








一、题目
1、题目描述
你需要从空字符串开始 构造 一个长度为 n n n 的字符串 s s s ,构造的过程为每次给当前字符串 前面 添加 一个 字符。构造过程中得到的所有字符串编号为 1 1 1 到 n n n ,其中长度为 i i i 的字符串编号为 s i si si 。比方说,
s = "abaca" ,s1 == "a" ,s2 == "ca" ,s3 == "aca"依次类推。 s i si si 的 得分 为 s i si si 和 s n sn sn 的 最长公共前缀 的长度(注意s == sn)。给你最终的字符串 s s s ,请你返回每一个 s i si si 的 得分之和 。
样例输入:s = "babab"
样例输出:9
2、基础框架
- C语言 给出的基础框架代码如下:
long long sumScores(char * s){
}

3、原题链接
二、解题报告
1、思路分析
(
1
)
(1)
(1) 要求
s
[
i
]
s[i]
s[i] 和
s
[
n
]
s[n]
s[n] 的最长公共前缀,假设原字符串为
S
S
S,对于
s
[
i
]
s[i]
s[i] 表示的是:
s
[
i
]
=
S
[
n
−
i
+
1
:
n
]
s[i] = S[n-i+1: n]
s[i]=S[n−i+1:n]
(
2
)
(2)
(2) 那么问题就转变成了求
S
[
n
−
i
+
1
:
n
]
S[n-i+1: n]
S[n−i+1:n] 和
S
[
1
:
n
]
S[1:n]
S[1:n] 的最长公共前缀。
(
3
)
(3)
