






覆盖知识范围:邻接表、邻接矩阵、迪杰斯特拉算法、创建文本文件等。
最终效果图如下所示:
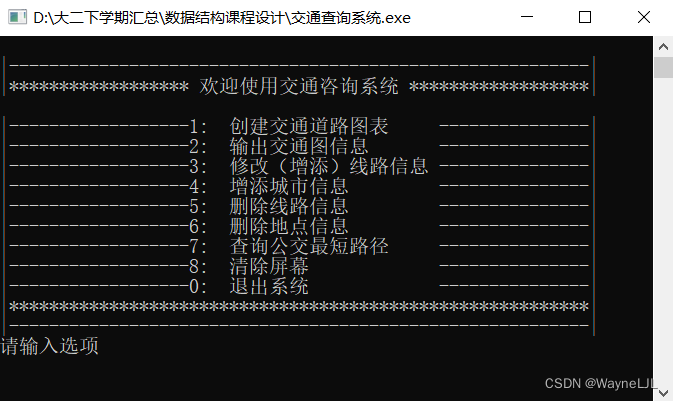
功能划分:
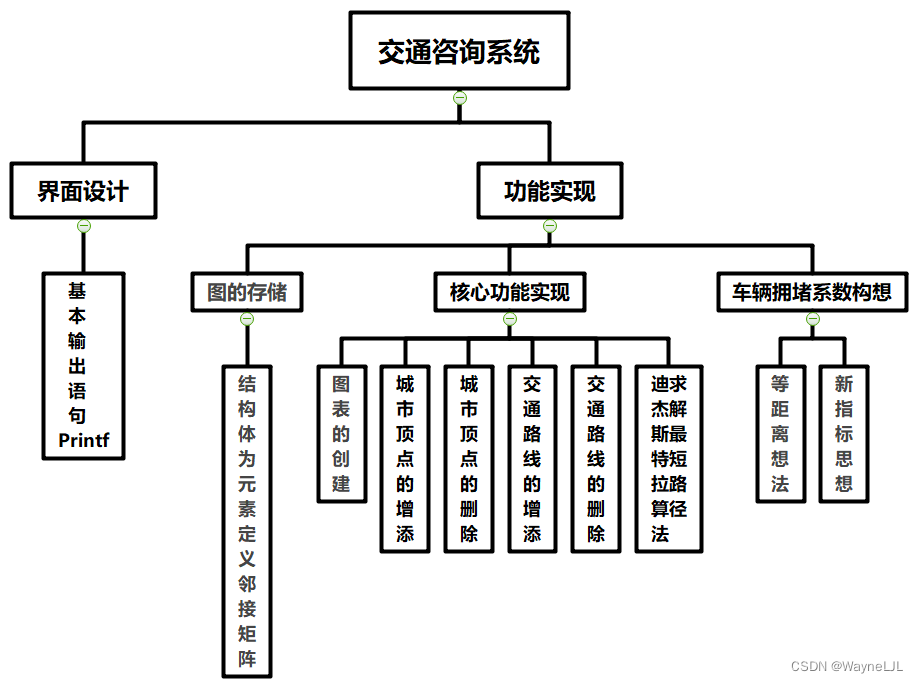
根据“交通咨询系统”的整体设计,这里将本系统所调用的所有C文件中的头文件以及函数进行简单的汇总,将其的功能加以基本介绍,也是对后面详细设计与实现部分的一个总的体现,表格信息如下图所示:
表1 交通咨询系统功能划分表
| 头文件位置 | 函数名 | 功能描述 |
| Stdlib.h | Create_net | 将用户输入的信息添加至矩阵 |
| String.h | Pri_net | 将邻接矩阵打印出来 |
| Stdio.h | Change_city | 改变或添加城市的基本信息 |
| Strstrea.h | Delete_city | 删除城市的基本信息 |
| Menu | 输出开始菜单界面 | |
| Min_path | 求出两城市间最短路径 | |
| Main | 调用执行主函数 |
通过上表,可以很清晰的看出本系统的部分功能实现与函数匹配的关系,但对层次的划分还会有些许模糊,对后期的代买编写还会出现功能的遗漏,为了进一步短时间内将此系统智能完整化,这里根据本“交通咨询系统”的设计理念,将上述功能结合当前网上资料显示的用户需求进行分析、总结、归纳,得到该系统的实体以及实体属性,并在这里采用层次图的方式抽象成信息结构即概念模型进行简单的展示,如下图所示:
一、邻接矩阵、邻接表
1.1 邻接矩阵
注意:
① 在简单应用中,可直接用二维数组作为图的邻接矩阵(顶点表及顶点数等均可省略)。
② 当邻接矩阵中的元素仅表示相应的边是否存在时,EdgeTyPe可定义为值为0和1的枚举类型。
③无向图的邻接矩阵是对称矩阵,对规模特大的邻接矩阵可压缩存储。
④邻接矩阵表示法的空间复杂度S(n)=0(n2)。
⑤建立无向网络的算法。
优势:
在算法设计方面,邻接矩阵的优势主要有:
①可以通过二维数组G[u][v]直接引用边(u, v),因此只需常数时间(O(1))即可确定顶点u和顶点v的关系。
②只要更改G[u][v]就能完成边的添加和删除,简单且高效。
1.2 邻接表
注意:
①n个顶点e条边的有向图,它的邻接表表示中有n个顶点表结点和e个边表结点。(因为有向图是单向的)
二、弗洛伊德Floyd算法
Floyd算法又称为插点法,是一种利用动态规划的思想寻找给定的加权图中多源点之间最短路径的算法,与Dijkstra算法类似。具体核心代码如下所示:
#include<stdio.h>
#include<stdlib.h>
#define max 1000000000
int d[1000][1000],path[1000][1000];
int main()
{
int i,j,k,m,n;
int x,y,z;
scanf("%d%d",&n,&m);
for(i=1;i<=n;i++)
for(j=1;j<=n;j++){
d[i][j]=max;
path[i][j]=j;
}
for(i=1;i<=m;i++) {
scanf("%d%d%d",&x,&y,&z);
d[x][y]=z;
