






openeuler部署
一、准备
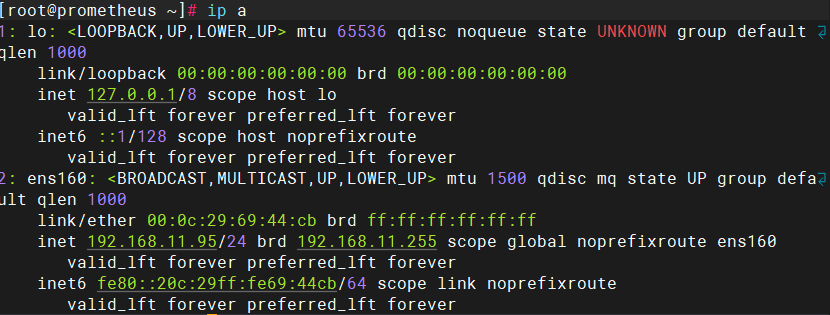
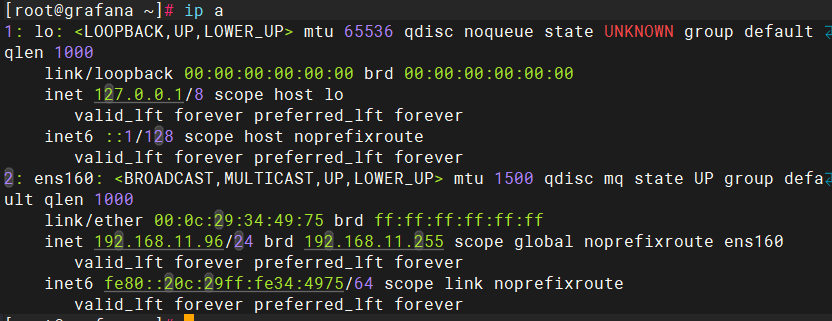
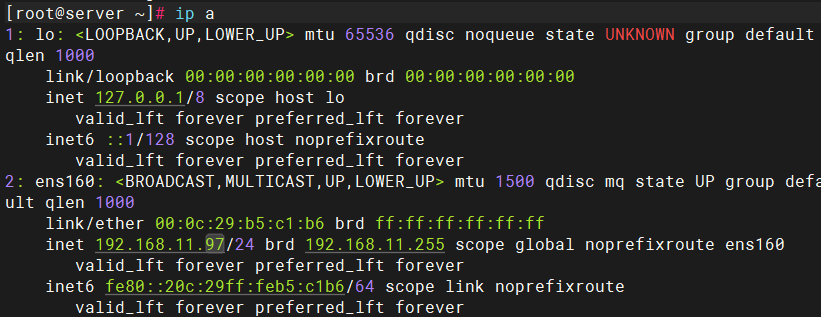
3台主机(1台安装prometheus、1台安装grafana、1台安装模拟业务)
均关闭防火墙与上下文
二、部署
prometheus
安装
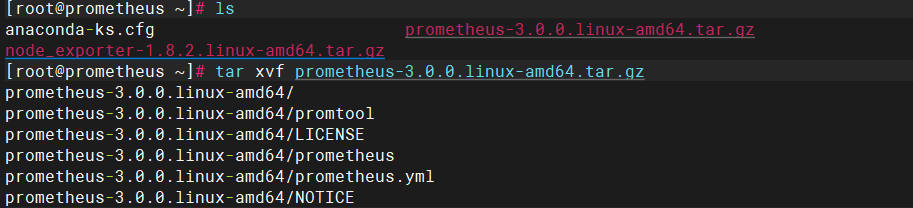

做链接命令

启动
[root@prometheus prom]# nohup prometheus --config.file=/usr/local/prom/prometheus.yml &
