







数据结构-排序篇:
内容:
- 思维导图(基于教材)
- 错题复盘+计算题(基于习题解析)
1.思维导图(基于教材)

2.错题复盘+计算题(基于习题解析)
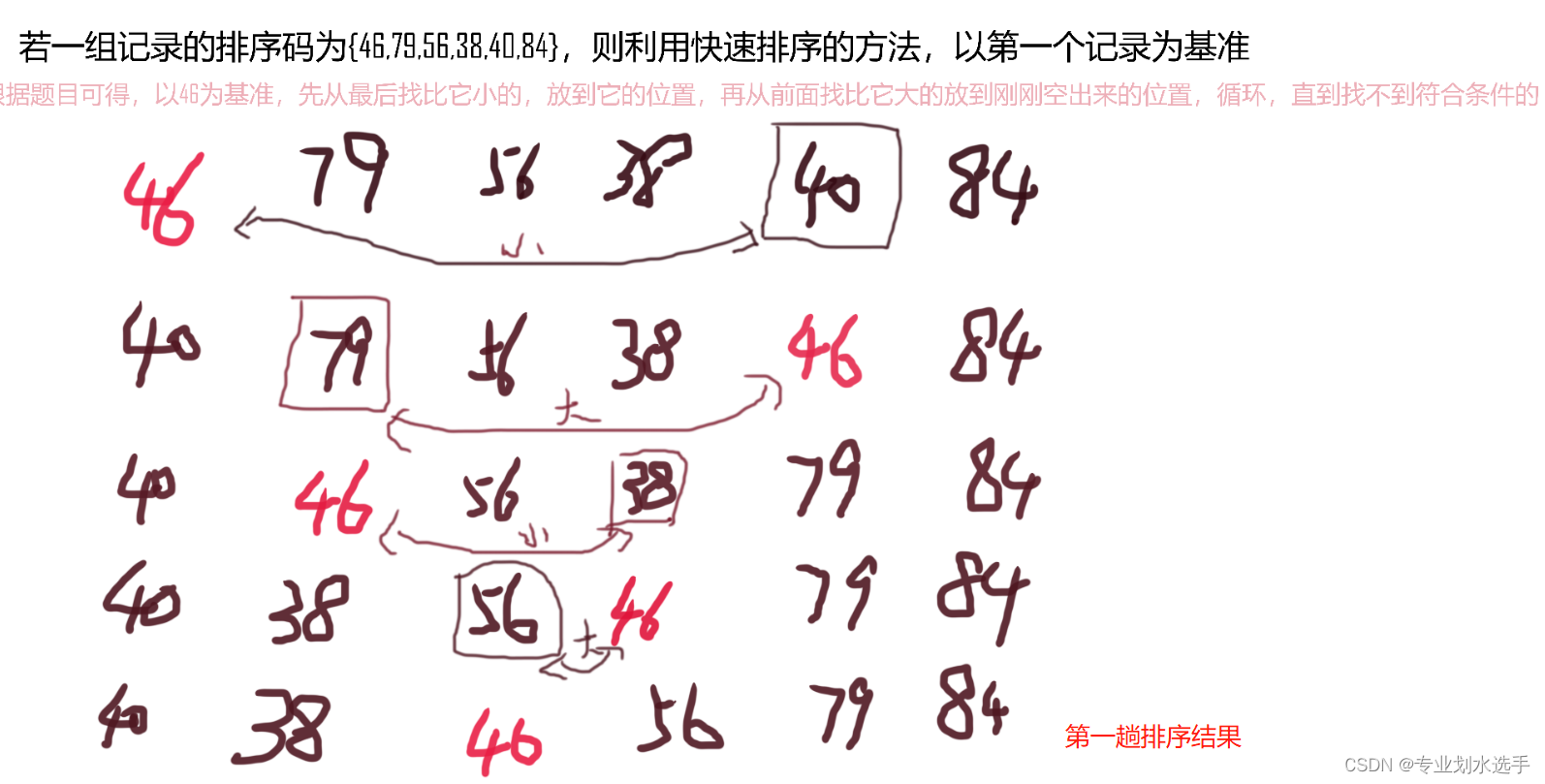
1 若一组记录的排序码为{46,79,56,38,40,84},则利用快速排序的方法,以第一个记录为基准得到的一次划分结果为(C)
A.38,40,46,56,79,84
B.40,38,46,79,56,84
C.40,38,46,56,79,84
D.40,38,46,84,56,79
解析:划分过程如下图所示
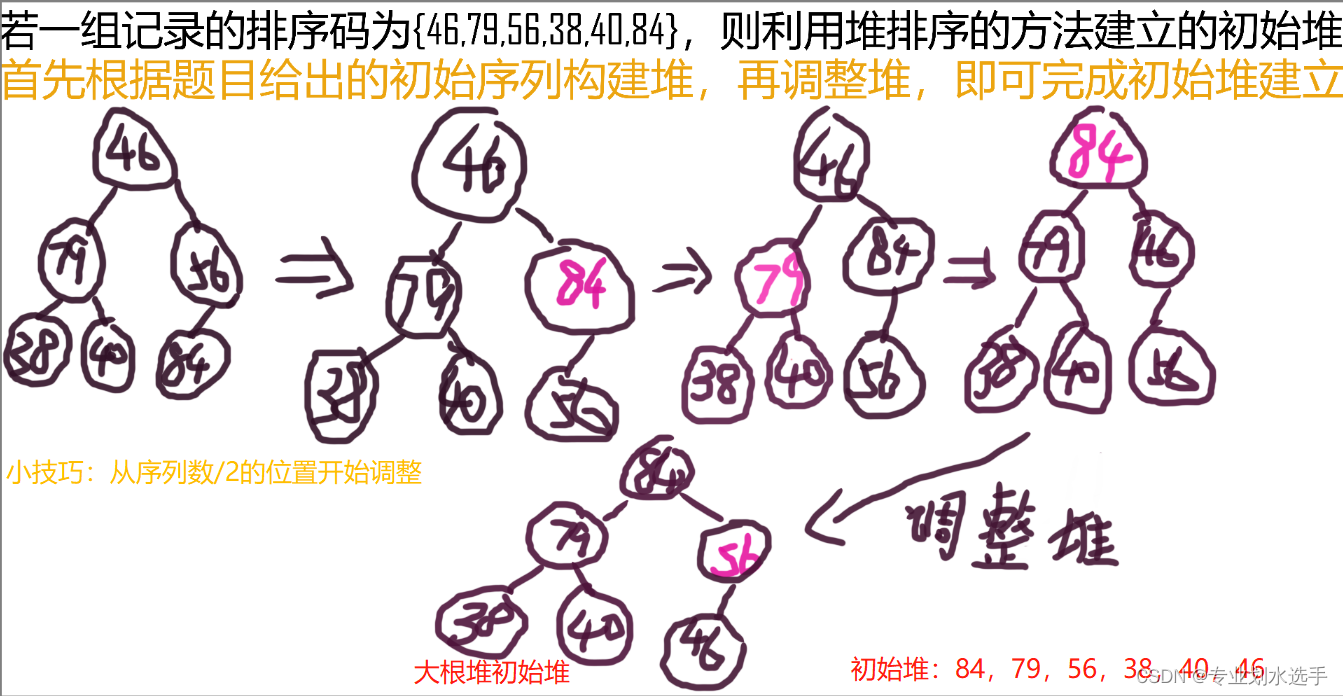
2 若一组记录的排序码为{46,79,56,38,40,84},则利用堆排序的方法建立的初始堆为(B)
A.79,46,56,38,40,84
B.84,79,56,38,40,46
C.84,79,56,46,40,38
D.84,56,79,40,46,38
解析:可以通过观察选项得出,题目需要建立大根堆,建立过程如下图所示
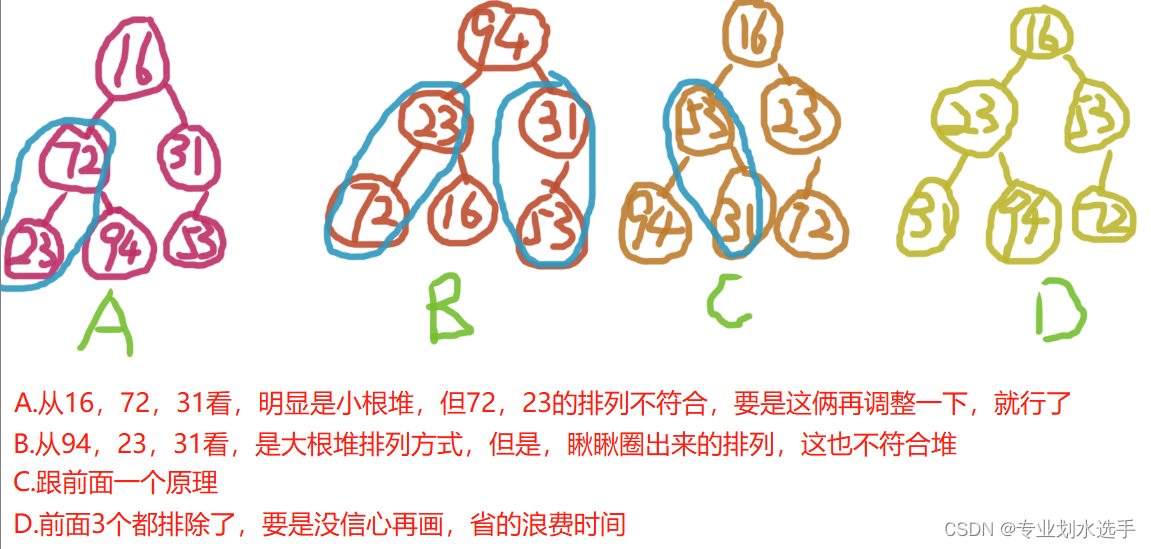
3 下列关键字序列中,(D)是堆
A.16,72,31,23,94,53
B.94,23,31,72,16,53
C.16,53,23,94,31,72
D.16,23,53,31,94,72
解析:根据四个选项,画出对应堆,再判断是否为合法堆,如下图所示
4 数据表中有10000个元素,如果仅要求求出最大的10个元素,则采用(D)算法最节省时间
