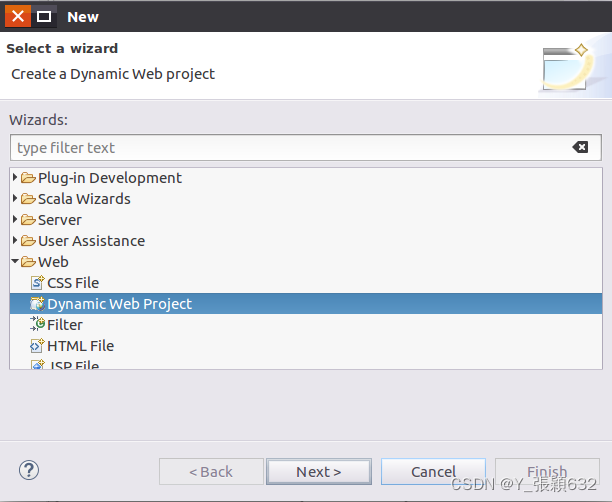
2.填入Project name后,并点击"New Runtime",如下图所示:
选择“Apache Tomcat v8.0”,点击next按钮
如果Apache Tomcat v8.0找不到就进行如下操作:
菜单栏的help选项中,选择install new software
安装向导被打开。在安装向导的窗口, 点击”Work
With”下拉,根据你的eclipse版本名选择
“http://download.eclipse.org/releases/oxygen“(如果你是 Eclipse oxygen版本)
加载出来后如图:
eclipse会搜寻这个网址的所有软件,并且显示到下面的列表(建议使用代理,否则可能要花很长时间显示和下载插件,至于如何设置eclipse代理,请自行google)。
展开 “Web, XML, Java EE and OSGi Enterprise
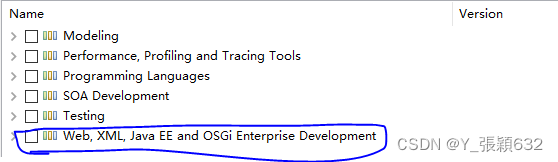
然后点开上面这个选项,然后勾选下面这个选项

然后就是点击next进行安装重启。
安装好了之后就会发现上面的问题里面都会有了apache tomcat,然后选择自己系统装的版本即可。
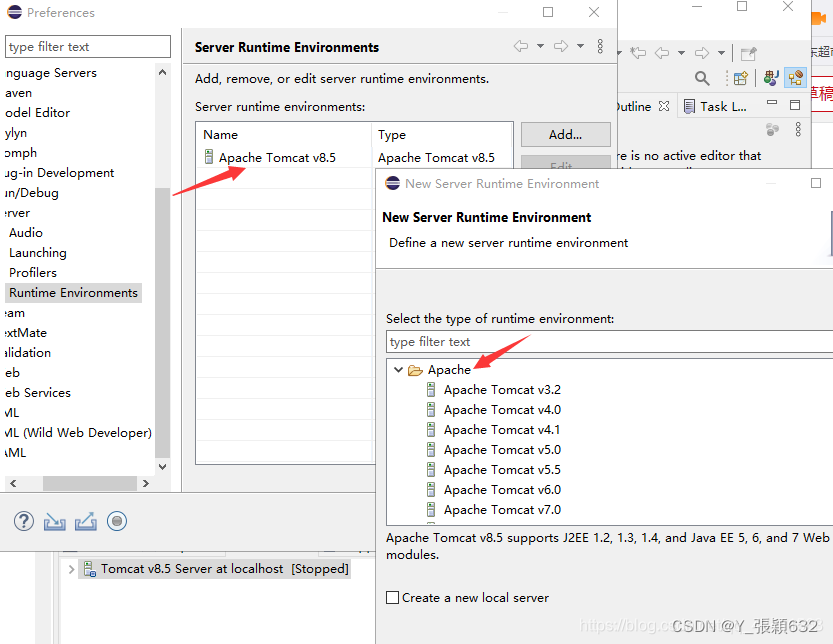
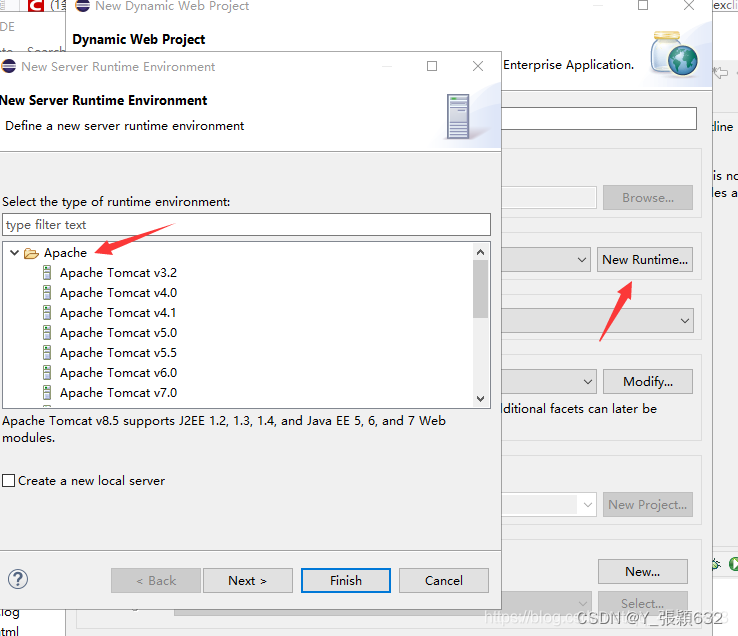
3.选择Tomcat安装文件夹
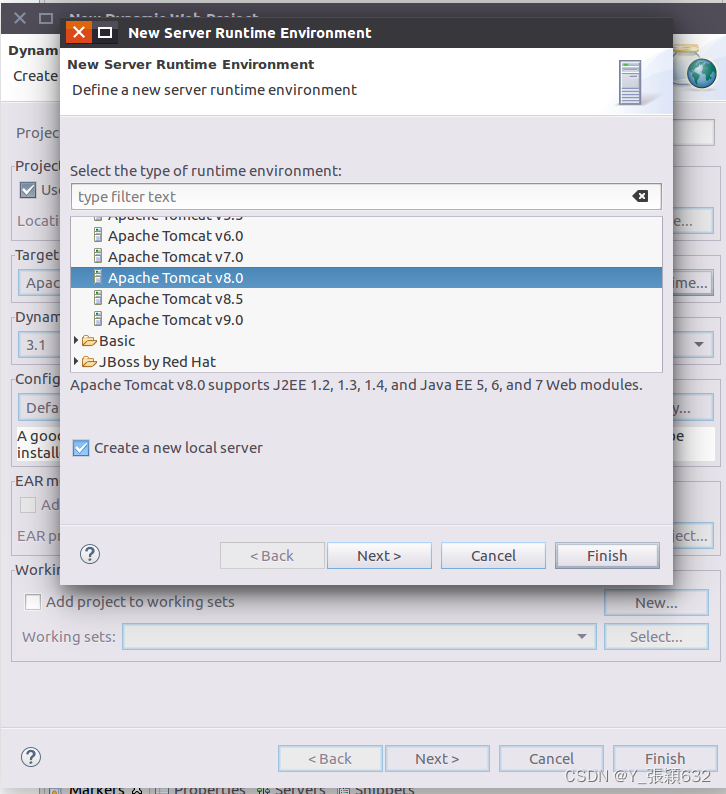
4.返回New Server Runtime Environment向导对话框,点击finish即可。
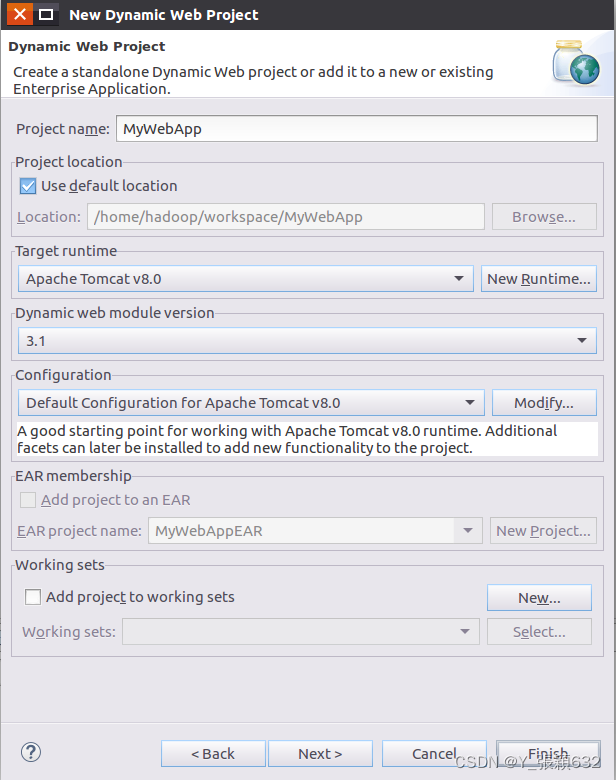
5.返回Dynamic Web Project向导对话框,点击finish即可。
6.这样新建一个Dynamic Web Project就完成了。
7.下载mysql-connector-java-5.1.40.zip
cd ~/Downloads/
unzip mysql-connector-java-5.1.40.zip -d ~
cd ~/mysql-connector-java-5.1.40/
