






Python
安装
HelloWorld
print("Hello World")

基础
字面量:代码中被写下来固定的值,
数字:Number
- 整数 int
- 浮点数 float
- 复数 complex
- 布尔 bool
字符串:String(双引号)
列表:List
元组:Tuple
集合:Set
字典:Dictionary
注释
-
单行注释 # 开头
-
# 我是注释 print("Hello World")
-
-
多行注释 ### 开头和结尾
-
""" 我是注释 第二行注释 """ print("Hello World")
-
字符串
单引号
双引号
三引号
-
格式化
-
name = "张三丰" desc = "很厉害" age = 100 print(name + desc) print(name + desc + age) #不可执行,类型不同,不能直接拼接 -
message = "有一个人叫: %s 他 %s 因为他年龄是 %d" %(name,desc,age) print(message) print("有一个人叫: %s 他 %s 因为他年龄是 %d" %(name,desc,age))-
%s 字符串占位
-
%d 整型占位
-
%f 浮点型占位
-
我们可以使用辅助符号"m.n"来控制数据的宽度和精度 m,控制宽度,要求是数字(很少使用),设置的宽度小于数字自身,不生效 .n,控制小数点精度,要求是数字,会进行小数的四舍五入 示例: %5d:表示将整数的宽度控制在5位,如数字11,被设置为5d,就会变成:[空格][空格][空格]11,用三个空格补足宽度。 %5.2f:表示将宽度控制为5,将小数点精度设置为2 小数点和小数部分也算入宽度计算。如,对11.345设置了%7.2f 后,结果是:[空格][空格]11.35。2个空格补足宽度,小数部分限制2位精度后,四舍五入为 .35 %.2f:表示不限制宽度,只设置小数点精度为2,如11.345设置%.2f后,结果是11.35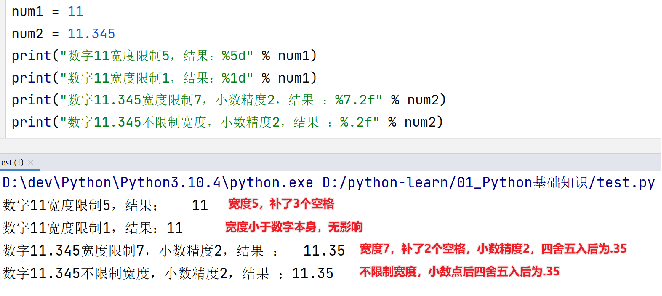
-
-
-
print(f"有一个人叫: {name} 他 {desc} 因为他年龄是 {age}") 有一个人叫: 张三丰 他 很厉害 因为他年龄是 100
数据类型
type() 进行转换
print(type(123))
print(type("闻C"))
-
<class 'int'> <class 'str'>
数据类型转换
int(x) 将 x 转成一个整数
float(x)
str(x)
标识符
- 英文、数字、下划线、中文(不推荐中文)
- 数字不能用在开头
- 大小写敏感
- 不可使用关键字
- 关键字:
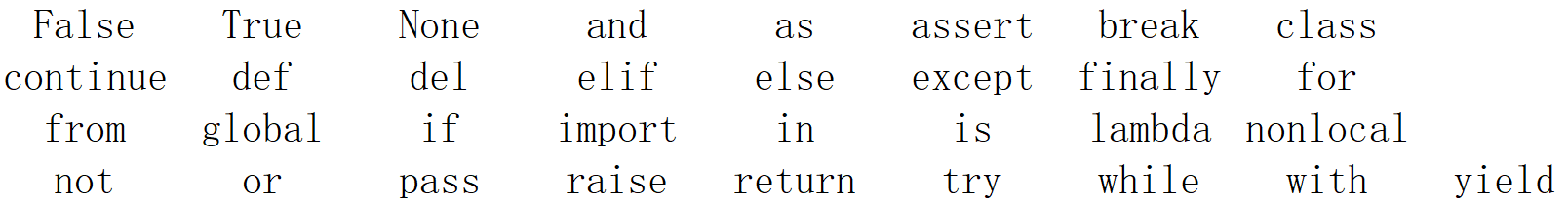
运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| + | 加 | 两个对象相加 a + b 输出结果 30 |
| - | 减 | 得到负数或是一个数减去另一个数 a - b 输出结果 -10 |
| * | 乘 | 两个数相乘或是返回一个被重复若干次的字符串 a * b 输出结果 200 |
| / | 除 | b / a 输出结果 2 |
| // | 取整除 | 返回商的整数部分 9//2 输出结果 4 , 9.0//2.0 输出结果 4.0 |
| % | 取余 | 返回除法的余数 b % a 输出结果 0 |
| ** | 指数 | a**b 为10的20次方, 输出结果 100000000000000000000 |
| 运算符 | 描述 | 实例 |
|---|---|---|
| += | 加法赋值运算符 | c += a 等效于 c = c + a |
| -= | 减法赋值运算符 | c -= a 等效于 c = c - a |
| *= | 乘法赋值运算符 | c *= a 等效于 c = c * a |
| /= | 除法赋值运算符 | c /= a 等效于 c = c / a |
| %= | 取模赋值运算符 | c %= a 等效于 c = c % a |
| **= | 幂赋值运算符 | c **= a 等效于 c = c ** a |
| //= | 取整除赋值运算符 | c //= a 等效于 c = c // a |
输入
input()
print("请输入你的名字:")
name = input()
print(f"你刚才输入的是 {name}")
- 所有是输入都是字符串
比较运算符
| 运算符 | 描述 | 示例 |
|---|---|---|
| == | 判断内容是否相等,满足为True,不满足为False | 如a=3,b=3,则(a == b) 为 True |
| != | 判断内容是否不相等,满足为True,不满足为False | 如a=1,b=3,则(a != b) 为 True |
| > | 判断运算符左侧内容是否大于右侧满足为True,不满足为False | 如a=7,b=3,则(a > b) 为 True |
| < | 判断运算符左侧内容是否小于右侧满足为True,不满足为False | 如a=3,b=7,则(a < b) 为 True |
| >= | 判断运算符左侧内容是否大于等于右侧满足为True,不满足为False | 如a=3,b=3,则(a >= b) 为 True |
| <= | 判断运算符左侧内容是否小于等于右侧满足为True,不满足为False | 如a=3,b=3,则(a <= b) 为 True |
if else if else
num = input()
num = int(num)
if num > 5:
print(f"你输入的数字是 {num} 是大于5的")
elif num > 2:
print(f"你输入的数字是 {num} 是大于2的")
else:
print(f"你输入的数字是 {num} 是小于等于2的")
print("小于等于2我才输出")
print("我无论如何都输出,因为我顶格了,不属于判断的分支")
循环
while
while True/False:
执行语句
for
for item in list:
执行语句
-
name = "wenc" for s in name: print(s)
# range(num) 从0开始,到数字 num,不包含 num
# range(n1,n2) 从n1开始,到数字 n2,不包含 n2
# range(n1,n2,step) 从n1开始,到数字 n2,不包含 n2,每次步长 step
range(5) [0,1,2,3,4]
range(2,5) [2,3,4]
range(1,9,2) [1,3,5,7]
作用域
能访问,不建议
for i in range(1,9,2):
print(i)
print("我是",i)
break
结束循环:该 for 循环结束
for i in range(5):
if i == 3:
break
print(i)
0
1
2
continue
结束本次循环:仅 == 3 的那一次跳过
for i in range(5):
if i == 3:
continue
print(i)
0
1
2
4
函数
先定义,后使用。
参数不需要和返回值没有可以省略
def 函数名(参数):
函数体
return 返回值
# 调用
函数名(参数)
-
def add(a,b): c = a+b return c num = add(2,5); print(num)
# 空函数,先不做
def emptyFun():
pass #先占位,什么都不做
如果没有 return 返回值的话,默认返回字面量 None
def fun():
print('我执行了')
r = fun()
print(r)
print(type(r))
# None 在判断上等于 False
if not r :
print('None == False')
def test(a,b):
"""
测试函数
:param a:
:return:
"""
return a+b
参数
def person(name, age, gender):
print(f"Name: {name}, Age: {age},Gender:{gender}")
person("闻家奇", 18, "男") # Name: 闻家奇, Age: 18,Gender:男