A.冒泡排序 B.快速排序 C.简单选择排序 D.堆排序
解析:平均情况下,冒泡排序和简单选择排序的时间复杂度是O(n^2),快速排序和堆排序的时间复杂度是O(nlog2n),但是快速排序每趟排序并不能确定一个最大数,所以堆排序最省时
5 如果待排元素个数n很大,例如超过100000,关键字的基数固定且位数不大,则基数排序的时间复杂度接近(B)
A.O(1) B.O(n) C.O(nlog2n) D.O(n^2)
解析:书上内容,对于n个记录(假设每个记录含d个关键字,每个关键字的取值范围为rd个值)进行链式基数排序时,每趟分配的时间复杂度为O(n),每趟收集的时间复杂度为O(rd),整个排序需要进行d趟分配和收集,所以时间复杂度为O(d(n+rd))。题目里讲了关键字基数固定且位数不大,因此rd可以忽略不计,所以基数排序的时间复杂度接近O(n)
6 当待排序序列的元素个数较多,元素的初始排列可能出现基本有序或基本逆序的情形,若对排序结果的稳定性不做要求时,宜采用(B)
A.直接排序 B.堆排序 C.快速排序 D.简单选择排序
解析:直接排序和简单选择排序适合序列基本有序的情况,不适合基本逆序的情形。快速排序适合初始记录无序的情况,若初始记录基本有序或基本逆序,那么时间复杂度会跟简单排序一样。堆排序适用于初始记录无序的情况,不过无论初始记录基本有序或基本逆序,时间复杂度都是O(nlog2 n)
7 适合并行处理的排序算法是(C)
A.折半插入排序 B.冒泡排序 C.快速排序 D.归并排序
解析:快速排序经过一趟排序后,会有左右两个子序列,在接下来的排序中,左右子序列并行处理,效率更高