并在后台运行

访问
grafana
安装
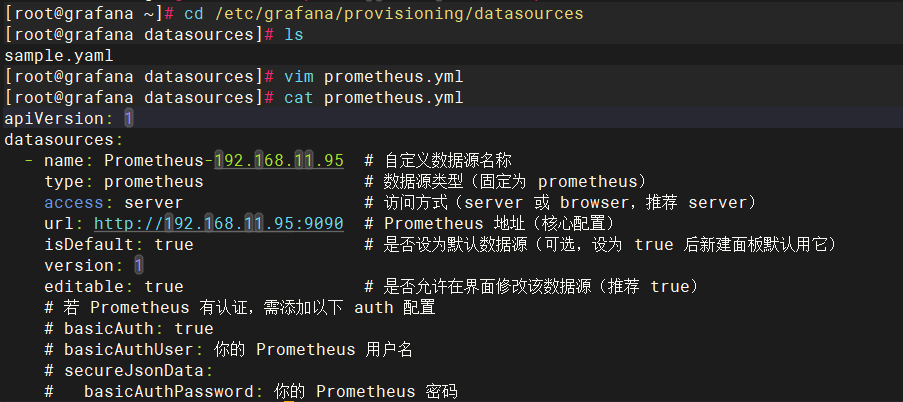
添加prometheus作为数据源
启动
systemctl enable --now grafana-server.service
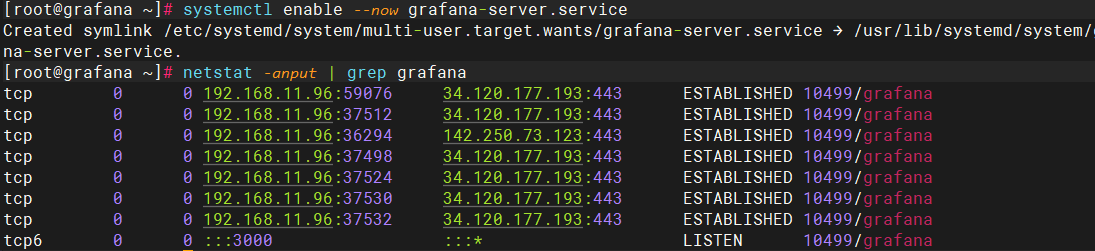
访问
初始用户密码默认admin/admin
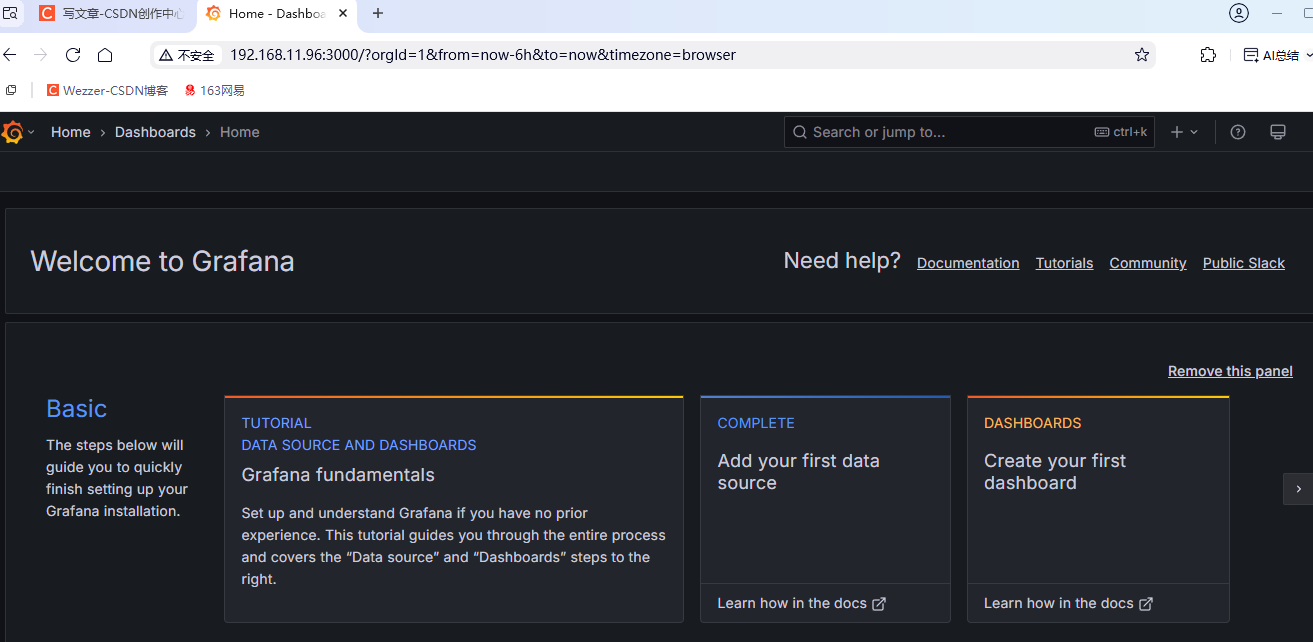
设置中文
exproter监控
监控prometheus主机
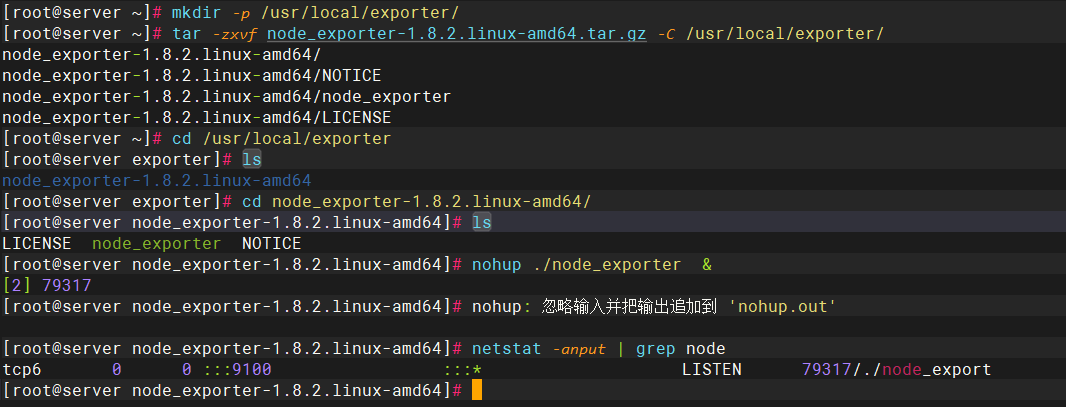
安装
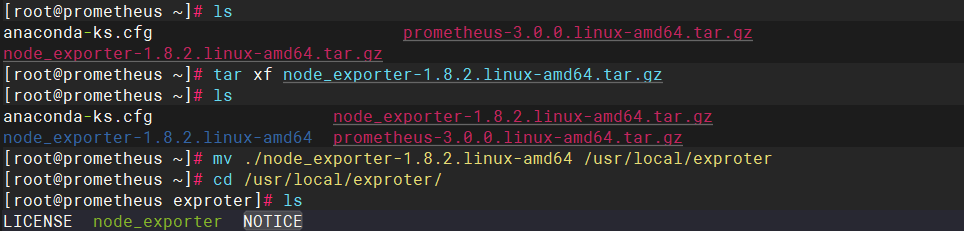
