







本文从多模态大模型相关概念出发,并以Flamingo 模型为例,探讨了基于多模态大模型训练的演进与前瞻。新一代训练范式包括统一架构、数据工程革新和动态适应机制,以提升跨模态推理能力和长视频理解。
多模态大模型
定义
什么是多模态大模型?
模态(Modality):指数据的一种类型或形式,如文本、图像、音频等。例如,图像是视觉模态,文本是语言模态。
多模态(Multimodal):涉及两种或更多不同信号类型的模态。例如,多模态研究可能探讨文本和图像的结合使用。
多模态模型(Multimodal Model):能处理和整合多种模态数据的AI模型。例如,模型能同时理解和生成文本描述的图像。
多模态系统(Multimodal System):能处理多种模态输入和输出的系统。例如,智能助手既能解析语音指令(音频输入)也能以文字回复(文本输出);ChatGPT增加了视觉问答;微信既可以纯文字聊天,又可以语音转文字,文字转语音,还集成了识别图像中文字的功能。
多模态大模型(Multimodal Large Language Models, MLLMs):将额外的模态融入大语言模型(LLMs),也就是将大语言模型扩展到多种数据类型,例如,OpenAI的GPT-4、微软的Kosmos-1和谷歌的PaLM-E都是近年来由科技巨头公司构建的多模态大模型示例。
多模态大模型 vs 多模态模型?
主要在于它们的规模和能力。多模态大模型利用大语言模型作为基础,具有处理和理解多种模态(如文本、图像等)数据的能力,可以实现先进的、跨模态的任务处理能力。而多模态模型可能指的是更广泛的概念,包括任何能够处理多种类型模态数据的模型,无论其规模大小。比如有些文生图模型,也是属于多模态模型,但并没有集成语言模型的组件,不能称之为多模态大模型。
