







2021美赛C题解题记录(内含完整代码)
第一次参加美赛,虽然感觉写的不是很理想,但无论结果如何,还是先记录一下比赛的过程与代码,做个小小的总结
文章目录
赛题
完整的赛题和翻译可以看我的另一篇文章
2021美赛C题赛题翻译
这里我就简要介绍一下题目
有一种害虫交亚洲大黄蜂,许多人提供了它的目击报告,但是大多数都是错误的目击报告(及目击的害虫非亚洲大黄蜂)
目击报告中包含了 经纬度
把专家已经核实过的目击报告呈现到经纬度就是下图的结果(也是出题给出的)
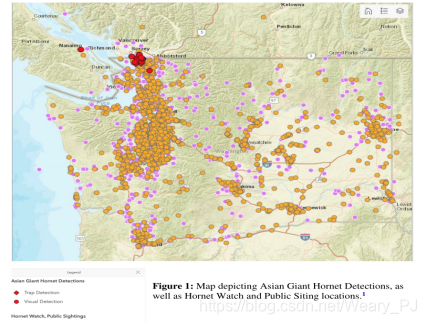
我们要结果的问题,对于赛题的翻译如下
- 讨论是否可以预测这种害虫随着时间的推移而传播,以及以何种精度。
- 大多数报道的目击事件都将其他黄蜂误认为是野黄蜂。只使用提供的数据集文件和(可能)提供的图像文件来创建、分析和讨论预测错误分类可能性的模型。
- 使用您的模型讨论您的分类分析如何导致优先调查最有可能是积极的目击报告。
- 说明如何随着时间的推移更新额外的新报告,以及更新应该发生的频率。
- 使用你的模型,有什么证据可以证明华盛顿州已经消灭了这种害虫?
最后,你的报告应该包括一份两页长的备忘录,总结你在华盛顿州农业部的成果。
总页数不超过25页
但实际上最重要的是前两问
第一问是对害虫的传播做一个预测
第二问是根据给出的害虫图像数据集训练一个图像分类器具
正文
因为参加美赛也是临时决定的,比赛开始前几天才组好队,也没经过什么培训,抱着以赛代练的心态去选C题,想锻炼锻炼数据分析和机器学习的能力
没想到啊,直接整了个图像分类,而且标签的分布还机器不平衡
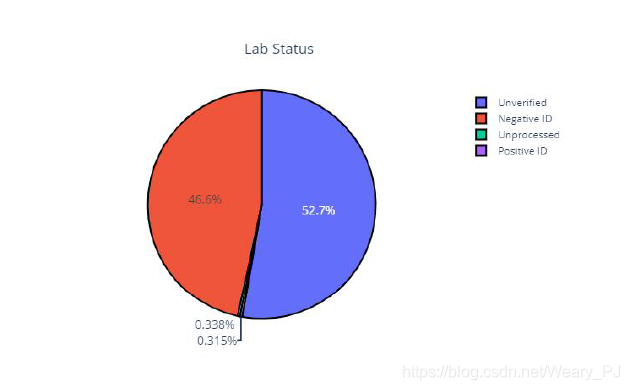
当初对数据集的分布画了一个饼图 可以说是很不均匀了
Positive的正例只有0.338%
Negative的负例和Unverified(为判断)的占了几乎99%
一开始拿到数据集也是有点懵的,只知道图像分类应该是深度学习没跑了,第一问预测可能可以试试时间序列模型
然后我们三个半吊子就开始了愉快的建模之旅
第一天
因为我们队里只有我接触过图像分类
所以第一天的任务分配就是 我钻研第二问,写论文的同学先写问题描述等东西,领一个同学研究第一问时间序列模型
对于图像分类问题,我也从来没实战过,所以Kaggle比赛中的猫狗分类案例的代码,希望能把它调通然后运用到本题中
索性调了一下午终于成功了,但第一问的队友那边出了问题,可能由于网速原因,python的一个库一直下载失败(我这边三分钟不到就下载成功了)最后直到第一天的晚上才解决
当时我给自己的任务是把kaggle的代码调通,然后把本题的数据放上去也能运行通,对于第一次实战的我来说,先花了不少时间来阅读源码,再花了不少时间来 规范数据集,是它能更好的套到之前的代码中
题目给出的数据集是这样的,一个文件夹里面一堆图片
其中部分图片有其标签值,但是存储在excel表格中
Day01代码1: 合并excel表,提取图片与标签对应关系
import pandas as pd
import numpy as np
df_imgId = pd.read_excel('2021MCM_ProblemC_ Images_by_GlobalID.xlsx')
df_dataset = pd.read_excel('2021MCMProblemC_DataSet.xlsx')
df_count = np.sum(df_imgId['GlobalID'].isin(df_dataset['GlobalID']))
print("df_imgId与df_dataset基于GlobalID相关联的数据量 : ", df_count)