(3) 首先我们需要回到一个概念,叫字符串哈希,具体可以参见如下:
对于一个字符串
s
s
s,
s
[
l
:
r
]
s[l:r]
s[l:r] 代表
s
s
s 从
l
l
l 到
r
r
r 的子串;
h
a
s
h
(
s
[
1
:
1
]
)
=
(
s
[
1
]
∗
B
0
)
m
o
d
P
hash(s[1:1]) = ( s[1]*B^{0} ) \mod P
hash(s[1:1])=(s[1]∗B0)modP
h
a
s
h
(
s
[
1
:
2
]
)
=
(
s
[
1
]
∗
B
1
+
s
[
2
]
∗
B
0
)
m
o
d
P
hash(s[1:2]) = ( s[1]*B^{1} + s[2]*B^{0} ) \mod P
hash(s[1:2])=(s[1]∗B1+s[2]∗B0)modP
h
a
s
h
(
s
[
1
:
3
]
)
=
(
s
[
1
]
∗
B
2
+
s
[
2
]
∗
B
1
+
s
[
3
]
∗
B
0
)
m
o
d
P
hash(s[1:3]) = ( s[1]*B^{2} + s[2]*B^{1} + s[3]*B^{0}) \mod P
hash(s[1:3])=(s[1]∗B2+s[2]∗B1+s[3]∗B0)modP
h
a
s
h
(
s
[
1
:
4
]
)
=
(
s
[
1
]
∗
B
3
+
s
[
2
]
∗
B
2
+
s
[
3
]
∗
B
1
+
s
[
4
]
∗
B
0
)
m
o
d
P
hash(s[1:4]) = ( s[1]*B^{3} + s[2]*B^{2} + s[3]*B^{1} + s[4]*B^{0}) \mod P
