







前言
提前了解:八大排序算法详解(通俗易懂)_杯浅的博客-CSDN博客
一.判断题
快速排序是稳定的算法。F
快速排序是不稳定排序,它可能会交换两个值相同的元素
将 10 个元素散列到 100 000 个单元的哈希表中,一定不会产生冲突。F
哈希算法会有小概率发生冲突现象,但是概率不会太大
哈希表-散列表
【哈希究竟代表什么?哈希表和哈希函数的核心原理】 https://www.bilibili.com/video/BV1SZ4y1z7wT/?share_source=copy_web&vd_source=a6401c9820869ff8ca006c68478cde72
【『教程』哈希表是个啥?】 https://www.bilibili.com/video/BV1qR4y1V7g6/?share_source=copy_web&vd_source=a6401c9820869ff8ca006c68478cde72
对N个记录进行快速排序,在最坏的情况下,其时间复杂度是O(NlogN)。F
对N个记录进行快速排序,在最坏的情况下,其时间复杂度是O(N^2);
对N个记录进行简单选择排序,比较次数和移动次数分别为O(N^2)和O(N)。T
即使把2个元素散列到有100个单元的表中,仍然有可能发生冲突。T
基于比较的排序算法中,只要算法的最坏时间复杂度或者平均时间复杂度达到了次平方级O(N * logN),则该排序算法一定是不稳定的。F

希尔排序是稳定的算法。F
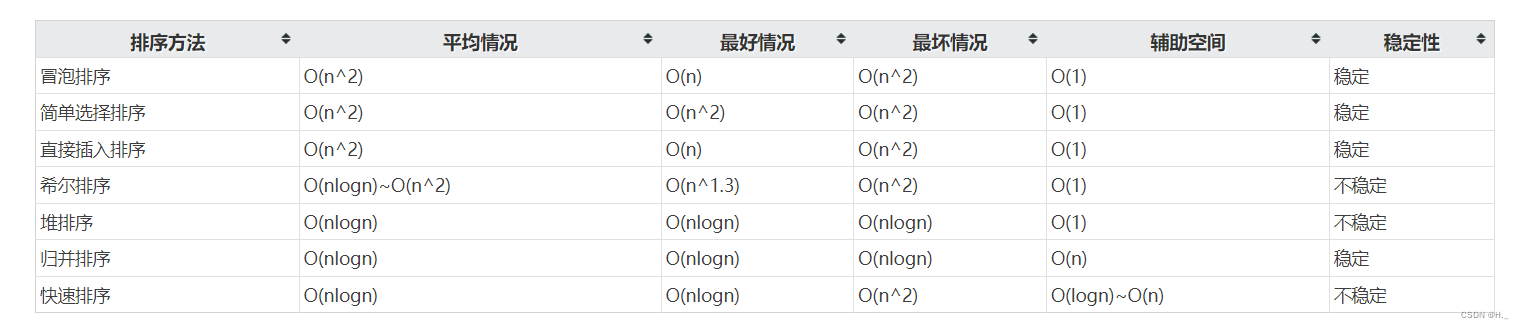
对N个不同的数据采用冒泡排序进行从大到小的排序,当元素基本有序时交换元素次数肯定最多。F
得看"有序"是正序还是逆序;
在散列表中,所谓同义词就是被不同散列函数映射到同一地址的两个元素。F
具有相同函数值的关键字对该散列函数来说称作同义词。
直接选择排序的时间复杂度为O(n^2),不受数据初始排列的影响。T
直接选择排序的时间复杂度是固定的O(n^2)
在散列中,函数“插入”和“查找”具有同样的时间复杂度。T
解析:插入和查找具有同样的时间复杂度O(1)。
对N个不同的数据采用冒泡排序进行从大到小的排序,当元素基本有序时交换元素次数肯定最多。
F
得看"有序"是正序还是逆序;
对N个记录进行堆排序,需要的额外空间为O(N)。F
堆排序仅需一个记录大小供交换用的辅助存储空间,所以空间复杂度为O(1)
直接插入排序是不稳定的排序方法。F
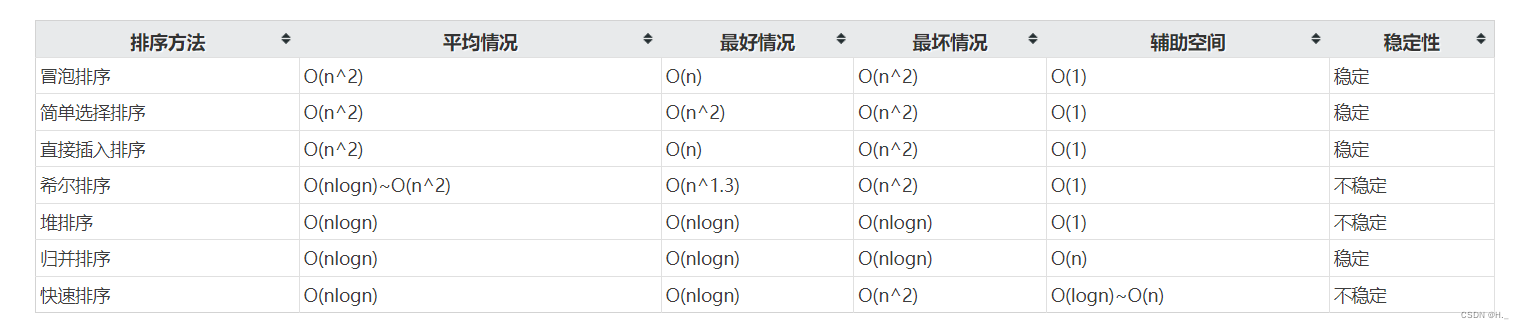
堆是完全二叉树,完全二叉树不一定是堆。T
在堆排序中,若要进行升序排序,则需要建立大根堆。T

快速排序的速度在所有排序方法中为最快,而且所需附加空间也最少。F
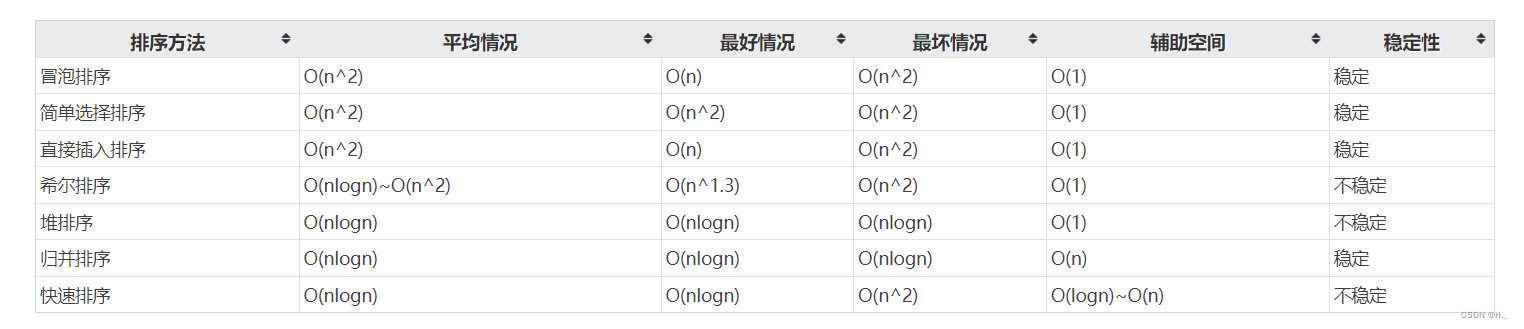