启动
[root@prometheus exproter]# nohup ./node_exporter &

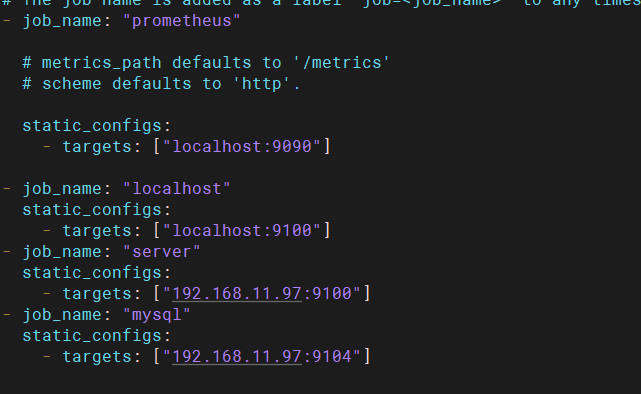
在prometheus添加任务
[root@prometheus prom]# vim prometheus.yml
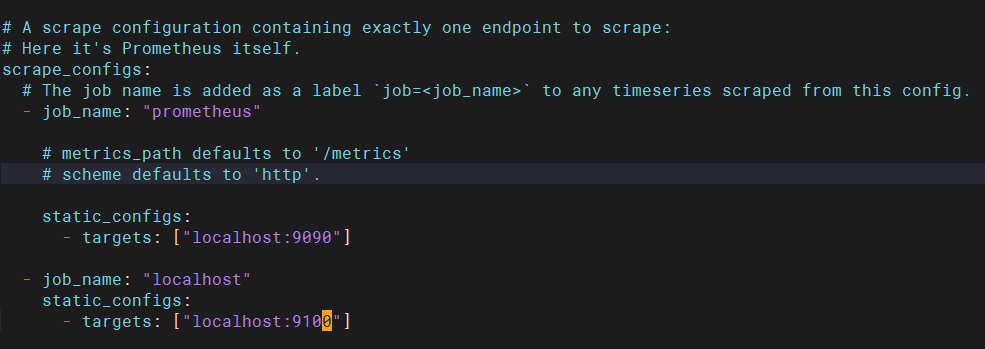
重启prometheus
[root@prometheus prom]# killall prometheus
[root@prometheus prom]# nohup prometheus --config.file=/usr/local/prom/prometheus.yml &