hash(s[1:4])=(s[1]∗B3+s[2]∗B2+s[3]∗B1+s[4]∗B0)modP
h
a
s
h
(
s
[
1
:
5
]
)
=
(
s
[
1
]
∗
B
4
+
s
[
2
]
∗
B
3
+
s
[
3
]
∗
B
2
+
s
[
4
]
∗
B
1
+
s
[
5
]
∗
B
0
)
m
o
d
P
hash(s[1:5]) = ( s[1]*B^{4} + s[2]*B^{3} + s[3]*B^{2} + s[4]*B^{1} + s[5]*B^{0}) \mod P
hash(s[1:5])=(s[1]∗B4+s[2]∗B3+s[3]∗B2+s[4]∗B1+s[5]∗B0)modP
那么我们如何求
h
a
s
h
(
s
[
3
:
5
]
)
hash(s[3:5])
hash(s[3:5]) 呢?
直接对字符串遍历,得到的结果为
h
a
s
h
(
s
[
3
:
5
]
)
=
(
s
[
3
]
∗
B
2
+
s
[
4
]
∗
B
1
+
s
[
5
]
∗
B
0
)
m
o
d
P
hash(s[3:5]) = ( s[3]*B^{2} + s[4]*B^{1} + s[5]*B^{0}) \mod P
hash(s[3:5])=(s[3]∗B2+s[4]∗B1+s[5]∗B0)modP,那么通过如下减法,得到:
h
a
s
h
(
s
[
1
:
5
]
)
−
h
a
s
h
(
s
[
3
:
5
]
)
=
(
s
[
1
]
∗
B
4
+
s
[
2
]
∗
B
3
)
m