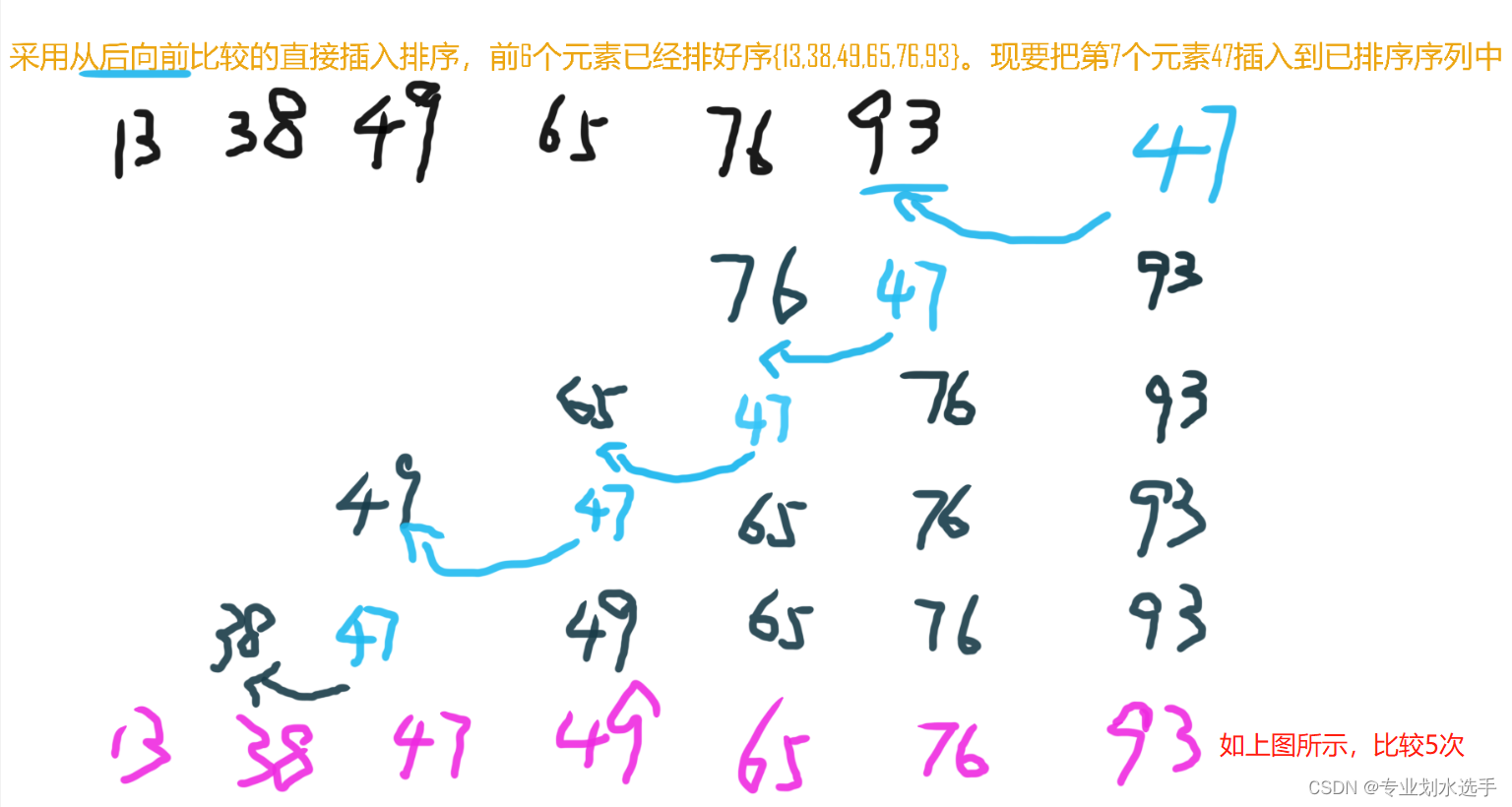
8 对序列{49,38,65,97,76,13,47,50}采用从后向前比较的直接插入排序,假设前6个元素已经排好序,如{13,38,49,65,76,93}。现在要把第7个元素47插入到已排序序列中,为寻找插入的合适位置,需要进行(C)次元素间的比较
A.3 B.4 C.5 D.6
解析:如下图所示
9 设在磁盘上存放有375000个记录,做5路平衡归并排序,内存工作区能容纳600个记录,为把所有记录排好序,需要做(B)趟归并排序
A.3 B.4 C.5 D.6
解析:由题所示,归并段为5,初始归并段个数=375000/600=624,归并趟数=向上取整log归并段个数 初始归并段个数=向上取整log 5 625=4
10 设有5个初始归并段,每个归并段有20个记录,采用5路平衡归并排序,若不采用败者树,使用传统的顺序选出最小记录(简单选择排序)的方法,总的比较次数是(20);若采用败者树最小的方法,总的比较次数是(300)
解析:不采用败者树的时候,对于k-路归并,让u个记录分布在k个归并段上,归并后的第一个记录应该是k个归并段中最小关键字记录,即应从每个归并段的第一个记录的相互比较中选出最小值,需要k-1次比较。同理,每得到归并后的有序段中的一个记录,都要进行k-1次比较。为了得到含u个记录的归并段需要进行(u-1)(k-1)次比较。从题目可知,在5个归并段中需要比较4次,共有100个记录,需要比较99次选出最小值,所以共需要比较4*99=396