person(age=20, name="张三", gender='女') # Name: 张三, Age: 20,Gender:女
person("约翰", gender='男', age=22) # Name: 约翰, Age: 22,Gender:男
-
可以根据位置,按位传参,
person("闻家奇", 18, "男")第一个就是 name,第二个就是 age,第三个就是 gender可以指定 key,
person(age=20, name="张三", gender='女')指定 key 就不一定需要根据位置可以混用
person("约翰", gender='男', age=22)第一个默认是 name,后面根据 key 传参
def person(name, age, gender):
print(f"Name: {name}, Age: {age},Gender:{gender}")
# person("闻家奇",18) # TypeError: person() missing 1 required positional argument
def user(name, age, gender="男"):
print(f"Name: {name}, Age: {age},Gender:{gender}")
user("闻家奇", 18) # Name: 闻家奇, Age: 18,Gender:男
user("孙晓惠", 20, "女") # Name: 孙晓惠, Age: 20,Gender:女
-
可以对属性设置默认值,但是该属性必须放到参数列表的最后
-
def user(name, age, gender="男"): 正确 def user(name="张", age, gender): 错误
-
不定长
def person(*args):
print(args)
person("闻") # ('闻',)
person("闻", 18) # ('闻', 18)
person("闻", 18, "男") # ('闻', 18, '男')
- 不定长参数,前面加个星号,所有参数都会被 args 接收,形成一个元组 tuple 类型。
def person(**kwargs):
print(kwargs)
person(name="闻") # {'name': '闻'}
person(name="闻", age=18) # {'name': '闻', 'age': 18}
person(name="闻", age=18, gender="男") # {'name': '闻', 'age': 18, 'gender': '男'}
- 两个星号,使用 KV 键值对的形式传递
多返回值
def add(a, b):
s = a + b
d = a - b
return s, d
s, d = add(5, 2)
print(s, d) # 7 3
函数作为参数
def testFun(fa):
result = fa(1, 2)
print(result)
def fa(a,b):
return a+b
testFun(fa)
- testFun 的参数是一个 函数
- fa 本身就是一个 函数
def calculate(a, b, logic):
result = logic(a, b)
print(f"Result: {result}")
return result
def add(a, b):
return a + b
def subtract(a, b):
return a - b
def multiply(a, b):
return a * b
def divide(a, b):
return a / b
calculate(10, 5, add) # Result: 15
calculate(10, 5, subtract) # Result: 5
calculate(10, 5, multiply) # Result: 50
calculate(10, 5, divide) # Result: 2.0
- 为什么不直接调用 add、substract 等方法呢?
匿名函数
def add(a, b):
print(f"Adding {a} and {b}")
lambda x, y: print(f"Adding {x} and {y}")
def add(a, b):
return a + b
lambda x, y: x + y
容器
列表
# 定义一个数组
arr = [1, 2, 3, 4, 5]
for e in arr:
print(e)
for i, e in enumerate(arr):
print(i, e)
- 索引遍历不能越界
- 支持反向索引
# 定义一个数组
arr = ["a", "b", "c", "d", "e"]
e = arr.index("a")
print(e) # 0 返回元素的索引
arr[1] = "w"
print(arr) # ['a', 'w', 'c', 'd', 'e'] 修改元素
arr.insert(2, "x")
print(arr) # ['a', 'w', 'x', 'c', 'd', 'e'] 插入元素
arr.append("z")
print(arr) # ['a', 'w', 'x', 'c', 'd', 'e', 'z'] 尾部追加元素
arr.extend(["y", "z"])
print(arr) # ['a', 'w', 'x', 'c', 'd', 'e', 'z', 'y', 'z'] 尾部追加多个元素
arr.remove("z")
print(arr) # ['a', 'w', 'x', 'c', 'd', 'e', 'y', 'z'] 删除首个匹配元素
arr.pop()
print(arr) # ['a', 'w', 'x', 'c', 'd', 'e', 'y'] 删除尾部元素
arr.pop(2)
print(arr) # ['a', 'w', 'c', 'd', 'e', 'y'] 删除指定索引元素
arr.reverse()
print(arr) # ['y', 'e', 'd', 'c', 'w', 'a'] 反转数组
arr.sort()
print(arr) # ['a', 'c', 'd', 'e', 'w', 'y'] 排序数组
arr.clear()
print(arr) # [] 清空数组
元组 Truple
使用 ( ) 进行定义,逗号隔开,元组的数据不可变。
字符串字符遍历等操作也是元组,不可变
# 定义一个元组
("a", "b", "c")
t = ("a", "b", "c")
print(t) # ('a', 'b', 'c')
t1 = ()
print(f"t1的类型是{type(t1)},内容是{t1}") # ()
t2 = tuple()
print(f"t2的类型是{type(t2)},内容是{t2}") # ()
-
# 元组只有一个元素,也要加上逗号 t = ("hello") print(f"t = {t}, type(t) = {type(t)}") # t = hello, type(t) = <class 'str'> t = ("hello",) print(f"t = {t}, type(t) = {type(t)}") # t = ('hello',), type(t) = <class 'tuple'> -
# 定义一个元组 t = ("a", "b", "c", "d", "e") print(t) # ('a', 'b', 'c', 'd', 'e') i = t.index("a") print(i) # 0 , 返回元素的索引 c = t.count("a") print(c) # 1 , 返回元素的个数 l = len(t) print(l) # 5 , 返回元组的长度 -
t = (1, 2, ["a", "b"]) print(t) # (1, 2, ['a', 'b']) t[2][0] = "hello" t[2][1] = "world" print(t) # (1, 2, ['hello', 'world']) # 元组不可变,如果是引用对象的话,值是可以变的。
序列
内容连续,有序,可以使用下标进行索引的。都叫序列。
比如:列表,字符串,元组
序列支持切片。切片:从一个序列中取出一个子序列