mv ./mysql-connector-java-5.1.40-bin.jar ~/workspace/MyWebApp/WebContent/WEB-INF/lib/mysql-connector-java-5.1.40-bin.jar
利用Eclipse 开发Dynamic Web Project应用
cd ~/Downloads/
sudo tar -zxvf ~/Downloads/MyWebApp_Tomcat.tar.gz -C /usr/local
在Ubuntu中找到MyWebApp
复制地址:/usr/local/MyWebApp(复制在文件管理器中)
移动到:/home/workspace/MyWebApp(粘贴在eclipse上)
具体内容:将src复制到eclipse对应的src中
将WebContent复制到eclipse对应的WebContent中
将build复制到eclipse对应的build中
对图中选中部分进行更改,将原本的5.1.45版本改为5.1.40版本,5.1.40版本在/home/hadoop/Downloads复制即可
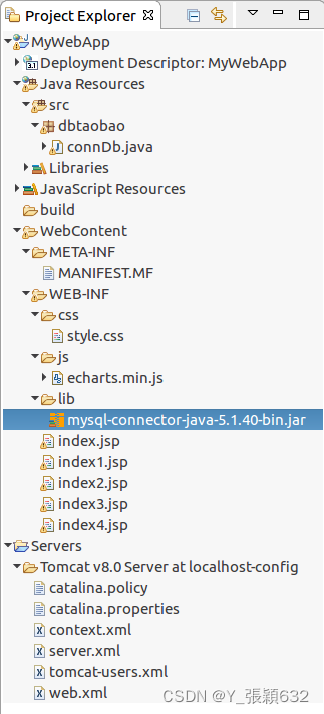
项目结构如图
如果没有显示则关闭eclipse,重新打开
ubuntu终端
cd /usr/local
./eclipse/eclipse
将index.jsp文件中的代码内容删除,改为如下内容
<%@ page language="java" import="dbtaobao.connDb,java.util.*" contentType="text/html; charset=UTF-8"
pageEncoding="UTF-8"%>
<%
ArrayList<String[]> list = connDb.index();
%>
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd">
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
<title>ECharts 可视化分析淘宝双11</title>
<link href="./css/style.css" type='text/css' rel="stylesheet"/>
<script src="./js/echarts.min.js"></script>
</head>
<body>
<div class='header'>
<p>ECharts 可视化分析淘宝双11</p>