采用败者树最小的方法时,内部归并的比较次数与归并路数无关,5路归并说明败者树的外结点有5个,败者树的高度h是向上取整log2 5。每次在参加比较的记录中选择关键字最小的记录,比较次数不超过高度h,共有100个记录,总比较次数不超过100*3=300
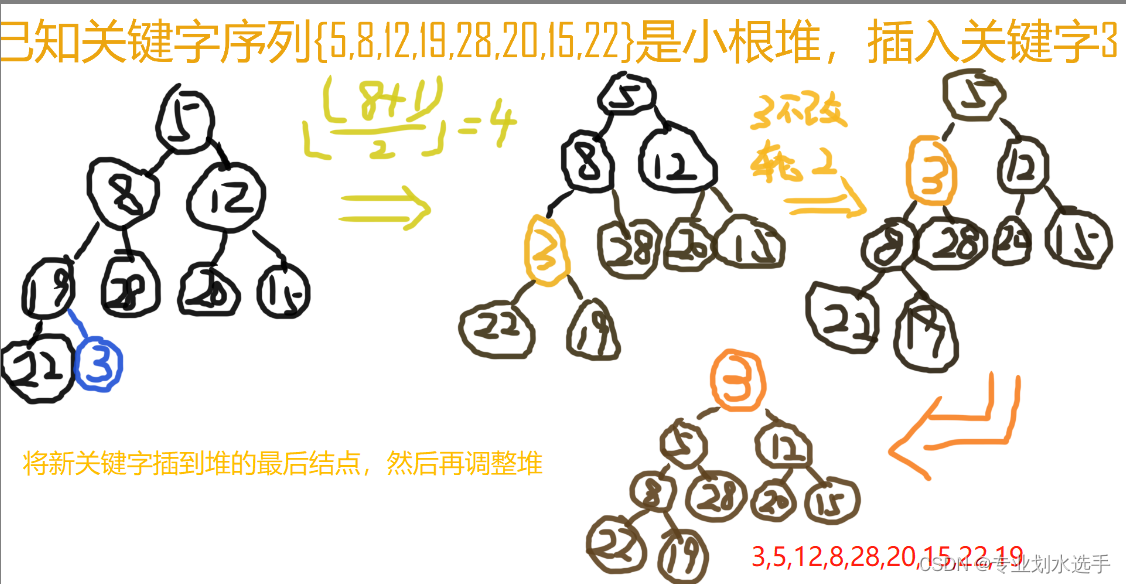
11 已知关键字序列{5,8,12,19,28,20,15,22}是小根堆,插入关键字3,调整后得到的小根堆是(A)
A.3,5,12,8,28,20,15,22,19
B.3,5,12,19,20,15,22,8,28
C.3,8,12,5,20,15,22,28,19
D.3,12,5,8,28,20,15,22,19
解析:如下图所示
12 若数据元素序列{11,12,13,7,8,9,23,4,5}是采用下列排序方法之一得到的第二趟排序后的结果,则该排序算法只能是(B)
A.冒泡排序 B.插入排序 C.选择排序 D.归并排序
解析:用排除法,假设用的是冒泡排序或选择排序,那么第二趟排序后的结果应该有2个最大或最小的元素,但题目给的序列不符合。如果用的是归并排序,那么应该形成2个长度为4的和1个长度为1的有序子序列,这也不符合
13 采用递归方式对顺序表进行快速排序,下列关于递归次数的叙述中,正确的是(D)
A.递归次数与初始数据的排列次数无关
B.每次划分后,先处理较长的分区可以减少递归次数
C.每次划分后,先处理较短的分区可以减少递归次数
D.递归次数与每次划分后得到的分区处理顺序无关
14 对一组数据{2,12,16,88,5,10}进行排序,若前三趟排序结果如下。
第一趟:{2,12,16,5,10,88};
第二趟:{2,12,5,10,16,88};