序列 [开始索引:结束索引:步长]
str = "0123456789"
print(str[0:9:1]) # 012345678 # 从0开始,到8结束,步长为1
print(str[0:5:1]) # 01234 # 从0开始,到4结束,步长为1
print(str[3:5:1]) # 34 # 从3开始,到4结束,步长为1
print(str[0:9:2]) # 02468 # 从0开始,到8结束,步长为2。01 23 45 67 89
print(str[0:9:3]) # 036 # 从0开始,到8结束,步长为3。012 345 678
print(str[3:9:2]) # 357 # 从3开始,到8结束,步长为2。34 56 78
-
str = "0123456789" print(str[0:9:1]) # 012345678 print(str[0:9]) # 012345678 步长为1可以省略 print(str[:5]) # 01234 开始位置省略表示从 0 开始 print(str[5:]) # 56789 结束位置省略表示到最后一个元素 print(str[5::2]) # 579 开始位置从5开始,到最后,步长为2 print(str[:]) # 0123456789 从头到尾,步长为1遍历 print(str[::-1]) # 9876543210 从头到尾,反向步长,相当于逆序输出
集合
列表: [1,2,3]
元组: (1,2,3)
字符串: "123"
集合: {1,2,3}
s = set() 定义空集合
集合不允许重复。
集合无法通过索引进行查询
s = {"a", "b", "c", "a", "b", "c"}
print(f"Set: {s}, Type: {type(s)}") # Set: {'a', 'b', 'c'}, Type: <class 'set'>
s.add("hello")
print(f"Set: {s}") # Set: {'a', 'b', 'c', 'hello'}
s.remove("hello")
print(f"Set: {s}") # Set: {'a', 'b', 'c'}
s.pop()
print(f"Set: {s}") # Set: 随机取出一个元素移除
s.clear()
print(f"Set: {s}") # Set: set()
s1 = {1, 2, 3}
s2 = {2, 3, 4}
print(s1 & s2) # {2, 3} 取2个集合交集
print(s1 | s2) # {1, 2, 3, 4} 取2个集合并集
print(s1 - s2) # {1} 取2个集合差集
print(s2 - s1) # {4} 取2个集合差集
print(s1 ^ s2) # {1, 4} 取2个集合异或集 = (并集 - 交集)
s1 = {1, 2, 3}
s2 = {2, 3, 4}
s3 = s1.difference(s2) # s1 - s2, 源集合不变
print(f"s1: {s1}") # s1: {1, 2, 3}
print(f"s2: {s2}") # s2: {2, 3, 4}
print(f"s3: {s3}") # s3: {1}
s5 = s1.union(s2) # s1 | s2, 源集合不变
print(f"s1: {s1}") # s1: {1, 2, 3}
print(f"s2: {s2}") # s2: {2, 3, 4}
print(f"s5: {s5}") # s5: {1, 2, 3, 4}
s1.difference_update(s2) # s1 -= s2, 源集合改变
print(f"s1: {s1}") # s1: {1}
print(f"s2: {s2}") # s2: {2, 3, 4}
字典
键值对,键唯一。没有索引
d = {"张三": 18,"李四": 19,"王五": 20}
d = {}
d = dict()
d = {
"张三": 18,
"李四": 19,
"王五": 20
}
print(d) # {'张三': 18, '李四': 19, '王五': 20}
print(f"d的类型是:{type(d)}") # d的类型是:<class 'dict'>
print(d["张三"]) # 18
d = {
"张三": 18,
"李四": 19,
"王五": 20
}
d["张三"] = 21
d["赵六"] = 22
print(d) # {'张三': 21, '李四': 19, '王五': 20, '赵六': 22} 存在则修改,不存在则添加
v = d.pop("赵六") # 删除指定的键
print(d) # {'张三': 21, '李四': 19, '王五': 20}
print(v) # 22
for k in d:
print(k, d[k]) # 张三 21 李四 19 王五 20
for k, v in d.items():
print(k, v) # 张三 21 李四 19 王五 20
print("张三" in d) # True
print("闻家奇" in d) # False
print("张三" not in d) # False
print(len(d)) # 3
d.clear()
print(d) # {}
通用
都能遍历,但是部分有索引,部分不能索引
函数:len() clear() max() min()
转换
list(容器)
str(容器)
tuple(容器)
set(容器)
my_list = {"a", "b", "c"}
my_tuple = {"a", "b", "c"}
my_dict = {"k1": "a", "k2": "b", "k3": "c"}
my_set = {"a", "b", "c", "a"}
my_str = "abc"
list_list = list(my_list)
tuple_list = list(my_tuple)
dict_list = list(my_dict)
set_list = list(my_set)
str_list = list(my_str)
print(f"list_list: {list_list}") # ['a', 'b', 'c']
print(f"tuple_list: {tuple_list}") # ['a', 'b', 'c']
print(f"dict_list: {dict_list}") # ['k1', 'k2', 'k3']
print(f"set_list: {set_list}") # ['a', 'b', 'c']
print(f"str_list: {str_list}") # ['a', 'b', 'c']
list_set = set(my_list)
tuple_set = set(my_tuple)
dict_set = set(my_dict)
set_set = set(my_set)
str_set = set(my_str)
print(list_set) # {'a', 'b', 'c'}
print(tuple_set) # {'a', 'b', 'c'}
print(dict_set) # {'k1', 'k2', 'k3'}
print(set_set) # {'a', 'b', 'c'}
print(str_set) # {'a', 'b', 'c'}
list_tuple = tuple(my_list)
tuple_tuple = tuple(my_tuple)
dict_tuple = tuple(my_dict)
set_tuple = tuple(my_set)
str_tuple = tuple(my_str)
print(list_tuple) # ('a', 'b', 'c')
print(tuple_tuple) # ('a', 'b', 'c')
print(dict_tuple) # ('k1', 'k2', 'k3')
print(set_tuple) # ('a', 'b', 'c')
print(str_tuple) # ('a', 'b', 'c')
list_str = str(my_list)
tuple_str = str(my_tuple)
dict_str = str(my_dict)
set_str = str(my_set)
str_str = str(my_str)