train = pd.merge(df_dataset, df_imgId, on='GlobalID', how='inner')
train_data = train[['FileName','Lab Status']]
train_data.to_csv('train_data.csv',index=None)
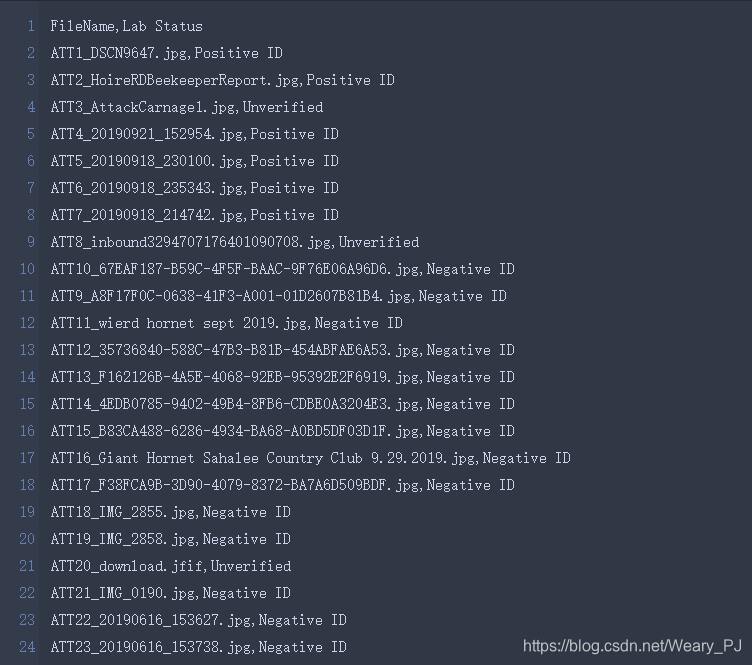
保存下来的csv如下
图片文件名 -> 标签
然后为了使得图片存储的更加有规律,我又写了一串代码来规范化图像数据集
Day01代码2: 数据集规范化存储与命名
功能: 将数据集复制到项目当前目录中的data中,并将其中的训练集与测试集分别放到train和test文件夹中
# -*- coding: utf-8 -*-
# @Time : 2021/2/5 11:53
# @Author : JokerTong
# @File : prepare01.py
# 将数据集复制到项目当前目录中的data中,并将其中的训练集与测试集分别放到train和test文件夹中
import d2lzh as d2l
import os
# 复制数据集
labels = d2l.read_csv_labels(r'D:\Joker\study\校内学习\美赛\2021美赛C题\dataset\train_data.csv')
con = 0
for fileName, label in list(labels.items()):
file_src = os.path.join(r'D:\Joker\study\校内学习\美赛\2021美赛C题\dataset\images', fileName)
if label == 'Positive ID' or label == 'Negative ID':
d2l.copyfile(file_src, 'data/train')
os.rename(os.path.join('data/train', fileName), os.path.join('data/train', f'{label}.' + fileName))
else:
d2l.copyfile(file_src, 'data/test')
con += 1
print(f'con: {con}/{len(labels.values())}')
结果如下: 顺便将每个图片的标签记录到其文件名上,按 .来分割
这里还有很多图像都不是jpg或者png的格式,所以我找了两个队友帮我将数据处理下, 基本上是手动与代码结合
下面是 python的opencv将视频按帧转换为图片的操作
因为之前就发现了正例过少的情况,所以采用数据增强的操作,把图片旋转,正则化,改变通道等等操作来增加正例的数量
Day01代码3: 数据集正例数据增强
功能: 使用imgaug 对训练集中的正样本进行数据增强,循环220轮(需要图像变换方法来避免重复图像的生成)
把正例从14张变成了 14 * 220 + 14 3094张
当然这里存在着很多问题,对于opencv的图像操作我还没学过,所以也是找的网上的代码
于是仅仅修改了一点点东西,这里的220轮中有很多图片是重复的,所以实际上样本的数量可能远小于 3094 不过毕竟进行了数据增强, 当时想着后面有时间再修改这里的代码 但是知道比赛结束都没时间改 希望以后碰到这种操作的时候我已经更加熟练了吧
# -*- coding: utf-8 -*-
# @Time : 2021/2/5 15:32
# @Author : JokerTong
# @File : prepare02.py
# 使用imgaug 对训练集中的正样本进行数据增强,循环220轮(需要图像变换方法来避免重复图像的生成)
# 增加图片数量的同时在 name-labels对应文件中添加新生成的图片与其标签
import cv2