第三趟:{2,5,10,12,16,88};
则采用的排序方法可能是(A)
A.冒泡排序 B.希尔排序 C.归并排序 D.基数排序
解析:从三趟排序结果来看,每趟排序都能确定一个最大元素,所以选冒泡排序
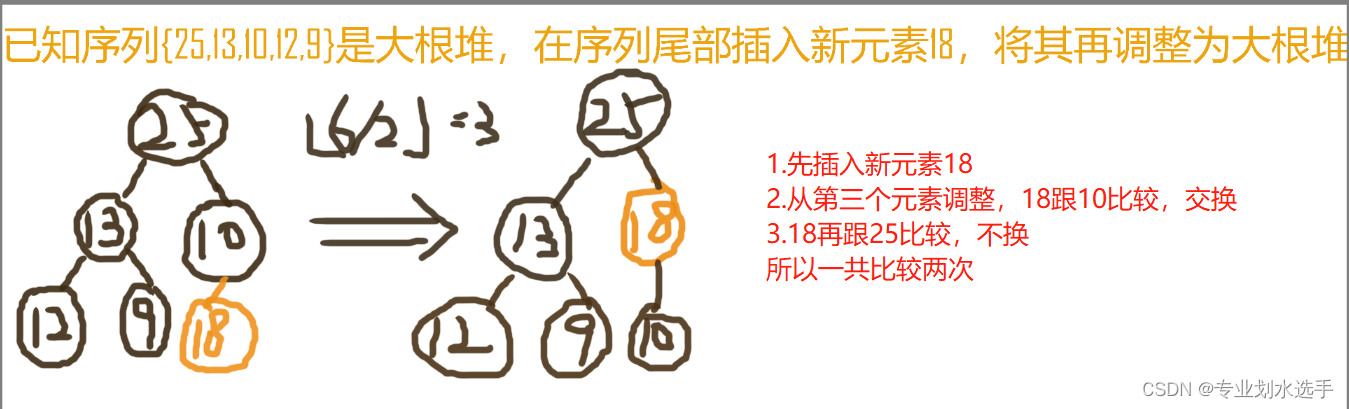
15 已知序列{25,13,10,12,9}是大根堆,在序列尾部插入新元素18,将其再调整为大根堆,调整过程中元素之间进行的比较次数为(B)
A.1 B.2 C.4 D.5
解析:原理跟11题一样
16 若对给定的关键字序列{110,119,007,911,114,120,122}进行基数排序,则第2趟分配收集后得到的关键字序列为(C)
A.{007,110,119,114,911,120,122}
B.{007,110,119,114,911,122,120}
C.{007,110,911,114,119,120,122}
D.{110,120,911,122,114,007,119}
解析:按照题目完成第2趟就能出答案,不用多做一步,我只是多举个例子

17 用希尔排序方法对一个数据序列进行排序时,若第一趟排序结果为9,1,4,13,7,8,20,23,15,则该趟排序采用的增量(间隔)可能是(B)
A.2 B.3 C.4 D.5
解析:不能直接算出来增量,只能根据选项值列判断,如下图所示

18 下列选项中,不可能是快速排序第2趟排序结果的是(C)
A.{2,3,5,4,6,7,9}
B.{2,7,5,6,4,3,9}
C.{3,2,5,4,7,6,9}
D.{4,2,3,5,7,6,9}