o
d
P
=
B
3
∗
(
s
[
1
]
∗
B
1
+
s
[
2
]
∗
B
0
)
m
o
d
P
=
B
3
∗
h
a
s
h
(
s
[
1
:
2
]
)
m
o
d
P
\begin{aligned}hash(s[1:5]) - hash(s[3:5]) &= ( s[1]*B^{4} + s[2]*B^{3} ) \mod P \\ &= B^3 * ( s[1]*B^{1} + s[2]*B^{0} ) \mod P \\ &= B^3 * hash(s[1:2]) \mod P \end{aligned}
hash(s[1:5])−hash(s[3:5])=(s[1]∗B4+s[2]∗B3)modP=B3∗(s[1]∗B1+s[2]∗B0)modP=B3∗hash(s[1:2])modP
移项后整理式子,得到:
h
a
s
h
(
s
[
3
:
5
]
)
=
(
h
a
s
h
(
s
[
1
:
5
]
)
−
B
3
∗
h
a
s
h
(
s
[
1
:
2
]
)
)
m
o
d
P
hash(s[3:5]) = ( hash(s[1:5]) - B^3 * hash(s[1:2]) ) \mod P
hash(s[3:5])=(hash(s[1:5])−B3∗hash(s[1:2]))modP
那么对于更加一般的情况,令
h
(
r
)
=
h
a
s
h
(
s
[
1
:
r
]
)
h(r) = hash(s[1:r])
h(r)=hash(s[1:r]),有:
h
a
s
h
(
s
[
l
:
r
]
)
=
(
h
(
r
)
−
B