print(list_str) # {'a', 'b', 'c'}
print(tuple_str) # {'a', 'b', 'c'}
print(dict_str) # {'k1': 'a', 'k2': 'b', 'k3': 'c'}
print(set_str) # {'a', 'b', 'c'}
print(str_str) # abc
排序。
字符串按照字典排序,数值按照数字排序
reverse ,默认 False,设置 True 表示逆序。
my_list = {"1", "3", "2", "11"}
my_tuple = {"1", "3", "2", "11"}
my_dict = {"k1": "1", "k2": "3", "k3": "2", "k4": "11"}
my_set = {"1", "3", "2", "11"}
my_str = "acbed"
print(sorted(my_list)) # ['1', '11', '2', '3']
print(sorted(my_tuple)) # ['1', '11', '2', '3']
print(sorted(my_dict)) # ['k1', 'k2', 'k3', 'k4']
print(sorted(my_set)) # ['1', '11', '2', '3']
print(sorted(my_str)) # ['a', 'b', 'c', 'd', 'e']
print(sorted(my_list, reverse=True)) # ['3', '2', '11', '1']
print(sorted(my_tuple, reverse=True)) # ['3', '2', '11', '1']
print(sorted(my_dict, reverse=True)) # ['k4', 'k3', 'k2', 'k1']
print(sorted(my_set, reverse=True)) # ['3', '2', '11', '1']
print(sorted(my_str, reverse=True)) # ['e', 'd', 'c', 'b', 'a']
函数式
arr = [
{"name": "张三", "age": 18},
{"name": "李四", "age": 19},
{"name": "王五", "age": 20},
{"name": "赵六", "age": 21},
{"name": "马七", "age": 22},
]
# 获得年龄大于等于 20 的人的列表
def filter_func(arr):
newArr = []
for item in arr:
if item["age"] >= 20:
newArr.append(item)
return newArr
newArr = filter_func(arr)
print(f"newArr: {newArr}") # newArr: [{'name': '王五', 'age': 20}, {'name': '赵六', 'age': 21}, {'name': '马七', 'age': 22}]
-
# 修改逻辑,获得年龄大于等于 21 的人的列表 def filter_func_agegt21(arr): newArr = [] for item in arr: if item["age"] >= 21: newArr.append(item) return newArr -
# 修改逻辑,获得年龄大于等于 22 的人的列表 def filter_func_agegt22(arr): newArr = [] for item in arr: if item["age"] >= 22: newArr.append(item) return newArr -
# 有人会考虑,既然这样,为什么不把年龄的值也传进去? def filter_func(arr,age): # 多加一个参数 newArr = [] for item in arr: if item["age"] >= age: newArr.append(item) return newArr -
# 修改逻辑,获得年龄小于 20 的人的列表 def filter_func_agelt20(arr): newArr = [] for item in arr: if item["age"] < 20: newArr.append(item) return newArr -
# 修改逻辑,获得名字包含英文字符的人的列表 # 修改逻辑,获得名字是2个字的人的列表 # 修改逻辑,获得名字是3个字的人且年龄>20岁的人的列表 # 修改逻辑,累死菜B程序员 -
def filter_func(arr,logic): newArr = [] for item in arr: if logic(item): newArr.append(item) return newArr newArr = filter_func(arr,logic=lambda item: item["age"] > 20) newArr = filter_func(arr,logic=lambda item: item["age"] > 21) newArr = filter_func(arr,logic=lambda item: item["age"] >= 22) newArr = filter_func(arr,logic=lambda item: item["age"] < 20) print(f"newArr: {newArr}")
文件
读取文件
在 F盘下准备一个 a.txt 文本,以下是内容
HelloWorld闻家奇
闻7
f = open("F:/a.txt", mode="r", encoding="UTF-8")
print(f"Type of f: {type(f)}") # <class '_io.TextIOWrapper'>
print(f.read(8)) # HelloWor
print(f.read(2)) # ld
print(f.read(2)) # 闻家
- 如果遇到报错,很有可能是 编码格式不对
- 多次 read 的连续调用,read() 会移动文件的指针。
print(f.read(8))会读取 8 个字符,也就是HelloWor,此时会把文件的指针移动到 r 这个位置print(f.read(2))继续读取 2个字符,也就是ld,再次移动文件指针print(f.read(2))再读取 2 个字符,读取闻家
f = open("F:/a.txt", mode="r", encoding="UTF-8")
print(f"Type of f: {type(f)}") # <class '_io.TextIOWrapper'>
lines = f.readlines()
print(f"Type of lines: {type(lines)}") # Type of lines: <class 'list'>
print(lines) # ['HelloWorld闻家奇\n', '闻7']
for line in lines:
print(line.strip())
\n换行f.readline()读取一行数据
关闭文件流
import time
f = open("F:/a.txt", mode="r", encoding="UTF-8")
time.sleep(30)
f.close()
time.sleep(30)通过暂停 30 秒模拟文件占用,此时该文件被 python 程序占用,是无法删除文件。- 程序运行结束需要手动 close(),调用 close 方法可以结束文件占用
with open("F:/a.txt", mode="r", encoding="UTF-8") as f:
f.readline()
- 使用 with ,会自动关闭文件流,
as f命名别名,相当于赋值变量。
写入
f = open("F:/a.txt", mode="w", encoding="UTF-8")
f.write("Hello, World!") # 写入内存缓冲区
f.flush() # 将内存缓冲区的数据写入文件
- 写入,没有文件会创建。
- mode 是 w 的话,如果之前文件存在,会覆盖掉之前的文件里的内容
- f.close() 内置了 f.flush(),调用 close 也会先 flush()
