







 本文详细介绍了如何在多台服务器上部署Prometheus监控系统,包括Prometheus、Grafana、AlertManager、node_exporter、blackbox_exporter等组件的安装、配置和告警规则设定,涵盖了基础资源、端口、进程、数据库和Redis的监控及告警测试。
本文详细介绍了如何在多台服务器上部署Prometheus监控系统,包括Prometheus、Grafana、AlertManager、node_exporter、blackbox_exporter等组件的安装、配置和告警规则设定,涵盖了基础资源、端口、进程、数据库和Redis的监控及告警测试。
prometheus监控及告警
一、资源列表
| 主机 | IP | 系统版本 | 备注 |
|---|---|---|---|
| ccweb-1 | 10.0.13.72 | CentOS Linux release 7.5.1804 (Core) | prometheus监控端 |
| ccweb-2 | 10.0.13.73 | CentOS Linux release 7.5.1804 (Core) | prometheus被监控端 |
| ccweb-3 | 10.0.13.75 | CentOS Linux release 7.5.1804 (Core) | prometheus被监控端 |
1.结构说明
本次部署搭建大致结构为:
首先搭建prometheus监控端搭配grafana展示
部署node_export等监测工具进行信息采集
再将采集到的信息进行整理,由grafana展示出去
告警配置则采用altermanger组件进行告警
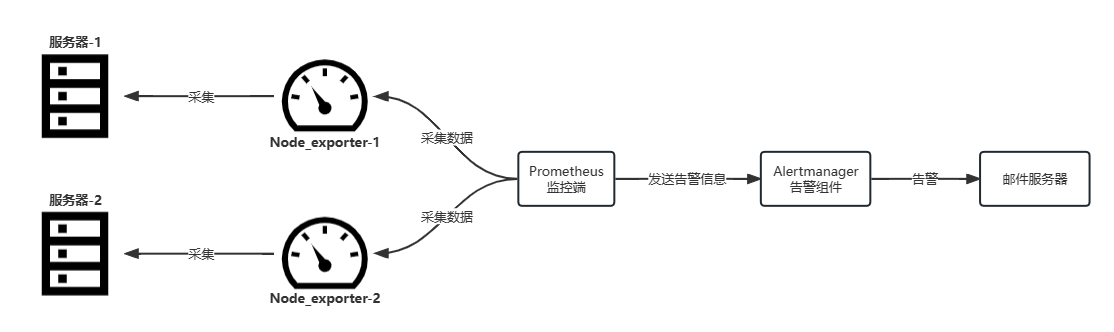
node_exporter采集器结构图:
node_exporter监测器部署在服务器上,Prometheus监控端调用服务器上的node_exporter监测器,将信息收集并展示,根据Prometheus上配置的阈值进行比较,若触发了阈值则调用alertmanager组件进行告警操作,alertmanager组件根据本身的配置,找到对应的邮件服务器,进行发送邮件的操作
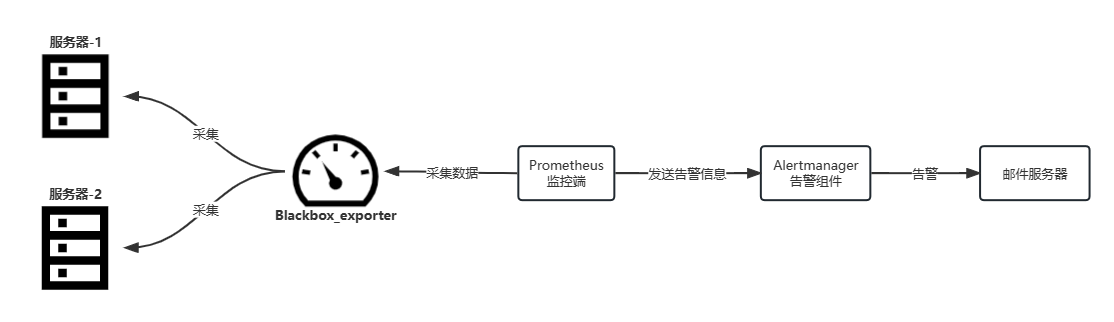
blackbox_exporter监测器结构图:
blackbox_exporter监测器与node_exporter监测器不同,blackbox_exporter监测器部署在任意服务器可以被调用即可,而node_exporter则要部署在被监控端内,其余原理均相同,只是采集方式不同
2.资源包下载
版本信息:
Prometheus版本:prometheus-2.41.0.linux-amd64
Grafana版本:grafana-9.3.6.linux-amd64
Altermanger版本:alertmanager-0.25.0.linux-amd64
Node_exporter版本:node_exporter-1.5.0.linux-amd64
Blackbox_exporter版本:blackbox_exporter-0.22.0.linux-amd64
Process_exporter版本:process-exporter-0.7.10.linux-amd64
Mysql_exporter版本:mysqld_exporter-0.14.0.linux-amd64
Redis_exporter版本:redis_exporter-v1.48.0.linux-amd64
prometheus-2.41.0.linux-amd64.tar.gz官网下载地址:
https://github.com/prometheus/prometheus/releases/download/v2.41.0/prometheus-2.41.0.linux-amd64.tar.gz
Alertmanager-0.25.0.linux-amd64.tar.gz官网下载地址:
https://github.com/prometheus/alertmanager/releases/download/v0.25.0/alertmanager-0.25.0.linux-amd64.tar.gz
Grafana-9.3.6.linux-amd64.tar.gz官网下载地址:
https://dl.grafana.com/oss/release/grafana-9.3.6.linux-amd64.tar.gz
Node_exporter-1.5.0.linux-amd64.tar.gz官网下载地址:
https://github.com/prometheus/node_exporter/releases/download/v1.5.0/node_exporter-1.5.0.linux-amd64.tar.gz
Blackbox_exporter-0.22.0.linux-amd64.tar.gz官网下载地址:
https://github.com/prometheus/blackbox_exporter/releases/download/v0.22.0/blackbox_exporter-0.22.0.linux-amd64.tar.gz
Process-exporter-0.7.10.linux-amd64.tar.gz官网下载地址:
https://github.com/ncabatoff/process-exporter/releases/download/v0.7.10/process-exporter-0.7.10.linux-amd64.tar.gz
Mysqld_exporter-0.14.0.linux-amd64.tar.gz官网下载地址:
https://github.com/prometheus/mysqld_exporter/releases/download/v0.14.0/mysqld_exporter-0.14.0.linux-amd64.tar.gz
Redis_exporter-v1.48.0.linux-amd64.tar.gz官网下载地址:
https://github.com/oliver006/redis_exporter/releases/download/v1.48.0/redis_exporter-v1.48.0.linux-amd64.tar.gz
以上下载连接访问慢,或无法下载可使用以下下载方式:
prometheus-2.41.0.linux-amd64.tar.gz下载地址:
链接:https://pan.baidu.com/s/1_4opyPxdELHLs0PE9UeLNQ?pwd=zska
提取码:zskaAlertmanager-0.25.0.linux-amd64.tar.gz下载地址:
链接:https://pan.baidu.com/s/1veMdroz3R3mIseW7UGzdQg?pwd=zska
提取码:zskaGrafana-9.3.6.linux-amd64.tar.gz下载地址:
链接:https://pan.baidu.com/s/1m6qOnEhuGZ6Q-JjlTm5sLw?pwd=zska
提取码:zskaNode_exporter-1.5.0.linux-amd64.tar.gz下载地址:
链接:https://pan.baidu.com/s/1IN7dfF7DMm6QpUR7yFEFBg?pwd=zska
提取码:zskaBlackbox_exporter-0.22.0.linux-amd64.tar.gz下载地址:
链接:https://pan.baidu.com/s/1b94funik-jckcPjJX6cOZA?pwd=zska
提取码:zskaProcess-exporter-0.7.10.linux-amd64.tar.gz下载地址:
链接:https://pan.baidu.com/s/17DBFbRVHSwWcvWLJ8LM3fg?pwd=zska
提取码:zskaMysqld_exporter-0.14.0.linux-amd64.tar.gz下载地址:
链接:https://pan.baidu.com/s/14tk7Puz4brsIThb1DgXrKg?pwd=zska
提取码:zskaRedis_exporter-v1.48.0.linux-amd64.tar.gz下载地址:
链接:https://pan.baidu.com/s/10uL5Wa3EVJIWFG01-Vd7AQ?pwd=zska
提取码:zska
二、服务部署
服务器列表
| 主机名 | IP | 系统版本 |
|---|---|---|
| ccweb-1 | 10.0.13.72 | CentOS Linux release 7.5.1804 (Core) |
| ccweb-2 | 10.0.13.73 | CentOS Linux release 7.5.1804 (Core) |
| ccweb-3 | 10.0.13.75 | CentOS Linux release 7.5.1804 (Core) |
1.部署Prometheus
prometheus监控端只需部署在一台上,有高可用需求则可以部署两台使用nginx代理出去
prometheus部署在:
| 主机名 | IP | 系统版本 |
|---|---|---|
| ccweb-1 | 10.0.13.72 | CentOS Linux release 7.5.1804 (Core) |
提前将prometheus-2.41.0.linux-amd64.tar.gz下载并上传至服务器

1.1解压
#创建目录,推荐安装到磁盘空间充足目录内
mkdir -p /data/monitor
#解压Prometheus至/data/monitor目录内
tar -zxvf prometheus-2.41.0.linux-amd64.tar.gz -C /data/monitor/
#切换工作目录
cd /data/monitor/
#改名,方便后续操作
mv prometheus-2.41.0.linux-amd64/ prometheus
#切换工作目录
cd /data/monitor/prometheus
#创建存储目录
mkdir data
1.2配置system管理
#编写配置,注意以下配置项以实际安装目录为准:
#ExecStart后是Prometheus的执行文件
#storage.tsdb.path后是Prometheus存储目录
#config.file后是Prometheus的配置文件位置
cat >> /usr/lib/systemd/system/prometheus.service << EOF
[Unit]
Description=https://prometheus.io
[Service]
Restart=on-failure
ExecStart=/data/monitor/prometheus/prometheus --storage.tsdb.path=/data/monitor/prometheus/data --config.file=/data/monitor/prometheus/prometheus.yml
[Install]
WantedBy=multi-user.target
EOF
#启动服务并查看启动状态
systemctl start prometheus && systemctl status prometheus
#服务各类操作
#启动Prometheus
systemctl start prometheus
#停止Prometheus
systemctl stop prometheus
#查看启动状态
systemctl status prometheus
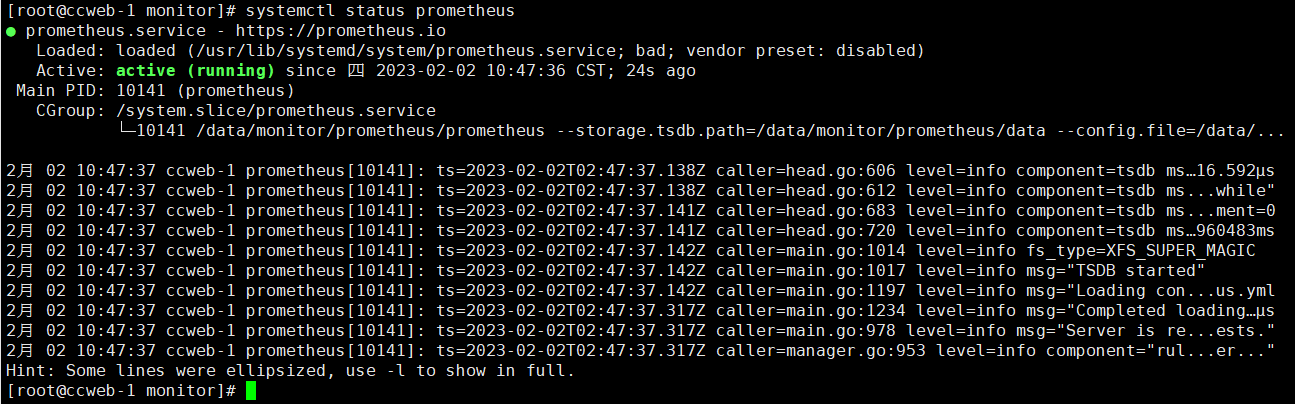
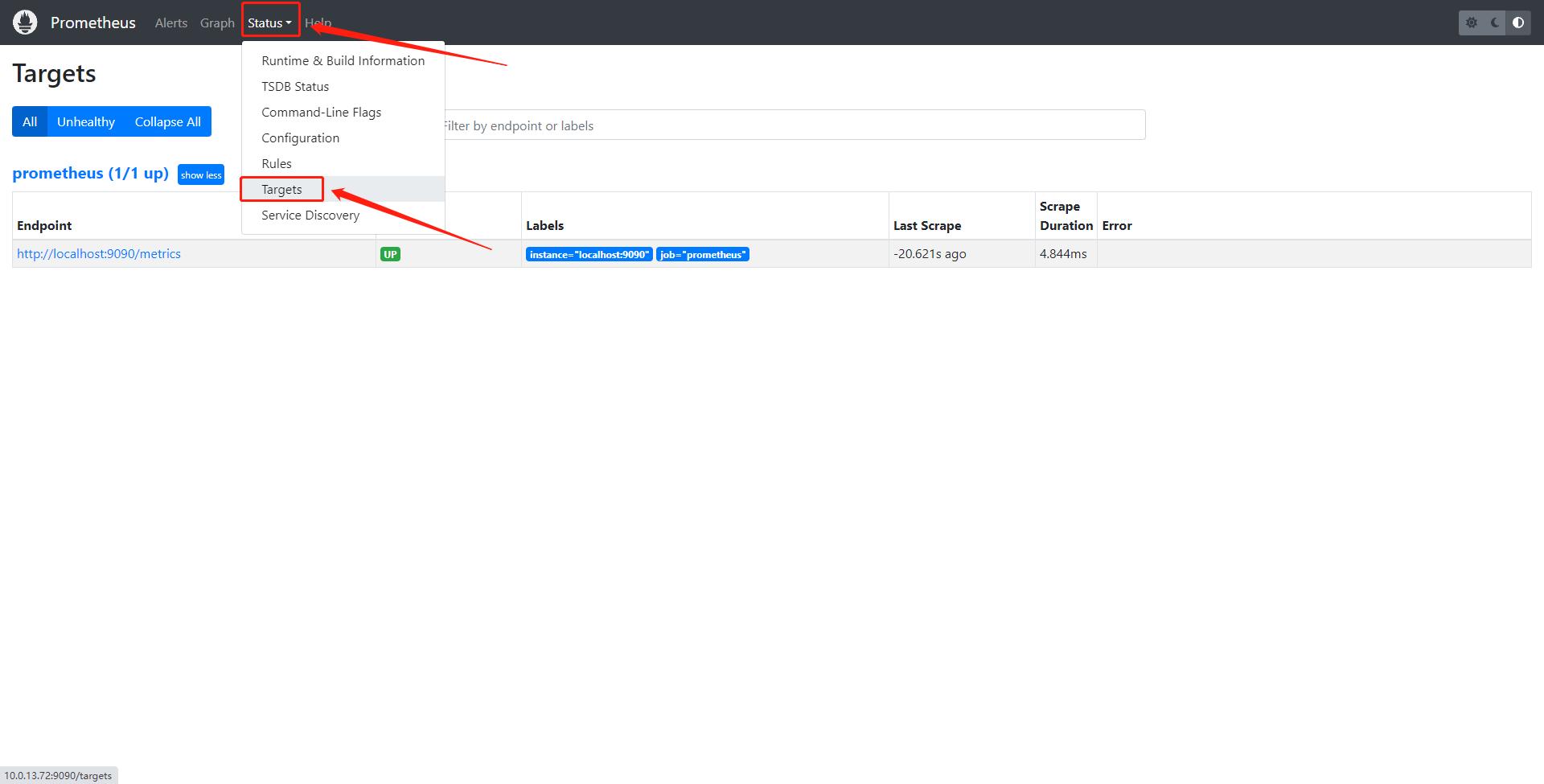
未更改端口情况下,浏览器访问http://localhost:9090
点击Status–>Targets即可获取对应监控信息,默认只有本机
2.部署Grafana
Grafana用来给prometheus做监控页面,弥补prometheus页面‘丑’的缺点
