






Backdoor Defense with Machine Unlearning
论文相关
paper地址:https://arxiv.org/abs/2201.09538
preliminarily accepted in IEEE International Conference on Computer Communications (IEEE INFOCOM 2022).
摘要
提出了一种新的方法 BAERASER,可以消除注入 victim model 的后门。具体来说,BAERASER主要通过两个关键步骤实现后门防御。首先,进行 trigger pattern 恢复,提取被受害者模型感染的触发模式。这里的触发模式恢复问题相当于从受害者模型中提取未知噪声分布的问题,可以通过基于熵最大化的生成模型轻松解决。随后,诱饵利用这些恢复的触发模式来逆转后门注入过程,并通过一种新设计的基于梯度上升的 machine unlearning 方法,诱导受害者模型来消除被污染的记忆。与以往的机器遗忘解决方案相比,该方法摆脱了对训练数据进行再训练的依赖,显示了更高的后门擦除有效性。
前人工作
Backdoor Injection Attack & Defense
后门攻击:很多种,This paper is proposed to defend against all kinds of attacks mentioned above
后门防御大体上分为两类:
-
后门检测:Strip、Deepinspect、One-pixel signature。最多能达到99%以上的准确率
-
后门消除:Fine-pruning、Neural attention distillation。效果不佳。
fine-tuning: straightforward and typically available to real-world applications, fine-tuning is not a robust method and fails to defend most of the state-of-the-art attacks with limited clean data
fine-pruning: usually causes considerable model performance degradation while achieving a high defense rate.
Neural attention distillation: not removing it thoroughly, and thus, cannot achieve a very high defense rate in most cases
Machine Unlearning
-
Cao et al.: 开山之作
优缺点:straightforward and effective, it can only be applied to the non-adaptive models and achieves poor performance on adaptive models, like neural networks.
-
the recently proposed methods to implement machine unlearning are mainly retraining based.
优缺点:easily understandable and practical for applications, the required computational and storage resources of these retraining-based methods are massive and usually unaffordable.
Contributions
insight: backdoor erasing is equivalent to unlearning the unexpected memory of the victim model about backdoor trigger patterns.
两个挑战:
-
find the targeted set of data to be unlearned
解决方案:adopt generative based model to recover the trigger patterns infected by the victim model without need to access any training data
之前方法的问题:Moreover, previous solutions for trigger pattern recovery are usually based on the typical generative model, like generative adversarial network (GAN), which often suffers from an unexpected performance loss when estimating high-dimensional trigger patterns.
Therefore, instead of using GAN, BAERASER adopts the mutual information neural estimator [16], a generative model that can avoid the above problem via entropy maximization.
-
前人工作的缺陷:most existing machine unlearning methods are based on retraining that requires a full access to the training set of the target model. However, such a rigid data access setting is usually hard to be satisfied in the backdoor defense scenarios as discussed in most prior works [6], [7], [9], [10].
解决方案:reverse the process via gradient ascent
a vanilla gradient ascent method in our evaluation can suffer from obvious model performance degradation caused by catastrophic forgetting. Therefore, BAERASER introduces a weighted penalty mechanism to mitigate the problem.
贡献如下:
- 提出了一种后门防御的新方法,use a max-entropy staircase approximator to achieve trigger reconstruction, and then, erase the injected backdoor via machine unlearning.
- introduce a gradient ascent based machine unlearning method that can mitigate catastrophic forgetting through a dynamic penalty mechanism
- conduct extensive experiments on four datasets with three state-of-the-art backdoor injection attacks. The results show that our method can lower the attack success rate by 98% on average with less than 5% accuracy drops, which outperforms most of prior methods
此外,This paper is proposed to defend against all kinds of attacks mentioned above
Method
Threat Model & Goals
the attacker has successfully launched the attack and the victim model needs to be purifified.
- The defender has no prior knowledge about which images are polluted or the target label of the attacker.
- The defender can only get access to a limited portion of validation data but cannot hold the whole training set.