prometheus查看
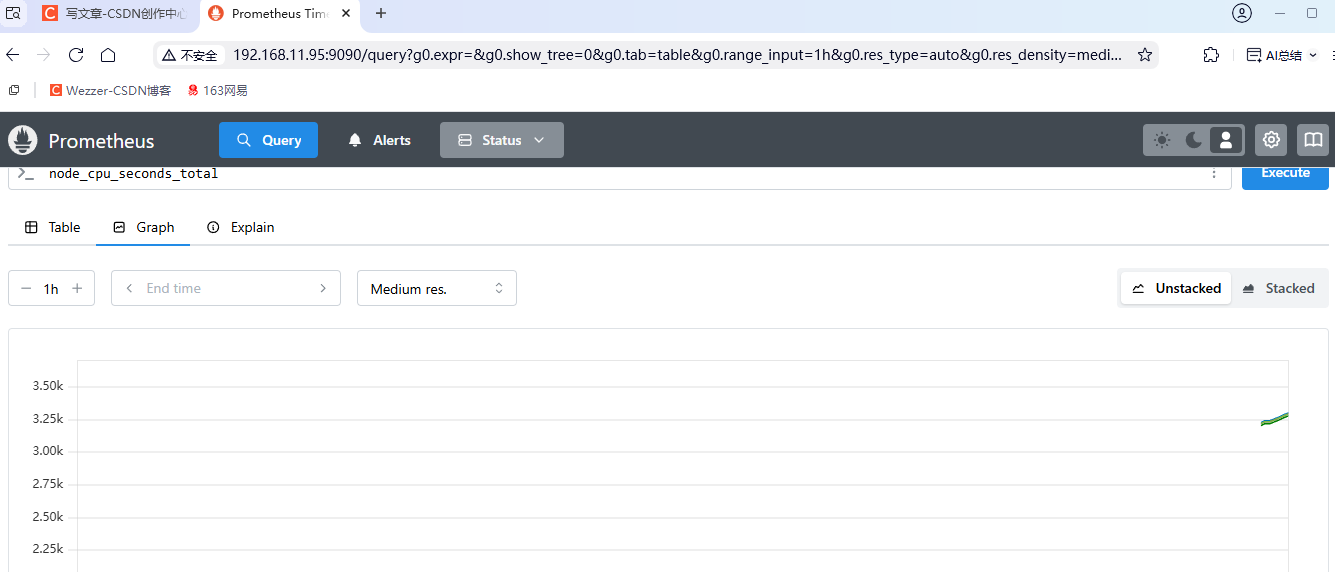
拉取的参数查看
http://192.168.11.95:9090/metrics
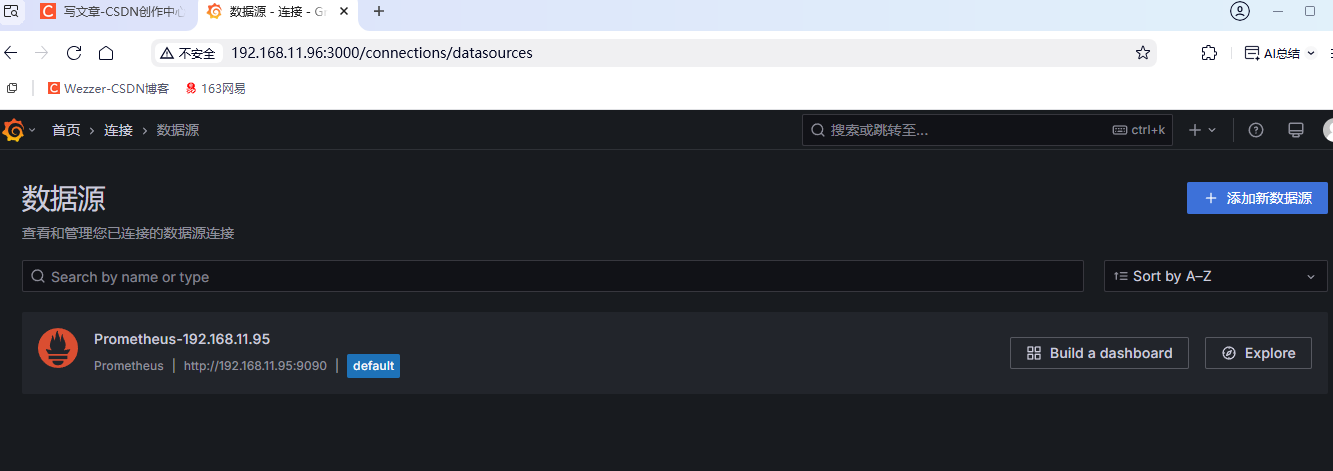
grafana查看
也可添加新数据源
新建仪表盘
可使用模板文件
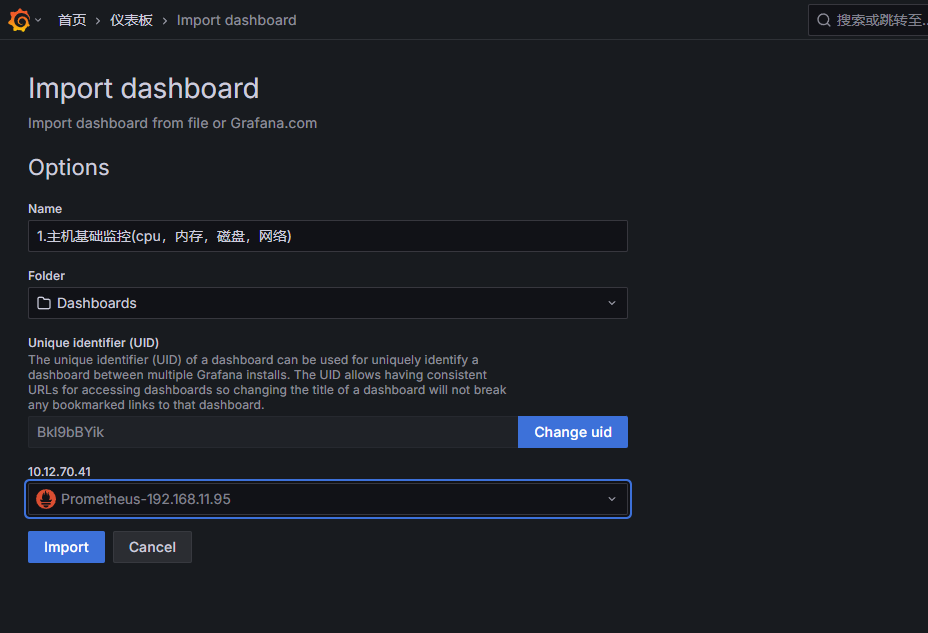
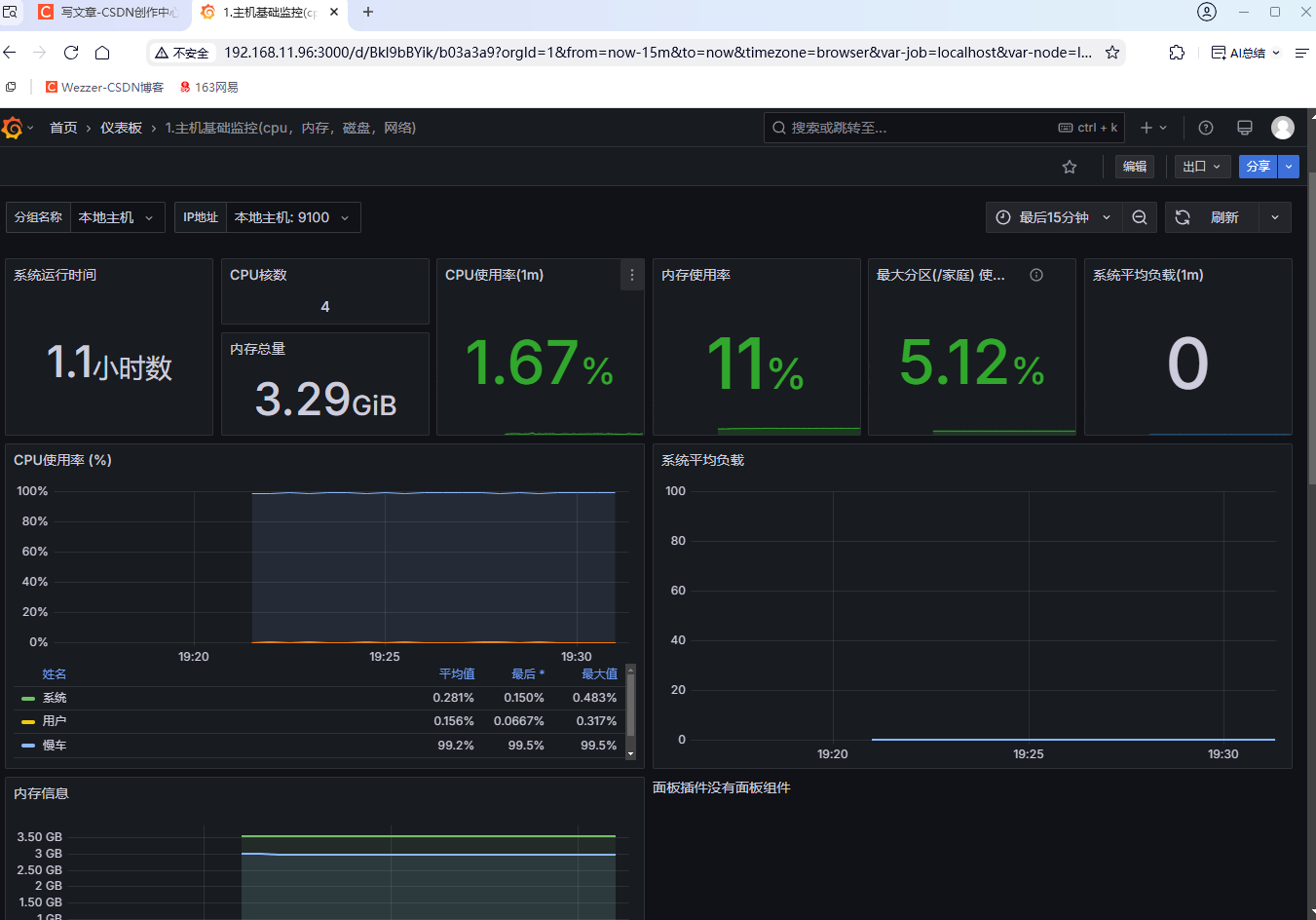
监控server服务端主机
使用exproter监控
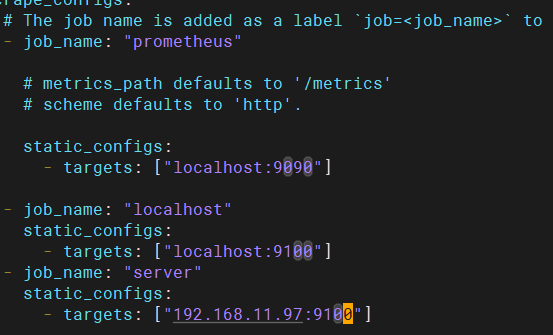
添加prometheus新任务
端口对应