通常与prometheus部署在一台服务器上
| 主机名 | IP | 系统版本 |
|---|---|---|
| ccweb-1 | 10.0.13.72 | CentOS Linux release 7.5.1804 (Core) |
提前将Grafana-9.3.6.linux-amd64.tar.gz下载并上传至服务器

2.1解压
#解压grafana到指定目录下
tar -zxvf grafana-9.3.6.linux-amd64.tar.gz -C /data/monitor/
#切换工作目录
cd /data/monitor
#改名,可略过
mv grafana-9.3.6/ grafana
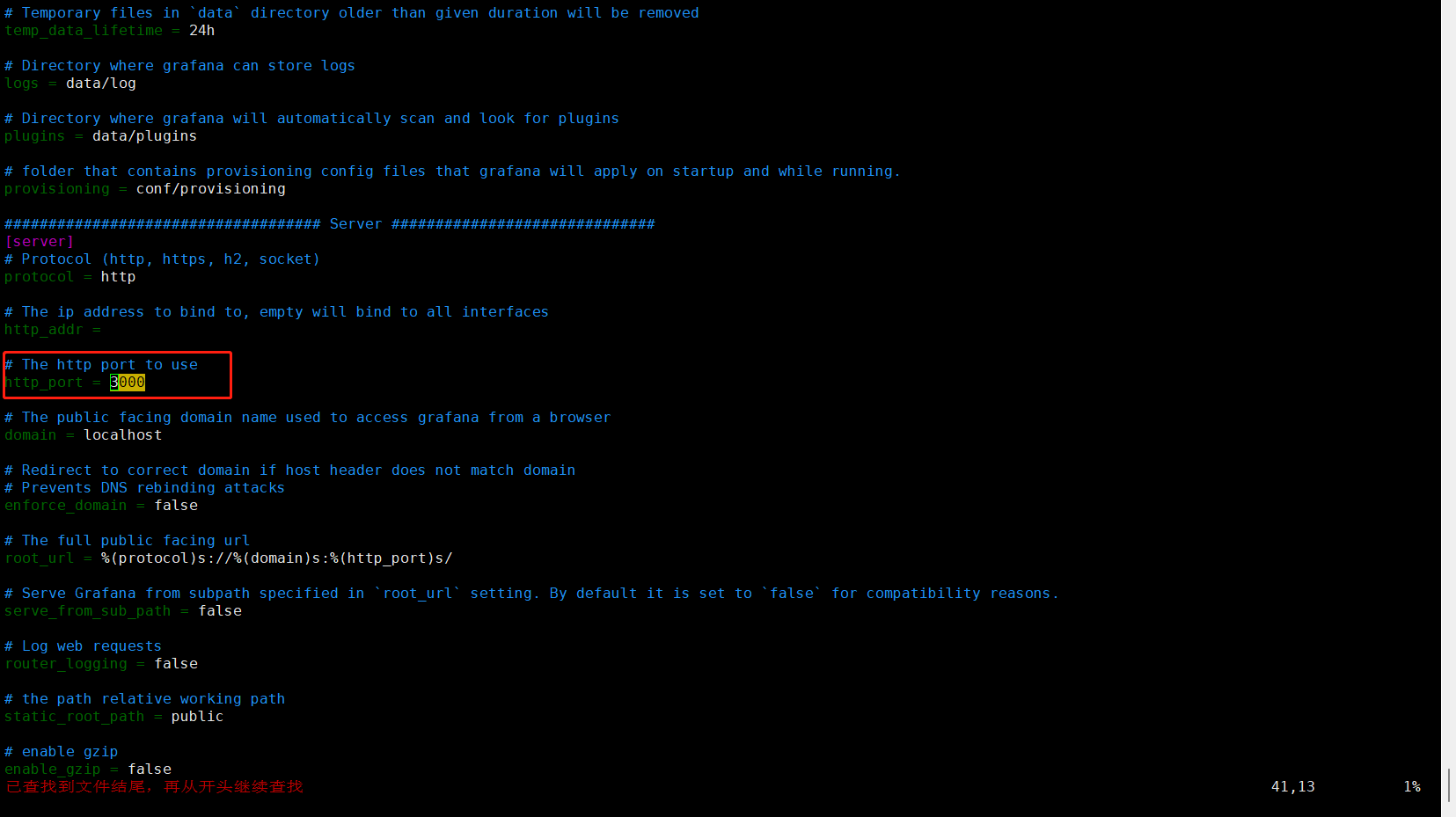
若有更改grafana默认端口的需求,编辑grafana/conf/defaults.ini,检索3000,更改http_port为自己想要的端口号即可
2.2配置system管理
cat >> /usr/lib/systemd/system/grafana.service << EOF
[Unit]
Description=Grafana
After=network.target
[Service]
ExecStart=/data/monitor/grafana/bin/grafana-server \
--config=/data/monitor/grafana/conf/defaults.ini \
--homepath=/data/monitor/grafana
[Install]
WantedBy=multi-user.target
EOF
#使配置生效
systemctl daemon-reload
#启动
systemctl start grafana
#验证
systemctl status grafana
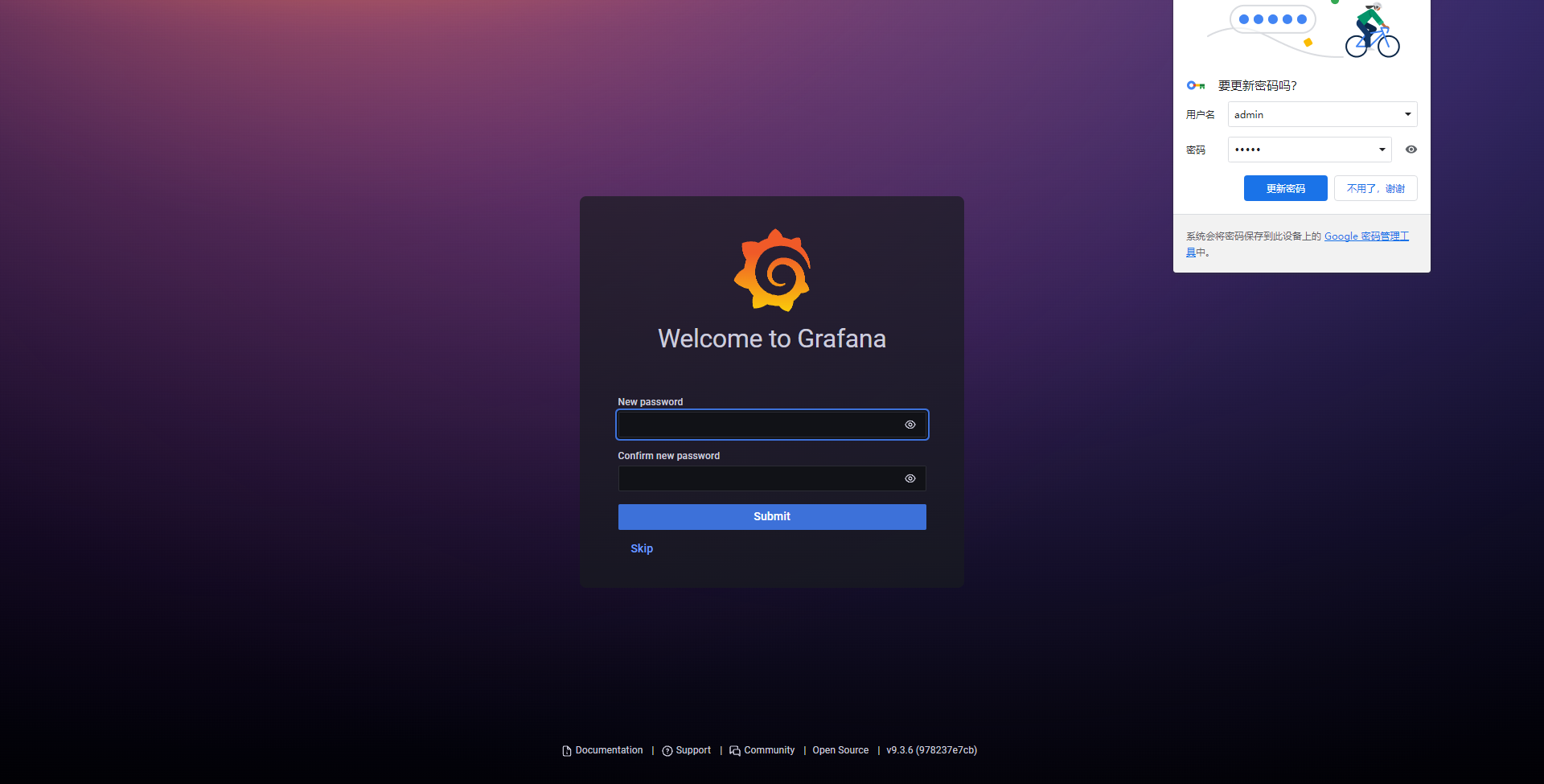
使用默认端口的情况下,浏览器访问http://localhost:3000
默认账号/密码:admin/admin
第一次登录会提示更改新的密码,可跳过也可设置
2.3配置grafana
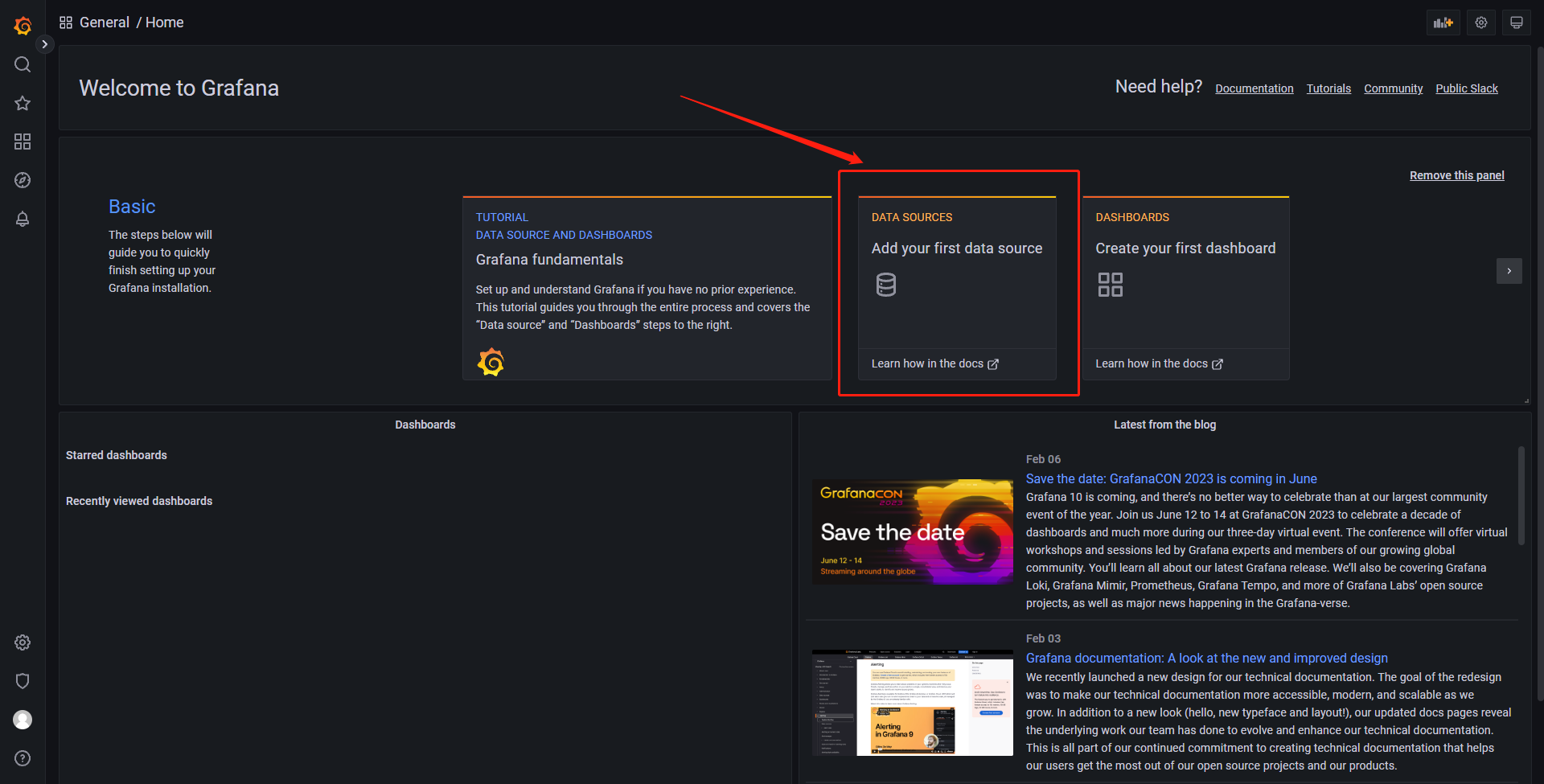
接下来需要在grafana页面上配置Prometheus的数据源,好让我们的grafana读取到Prometheus上的监控数据
点击首页内的‘DATA SOURCES’
选择‘Prometheus’
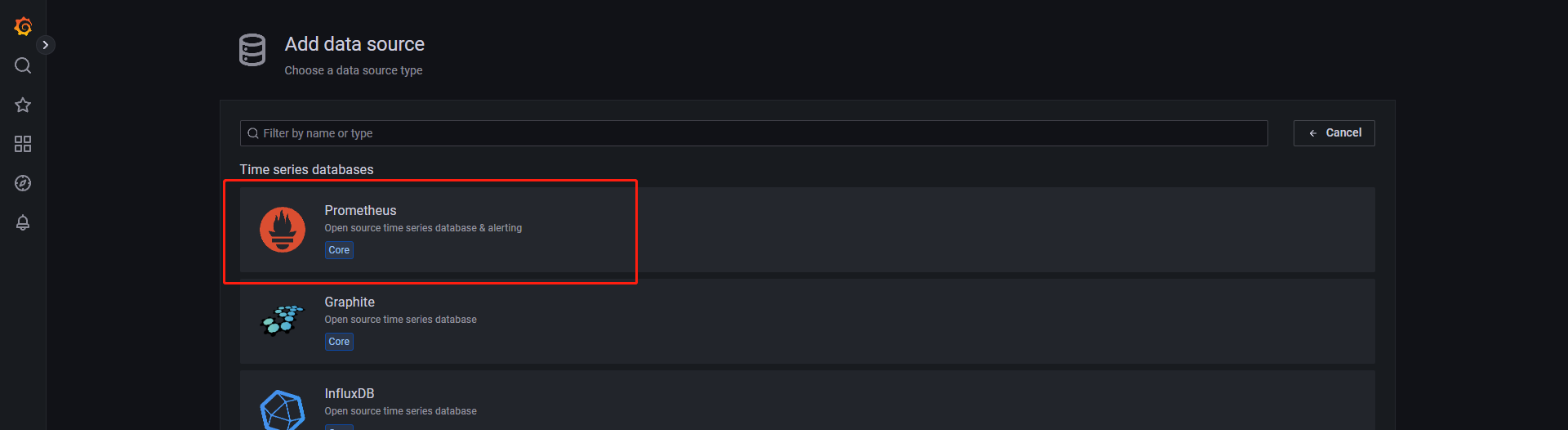
’Name‘可自定义,也就是这个数据源的名称
'URL’填写http://prometheus服务器ip:9090(端口以实际为准)
'HTTP method’改为GET
其他规则及选项根据个人需要进行配置即可
填写完毕后,点击下方‘Save & test’,会保存并测试连接
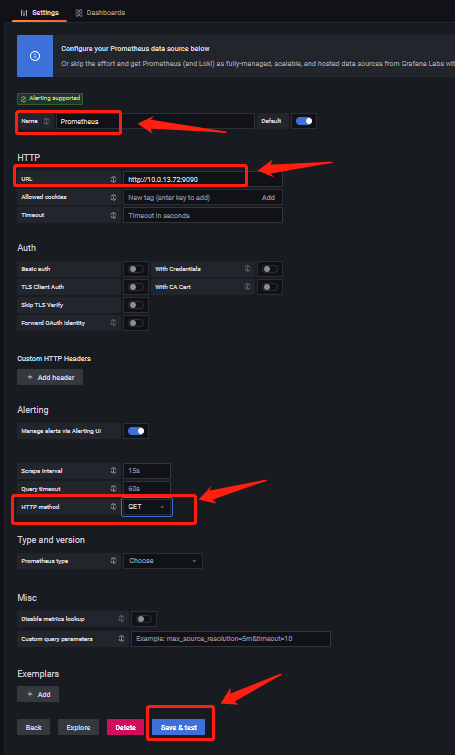
显示‘Data source is working’即连接成功
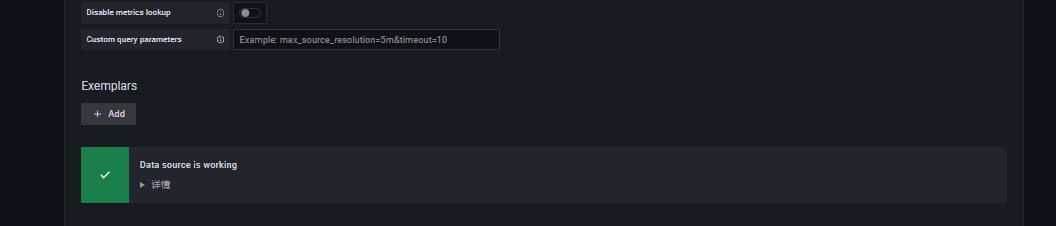
点击页面的‘设置按钮’—>'Data source’即可查看到我们刚刚建立的数据源
3.部署AlertManager
AlertManager为Prometheus采用的告警程序,它负责将重复数据删除,分组和路由到正确的接收者,通知方式有电子邮件、短信、微信等。
通常部署在Prometheus服务器上
| 主机名 | IP | 系统版本 |
|---|---|---|
| ccweb-1 | 10.0.13.72 | CentOS Linux release 7.5.1804 (Core) |
提前将Alertmanager-0.25.0.linux-amd64.tar.gz下载并上传至服务器

3.1解压
#解压到指定目录
tar -zxvf alertmanager-0.25.0.linux-amd64.tar.gz -C /data/monitor/
#切换工作目录
cd /data/monitor
#改名,可跳过
mv alertmanager-0.25.0.linux-amd64/ alertmanager
3.2配置
首先配置告警模板
#切换工作目录
cd /data/monitor/alertmanager
#添加配置
cat >> email.tmpl << EOF
{{ define "email.from" }}euphoria0926@163.com{{ end }}
{{ define "email.to" }}zhengshuo@utry.cn{{ end }}
{{ define "email.to.html" }}
{{ range .Alerts }}
=========start==========<br>
告警程序: prometheus_alert <br>
告警级别: {{ .Labels.severity }} 级 <br>
告警类型: {{ .Labels.alertname }} <br>
故障主机: {{ .Labels.instance }} <br>
告警主题: {{ .Annotations.summary }} <br>
告警详情: {{ .Annotations.description }} <br>
触发时间: {{ (.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }} <br>
=========end==========<br>
{{ end }}
{{ end }}
EOF
需要提前准备一个邮箱作为发送者,并需要开启SMTP/POP3/IAMP认证且记录授权码
#切换工作目录
cd /data/monitor/alertmanager
#注释配置文件所有行
sed -i 's/^#*/#/' alertmanager.yml
#导入配置
cat >> alertmanager.yml << EOF
global:
resolve_timeout: 5m
# 配置邮箱服务器
smtp_smarthost: 'smtp.163.com:25' # smtp地址
smtp_from: 'eupho*****@163.com' # 发送邮箱地址
smtp_auth_username: 'euph*****@163.com' # 发送邮箱用户名
smtp_auth_password: 'DCCFIY**********' # 邮箱授权码,不是邮箱密码
smtp_require_tls: false
templates:
- '/data/monitor/alertmanager/email.tmpl'
route:
group_by: ['alertname'] # 分组名
group_wait: 10s # 收到第一个告警后的等待时间,如果10s时间内再次收到告警,则2条告警合并发送
group_interval: 2m # 重新发送告警的间隔时间
repeat_interval: 2m # 重复告警的发送时间
receiver: 'mail'
# 接受人
receivers:
- name: 'mail'
email_configs:
- to: 'zh******8@ut**.cn' # 多个邮箱,用英文,隔开
html: '{{ template "email.to.html" . }}'
send_resolved: true
# 抑制规则
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
EOF
3.3配置system管理
cat >> /usr/lib/systemd/system/alertmanager.service << EOF
[Unit]
Description=alertmanager System
Documentation=alertmanager System
[Service]
ExecStart=/data/monitor/alertmanager/alertmanager --config.file=/data/monitor/alertmanager/alertmanager.yml
[Install]
WantedBy=multi-user.target
EOF
#使配置生效
systemctl daemon-reload
#启动
systemctl start alertmanager
#验证
systemctl status alertmanager
4.部署node_export
Node_export是一款专业的基础性能检测工具,用于服务器基础资源使用的监控
一般部署在被监控节点上
| 主机 | IP | 系统版本 |
|---|---|---|
| ccweb-2 | 10.0.13.73 | CentOS Linux release 7.5.1804 (Core) |
| ccweb-3 | 10.0.13.75 | CentOS Linux release 7.5.1804 (Core) |
需提前将Node_exporter-1.5.0.linux-amd64.tar.gz下载并上传至服务器

4.1解压
#创建解压目录,建议选择磁盘资源充足空间进行创建
mkdir /data
#解压至指定目录
tar -zxvf node_exporter-1.5.0.linux-amd64.tar.gz -C /data/
#切换目录
cd /data
#改名,可跳过
mv node_exporter-1.5.0.linux-amd64/ node_exporter
4.2配置system管理
cat >> /usr/lib/systemd/system/node_exporter.service << EOF
[Unit]
Description=Prometheus Node Exporter
After=network.target
[Service]
ExecStart=/data/node_exporter/node_exporter
User=root
[Install]
WantedBy=multi-user.target
EOF
#使配置生效
systemctl daemon-reload
4.3启动
#启动
systemctl start node_exporter
#验证
systemctl status node_exporter
#以上启动方式默认为9100端口
#若想自定义端口使用以下启动方式
#切换目录
cd /data/node_exporter
#使用nohup并后台启动,addrees后的7100端口代表将会监听7100端口,是可以自定义修改的
nohup ./node_exporter --web.listen-address=:7100 &
#启动完成后验证,查看指定的端口是否正常被监听即可
ss -antpl | grep 7100
三、配置告警
基础服务部署完毕后,开始配置告警,本次采用邮箱告警
所谓告警也就是某些监控项达到阈值后执行发送告警的操作
那么这李的监控项即阈值包括告警操作都是我们自己定义的
接下来对服务器基础资源进行监控,如果超出我们定义的阈值将会对我们定义的邮箱发送告警
1.编写告警规则
以下操作在Prometheus监控端操作
#切换工作目录
cd /data/monitor/prometheus
#创建规则目录
mkdir rules
#编写规则,以下各阈值及时间可根据实际情况调整
cat >> rules/general.yml << EOF
groups:
- name: example #告警规则组名称
rules:
# 任何实例5分钟内无法访问发出告警
- alert: InstanceDown # 告警规则名称
expr: up == 0 # 基于PromQL的触发条件
for: 5m # 等待评估时间
annotations: # 指定附加信息
summary: " {{ \$labels.instance }} 停止工作"
description: "{{ \$labels.instance }}:job {{ \$labels.job }} 已经停止5分钟以上."