Defense goal: 在erasing trigger的同时保持CA

Defense Intuition and Overview
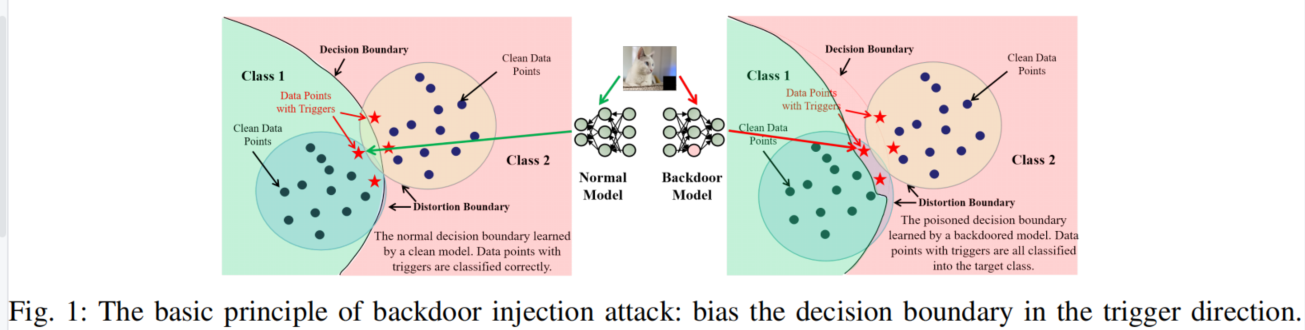
BAERASER involves two key steps, i.e., trigger pattern recovery and trigger pattern unlearning.
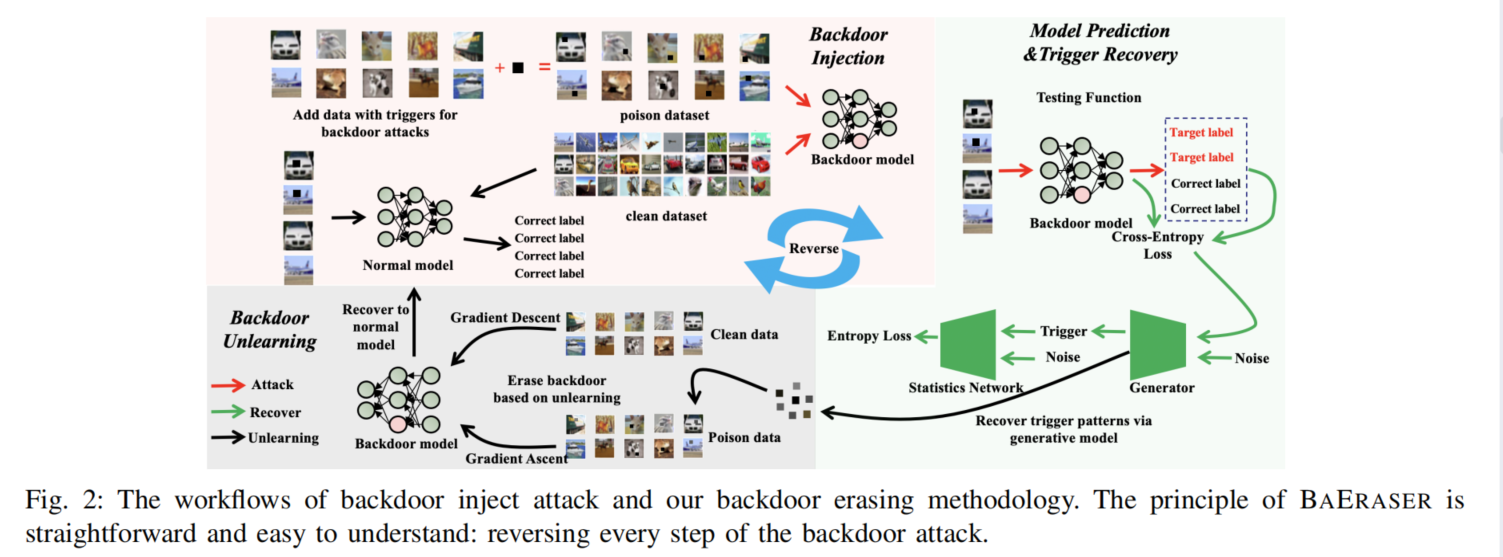
Trigger Pattern Recovery
max-entropy staircase approximator (MSA)
constrained the trigger pattern recovery problem to be an unknown noise distribution extraction problem.
Observation 1: the backdoor injection attack tricks F to learn a specific trigger pattern distribution ∆ that can transform F(X +∆) = y_i to be F(X +∆) = y_t.
Observation 2: If a trigger pattern ∆ exists, all inputs X +∆ will be classifified into the target class y_t.
