






Numpy
数据类型:
- 数字类型
- 整型
- 布尔型 bool
- 整型 int
- 长整型 long
- 非整型
- 浮点型 float
- 复数 complex
- 整型
- 容器
- 序列
- 字符串 str
- 列表 list
- 元组 tuple
- 集合
- 可变集合 set
- 不可变集合 frozenset
- 映射
- 字典 dict
- 序列
list:
对象头:长度:items
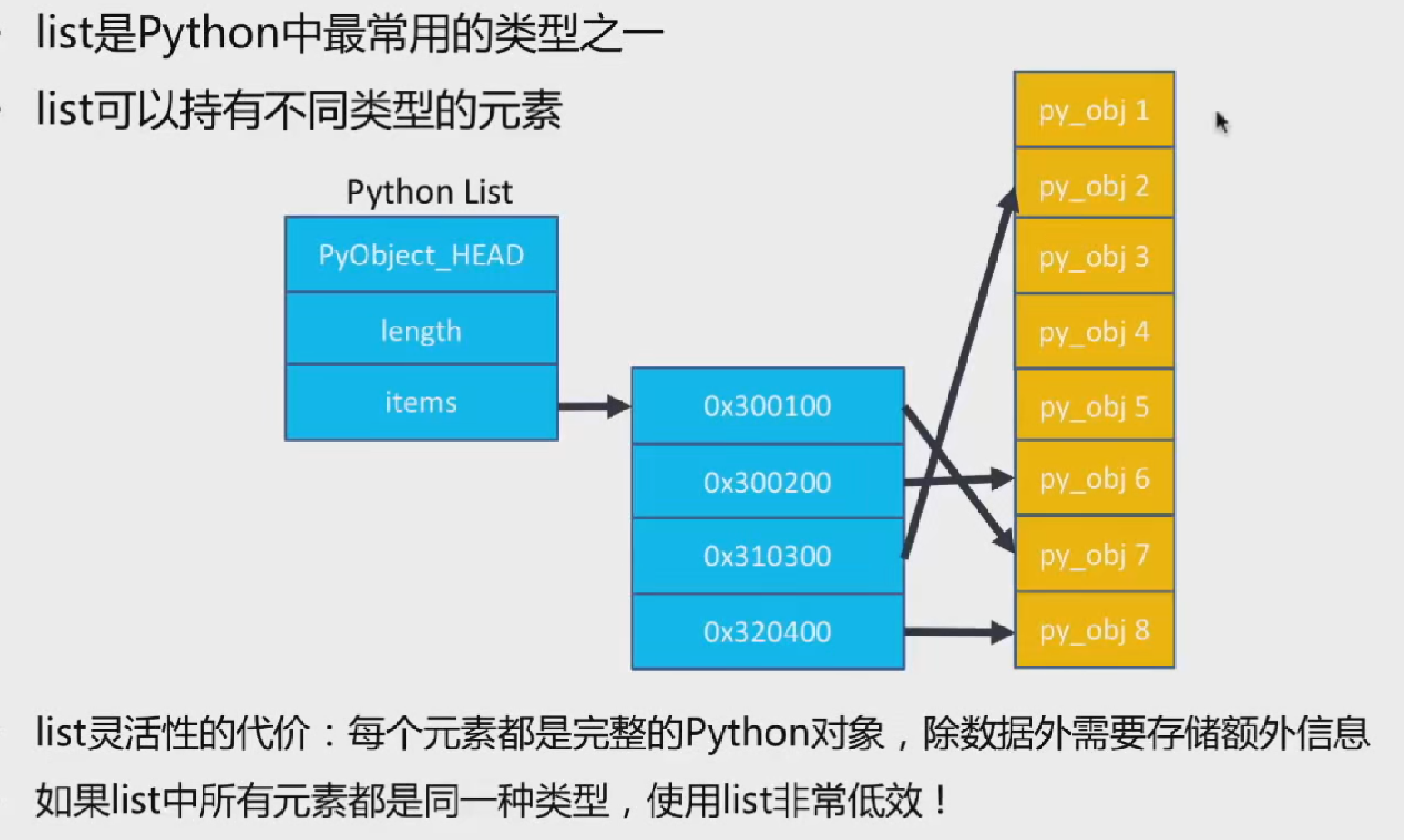
ndarray。

基本用法
x = np.array([[1, 2, 3], [4, 5, 6]])
print(x)
print(f"Type: {type(x)}") # Type: <class 'numpy.ndarray'>
print(f"Ndim: {x.ndim}") # Ndim: 2
print(f"Shape: {x.shape}") # Shape: (2, 3)
print(f"Size: {x.size}") # Size: 6
print(f"Dtype: {x.dtype}") # Dtype: int64
print(f"Itemsize: {x.itemsize}") # Itemsize: 8
print(f"Strides: {x.strides}") # Strides: (24, 8)
print(f"Nbytes: {x.nbytes}") # Nbytes: 48
print(f"Data: {x.data}") # Data: <memory at 0x7f8b1c1b3d00>
print(f"Flags: {x.flags}") # Flags: C_CONTIGUOUS : True
-
ndim:维度数
-
shape:数组形状,2行3列
-
size:一共6个
-
dtype:数组元素类型,长整型 int64
-
itemsize:每个元素需要的内存,8字节
-
strides:在不同维度上遍历数组需要跨过的字节数,(24,8)一行元素 3个 int64 ,每个 8字节,每一行元素相隔 24字节,比如 1 和 4之间间隔 24 字节,2 和 5 间隔 24 个字节,8表示每个元素的字节数
-
nbytes:存储该数组需要的内存大小 = itemsize * size = 6*8 = 48 字节
-
data:数组元素对应的内存区域地址
创建数组
array(object, dtype=None, copy=True, order='K', subok=False, ndmin=0)
- object:列表,元组,数组 等 array 类型的对象
- dtype:数组元素类型,自动向更高精度转换
- order:数组在内存中的存储的顺序,C语言风隔 行优先,Fortran 风格列优先
- ‘C’: 行优先(C-style)
‘F’: 列优先(Fortran-style)
‘A’: 如果可能则使用 Fortran-style,否则使用 C-style
‘K’: 尽可能保持输入数据的顺序
- ‘C’: 行优先(C-style)
import numpy as np
# Create a 1D NumPy array
x1 = np.array([1, 2, 3,4,5])
# Create a 2D NumPy array
x2 = np.array([[1, 2, 3],[4,5,6]])
# Create a 3D NumPy array
x3 = np.array([[[1, 2, 3], [4, 5, 6]], [[7, 8, 9], [10, 11, 12]]])
print(x1)
print(x2)
print(x3)
-
[1 2 3 4 5] [[1 2 3] [4 5 6]] [[[ 1 2 3] [ 4 5 6]] [[ 7 8 9] [10 11 12]]]
# 指定类型,所有数据类型都是 float
x = np.array([1, 2, 3], dtype=float)
print(x) # [1. 2. 3.]