- name: node.rules
rules:
- alert: NodeFilesystemUsage
expr: 100 - (node_filesystem_free_bytes{fstype=~"ext4|xfs"} / node_filesystem_size_bytes{fstype=~"ext4|xfs"} * 100) > 80
for: 2m
labels:
severity: warning
annotations:
summary: "{{\$labels.instance}}: {{\$labels.mountpoint }} 分区使用过高"
description: "{{\$labels.instance}}: {{\$labels.mountpoint }} 分区使用大于 80% (当前值: {{ \$value }})"
- alert: NodeMemoryUsage
expr: 100 - (node_memory_MemFree_bytes+node_memory_Cached_bytes+node_memory_Buffers_bytes) / node_memory_MemTotal_bytes * 100 > 80
for: 2m
labels:
severity: warning
annotations:
summary: "{{\$labels.instance}}: 内存使用过高"
description: "{{\$labels.instance}}: 内存使用大于 80% (当前值: {{\$value }})"
- alert: NodeCPUUsage
expr: 100 - (avg(irate(node_cpu_seconds_total{mode="idle"}[5m])) by (instance) * 100) > 80
for: 2m
labels:
severity: warning
annotations:
summary: "{{\$labels.instance}}: CPU使用过高"
description: "{{\$labels.instance}}: CPU使用大于 80% (当前值: {{ \$value }})"
EOF
#编写主机告警规则
cat >> rules/host-monitor.yml << EOF
groups:
- name: node-up
rules:
- alert: node-up
expr: up == 0
for: 10s
labels:
severity: warning
team: node
annotations:
summary: " {{ \$labels.instance }} 服务已停止运行超过 10s!"
EOF
2.编写全局配置
#切换工作目录
cd /data/monitor/prometheus
#备份原配置文件
mv prometheus.yml prometheus.yml_bak
#编写配置
cat >> prometheus.yml << EOF
# my global config
global:
scrape_interval: 15s # 将刮擦间隔设置为每15秒。默认值为每1分钟。
evaluation_interval: 15s # 每15秒评估一次规则。默认值为每1分钟。
# scrape_timeout设置为全局默认值(10s)。
# Alertmanager 配置
alerting:
alertmanagers:
- static_configs:
- targets:
- 10.0.13.72:9093 # alertmanager所在服务器,默认端口为9093
# 加载规则一次,并根据全局“evaluation_interval”定期评估规则。
rule_files:
- "/data/monitor/prometheus/rules/*.yml" # 指定报警规则文件的位置
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label \`job=<job_name>\` to any timeseries scraped from this config.
- job_name: "prometheus" # 这个job是默认的,不用管
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ["localhost:9090"]
- job_name: 'ccweb' # job名称可自定义
static_configs:
- targets: ["10.0.13.73:9100",
"10.0.13.75:9100"] # exporter监测器所在服务器及对应的端口
EOF
#重启服务
systemctl restart prometheus alertmanager
3.告警验证
设置完以上的规则后,首先前端查看是否添加成功
浏览器访问http://10.0.13.72:9090,点击’Status’—>‘Targets’
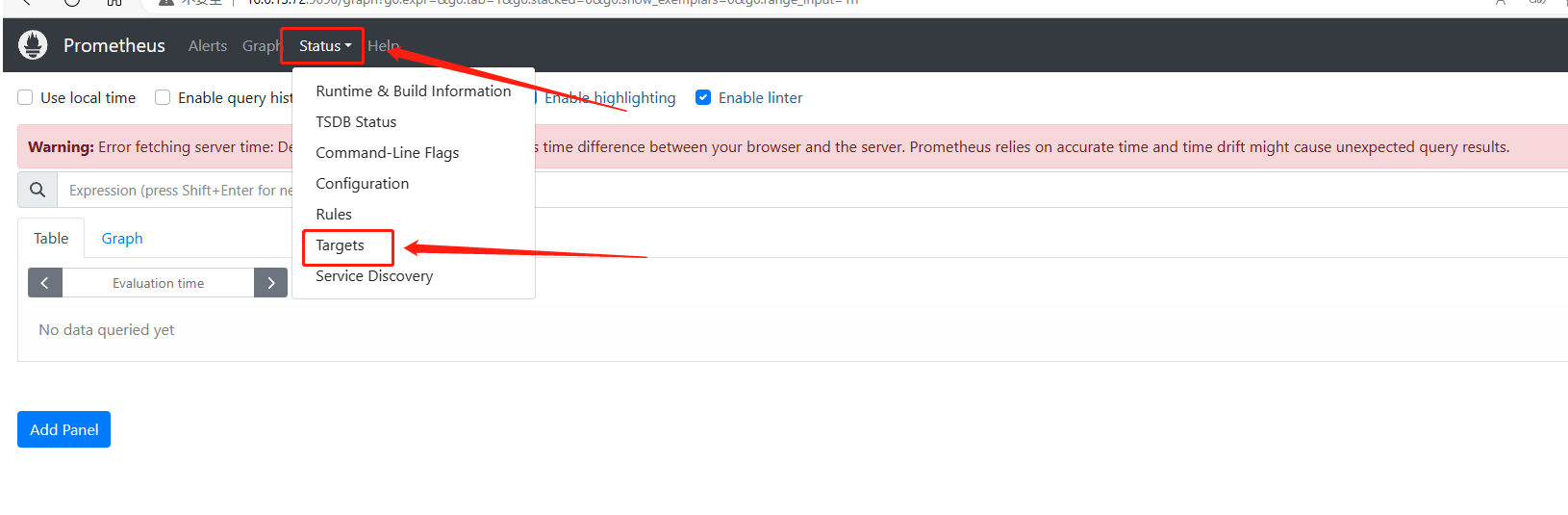
可以看到我们定义的job,以及对应的服务器状态
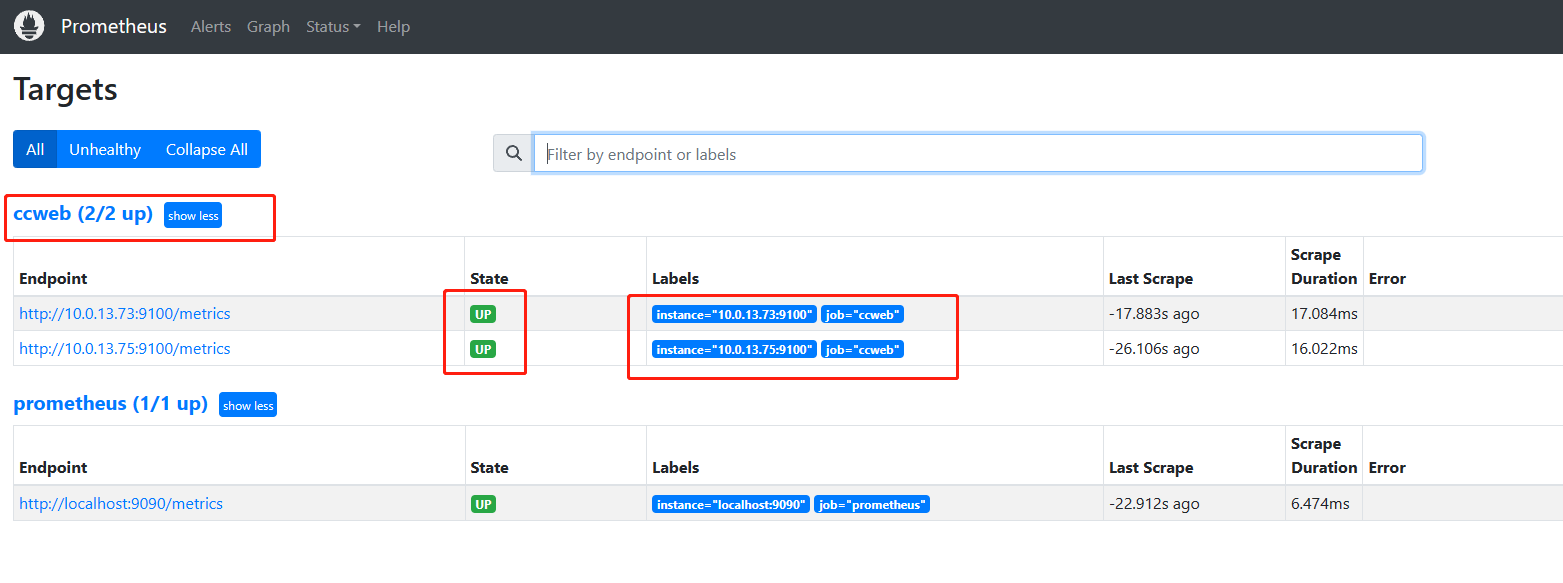
这个时候我们来到被监控端,关闭node_exporter程序,查看页面情况及是否会告警
#关闭node_exporter
systemctl stop node_exporter
发现前端已经显示down
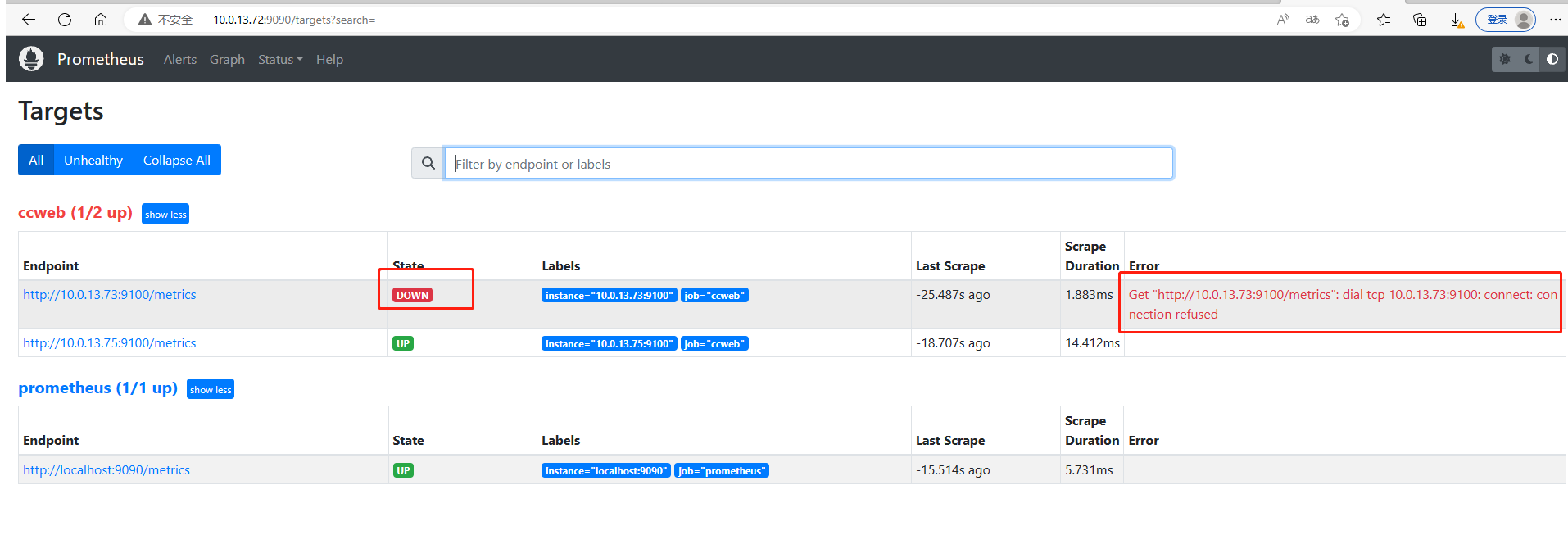
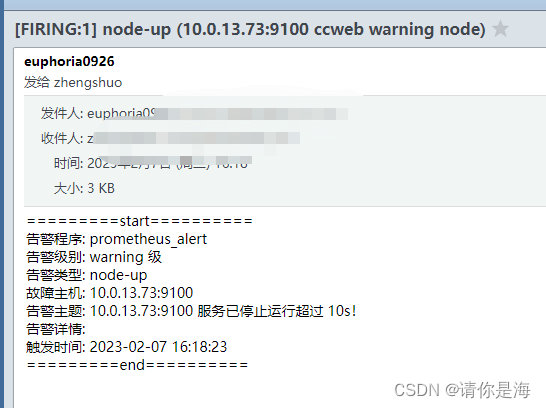
告警内容也已经发送
测试另一个阈值,监控服务器资源使用,异常则告警,测试服务器资源则需要手动将阈值调低
来到prometheus服务器,更改配置
#切换工作目录
cd /data/monitor/prometheus/rules
#编辑配置文件
vim general.yml
expr: 100 - (node_filesystem_free_bytes{fstype=~"ext4|xfs"} / node_filesystem_size_bytes{fstype=~"ext4|xfs"} * 100) > 80
#将以上内容改为
expr: 100 - (node_filesystem_free_bytes{fstype=~"ext4|xfs"} / node_filesystem_size_bytes{fstype=~"ext4|xfs"} * 100) > 1
#保存退出后,重启服务
systemctl restart prometheus
等待两分钟,发现告警已发送,这时候测试以完毕,将配置还原后重启服务

四、服务监控及告警
配置监控主机的部分http端口,并进行访问测试,访问不通及告警的操作
在Prometheus监控端执行
1.安装blackbox_exporter
blackbox_exporter-黑盒监控
常用于HTTP探针、TCP探针检测及站点或者服务的可访问性,以及访问效率等。
下载地址:
Blackbox_exporter-0.22.0.linux-amd64.tar.gz官网下载地址:
https://github.com/prometheus/blackbox_exporter/releases/download/v0.22.0/blackbox_exporter-0.22.0.linux-amd64.tar.gz
若下载较慢或访问不通,选择以下链接进行下载:
链接:https://pan.baidu.com/s/1b94funik-jckcPjJX6cOZA?pwd=zska
提取码:zska将下载好的服务包上传至服务器,blackbox_exporter不同于node_exporter,黑盒监测器可以部署在任何节点上,只要能够被监控端访问到以及能够访问被监控端需要监控的端口即可,本次部署选择部署在监控端
#解压至指定目录
tar -zxvf blackbox_exporter-0.22.0.linux-amd64.tar.gz -C /data/monitor/
#切换目录
cd /data/monitor
#改名,方便后续操作
mv blackbox_exporter-0.22.0.linux-amd64/ blackbox_exporter
2.配置system管理
#配置system管理,注意--web.listen-address=:9115,后面的9115代表启动黑盒监测器后程序监听的端口,可自定义修改
#而ExecStart与--config.file后的路径配置为实际的安装目录即可
cat >> /usr/lib/systemd/system/blackbox_exporter.service << EOF
[Unit]
Description=Prometheus Blackbox Exporter
After=network.target
[Service]
Type=simple
User=root
Group=root
ExecStart=/data/monitor/blackbox_exporter/blackbox_exporter \\
--config.file=/data/monitor/blackbox_exporter/blackbox.yml \\
--web.listen-address=:9115
Restart=on-failure
[Install]
WantedBy=multi-user.target
EOF
#启动测试
systemctl start blackbox_exporter
#查看启动状态
systemctl status blackbox_exporter
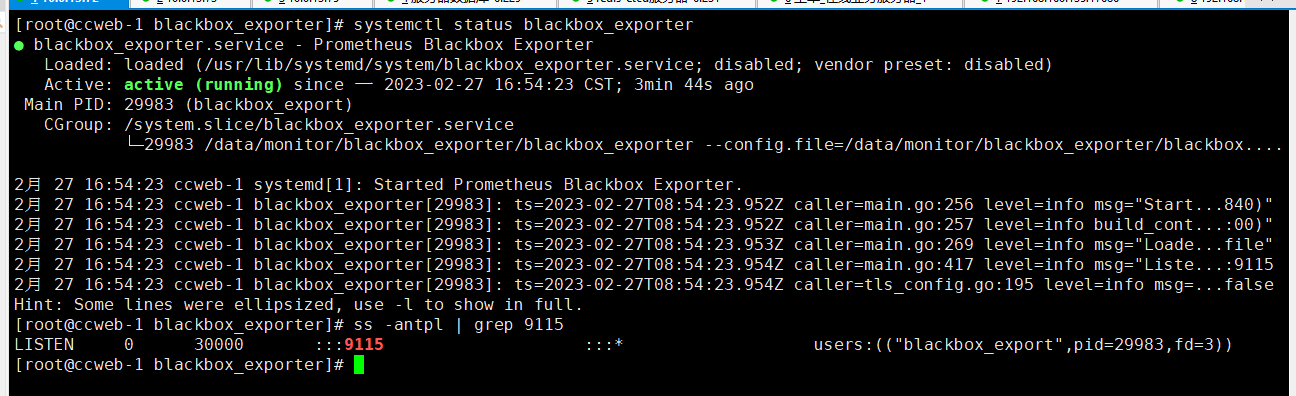
3.配置监控规则
来到监控端对Prometheus主应用进行配置
#切换目录
cd /data/monitor/promehtues
#编辑主配置文件
vim prometheus.yml
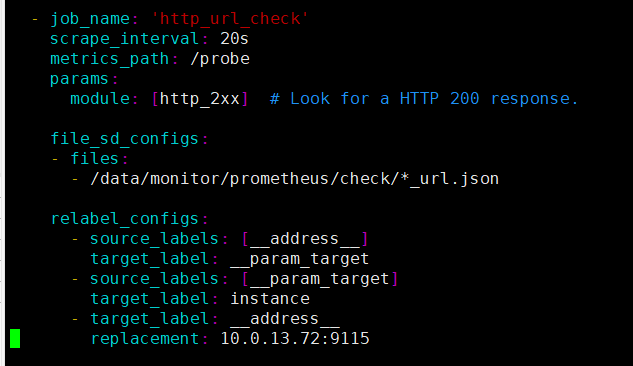
#在最下方添加以下内容,注意files模块是指定要读取的配置路径,而replacement指定的是blackbox_exporter所在服务器+port
- job_name: 'http_url_check'
scrape_interval: 20s
metrics_path: /probe
params:
module: [http_2xx] # Look for a HTTP 200 response.