和对抗样本的区别:对抗样本的noise适用于单个样本,而MSA的noise适用于 a batch of inputs;MSA还会 abandons the recovered trigger patterns whose overall attack success rates are lower than the desired threshold (line 13).

个人理解:
对每个label,经过n次迭代,recover出一个trigger,每次迭代都让 F θ 0 ( x + G i ( δ ) ) [ y p ] F_{\theta_0}(x+G_i(\delta))[y_p] Fθ0(x+Gi(δ))[yp]( F θ 0 ( x + G i ( δ ) ) F_{\theta_0}(x+G_i(\delta)) Fθ0(x+Gi(δ))是添加了trigger的input经过backdoor model之后的输出, F θ 0 ( x + G i ( δ ) ) [ y p ] F_{\theta_0}(x+G_i(\delta))[y_p] Fθ0(x+Gi(δ))[yp]就是输出为 y p y_p yp的概率)尽可能接近 ε i \varepsilon_i εi,那么最后一次迭代, F θ 0 ( x + G i ( δ ) ) [ y p ] F_{\theta_0}(x+G_i(\delta))[y_p] Fθ0(x+Gi(δ))[yp]就应该接近1。
max函数起到截断的作用,也就是说如果 ε i − F θ 0 ( x + G i ( δ ) ) [ y p ] < 0 \varepsilon_i - F_{\theta_0}(x+G_i(\delta))[y_p] < 0 εi−Fθ0(x+Gi(δ))[yp]<0,也就是 F θ 0 ( x + G i ( δ ) ) [ y p ] F_{\theta_0}(x+G_i(\delta))[y_p] Fθ0(x+Gi(δ))[yp]比 ε i \varepsilon_i εi大(这正是我们所希望的,加了trigger之后在target label上的概率当然越大越好啦),所以这时候就让损失为0而不是为负数。
H i H_i Hi是mutual information estimator,作用是让 G i ( δ ) G_i(\delta) Gi(δ)和 δ ′ \delta' δ′尽可能相似?
第13行,只有ASR高于阈值 τ \tau τ的trigger才会被加入trigger pool。
Trigger Pattern Unlearning

直接的loss:

may cause obvious catastrophic forgetting, which makes the model suffer from signifificant performance degradation
tricks:
- leveraging the validation data to maintain the memory of the target model over the normal data
- introducing a dynamic penalty mechanism to punish the over-unlearning of the memorizes unrelated to trigger patterns.


As β/α increases, more attention of BAERASER is paid to control model performance loss, and otherwise, BAERASER tends to lower the ASR as much as possible.
实验
Baselines: Fine Tuning、Fine-Pruning、Neural Attention Distillation(NAD)
Attacks:BadNet [29], TrojanNN [9] and IMC[30]
Datasets:MNIST, Fashion-MNIST, CIFAR-10, and CIFAR-100
base model:ResNet18
Evaluation Metrics:Attack Success Rate (ASR) and model Accuracy (Acc)
Comparison analysis
效果非常好:
Overall, BAERASER signifificantly outperforms all baselines on most attack settings and lowers around 98% ASR of all three backdoor attacks while introducing negligible Acc drops.
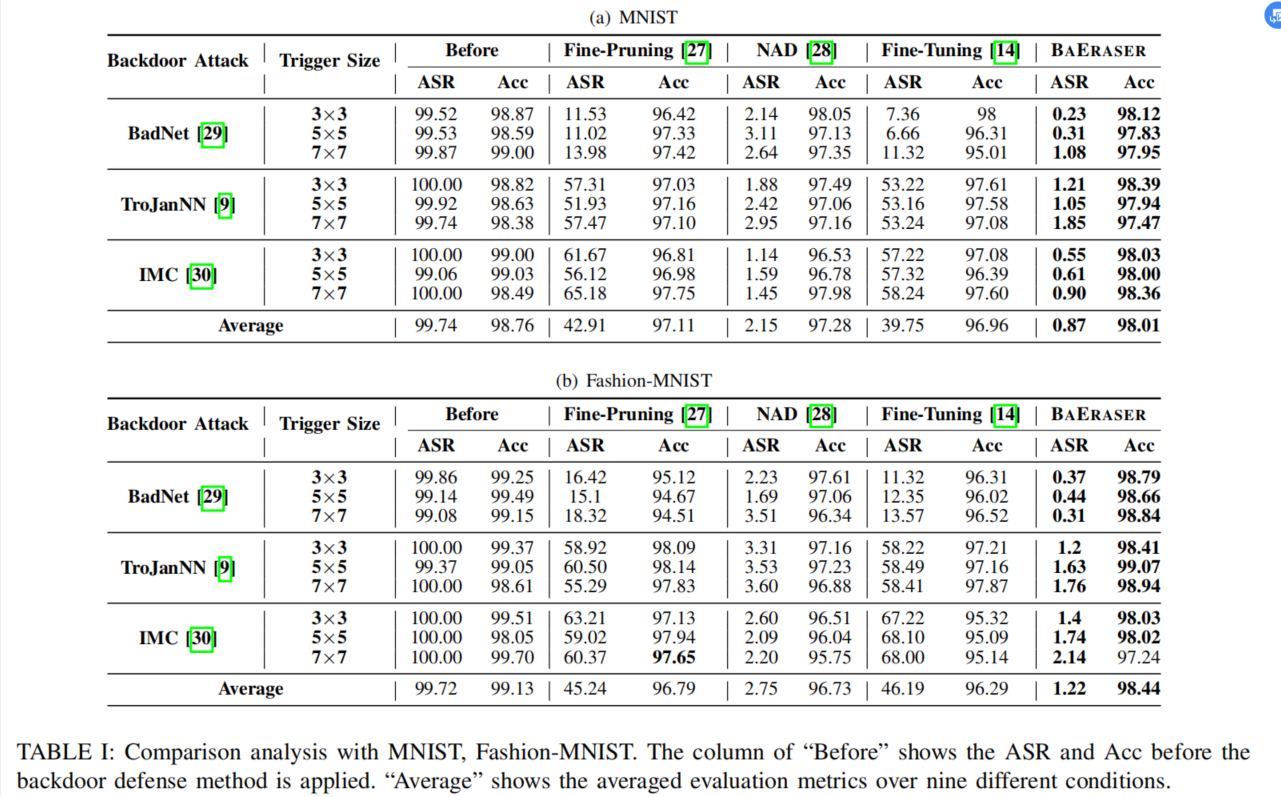
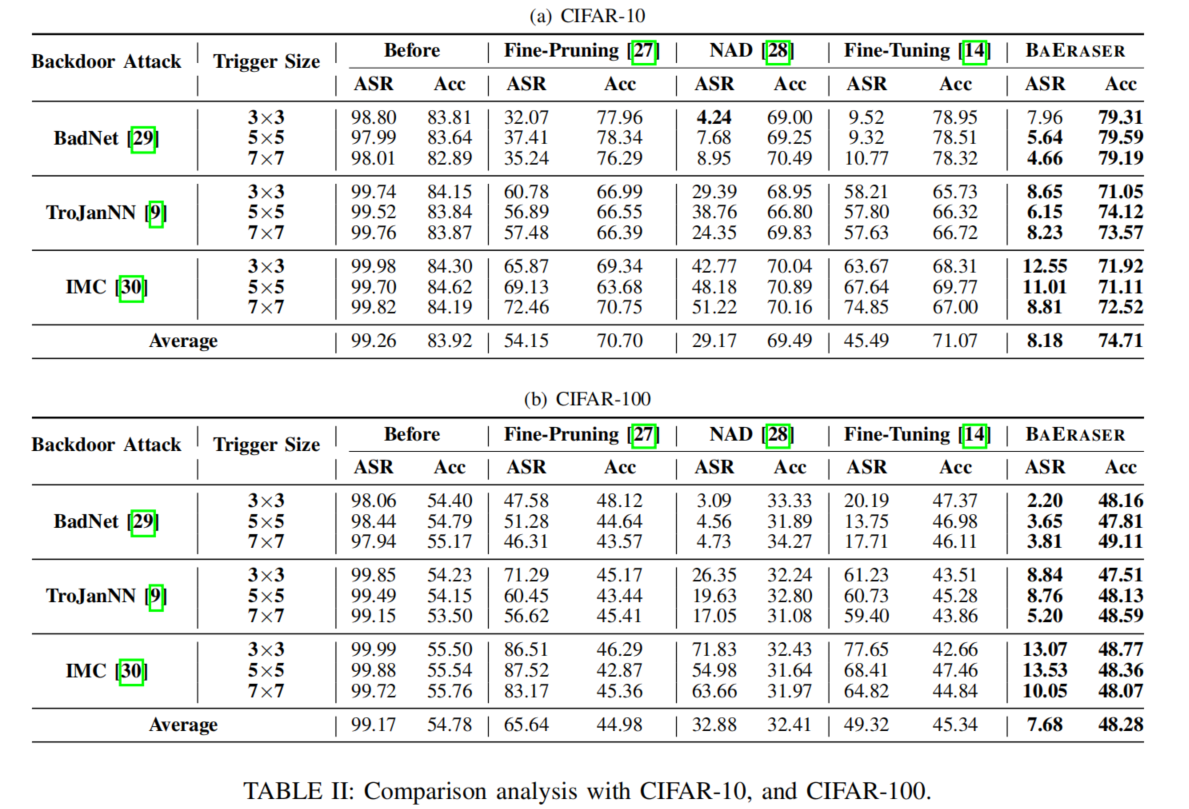
characteristic:For BAERASER, its performance potentially becomes better along with the increasing of trigger sizes, however, other methods tends to perform worse in the same condition.