对N个记录进行归并排序,归并趟数的数量级是O(NlogN)。F
注意是归并的躺数的数量级而不是归并排序的时间复杂度, 因此为logN。
【数据结构——三分钟搞定归并排序】 https://www.bilibili.com/video/BV1hs4y1a7aM/?share_source=copy_web&vd_source=a6401c9820869ff8ca006c68478cde72
要从50个键值中找出最大的3个值,选择排序比堆排序快。T
规模较小直接选择排序快。
在任何情况下,归并排序都比简单插入排序快。F
内排序要求数据一定要以顺序方式存储。F
错。内排序是指在排序的整个过程中,数据全部存放在计算机的内存储器中,并且在内存储器中调整记录的相对位置,但并不要求以顺序方式存储。
冒泡排序算法的最坏时间复杂性是O(n2),而快速排序算法的最坏时间复杂性是O(nlog2n),所以快速排序比冒泡排序效率好。F
(101,88,46,70,34,39,45,58,66,10)是堆。T
层序遍历来看,这是最大堆
当待排序记录已经从小到大排序或者已经从大到小排序时,快速排序的执行时间最省。F
在基本有序的情况下,快速排序算法的时间复杂度为O(n^2);无序时, 快排才比较省时间O(n*logn)
有一大根堆,堆中任意结点的关键字均大于它的左右孩子关键字,则其具有最小值的结点一定是一个叶子结点并可能在堆的最后两层中。T
将M个元素存入用长度为S的数组表示的散列表,则该表的装填因子为M/S。T
散列表的装填因子 α 定义为 =表中填入的记录数 / 散列表的长度;
用希尔(shell)方法排序时,若关键字的初始排序杂乱无序,则排序效率就低。F
希尔排序又称“缩小增量排序”,即每趟只对相同增量距离的关键字进行比较,这与关键字序列初始有序或无序无关
排序的稳定性是指排序算法中的比较次数保持不变,且算法能够终止。F
稳定性:稳定排序算法会让原本有相等键值的纪录维持相对次序。也就是如果一个排序算法是稳定的,当有两个相等键值的纪录R和S,且在原本的列表中R出现在S之前,在排序过的列表中R也将会是在S之前。
二.单选题
1.下列排序算法中,哪种算法可能出现:在最后一趟开始之前,所有的元素都不在其最终的位置上?(设待排元素个数N>2)
A.快速排序
B.冒泡排序
C.堆排序
D.插入排序
插入排序可能插在第一个,所有元素后移一位。
2.给定散列表大小为17,散列函数为H(Key)=Key%17。采用平方探测法处理冲突:hi(k)=(H(k)±i2)%17将关键字序列{ 6, 22, 7, 26, 9, 23 }依次插入到散列表中。那么元素23存放在散列表中的位置是:
A.0
B.15
C.6
D.2
有简单的冲突解决方案的算法介绍