with open("F:/a.txt", mode="a", encoding="UTF-8") as f:
f.write("Hello, World!") # 写入内存缓冲区
f.flush() # 将内存缓冲区的数据写入文件
- 模式改成 a,append,追加到文件尾部。
异常
try except
try:
open("file.txt")
except:
print("File not found")
- 对可能报错的代码块进行捕获
- exception 出现异常会执行
多个异常
try:
open("file.txt")
d = 1/0
except FileNotFoundError as e:
print("File not found")
except ZeroDivisionError as e:
print("Division by zero")
- 捕获多个异常
try:
open("file.txt")
d = 1 / 0
except (FileNotFoundError, ZeroDivisionError) as e:
print("出现异常")
- 捕获的异常放到元组里
try:
open("file.txt")
d = 1 / 0
except Exception as e:
print("出现异常")
- Exception 是可以捕获到所以异常
else
try:
d = 1/1
# d1 = 1/0
except Exception as e:
print("出现异常")
else:
print("没有异常")
- 使用 else 语句,如果没有异常就会执行 else 分支的代码块
finally
try:
# d = 1/1
d1 = 1/0
except Exception as e:
print("出现异常")
else:
print("没有异常")
finally:
print("无论是否有异常,都会执行")
传递
def main():
func02()
def func01():
d = 1 / 0
def func02():
print("执行func02")
func01()
print("func02执行完毕")
main()
-
执行func02 Traceback (most recent call last): File "F:\wen_project\pystudy\main.py", line 15, in <module> main() File "F:\wen_project\pystudy\main.py", line 2, in main func02() File "F:\wen_project\pystudy\main.py", line 11, in func02 func01() File "F:\wen_project\pystudy\main.py", line 6, in func01 d = 1 / 0 ~~^~~ ZeroDivisionError: division by zerodef main(): try: func02() except: print("出现异常") def func01(): d = 1 / 0 def func02(): print("执行func02") func01() print("func02执行完毕") main()
模块
[from 模块名称] import [模块 | 类 | 变量 | 函数 | *] [as 别名]
-
import XX模块 from XX模块 import 类、变量、方法 from XX模块 import * from XX模块 import XX as YY import XX as YYimport time time.sleep(3) print("game over")from time import sleep sleep(3) print("game over")import time as t t.sleep(3) print("game over")from time import sleep as s s(3) print("game over")
自定义模块
- 新建
my_module.py文件 - 创建函数 add
- 在 main.py 导入模块
from my_module import * - 在 main.py 使用
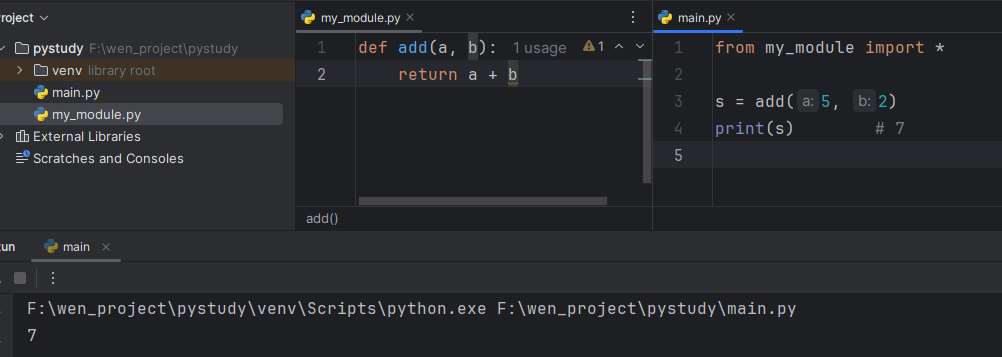
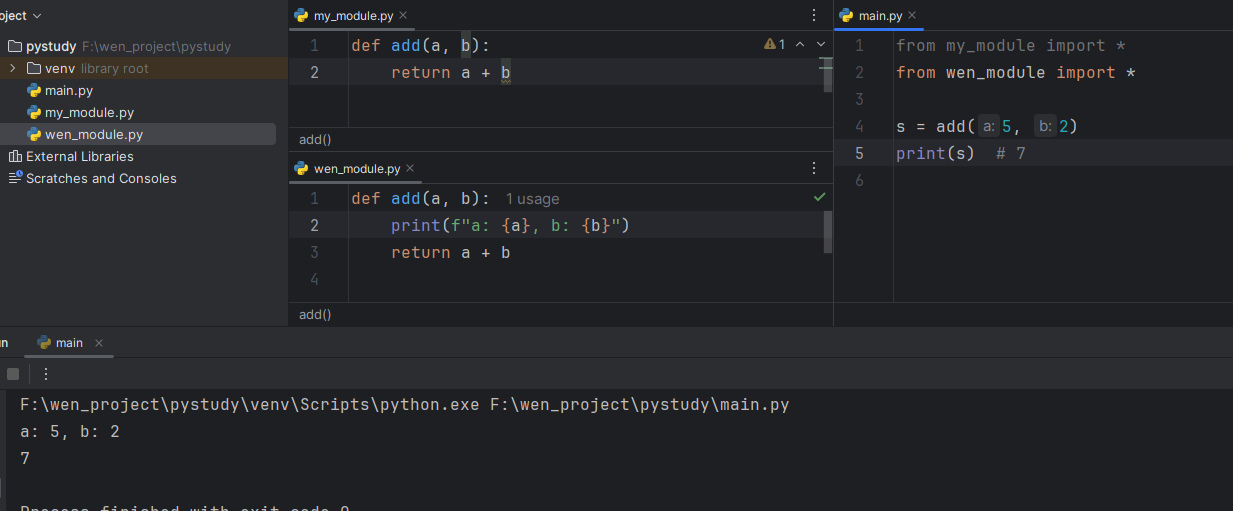
- 如果 my_module1.py 和 wen_module.py 里面都有 add 方法,在 main.py 都导入了,并且使用了 add 方法,使用的是后导入模块中的函数
内置变量
假设我创建了一个 my_module.py,写了一个函数 add,我不确定该功能是否正确,所以写了一个测试,
-
def add(a, b): print(f"a: {a}, b: {b}") return a + b add(7, 3)而我在文件里引入该模块的时候,就会自动执行该
add(7,3)from my_module import *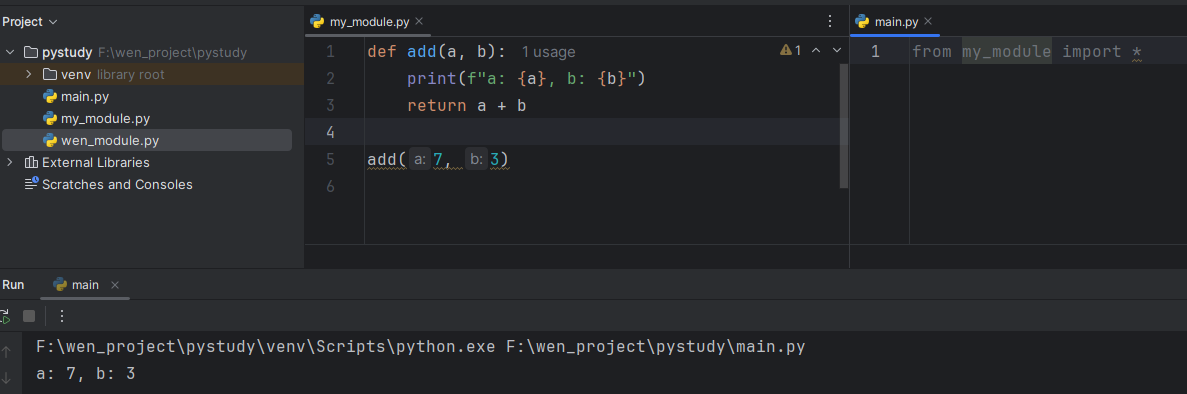
如何不删除掉该 add(7,3)函数,又能在导入时不调用呢?不删除可能是因为后续需要进行测试。
def add(a, b):
print(f"a: {a}, b: {b}")
return a + b
if __name__ == "__main__":
add(7, 3)
__name__是内置的一个变量,当右击运行该 my_module.py 文件的时候,就会把__name__设置成__main__,此时 if 条件成立,执行add(7,3),而当导入的时候 if 的条件不成立,就不会运行
__all__
-
定义
my_module.py,定义 3 个函数,add、subtract、multiply,但是使用内置变量设置__all__ = ['add', 'subtract']def add(a, b): return a + b def subtract(a, b): return a - b def multiply(a, b): return a * b __all__ = ['add', 'subtract'] -
在其他模块使用
import *导入的时候,只能导入这 2 个函数,此时的 * 只能导入上面__all__ = ['add', 'subtract']的函数from my_module import * print(add(10,5)) print(subtract(10,5)) # print(multiply(10,5)) # 报错
包
包本质也是一个模块,只不过组织方式稍微再扩大一点。
假设有 5 个 模块文件,需要导入 5 次,而一个大一点的工程里,模块很多。总不能把所有文件都写一个 a_module.py 里,要不然该文件也会超级大
-
my_module1.py -
my_module2.py -
my_module3.py -
my_module4.py -
my_module5.py -
from my_module1 import * from my_module2 import * from my_module3 import * from my_module4 import * from my_module5 import *
我们创建一个文件夹,在该文件夹下写一个文件 __init__.py,在该文件里导入上面的模块
- 一个普通的文件夹,下面有
__init__.py,那么该文件夹就是 包。没有就是普通的文件夹
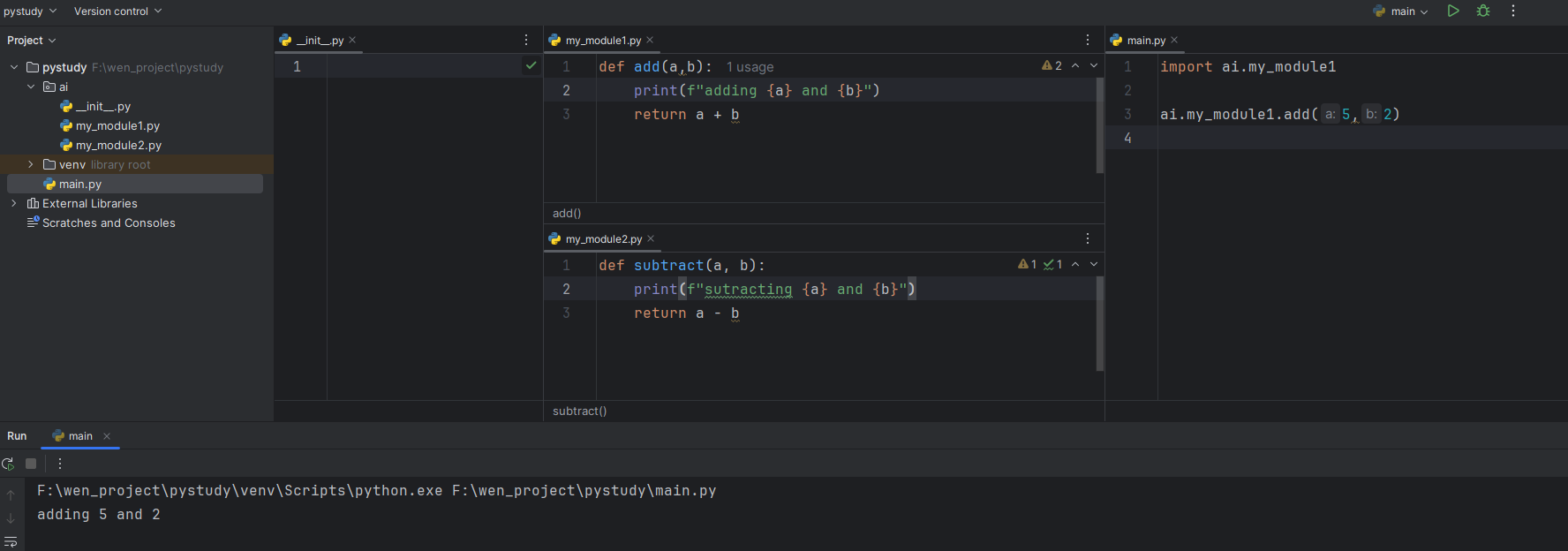
import ai.my_module1
ai.my_module1.add(5,2)
from ai import my_module1
my_module1.add(5,2)
from ai.my_module1 import add
add(5,2)
在 __init__.py 里指定导入的包
-
__all__ = ["my_module1", "my_module2"]from ai import * my_module1.add(5, 2)
第三方包