r
−
l
+
1
∗
h
(
l
−
1
)
)
m
o
d
P
hash(s[l:r]) = ( h(r) - B^{r-l+1} * h(l-1) ) \mod P
hash(s[l:r])=(h(r)−Br−l+1∗h(l−1))modP
其中
h
(
i
)
h(i)
h(i) 和
B
i
B^i
Bi 都可以事先一次线性扫描预处理后放在数组中,则每次取子串哈希值的时间复杂度为
O
(
1
)
O(1)
O(1)。
对于字符串哈希更加深入的内容,可以参考:夜深人静写算法(九)- 哈希表。
(
4
)
(4)
(4) 字符串哈希的模板如下:
#define ull unsigned long long
#define maxn 100010
#define P 10207
ull h[maxn], p[maxn];
void initHash(const char *s) {
// 这个字符串是从 1 - n-1
int n = strlen(s);
int i;
p[0] = 1;
h[0] = 0;
for(i = 1; i < n; ++i) {
h[i] = h[i-1] * P + s[i];
p[i] = p[i-1] * P;
}
}
ull getSubHash(int l, int r) {
return h[r] - h[l-1] * p[r - l + 1];
}
( 5 ) (5) (5) 于是,对于每个位置 i i i,只要二分长度,然后通过字符串哈希求出最长的公共子串,累加长度就是答案了。
2、时间复杂度
最坏时间复杂度 O ( n l o g n ) O(nlogn) O(nlogn) 。