</div>
<div class="content">
<div class="nav">
<ul>
<li class="current"><a href="#">所有买家各消费行为对比</a></li>
<li><a href="./index1.jsp">男女买家交易对比</a></li>
<li><a href="./index2.jsp">男女买家各个年龄段交易对比</a></li>
<li><a href="./index3.jsp">商品类别交易额对比</a></li>
<li><a href="./index4.jsp">各省份的总成交量对比</a></li>
</ul>
</div>
<div class="container">
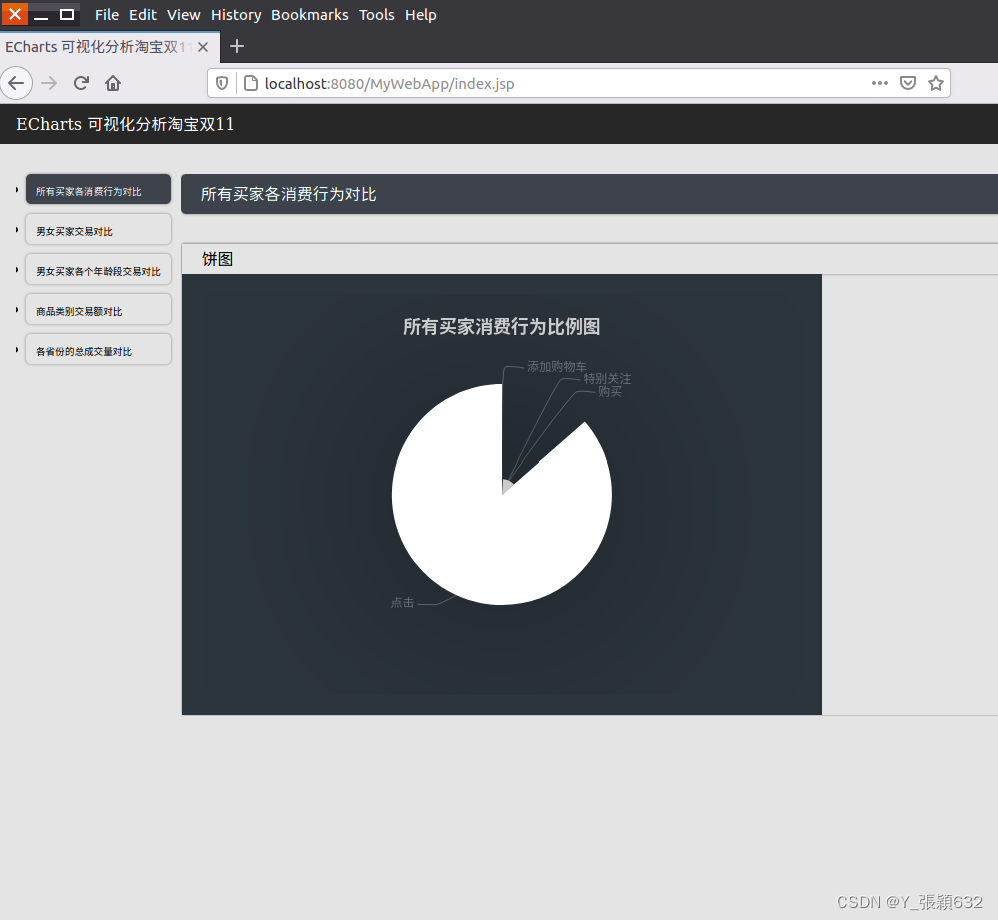
<div class="title">所有买家各消费行为对比</div>
<div class="show">
<div class='chart-type'>饼图</div>
<div id="main"></div>
</div>
</div>
</div>
<script>
//基于准备好的dom,初始化echarts实例
var myChart = echarts.init(document.getElementById('main'));
// 指定图表的配置项和数据
option = {
backgroundColor: '#2c343c',
title: {
text: '所有买家消费行为比例图',
left: 'center',
top: 20,
textStyle: {
color: '#ccc'
}
},
tooltip : {
trigger: 'item',
formatter: "{a} <br/>{b} : {c} ({d}%)"
},
visualMap: {
show: false,
min: 80,
max: 600,
inRange: {
colorLightness: [0, 1]
}
},
series : [
{
name:'消费行为',
type:'pie',
radius : '55%',
center: ['50%', '50%'],
data:[
{value:<%=list.get(0)[1]%>, name:'特别关注'},
{value:<%=list.get(1)[1]%>, name:'购买'},