包可以包含一堆module,每个 module 包含了很多功能。一个包就是一堆功能的一个集合体。
python 生态里有很多第三方包,生成 word 文档,科学计算,数据分析等。要使用就得先导入。
- 科学计算
numpy - 数据分析
pandas - 大数据计算
pyspark,apache-flink - 图形可视化
matplotlib,pyecharts - 人工智能
tensorflow
pip install numpy
pip install numpy==2.0.1 # 指定版本号
pip install 'numpy>=2.0.1' # 指定版本不能小于该版本号
pip install numpy -i https://mirrors.aliyun.com/pypi/simple # 指定阿里云镜像源
pip install numpy -i https://pypi.tuna.tsinghua.edu.cn/simple # 指定清华镜像源
- 国内由于网络原因,如果不能翻墙的话,指定国内镜像源
包导出
pip freeze > requirements.txt
-
当我们一个项目依赖了很多包的时候,其他人下载项目下来想要运行,如何知道你导入了哪些包呢?我们使用上面的命令,把当前环境所有的包都导出来,这样别人只要根据
requirements.txt里面的依赖就可以下载了 -
# 根据 requirements.txt 下载依赖包 pip install -r requirements.txt
上面的 pip freeze > requirements.txt 是导出当前环境下所有的包,但是项目可能并不需要那么多,只依赖了其中部分包,使用 pipreqs 导出项目运行必需的包
pip install pipreqs
pipreqs ./
pipreqs ./ --encoding=utf8 # 指定生成文件的编码格式
pip install pipreqs因为pipreqs不是 python 内置的包,需要先下载pipreqs ./打包项目必需的依赖包
JSON
# json 互相转换
import json
arr = [
{"name": "张三", "age": 18},
{"name": "李四", "age": 19},
{"name": "王五", "age": 20}
]
j = json.dumps(arr)
print(type(j))
print(j)
j = json.dumps(arr, ensure_ascii=False)
print(j)
ja = json.loads(j)
print(type(ja))
print(ja)
-
json.dumps(Python对象,ensure_ascii=False)把 Python 对象转成 Json 字符串,ensure_ascii=False不使用 ascii,防止中文乱码 -
json.loads(Json字符串)把 Json 转成 Python 对象 -
<class 'str'> [{"name": "\u5f20\u4e09", "age": 18}, {"name": "\u674e\u56db", "age": 19}, {"name": "\u738b\u4e94", "age": 20}] [{"name": "张三", "age": 18}, {"name": "李四", "age": 19}, {"name": "王五", "age": 20}] <class 'list'> [{'name': '张三', 'age': 18}, {'name': '李四', 'age': 19}, {'name': '王五', 'age': 20}]
对象
class Student: # 定义一个类
name: None
age: None
student = Student() # 实例化对象
student.name = "张三" # 设置对象的属性
print(student.name)
class Student: # 定义一个类
name: None
age: None
def introduce(self): # 定义一个方法
print(f"我叫{self.name},今年{self.age}岁。")
student = Student() # 实例化对象
student.name = "张三" # 设置对象的属性
student.age = 18
student.introduce()
成员方法
def 方法名(self,参数1,参数2......):
方法体
-
self 表示自身,方法内部使用类的成员属性,必须使用 self
-
class Student: # 定义一个类 name: None age: None def introduce(self): # 定义一个方法 print(f"我叫{self.name},今年{self.age}岁。") def exam(self): self.introduce() print("我在考试!") student = Student() # 实例化对象 student.name = "张三" # 设置对象的属性 student.age = 18 student.introduce() student.exam()class Student: # 定义一个类 name: None age: None def introduce(self): # 定义一个方法 print(f"我叫{self.name},今年{self.age}岁。") def exam(self): self.introduce() print("我在考试!") def say(self,str): print(str) student = Student() # 实例化对象 student.name = "张三" # 设置对象的属性 student.age = 18 student.introduce() student.exam() student.say("我就是我,不一样的烟火")- self 可以不用管,不用传参。
构造方法
__init__() 就是构造方法
创建对象的时候,会自动执行,传入的参数会传给 __init__ 方法使用
class Student:
name: None
age: None
def __init__(self, name, age):
self.name = name
self.age = age
print("初始化成功")
student1 = Student("张三", 18)
student2 = Student("李四", 20)
print(f"学生1的名字是{student1.name},年龄是{student1.age}")
print(f"学生2的名字是{student2.name},年龄是{student2.age}")
-
初始化成功 初始化成功 学生1的名字是张三,年龄是18 学生2的名字是李四,年龄是20
魔术方法
内置的就叫魔术方法,比如 init 方法,名称前后各有2个下划线
# 魔术方法有几十个,掌握常见的几种
__init__()
__str__()
__lt__() __gt__()
__le__() __ge__()
__eq__()
str
class Student:
name: None
age: None
def __init__(self, name, age):
self.name = name
self.age = age
student1 = Student("张三", 18)
print(student1) # <__main__.Student object at 0x000001DDEB021A60>
print(str(student1)) # <__main__.Student object at 0x000001DDEB021A60>
-
class Student: name: None age: None def __init__(self, name, age): self.name = name self.age = age def __str__(self): return f"Student(name={self.name}, age={self.age})" student1 = Student("张三", 18) print(student1) # Student(name=张三, age=18) print(str(student1)) # Student(name=张三, age=18)
