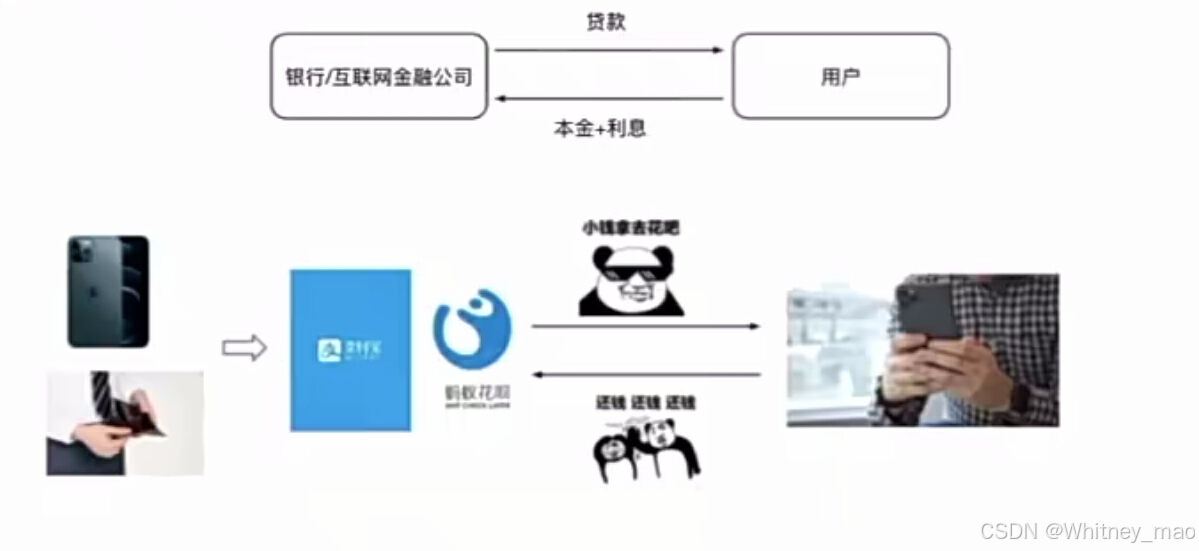
 金融机构风控模型的构建与运营
金融机构风控模型的构建与运营





本文主要讲述了金融机构风控模型的重要性及其应用。首先,开头概述了风控模型的整体建模流程,包括特征工程和建模方法。接着,本文强调了贷前、贷中、贷后三个阶段中风控模型的应用,如信用评分、行为评分和催收评分。同时还提到了信贷产品的基本形式和用户资质评估的重要性。最后,本文总结了贷前、贷中、贷后三个阶段中模型与策略的互动,以及模型在信用评估中的关键作用。
建模流程
风控模型是金融机构全链条的最后一道关卡,主要关注信贷产品的风险评估。而建模流程包括特征工程、建模方法、模型监控等步骤。
模型定位:ABC
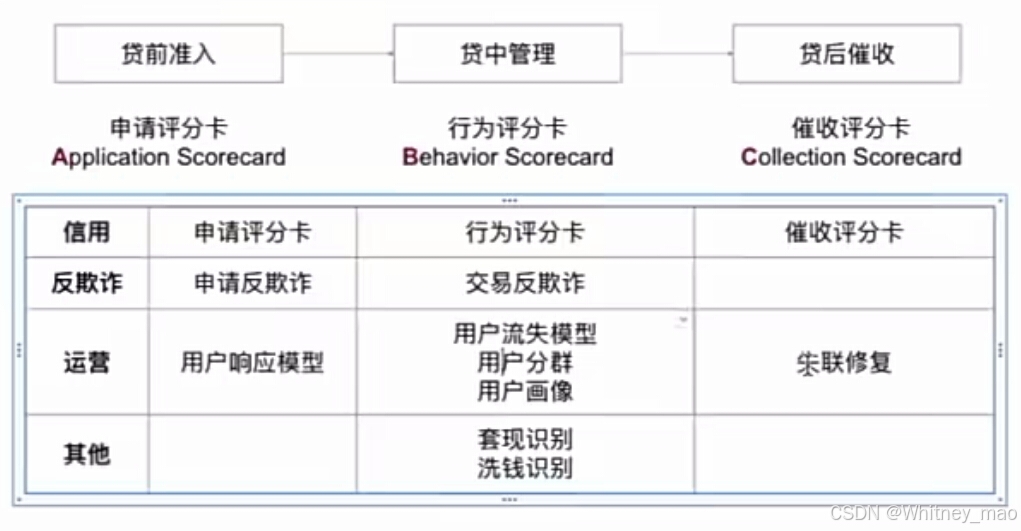
信贷产品常见模型包括申请评分卡(A卡)、行为评分卡(B卡)和催收评分卡(C卡)。ABC卡是风控模型的核心,分别对应申请评分卡、行为评分卡和催收评分卡,此外风控模型还包括反欺诈、运营和催收修复等模块。
A贷前准入
贷前流程是金融信贷业务中的关键环节,它决定了是否向用户提供贷款以及贷款的额度和利率。贷前流程包括用户注册、填写四要素、授信定价和审批阶段。