{value:<%=list.get(2)[1]%>, name:'添加购物车'},
{value:<%=list.get(3)[1]%>, name:'点击'},
].sort(function (a, b) { return a.value - b.value}),
roseType: 'angle',
label: {
normal: {
textStyle: {
color: 'rgba(255, 255, 255, 0.3)'
}
}
},
labelLine: {
normal: {
lineStyle: {
color: 'rgba(255, 255, 255, 0.3)'
},
smooth: 0.2,
length: 10,
length2: 20
}
},
itemStyle: {
normal: {
color: '#c23531',
shadowBlur: 200,
shadowColor: 'rgba(0, 0, 0, 0.5)'
}
},
animationType: 'scale',
animationEasing: 'elasticOut',
animationDelay: function (idx) {
return Math.random() * 200;
}
}
]
};
// 使用刚指定的配置项和数据显示图表。
myChart.setOption(option);
</script>
</body>
</html>
将connDb.java文件中的代码内容删除,改为如下内容,注意将
DriverManager.getConnection()中的最后两个参数改为:自己的用户名,密码(例如:"root","zhangying")
package dbtaobao;
import java.sql.*;
import java.util.ArrayList;
public class connDb {
private static Connection con = null;
private static Statement stmt = null;
private static ResultSet rs = null;
//连接数据库方法
public static void startConn(){
try{
Class.forName("com.mysql.jdbc.Driver");
//连接数据库中间件
try{