3、代码详解
#define ull unsigned long long
#define maxn 100010
#define P 10207
ull h[maxn], p[maxn];
void initHash(const char *s) {
// 这个字符串是从 1 - n-1
int n = strlen(s);
int i;
p[0] = 1;
h[0] = 0;
for(i = 1; i < n; ++i) {
h[i] = h[i-1] * P + s[i];
p[i] = p[i-1] * P;
}
}
ull getSubHash(int l, int r) {
return h[r] - h[l-1] * p[r - l + 1];
}
class Solution {
public:
long long sumScores(string s) {
s = "#" + s;
long long ret = 0;
int n = s.size() - 1;
initHash(s.c_str());
for(int i = 1; i <= n; ++i) {
int l1 = n - i + 1;
int l2 = 1;
int l = 1, r = i;
int ans = 0;
while(l <= r) {
int mid = (l + r) >> 1;
if(getSubHash(l1, l1 + mid - 1) == getSubHash(l2, l2 + mid - 1)) {
ans = mid;
l = mid + 1;
}else {
r = mid - 1;
}
}
ret += ans;
}
return ret;
}
};
三、本题小知识
字符串哈希的问题,可以解决很多比较难想的字符串问题(代替 KMP、后缀树组 等等)。

四、加群须知
相信看我文章的大多数都是「 大学生 」,能上大学的都是「 精英 」,那么我们自然要「 精益求精 」,如果你还是「 大一 」,那么太好了,你拥有大把时间,当然你可以选择「 刷剧 」,然而,「 学好算法 」,三年后的你自然「 不能同日而语 」。
那么这里,我整理了「 几十个基础算法 」 的分类,点击开启:
如果链接被屏蔽,或者有权限问题,可以私聊作者解决。

大致题集一览:
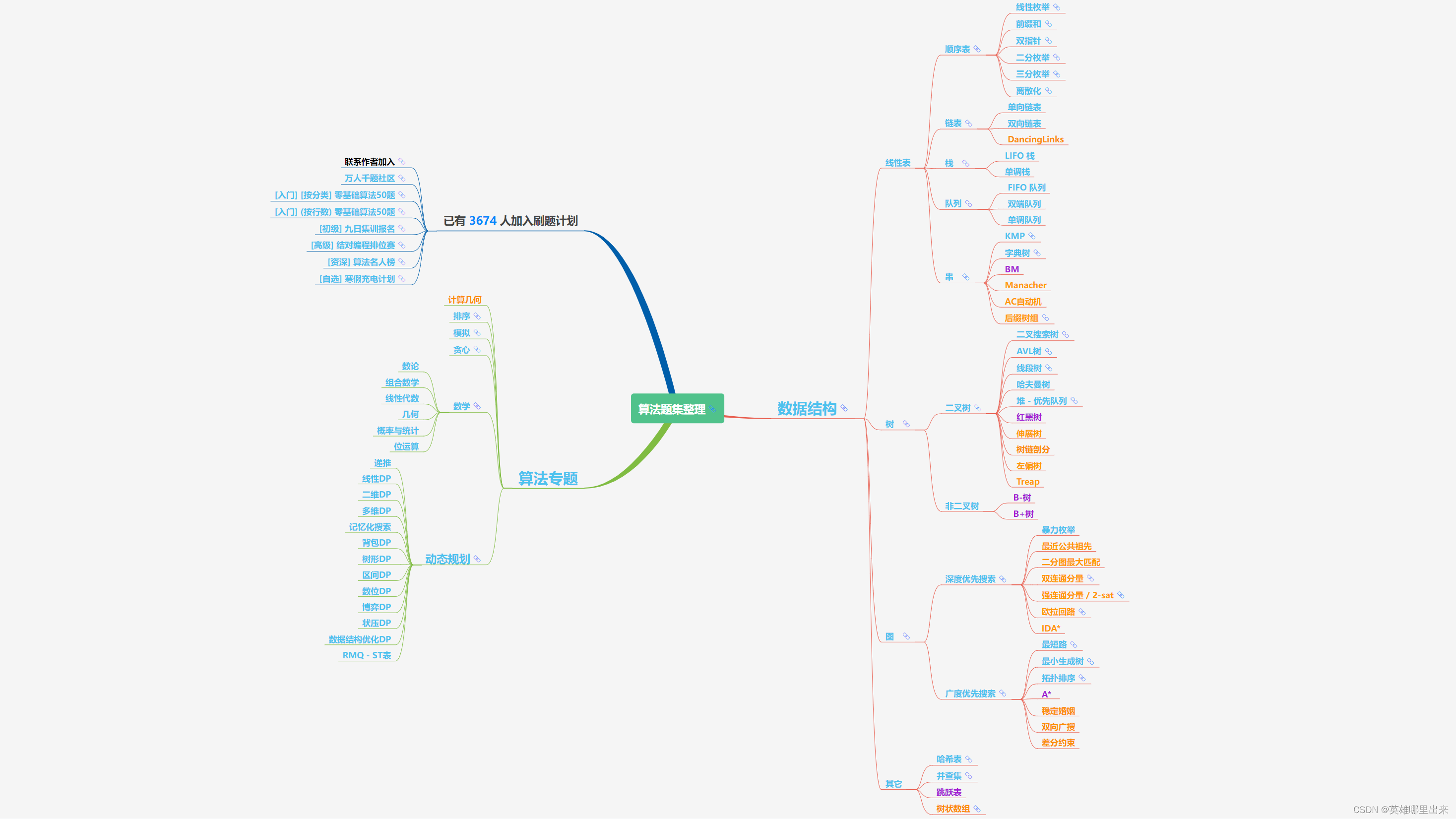
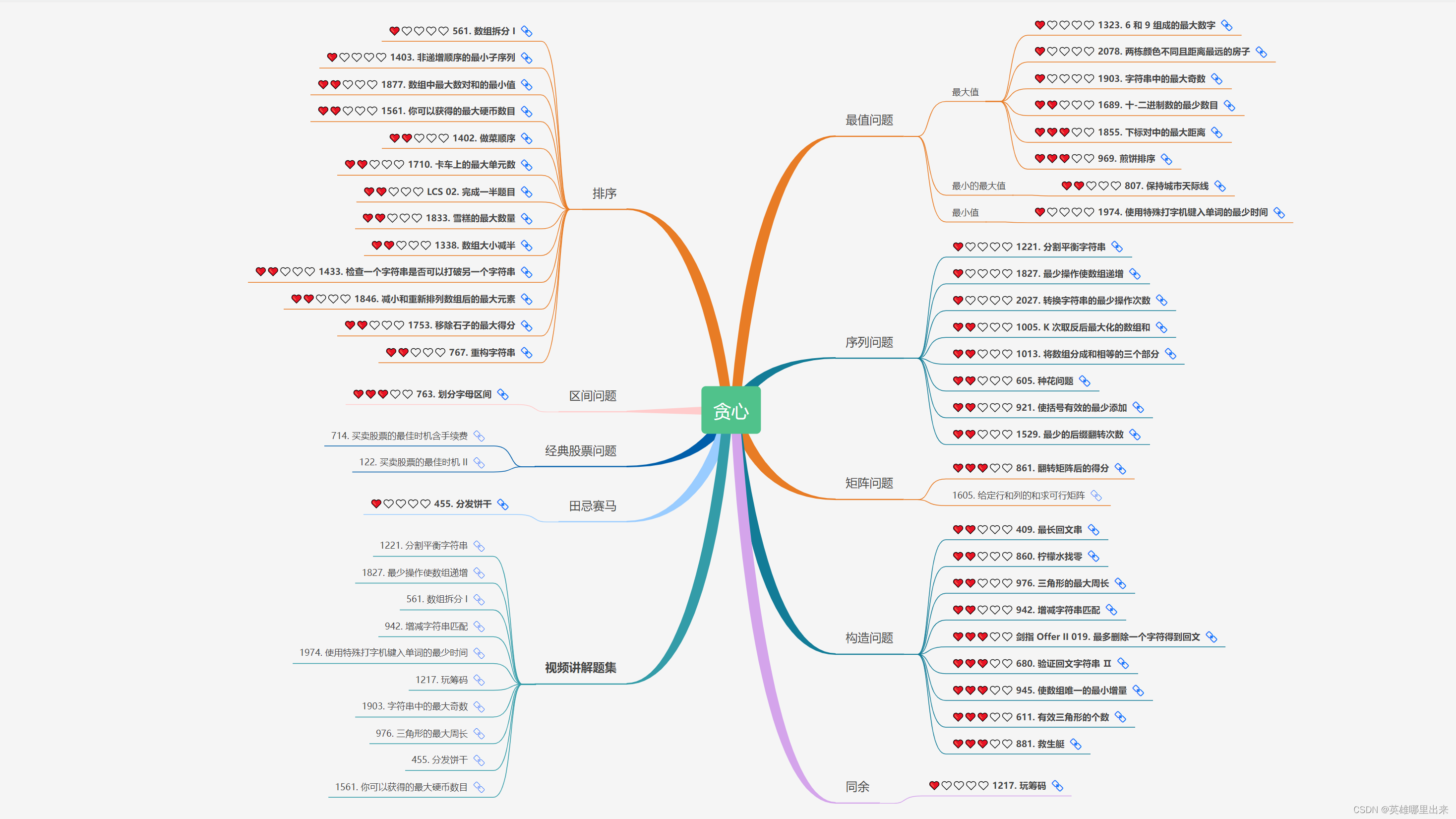
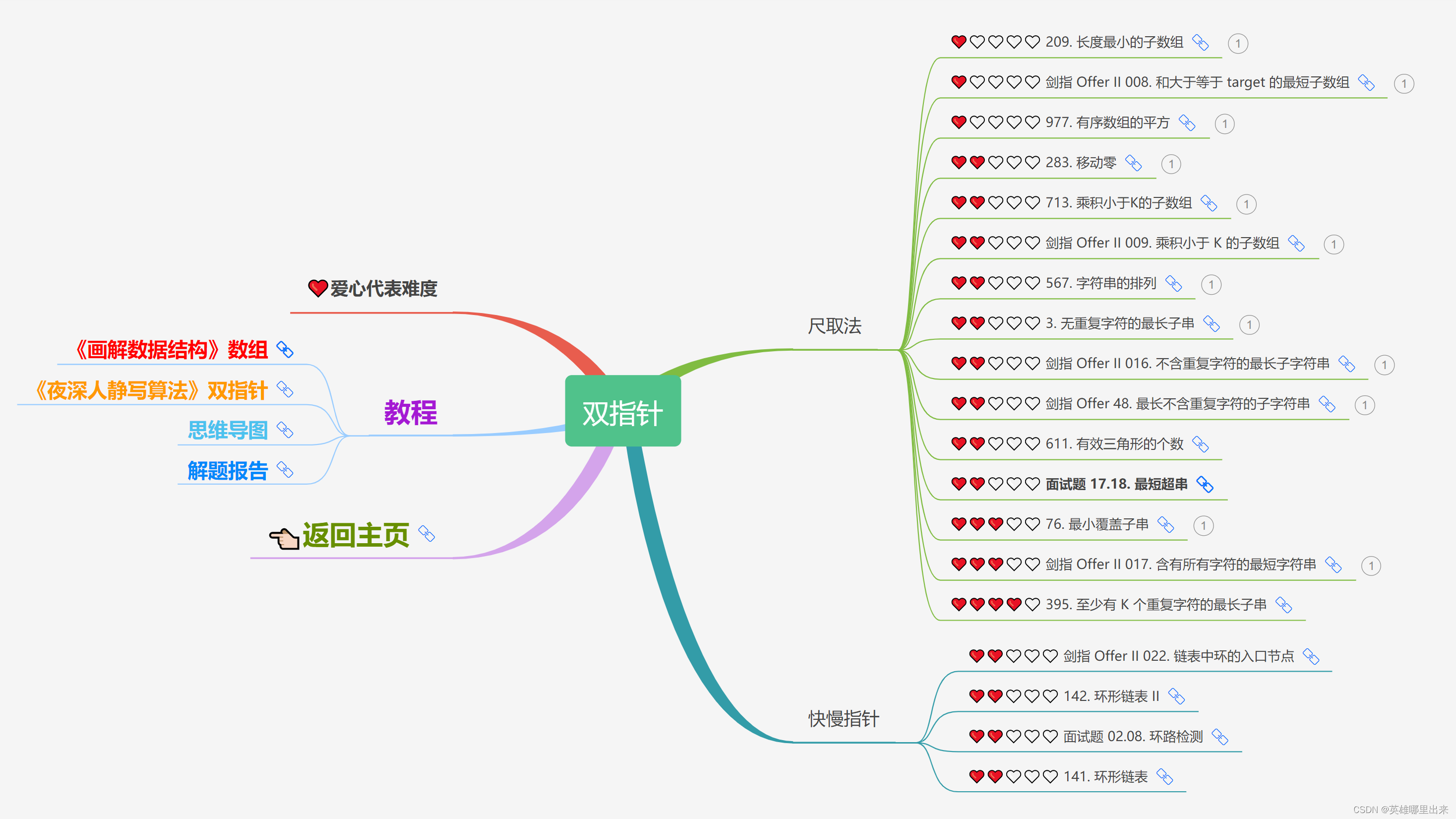

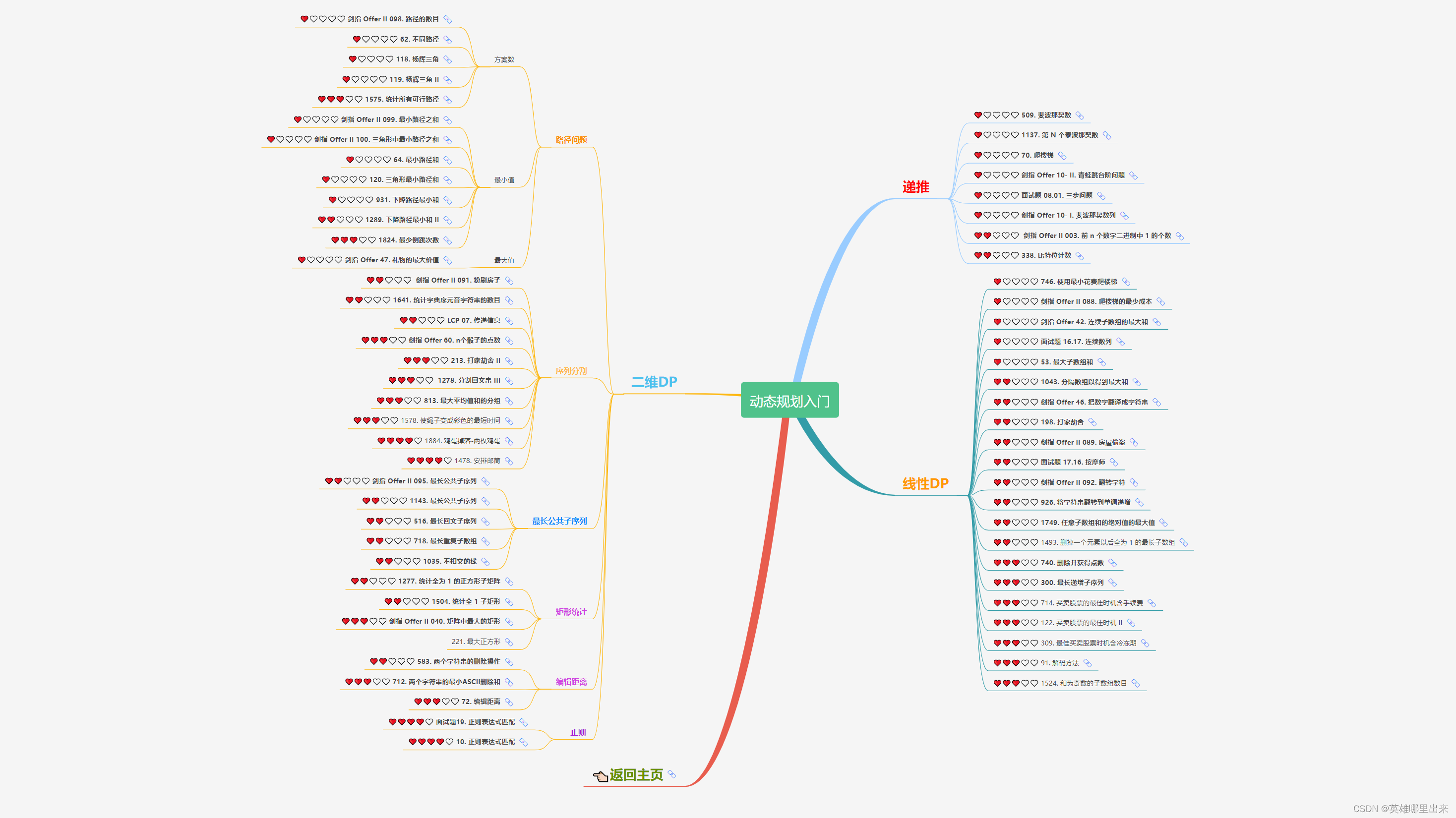
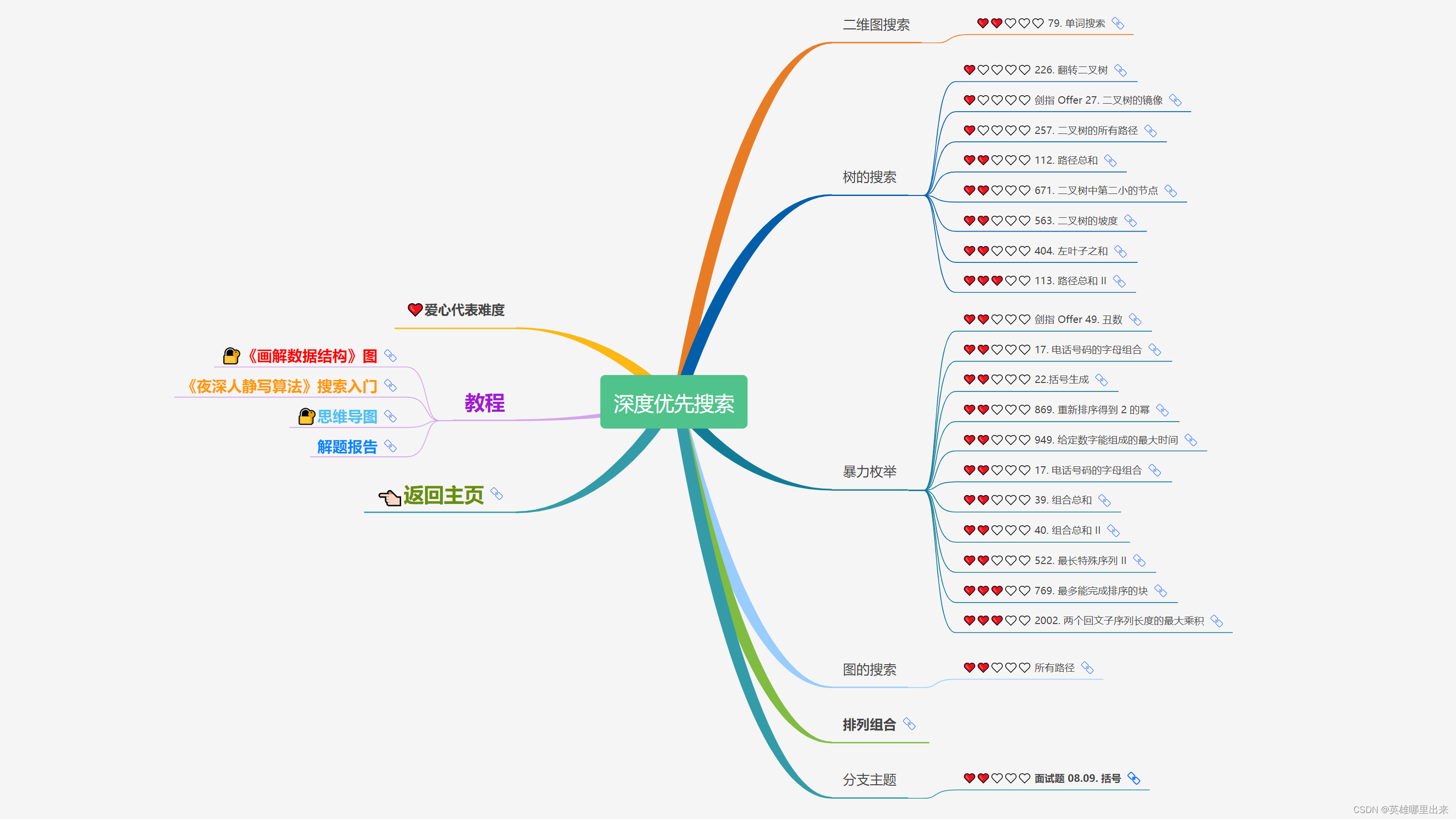
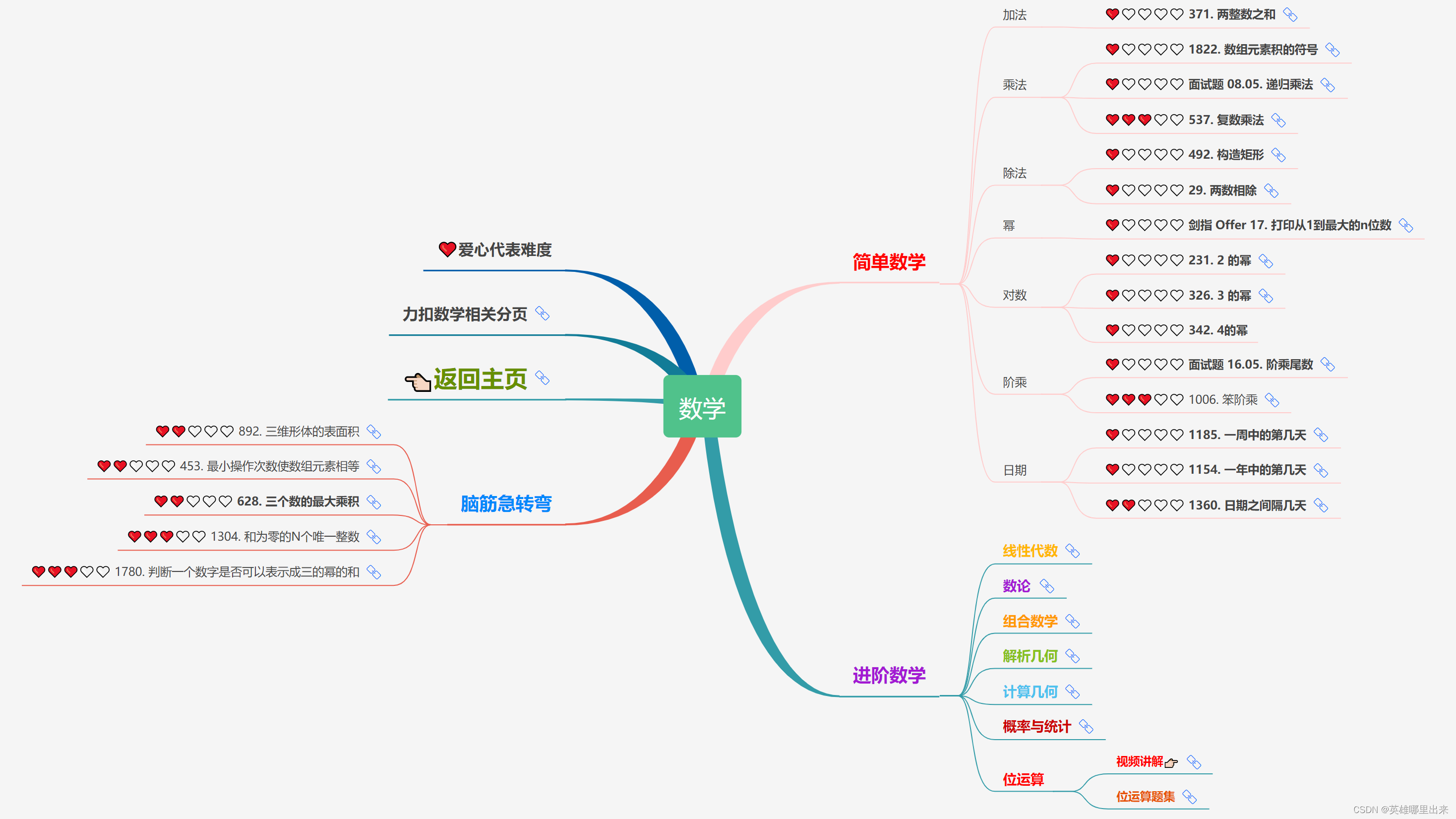
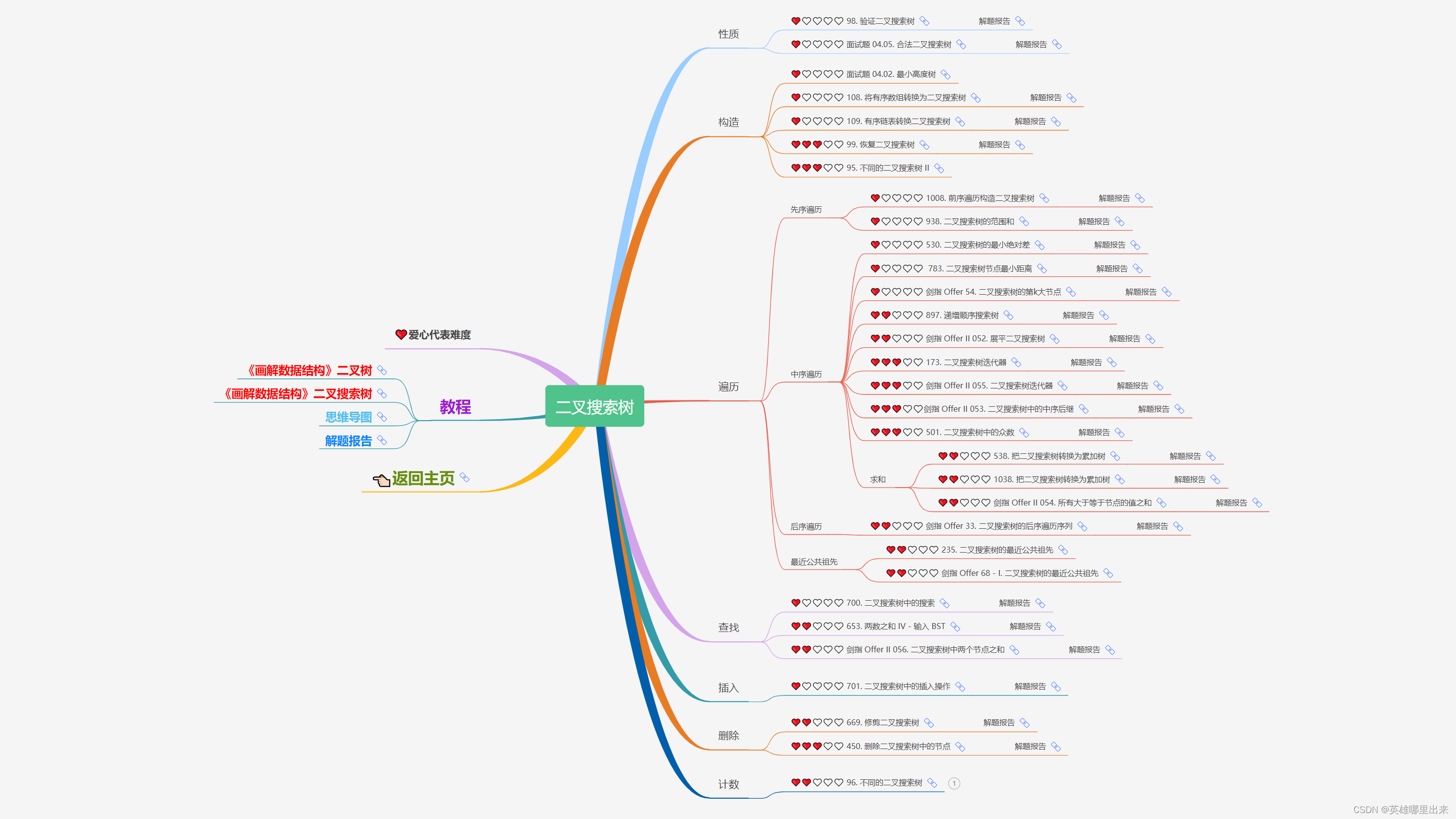
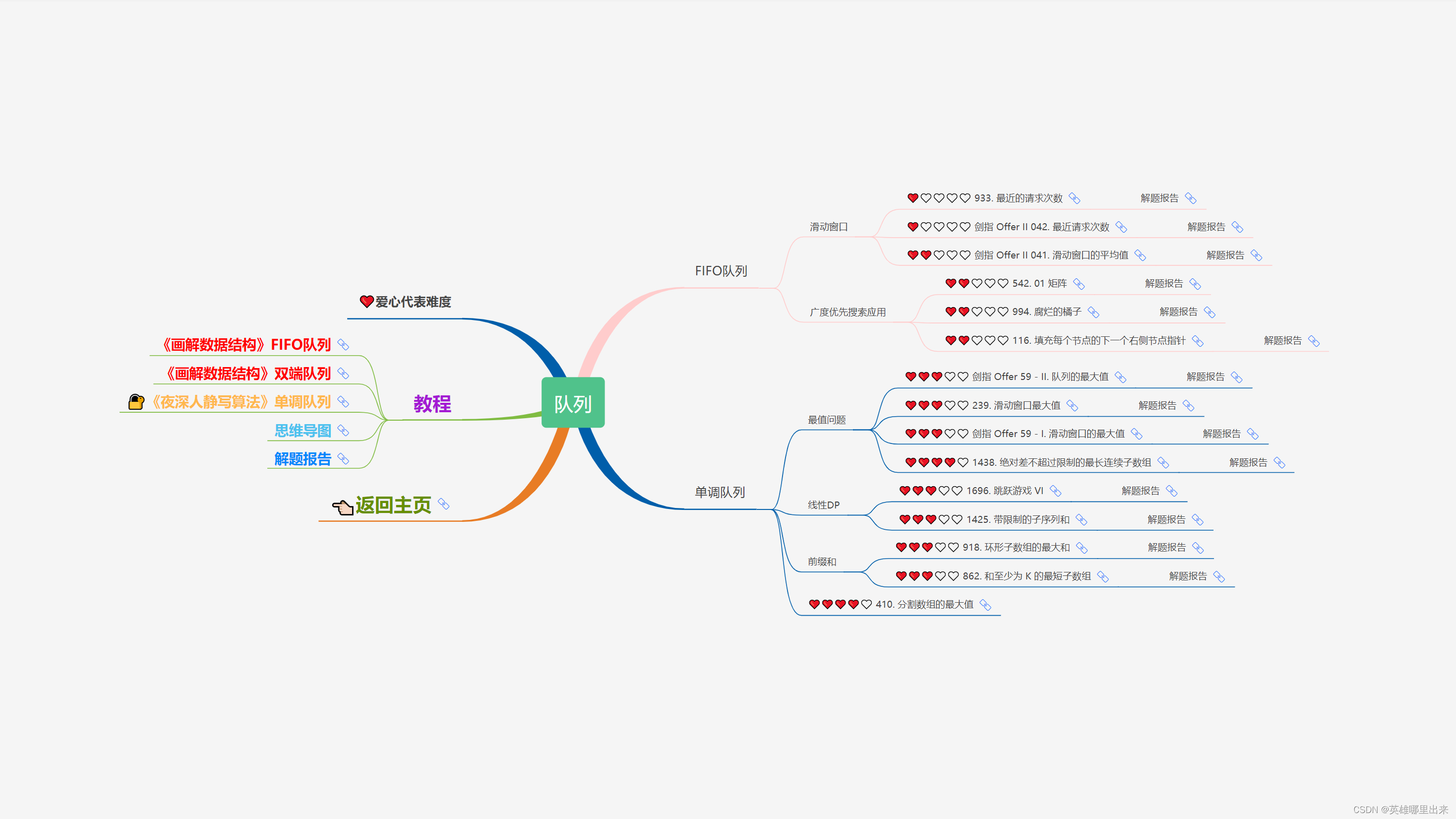
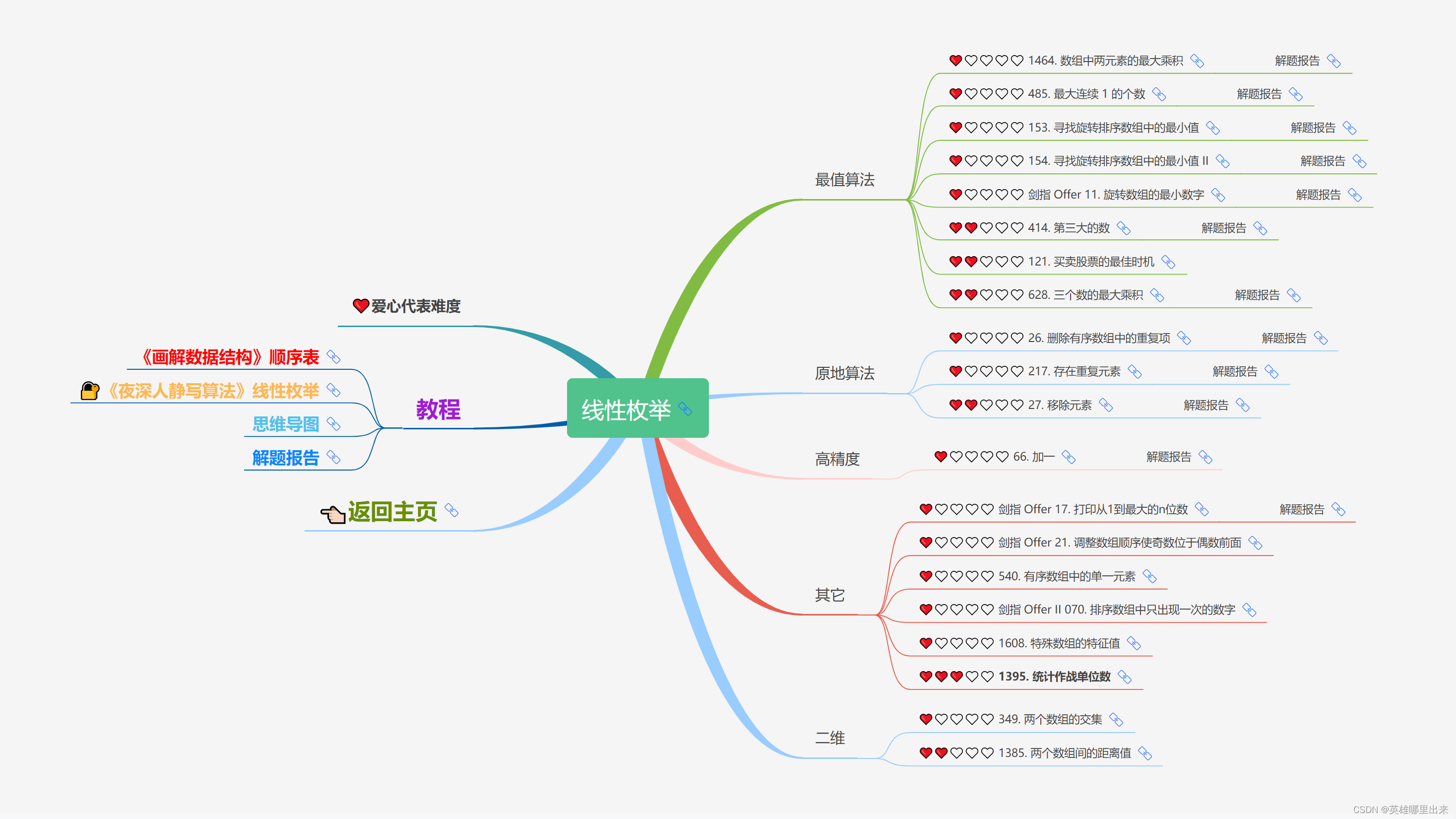
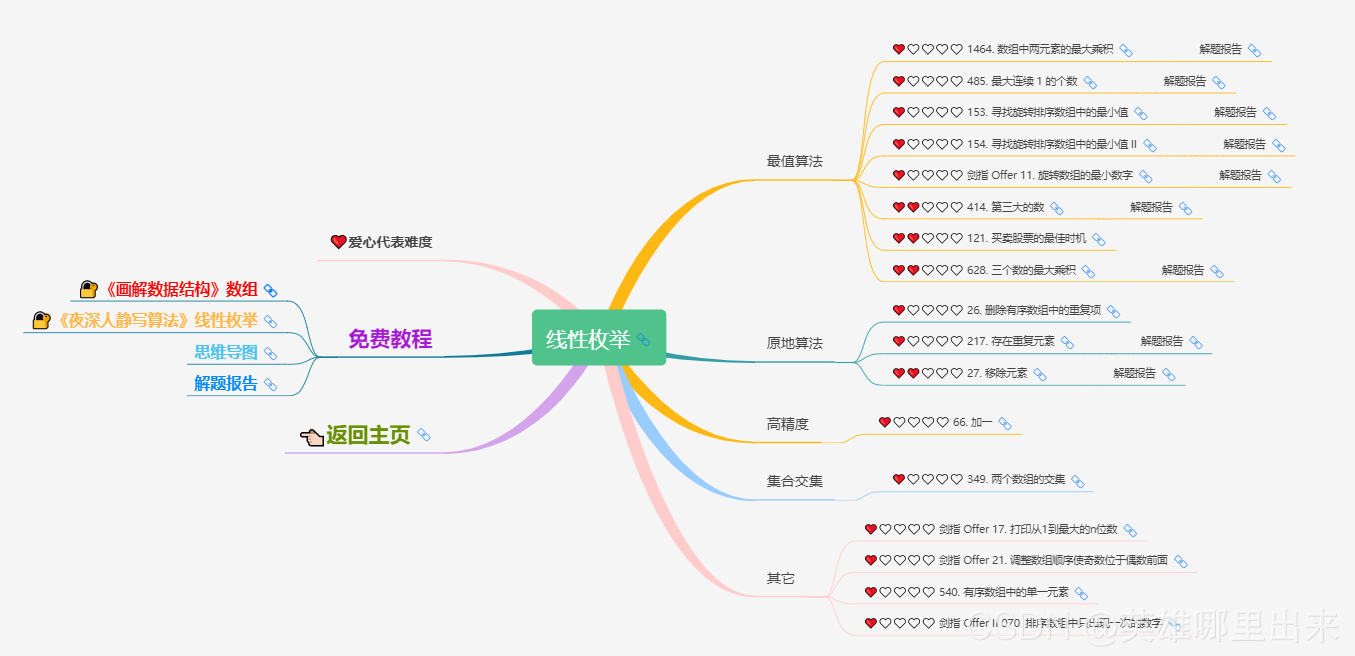