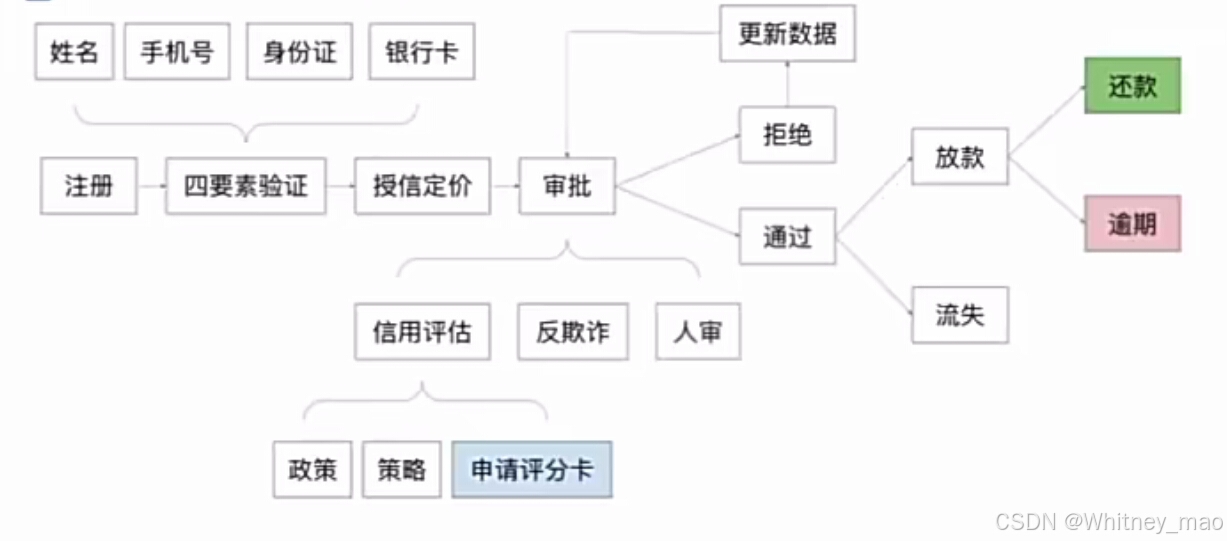
- 授信定价:授信定价是金融机构根据用户的信用状况、风险水平、市场条件等因素,决定给予用户的贷款额度、利率和费用等条件的过程。这一阶段涉及对用户的信用评估和对相关风险的定价,以确保金融机构在提供贷款服务的同时,能够覆盖潜在风险并获得合理收益。
- 步骤包括: 客户风险评估, 市场条件分析, 产品特性考量
- 审批阶段是贷前流程的核心环节,它决定了用户的贷款申请是否通过以及贷款的额度和利率等条件。审批阶段涉及多个步骤和工具,包括信用卡评估、反欺诈、人工审核和模型提供的申请评分卡等。
- 信用卡评估:模型根据信用评分卡出的分数档位决定是否通过申请。
- 人工审核
- 反欺诈
- 申请评分卡
B贷中管理
贷中管理是金融信贷业务中的一个重要环节,它涵盖了首次用信后的账户管理和再次借款的审批。在这个过程中,行为评分卡(B卡)发挥着至关重要的作用,它根据用户的信用行为来动态调整额度或决定是否拒绝借款。信用卡形式则是定期审查信用并调整额度。
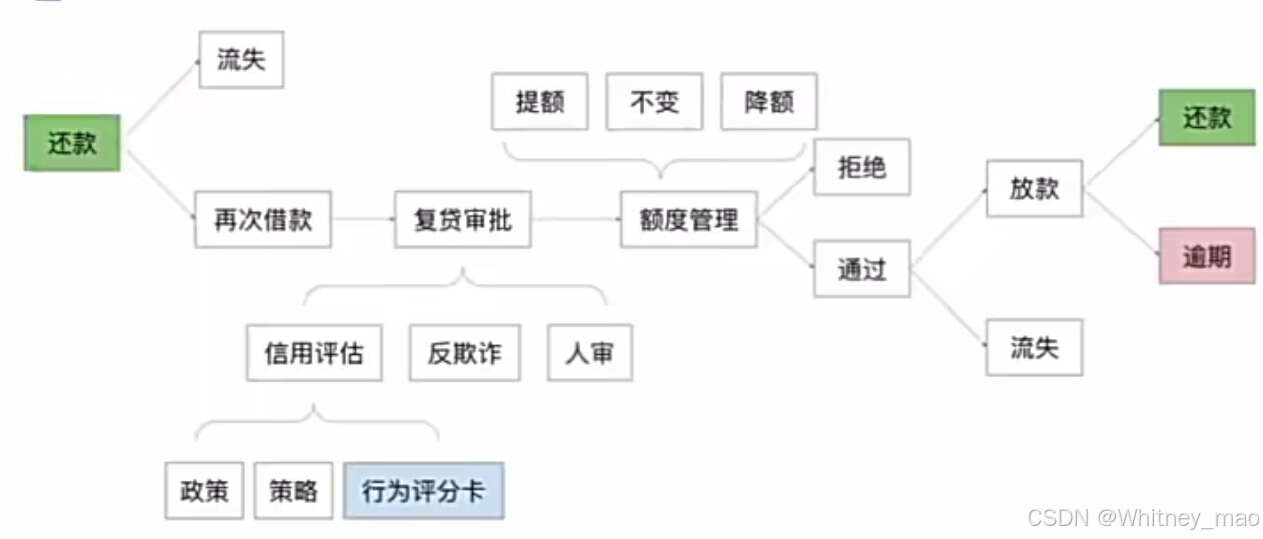