多模态大模型的训练方式
传统方法
传统的训练方法主要是通过Seq2Seq,例如Image Caption,主要采用End-to-End训练方式。
具体实现逻辑可以概括为:
训练数据<Image1, Des1>,<Image2, Des2>,…,<Image n, Des n>
早期的训练项目示例:flamingo
Flamingo 模型是视觉语言模型(VLM)的一个代表性模型,核心目标是通过融合视觉和文本信息实现更接近人类认知的跨模态推理能力,其核心创新与应用价值延续至今。
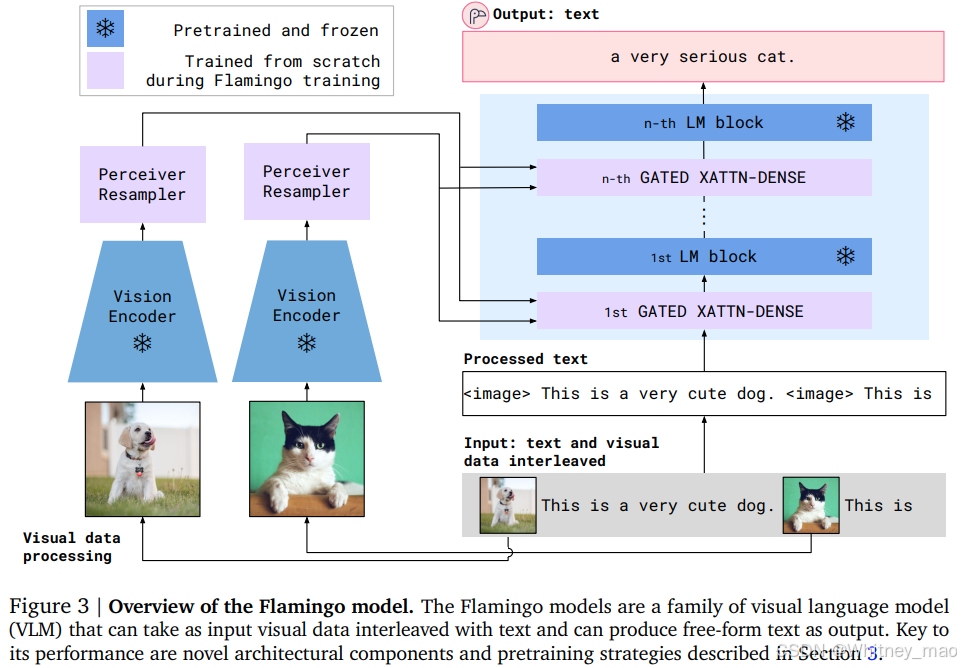
1. 架构设计的范式突破
- 双流异构编码器
视觉分支采用改进的 NFNet(Normalizer-Free ResNet)作为骨干网络,通过消除批量归一化层降低训练内存消耗;文本分支则基于稀疏激活的 Chinchilla 模型(700 亿参数),通过参数复用提升计算效率。两模态的异构设计体现了硬件约束下的工程优化智慧。 - Perceiver 重采样机制
针对视觉特征与语言模型维度不匹配问题,引入 Perceiver Resampler 模块:- 使用可学习的 latent query 对图像块特征进行交叉注意力聚合
- 输出固定长度的视觉 token 序列(如 64 tokens)
- 该机制使模型可处理任意分辨率的输入图像,显著提升泛化能力
- 门控交叉注意力(Gated XATTN-DENSE)
在语言模型每层插入可学习的门控单元,动态调节视觉信号对文本生成的贡献度。数学表达为:
h’ = h + σ(α) * Attn(h, V)