原因:machine unlearning is sensitive to the feature distribution required to be unlearned
According to Eq. 4, more distinguished trigger patterns will promote the gradient ascent of machine unlearning to converge faster to wards the desired direction and mitigate its side-effect on other normal data (less punishment)
Further Understanding of BAERASER
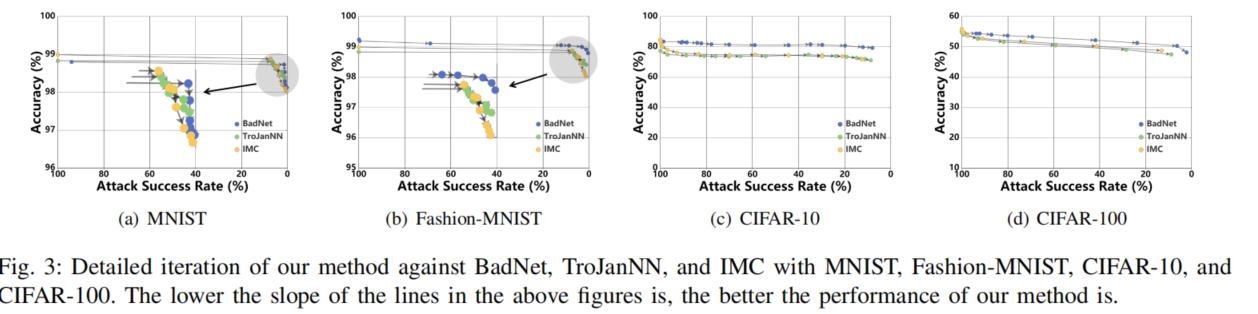
Trade-off between ASR and Acc
lower ASR requires more Acc sacrififice, and the sacrifificed Acc intensively grows with the decreasing of ASR.
Besides, although Acc decay rate increases with unlearning iterations, we can still maintain less than 10% Acc drops as the ASR is decreased to be almost 0%.
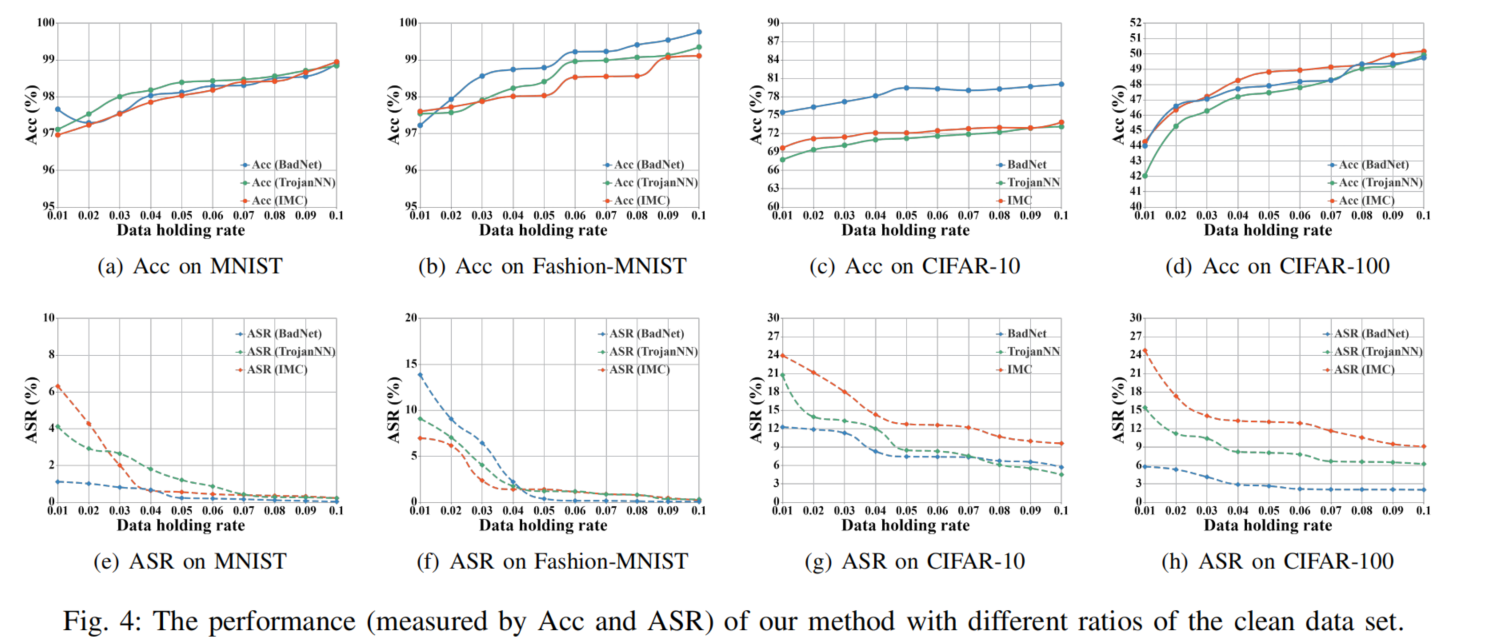
Impact of Holding Ratio