【哈希究竟代表什么?哈希表和哈希函数的核心原理】 https://www.bilibili.com/video/BV1SZ4y1z7wT/?share_source=copy_web&vd_source=a6401c9820869ff8ca006c68478cde72

3.在下列查找的方法中,平均查找长度与结点个数无关的查找方法是:
A.利用二叉搜索树
B.顺序查找
C.二分法
D.利用哈希(散列)表
散列表的平均查找长度依赖于散列表的装填因子,不直接依赖于表的长度
4.对N个记录进行堆排序,最坏的情况下时间复杂度是:
A.O(N^2)
B.O(N)
C.O(logN)
D.O(NlogN)
5.将序列{ 2, 12, 16, 88, 5, 10, 34 }排序。若前2趟排序的结果如下:
- 第1趟排序后:2, 12, 16, 10, 5, 34, 88
- 第2趟排序后:2, 5, 10, 12, 16, 34, 88
则可能的排序算法是:
A.冒泡排序
B.插入排序
C.快速排序
D.归并排序
6.对N个元素采用简单选择排序,比较次数和移动次数分别为:
A.O(logN), O(N^2)
B.O(N), O(logN)
C.O(N^2), O(N)
D.O(NlogN), O(NlogN)
7.有组记录的排序码为{ 46,79,56,38,40,84 },则利用堆排序的方法建立的初始堆为:
A.84,79,56,38,40,46
B.84,79,56,46,40,38
C.84,56,79,40,46,38
D.79,46,56,38,40,80
堆排序基于最大堆来实现
8.假定有k个关键字互为同义词,若用线性探测法把这k个关键字存入散列表中,至少要进行多少次探测?( )
A.k(k+1)/2次
B.k次
C.k-1次
D.k+1次
链接:假定有k个关键字互为同义词,若用线性探测法把这k个关键字存入__牛客网
来源:牛客网
线性探测法:通过散列函数hash(key),找到关键字key在线性序列中的位置,如果当前位置已经有了一个关键字,就产生了哈希冲突,就往后探测i个位置(i小于线性序列的大小),直到当前位置没有关键字存在。
互为同义词可以理解为都hash到同一个位置上,如果不是第一个到达该位置的值,我们就需要以某一策略(这里理解为每次往后面移一个位置即可)依次往后面查找,直到找到空位置,所以总的查找次数就是 1+2+...+k=k(k+1)/2
9.对于10个数的简单选择排序,最坏情况下需要交换元素的次数为:
A.9
B.45
C.36
D.100
因为倒最后一趟的时候要找的序列只有第一个元素自己 ,所以就不用比较了,比较n-1次就可以
10.对包含N个元素的散列表进行查找,平均查找长度为:
A.不确定
B.O(logN)
C.O(N)
D.O(1)
散列表是线性表查找的一种方法。这种方法的一个特点是,平均检索长度不直接依赖于元素的个数。元素的个数增加,其平均检索长度并不增加,而与负载因子有关。
11.设有100个元素的有序序列,如果用二分插入排序再插入一个元素,则最大比较次数是:
A.7
B.50
C.25
D.10
可以根据二叉搜索树判断,最多为 [ log2(n) ]向下取整 + 1次.
12.下面四种排序算法中,稳定的算法是:
A.堆排序
B.归并排序
C.希尔排序
D.快速排序
13.在散列表中,所谓同义词就是:
A.被映射到不同散列地址的一个元素
B.具有相同散列地址的两个元素
C.被不同散列函数映射到同一地址的两个元素
D.两个意义相近的单词
在散列表中,所谓同义词就是具有相同散列地址的两个元素。
C选项:改成 相同散列函数 才对
14.下列排序方法中,()是稳定的排序方法?
A.希尔排序
B.直接选择排序
C.快速排序
D.直接插入排序
15.某内排序方法的稳定性是指()。
A.该排序算法不允许有相同的关键字记录
B.平均时间为0(nlog2n)的排序方法
C.该排序算法允许有相同的关键字记录
D.以上都不对
内排序是指数据全部在内存中进行排序;稳定性是指数据中相同关键字的数据排序前后相对顺序不改变;
16.对一组数据{ 2,12,16,88,5,10 }进行排序,若前三趟排序结果如下:
第一趟排序结果:2,12,16,5,10,88
第二趟排序结果:2,12,5,10,16,88
第三趟排序结果:2,5,10,12,16,88
则采用的排序方法可能是:
A.基数排序
B.希尔排序
C.冒泡排序
D.归并排序
17.已知线性表的关键字集合 { 21,11, 13,25,48,6,39,83,30,96,108 },散列函数为 h(key)=key%11,采用分离链接法解决冲突。则成功查找的平均查找长度为 __
A.2.36
B.1.27
C.1.18
D.1.36
15/11中的11不是表长,而是查找的元素个数

有简单的解决冲突的算法介绍
【哈希究竟代表什么?哈希表和哈希函数的核心原理】 https://www.bilibili.com/video/BV1SZ4y1z7wT/?share_source=copy_web&vd_source=a6401c9820869ff8ca006c68478cde72
18.设散列表的地址区间为[0,16],散列函数为H(Key)=Key%17。采用线性探测法处理冲突,并将关键字序列{ 26,25,72,38,8,18,59 }依次存储到散列表中。元素59存放在散列表中的地址是:
A.10
B.8
C.9
D.11
有简单的解决冲突的算法介绍
【哈希究竟代表什么?哈希表和哈希函数的核心原理】 https://www.bilibili.com/video/BV1SZ4y1z7wT/?share_source=copy_web&vd_source=a6401c9820869ff8ca006c68478cde72
19.假定有K个关键字互为同义词,若用线性探测法把这K个关键字存入散列表中,至少要进行多少次探测?