比较方法
class Student:
name: None
age: None
def __init__(self, name, age):
self.name = name
self.age = age
def __lt__(self, other):
return self.age < other.age
student1 = Student("张三", 18)
student2 = Student("李四", 20)
print(student1 < student2) # True
-
对象本身不可以比较大小,修改了 lt 方法的逻辑,传入另外一个对象 other,通过自定义逻辑比较年龄来判断对象大小
-
class Student: name: None age: None def __init__(self, name, age): self.name = name self.age = age def __lt__(self, other): return len(self.name) < len(other.name) # 修改比较对象大小的逻辑,按照名称的长度 student1 = Student("张三", 18) student2 = Student("李四", 20) student3 = Student("李四光", 20) print(student1 < student2) # False print(student1 < student3) # True
eq
eq 默认比较的是内存地址
class Student:
name: None
age: None
def __init__(self, name, age):
self.name = name
self.age = age
student1 = Student("张三", 18)
student2 = Student("李四", 20)
print(student1) # <__main__.Student object at 0x000001FA2CBC23F0>
print(student2) # <__main__.Student object at 0x000001FA2CBC2450>
print(student1 == student2) # False
封装
部分属性、方法进行开放使用,部分属性、方法私有使用
使用 2个下划线,表示私有
class Student:
name: None
__age: None # 私有属性
def introduce(self):
print(f"我叫{self.name}")
self.__money() # 只能内部调用
def __money(self): # 私有方法
print("我有100元")
student = Student()
student.name = "张三"
student.__age = 18 # 虽然设置,但是无法设置成功
student.introduce()
# student1.money() # 无法调用,报错 AttributeError: 'Student' object has no attribute 'money'
继承
单继承
class Phone6:
name = "iPhone 6"
network : None
def call(self):
print("打电话")
p = Phone6()
print(p.name) # iPhone 6
p.call() # 打电话
class Phone7(Phone6):
face_id = True
def face_unlock(self):
print("面部解锁")
p7 = Phone7()
p7.name = "iPhone 7"
print(p7.name) # iPhone 7
p7.call() # 打电话
p7.face_unlock() # 面部解锁
多继承
class 类名(父类1,父类2,......):
xxx
class Phone:
def call(self):
print("可以打电话")
class NFC:
def nfc(self):
print("可以NFC刷卡")
class XiaoMi(Phone,NFC):
def heating(self):
print("可以当暖手宝")
xm = XiaoMi()
xm.call() # 可以打电话
xm.nfc() # 可以NFC刷卡
xm.heating() # 可以当暖手宝
当多继承的时候,出现菱形继承问题
A 类里面有 name 属性,有 test() 方法,
B 类里面有 name 属性,有 test() 方法,
class C(A,B) C 继承了 A,B,当 C 调用属性和方法的时候,按照左侧优先,name 和 test() 方法是 A 方法的
class Phone:
name = "Phone"
def test(self):
print("我是 Phone 类的 test 方法")
class NFC:
name = "NFC"
def test(self):
print("我是 NFC 类的 test 方法")
class XiaoMi(Phone, NFC):
pass
xm = XiaoMi()
print(xm.name) # Phone
xm.test() # 我是 Phone 类的 test 方法
复写
class Phone:
def photograph(self):
print("我是 Phone 类的 photograph 方法")
class XiaoMi(Phone):
def photograph(self):
print("我是 XiaoMi 类的 photograph 方法")
xm = XiaoMi()
xm.photograph() # 我是 XiaoMi 类的 photograph 方法
- 复写父类中同名方法,就会复写该方法
class Phone:
def photograph(self):
print("我是 Phone 类的 photograph 方法")
class XiaoMi(Phone):
def photograph(self):
Phone.photograph(self) # 调用父类的 photograph 方法
super().photograph() # 调用父类的 photograph 方法
print("我是 XiaoMi 类的 photograph 方法")
xm = XiaoMi()
xm.photograph() # 我是 XiaoMi 类的 photograph 方法
-
我是 Phone 类的 photograph 方法 我是 Phone 类的 photograph 方法 我是 XiaoMi 类的 photograph 方法 -
如果子类想调用父类的属性或者方法,要么使用父类名称指定,要么使用 super() 指定
-
Phone.name Phone.photograph(self) super().name super().photograph()
-
多态
多态:多种状态,某个行为,使用不同对象,得到不同状态。
class MobilePhone:
def call(self):
pass
class ApplePhone(MobilePhone):
def call(self):
print("Calling from Apple Phone")
class XiaoMiPhone(MobilePhone):
def call(self):
print("Calling from XiaoMi Phone")
def func(mobilePhone: MobilePhone):
mobilePhone.call()
apple = ApplePhone()
xiaomi = XiaoMiPhone()
func(apple) # Calling from Apple Phone
func(xiaomi) # Calling from XiaoMi Phone
-
ApplePhone和XiaoMiPhone都是MobilePhone的子类,都重写了call()方法 -
当调用
func()的时候,需要传入一个MobilePhone,传入哪个就执行哪个的call()方法。 -
思考:为什么不直接调用对应的函数方法?