print(x.dtype) # float64
print(type(x[0])) # <class 'numpy.float64'>
# 自动向 float 转换
x = np.array([1, 2, 3.1])
print(x) # [1. 2. 3.1]
print(x.dtype) # float64
print(type(x[0])) # <class 'numpy.float64'>
数组初始化
import numpy as np
arr = np.zeros((2,3))
print(arr)
list = [[1,2],[3,4],[5,6]]
print(list)
newArr = np.zeros_like(list)
print(newArr)
-
np.zeros((2,3))创建 2行3列的数组,数值全是0 -
np.zeros_like(list)创建跟该数组同样结构的数组 -
[[0. 0. 0.] [0. 0. 0.]] [[1, 2], [3, 4], [5, 6]] [[0 0] [0 0] [0 0]]
arr = np.ones((2,3))
newArr = np.ones_like(list)
- 用法同上,创建的数组的值是 1
arr = np.full((2,3),5)
newArr = np.full_like(list,5)
- 用法同上,用什么值填充该数组,案例填充的是 5
import numpy as np
a = np.eye(3,4,0)
print(a)
b = np.eye(3,4,1)
print(b)
c = np.eye(3,4,-1)
print(c)
-
[[1. 0. 0. 0.] [0. 1. 0. 0.] [0. 0. 1. 0.]] [[0. 1. 0. 0.] [0. 0. 1. 0.] [0. 0. 0. 1.]] [[0. 0. 0. 0.] [1. 0. 0. 0.] [0. 1. 0. 0.]] -
np.eye(3,4,0)创建 3行4列的数组,0表示正中间的对角线,1表示向上移1行,-1表示向下移1行的对角线
a = np.empty((2,3))
print(a)
- 创建 2行3列的数组,但是不初始化。效率高,省去初始化时间
a = np.arange(0,10,1)
print(a) # [0 1 2 3 4 5 6 7 8 9]
b = np.arange(5,20,2)
print(b) # [ 5 7 9 11 13 15 17 19]
np.arange(0,10,1)创建 从 0 到 10,步长为 1 的数组,不包含 10
a = np.linspace(0, 10, 5)
print(a) # [ 0. 2.5 5. 7.5 10. ]
b = np.linspace(0, 10, 5, endpoint=False)
print(b) # [0. 2. 4. 6. 8.]
np.linspace(0, 10, 5)从 0 到 10,返回 5 个点,包含最后一个点 10,相当于 4 等分np.linspace(0, 10, 5, endpoint=False)从 0 到 10,返回 5 个点,不包含最后一个点 10,相当于 5 等分
a = np.fromfunction(lambda i, j: i*2, (3, 4), dtype=int)
print(a)
b = np.fromfunction(lambda i, j: i*j, (3, 4), dtype=int)
print(b)
c = np.fromfunction(lambda i, j: i>j, (3, 4), dtype=int)
print(c)
-
[[0 0 0 0] [2 2 2 2] [4 4 4 4]] [[0 0 0 0] [0 1 2 3] [0 2 4 6]] [[False False False False] [ True False False False] [ True True False False]] -
np.fromfunction(lambda i, j: i*2, (3, 4), dtype=int)第一个是计算的逻辑函数(i和j 代表行和列的下标索引),第二个几行几列,第三个是第一个参数类型,也就是 i 和 j 的类型
数据类型
类型:
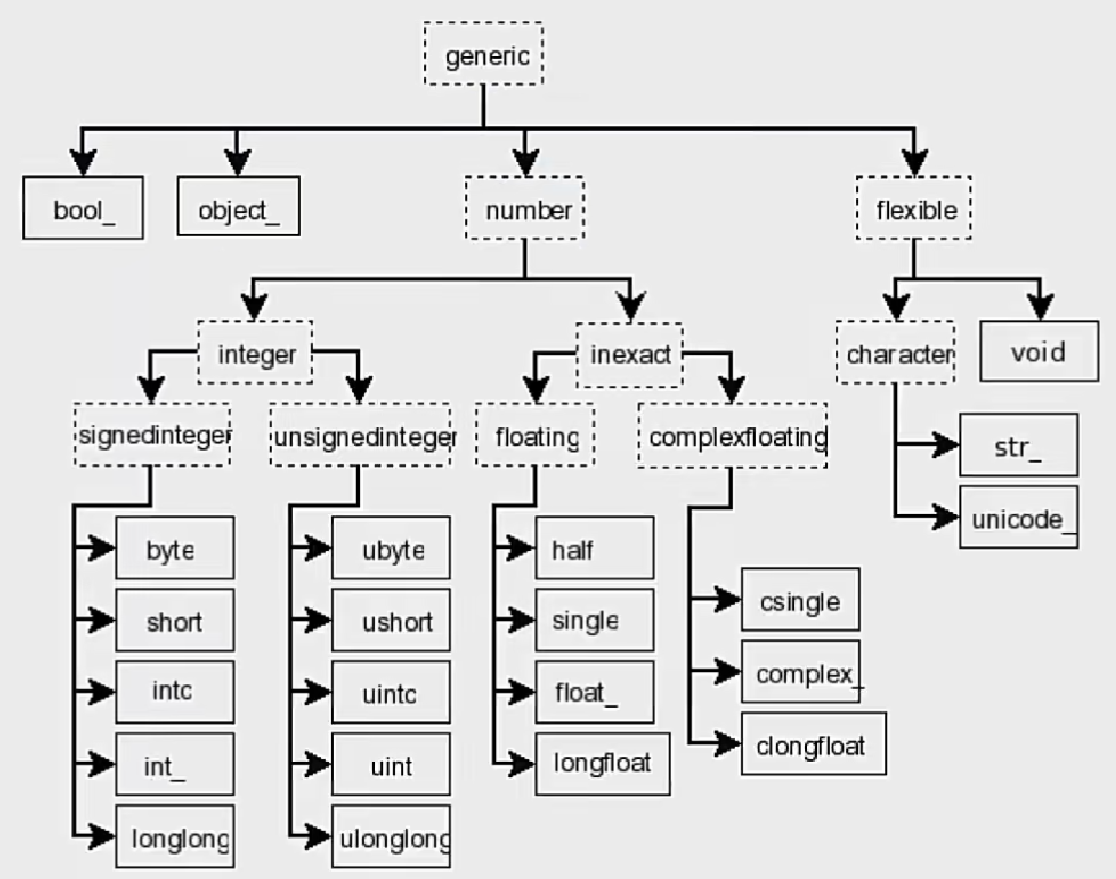
generic
- bool_
- object_
- number
- integer
- byte
- short
- intc
- int_
- longlong
- ubyte
- ushort
- uintc
- uint
- ulonglong
- inexact
- half
- single
- float_
- longfloat
- csingle
- complex_
- clongfloat
- integer
- flexibel
- void
- str_
- unicode_
隐式类型转换
import numpy as np
array = np.array([True, False], dtype=np.int8)
print(array) # [1 0]
import numpy as np
array = np.array([True,False], dtype=np.float16)
print(array) # [1. 0.]