con = DriverManager.getConnection("jdbc:MySQL://localhost:3306/dbtaobao?useSSL=false&useUnicode=true&characterEncoding=UTF-8&serverTimezone=UTC","root","root");
}catch(SQLException e){
e.printStackTrace();
}
}catch(ClassNotFoundException e){
e.printStackTrace();
}
}
//关闭连接数据库方法
public static void endConn() throws SQLException{
if(con != null){
con.close();
con = null;
}
if(rs != null){
rs.close();
rs = null;
}
if(stmt != null){
stmt.close();
stmt = null;
}
}
//数据库双11 所有买家消费行为比例
public static ArrayList index() throws SQLException{
ArrayList<String[]> list = new ArrayList();
startConn();
stmt = con.createStatement();
rs = stmt.executeQuery("select action,count(*) num from user_log group by action desc");
while(rs.next()){
String[] temp={rs.getString("action"),rs.getString("num")};
list.add(temp);
}
endConn();
return list;
}
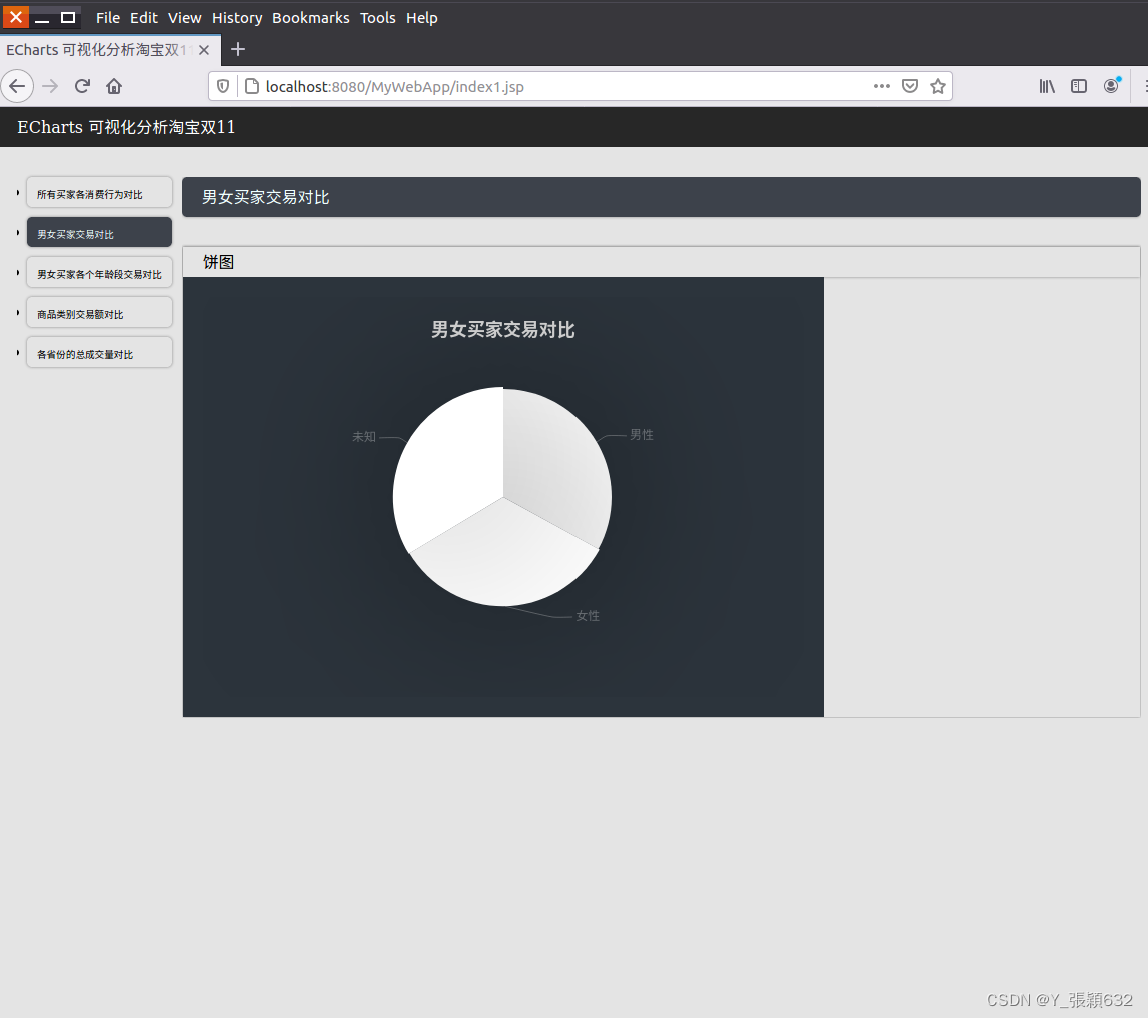
//男女买家交易对比
public static ArrayList index_1() throws SQLException{
ArrayList<String[]> list = new ArrayList();
startConn();
stmt = con.createStatement();
rs = stmt.executeQuery("select gender,count(*) num from user_log group by gender desc");