from imgaug import augmenters as iaa
import os
# 数据增强
# Sometimes(0.5, ...) applies the given augmenter in 50% of all cases,
# e.g. Sometimes(0.5, GaussianBlur(0.3)) would blur roughly every second image.
sometimes = lambda aug: iaa.Sometimes(0.5, aug)
# 图片文件相关路径
path = 'data/train'
savedpath = 'data/train/'
# 定义一组变换方法.
seq = iaa.Sequential([
# 选择0到5种方法做变换
iaa.SomeOf((0, 5),
[
iaa.Fliplr(0.5), # 对50%的图片进行水平镜像翻转
iaa.Flipud(0.5), # 对50%的图片进行垂直镜像翻转
# Convert some images into their superpixel representation,
# sample between 20 and 200 superpixels per image, but do
# not replace all superpixels with their average, only
# some of them (p_replace).
sometimes(
iaa.Superpixels(
p_replace=(0, 1.0),
n_segments=(20, 200)
)
),
# Blur each image with varying strength using
# gaussian blur (sigma between 0 and 3.0),
# average/uniform blur (kernel size between 2x2 and 7x7)
# median blur (kernel size between 3x3 and 11x11).
iaa.OneOf([
iaa.GaussianBlur((0, 3.0)),
iaa.AverageBlur(k=(2, 7)),
iaa.MedianBlur(k=(3, 11)),
]),
# Sharpen each image, overlay the result with the original
# image using an alpha between 0 (no sharpening) and 1
# (full sharpening effect).
iaa.Sharpen(alpha=(0, 1.0), lightness=(0.75, 1.5)),
# Same as sharpen, but for an embossing effect.
iaa.Emboss(alpha=(0, 1.0), strength=(0, 2.0)),
# Add gaussian noise to some images.
# In 50% of these cases, the noise is randomly sampled per
# channel and pixel.
# In the other 50% of all cases it is sampled once per
# pixel (i.e. brightness change).
iaa.AdditiveGaussianNoise(
loc=0, scale=(0.0, 0.05 * 255)