解析:考的是快速排序的定义,每趟排序结束后都将枢纽元素放入最终位置,且枢纽之前的所有元素均小于它,之后的所有元素均大于它。所以第2趟排序结束后,至少有2个元素放在最终位置。A、B中的2,9可以当作枢纽,D中的5,9可以当作枢纽。C只有9可以当枢纽
19 已知小根堆为{8,15,10,21,34,16,12},删除关键字8之后重建堆,在此过程中,关键字之间的比较次数是(C)
A.1 B.2 C.3 D.4
解析:值得注意的是,堆删除关键字后,由序列尾部关键字补上

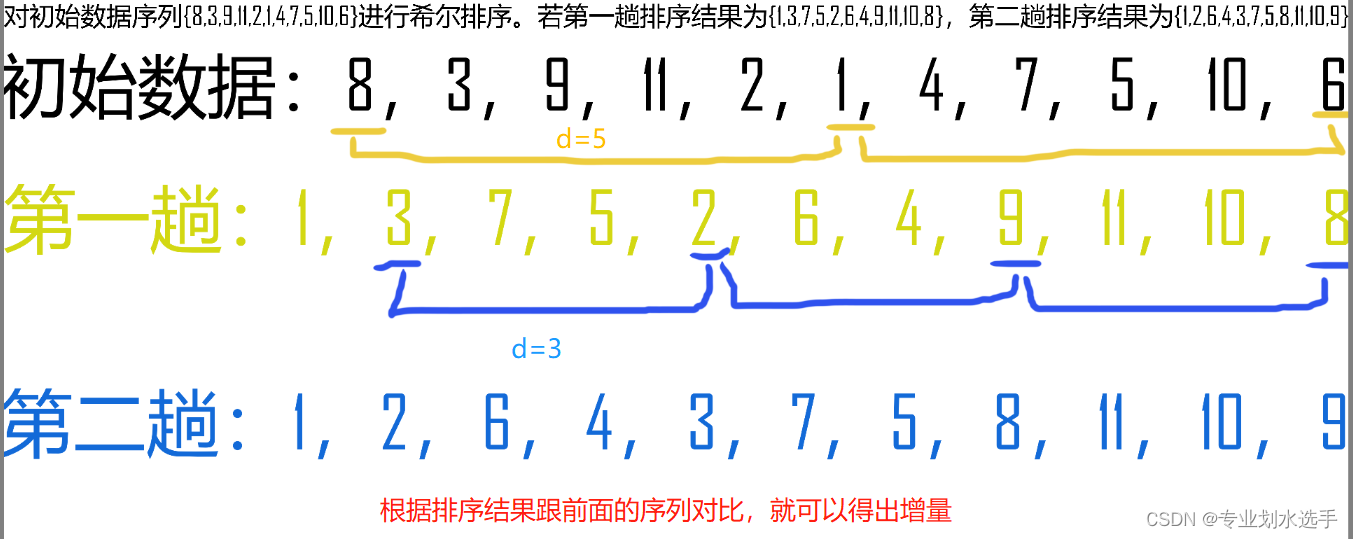
20 对初始数据序列{8,3,9,11,2,1,4,7,5,10,6}进行希尔排序。若第一趟排序结果为{1,3,7,5,2,6,4,9,11,10,8},第二趟排序结果为{1,2,6,4,3,7,5,8,11,10,9},则两趟排序采用的增量(间隔)依次是(D)
A.3,1 B.3,2 C.5,2 D.5,3
解析:列举对比,如下图所示
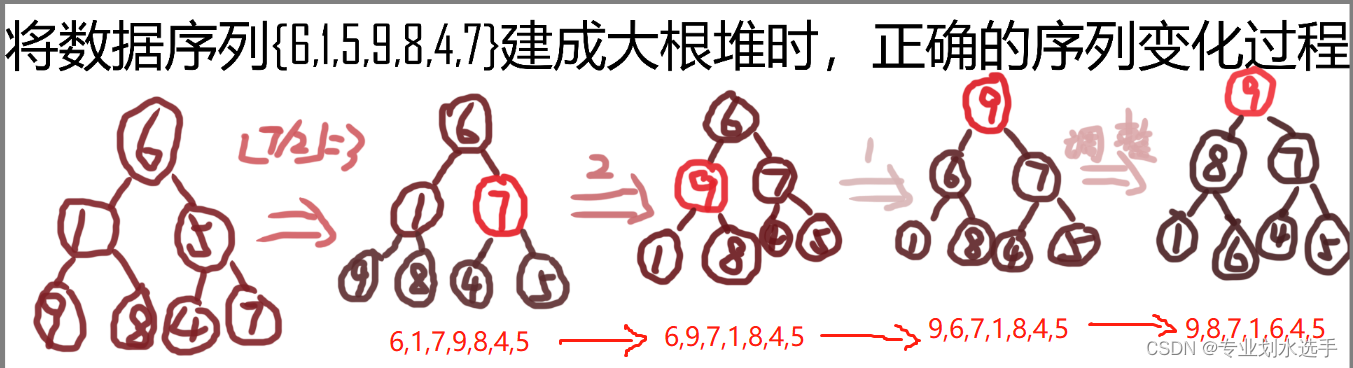
21 在将数据序列{6,1,5,9,8,4,7}建成大根堆时,正确的序列变化过程是(A)
A.6,1,7,9,8,4,5 —> 6,9,7,1,8,4,5 —> 9,6,7,1,8,4,5 —> 9,8,7,1,6,4,5
B.6,9,5,1,8,4,7 —> 6,9,7,1,8,4,5 —> 9,6,7,1,8,4,5 —> 9,8,7,1,6,4,5
C.6,9,5,1,8,4,7 —> 9,6,5,1,8,4,7 —> 9,6,7,1,8,4,5 —> 9,8,7,1,6,4,5