while(rs.next()){
String[] temp={rs.getString("gender"),rs.getString("num")};
list.add(temp);
}
endConn();
return list;
}
//男女买家各个年龄段交易对比
public static ArrayList index_2() throws SQLException{
ArrayList<String[]> list = new ArrayList();
startConn();
stmt = con.createStatement();
rs = stmt.executeQuery("select gender,age_range,count(*) num from user_log group by gender,age_range desc");
while(rs.next()){
String[] temp={rs.getString("gender"),rs.getString("age_range"),rs.getString("num")};
list.add(temp);
}
endConn();
return list;
}
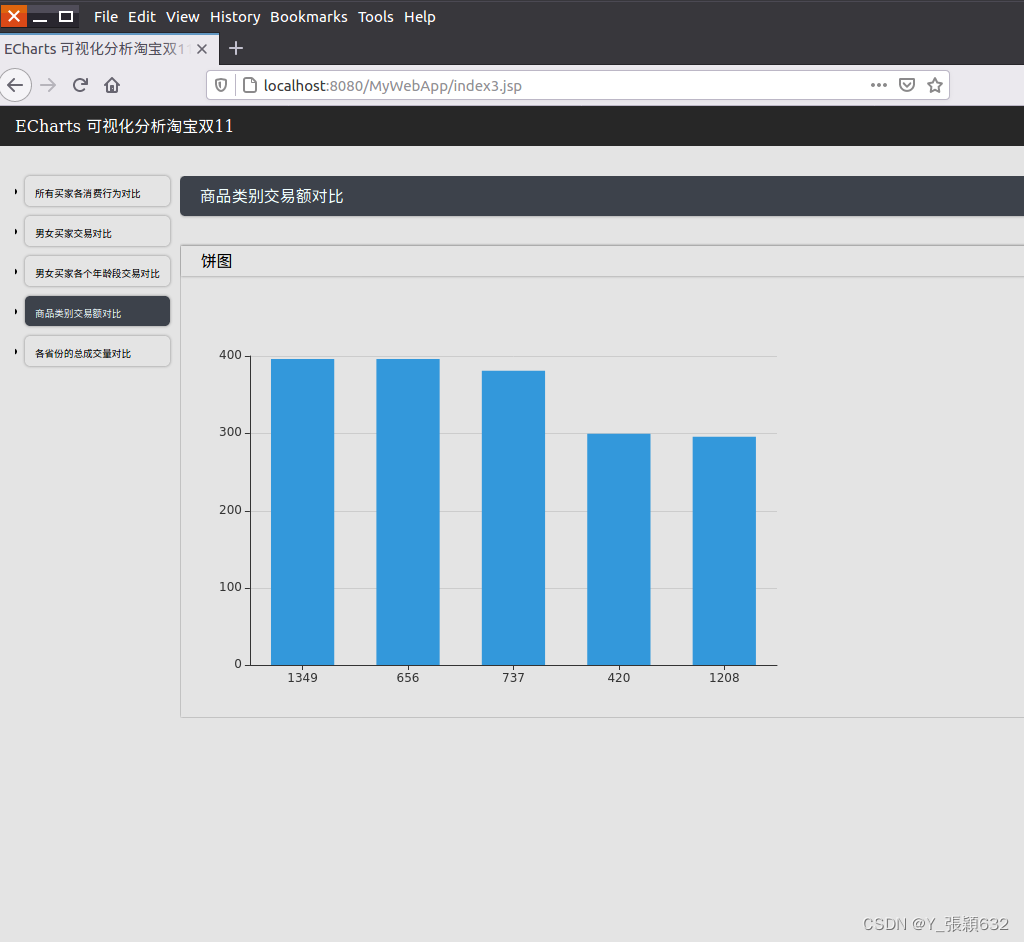
//获取销量前五的商品类别
public static ArrayList index_3() throws SQLException{
ArrayList<String[]> list = new ArrayList();
startConn();
stmt = con.createStatement();
rs = stmt.executeQuery("select cat_id,count(*) num from user_log group by cat_id order by count(*) desc limit 5");
while(rs.next()){
String[] temp={rs.getString("cat_id"),rs.getString("num")};
list.add(temp);
}
endConn();
return list;
}
//各个省份的的总成交量对比
public static ArrayList index_4() throws SQLException{