file_sd_configs:
- files:
- /data/monitor/prometheus/check/*_url.json
relabel_configs:
- source_labels: [__address__]
target_label: __param_target
- source_labels: [__param_target]
target_label: instance
- target_label: __address__
replacement: 10.0.13.72:9115
#创建监测器所读取配置目录
mkdir /data/monitor/prometheus/check
#切换目录
cd /data/monitor/prometheus/check
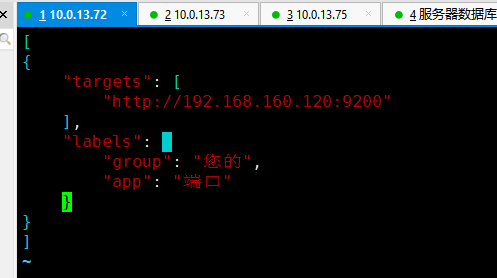
#编辑监测器所读取配置文件,注意targets下方的url为要监测的url,多个使用英文逗号隔开
cat >> test_url.json << EOF
[
{
"targets": [
"http://10.0.13.73:80"
],
"labels": {
"group": "您的",
"app": "端口"
}
}
]
EOF
4.配置告警规则
编写告警规则
#切换目录
cd /opt/monitor/prometheus/rules
#编辑文件
cat >> port.yml << EOF
groups:
- name: http url check
rules:
- alert: http_url_check failed
for: 5s
expr: probe_success{job="http_url_check"} == 0
labels:
serverity: critical
annotations:
description: "{{ \$labels.group }}的{{ \$labels.app }} 检测失败,当前probe_success的值为{{ \$value }}"
summary: "以上服务器的 {{ \$labels.app }} 访问不通"
EOF
5.告警测试
首先重启监控端,重启服务
再登录10.0.13.73服务器关闭监听80端口的服务,若没有监听80端口的服务,则重启服务即可
等待5分钟查看邮箱是否有以下告警信息,告警信息有点乱,主要是看故障主机和告警主题,有需要可自行修改告警模板
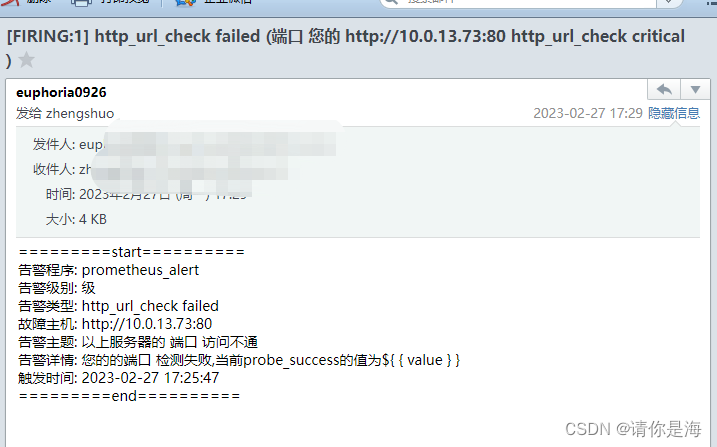
五、端口监控及告警
监控服务器tcp端口是否正常的常用监测手段
同样是使用blackbox_exporter监测器进行端口服务的监控,tcp模块功能主要是
- 业务组件端口状态监听
- 应用层协议定义与监听
首先参考第四章节内的1小节和2小节进行blackbox_exporter监测器的安装
1.配置监控规则
部署完blackbox_exporter后记得记住他的地址如ip+port
来到Prometheus监控端编辑对端口的监控
#切换工作目录
cd /data/monitor/promehteus
#编辑目录
vim prometheus.yml
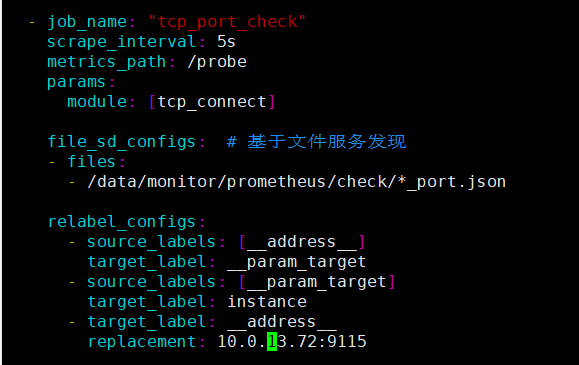
#在最下方加入以下job,注意files模块是指定要读取的配置路径,而replacement指定的是blackbox_exporter所在服务器+port
- job_name: "tcp_port_check"
scrape_interval: 5s
metrics_path: /probe
params:
module: [tcp_connect]
file_sd_configs: # 基于文件服务发现
- files:
- /data/monitor/prometheus/check/*_port.json
relabel_configs:
- source_labels: [__address__]
target_label: __param_target
- source_labels: [__param_target]
target_label: instance
- target_label: __address__
replacement: 10.0.13.72:9115
#创建监测器所读取配置目录
mkdir /data/monitor/prometheus/check
#切换目录
cd /data/monitor/prometheus/check
#编辑监测器所读取配置文件,注意targets下方的url为要监测的url,多个使用英文逗号隔开
cat >> test_port.json << EOF
[
{
"targets": [
"10.0.13.75:80"
],
"labels": {
"group": "ccweb",
"app": "backend"
}
}
]
EOF
2.配置告警规则
#切换目录
cd /data/monitor/prometheus/rules
#编辑配置文件
vim port.yml
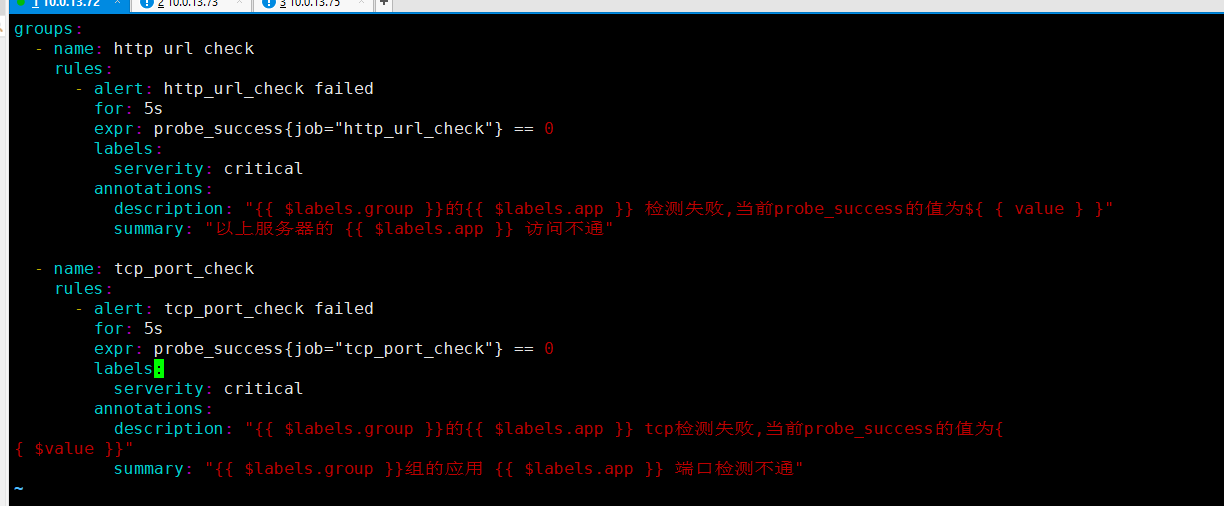
#将以下内容添加在文件最下方即可,注意第一行的group,若文件内存在,即去除
groups:
- name: tcp_port_check
rules:
- alert: tcp_port_check failed
for: 5s
expr: probe_success{job="tcp_port_check"} == 0
labels:
serverity: critical
annotations:
description: "{{ $labels.group }}的{{ $labels.app }} tcp检测失败,当前probe_success的值为{
{ $value }}"
summary: "{{ $labels.group }}组的应用 {{ $labels.app }} 端口检测不通"
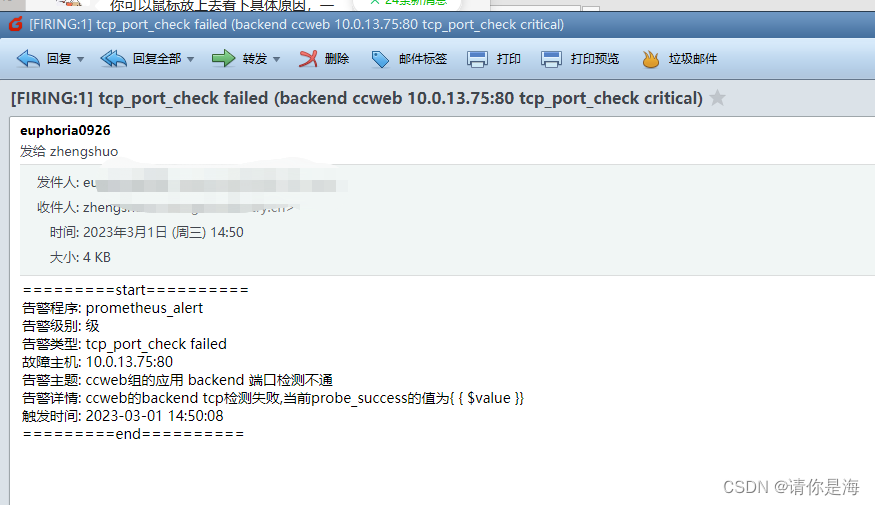
3.告警测试
首先重启监控端,重启服务
再登录10.0.13.75服务器关闭监听80端口的服务,若没有监听80端口的服务,则重启服务即可
等待5分钟查看邮箱是否有以下告警信息,告警信息有点乱,主要是看故障主机和告警主题,有需要可自行修改告警模板
六、进程监控及告警
监控服务器全部或某些进程是否健康,以及进程所占用资源是否异常
使用process_exporter监测器进行进程信息的采集
与node_exporter监测器相同,需要监测哪台服务器的进程,就将process_exporter监测器部署在哪台
1.安装process_exporter
将Process-exporter-0.7.10.linux-amd64.tar.gz下载并上传至服务器

#解压至指定目录
tar -zxvf process-exporter-0.7.10.linux-amd64.tar.gz -C /data/monitor
#切换工作目录
cd /data/monitor
#改名,方便后续操作
mv process-exporter-0.7.10.linux-amd64 process-exporter
#编辑配置文件,注意注释了的三行代表获取全部进程
cat >> /data/monitor/process-exporter/process-name.yaml
process_names:
# - name: "{{.Comm}}"
# cmdline:
# - '.+'
- name: "{{.Matches}}"
cmdline:
- 'nginx' #全局标识,写了nginx相当于获取进程的方式为`ps -ef | grep nginx`
EOF
name后可用的模板变量:
{{.Comm}} 包含原始可执行文件的基本名称,即 /proc//stat
{{.ExeBase}} 包含可执行文件的基本名称
{{.ExeFull}} 包含可执行文件的标准路径
{{.Username}} 包含有效用户的用户名
{{.Matches}} 包含所有由于应用cmdline正则表达式而产生的匹配项
{{.PID}} 包含过程的PID。请注意,使用PID意味着该组将仅包含一个进程
{{.StartTime}} 包含过程的开始时间。与PID结合使用时,这很有用,因为PID会随着时间的推移而被重用
#配置system,注意各参数定义的目录以实际为准
cat >> /usr/lib/systemd/system/process-exporter.service << EOF
[Unit]
Description=Prometheus exporter for processors metrics, written in Go with pluggable metric collectors.
Documentation=https://github.com/ncabatoff/process-exporter
After=network.target
[Service]
Type=simple
User=root
WorkingDirectory=/data/monitor/process-exporter
ExecStart=/data/monitor/process-exporter/process-exporter -config.path=/data/monitor/process-exporter/process-name.yaml
Restart=on-failure