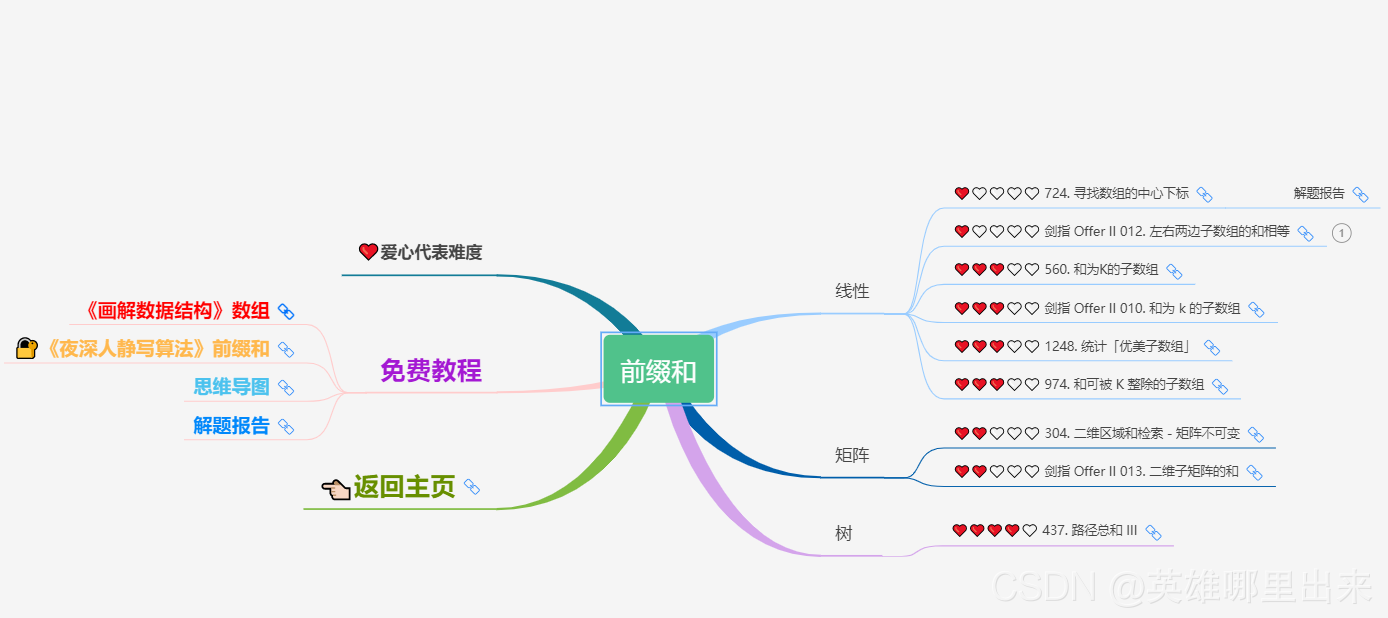
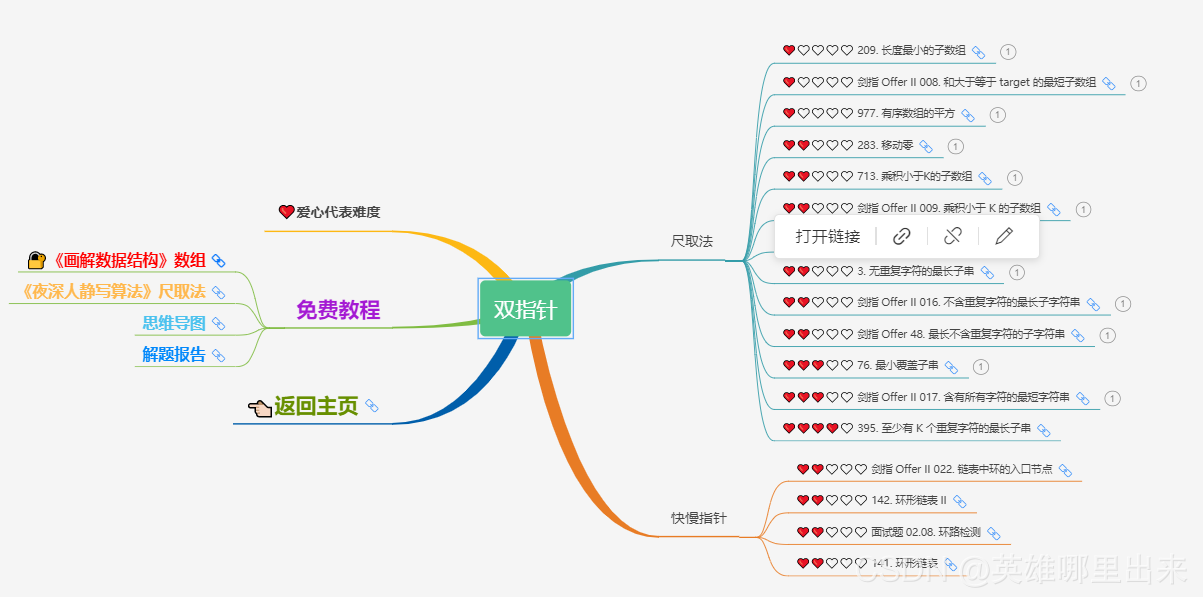
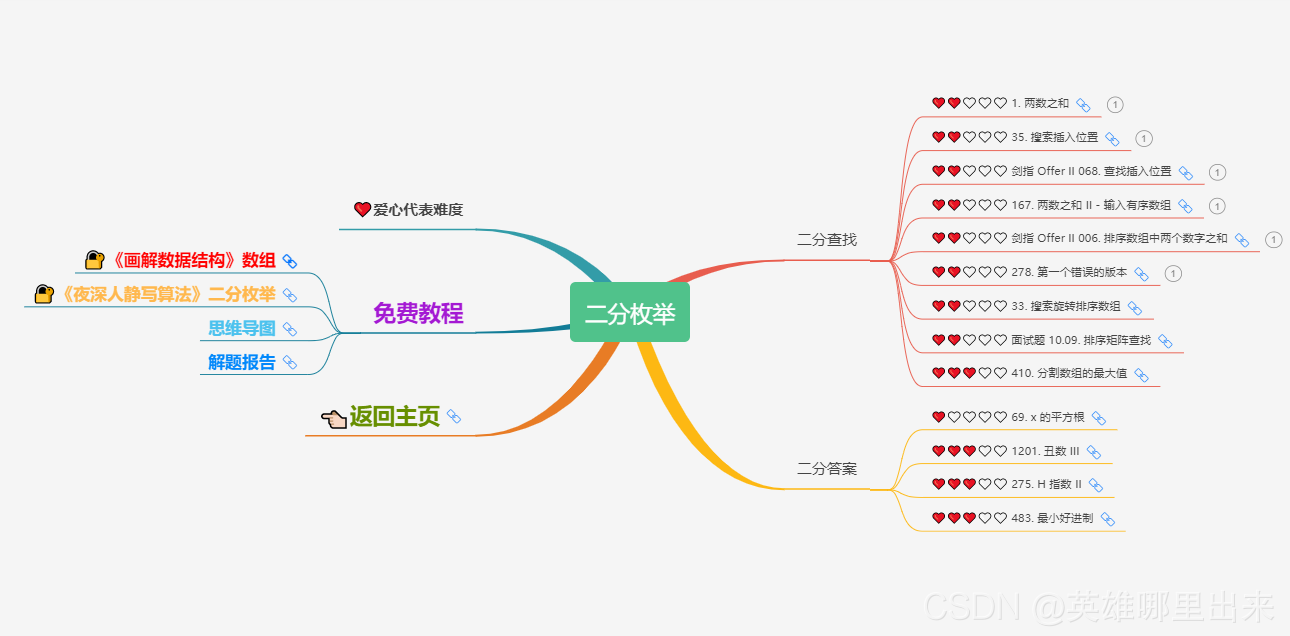
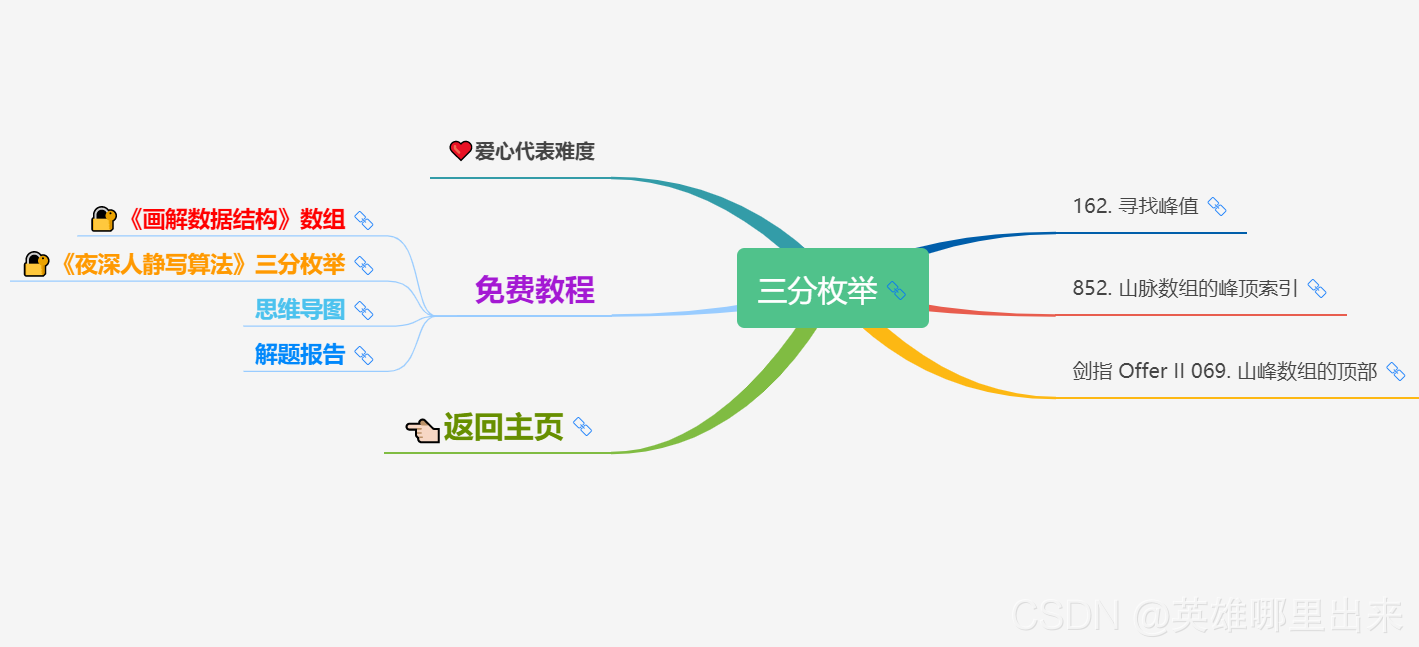
为了让这件事情变得有趣,以及「 照顾初学者 」,目前题目只开放最简单的算法 「 枚举系列 」 (包括:线性枚举、双指针、前缀和、二分枚举、三分枚举),当有 一半成员刷完 「 枚举系列 」 的所有题以后,会开放下个章节,等这套题全部刷完,你还在群里,那么你就会成为「 夜深人静写算法 」专家团 的一员。
不要小看这个专家团,三年之后,你将会是别人 望尘莫及 的存在。如果要加入,可以联系我,考虑到大家都是学生, 没有「 主要经济来源 」,在你成为神的路上,「 不会索取任何 」。
🔥联系作者,或者扫作者主页二维码加群,加入刷题行列吧🔥
🔥让天下没有难学的算法🔥
C语言免费动漫教程,和我一起打卡! 🌞《光天化日学C语言》🌞
让你养成九天持续刷题的习惯 🔥《九日集训》🔥
入门级C语言真题汇总 🧡《C语言入门100例》🧡
组团学习,抱团生长 🌌《算法零基础100讲》🌌
几张动图学会一种数据结构 🌳《画解数据结构》🌳
竞赛选手金典图文教程 💜《夜深人静写算法》💜
















 1365
1365











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