),
# Invert each image's chanell with 5% probability.
# This sets each pixel value v to 255-v.
iaa.Invert(0.05, per_channel=True), # invert color channels
# Add a value of -10 to 10 to each pixel.
iaa.Add((-10, 10), per_channel=0.5),
# Add random values between -40 and 40 to images, with each value being sampled per pixel:
iaa.AddElementwise((-40, 40)),
# Change brightness of images (50-150% of original value).
iaa.Multiply((0.5, 1.5)),
# Multiply each pixel with a random value between 0.5 and 1.5.
iaa.MultiplyElementwise((0.5, 1.5)),
# Improve or worsen the contrast of images.
iaa.ContrastNormalization((0.5, 2.0)),
],
# do all of the above augmentations in random order
random_order=True
)
], random_order=True) # apply augmenters in random order
imglist = []
filelist = os.listdir(path)
positive_list = []
# 遍历要增强的文件夹,把所有的图片保存在imglist中
for item in filelist:
if 'Positive' in item:
img = cv2.imread(os.path.join(path, item))
positive_list.append(item)
imglist.append(img)
print('all the picture have been appent to imglist')
print(positive_list)
# 对文件夹中的图片进行增强操作,循环30次
filenames = []
for count in range(220):
images_aug = seq.augment_images(imglist)
for index in range(len(images_aug)):
filename = f'{positive_list[index]}{count}.jpg'
# 保存图片
cv2.imwrite(savedpath + filename, images_aug[index])
filenames.append(filename)
print(f'{count} / 220')
for filename in filenames:
label, name = filename.split('.', 1)
with open('data/train_data.csv', 'a+') as f:
f.write(f'\n{name},{label}')
Day01代码4: 图像分类Resnet迁移学习
下面是图像分类的终稿,比赛的时候直接在上面改的,也没有存第一天的中间结果,不过第一天的进度是完成了初步运行,效果也还算理想(抛开可能存在的过拟合现象的话) 正确率也有90多
终稿里包含了Resnet(34, 50, 152)三种不同层次网络的训练与混淆矩阵结果的输出
# -*- coding: utf-8 -*-
# @Time : 2021/2/5 9:29
# @Author : JokerTong
# @File : net_train.py
# 模型训练
from torch.utils.data import Dataset
from sklearn.metrics import confusion_matrix
import matplotlib.pyplot as plt
import d2lzh as d2l
import torch
import torchvision
from torch import nn
import os
# 定义初始参数
data_dir = r'data'
valid_ratio = 0.1
batch_size = 64
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 划分验证集
def reorg_bees_data(data_dir, valid_ratio):
# 读取训练数据标签
labels = d2l.read_csv_labels(os.path.join(data_dir, 'train_data.csv'))