A.K
B.K−1
C.K(K+1)/2
D.K+1
链接:假定有k个关键字互为同义词,若用线性探测法把这k个关键字存入__牛客网
来源:牛客网
线性探测法:通过散列函数hash(key),找到关键字key在线性序列中的位置,如果当前位置已经有了一个关键字,就产生了哈希冲突,就往后探测i个位置(i小于线性序列的大小),直到当前位置没有关键字存在。
互为同义词可以理解为都hash到同一个位置上,如果不是第一个到达该位置的值,我们就需要以某一策略(这里理解为每次往后面移一个位置即可)依次往后面查找,直到找到空位置,所以总的查找次数就是 1+2+...+k=k(k+1)/2
20.设哈希表长为14,哈希函数是H(key)=key%11,表中已有数据的关键字为15,38,61,84共四个,现要将关键字为49的结点加到表中,用二次探测再散列法解决冲突,则放入的位置是( )
A.8
B.3
C.5
D.9
二次探测法--平方探测法;
【哈希究竟代表什么?哈希表和哈希函数的核心原理】 https://www.bilibili.com/video/BV1SZ4y1z7wT/?share_source=copy_web&vd_source=a6401c9820869ff8ca006c68478cde72
21.对N个记录进行堆排序,需要的额外空间为:
A.O(1)
B.O(N)
C.O(NlogN)
D.O(logN)
22.有组记录的排序码为{46,79,56,38,40,84 },采用快速排序(以位于最左位置的对象为基准而)得到的第一次划分结果为:
A.{40,38,46,56,79,84}
B.{38,46,79,56,40,84}
C.{38,46,56,79,40,84}
D.{38,79,56,46,40,84}
【数据结构 快速排序的手排过程 【一学就会系列】】 https://www.bilibili.com/video/BV18T4y197xL/?share_source=copy_web&vd_source=a6401c9820869ff8ca006c68478cde72
23.对N个记录进行快速排序,在最坏的情况下,其时间复杂度是:
A.O(N)
B.O(N^2logN)
C.O(NlogN)
D.O(N^2)
24.对大部分元素已有序的数组进行排序时,直接插入排序比简单选择排序效率更高,其原因是:
- (I). 直接插入排序过程中元素之间的比较次数更少
- (II). 直接插入排序过程中所需要的辅助空间更少
- (III). 直接插入排序过程中元素的移动次数更少
A.I、II 和 III
B.仅 III
C.仅 I、II
D.仅 I
课本P238:直接插入排序
(I).最好情况下,比较1次;
(II). 直接插入法只需要一个记录的辅助空间r[0],所以空间复杂度为O(1);
(III).最好情况下,不移动;
课本P247:简单选择排序:
(I).无论什么情况下,比较次数都为 n(n-1)/2;
(II). 只有在两个记录交换时需要一个辅助空间,所以空间复杂度为O(1);
(III).最好情况,不移动;
所以 (I). 对;(II). 一样,错;(III).一样,错;
————————————————
版权声明:本文为CSDN博主「嘻嘻的妙妙屋」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/Jessieeeeeee/article/details/107307114
25.选择一个排序算法时,除算法的时空效率外,下列因素中,还需要考虑的是:
- I、数据的规模
- II、数据的存储方式
- III、算法的稳定性
- IV、数据的初始状态
A.I、II、III、IV
B.仅 II、III、IV
C.仅 III
D.仅 I、II
26.下面的四种排序方法中,()的排序过程中的比较次数与初始状态无关。