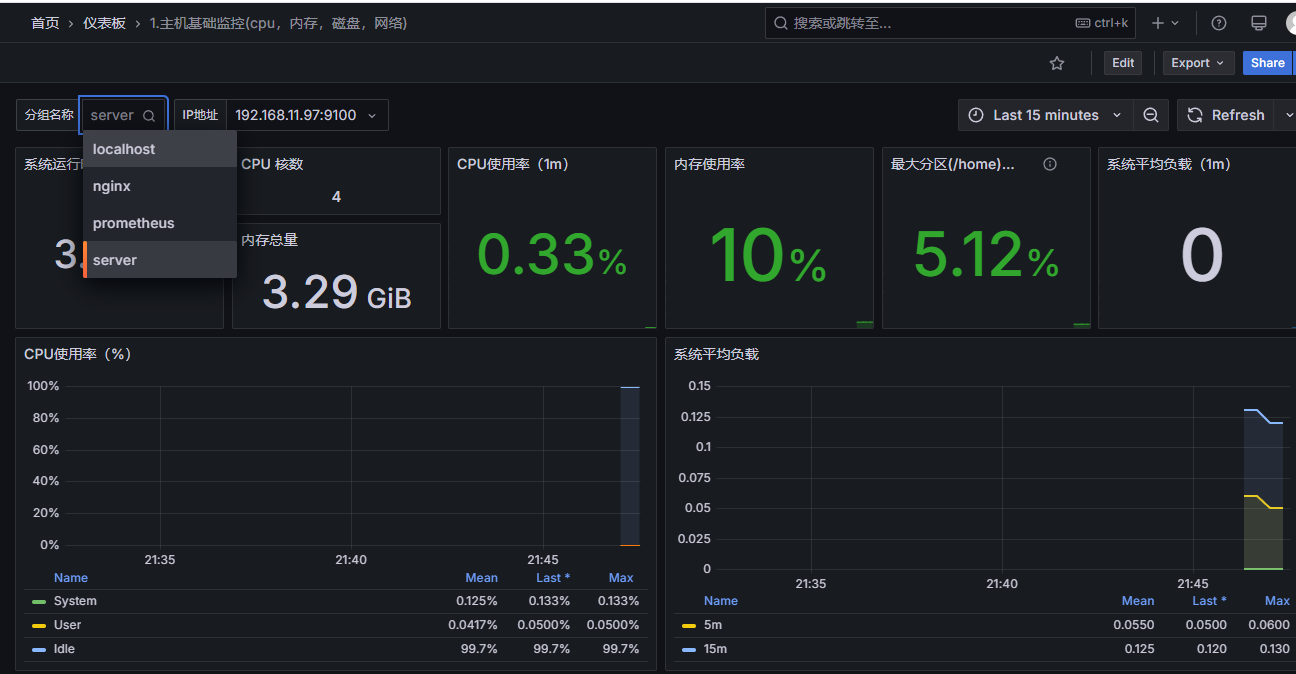
重启

grafana网页端
监控mysql服务
下载mysql服务
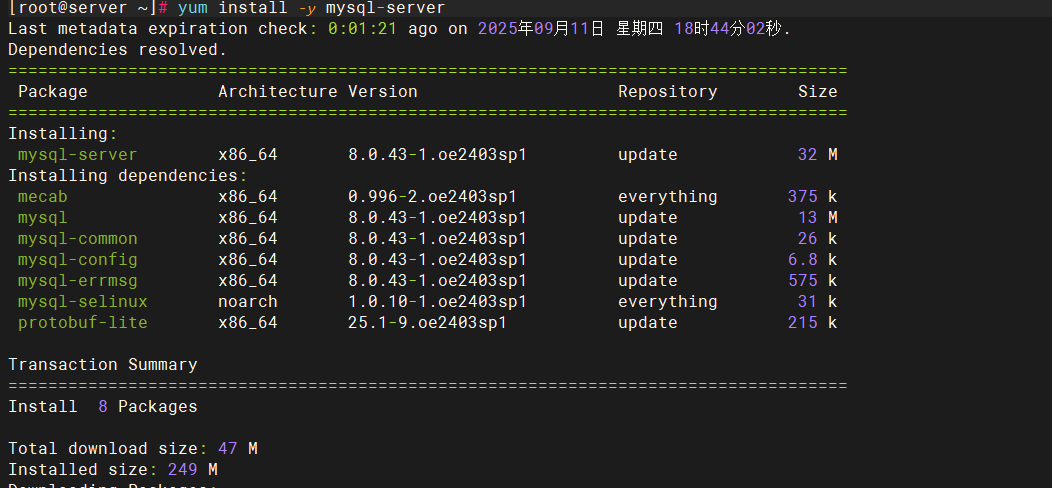
启动mysql服务
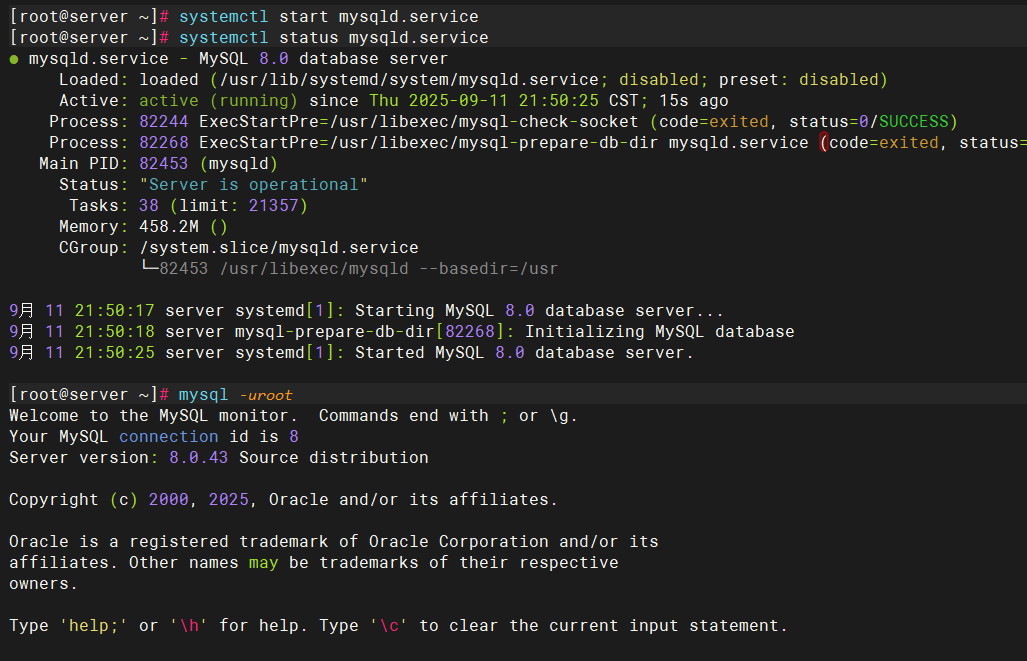
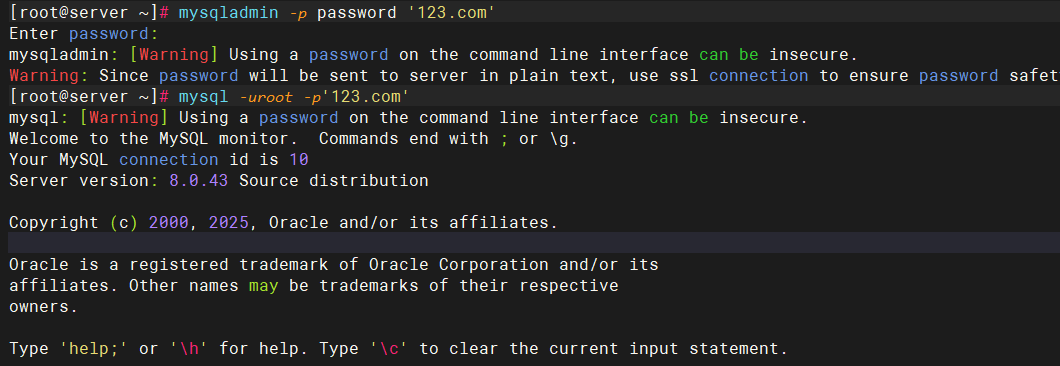
修改密码
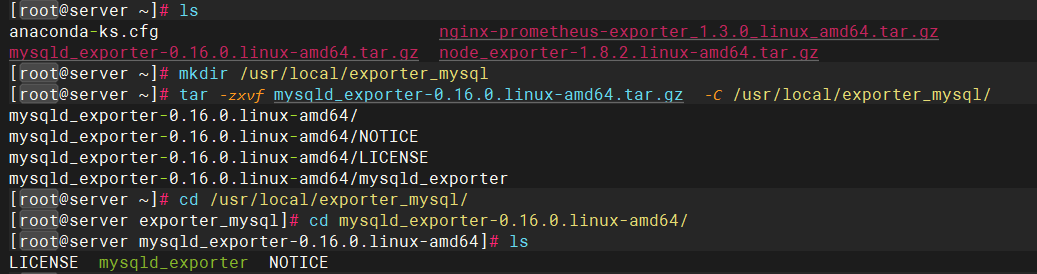
使用exproter模拟版
创建连接密码本

启动

创建prometheus新任务
重启

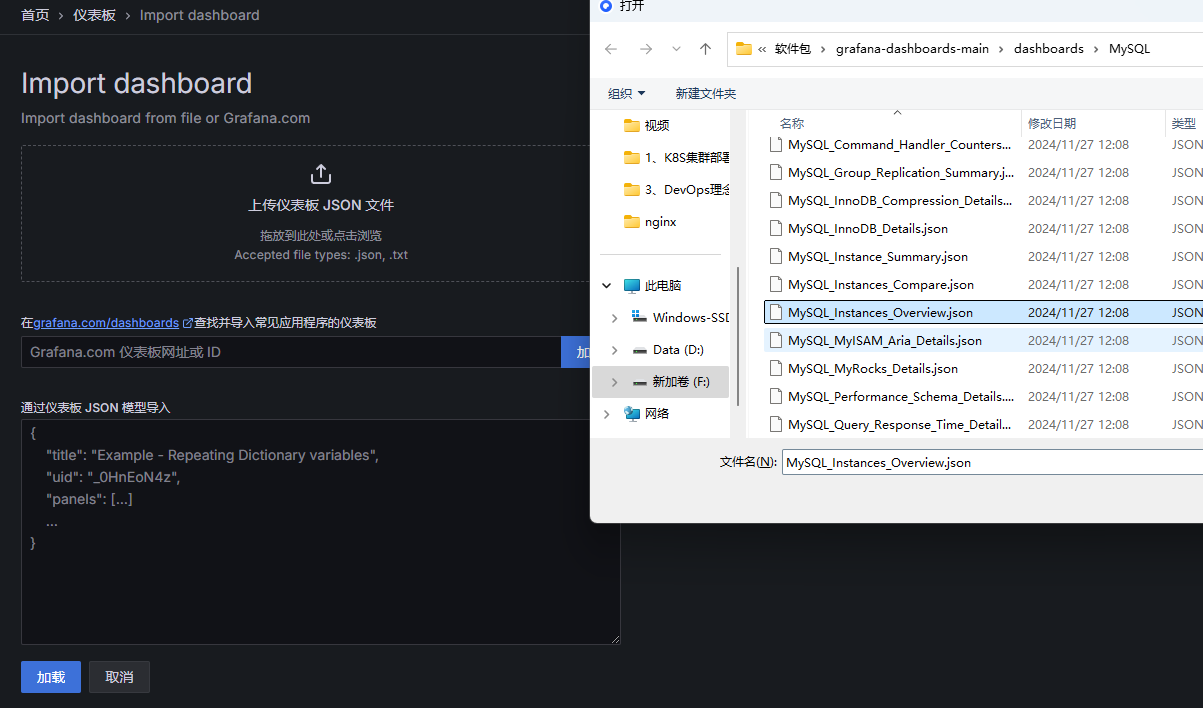