[Install]
WantedBy=multi-user.target
EOF
#使配置生效
systemctl daemon-reload
#启动,默认占用9256端口
systemctl start process-exporter
#配置开机自启
systemctl enable process-exporter
2.配置Prometheus
来到Prometheus监控端,配置Prometheus配置文件
#切换目录
cd /data/monitor/prometheus
#编辑配置文件,注意IP变化,多个IP以','隔开
cat >> prometheus.yml << EOF
- job_name: 'nginx-check'
static_configs:
- targets: ["10.0.13.76:9256"]
EOF
#检查配置文件是否合法
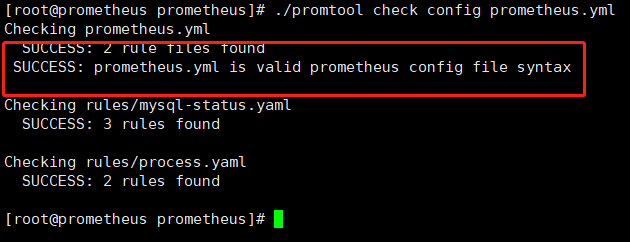
./promtool check config prometheus.yml

#重启Prometheus
systemctl restart prometheus
3.配置grafana
登录grafana页面,如图点击
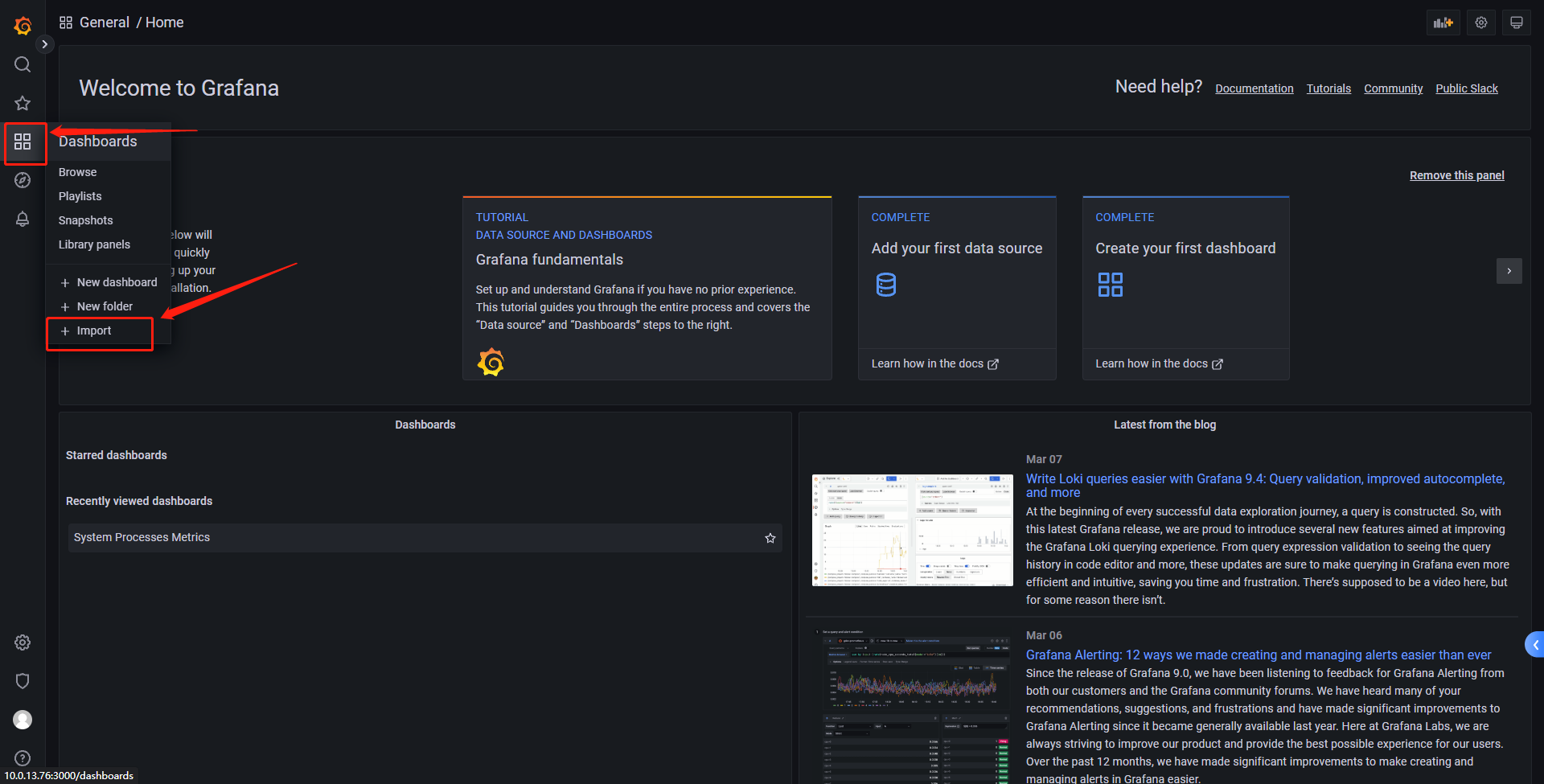
在Import via grafana.com下面的栏内输入8378,后点击左边的load
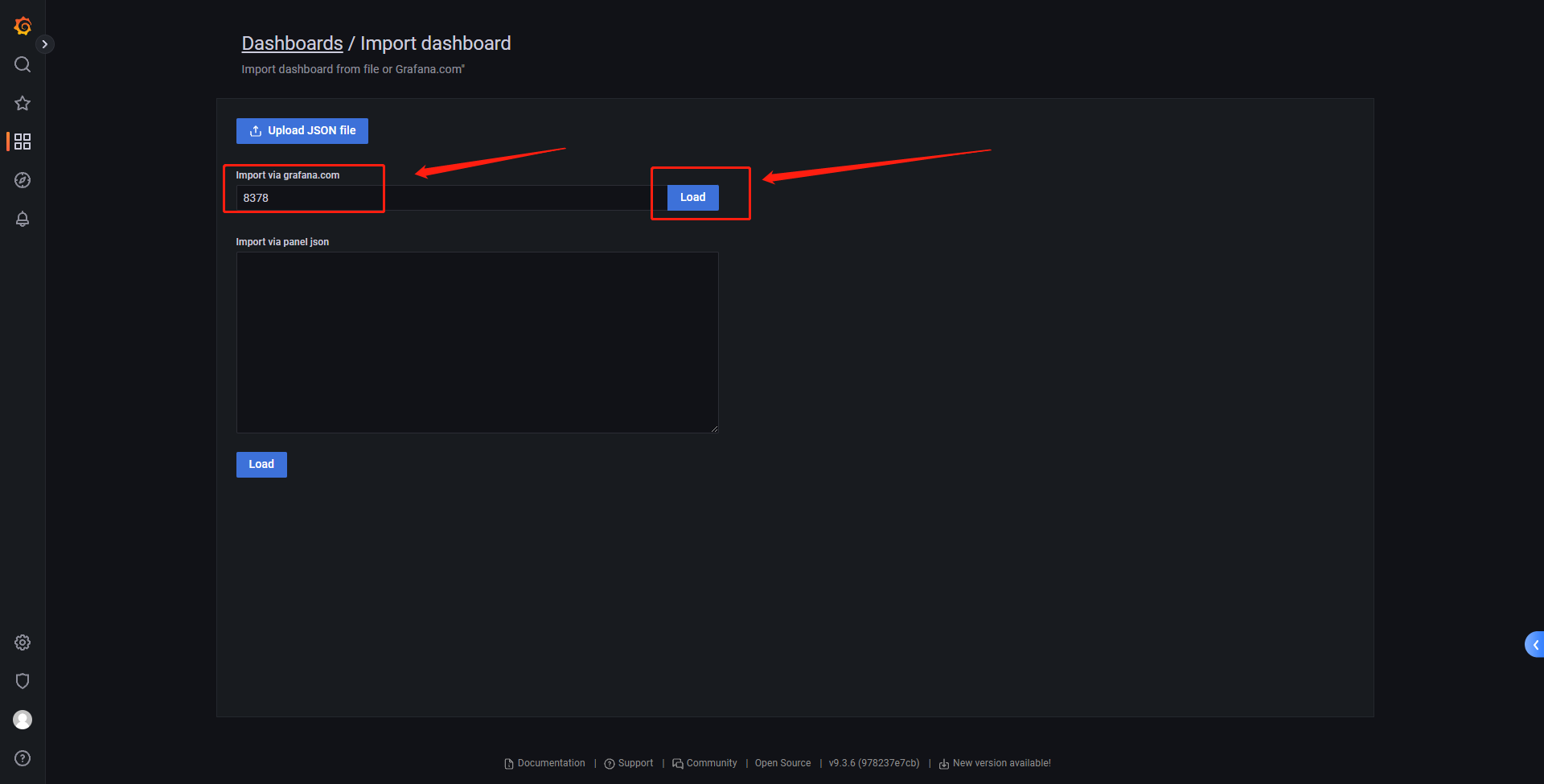
名称name自定义,点击import
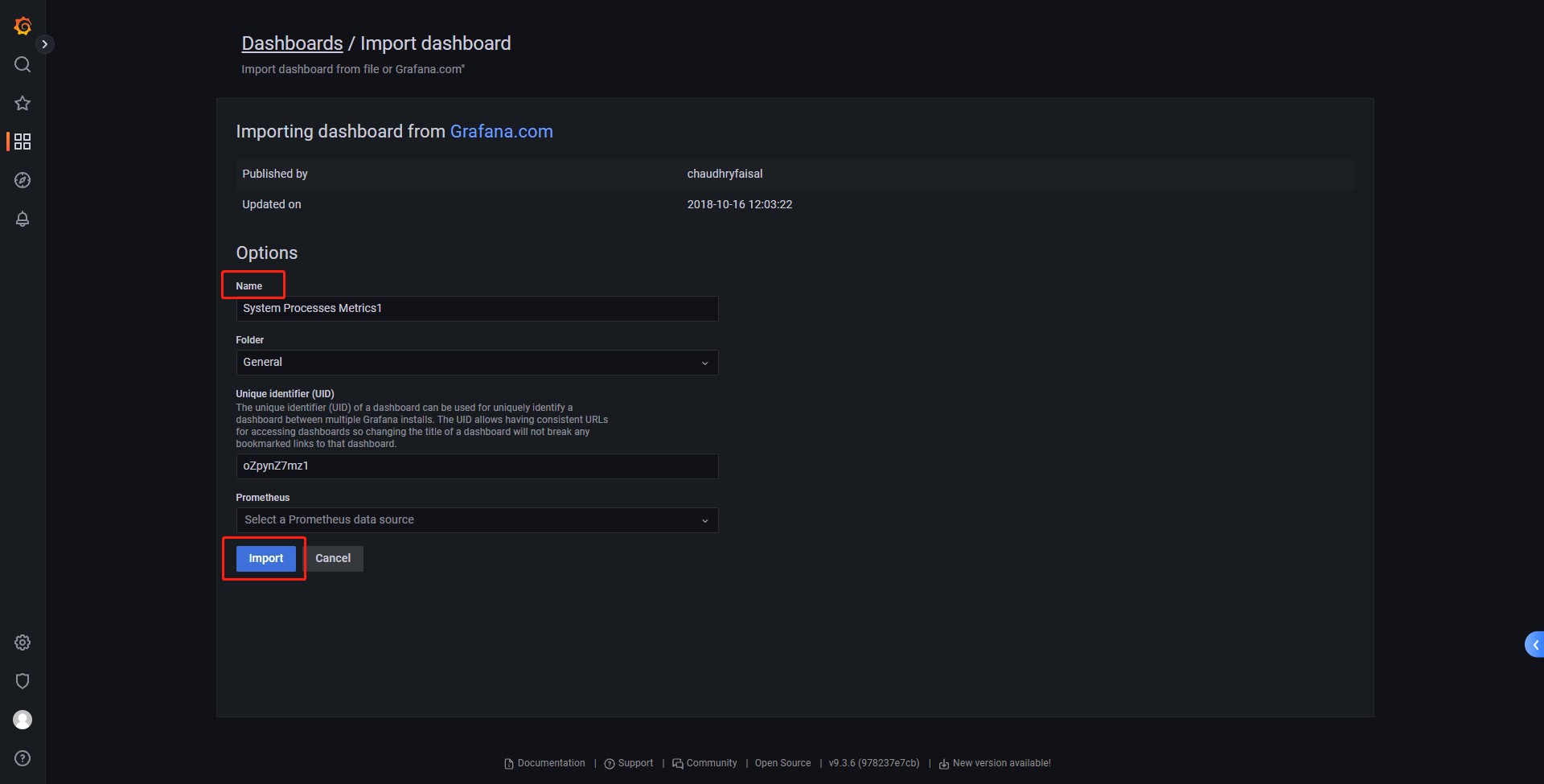
即可看到定义的nginx进程在被监控
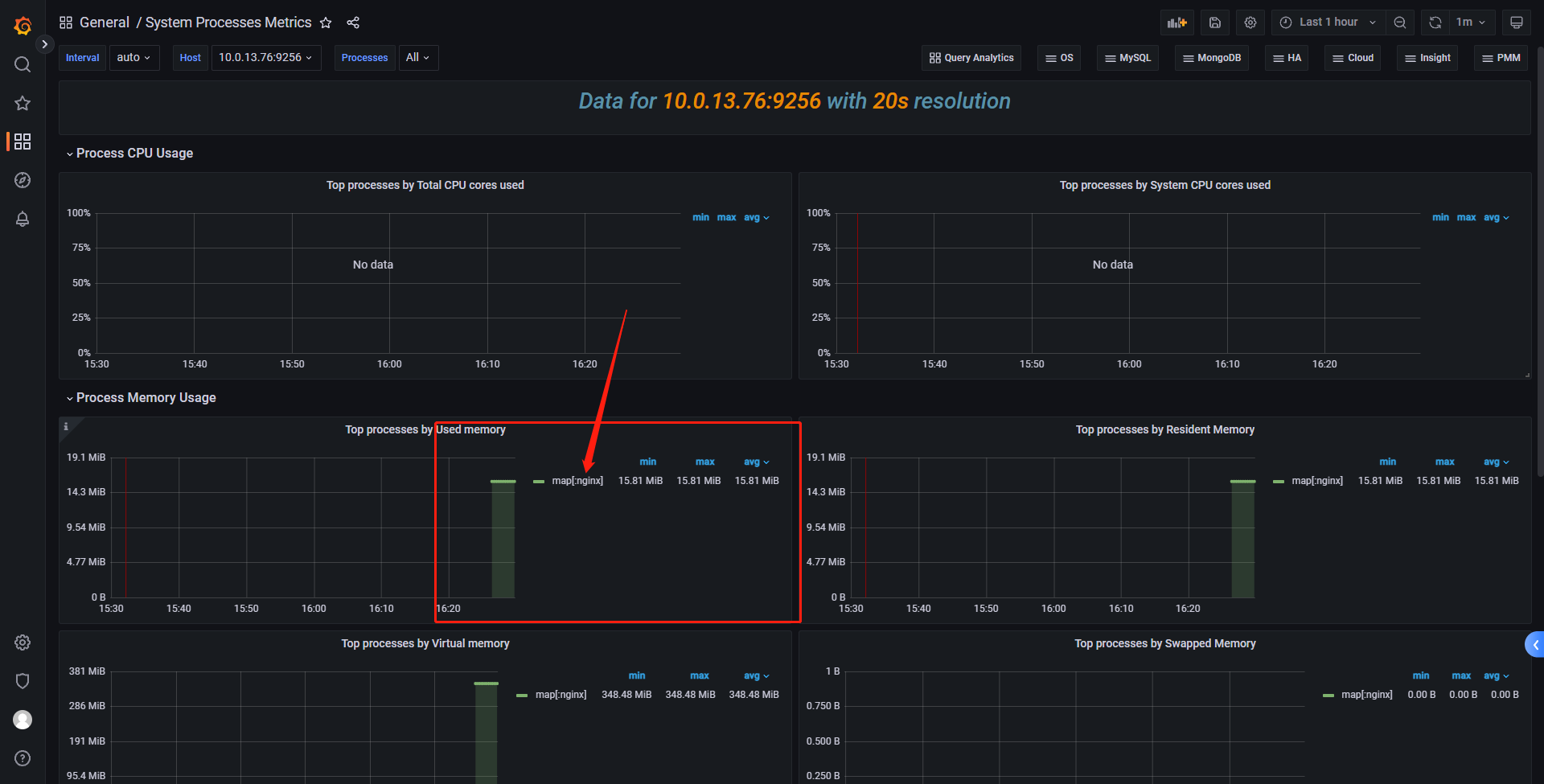
后续进入页面可以通过点击首页的Search dashboards查看我们导入的模板
4.告警规则配置
上面配置最主要的两个配置:
prometheus.yml 配置了process-exporter监测器的位置
process-name.yaml 配置要监测的进程也就是cmdline下的进程识别名
接下来要对rules也就是告警阈值规则进行配置
#切换工作目录
cd /data/monitor/prometheus/rules
#编辑配置文件
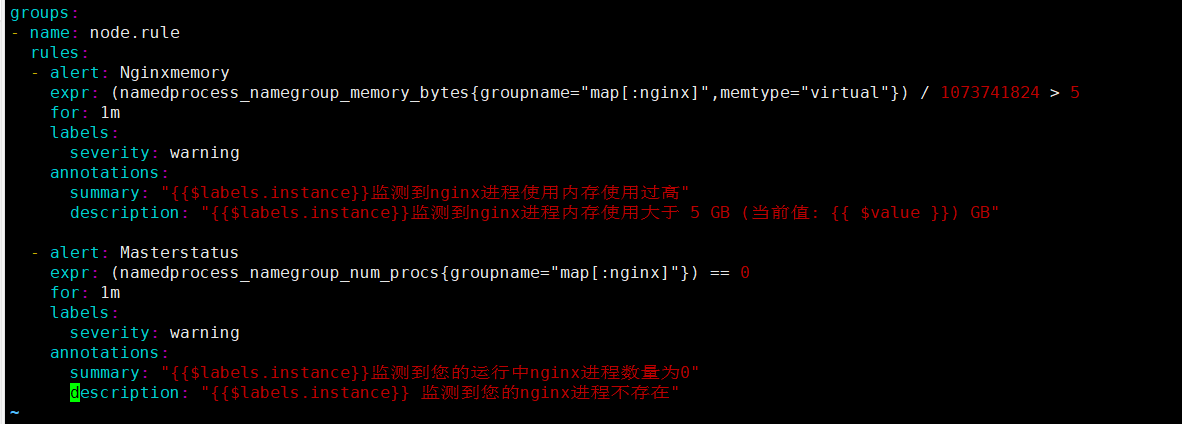
cat >> process.yaml << EOF
groups:
- name: node.rule
rules:
- alert: Nginxmemory
expr: (namedprocess_namegroup_memory_bytes{groupname="map[:nginx]",memtype="virtual"}) / 1073741824 > 5
for: 1m
labels:
severity: warning
annotations:
summary: "{{\$labels.instance}}监测到nginx进程使用内存使用过高"
description: "{{\$labels.instance}}监测到nginx进程内存使用大于 5 GB (当前值: {{ \$value }}) GB"
- alert: Masterstatus
expr: (namedprocess_namegroup_num_procs{groupname="map[:nginx]"}) == 0
for: 1m
labels:
severity: warning
annotations:
summary: "{{\$labels.instance}}监测到您的运行中nginx进程数量为0"
description: "{{\$labels.instance}} 监测到您的nginx进程不存在"
EOF
#文件解析:
#上方的配置一共有两个rules
#第一个是Nginxmemory,也就是nginx进程占用的内存
#expr后面的公式代表的是'(namedprocess_namegroup_memory_bytes{groupname="map[:nginx]",memtype="virtual"})'代表nginx进程占用总内存数,一般为b字节形式,所以后面/除以1073741824转换为GB字节,如果大于5GB则满足条件触发告警
#第二个是Masterstatus
#也就是进程的存货状态
#expr后的比较是'(namedprocess_namegroup_num_procs{groupname="map[:nginx]"})'代表groupname内map为nginx,也就是我们配置的进程名,监测到的总进程数== 0,也就是没有监测到的时候,满足条件触发告警
#重启服务重载配置
systemctl restart prometheus
systemctl restart alertmanager
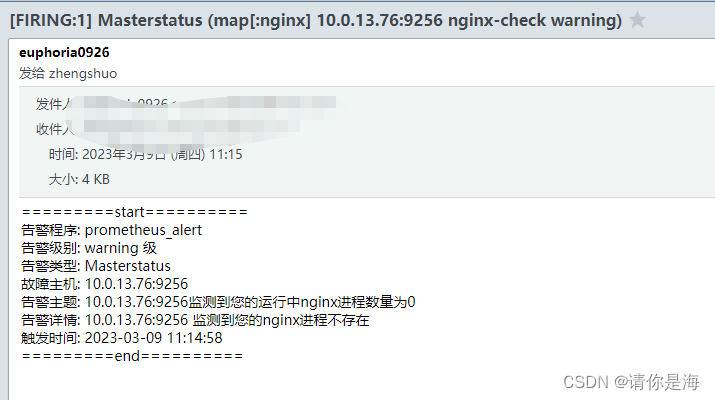
5.告警测试
来到安装process-exporter的服务器上
手动关停监测的进程程序,也就是nginx
#关闭nginx所有进程
for i in `ps -ef | grep nginx | grep -v grep | awk '{print $2}'` ; do echo "$i killd" ; kill -9 $i ; done
#关闭后等待告警信息的到来,长时间未收到告警信息,检查配置是否正确
七、数据库监控
监测mysql数据库的状态,需要使用的mysql专用的监测器-mysql-exporter
1.单机监控
以下是单机mysql监控操作
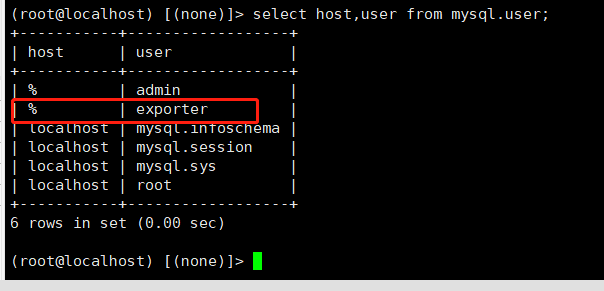
1.1创建用户
再进行服务的安装之前,在需要监控的数据库内,创建对应的用户,供mysqld_exporter使用
--创建用户
CREATE USER 'exporter'@'%' identified by '你的密码';
--给予权限
GRANT PROCESS, REPLICATION CLIENT, SELECT ON *.* TO 'exporter'@'%';
--刷新授权表
flush privileges;
--查看用户列表
select host,user from mysql.user;
1.2安装mysql_exporter
首先将下载好的mysql_exporter上传至服务器
#解压到指定目录
tar -zxvf mysqld_exporter-0.14.0.linux-amd64.tar.gz -C /data/monitor/
#切换工作目录
cd /data/monitor
#改名方便后续操作
mv mysqld_exporter-0.14.0.linux-amd64/ mysqld_exporter
#切换目录
cd /data/monitor/mysqld_exporter
#编写配置文件,根据您的数据库信息进行以下信息的配置
cat >> .my.cnf << EOF
[client]
host=ip
port=端口
user=用户名
password=密码
EOF
#启动mysqld_exporter,默认监听9104,可以使用--web.listen-address=":端口"修改程序监听端口
nohup ./mysqld_exporter --config.my-cnf=.my.cnf & &>/dev/null
#查看监测数据
curl 10.0.13.76:9104/metrics
1.3配置prometheus
来到Prometheus监控端进行配置,读取我们mysqld_exporter采集的信息
#切换目录
cd /data/monitor/prometheus
#编辑配置,注意mysqld_exporter的ip+port改为自己的
cat >> prometheus.yml << EOF
- job_name: 'mysqld-status'
static_configs:
- targets: ["10.0.13.76:9104"]
EOF
#检查格式
./promtool check config prometheus.yml
#重启服务
systemctl restart prometheus
1.4配置grafana
登录grafana页面,如图点击import
输入7362,随后点击load,注意服务端要能访问到Grafana.com,才能加载模板
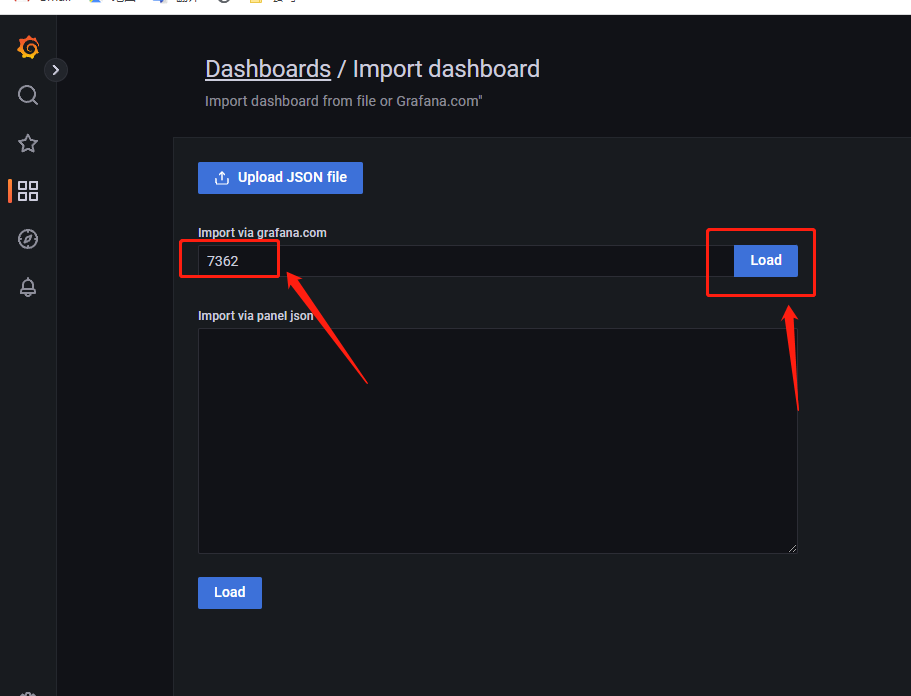
名称自定义,数据源绑定我们的Prometheus即可点击import
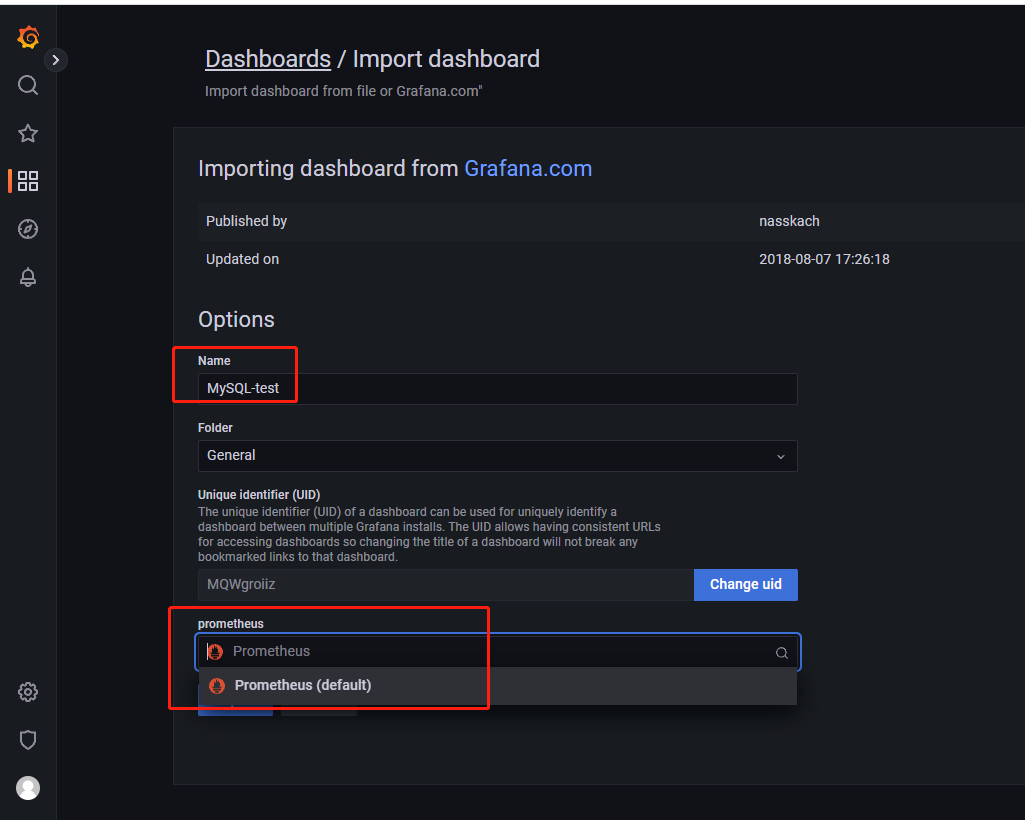
页面配置完成
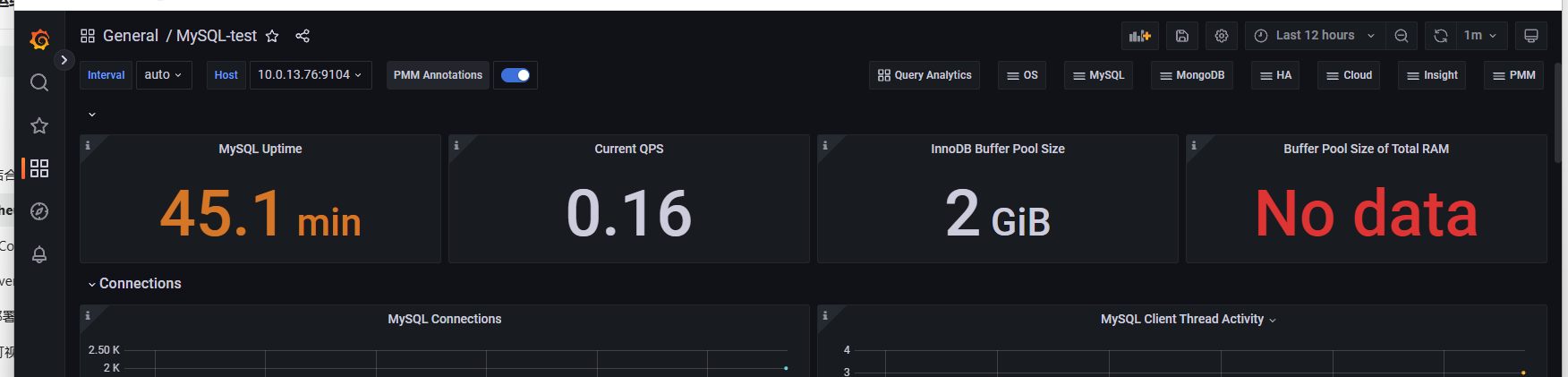
后期进入可以通过点击search dashborads查看视图
1.5配置告警
回到Prometheus服务端,编写告警规则
#切换目录
cd /data/monitor/prometheus/rules
#编辑配置
cat >> mysql-status.yaml << EOF
groups:
- name: Mysql-rules
rules:
- alert: Mysql-status
expr: up == 0
for: 5s
labels:
severity: error
annotations:
summary: " {{ \$labels.instance }} 监测到Mysql已停止运行!"