BAERASER performs better with higher holding ratios of clean data. Furthermore, even with only 1% clean data (500 clean data points), BAERASER still achieves an appealing defense rate (lowering at most 98% ASR)
Impact of α and β
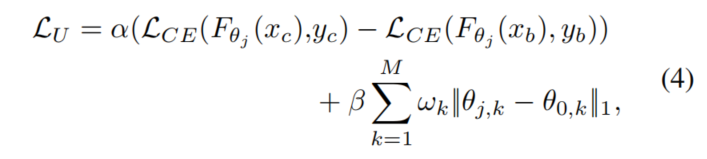
As β/α increases, more attention of BAERASER is paid to control model performance loss, and otherwise, BAERASER tends to lower the ASR as much as possible.
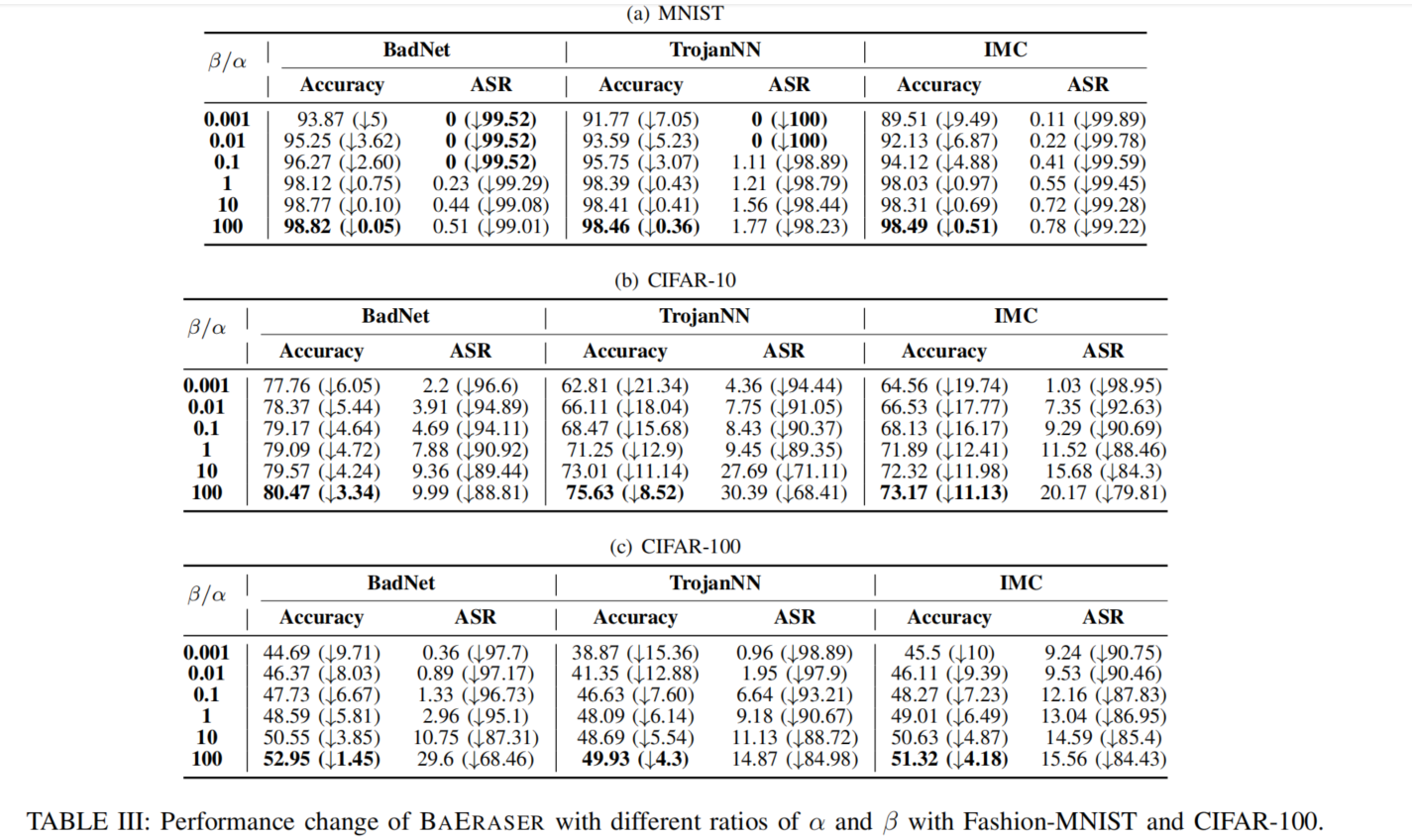
On the one hand, when the ratio is chosen to be a very small value (0*.*0001), the penalty item is approximately canceled, so that ASR can be lowered to almost 0% but more than 10% Acc drop (catastrophic forgetting) is introduced. On the other hand, the penalty item plays a major role and the Acc drop is well controlled when β/α reaches 100.