# 整理训练数据集
d2l.reorg_train_valid(data_dir, labels, valid_ratio)
# 整理测试数据集
d2l.reorg_test(data_dir)
# reorg_bees_data(data_dir, valid_ratio)
print('数据划分完成')
transform_train = torchvision.transforms.Compose([
# 随机对图像裁剪出面积为原图像面积0.08~1倍、且高和宽之比在3/4~4/3的图像
# 再放缩为高和宽均为224像素的新图像
torchvision.transforms.RandomResizedCrop(224, scale=(0.08, 1.0), ratio=(3.0 / 4.0, 4.0 / 3.0)),
torchvision.transforms.RandomHorizontalFlip(),
# 随机变化亮度、对比度和饱和度
torchvision.transforms.ColorJitter(brightness=0.4, contrast=0.4, saturation=0.4),
torchvision.transforms.ToTensor(),
# 对图像的每个通道做标准化
torchvision.transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
transform_test = torchvision.transforms.Compose([
torchvision.transforms.Resize(256),
# 将图像中央的高和宽均为224的正方形区域裁剪出来
torchvision.transforms.CenterCrop(224),
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
train_ds, train_valid_ds = [torchvision.datasets.ImageFolder(
os.path.join(data_dir, 'train_valid_test', folder),
transform=transform_train) for folder in ['train', 'train_valid']
]
valid_ds, test_ds = [torchvision.datasets.ImageFolder(
os.path.join(data_dir, 'train_valid_test', folder),
transform=transform_test) for folder in ['valid', 'test']
]
# unknown_ds = torchvision.datasets.ImageFolder(
# os.path.join(data_dir, 'train_valid_test', 'test', 'unknown'),
# transform=transform_test)
train_iter, train_valid_iter = [torch.utils.data.DataLoader(
dataset, batch_size, shuffle=True, drop_last=True) for dataset in (train_ds, train_valid_ds)
]
valid_iter = torch.utils.data.DataLoader(valid_ds, batch_size, shuffle=False, drop_last=True)
test_iter = \
torch.utils.data.DataLoader(test_ds, batch_size, shuffle=False, drop_last=False)
def get_net34(devices):
finetune_net = nn.Sequential()
finetune_net.features = torchvision.models.resnet34(pretrained=True)
# 定义新的输出网络
# 120是输出的类别个数
finetune_net.output_new = nn.Sequential(nn.Linear(1000, 256),
nn.ReLU(),
nn.Linear(256, 2))
# 把模型参数分配到内存或显存上
finetune_net = finetune_net.to(devices)
for param in finetune_net.features.parameters():
param.requires_grad = False
return finetune_net
def get_net50(devices):
finetune_net = nn.Sequential()
finetune_net.features = torchvision.models.resnet50(pretrained=True)