其中, α 为可学习门控参数,σ 为 sigmoid 函数,实现了模态融合的软切换。
2. 训练范式的创新
-
交错序列建模
输入序列形式如 [图像_1, 文本_1, 图像_2, 文本_2, …],模型需要建立跨模态的因果依赖关系。通过掩码矩阵控制注意力范围,确保每个位置的预测仅依赖历史信息。 -
混合训练策略
- 预训练阶段:使用 43M 图文对(ALT-400M 数据集)进行跨模态对齐
- 微调阶段:在 1.5M 交错多模态序列(网页抓取数据)上优化上下文学习能力
- 采用梯度累积和模型并行解决显存瓶颈
-
稀疏激活技术
语言模型部分采用条件计算(Conditional Computation),仅激活约 20%的神经元处理视觉信号,在保持模型容量的同时显著降低计算开销。
3. 小结
Flamingo 的技术路线揭示了多模态智能的演进方向:通过架构创新实现模态深度融合,利用大规模预训练捕获跨模态关联,最终在少样本场景下展现类人的推理能力。Flamingo 模型通过多模态预训练和架构创新,已显著缓解了传统单任务训练模式下的数据依赖和计算效率问题,但仍会面临几个核心问题:
- 传统单任务训练需为每个 Image Caption 任务独立建模,本质上是未建立跨任务的共享表征空间。Flamingo 的解决方案已部分突破该限制,但仍需通过微调适配下游任务。
- 传统监督学习需为每个任务收集大规模标注数据(如 COCO Caption 需 12 万人工标注图文对),成本高昂且不可持续。
更有“潜力”的训练方法
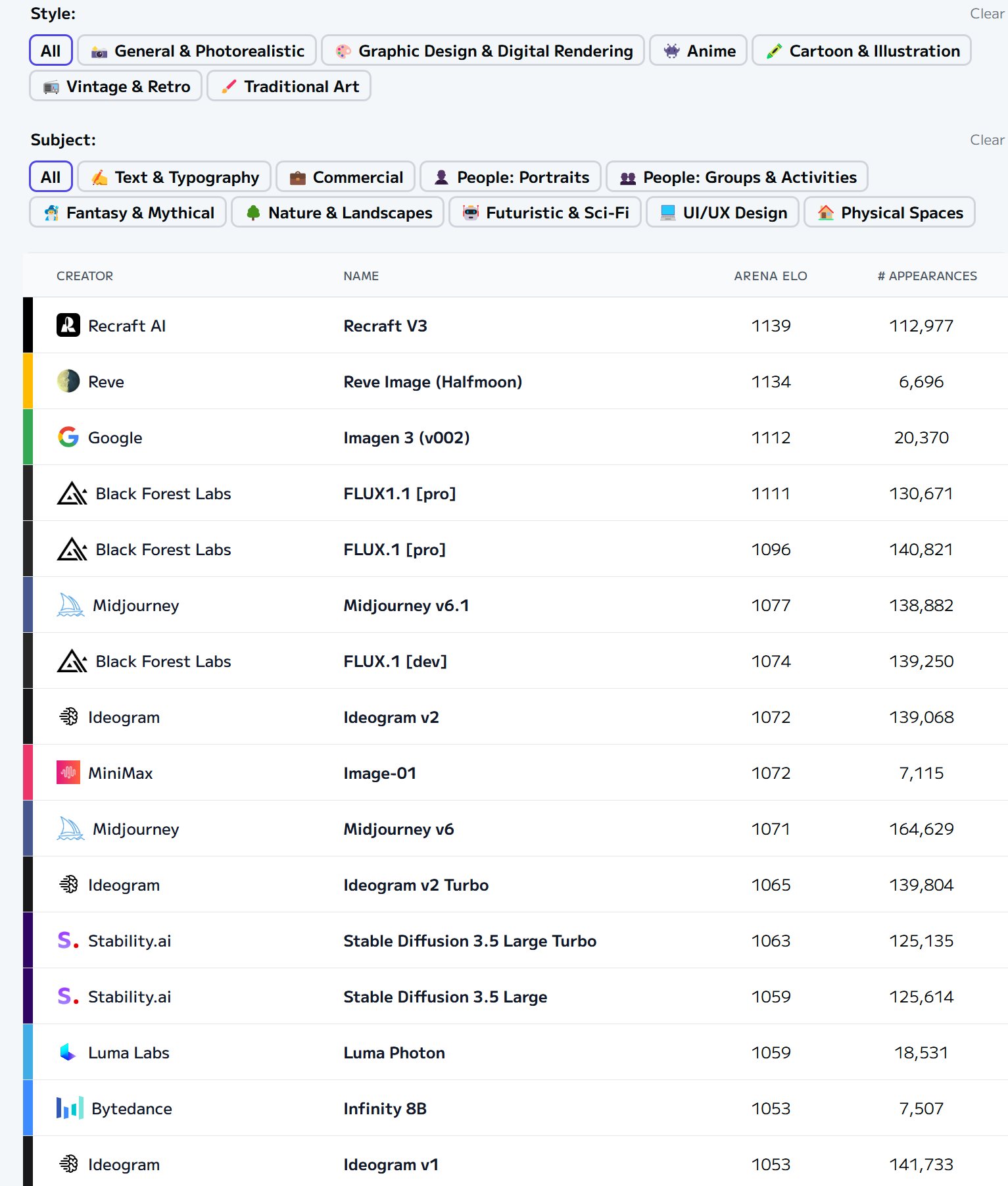
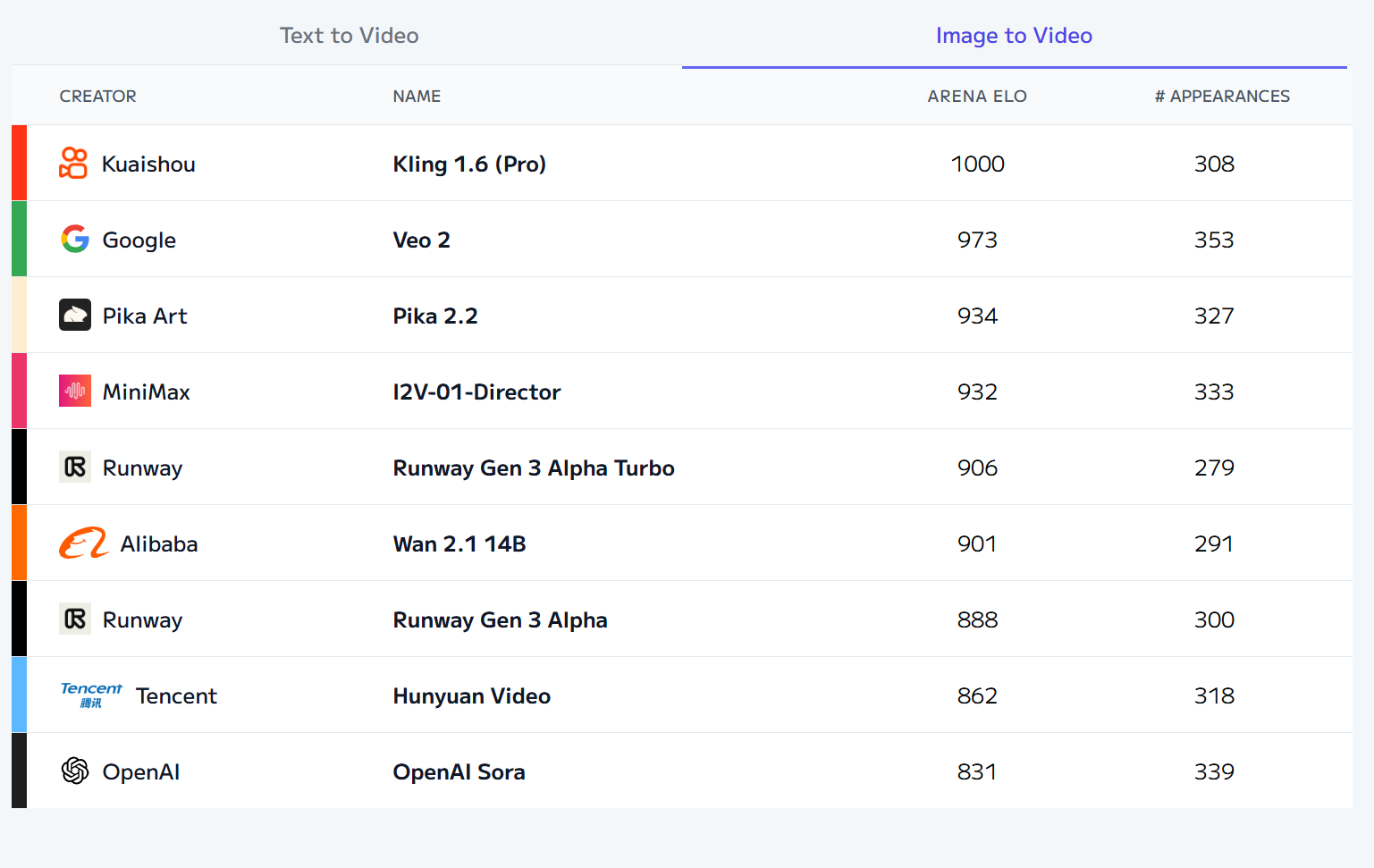