d[y][x]=z;
}
for(k=1;k<=n;k++)
for(i=1;i<=n;i++)
for(j=1;j<=n;j++) {
if(d[i][k]+d[k][j]<d[i][j]) {
d[i][j]=d[i][k]+d[k][j];
path[i][j]=path[i][k];
}
}
for(i=1;i<=n;i++)
for(j=1;j<=i;j++)
if (i!=j) printf("%d->%d:%d\n",i,j,d[i][j]);
int f, en;
scanf("%d%d",&f,&en);
while (f!=en) {
printf("%d->",f);
f=path[f][en];
}
printf("%d\n",en);
return 0;
}三、普里姆Prim算法
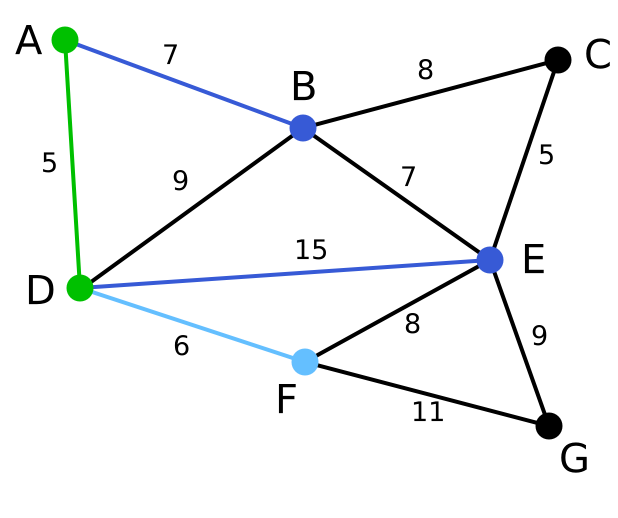
普里姆算法(Prim算法),图论中的一种算法,可在加权连通图里搜索最小生成树。意即由此算法搜索到的边子集所构成的树中,不但包括了连通图里的所有顶点(英语:Vertex (graph theory)),且其所有边的权值之和亦为最小。图示如下:
| 图例 | 说明 | 不可选 | 可选 | 已选(Vnew) |
|
| 此为原始的加权连通图。每条边一侧的数字代表其权值。 | - | - | - |
|
| 顶点D被任意选为起始点。顶点A、B、E和F通过单条边与D相连。A是距离D最近的顶点,因此将A及对应边AD以高亮表示。 | C, G | A, B, E, F | D |
|
| 下一个顶点为距离D或A最近的顶点。B距D为9,距A为7,E为15,F为6。因此,F距D或A最近,因此将顶点F与相应边DF以高亮表示。 | C, G | B, E, F | A, D |
|
| 算法继续重复上面的步骤。距离A为7的顶点B被高亮表示。 | C | B, E, G | A, D, F |
|
| 在当前情况下,可以在C、E与G间进行选择。C距B为8,E距B为7,G距F为11。点E最近,因此将顶点E与相应边BE高亮表示。 | 无 | C, E, G | A, D, F, B |
|
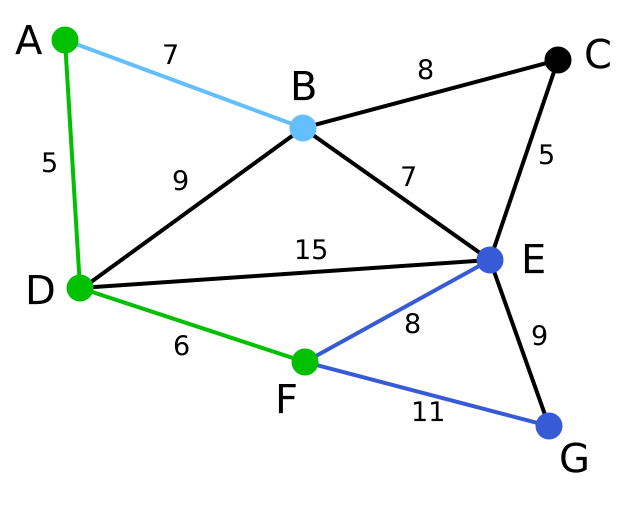
| 这里,可供选择的顶点只有C和G。C距E为5,G距E为9,故选取C,并与边EC一同高亮表示。 | 无 | C, G | A, D, F, B, E |
|
| 顶点G是唯一剩下的顶点,它距F为11,距E为9,E最近,故高亮表示G及相应边EG。 | 无 | G | A, D, F, B, E, C |
|
| 所有顶点均已被选取,图中绿色部分即为连通图的最小生成树。在此例中,最小生成树的权值之和为39。 | 无 | 无 | A, D, F, B, E, C, G |






部分核心代码展示如下:
#define MAXN 1000
#define INF 1<<30
int closest[MAXN],lowcost[MAXN],m;//m为节点的个数
int G[MAXN][MAXN];//邻接矩阵
int prim()
{
for(int i=0;i<m;i++)
{
lowcost[i] = INF;
}