# 定义新的输出网络
# 120是输出的类别个数
finetune_net.output_new = nn.Sequential(nn.Linear(1000, 256),
nn.ReLU(),
nn.Linear(256, 2))
# 把模型参数分配到内存或显存上
finetune_net = finetune_net.to(devices)
for param in finetune_net.features.parameters():
param.requires_grad = False
return finetune_net
def get_net152(devices):
finetune_net = nn.Sequential()
finetune_net.features = torchvision.models.resnet152(pretrained=True)
# 定义新的输出网络
# 120是输出的类别个数
finetune_net.output_new = nn.Sequential(nn.Linear(1000, 256),
nn.ReLU(),
nn.Linear(256, 2))
# 把模型参数分配到内存或显存上
finetune_net = finetune_net.to(devices)
for param in finetune_net.features.parameters():
param.requires_grad = False
return finetune_net
loss = nn.CrossEntropyLoss()
devices, num_epochs, lr, wd = device, 10, 0.0001, 1e-4
# resnet34
net34 = get_net34(devices)
optimizer34 = torch.optim.Adam(net34.parameters(), lr=lr, weight_decay=wd)
print('开始训练resnet34')
net34.load_state_dict(torch.load('bees.pth'))
# d2l.train(train_iter, valid_iter, net34, loss, optimizer34, device, num_epochs)
print('训练完成,混淆矩阵如下')
# 训练结束,绘制混淆矩阵
preds = []
y_list = []
for data, label in train_valid_iter:
output = net34(data.to(device))
arrays = output.cpu().detach().numpy()
li = []
for array in arrays:
p1, p2 = array
if p1 > p2:
li.append(0)
else:
li.append(1)
preds.extend(li)
y_list.extend(list(label.cpu().detach().numpy()))
confusion_matrix34 = confusion_matrix(y_list, preds)
print('resnet34', confusion_matrix34)
print('*' * 50)
# resnet50
net50 = get_net50(devices)
optimizer50 = torch.optim.Adam(net50.parameters(), lr=lr, weight_decay=wd)
print('开始训练resnet50')
net50.load_state_dict(torch.load('best_bees.pth'))
# d2l.train(train_iter, valid_ite
# r, net50, loss, optimizer50, device, num_epochs)
print('训练完成,混淆矩阵如下')
# 训练结束,绘制混淆矩阵
preds = []
y_list = []
for data, label in train_valid_iter:
output = net50(data.to(device))
arrays = output.cpu().detach().numpy()
li = []
for array in arrays:
p1, p2 = array
if p1 > p2:
li.append(0)
else:
li.append(1)
preds.extend(li)
y_list.extend(list(label.cpu().detach().numpy()))
confusion_matrix50 = confusion_matrix(y_list, preds)
print('resnet50', confusion_matrix50)
print('*' * 50)