grafana网页导入 mysql图标模板
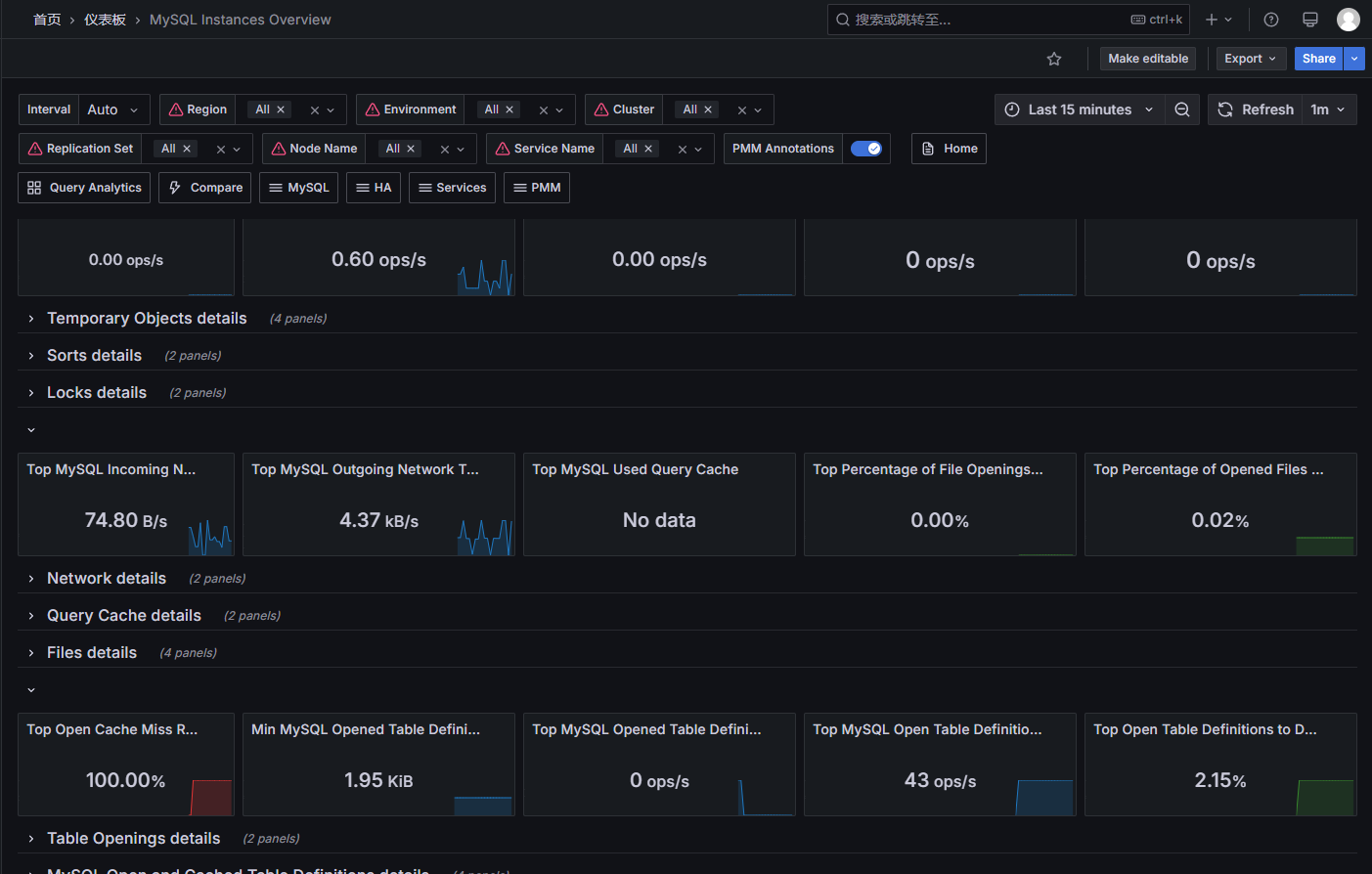
结果
监控报警
网易邮箱
开启smtp服务

使用alertmanager
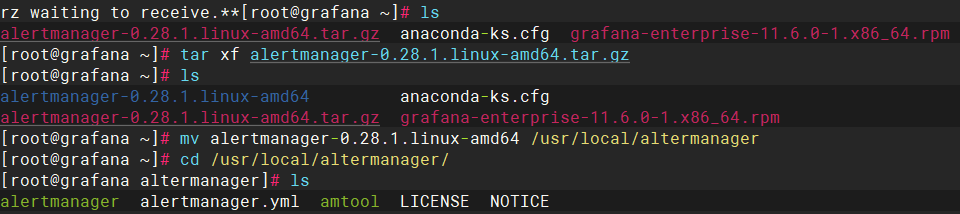
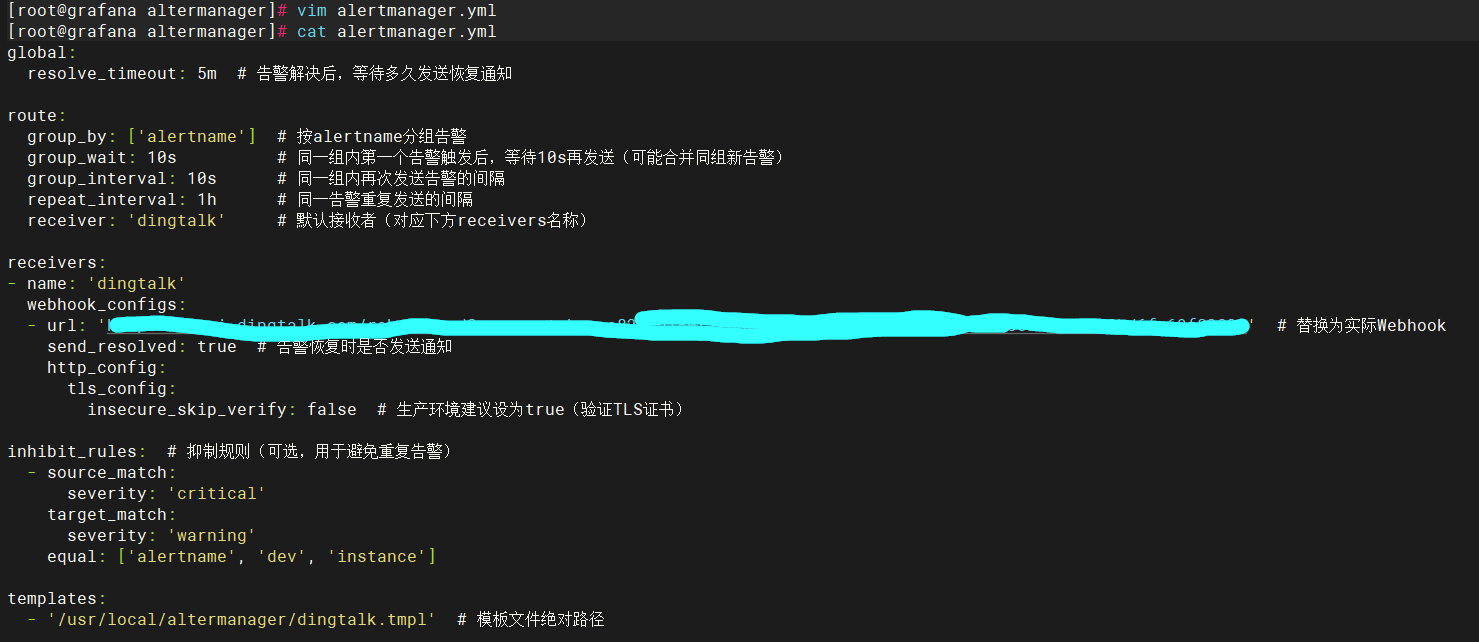
编写配置文件
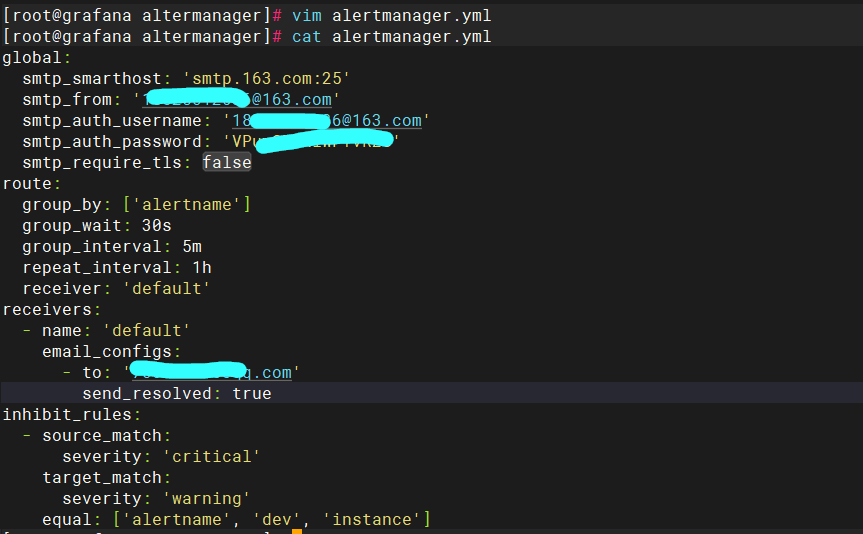
启动

修改prometheus
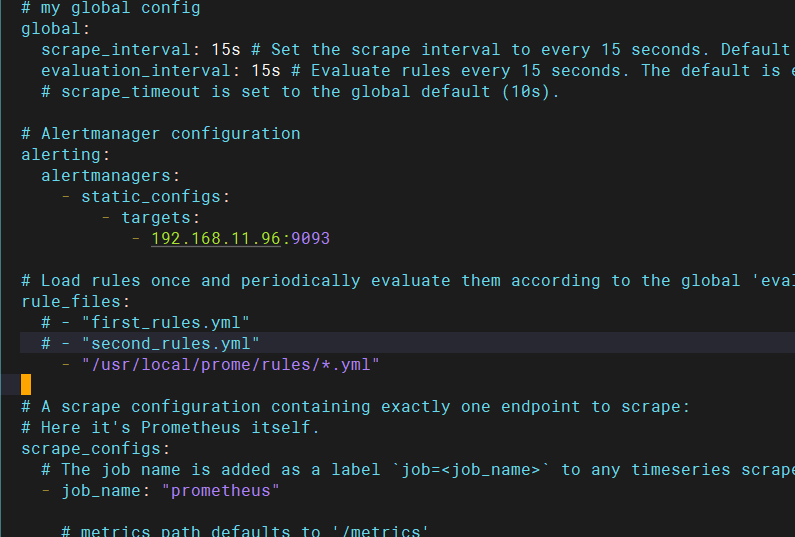
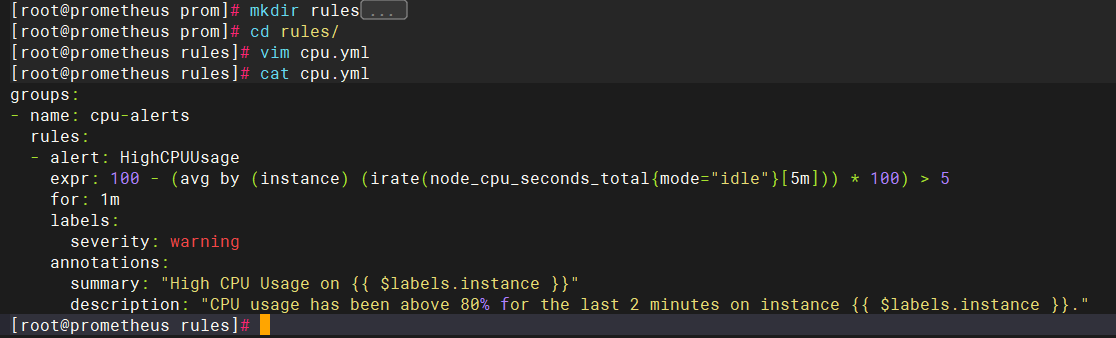
添加警告规则
重启prometheus