description: "Mysql数据库宕机,请检查"
EOF
#重启Prometheus,加载配置
systemctl restart prometheus
1.6告警测试
来到监测的数据库服务器,进行手动停机,查看告警信息是否会正常发送
#关闭数据库
systemctl stop mysqld
#查看mysqld_exporter监测信息,注意ip和port改为自己的
curl 10.0.13.76:9104/metrics
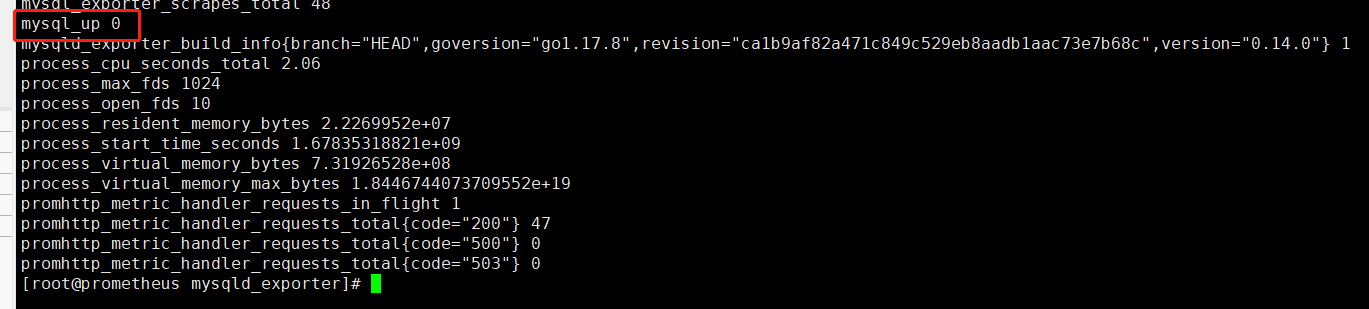
等待报警信息的到来,如果超过五分钟没有告警信息,代表程序配置出现问题
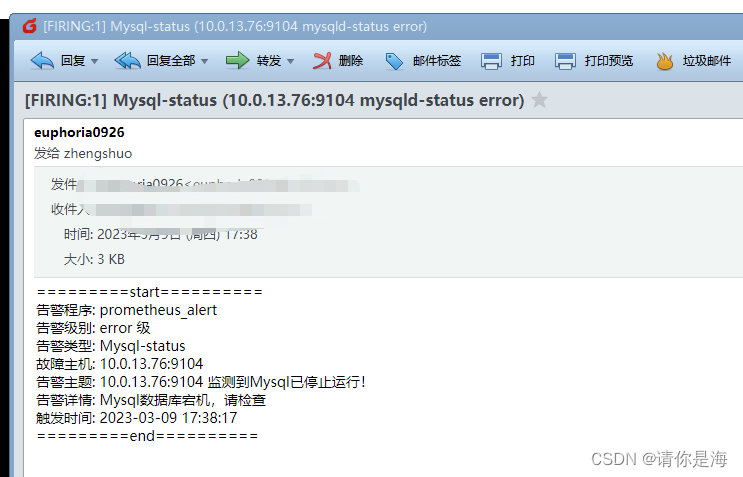
2.双机监控
以下是mysql主从集群的监控操作
2.1创建用户
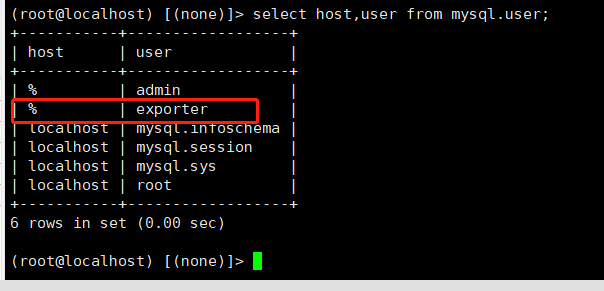
在进行服务的部署之前,我们首先需要创建赋有权限的用户,供exporter使用
来到mysql-master节点,创建用户,从服务器会同步创建
--创建用户
CREATE USER 'exporter'@'%' identified by '你的密码';
--给予权限
GRANT PROCESS, REPLICATION CLIENT, SELECT ON *.* TO 'exporter'@'%';
--刷新授权表
flush privileges;
--查看用户列表
select host,user from mysql.user;
2.2安装mysql_exporter
mysql_exporter需要安装到两台节点上
以下操作两台服务器都需要执行
首先将下载好的资源包上传至服务器
#解压到指定目录
tar -zxvf mysqld_exporter-0.14.0.linux-amd64.tar.gz -C /data/monitor/
#切换工作目录
cd /data/monitor
#改名方便后续操作
mv mysqld_exporter-0.14.0.linux-amd64/ mysqld_exporter
#切换目录
cd /data/monitor/mysqld_exporter
#编写配置文件,根据您的数据库信息进行以下信息的配置,注意主节点从节点IP变化
cat >> .my.cnf << EOF
[client]
host=ip
port=端口
user=用户名
password=密码
EOF
#启动mysqld_exporter,默认监听9104,可以使用--web.listen-address=":端口"修改程序监听端口
nohup ./mysqld_exporter --config.my-cnf=.my.cnf & &>/dev/null
#查看监测数据,获取的ip+port改为自己的两台节点
curl 10.0.13.76:9104/metrics
2.3配置Prometheus
来到Prometheus监控端进行配置,读取我们mysqld_exporter采集的信息
#切换目录
cd /data/monitor/prometheus
#编辑配置,注意mysqld_exporter的ip+port改为自己的
cat >> prometheus.yml << EOF
- job_name: 'mysqld-master'
static_configs:
- targets: ["10.0.13.76:9104"]
- job_name: 'mysql-slave'
static_configs:
- targets: ["10.0.13.75:9104"]
EOF
#检查格式
./promtool check config prometheus.yml
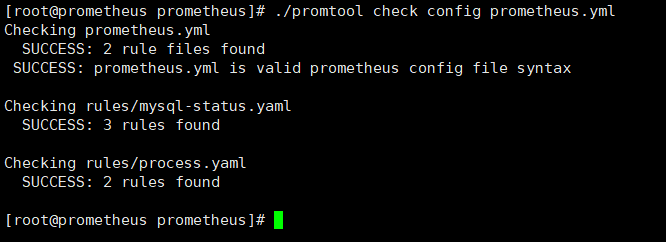
#重启服务,加载配置
systemctl restart prometheus
2.4配置grafana
登录grafana页面,如图点击import
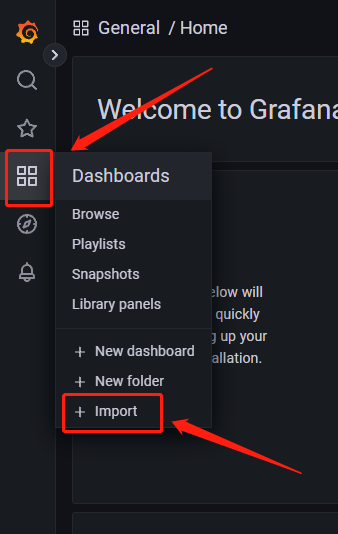
输入7362,如图点击load
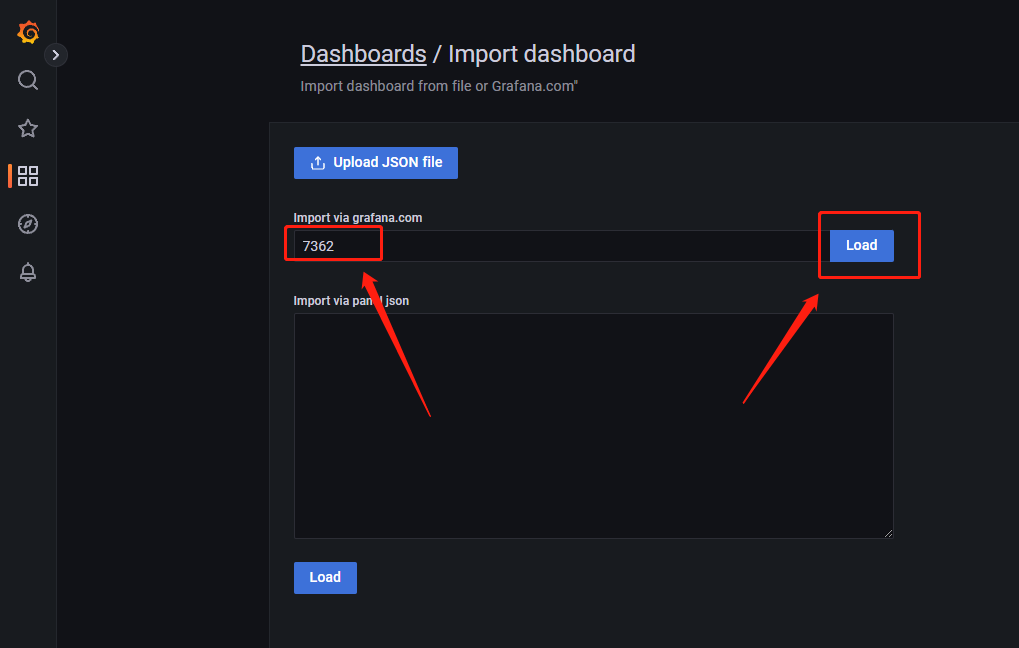
名称自定义,数据源选择我们的Prometheus即可点击import
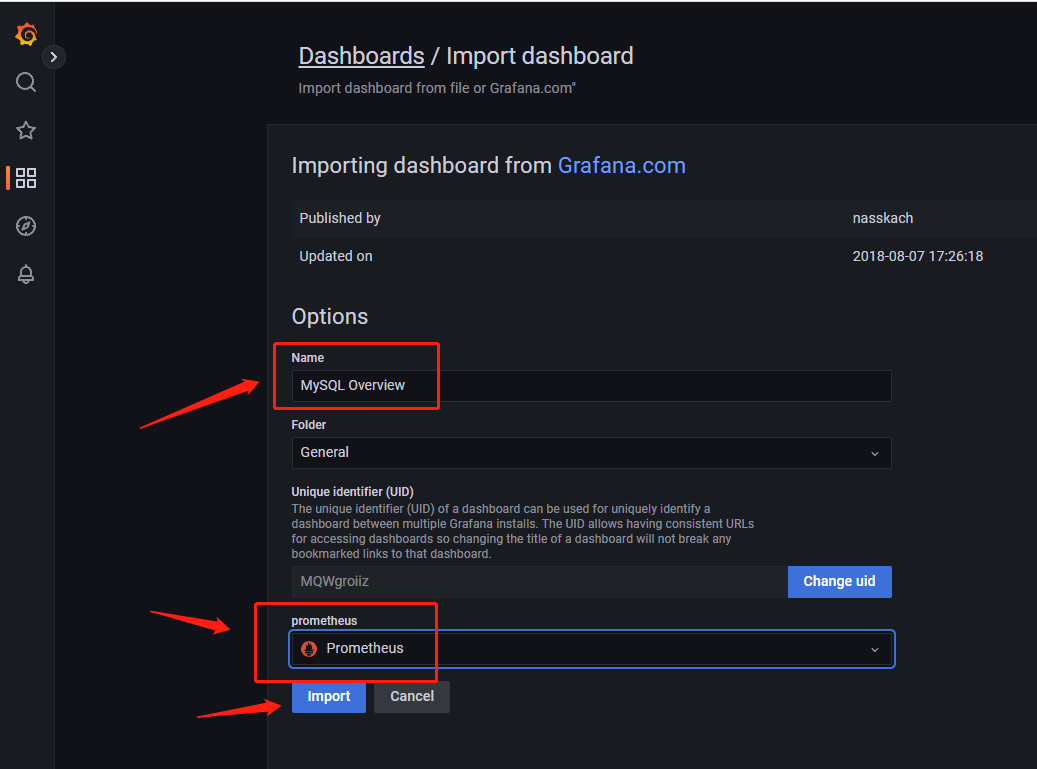
这个页面主要用来查看master节点状态,也可以通过点击如图位置,切换服务器
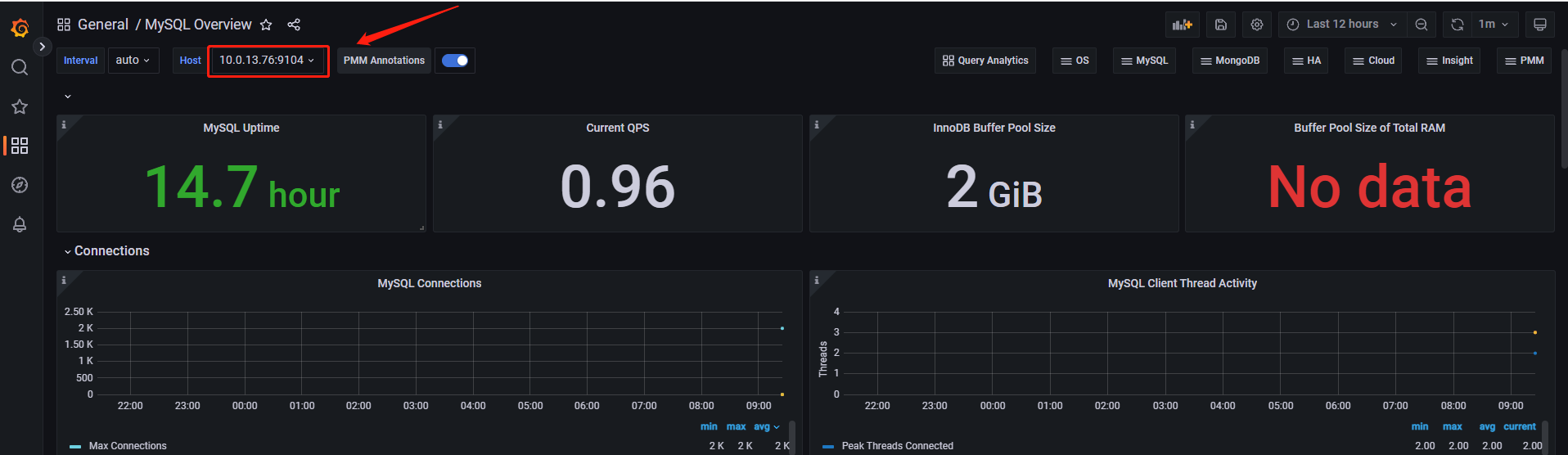
回到grafana页面,如图点击import
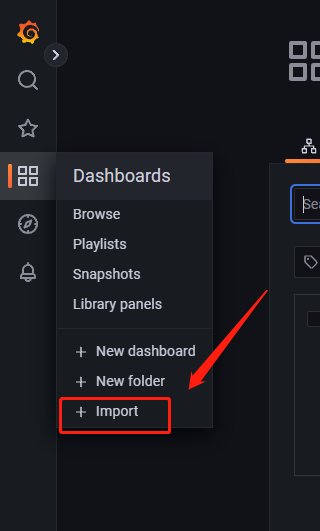
输入7371,并如图点击load,注意需要服务器可以访问Grafana.com
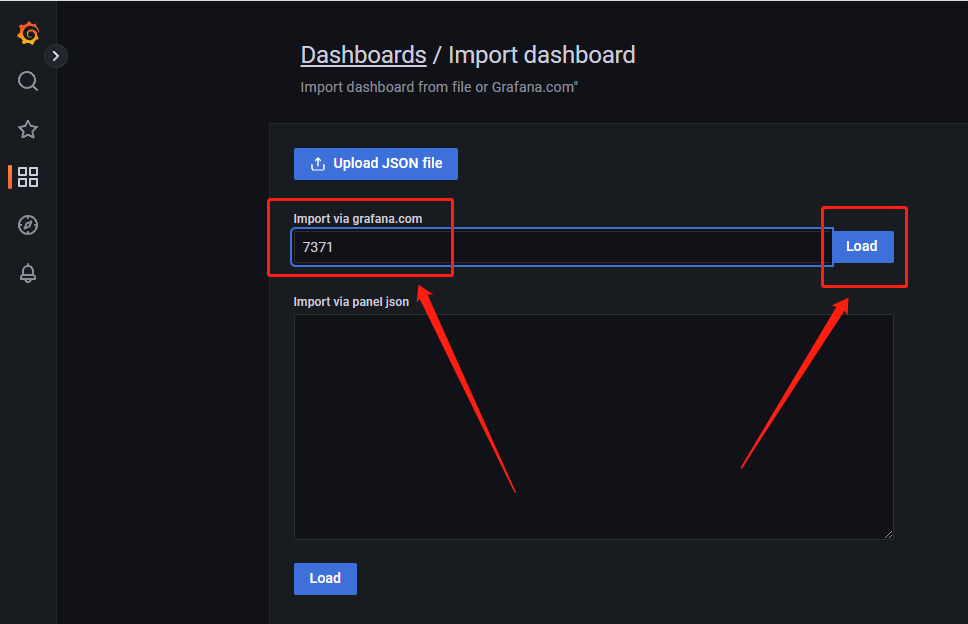
名称自定义,数据源选择我们的Prometheus即可点击import
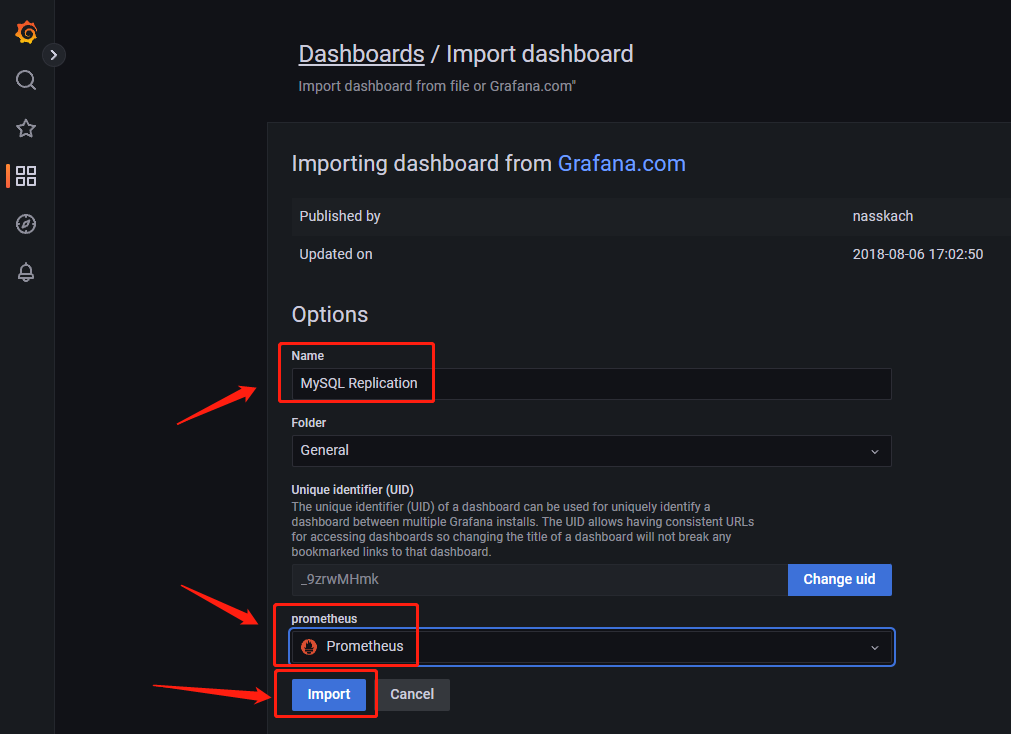
这个页面是监测IO与SQL线程运行状态的,查看从服务器即可
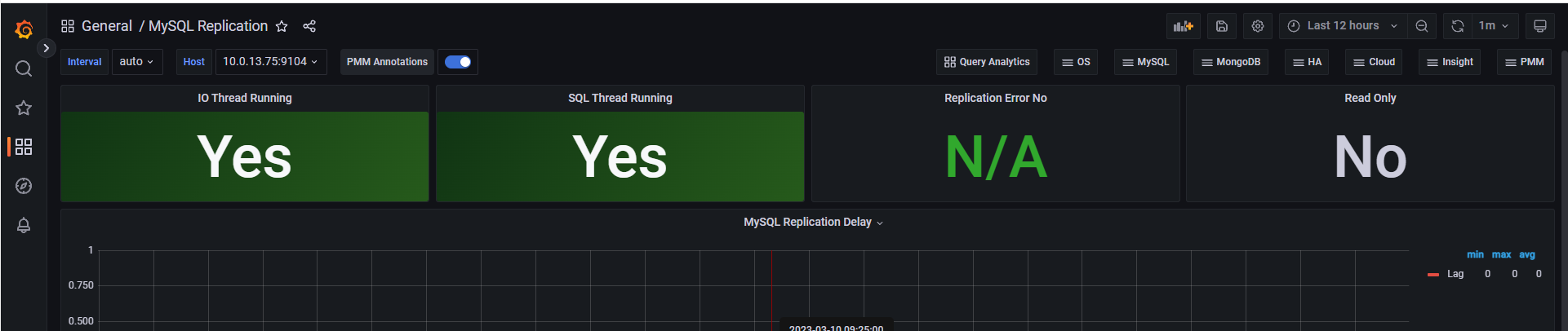
后面可以通过主页的Search dashboards查看已创建的视图
2.5配置告警
来到Prometheus的服务端,编辑告警配置
#切换目录
cd /data/monitor/prometheus
#编辑告警配置,大致为节点运行状态告警,io线程状态告警与sql线程状态告警
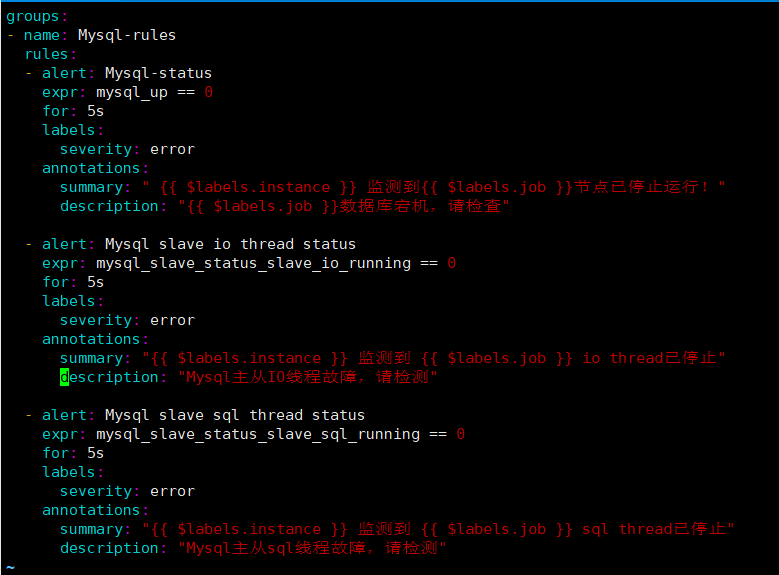
cat >> rules/mysql-status.yaml << EOF
groups:
- name: Mysql-rules
rules:
- alert: Mysql-status
expr: mysql_up == 0
for: 5s
labels:
severity: error
annotations:
summary: " {{ \$labels.instance }} 监测到{{ \$labels.job }}节点已停止运行!"