D.6,1,7,9,8,4,5 —> 7,1,6,9,8,4,5 —> 7,9,6,1,8,4,5 —> 9,7,6,1,8,4,5 —> 9,8,7,1,6,4,5
解析:将构建大根堆的过程画出即可,如下图所示
22 排序过程中,对尚未确定最终位置的所有元素进行一遍处理称为一趟排序。下列序列中,不可能是快速排序第二趟结果的是(D)
A.5,2,16,12,28,60,32,72
B.2,16,5,28,12,60,32,72
C.2,12,16,5,28,32,72,60
D.5,2,12,28,16,32,72,60
解析:跟18题原理一样。A.28和72可当做枢纽,B.2和72可当做枢纽,C.2和28可当做枢纽
23 设外存上有120个初始归并段,进行12路归并时,为实现最佳归并,需要补充的虚段个数是(B)
A.1 B.2 C.3 D.4
解析:在一般情况下,为实现最佳归并,m个初始归并段利用k-路归并,若(m-1)%(k-1)=0,则不需要加虚段,否则需要附加k-(m-1)%(k-1)-1个虚段。由题所得(120-1)%(12-1)=9,所以需要附加12-(120-1)%(12-1)-1=2,所以需要补充的虚段个数是2
24 设关键字序列{93,946,372,9,146,151,301,485,236,372,43,892}采用最低位(LSD)基数排序进行升序排序,第一趟分配收集后元素372之前和之后分别紧邻的元素是(C)
A.43,892 B.236,301 C.301,892 D.485,301
解析:如下图所示,第一趟分配收集后元素372之前和之后分别紧邻的元素是301和892