# resnet152
net152 = get_net152(devices)
optimizer152 = torch.optim.Adam(net152.parameters(), lr=lr, weight_decay=wd)
print('开始训练resnet152')
d2l.train(train_iter, valid_iter, net152, loss, optimizer152, device, num_epochs)
print('训练完成,混淆矩阵如下')
# 训练结束,绘制混淆矩阵
preds = []
y_list = []
for data, label in train_valid_iter:
output = net152(data.to(device))
arrays = output.cpu().detach().numpy()
li = []
for array in arrays:
p1, p2 = array
if p1 > p2:
li.append(0)
else:
li.append(1)
preds.extend(li)
y_list.extend(list(label.cpu().detach().numpy()))
confusion_matrix152 = confusion_matrix(y_list, preds)
print('resnet152', confusion_matrix152)
print('*' * 50)
第二天
感觉第一天过的最充实,把图像分类的代码初步调通了
第二天本来想写点第二问的论文,然后试试图像切割的操作
不过论文经验很少的我 写的时候就范懵了,因为我之前参加建模比赛的时候都有专门的论文手来写文章,她也懂一点模型(是数学专业的) 但这次图像分类的知识只能我先写好再给论文手翻译.
说实话, 数学建模最常用的那几个模型我是会扯的 但是把深度学习用进模型的情况我还是第一次碰到
要不要介绍一下深度学习?
卷积神经网络要写多少?
卷积池化下采样全连接这些层都要具体介绍吗?
写了半天发现没什么公式,要不要把反向传播 梯度下降什么推导一下?
损失函数公司 softmax等要介绍多详细?
碰到了一堆问题,到最后还是磕磕碰碰的写出了个雏形,但也花了很长的时间
然后进行对网络优化的操作, 这些现在想想挺简单的,但当时实在是花了挺久的时间
然后第一问那边又出问题了,所以就没空搞切割了, 第一问的同学说没什么思路,我之前推荐的时间序列模型 fbprophet 下载老是出错,到最后好不容易下载成功,但是所给的数据太少,而且时间也不离散,似乎用fbprophet 来预测没什么效果, 于是便卡在第一问
我当时看了看, 对于这些不连续的时间 只有14条的样本也没什么思路
虽然我当时提了一下用所有的数据一起去预测,先不管标签,但也不知道为什么后来没有采用,然后第一问的同学就对着14条数据挺发愁的,第二天就这样过去了
Day02代码: 视频处理为图片
# coding=utf-8
import os
import sys
os.chdir("C:/Users/lyy/Desktop/images")
# allFile=os.listdir("C:/Users/lyy/Desktop/2021MCM_ProblemC_Files")
# 全局变量
# VIDEO_PATH = '2021MCM_ProblemC_Files/ATT46_trim.75A56855-B3BF-4B3D-8E9F-3E34CE90D8FB.MOV' # 视频地址
# EXTRACT_FOLDER = './image' # 存放帧图片的位置
EXTRACT_FREQUENCY =15
# 帧提取频率
def extract_frames(video_path, dst_folder, index):
print("---------extract_frames--------------")
# 主操作
import cv2
video = cv2.VideoCapture()
if not video.open(video_path):
print("can not open the video")
exit(1)
count = 1
while True:
_, frame = video.read()
if frame is None:
break
if count % EXTRACT_FREQUENCY == 0:
save_path = "{}/{}.jpg".format(dst_folder, dst_folder+"-"+str(index))
cv2.imwrite(save_path, frame)
index += 1
count += 1
video.release()
# 打印出所提取帧的总数
print("Totally save {:d} pics".format(index-1))
def main(EXTRACT_FOLDER,VIDEO_PATH):
# 递归删除之前存放帧图片的文件夹,并新建一个
print("----------Main------------")