description: "{{ \$labels.job }}数据库宕机,请检查"
- alert: Mysql slave io thread status
expr: mysql_slave_status_slave_io_running == 0
for: 5s
labels:
severity: error
annotations:
summary: "{{ \$labels.instance }} 监测到 {{ \$labels.job }} io thread已停止"
description: "Mysql主从IO线程故障,请检查"
- alert: Mysql slave sql thread status
expr: mysql_slave_status_slave_sql_running == 0
for: 5s
labels:
severity: error
annotations:
summary: "{{ \$labels.instance }} 监测到 {{ \$labels.job }} sql thread已停止"
description: "Mysql主从sql线程故障,请检查"
EOF
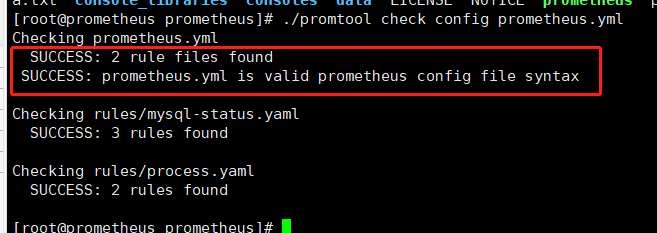
#检查配置文件是否合法
./promtool check config prometheus.yml
#重启服务,加载配置
systemctl restart prometheus
2.6告警测试
来到mysql-slave端与master-master端,关闭mysqld服务
#关闭数据库服务
systemctl stop mysqld
#等待告警信息到来,超过五分钟还没有收到告警信息,则代表配置信息有误
master与slave节点服务状态告警
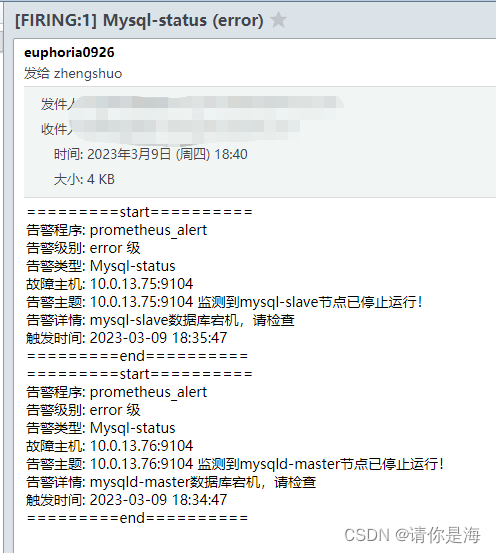
io线程告警
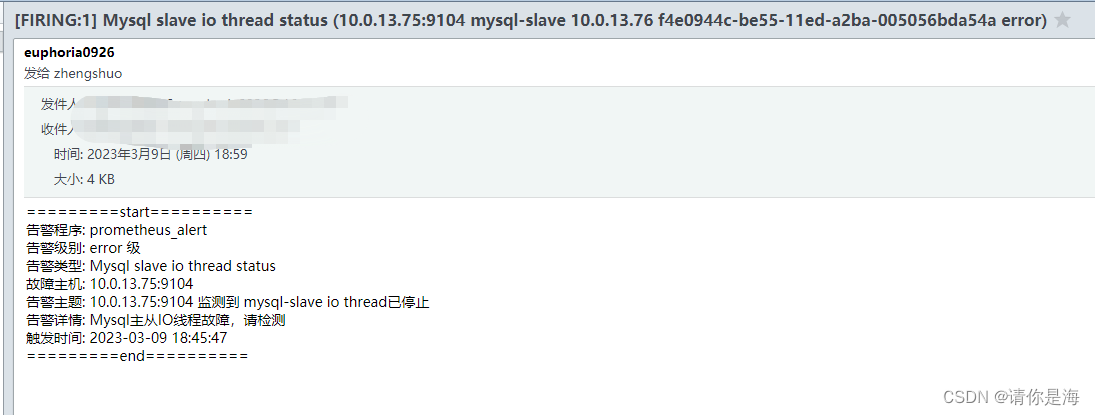
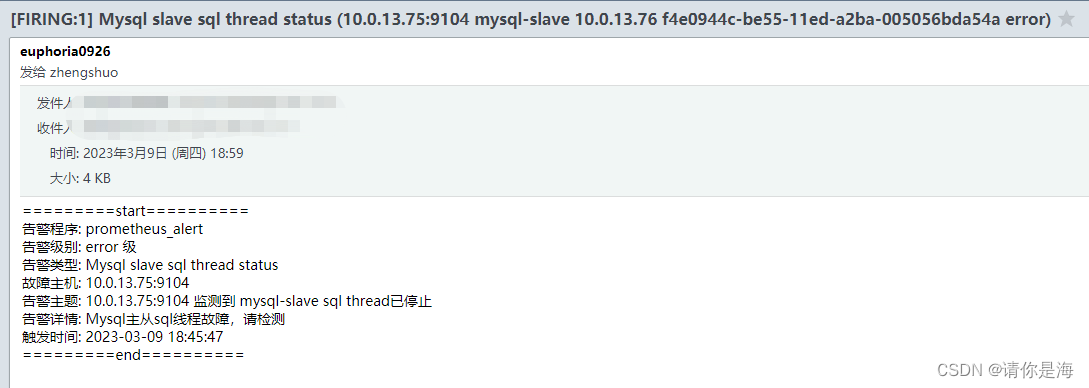
sql线程告警
八、监控Redis
redis的监控需要用的专用的监测器-redis_exporter
我们再对redis进行监控前,注意redis的配置文件内bind的ip地址要包括监测器所在服务器(或0.0.0.0开放全部)
1.单机监控
以下为单机redis的监控操作
1.1安装redis_exporter
redis_exporter的监测方式类似于blackbox_exporter,部署在服务端即可
首先将资源包下载并上传至服务器
#解压至指定目录
tar -zxvf redis_exporter-v1.48.0.linux-amd64.tar.gz -C /data/monitor/
#切换工作目录
cd /data/monitor
#改名
mv redis_exporter-v1.48.0.linux-amd64/ redis_exporter
#切换目录
cd /data/monitor/redis_exporter
#以下为启动时可选用的选项
-redis.addr:指明一个或多个 Redis 节点的地址,多个节点使用逗号分隔,默认为redis://localhost:6379
-redis.password:验证 Redis 时使用的密码;
-redis.file:包含一个或多个 redis 节点的文件路径,每行一个节点,此选项与
-redis.addr 互 斥。-web.listen-address:监听的地址和端口,默认为 0.0.0.0:9121
#启动服务,addr后填自己的ip+port,没有设置密码则无需指定,默认监听端口9121,想要指定端口使用-web.listen-address参数
nohup ./redis_exporter -redis.addr 10.0.13.76:6380 -redis.password '您的密码' & &>/dev/null
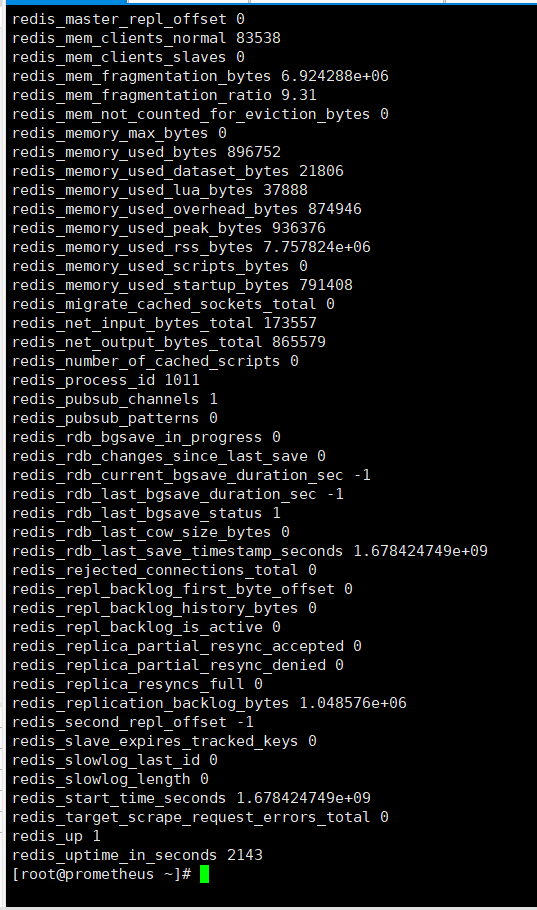
#监测数据获取
curl http://127.0.0.1:9121/metrics
1.2配置Prometheus
来到Prometheus服务端,采集redis_exporter收集到的信息
#切换工作目录
cd /data/monitor/prometheus
#编辑配置文件,注意redis_exporter的地址改为自己的
cat >> prometheus.yml << EOF
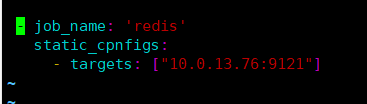
- job_name: 'redis'
static_configs:
- targets: ["10.0.13.76:9121"]
EOF
#检查格式是否合法
./promtool check config prometheus.yml
#重启Prometheus,加载配置
systemctl restart prometheus
1.3配置grafana
登录grafana页面,如图点击import
输入763,如图点击load
名称自定义,数据源选择我们的Prometheus即可点击import
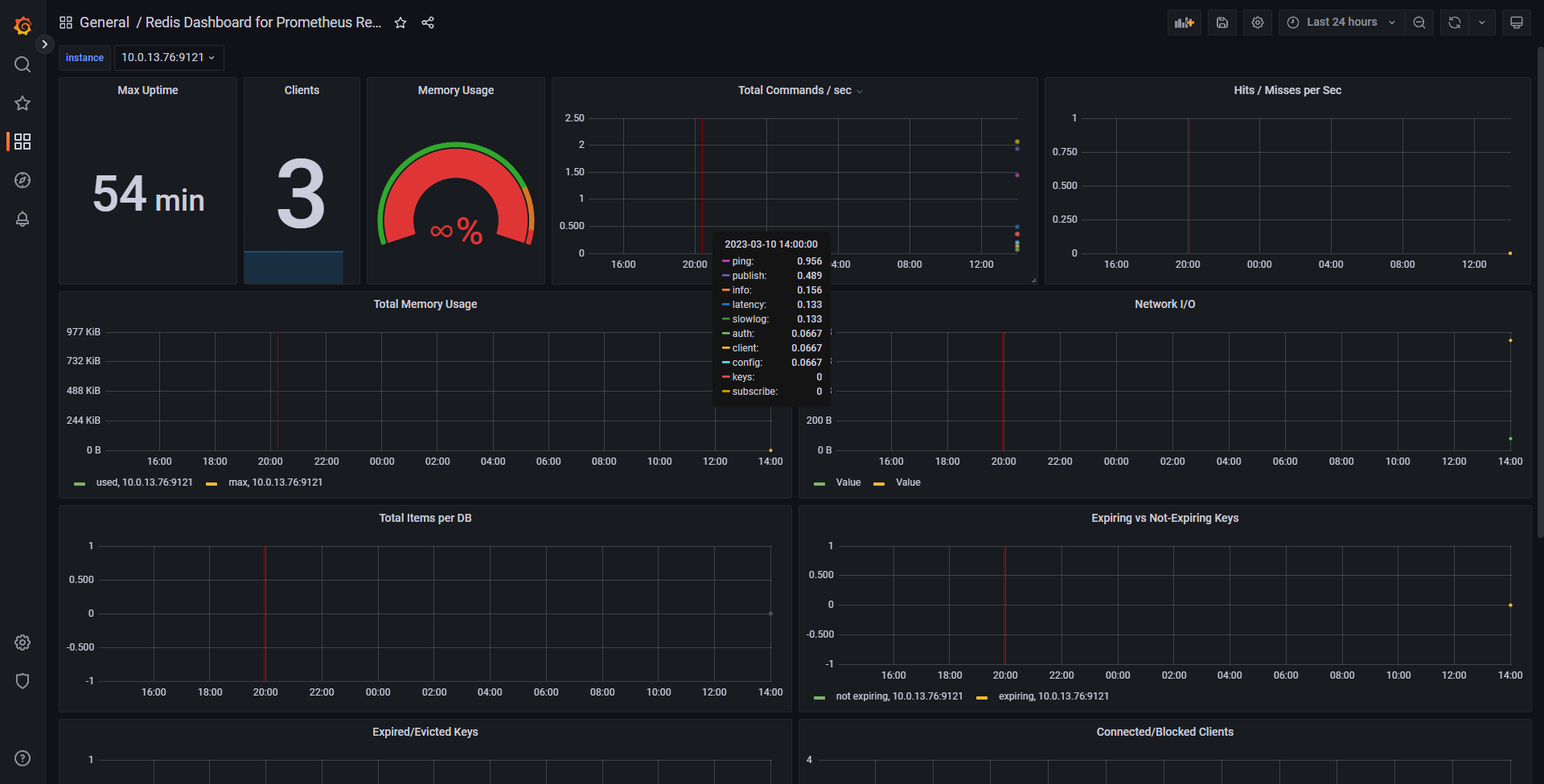
可以看到一些搜集来的数据视图
后续可以通过点击首页的Search dashboards查看我们已创建的视图
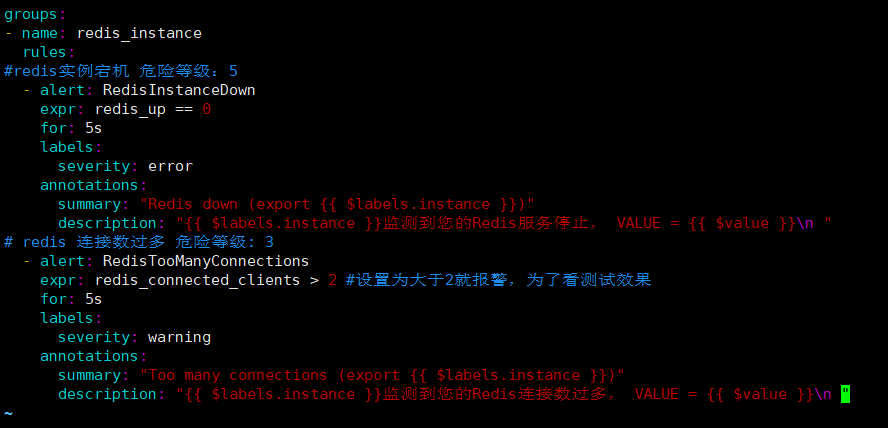
1.4配置告警
来到Prometheus服务端,配置告警规则
#切换目录
cd /data/monitor/prometheus
#编辑配置文件
vim rules/redis.yaml
#添加以下内容
groups:
- name: redis_instance
rules:
#redis实例宕机 危险等级:5
- alert: RedisInstanceDown
expr: redis_up == 0
for: 5s
labels:
severity: error
annotations:
summary: "Redis down (export {{ $labels.instance }})"
description: "{{ $labels.instance }}监测到您的Redis服务停止, VALUE = {{ $value }}\n "
# redis 连接数过多 危险等级: 3
- alert: RedisTooManyConnections
expr: redis_connected_clients > 2 #设置为大于2就报警,为了看测试效果
for: 5s
labels:
severity: warning
annotations:
summary: "Too many connections (export {{ $labels.instance }})"
description: "{{ $labels.instance }}监测到您的Redis连接数过多, VALUE = {{ $value }}\n "
#查看配置文件是否合法
./promtool check config prometheus.yml
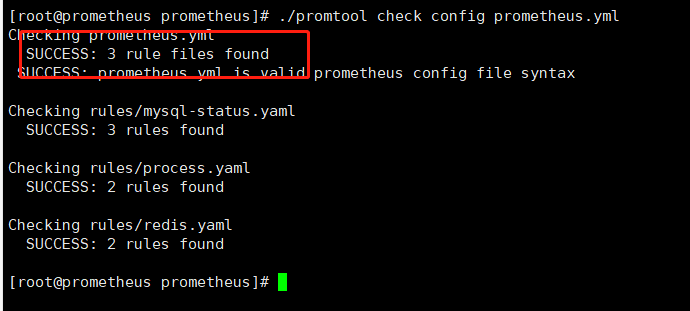
#重启Prometheus,加载配置
systemctl restart prometheus
1.5告警测试
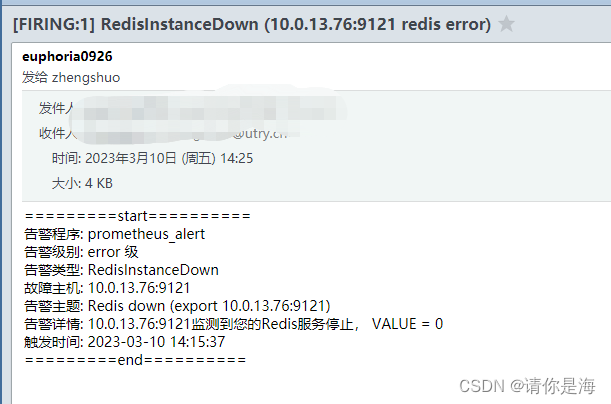
来到redis服务端,关闭redis,等待五分钟查看是否有报警消息
#关闭redis服务
for i in `ps -ef | grep redis | grep -vE "grep|redis_exporter" | awk '{print $2}'` ; do echo "$i killd" ; kill -9 $i ; done
服务状态告警:
连接数告警:
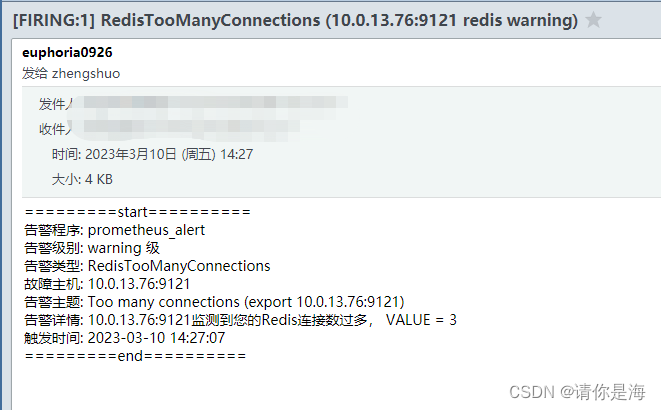
2.集群监控
以下为集群redis的监控操作
资源列表如下
| 主机 | IP | 备注 |
|---|---|---|
| redis-1 | 10.0.13.76 | reids节点一 |
| redis-2 | 10.0.13.72 | redis节点二 |
| redis-3 | 10.0.13.73 | redis节点三 |
2.1安装redis_exporter
虽然redis_exporter可以一个监测多个redis服务
但是我们没用什么特别好的办法把他们进行区分,且reids_exporter占用资源较小,这里推荐要监控的每台redis都部署一个redis_exporter
以下操作redis集群内每台轮流操作
首先将资源包上传至服务器
#解压至指定目录
