







图中显示了MR中的高层次数据流,并表明了数据流各个部分的角色。
在输入端,在map之前执行数据分割的工作,在map中执行读取分割工作,所有的输出工作在reduce段执行,输出结果
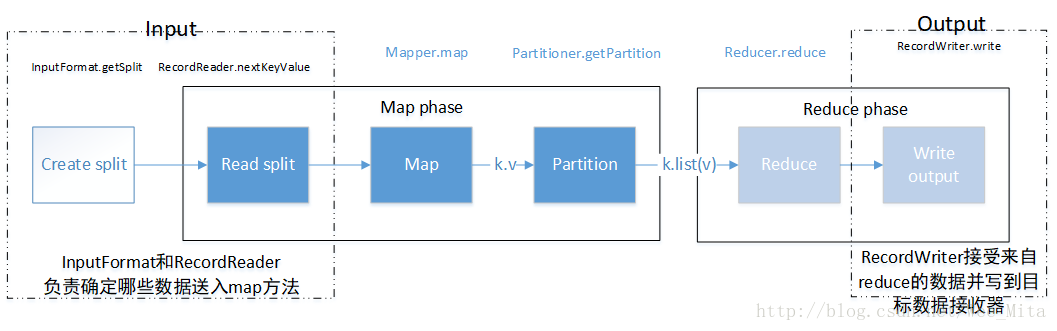
部分情况下只需要map作业就可以了,那么数据流中没有Partition和Reduce这2个模块
1、数据输入
MR中有2个支持数据输入的类:
- InputFormat:用于决定如何为map任务分割输入数据
- RecordReader:读取输入数据
1-1、 InputFormat
MR中的每个作业必须通过InputFormat抽象类来约定输入数据
InputFormat必须实现三个约定:
- 为map的输入参数key和value定义数据类型
- 指定如何分割输入数据
- 指定RecordReader实例从源读取数据
InputFormat类的注释和它的三个构造函数:
abstract InputFormat<K,V>:map输入的键值的类型定义List<InoutSplit> getSplits(jobContext context):分割输入数据,转换为InputSplit列表RecordReader<K,V> createRecordReader(InputSplit split, TaskAttemptContext context):创建RecordReader从作业输入中读取数据
最关键的是确定如何划分输入数据
在MR中,这种划分称为input split,这直接影响map 的并行运行。
因为每个分片有一个单独的map任务执行,如果InputFormat不能通过单个数据源创建多个input split,这将导致map任务运行缓慢(此时文件是单线程顺序处理的)
TextInputFormat类实现了InputFormat类的createRecordReader方法,但是将计算input split个数的工作交给父类(FileInputFormat)处理。
指定MR作业的InputFormat:job.setInputFormatClass(TextInputFormat.class)
FileInputFormat:
package T607;
import org.apache.hadoop.fs.BlockLocation;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.JobContext;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import java.io.IOException;
import java 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 314
314

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