import numpy as np
array = np.array([1,2,3], dtype=np.float32)
print(array) # [1. 2. 3.]
import numpy as np
array = np.array([1.1, 2.2, 3.3], dtype=np.int8)
print(array) # [1 2 3]
显示类型转换
import numpy as np
array = np.array([1.1, 2.2, 3.3])
newArray = np.int8(array)
print(array) # [1.1 2.2 3.3]
print(newArray) # [1 2 3]
import numpy as np
array = np.array([1.1, 2.2, 3.3])
newArray = array.astype(np.int8)
print(array) # [1.1 2.2 3.3]
print(newArray) # [1 2 3]
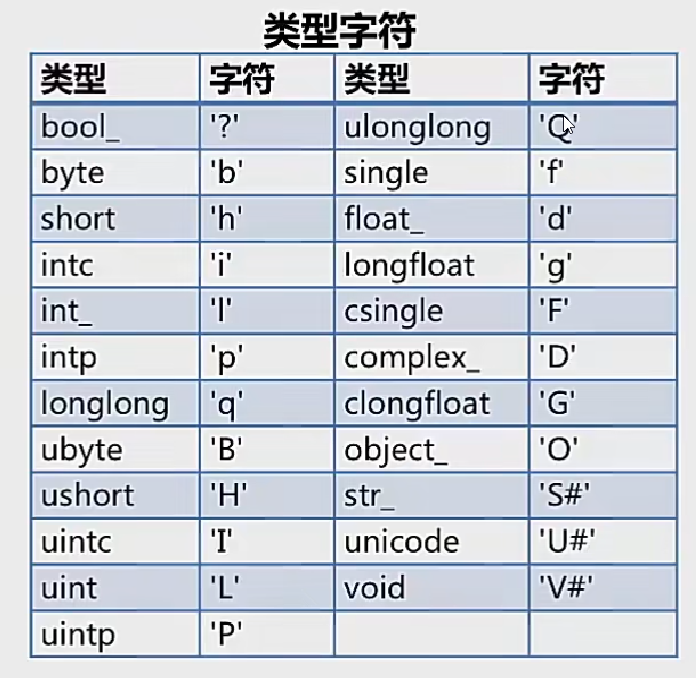
类型字符表达
| 字符 | 含义 |
|---|---|
| > | 高位优先 |
| < | 低位优先 |
| = | 本机硬件决定 |
| | | 不 |
import numpy as np
# 查看所有的类型字符
print(np.sctypeDict)
import struct
def check_endianness():
# 使用 pack 将整数 1 打包成二进制数据
packed = struct.pack("I", 1)
# 检查第一个字节的值以确定系统的大端或小端
if packed[0] == 1:
return "Little Endian"
else:
return "Big Endian"
# 输出系统的字节序
print(f"System is {check_endianness()}")
import numpy as np
array1 = np.array([1, 2.2, 3, 4], dtype=np.int8)
array2 = np.array([1, 2.2, 3, 4], dtype='i1') #等同于 np.int8,1个字节的 int
print(array1) # [1 2 3 4]
print(array2) # [1 2 3 4]
import numpy as np
a1 = np.array([1], dtype='i4')
b1 = bytearray(a1.data)
print(b1) # bytearray(b'\x01\x00\x00\x00')
a2 = np.array([1], dtype='>i4')
b2 = bytearray(a2.data)
print(b2) # bytearray(b'\x00\x00\x00\x01')
a3 = np.array([1], dtype='<i4')
b3 = bytearray(a3.data)
print(b3) # bytearray(b'\x01\x00\x00\x00')
- ‘>i4’ 表示高位优先,‘<i4’ 表示低位优先
文件 IO
数组
np.save('data.npy', np.array([1, 2, 3, 4, 5]), allow_pickle=False, fix_imports=True)
np.savez('data.npz', **args,**kwds)
np.savez_compressed('data.npz', a, b)
save()保存单个 arraysavez()保存多个 arraysavez_compressed保存并且压缩
np.load('data.npy', mmap_mode=None,allow_pickle=False, fix_imports=True,encoding='ASCII')
load()既可以加载.npy文件,也可以读取.npz文件返回 NpzFile 对象(用完关闭流 close),可以用.keys()查看所有的 keymmap_mode可选值为:None,r+,r,w+,c,如果不是 None 会使用指定模式把内存映射成一个 file 对象,可以部分访问而不需要全部导入。
import numpy as np
# allow_pickle=True/False 是否使用pickle序列化, 默认为True,建议设为False,因为pickle序列化存在安全漏洞,且有python版本兼容问题
# np.save('data.npy', np.array([1, 2, 3, 4, 5]), allow_pickle=False, fix_imports=True)
array = np.load('data.npy', allow_pickle=False, fix_imports=True)
print(array) # [1 2 3 4 5]
import numpy as np
a = np.array([1, 2, 3])
b = np.array([4, 5, 6])
np.savez('data.npz', a, b)
with np.load('data.npz') as data:
keys = data.keys()
print(keys) # KeysView(NpzFile 'data.npz' with keys: arr_0, arr_1)
arr0 = data['arr_0']
arr1 = data['arr_1']
print(arr0) # [1 2 3]
print(arr1) # [4 5 6]
import numpy as np
a = np.array([1, 2, 3])
b = np.array([4, 5, 6])
np.savez_compressed('data.npz', a, b, x=a, y=b) # 指定数组的名称分别为 x,y, load 读取文件的时候可以使用 x 读取第一个数组
with np.load('data.npz') as data:
keys = data.keys()
print(keys) # KeysView(NpzFile 'data.npz' with keys: x, y, arr_0, arr_1)
arr0 = data['x']
arr1 = data['y']
print(arr0) # [1 2 3]
print(arr1) # [4 5 6]
文本文件
np.savetxt(fname, X, fmt='%.18e', delimiter=' ', newline='\n', header='', footer='', comments='# ', encoding=None)
- fname(str 或 file handle):文件名或打开的文件对象。
X(array_like):要保存的数组。
fmt(str 或者 sequence of strs, optional):格式字符串或字符串序列,默认值为 ‘%.18e’。
delimiter(str, optional):分隔符,默认值为空格。
newline(str, optional):行结束符,默认值为换行符。
header(str, optional):写入文件开头的字符串。
footer(str, optional):写入文件末尾的字符串。
comments(str, optional):注释标志,默认值为 '# '。
encoding(str, optional):文件编码,默认值为 None。
np.loadtxt(fname, dtype=float, comments='#', delimiter=None, converters=None, skiprows=0, usecols=None, unpack=False, ndmin=0, encoding='bytes', max_rows=None, like=None)