多模态大模型的训练方式正在经历从传统架构向新型范式的演进,不同专业领域构建基础模型(Foundation Model)的核心价值在于将通用智能的泛化能力与领域知识的深度理解相结合,从而在特定场景下实现超越通用模型的性能与效率。首先,先了解一下当前人工智能产品竞技评测结果:
- Image领域:
- Video Arena:
Text to Video:
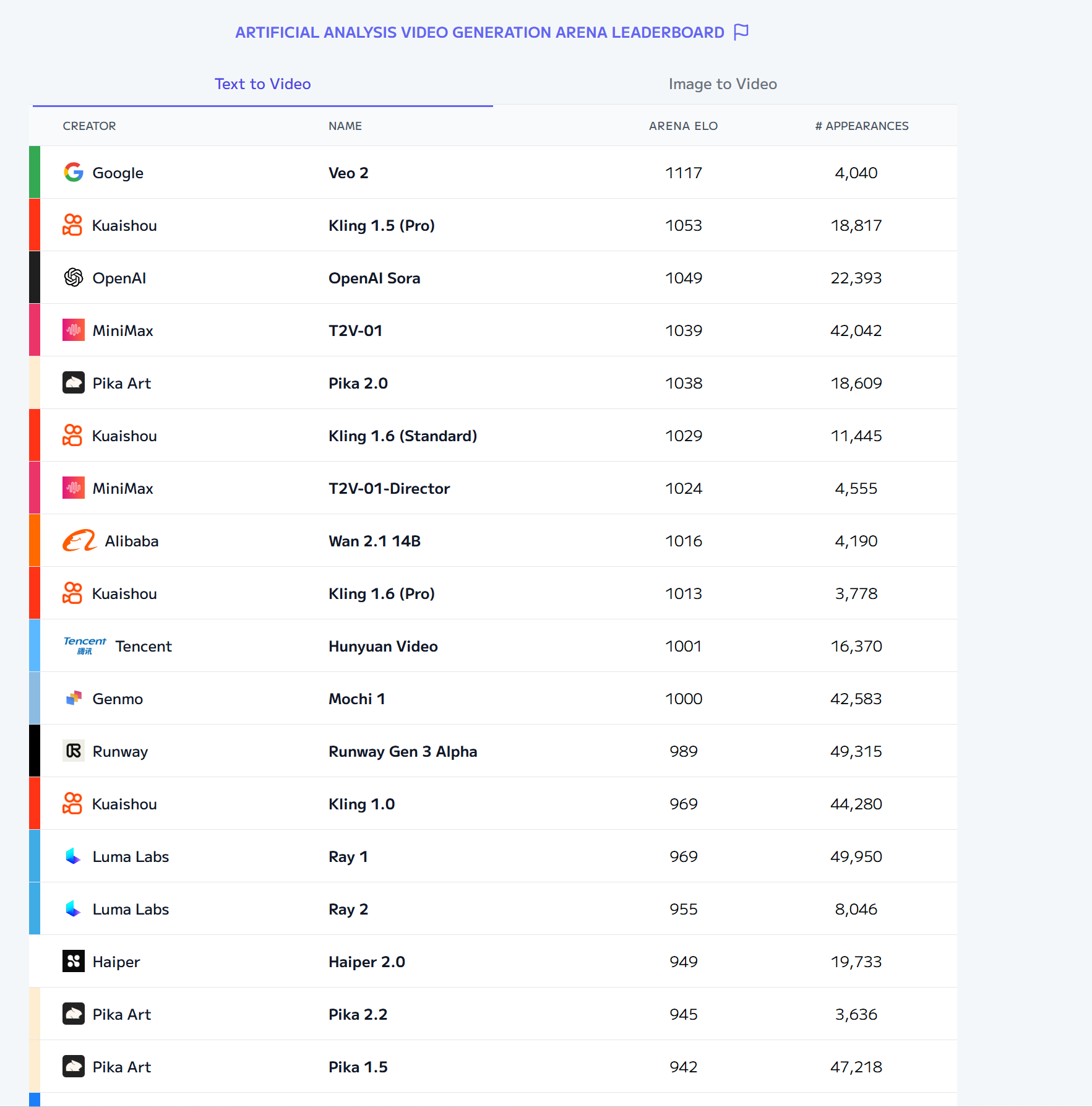
Image to Video:
- Speech

通过逆向工程分析产品功能,解析底层模型架构,初步假设更具潜力的方法侧重于统一架构、数据效率和动态适应三个维度。
统一架构(模态建模):打破模态壁垒
(1)全模态 Transformer
核心思想:将图像、视频、音频、文本统一映射为离散 token(如 ViT 处理图像为 16x16 的 patch token,音频转为频谱图 token),共享同一 Transformer 架构进行编码和解码。
- 优势:
- 模态无关性:新增模态仅需扩展 tokenizer,无需修改模型结构
- 跨模态注意力:通过自注意力机制自动捕获模态间关联
- 框架:
- 采用共享自注意力机制的通用编码器(如CoCa)
- 模态无关的位置编码设计
- 动态路由机制实现跨模态特征选择
- 参数高效化设计
- 混合专家系统(MoE)实现模态专属处理
- 可插拔适配器模块(Adapter)实现零样本迁移
- 参数冻结下的提示学习(Prompt Tuning)
(2)符号-神经混合架构
- 神经网络提取原始特征
- 符号引擎
数据效率:从「标注依赖」到「自进化」
- 生成式预训练
(1)技术路径:
跨模态扩散:如 Stability AI 的 Stable Diffusion XL,联合优化图像生成与文本理解
自回归生成:如 OpenAI DALL·E 3,通过文本→图像→文本循环生成,自动扩充训练数据
(2)数据合成公式:
\mathcal{D}{syn} = { (x_i, y_i) | x_i = G{\text{text→image}}(z_i), y_i = G_{\text{image→text}}(x_i) }
其中生成器 G 与判别器 D 交替优化,形成数据自增强闭环。
- 世界模型驱动训练
原理:构建虚拟环境(如 Unity 模拟器),让模型在合成场景中主动探索:- 视觉:渲染多视角图像流
- 语言:自动生成场景描述问答对
- 物理:通过刚体动力学引擎生成因果事件链
动态适应(动态计算网络):让模型「按需思考」
-
条件计算
- MoE(Mixture of Experts):如 Google V-MoE,每个图像 patch 动态路由至不同专家网络
- 早退机制(Early Exit):对简单样本在浅层输出结果,复杂样本深入计算。
-
动态提示引擎
- Prompt 工厂:根据输入内容自动生成适配的 prompt 模板;
- 可微分提示:将离散 prompt 替换为连续向量(如 P-tuning v2)
-
动态知识检索增强
基于领域知识图谱的深度融合,模型推理时实时检索领域知识库。
未来多模态训练的核心范式将转向生成即训练、推理即优化、交互即标注的自我进化模式,最终实现人类水平的跨模态情境理解与因果推理能力。后续将基于具体产品以及应用剖析多模态大模型的技术实现。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