import shutil
try:
shutil.rmtree(EXTRACT_FOLDER)
except OSError:
pass
import os
print(EXTRACT_FOLDER)
print(VIDEO_PATH)
os.mkdir(EXTRACT_FOLDER)
# 抽取帧图片,并保存到指定路径
extract_frames(VIDEO_PATH, EXTRACT_FOLDER, 1)
def del_files(path):
print("----------del_files------------")
# for root, dirs, files in os.walk(path):
# for name in files:
# if name.endswith(".MOV"):
# print(name)
for root, dirs, files in os.walk(path):
for file in files:
# if os.path.splitext(file)[1] == '.MOV':
if file.endswith(".MP4"):
print("----处理MOV----------")
t = os.path.splitext(file)[0:-1]
s =".".join(t)
print(".".join(t)+'.MP4') # 打印所有py格式的文件名
main(s,path+"/"+s+'.MP4')
if __name__ == '__main__':
# main(EXTRACT_FOLDER,VIDEO_PATH)
del_files("C:/Users/lyy/Desktop/2021MCM_ProblemC_Files")
第三天
因为再这样下去感觉要来不及了,我想的是第四天用来改文章, 这样排时间也不会太累,每天也可以按时睡觉 可事与愿违哎
第三天我们三个一起讨论了一下后三问的思路,决定先把模型写好翻译好, 这样第一问做完之后填空就行了
- 第三问使用您的模型讨论您的分类分析如何导致优先调查最有可能是积极的目击报告
- 我们想的就是通过第一问和第二问的模型,综合到一起得到一个新的模型
- 第一问的模型和第二问的模型我们都打算以是害虫的概率作为预测结果
- 所以第三问的模型只需要为前两问的模型结果加一个权重即可
- 这里我们瞎定义了一个 0.2 和 0.8作为报告存在图像数据时的权重分分配
- 将计算出的权重作为报告的得分(是害虫的概率)来排序, 以降序的形式优先调查报告
- 第四问说明如何随着时间的推移更新你的模型,以及更新应该发生的频率。
- 这里我们对题目还有点疑问,之前翻译的版本也可能有点不准确,到后来总算是统一了, 对于图像数据来说,我们把计算报告的累积值,达到总数据的 20% 时就去模型里面跑一跑,更新一下
- 频率的话我们也知道怎么说,到最后就扯了扯, 根据报告累积的时间来决定
- 第五问使用你的模型,有什么证据可以证明华盛顿州已经消灭了这种害虫?
- 这个就对未预测的报告用我们前面的模型都跑一遍,然后最后得到的结果是一堆概率几乎为0的,那么就结了, 我们的说法是根据正例报告去消灭害虫,然后根据模型得出的预测结果到最后几乎都为0,可以证明华盛顿州已经消灭了它
这三问扯完翻译完好像也花了很久
再加上我又完善了一下第二问, 加上论文同学的翻译 这一天也就这样过去了
第一问的同学还是没什么思路 ,所以我们打算最后一天一起完成第一问
第四天
第一问最后糊里糊涂的出来了(过程省略)
先用python的一个十分神奇的库PyCaret
这是真的牛逼
Day04代码: 第一问模型建立
首先以 dataframe的格式把数据加载进来
保留所给的特征
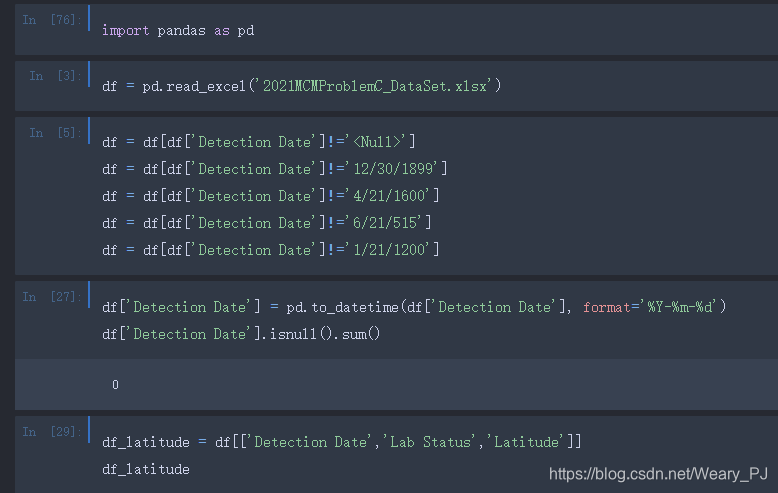
然后就直接按PyCaret的模板代码运行
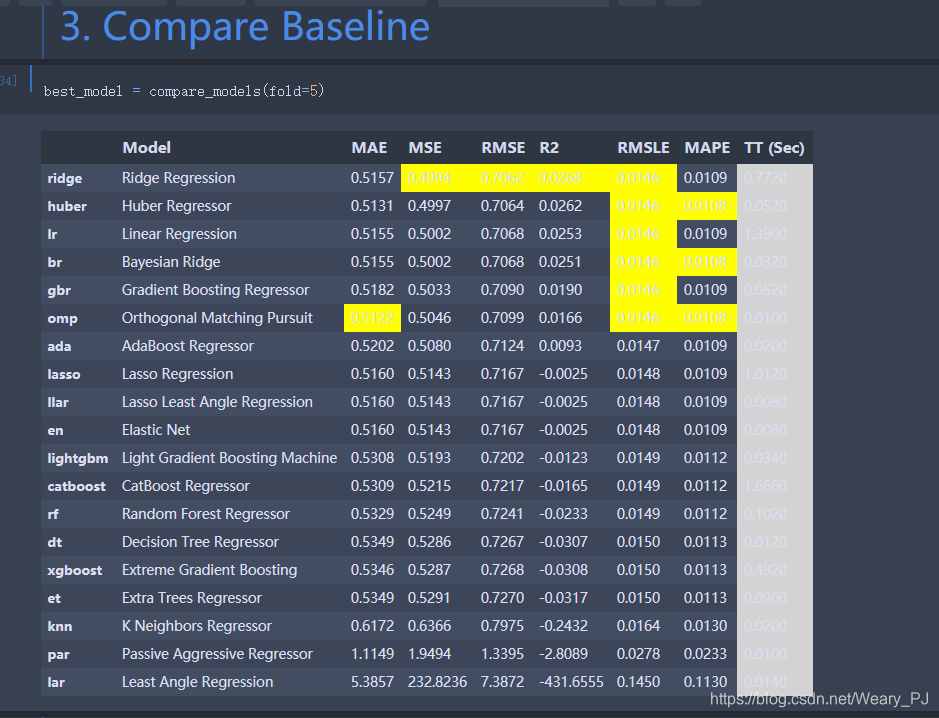
得到一堆模型的初步对比结果
然后我们就从中随便选了一个稍微好一点(Ridge Regression)的作为第一问的预测模型
然后就分别以经度和维度未其预测,虽然得到的结果感觉看上去误差蛮大的,但是死马当活医, 还是给他写上去了
这一天就扯东扯西, 一直到下午3.30左右才把大部分内容写完
然后就改了一晚上 0.30才睡觉
第五天
早上起来 对论文做了最后一遍检查
改了一些表格样式等等,等待交题目
交题目是真的想骂人,从8.30开始发邮件,然后一直拒收
换了qq有些,gmail, 学校邮箱,网易邮箱都不行
最后9.50多的时候队友用新浪邮箱发出去了
长舒一口气
但是TMD10.00多说邮件被拒收
然后我们就又开始疯狂的发邮件
最后终于没拒收了
到了10号我也收到了官网的邮件
庆祝美赛告一段落
感慨: 学好数据分析很重要啊
opencv也要好好学学
PyCaret感觉是个好东西也要学学
哎 感觉自己真他喵的渺小




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