- fname(str 或 file handle):文件名或打开的文件对象。
dtype(data-type, optional):数据类型,默认值为 float。
comments(str, optional):注释标志,默认值为 '# '。
delimiter(str, optional):分隔符,默认值为 None,这意味着任何连续的空白字符都将被视为分隔符。
converters(dict, optional):转换器函数字典,默认为 None。
skiprows(int, optional):跳过的行数,默认值为 0。
usecols(int or sequence, optional):使用的列索引或索引序列,默认值为 None。
unpack(bool, optional):如果 True,将返回解包后的数组列,默认值为 False。
ndmin(int, optional):返回数组的最小维数,默认值为 0。
encoding(str, optional):文件编码,默认值为 ‘bytes’。
max_rows(int, optional):要读取的最大行数,默认值为 None。
like(array_like, optional):定义输出类型的参考数组,默认值为 None。
import numpy as np
data = np.array([[1.5, 2.3, 3.1], [4.5, 5.6, 6.7], [7.8, 8.9, 9.0]])
np.savetxt('data.txt', data, fmt='%.2f', delimiter=',', header='Column1, Column2, Column3')
loaded_data = np.loadtxt('data.txt', delimiter=',', skiprows=1)
print("加载的数据:")
print(loaded_data)
np.tofile()
np.fromfile()
- 不推荐,和操作系统相关,可能有问题
操作多维数组
选择数组
import numpy as np
arr = np.array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
print(arr[0]) # 0
print(arr[0:9:1]) # [0 1 2 3 4 5 6 7 8]
print(arr[0:9:2]) # [0 2 4 6 8]
print(arr[3:9:2]) # [3 5 7]
print(arr[::2]) # [0 2 4 6 8]
print(arr[3::2]) # [3 5 7 9]
print(arr[:4:2]) # [0 2]
print(arr[:]) # [0 1 2 3 4 5 6 7 8 9]
print(arr[::]) # [0 1 2 3 4 5 6 7 8 9]
print(arr[1:]) # [1 2 3 4 5 6 7 8 9]
print(arr[:5]) # [0 1 2 3 4]
print(arr[-2:]) # [8 9]
print(arr[:-2]) # [0 1 2 3 4 5 6 7]
| 反向索引 | -10 | -9 | -8 | -7 | -6 | -5 | -4 | -3 | -2 | -1 |
| 数组 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 下标索引 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
import numpy as np
arr = np.array([[0, 1, 2, 3], [4, 5, 6, 7], [8, 9, 10, 11]])
print(arr)
print(arr[1][2]) # 6
print(arr[2][1]) # 9
| 列 0 | 列 1 | 列 2 | 列 3 | |
|---|---|---|---|---|
| 行 0 | 0 | 1 | 2 | 3 |
| 行 1 | 4 | 5 | 6 | 7 |
| 行 2 | 8 | 9 | 10 | 11 |
import numpy as np
arr = np.array([[0, 1, 2, 3], [4, 5, 6, 7], [8, 9, 10, 11]])
print(arr[1][2]) # 6
print(arr[1, 2]) # 6
print(arr[:, :]) # 所有行,所有列
print(arr[1, 1::2]) # 第一行,从第一列开始,到第二列结束,步长为2
print(arr[1, 0::2]) # 第一行,从第零列开始,到第二列结束,步长为2
print(arr[1, 0::1]) # 第一行,从第零列开始,到第二列结束,步长为1
print(arr[0:2, :]) # 第零行开始到第二行(不包含),所有列
print(arr[0:2:1, :]) # 第零行开始到第二行(不包含),所有列
print(arr[0:2:2, :]) # 第零行开始到第二行(不包含),步长为2,所有列
import numpy as np
arr = np.arange(12).reshape(3, 4)
print(arr)
for r in arr:
print(f"Type: {type(r)}, Value: {r}")
for e in arr.flat: # arr.flat 会迭代数组中的每一个元素
print(f"Type: {type(e)}, Value: {e}")
import numpy as np
arr = np.array([
[0, 1],
[2, 3],
[4, 5]
])
print(arr)
for i in range(arr.shape[0]):
print(f"第 {i} 行: {arr[i, :]}")
print("")
for j in range(arr.shape[1]):
print(f"第 {j} 列: {arr[:, j]}")
-
第 0 行: [0 1] 第 1 行: [2 3] 第 2 行: [4 5] 第 0 列: [0 2 4] 第 1 列: [1 3 5]
import numpy as np
arr = np.arange(24).reshape(2, 3, 4)
print(arr)
print("第 0 维度")
for i in range(arr.shape[0]):
print(arr[i, :, :])
print("===")
print("第 1 维度")
for i in range(arr.shape[1]):
print(arr[:, i, :])
print("===")
print("第 2 维度")
for i in range(arr.shape[2]):
print(arr[:, :, i])
print("===")
-
沿着某一维度进行遍历
-
多维数组的含义有很多种解释,可以用在中学学的立体坐标系上,也可以用于地理 gis 信息的点线面等
-
如果对维度遍历不是很理解,可以用 xyz 坐标系进行尝试理解
-
找2张纸叠在一起,下面一张纸上写一个二维数组,0到11,再同样的在上面一张纸上,同样写 12到23
-
y ↓ x→ 轴→ 方→ 向→ 轴 ↓ 0 1 2 3 方 ↓ 4 5 6 7 向 ↓ 8 9 10 11 -
第 0 维度沿着 z 轴,从 z 轴 的 0 开始向上遍历。发现第 0 维度有 2 组数据,分别是 2 页纸上的
-
第 1 维度沿着 y 轴,从 y 轴 的 0 开始向 y 轴正向遍历,发现第 1 维度有 3 组数据,
-
依次类推。
-
-
import numpy as np
arr = np.array([10, 11, 12, 13, 14, 15, 16, 17, 18, 19])