ArrayList<String[]> list = new ArrayList();
startConn();
stmt = con.createStatement();
rs = stmt.executeQuery("select province,count(*) num from user_log group by province order by count(*) desc");
while(rs.next()){
String[] temp={rs.getString("province"),rs.getString("num")};
list.add(temp);
}
endConn();
return list;
}
}
eclipse左侧的资源管理器中找不到导入的项目中的个别文件夹,而在这个文件夹又存在项目中。
解决办法:Window--->show view--->Navigator。
打开tomcat

双击打开index.jsp文件,然后顶部Run菜单选择:Run As-->Run on Server
出现如下对话框,找到运行的tomcat进行选中,点击finish。

如果出现错误

解决方法如下:
1、登录mysql数据库,查询数据库连接等待时间:show global variables like '%timeout';
interactive_timeout、wait_timeout这两个参数都是28800秒,即8小时。interactive_timeout是服务器关闭交互式连接前数据库等待的时间(如在mysql命令输入界面操作数据库),wait_timeout是服务器关闭非交互式连接前等待的时间(如程序通过hibernate连接数据库)。
2、为了保持这两个数据的同步,同时修改这两个参数。
service mysql start
mysql> set wait_timeout=864000;
mysql> set interactive_timeout=864000;
3、最后重启mysql
systemctl restart mysql;
此时通过外部浏览器,例如火狐浏览器,打开MyWebApp地址,也能查看到该项目应用。页面效果即在浏览器进行显示。

















 1143
1143

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