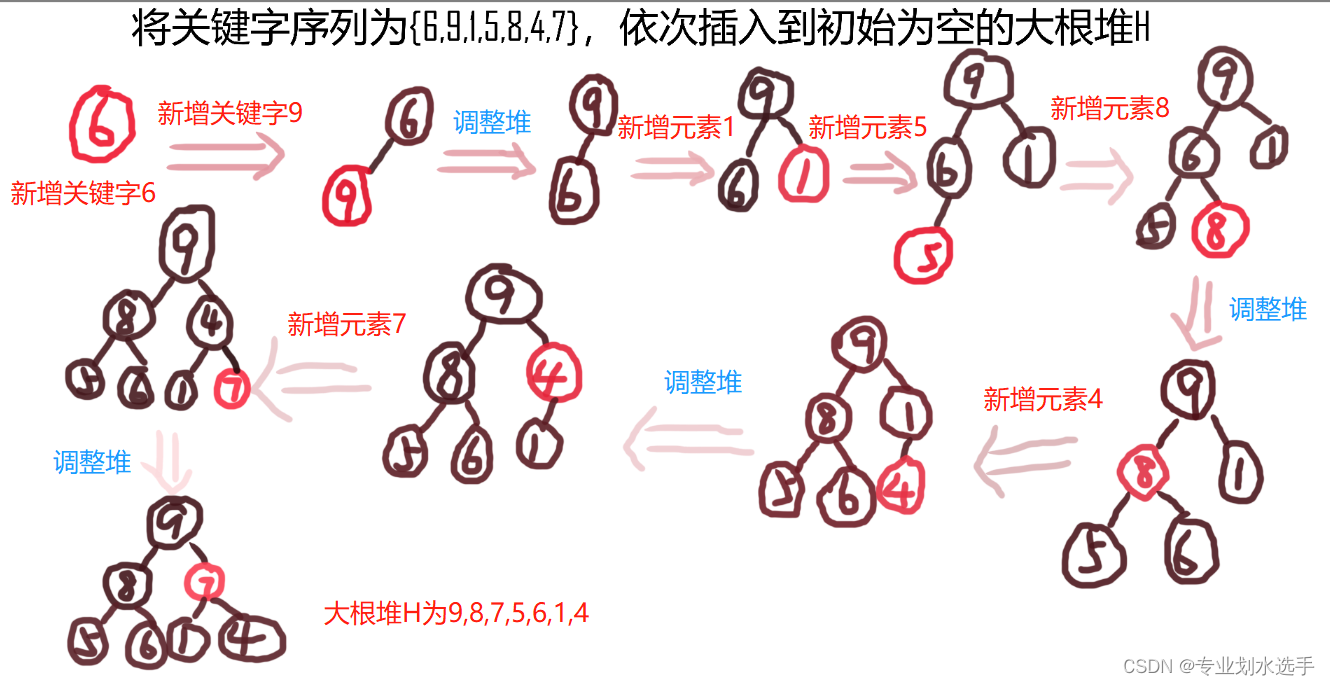
25 将关键字序列为{6,9,1,5,8,4,7},依次插入到初始为空的大根堆H中,得到的H是(B)
A.9,8,7,6,5,4,1
B.9,8,7,5,6,1,4
C.9,8,7,5,6,4,1
D.9,6,7,5,8,4,1
解析:主要关注的点是依次插入,也就是说,边将元素插入堆边调整使其恒为大根堆
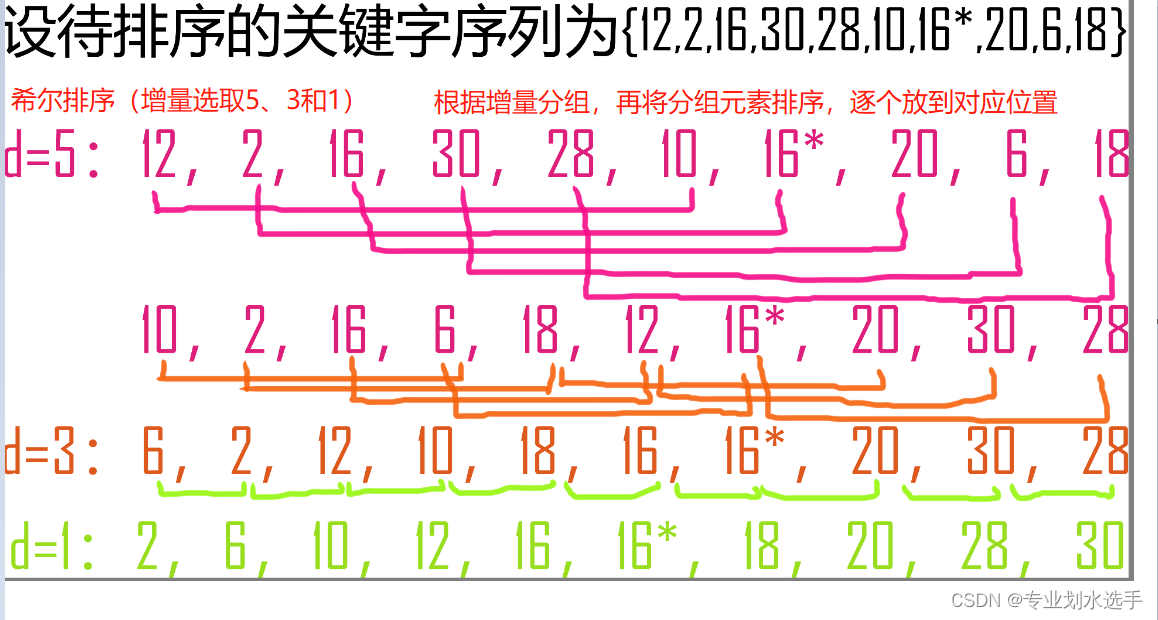
26 设待排序的关键字序列为{12,2,16,30,28,10,16*,20,6,18},试分别写出使用以下排序方法,每趟排序结束后关键字序列的状态
1.直接插入排序

2.折半插入排序

虽然过程跟直接插入排序一样,但排序算法是不同的
3.希尔排序(增量选取5、3和1)
4.冒泡排序

5.快速排序

6.简单选择排序

7.堆排序
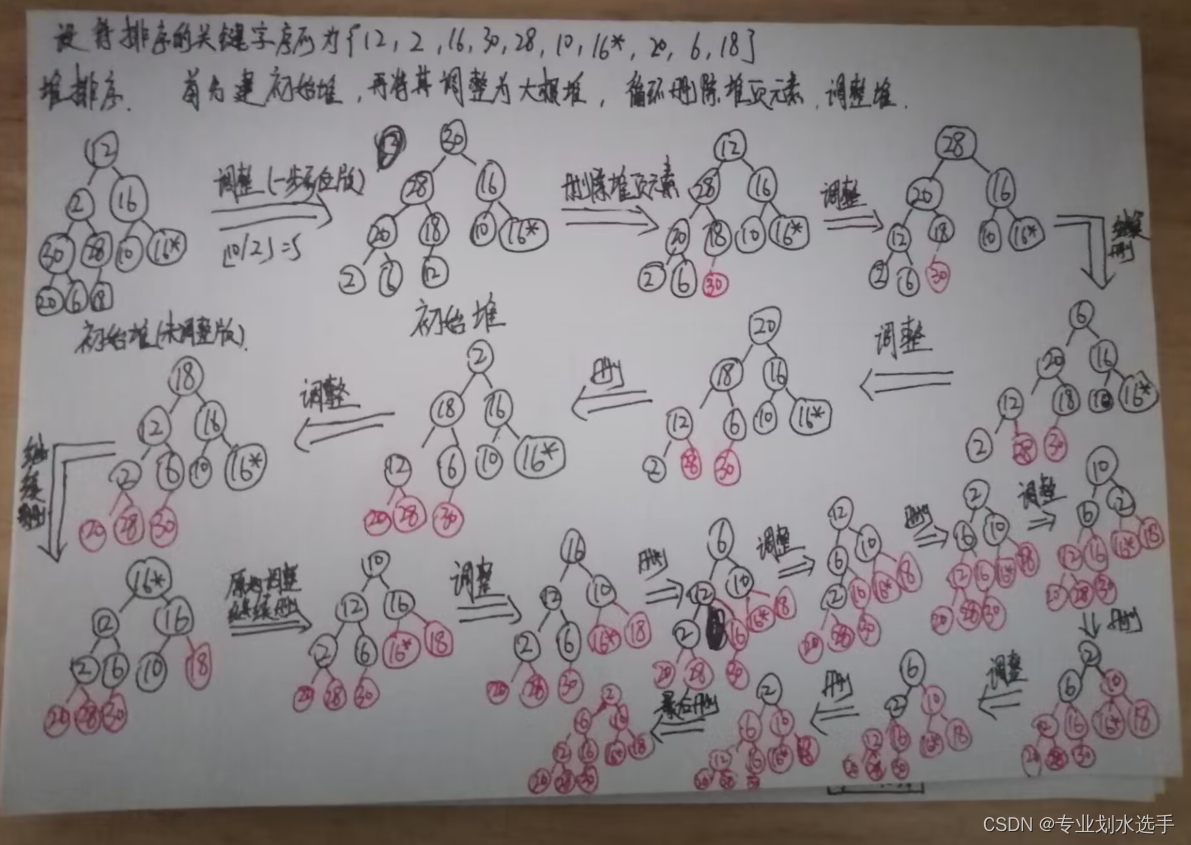
步骤太繁琐,画图工具画的我好累,原理跟前面选择题差不多,将就看吧
8.二路归并排序

我上学期数据结构期末考了87,没挂科^.^
写到这里,数据结构专栏就结束了,王卓老师的视频真的很棒,平时上课讲的速度太快没跟上,多亏了这些视频,再次感谢王卓老师。下次再登就不知道什么时候了,有缘再见,打算继续摆烂划水















 1436
1436











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