A.快速排序
B.选择排序法
C.插入排序
D.堆排序
链接:排序算法中,比较次数与初始序列无关的排序方法有哪些?_搜狐笔试题_牛客网
来源:牛客网
- 元素的移动次数与关键字的初始排列次序无关的是:基数排序
- 元素的比较次数与初始序列无关是:选择排序、折半插入排序
- 算法的时间复杂度与初始序列无关的是:选择排序、堆排序、归并排序、基数排序
- 算法的排序趟数与初始序列无关的是:插入排序、选择排序、基数排序
27.给定散列表大小为17,散列函数为H(Key)=Key%17。采用平方探测法处理冲突:hi(k)=(H(k)±i2)%17将关键字序列{ 23, 22, 7, 26, 9, 6 }依次插入到散列表中。那么元素6存放在散列表中的位置是:
A.10
B.15
C.6
D.2
28.排序过程中,对尚未确定最终位置的所有元素进行一遍处理称为一“趟”。下列序列中,不可能是快速排序第二趟结果的是:
A.2, 16, 5, 28, 12, 60, 32, 72
B.5, 2, 16, 12, 28, 60, 32, 72
C.5, 2, 12, 28, 16, 32, 72, 60
D.2, 12, 16, 5, 28, 32, 72, 60
(1条消息) 数据结构:下列选项中,不可能是快速排序第2趟排序结果的是(2019年全国试题10)_不可能是快速排序第二趟排序结果的是_寒泉Hq的博客-CSDN博客
29.设有一组关键字 { 29,01, 13,15,56,20,87,27,69,9,10,74 },散列函数为 H(key)=key%17,采用平方探测方法解决冲突。试在 0 到 18 的散列地址空间中对该关键字序列构造散列表,则成功查找的平均查找长度为 __
A.1.25
B.0.33
C.1.33
D.1.17
引用:(1条消息) 数据结构——排序查找算法作业(PTA 第12-13周)大一下_顺序查找pta-CSDN博客
题目是说要平方探测方法,故应该是11 1 13 15 5 3 2 8 1 9 10 6,有冲突,然后1±1,发现地址为0可以,故变为11 1 13 15 5 3 2 8 0 9 10 6,此时是69比较了2次,故计算成功查找的平均查找长度:(11*1+2)/12=1.25
(1条消息) 散列表平均查找长度计算题_real_metrix的博客-CSDN博客
包括成功和失败的
30.现有长度为 11 且初始为空的散列表 HT,散列函数是 H(key)=key%7,采用线性探查(线性探测再散列)法解决冲突。将关键字序列 87,40,30,6,11,22,98,20 依次插入到 HT 后,HT 查找失败的平均查找长度是:
A.6
B.4
C.6.29
D.5.25
31.在快速排序的一趟划分过程中,当遇到与基准数相等的元素时,如果左指针停止移动,而右指针在同样情况下却不停止移动,那么当所有元素都相等时,算法的时间复杂度是多少?
A.O(NlogN)
B.O(N^2)
C.O(N)
D.O(logN)

32.对于7个数进行冒泡排序,需要进行的比较次数为:
A.14
B.21
C.49
D.7
最坏的情况下
第一轮冒泡,索引 1 的数与索引 2 的数比较,2与3比较……6与7比较,比较6次。
第二轮就是5次。以此类推,到最后一轮只有一个数的时候不进行比较,是0次。
6+5+4+3+2+1+0= 21
33.将关键字序列 { 7,8,30,11,18,9,14 },散列存储到散列列表中,散列表的存储空间是一个下标从 0 开始的一维数组。处理冲突采用线性探测法。散列函数为 h(key)=(key×3)% 表长,要求装入因子为 0.7。则成功查找的平均查找长度为 __
A.1.14
B.1.57
C.1.00
D.1.29
散列表的装填因子 α 定义为 =表中填入的记录数 / 散列表的长度;
表长为10;和其他的题目不一样!!!