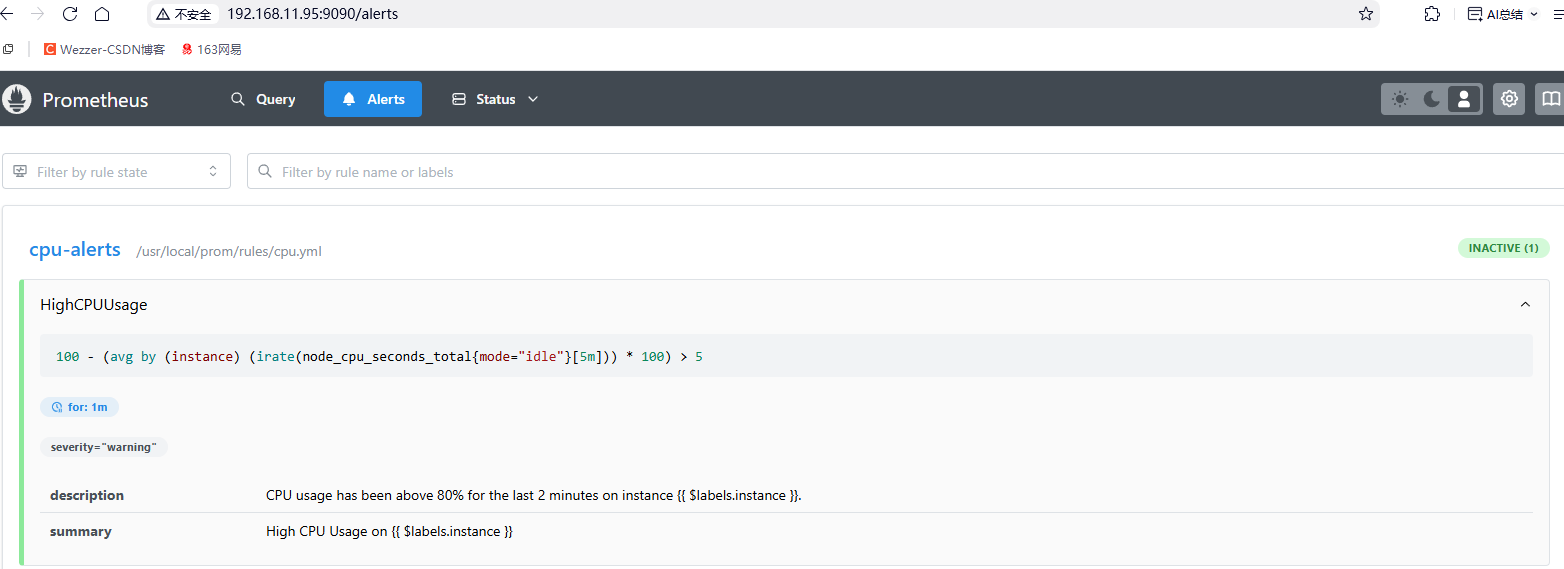
查看规则是否正常加载
模拟故障
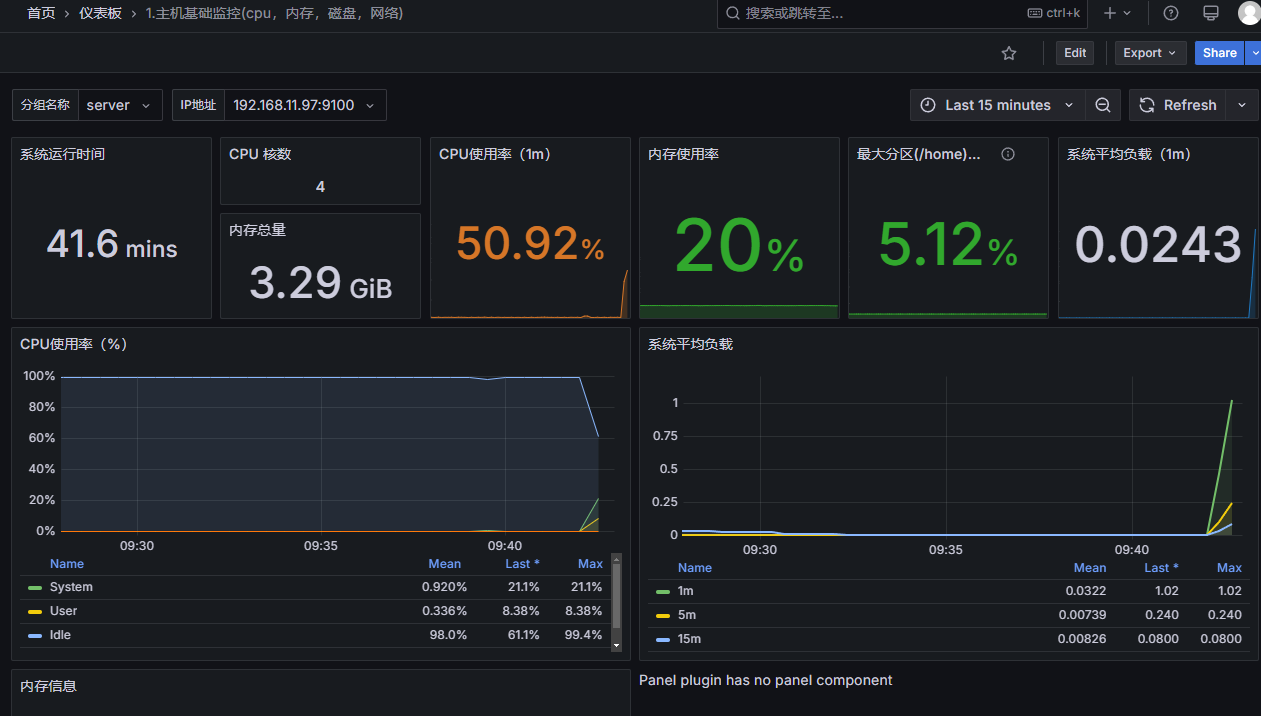
结果
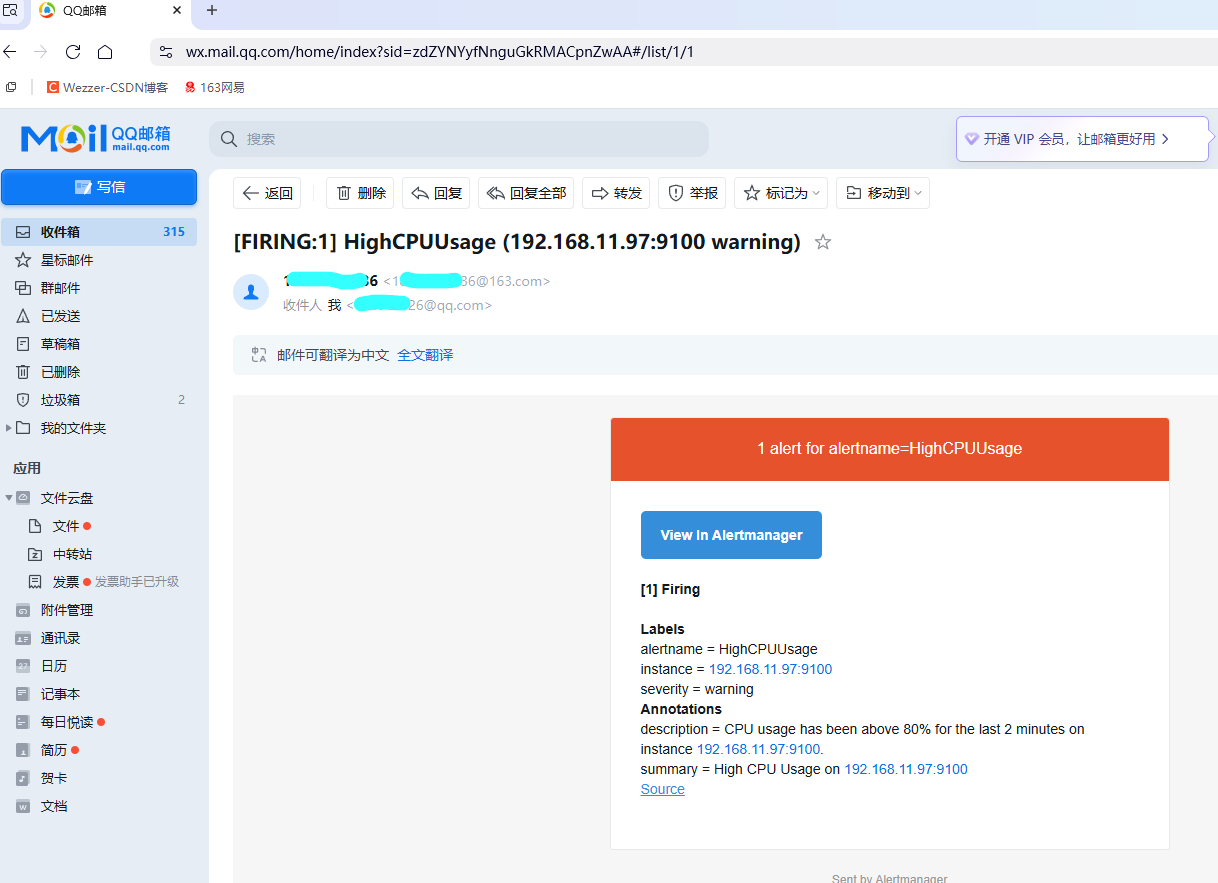
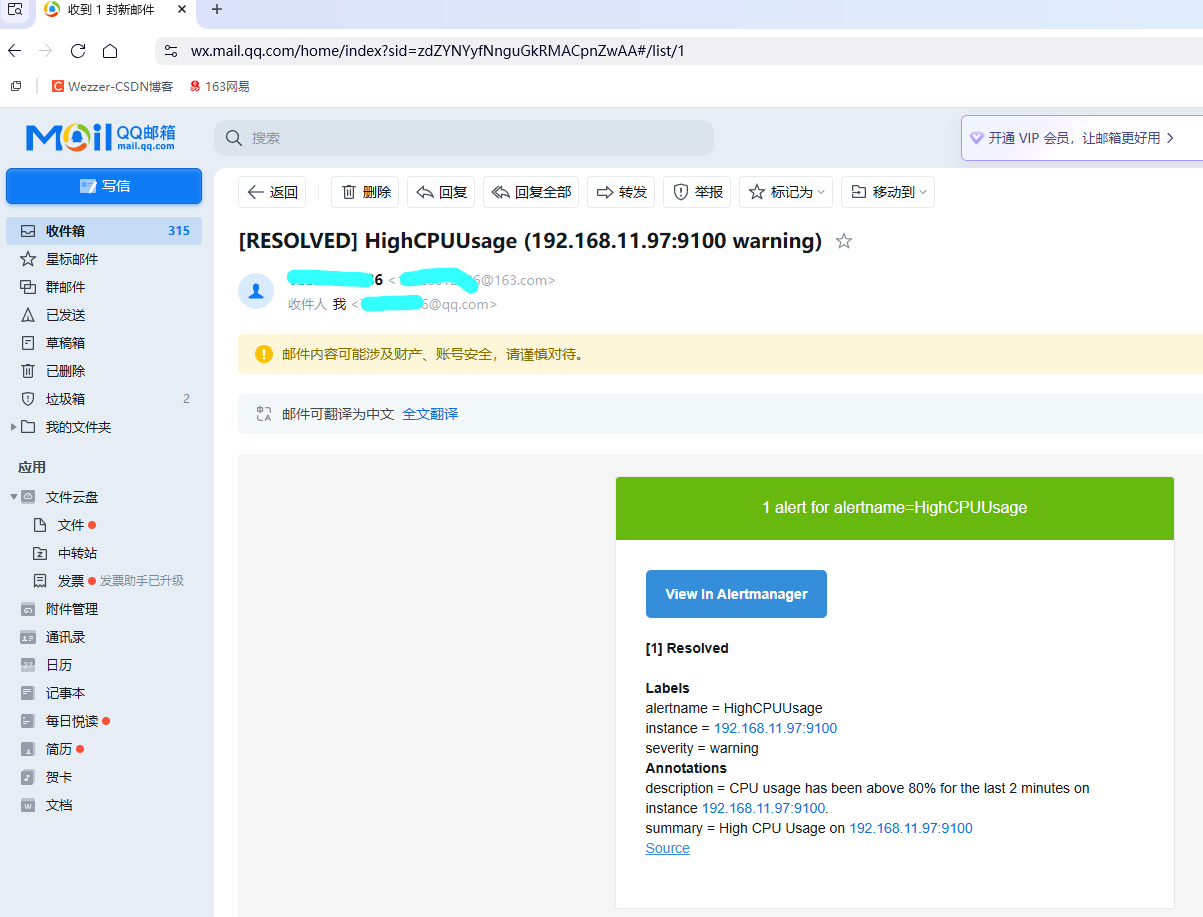
钉钉告警
alertmanage 配置文件失效 启动不了
curl -X POST "https://oapi.dingtalk.com/robot/send?access_token" \
-H "Content-Type: application/json" \