idx = [1, 3, 1, 4] # 索引数组
print(arr[idx]) # [11 13 11 14]
idx = np.array([[1, 3], [1, 4]]) # 二维索引数组,代表了返回结果的形状
print(arr[idx]) # [[11 13]
# [11 14]]
import numpy as np
arr = np.arange(10, 19).reshape((3, 3))
print(arr)
idx1 = [0, 1, 2] # 指定第一维度的索引
idx2 = [2, 1, 0] # 指定第二维度的索引
print(arr[idx1, idx2]) # [12 14 16]
-
相当于查询 3 次,
arr[0,2],arr[1,1],arr[2,0] -
索引 Y0 Y1 Y2 X0 10 11 12 X1 13 14 15 X2 16 17 18
import numpy as np
arr = np.arange(10, 19).reshape((3, 3))
print(arr)
idx1 = np.array([[0, 0], [1, 1]])
idx2 = np.array([[2, 1], [2, 1]])
print(arr[idx1, idx2]) # [[12 11]
# [15 14]]
-
idx1 idx1 idx2 idx2 0 0 2 1 x[0,2] x[0,1] 1 1 2 1 x[1,2] x[1,1]
布尔数组
import numpy as np
arr = np.arange(12).reshape((3, 4))
print(arr)
print(arr > 8)
print(np.less(arr, 6))
-
能够得到一个 布尔类型的数组
-
符号 函数 == np.equals() < np.less > np.greater != np.not_equal <= np.less_equal >= np.greater_equal & np.bitwise_and | np.bitwise_or ^ np.bitwise_xor ~ np.bitwise_not import numpy as np arr = np.arange(12).reshape((3, 4)) print(arr) print(arr > 8) # 布尔数组,和源数组结构相同 print(arr[arr > 8]) # [ 9 10 11] print(np.less(arr, 6)) print(arr[np.less(arr, 6)]) # [0 1 2 3 4 5]- 布尔数组会 mask 出 True 的值
改变形状
import numpy as np
array = np.array([[1, 2, 3], [4, 5, 6]])
print(array)
print(array.shape) # (2, 3)
print("===================")
a1 = array.reshape(3, 2)
print(a1)
print(a1.shape) # (3, 2)
print("===================")
a2 = array.reshape(-1, 2)
print(a2)
print(a2.shape) # (3, 2) -1 表示自动计算, 6/2=3
print("===================")
a3 = array.reshape((-1,))
print(a3) # [1 2 3 4 5 6]
print(a3.shape) # (6,) 拉平,称为 flatten
print("===================")
a4 = array.reshape((-1,), order='F')
print(a4) # [1 4 2 5 3 6]
print(a4.shape) # (6,) 用 Fortran 风格读取原来的数组
print("===================")
a5 = array.reshape((3, 1, 2))
print(a5)
print(a5.shape) # (3, 1, 2) # 增加维度,需要注意的是,reshape后的维度乘积必须等于原来的维度乘积
import numpy as np
array = np.array([[1, 2, 3], [4, 5, 6]])
a1 = np.resize(array, (2, 2)) # 溢出的话,截断
print(a1)
a2 = np.resize(array, (3, 3)) # 不够的话,使用数组的元素重复填充
print(a2)
- np.resize 不会修改原数据
x = np.array([[1, 2, 3], [4, 5, 6]])
x.resize((2, 2)) # ndarray.resize 方法,直接修改原数组
print(x)
y = np.array([[1, 2, 3], [4, 5, 6]])
y.resize((3, 3))
print(y)
-
ndarray.resize 会修改原数组
-
import numpy as np x = np.array([[1, 2, 3], [4, 5, 6]]) y = x x.resize(2, 3) # 虽然形状改变,但总数不变,可以修改 print(x) print(y)x.resize(3, 3) # 修改成 3x3,报错x.resize((3, 3),refcheck=False) # 设置 refcheck=False, x 和 y 形状都改变
import numpy as np
x1 = np.array([1, 2, 3])
y1 = np.array([11, 12, 13])
x2 = np.array([[1, 2, 3], [4, 5, 6]])
y2 = np.array([[11, 12, 13], [14, 15, 16]])
a1 = np.column_stack((x1, y1)) # 每一个数组作为一列,需要确保两个数组的长度相同
print(a1)
a2 = np.vstack((x2, y2)) # 按照第一个维度进行堆叠 vertical(垂直)
print(a2)
a3 = np.hstack((x2, y2)) # 按照第二个维度进行堆叠 horizontal(水平)
print(a3)
a4 = np.concatenate((x2, y2), 0) # 按照第一个维度进行堆叠,vstack 是 concatenate 在二维数组上的特例
print(a4)
a5 = np.concatenate((x2, y2), 1) # 按照第二个维度进行堆叠,hstack 是 concatenate 在二维数组上的特例
print(a5)
a6 = np.stack((x1, y1), 0)
print(a6)
a7 = np.stack((x1, y1), 1)
print(a7)
print("========================== 3行3列在 0 维度上合并 ==========================")
a8 = np.stack((x2, y2), 0)
print(a8)
print("========================== 3行3列在 1 维度上合并 ==========================")
a9 = np.stack((x2, y2), 1)
print(a9)
import numpy as np
x = np.arange(1, 31).reshape(5, 6)
print(x)
c1, c2, c3 = np.hsplit(x, 3) # 水平平均拆分成 3 份, 以列为单位
print(c1)
print(c2)
print(c3)
c = np.hsplit(x, 3)