tar -zxvf redis_exporter-v1.48.0.linux-amd64.tar.gz -C /data/monitor/
#切换工作目录
cd /data/monitor
#改名
mv redis_exporter-v1.48.0.linux-amd64/ redis_exporter
#切换目录
cd /data/monitor/redis_exporter
#以下为启动时可选用的选项
-redis.addr:指明一个或多个 Redis 节点的地址,多个节点使用逗号分隔,默认为redis://localhost:6379
-redis.password:验证 Redis 时使用的密码;
-redis.file:包含一个或多个 redis 节点的文件路径,每行一个节点,此选项与
-redis.addr 互 斥。-web.listen-address:监听的地址和端口,默认为 0.0.0.0:9121
#启动服务,addr后填写本机ip+port,没有设置密码则无需指定,默认监听端口9121,想要指定端口使用-web.listen-address参数
nohup ./redis_exporter -redis.addr 10.0.13.76:6380 -redis.password '您的密码' & &>/dev/null
#监测数据获取
curl http://127.0.0.1:9121/metrics
2.2配置Prometheus
来到Prometheus服务端,采集redis_exporter收集到的信息
#切换目录
cd /data/monitor/prometheus
#编辑配置
cat >> prometheus.yml << EOF
- job_name: 'redis-1'
static_configs:
- targets: ["10.0.13.76:9121"]
- job_name: 'redis-2'
static_configs:
- targets: ["10.0.13.72:9121"]
- job_name: 'redis-3'
static_configs:
- targets: ["10.0.13.73:9121"]
EOF
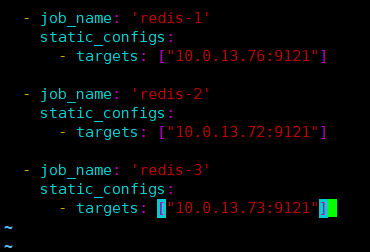
#检测配置是否合法
./promtool check config prometheus.yml
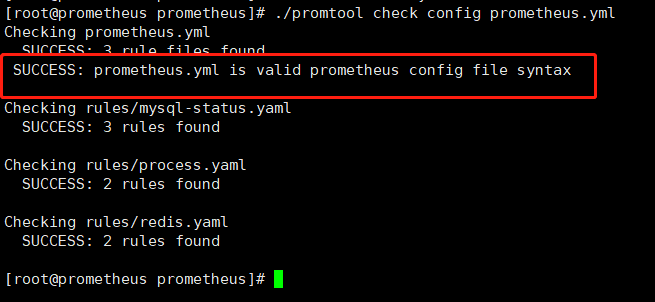
#重启服务,加载配置
systemctl restart prometheus
2.3配置grafana
登录grafana页面,如图点击import
输入763,如图点击load
名称自定义,数据源选择我们的Prometheus即可点击import
可通过点击如图位置,切换监测的主机
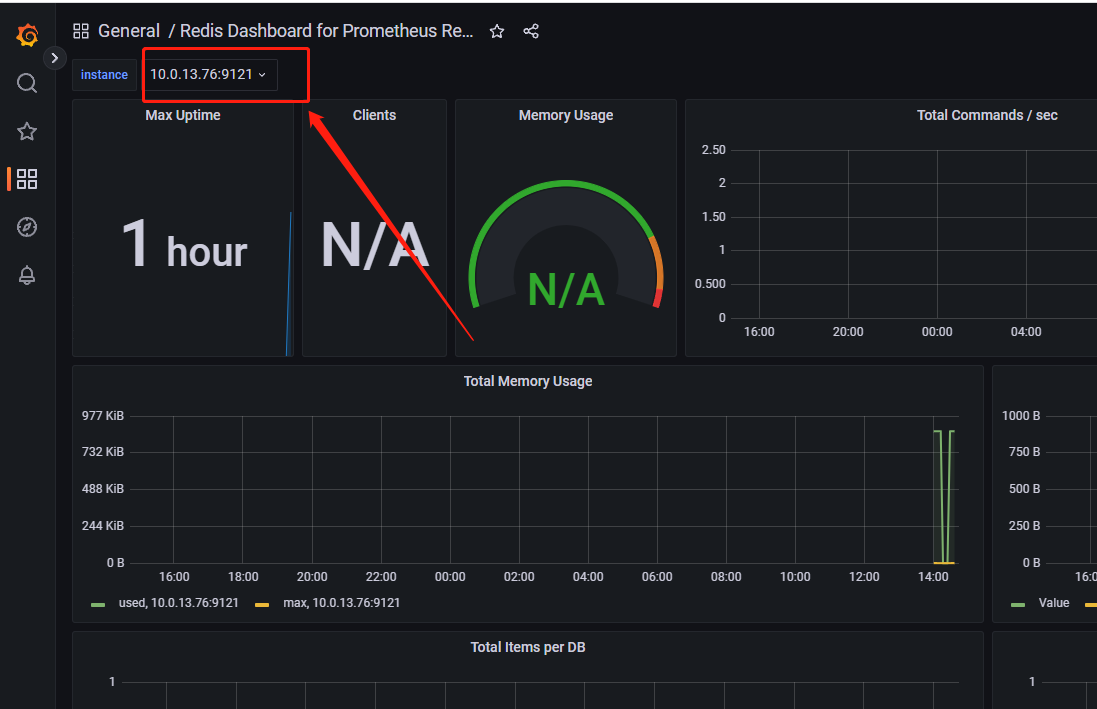
后续可以通过点击首页的Search dashboards查看我们已创建的视图
2.4配置告警
来到Prometheus服务端,进行告警规则配置
#切换目录
cd /data/monitor/prometheus
#编辑配置文件
vim rules/redis.yaml
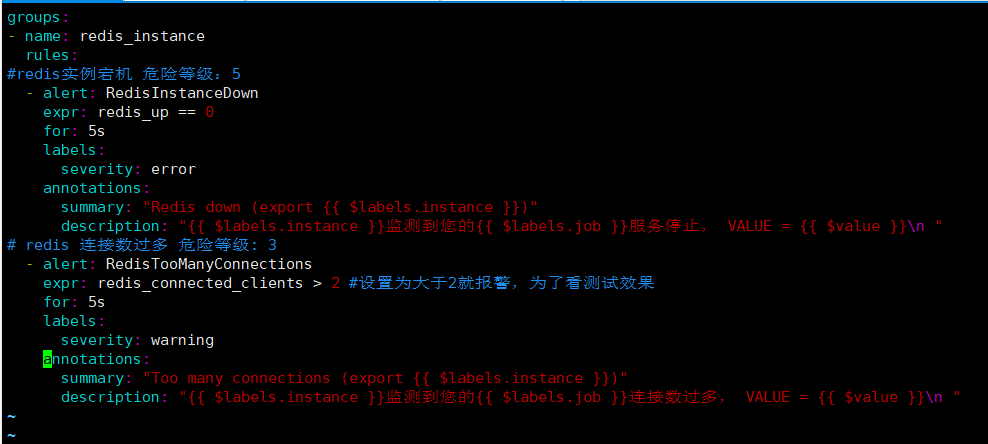
#添加以下内容
groups:
- name: redis_instance
rules:
#redis实例宕机 危险等级:5
- alert: RedisInstanceDown
expr: redis_up == 0
for: 5s
labels:
severity: error
annotations:
summary: "Redis down (export {{ $labels.instance }})"
description: "{{ $labels.instance }}监测到您的{{ $labels.job }}服务停止, VALUE = {{ $value }}\n "
# redis 连接数过多 危险等级: 3
- alert: RedisTooManyConnections
expr: redis_connected_clients > 2 #设置为大于2就报警,为了看测试效果
for: 5s
labels:
severity: warning
annotations:
summary: "Too many connections (export {{ $labels.instance }})"
description: "{{ $labels.instance }}监测到您的{{ $labels.job }}连接数过多, VALUE = {{ $value }}\n "
#检测配置文件是否合法
./promtool check config prometheus.yml
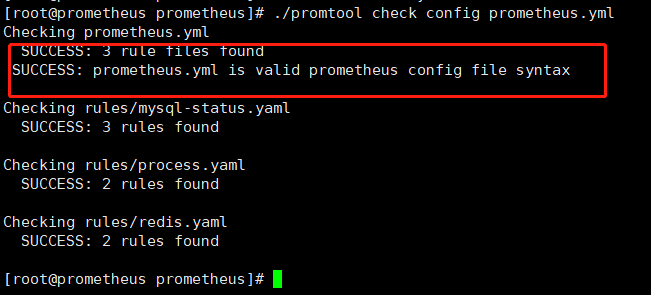
#重启服务,加载配置
systemctl restart prometheus
2.5告警测试
来到redis服务端,关闭redis,等待五分钟查看是否有报警消息
#关闭redis服务
for i in `ps -ef | grep redis | grep -vE "grep|redis_exporter" | awk '{print $2}'` ; do echo "$i killd" ; kill -9 $i ; done
服务状态告警
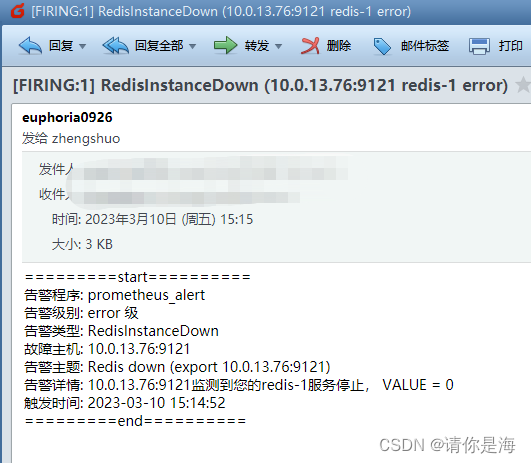
连接数告警
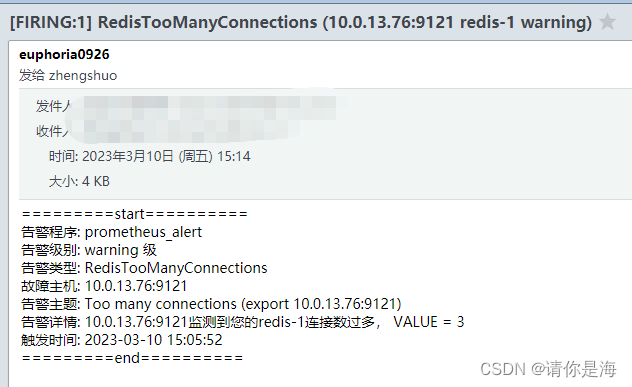
可通过点击如图位置,切换监测的主机
后续可以通过点击首页的Search dashboards查看我们已创建的视图
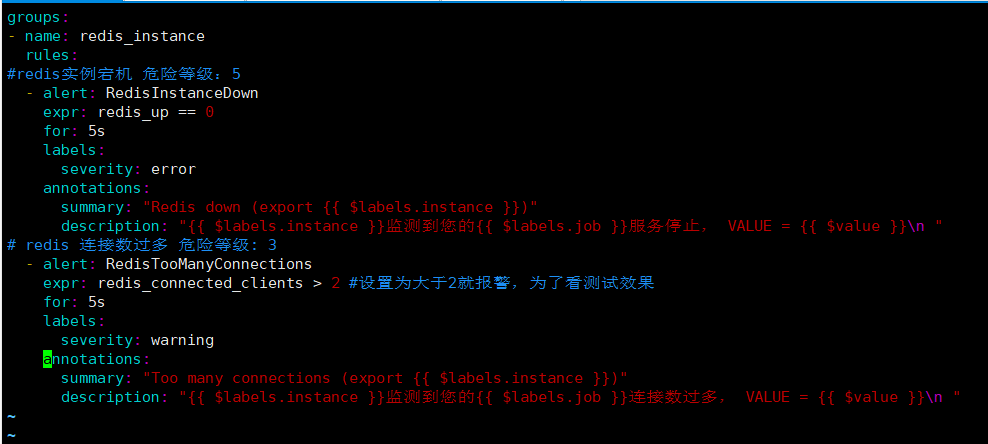
2.4配置告警
来到Prometheus服务端,进行告警规则配置
#切换目录
cd /data/monitor/prometheus
#编辑配置文件
vim rules/redis.yaml
#添加以下内容
groups:
- name: redis_instance
rules:
#redis实例宕机 危险等级:5
- alert: RedisInstanceDown
expr: redis_up == 0
for: 5s
labels:
severity: error
annotations:
summary: "Redis down (export {{ $labels.instance }})"
description: "{{ $labels.instance }}监测到您的{{ $labels.job }}服务停止, VALUE = {{ $value }}\n "
# redis 连接数过多 危险等级: 3
- alert: RedisTooManyConnections
expr: redis_connected_clients > 2 #设置为大于2就报警,为了看测试效果
for: 5s
labels:
severity: warning
annotations:
summary: "Too many connections (export {{ $labels.instance }})"
description: "{{ $labels.instance }}监测到您的{{ $labels.job }}连接数过多, VALUE = {{ $value }}\n "
#检测配置文件是否合法
./promtool check config prometheus.yml
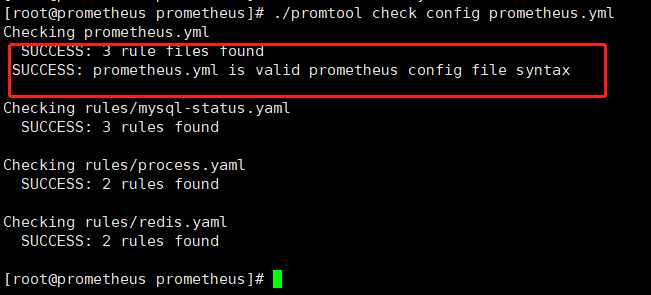
#重启服务,加载配置
systemctl restart prometheus
2.5告警测试
来到redis服务端,关闭redis,等待五分钟查看是否有报警消息
#关闭redis服务
for i in `ps -ef | grep redis | grep -vE "grep|redis_exporter" | awk '{print $2}'` ; do echo "$i killd" ; kill -9 $i ; done
服务状态告警
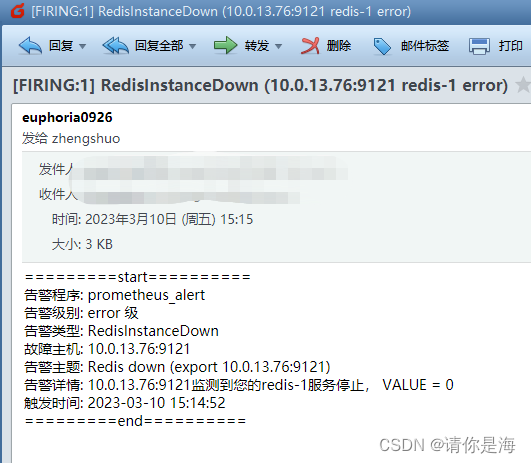
连接数告警
![[外链图片转存中...(img-hB1jt37B-1683267139253)]](https://i-blog.csdnimg.cn/blog_migrate/826bdcf0efd702e9fac172753933380d.png)


















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