-d '{"msgtype":"markdown","markdown":{"title":"测试告警","text":"### 测试告警(告警)\n#### 详情:测试 关键词匹配"}}'
添加机器人
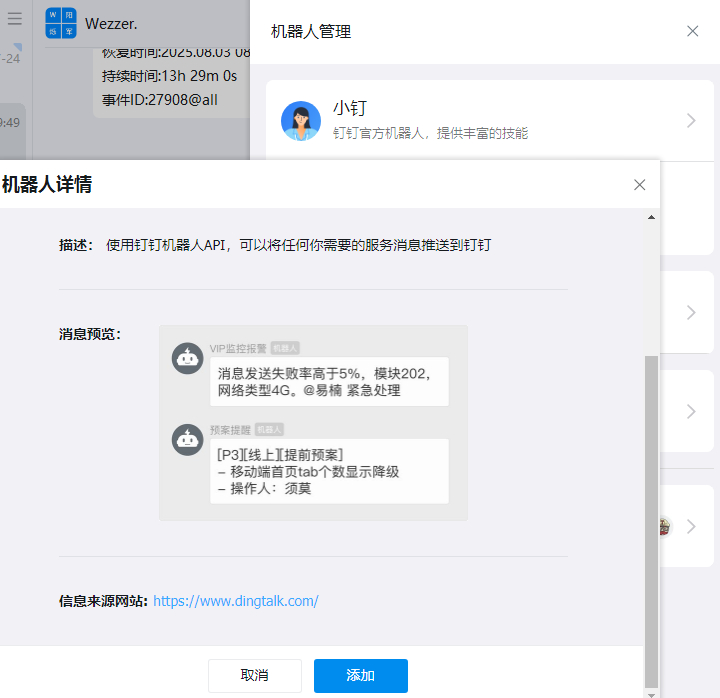
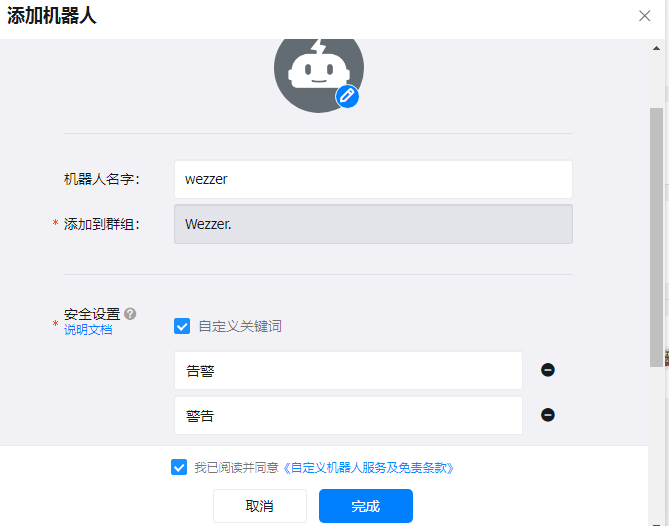
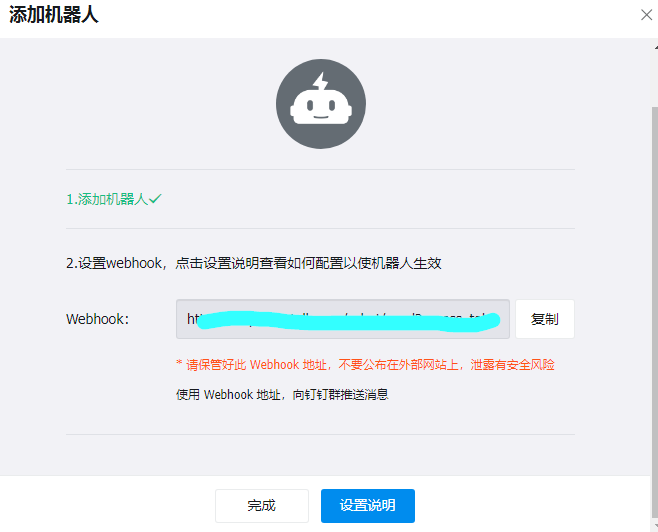
配置alertmanage
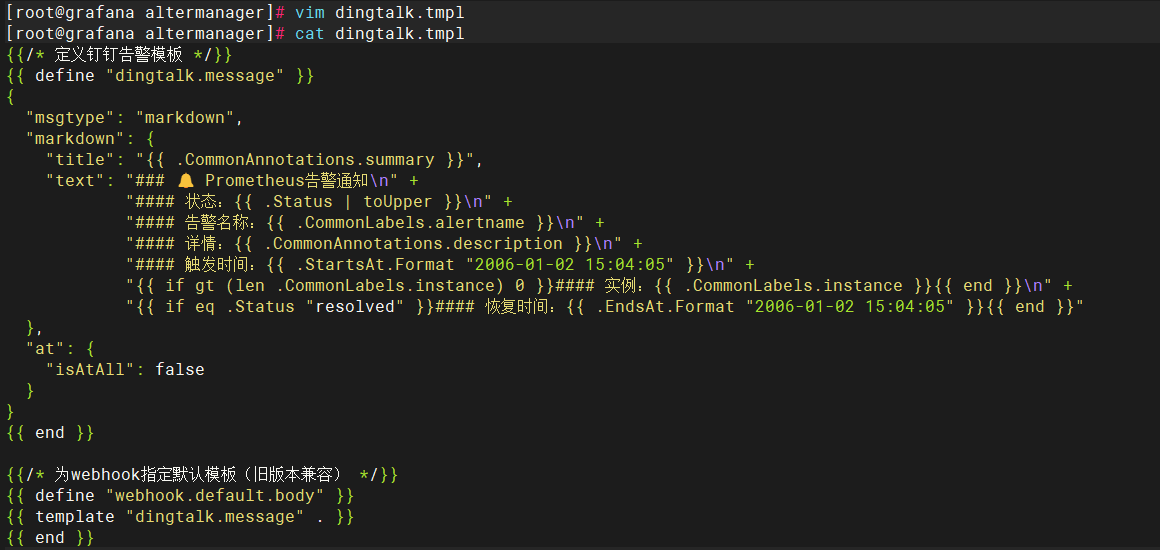
模板
启动 alertmanage

模拟故障

















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