for(int i=0;i<m;i++)
{
closest[i] = 0;
}
closest[0] = -1;//加入第一个点,-1表示该点在集合U中,否则在集合V中
int num = 0,ans = 0,e = 0;//e为最新加入集合的点
while (num < m-1)//加入m-1条边
{
int micost = INF,miedge = -1;
for(int i=0;i<m;i++)
if(closest[i] != -1)
{
int temp = G[e][i];
if(temp < lowcost[i])
{
lowcost[i] = temp;
closest[i] = e;
}
if(lowcost[i] < micost)
micost = lowcost[miedge=i];
}
ans += micost;
closest[e = miedge] = -1;
num++;
}
return ans;
}四、Dijkstra迪杰斯特拉算法核心
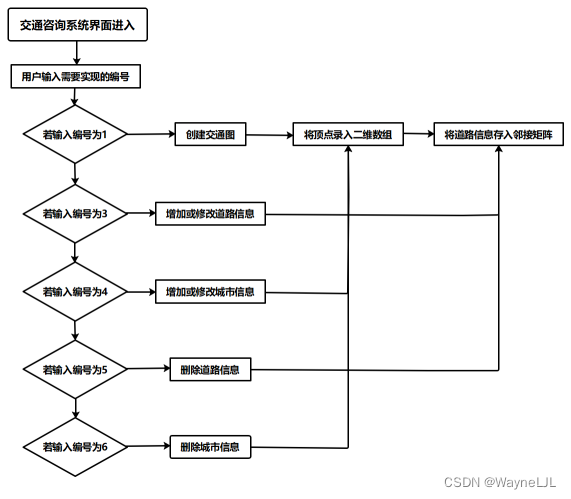
其中,交通咨询系统城市和道路信息的增删流程的分析图如下图所示:
4.1 初始化结构体对象
此处代码为结构体变量的定义,目的是对图型结构的存储形式进行简单的声明,此时变量的定义分别代表存储地点名称,Num 为交通图中所包含最多地点数量,这里8是指单个地点的字符串长度不能超过8 、利用邻接表存储行驶每条道路花费的时间、地点数量和地点的道路的数量。具体代码展示如下:
typedef struct
{
char citys[Num][Num];
float time[Num][Num];
int citynum,roadnum;
} mgraph;4.2 利用邻接表和邻接矩阵创建地点交通图,初始化矩阵信息
这段代码主要是利用邻接矩阵创建地点交通图,通过单字符流获取用户输入的城市个数,与此同时设置for循环利用编号与城市字符串二维数组匹配,达到实现自动补全城市编号的效果,再通过gets函数,把输入的城市信息放入到citys字符串数组中,然后初始化矩阵,此时将矩阵中所有位置都填上999,表示道路间的最大距离,即所有地点都不直接相邻,并且假设999 就是邻接矩阵中的∞,利用for循环方法输入边的信息,并且根据用户输入的道路拥堵系数,来计算每条道路行驶的时间,并将数据存入邻接矩阵的二维数组当中,这里设置本邻接矩阵为对称矩阵,因此也从而确定了无向图的标准,通过系数的引入,来实现交通图的设置,这一功能。
void create_net(mgraph *g) {
int i,j,k,v,drivetime;
float t,m;
printf("请输入城市数量和道路数量:");
scanf("%d %d",&g->citynum,&g->roadnum);
getchar();
for(i=1; i<=g->citynum; i++)
{ //输入地点信息(名)
printf("第%d 个城市信息:",i);//有符号的十进制整数
gets(g->citys[i]);
}
for(i=1; i<=g->citynum; i++)
{ for(j=1; j<=g->citynum; j++){
g->time[i][j]=999; }}
... ...