34.下列排序算法中( )排序在一趟结束后不一定能选出一个元素放在其最终位置上。
A.归并
B.冒泡
C.选择
D.堆
希尔,归并,直接插入都有可能某一趟结束后未必能选出一个元素放在其最终位置上
链接:下列排序算法中,某一趟结束后未必能选出一个元素放在其最终位置__牛客网
来源:牛客网
简单选择排序,能够取出当前无序序列中最(小or大)值与第一位置的元素互换位置。
堆排序每趟总能选出一个最值位于根节点。
冒泡排序总是两两比较选出一个最值位于数组前面。
快速排序选出的枢轴在一趟排序中就位于了它最终的位置
插入排序(直接、二分)不一定会位于最终的位置,因为不确定插入的元素对于前面的元素是否产生影响。
希尔排序(本质也是插入排序)只在子序列中直接插入排序。所以不能确定。
二路归并排序除非在缓存区一次放入所有的序列(这样得不偿失),否则不能确定最终位置。
所以只有 简单选择排序、快速排序、冒泡排序、堆排序才 在第一趟中选出一个元素放在最终位置
35.对初始数据序列{ 8, 3, 9, 11, 2, 1, 4, 7, 5, 10, 6 }进行希尔排序。若第一趟排序结果为( 1, 3, 7, 5, 2, 6, 4, 9, 11, 10, 8 ),第二趟排序结果为( 1, 2, 6, 4, 3, 7, 5, 8, 11, 10, 9 ),则两趟排序采用的增量(间隔)依次是:
A.5, 2
B.3, 2
C.3, 1
D.5, 3
D 先看第一趟,1从最开始的5号位移动到0号位,说明第一趟步长是5,直接排除A,B
再看第二趟,2从第一趟排序结果的第4位移动到1号位,说明第二趟步长是3
36.下列排序算法中,时间复杂度不受数据初始状态影响,恒为O(NlogN)的是:
A.直接选择排序
B.冒泡排序
C.快速排序
D.堆排序
37.对N个记录进行归并排序,归并趟数的数量级是:
A.O(NlogN)
B.O(N^2)
C.O(logN)
D.O(N)
注意是归并的躺数的数量级而不是归并排序的时间复杂度, 因此为logN。
【数据结构——三分钟搞定归并排序】 https://www.bilibili.com/video/BV1hs4y1a7aM/?share_source=copy_web&vd_source=a6401c9820869ff8ca006c68478cde72
三.算法题
1.R6-1 冒泡排序
编程实现冒泡排序函数。void bubbleSort(int arr[], int n);。其中arr存放待排序的数据,n为数组长度(1≤n≤1000)。
函数接口定义如下:
/* 对长度为n的数组arr执行冒泡排序 */ void bubbleSort(int arr[], int n);
请实现bubbleSort函数,使排序后的数据从小到大排列。
裁判测试程序样例:
#include <stdio.h> #define N 1000 int arr[N]; /* 对长度为n的数组arr执行冒泡排序 */ void bubbleSort(int arr[], int n); /* 打印长度为n的数组arr */ void printArray(int arr[], int n); void swap(int *xp, int *yp) { int temp = *xp; *xp = *yp; *yp = temp; } int main() { int n, i; scanf("%d", &n); for (i = 0; i < n; ++i) { scanf("%d", &arr[i]); } bubbleSort(arr, n); printArray(arr, n); return 0; } /* 打印长度为n的数组arr */ void printArray(int arr[], int n) { int i; for (i = 0; i < n; i++) { printf("%d", arr[i]); if (i < n - 1) /* 下标0..n-2每个元素后面有个空格 */ printf(" "); /*下标n-1,也就是最后一个元素后面没有空格*/ } printf("\n"); /* 一行打印完后换行 */ } /* 你的代码将嵌在这里 */输入样例:
10
1 19 9 11 4 3 5 8 10 6
输出样例:
1 3 4 5 6 8 9 10 11 19#include<stdbool.h>
void bubbleSort(int *arr,int n)
{
for(int i=n-1;i>0;i--)
{
bool flag=false;
for(int j=0;j<i;j++)
{
if(arr[j]>arr[j+1])
{
swap(&arr[j],&arr[j+1]);
flag=true;
}
}
if(flag==false)break;
}
}2. R6-2 插入排序
编程实现插入排序函数。void insertionSort(int arr[], int n);。其中arr存放待排序的数据,n为数组长度(1≤n≤1000)。
函数接口定义如下:
/* 对长度为n的数组arr执行插入排序 */ void insertionSort(int arr[], int n);
请实现insertionSort函数,使排序后的数据从小到大排列。
裁判测试程序样例:
#include <stdio.h> #define N 1000 int arr[N]; /* 对长度为n的数组arr执行插入排序 */ void insertionSort(int arr[], int n); /* 打印长度为n的数组arr */ void printArray(int arr[], int n); int main() { int n, i; scanf("%d", &n); for (i = 0; i < n; ++i) { scanf("%d", &arr[i]); } insertionSort(arr, n); printArray(arr, n); return 0; } /* 打印长度为n的数组arr */ void printArray(int arr[], int n) { int i; for (i = 0; i < n; i++) { printf("%d", arr[i]); if (i < n - 1) /* 下标0..n-2每个元素后面有个空格 */ printf(" ");/*下标n-1,也就是最后一个元素后面没有空格*/ } printf("\n");/* 一行打印完后换行 */ } /* 你的代码将嵌在这里 */