-
apple = ApplePhone() xiaomi = XiaoMiPhone() apple.call() # Calling from Apple Phone xiaomi.call() # Calling from XiaoMi Phone func(apple) # Calling from Apple Phone func(xiaomi) # Calling from XiaoMi Phone -
解答:可以抽象父类。比如我们编写
func()函数的时候,我并不能知道有哪些手机,也无法完全罗列出所有手机,可以抽象出一个高级的父类MobilePhone,在func()函数内部可以使用mobilePhone.call()编写代码,如果以后有新的手机出现,比如class HuaWei(MobilePhone)我们调用的时候只要在func(huawei)即可调用华为手机的方法。如果不是这么操作。我们就需要对每个手机都要编写 func 方法 -
def func(mobilePhone: MobilePhone): print("准备吃饭") print("定好饭店") mobilePhone.call() print("吃完回家") print("洗澡睡觉")-
def func(apple: ApplePhone): # 这种写法,出现一种手机就要写一个 print("准备吃饭") print("定好饭店") apple.call() print("吃完回家") print("洗澡睡觉")
-
-
抽象
class MobilePhone:
def call(self):
pass
- 这个 call 方法,函数实现是 pass,就是抽象方法
- 这个 MobilePhone 类,包含抽象方法,就是抽象类,也可以成为接口
类型注解
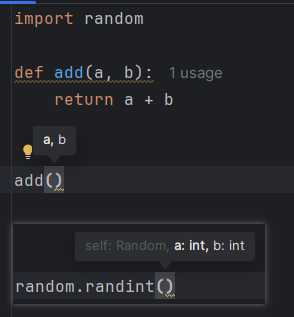
使用 Ctrl + P 查看函数参数的类型,比如 random.randint() 需要传入2个 int 类型,但是 add就不知道要传入什么类型
类型注解:
- 给变量设置类型
- 给方法的参数和返回值设置类型
- 给容器设置注解
变量注解
var1 = "闻家奇"
var2 = 18
var3 = [1, 2, 3]
var4 = {"money": 100}
var1: str = "闻家奇"
var2: int = 18
var3: list = [1, 2, 3]
var4: dict = {"money": 100}
函数变量注解
def add(a: int, b: int):
return a + b
add(1, 2)
- 这样别人调用
add()方法的时候就知道参数什么类型了。
def func(name, age) -> Student:
student = Student()
student.name = name
student.age = age
return student
- 在方法的后面加上
-> Student标记返回值类型
对象类型注解
class Student:
name: str
age: int
student: Student = Student()
student.name = "闻家奇"
student.age = 18
print(f"学生姓名:{student.name},年龄:{student.age}") # 学生姓名:闻家奇,年龄:18
容器类型注解
my_list: list = [1, 2, 3, 4, 5]
my_tuple: tuple = (1, 2, 3, 4, 5)
my_dict: dict = {"name": "闻家奇", "age": 18}
my_set: set = {1, 2, 3, 4, 5}
my_str: str = "Hello, World!"
- 只是对
my_list等容器类型做个注解。表示是list、tuple等类型。没有对list内的元素做注解
my_list: list[int] = [1, 2, 3, 4, "hello"]
my_tuple: tuple[str, int, bool] = ("闻家奇", 18, True)
my_dict: dict[str, int] = {
"姓名": "闻家奇",
"年龄": 20
}
my_set: set[int] = {1, 2, 3, 4, 5}
def test(d: dict[str, int]):
print(d)
test({"name", "闻家奇"})
my_list: list[int] = [1, 2, 3, 4, "hello"]虽然对元素做了注解,但是仍然可以把字符串hello放进去,因为不是强类型校验。my_dict: dict[str, int]字典类型的注解有2个,第一个表示 key,第二个表示 value
注释注解
import random
rand = random.randint(1, 10) # type: int
- 可以在注释里对变量进行注解。格式
# type: 类型 rand = random.randint(1, 10) # type: int表示 rand 是一个 int 类型。等同于rand: int = random.randint(1, 10)
实践
类型注解只是一个标记,不是强制性的。
var1: str = "闻家奇"
var2: int = 18
var3: list = [1, 2, 3]
var4: dict = {"money": 100}
-
这种定义变量的一般不会使用,变量一下子就能知道类型的
-
var1 = "闻家奇" var2 = 18 var3 = [1, 2, 3] var4 = {"money": 100}
-
s : Student = func()
- 这种函数无法知道返回类型的,可以使用类型注解,其他人阅读代码一下子就能知道 s 的类型
Union
from typing import Union
my_list_1: list = [1, 2, 3, 4, 5]
my_list_2: list[int] = [1, 2, 3, 4, 5]
my_list_3: list[int] = [1, 2, 3, 4, "hello"] # 不会报错,但不推荐
my_list_4: list[Union[int, str]] = [1, 2, 3, 4, "hello"]
- 使用需要导包
pip install Union - 使用
Union定义多种类型。my_list_4: list[Union[int, str]] = [1, 2, 3, 4, "hello"]该 list 里的元素可能是 str 也可能是 int 类型
闭包
def outer(prefix):
def inner(msg):
print(f"{prefix}: {msg}")
return inner
inner = outer("阿里巴巴")
inner("我是淘宝")
inner("我是天猫")
- 调用
outer(prefix)会得到一个内部的函数inner(msg),由于先调用outer(prefix)所以先确定下来 prefix 的变量。后续调用inner()都使用该 prefix
def outer(startNum):
def inner(step):
nonlocal startNum
startNum += step
print(f"当前的值是: {startNum}")
return inner
inner = outer(10)
inner(2)
inner(2)
inner(2)
- 内部函数修改外部函数的值,需要先对该变量加上
nonlocal
优点:无需定义全局变量,可以持续的访问、修改某个值。安全
缺点:由于内部函数持续引用,会一直不释放内存,容易内存泄漏
多线程
PySpark
https://www.bilibili.com/video/BV1qW4y1a7fU/?p=139&vd_source=4a8f6785b4f0d27ffaf69dbb4024042e















 7万+
7万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