for i, arr in enumerate(c):
print(f'第{i}个数组')
print(arr)
-
import numpy as np x = np.arange(1, 31).reshape(5, 6) print(x) c1, c2 = np.hsplit(x, (2, )) # 从索引 2 处开始截断 c1, c2 = np.hsplit(x, [2, ]) print(c1) # 2列 print(c2) # 4列import numpy as np x = np.arange(1, 31).reshape(5, 6) print(x) c1,c2,c3 = np.hsplit(x, (2, 3)) # 从索引 2,3 处开始截断,分成 3 份 c1,c2,c3 = np.hsplit(x, [2, 3]) print(c1) # 1,2 列 print(c2) # 3 列 print(c3) # 4,5,6 列c1,c2,c3 = np.vsplit(x, [2, 3]) c1,c2,c3 = np.vsplit(x, (2, 3)) # 垂直方向,按行切割
基本计算
import numpy as np
x = np.array([[1, 2, 3], [4, 5, 6]])
y = np.array([[1, 2, 3], [3, 2, 1]])
print(x)
print(y)
print("========")
print(-x)
print(x + y)
print(x - y)
print(x * y)
print(x / y)
print(x // y) # floor division, / 取 floor
print(x ** y) # power
print(x % y) # mod
x += y
x -= y
x *= y
x /= y
x //= y
x **= y
x %= y
import numpy as np
x = np.array([[1, 2, 3], [4, 5, 6]])
y = np.array([[1, 2, 3], [3, 2, 1]])
print(x)
print(y)
print("========")
print(x > y)
print(x < y)
print(x >= y)
print(x <= y)
print(x == y)
print(x != y)
| 运算符 | 对应的函数 | 说明 |
|---|---|---|
| + | np.add | 加 |
| - | np.subtract | 减 |
| - | np.negative | 负数 |
| * | np.multiply | 乘 |
| / | np.divide | 除 |
| // | np.floor_divide | 整除 |
| ** | np.power | 幂 |
| % | np.mod | 模 |
| np.ceil | 向上取整 | |
| np.floor | 向下取整 | |
| np.round | 四舍五入 | |
| np.clip | 指定上下限截断 | |
| np.conj(conjugate) | 共轭数 | |
| np.minimum | 求最小值 | |
| np.maximum | 求最大值 | |
| np.diff | 差分比较 | |
| np.cumsum | 累计和 | |
| np.cumprod | 累计乘积 |
import numpy as np
x = np.array([[1, 2, 3], [4, 5, 6]])
y = np.array([[1, 2, 3], [3, 2, 1]])
print("数组 x:")
print(x)
print("数组 y:")
print(y)
print("====================")
print("===== 加法 (np.add) =====")
print(np.add(x, y))
print("====================")
print("===== 減法 (np.subtract) =====")
print(np.subtract(x, y))
print("====================")
print("===== 取负 (np.negative) =====")
print(np.negative(x))
print("====================")
print("===== 乘法 (np.multiply) =====")
print(np.multiply(x, y))
print("====================")
print("===== 除法 (np.divide) =====")
print(np.divide(x, y))
print("====================")
print("===== 整除 (np.floor_divide) =====")
print(np.floor_divide(x, y))
print("====================")
print("===== 幂运算 (np.power, x^2) =====")
print(np.power(x, 2))
print("====================")
print("===== 取模 (np.mod) =====")
print(np.mod(x, y))
print("====================")
# 创建一个新数组 z 用于演示 ceil, floor 和 round 函数
z = np.array([1.2, 3.5, 5.7])
print("===== 向上取整 (np.ceil) =====")
print(np.ceil(z))
print("====================")
print("===== 向下取整 (np.floor) =====")
print(np.floor(z))
print("====================")
print("===== 四舍五入 (np.round) =====")
print(np.round(z))
print("====================")
print("===== 截断 (np.clip, minimum=2, maximum=5) =====")
print(np.clip(x, 2, 5))
print("====================")
# 创建一个复数数组 c 用于演示共轭函数
c = np.array([1+2j, 3+4j])
print("===== 共轭 (np.conjugate) =====")
print(np.conj(c))
print(np.conjugate(c))
print("====================")
print("===== 最小值 (np.minimum) =====")
print(np.minimum(x, y))
print("====================")
print("===== 最大值 (np.maximum) =====")
print(np.maximum(x, y))
print("====================")
print("===== 差分 (np.diff) =====")
print(np.diff(x, axis=0)) # 0表示沿着行方向计算差分,下面一个数减上面一个数
print(np.diff(y, axis=0))
print(np.diff(y, axis=1)) # 1表示沿着列方向计算差分,后面一个数减前面一个数
print("====================")
print("===== 累计和 (np.cumsum) =====")
print(np.cumsum(x))