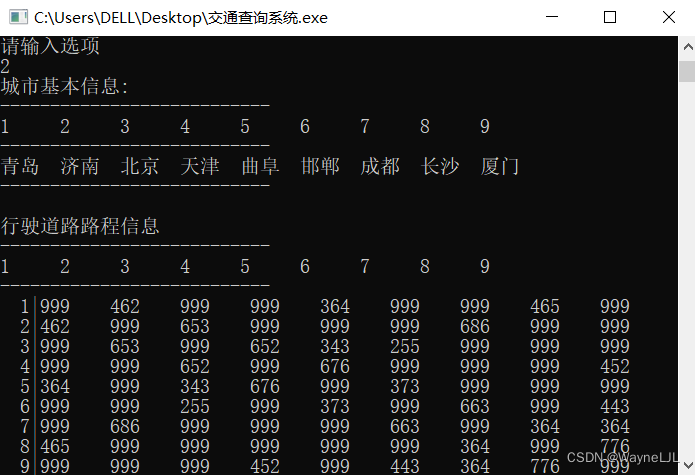
}效果图如下所示:

4.3 按顺序输出邻接矩阵
这里定义输出的格式为“%-6d”、“%-6s”形式,即输出的字符串只占六列,若大于则全部输出,若小于则补全,是为了适应上述对citys二维数组的声明定义,由于C语言中并没有字符串类型,因此对于字符串的存储,这里只能选用二维数组的形式,对字符串进行单个字符的存储,这也就顺理成章的引出了下面字符串覆盖的strcpy()方法。部分代码展示如下:
for(i=1;i<=g->citynum;i++)
{
printf("%3d|",i);
int j=1;
for(j=1;j<=g->citynum;j++)
{
printf("%-6.f ",g->time[i][j]);
}
printf("\n");
}效果图展示如下:
4.4 创建文件txt信息
此部分代码是根据文件读取的方法,将与前面的最短路径算法联动,在输出用户所需两城市即两顶点之间最短路径的同时,将顶点与最短路径存入文本文档中,首先根据fopen函数,定义“w”即路径中未存在此文件时自定义生成的形式,将信息调用fprintf的方法存入,实现简单的后台存储功能,为后期功能的进一步优化与扩充提供思路。代码如下:
void txt(mgraph *g){
FILE *fp;
fp=fopen("chaxun.txt","w");
... ...
fprintf(fp,"\n途径路径:%d ",v);
fprintf(fp,"%s ",g->citys[v]);
while(Path[v]!=-1)
{
fprintf(fp,"<-%d ",Path[v]);
fprintf(fp,"%s ",g->citys[Path[v]]);
printf("<-");
printf("%d ",Path[v]);
printf(g->citys[Path[v]]);
v=Path[v];
}
fclose(fp);
} 效果图展示如下:

4.5 计算最短路径
这里度最短路径的求解,首先我定义了两个数组Path与dis,一个用来存储途径的顶点路径,一个用来存储最短路径的距离大小,这里通过学习,巧妙的使用了memset算法,将路径的集合填充上-1,原因在于路径上的顶点值必大于零,因此,也方便了后期输出代码的判断,接着,我将dis距离数组填充上最大值,也是利用了任何一个自定义路径都会小于这个值的原理,然后,我们根据用户的顶点输入开始循环判断,首先在代码中,将自回路设置为0,接着设置两个整型变量,用于放入que数组中,设置循环中需要查询的顶点的值,这里在while语句内外设置的自增运算,是为了将查询顶点带入到循环内部,根据两个if语句的判断,将路径值最终赋给dis数组中,这里也是对核心代码的一个特色的改变,即在本循环语句中,并没有用到终点的编号,而是将起点所有的最短路径带入到数组之中,根据后续的代码进行输出,而此处que数组的重新赋值,则可以理解为对待测顶点的设置。部分代码展示如下:
void min_path(mgraph *g) {
memset(Path,-1,sizeof Path);
printf("输入要查询的两个点编号\n");
... ...
if(g->time[u][i]<999){
if(dis[u]+g->time[u][i]<dis[i]){
Path[i]=u;dis[i]=dis[u]+g->time[u][i];
que[++tail]=i;}}}}txt();} 4.6 设置界面主函数Main
需源码 私信扣扣 1092644308















 3314
3314











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