输入样例:
10
1 19 9 11 4 3 5 8 10 6
输出样例:
1 3 4 5 6 8 9 10 11 19void insertionSort(int *arr,int n)//直接插入排序
{
for(int i=0;i<n-1;i++)
{
//单趟插入排序
int end=i;
int temp=arr[end+1];
while(end>=0)
{
if(temp<arr[end])
{
arr[end+1]=arr[end];
end--;
}else{
break;
}
}
arr[end+1]=temp;
}
}3. R6-3 二分查找
本题要求实现二分查找算法。
函数接口定义:
Position BinarySearch( List L, ElementType X );
其中List结构定义如下:typedef int Position; typedef struct LNode *List; struct LNode { ElementType Data[MAXSIZE]; Position Last; /* 保存线性表中最后一个元素的位置 */ };
L是用户传入的一个线性表,其中ElementType元素可以通过>、==、<进行比较,并且题目保证传入的数据是递增有序的。函数BinarySearch要查找X在Data中的位置,即数组下标(注意:元素从下标1开始存储)。找到则返回下标,否则返回一个特殊的失败标记NotFound。
裁判测试程序样例:
#include <stdio.h> #include <stdlib.h> #define MAXSIZE 10 #define NotFound 0 typedef int ElementType; typedef int Position; typedef struct LNode *List; struct LNode { ElementType Data[MAXSIZE]; Position Last; /* 保存线性表中最后一个元素的位置 */ }; List ReadInput(); /* 裁判实现,细节不表。元素从下标1开始存储 */ Position BinarySearch( List L, ElementType X ); int main() { List L; ElementType X; Position P; L = ReadInput(); scanf("%d", &X); P = BinarySearch( L, X ); printf("%d\n", P); return 0; } /* 你的代码将被嵌在这里 */
输入样例1:
5
12 31 55 89 101
31
输出样例1:
2
输入样例2:
3
26 78 233
31
输出样例2:
0Position BinarySearch(List L, ElementType X)
{
int left=1 , right=L->Last ;//记住数组的两端
while(left<=right)//如果left>right则查找不到
{
int middle=(left+right)/2;
if(L->Data[middle]==X)//找到要查的元素
return middle;
else if(L->Data[middle]<X)//如果中间值比X小,则在数组的右边查
left=middle+1;
else
right=middle-1;
}
return NotFound;
}4.R7-1 选择排序
本题要求从键盘读入n个整数,对这些数做选择排序。输出选择排序每一步的结果和最终结果。
输入格式:
输入的第一行是一个正整数n,表示 在第二行中会有n个整数。
输出格式:
输出选择排序每一步的结果和最终结果。
输入样例:
在这里给出一组输入。例如:
5
3 7 2 9 1
输出样例:
在这里给出相应的输出。例如:
step 1: 1 7 2 9 3
step 2: 1 2 7 9 3
step 3: 1 2 3 9 7
step 4: 1 2 3 7 9
sorted array: 1 2 3 7 9#include<bits/stdc++.h> using namespace std; void SelectSort(int *arr,int n); int main() { int n; cin>>n; int *arr = new int[n]; for(int i=0;i<n;i++) { cin>>arr[i]; } //进行选择排序 SelectSort(arr,n); return 0; } void SelectSort(int *arr,int n) { for(int i=0;i<=n-1;i++) { int minid=i; for(int j=i+1;j<=n-1;j++) { if(arr[j]<arr[minid]) { minid=j; } } //交换位置 int temp; temp=arr[i]; arr[i]=arr[minid]; arr[minid]=temp; if(i!=n-1) { printf("step %d: ",i+1); for(int k=0;k<n;k++) { printf("%d ",arr[k]); } printf("\n"); }else { printf("sorted array: "); for(int k=0;k<n;k++) { printf("%d ",arr[k]); } } } }
















 5623
5623











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