print("====================")
print("===== 累计乘积 (np.cumprod) =====")
print(np.cumprod(x))
print("====================")
| 对应的函数 | 说明 |
|---|---|
| np.all | 是否全为 True |
| np.any | 是否包含 True |
import numpy as np
x = np.array([True, True])
y = np.array([True, False])
z = np.array([False, False])
print(np.all(x)) # True
print(np.all(y)) # False
print(np.all(z)) # False
print(np.any(x)) # True
print(np.any(y)) # True
print(np.any(z)) # False
| 对应的函数(按照某一维度) | 说明 |
|---|---|
| np.average | 加权平均值 |
| np.mean | 平均值 |
| np.median | 中位数 |
| np.std | 标准差 |
| np.sum | 求和 |
| np.prod | 求积 |
| np.min | 求最小 |
| np.max | 求最大 |
| np.bincount | 统计每个元素出现的次数 |
import numpy as np
x = np.array([[1, 2, 3], [4, 5, 6]])
print(x)
print(np.sum(x)) # 21
print(np.sum(x, axis=0)) # [5 7 9]
print(np.sum(x, axis=1)) # [ 6 15]
print(np.mean(x)) # 3.5
weights = np.array([0.7, 0.3])
print(np.average(x, weights=weights, axis=0)) # [1.9 2.9 3.9] [1x0.7 + 4x0.3, 2x0.7 + 5x0.3, 3x0.7 + 6x0.3]
| 对应的函数(按照某一维度) | 说明 |
|---|---|
| np.argmin | 沿着某个维度查找最小元素的下标 |
| np.argmax | 沿着某个维度查找最大元素的下标 |
| np.nonzero | 查找非零元素的下标 |
| np.where | 根据条件查询或者替换 |
| np.argsort | 沿着某个维度计算下标, |
| np.sort | 沿着某个维度将元素按递增排序 |
| np.lexsort | 根据多个 array 进行排序 |
import numpy as np
x = np.array([2, 1, 0, 3])
y = np.array([[2, 1, 0, 3], [1, 2, 3, 4]])
print(x)
print(y)
print(np.argmin(x)) # 2
print(np.argmin(y, axis=0)) # [1 0 0 0] # 2和1比,1比较小,所以第一个是索引 1,
print(np.argmin(y, axis=1)) # [2 0]
print(np.argmax(x)) # 3
print(np.argmax(y, axis=0)) # [0 1 1 1]
print(np.argmax(y, axis=1)) # [3 3]
import numpy as np
m = np.array([[1, 2], [0, 3]])
print(m)
x_idx, y_idx = np.nonzero(m)
print(x_idx) # [0 0 1] #1=>(0 0) 2=>(0 1) 3=>(1 1) 取行索引
print(y_idx) # [0 1 1] #1=>(0 0) 2=>(0 1) 3=>(1 1) 取列索引
print(m[x_idx, y_idx]) # [1 2 3]
import numpy as np
m = np.arange(12).reshape(3, 4)
print(m)
x_idx, y_idx = np.where(m % 2 == 0)
print(x_idx) # [0 0 1 1 2 2]
print(y_idx) # [0 2 0 2 0 2]
print(m[x_idx, y_idx]) # [ 0 2 4 6 8 10]
n = np.where(m % 2 == 0, 88, 77) # 符合 m % 2 == 0 的元素改为 88,否則改为 77
print(n)
import numpy as np
m = np.array([9, 5, 2, 7])
print(m) # [9 5 2 7]
idx = np.argsort(m)
print(idx) # [2 1 3 0]
print(m[idx]) # [2 5 7 9]
m = np.array([[9, 5, 2, 7], [6, 7, 8, 3]])
print(m)
print(np.sort(m))
print(np.sort(m, axis=0)) # 按照指定维度进行排序
print(np.sort(m, axis=1))
线性代数
| 对应的函数(按照某一维度) | 说明 |
|---|---|
| np.cross | 两个向量的叉乘 |
| np.dot | 两个array的点乘,1维=内积,2维=矩阵乘 |
| np.inner | 两个向量的内积 |
| np.outer | 两个向量的外积 |
| np.trace | 矩阵的迹 |
| np.transpose | 矩阵的转置 |
| np.vdot | 两个向量的点乘,只用于1维数组 |
| np.corrcoef | 计算 Pearson 相关系数 |
| np.cov | 计算协方差阵 |
| np.std | 沿指定维度计算标准差 |
| np.var | 沿指定维度计算方差 |
自定义函数
import numpy as np
def myFun(x):
return np.max(x) - np.min(x)
x = np.array([1, 2, 3, 4, 5])
n = np.apply_along_axis(myFun, axis=0, arr=x)
print(n) # 4
y = np.array([[1, 2, 3], [6, 8, 10]])
m0 = np.apply_along_axis(myFun, axis=0, arr=y)
print(m0) # [5 6 7]
m1 = np.apply_along_axis(myFun, axis=1, arr=y)
print(m1) # [2 4]
np.apply_along_axis使用自定义函数进行运算
import numpy as np
def myFun(x):
return x % 2 == 0
v = np.vectorize(myFun, otypes=[np.bool_])
v1 = v(np.array([[1, 2, 3, 4], [5, 6, 7, 8]]))
print(v1)
np.vectorize向量化
加速技巧
import numpy as np
x = np.arange(1000)
y = np.arange(1000)
%timeit -r 10 -q -o z = np.outer(x, y)
z = np.empty((1000,1000),dtype=np.int_)
%timeit -r 10 -q -o np.outer(x, y)
广播
import numpy as np
x = np.array([1, 2, 3])
x_ = x + 2
print(x_) # [3 4 5]
m = np.array([[1, 2, 3], [4, 5, 6]])