Visualization of Recovered Triggers
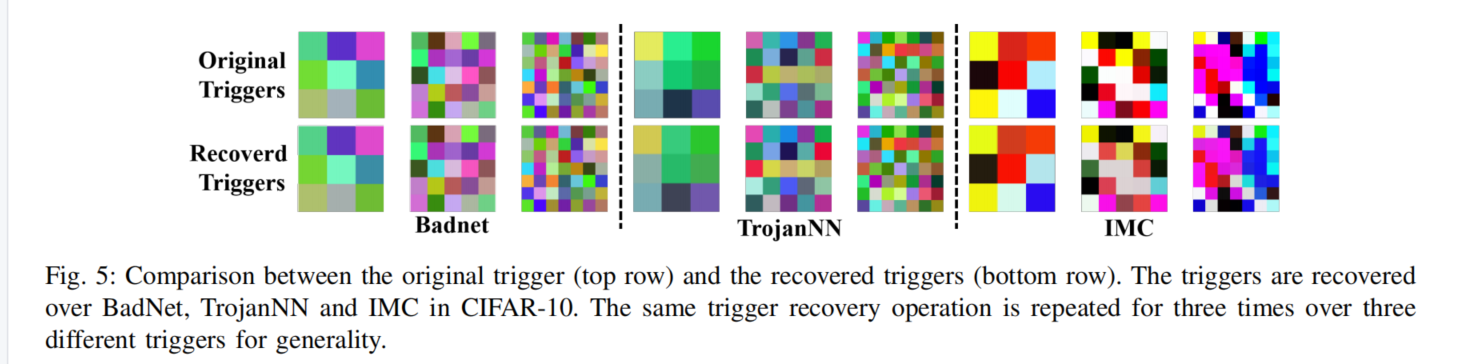
Although the patterns of recovered triggers have a difference with the original trigger, the difference for most pixels is negligible
Understanding of Backdoor Unlearning

-
迭代次数少
-
backdoor unlearning is robust to the change of trigger positions
-
backdoor unlearning hardly affects correct memories
最后一张图使用正确的标签作为目标标签
In such a condition, backdoor unlearning does not mislead the victim model to unlearning the related memory. This is because the penalty mechanism of the backdoor unlearning loss (Eq. 4) in BAERASER can effectively restrain correct memory unlearning.















 687
687











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