n = np.array([10, 20, 30])
o = m + n
print(o) # [[11 22 33] [14 25 36]]
- 上面示例,2个不同维度的 array 进行计算。为什么可以计算。
- 2 个广播原则:
- 输入的两个 array 维度不等,在维度较小的 array 前面增加大小为1的维度,直到维度相等
- 对两个 array 依次比较每个维度的大小,对于某个维度一个 array 大小为1,另一个不是,则在这个维度上将大小为1的那个 array 扩充,直到2个 array 维度大小相同
import numpy as np
x = np.array([[0], [1], [3]]) # 3行1列
y = np.array([0, 1, 2, 3]) # 1行4列
print(x)
print(y)
print(x + y)
拷贝
完全不拷贝
import numpy as np
x = np.array([1, 2, 3])
y = x
print(y is x) # True 完全不拷贝, y和x是同一个ndarray对象
视图
import numpy as np
x = np.array([1, 2, 3])
y = x.view()
# y = x[1:2] 切片也是视图
print(y.flags.owndata) # False 是一个视图
print(y.base is x) # True y 是基于 x 创建的
x[1] = 100
print(x) # [ 1 100 3]
print(y) # [ 1 100 3]
-
修改 x 或者 y 都会改变另外一个,但是改变形状和类型对原始 array 没影响
-
import numpy as np x = np.array([1, 2, 3, 4]) y = x.view() print(y) # [1 2 3 4] y = y.reshape((2, 2)).astype(np.float32) # 对视图 y 进行修改形状和类型 x[1] = 100 print(x) # [ 1 100 3 4] # print(y) # [[ 1. 2.] [ 3. 4.]] #
深拷贝
import numpy as np
x = np.array([1, 2, 3, 4])
y = x.copy()
print(y is x) # False
print(y.base is x) # False
print(y.flags.owndata) # True
y = x[x % 2 == 0]
print(y is x) # False
print(y.base is x) # False
print(y.flags.owndata) # True
y = x[[1,3]]
print(y is x) # False
print(y.base is x) # False
print(y.flags.owndata) # True
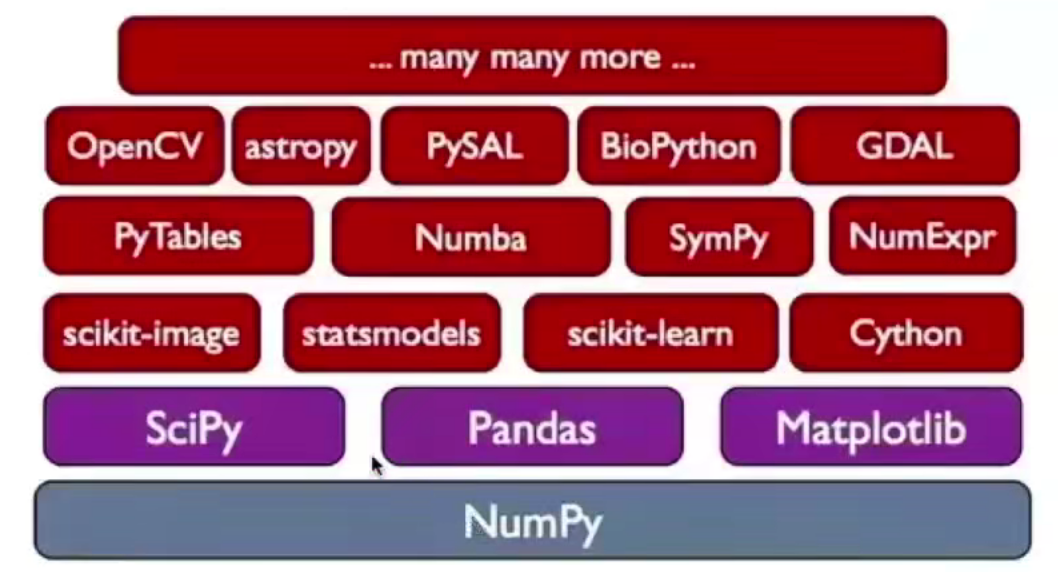
Scipy
-
基于 Numpy 开发的数据工具包
- Numpy 侧重数值计算,提供了多维数组,基本运算
- Scipy 侧重数据科学,提供了科学计算工具
-
以 子模块的形式提供了大部分科学计算工具
-
子模块 描述 cluster 聚类算法 constants 物理和数学常量 fftpack 快速傅里叶变换 integrate 积分和常微分方程 intepolate 插值和样条平滑 linalg 线性代数,比 Numpy里的 linalg 优化,性能更好 ndimage 图像处理 optimize 最优化及求根 signal 信号处理 sparse 稀疏矩阵 spatial 空间数据结构和算法 special 特殊函数 stats 统计分析
-
-
scipy 随 anaconda 自带,也可以通过 conda install scipy 安装
向量
- 加法和数乘
import numpy as np
x1 = np.array([1, 2])
print(x1) # [1 2]
x2 = np.array([2, 3])
print(x2) # [2 3]
print(x1 + x2) # [3 5]
print(3 * x1) # [3 6]
import numpy as np
x1 = np.array([1, 2, 3])
print(x1) # [1 2 3]
x2 = np.array([2, 3, 4])
print(x2) # [2 3 4]
print(x1 + x2) # [3 5 7]
print(3 * x1) # [3 6 9]
import numpy as np
x = np.array([1, 2])
y = np.array([3, 4])
z = np.array([5, 6])
# 结合律
print(x + (y + z)) # [ 9 12]
print((x + y) + z) # [ 9 12]
# 交换律
print(x + y) # [4 6]
print(y + x) # [4 6]
# 零向量
print(np.zeros_like(x)) # [0 0]
print(x + np.zeros_like(x)) # [1 2]
# 逆向量
print(-x) # [-1 -2]
print(x + (-x)) # [0 0]
# 树乘分配律
print(2 * (x + y)) # [ 8 12]
print(2 * x + 2 * y) # [ 8 12]
print((2 + 3) * x) # [ 5 10]
print(2 * x + 3 * x) # [ 5 10]
# 乘法
print(2 * (3 * x)) # [ 6 12]
print((2 * 3) * x) # [ 6 12]

Pandas
python data analysis library
基于 numpy 开发的数据分析工具
- NumPy:n 维数组容器,矩阵为基础,
- SciPy:科学计算函数库,基于 Numpy,傅里叶变换,
- Pandas:表格容器,基于 Numpy,数据分析
快速入门 https://pandas.pydata.org/pandas-docs/stable/10min.html#operations
API 资料查询 http://pandas.pydata.org/pandas-docs/stable/api.html
安装和导入
# pip install pandas
import pandas as pd
print(pd.__version__)
Series:理解为 任意数据类型的一维数组,数据类型一致。数据和索引组成
- pandas.Series(data=None,index=None,dtype=None)
import numpy as np
import pandas as pd
# 通过 ndarray 创建
n1 = pd.Series(np.array([1, 2, 3, 4, 5]))
print(n1)
# 通过 list 创建
s1 = pd.Series([1, 2, 3])
print(s1) # 不指定 index, 默认从 0 开始
s2 = pd.Series([1, 2, 3, 4, 5], index=['a', 'b', 'c', 'd', 'e'])
print(s2) # 指定 index,需要长度和 data 长度一致
# 通过 dict 创建
d = {"name": "张三", "age": 18}
d1 = pd.Series(d) # key 作为 index, value 作为 data
print(d1)
DataFrame:二维表格,

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