首次用信后的账户管理: 在用户首次使用信贷产品(如贷款、信用卡等)后,金融机构会对其账户进行持续的管理和监控。这包括跟踪用户的还款情况、消费习惯、信用记录等,以确保用户能够按时还款并维护良好的信用状况。
再次借款的审批: 当用户需要再次借款时,金融机构会重新评估其信用状况和还款能力。这通常涉及对用户的个人信息、收入状况、负债情况等进行审核,并参考其历史借款和还款记录。
动态评估信用行为: 行为评分卡是一种基于用户历史行为数据的评分模型,它能够动态地评估用户的信用行为和风险状况。通过分析用户的消费行为、还款记录、负债压力等,行为评分卡能够预测用户未来的逾期风险。
调整额度或拒绝借款: 根据行为评分卡的评估结果,金融机构可以灵活地调整用户的信用额度或决定是否拒绝其借款申请。对于低风险、高信用的用户,金融机构可能会提高其信用额度,以满足其更高的消费需求;而对于高风险、低信用的用户,金融机构可能会降低其信用额度或拒绝其借款申请,以降低潜在的风险。
- 信用卡形式的贷中管理
- 定期审查信用:对于信用卡用户,金融机构会定期进行信用审查,以评估其信用状况和还款能力。这通常涉及对用户的消费记录、还款记录、负债情况等进行综合分析。
- 调整额度:根据信用审查的结果,金融机构会相应地调整用户的信用卡额度。对于信用状况良好的用户,金融机构可能会提高其信用卡额度,以鼓励其更多的消费和还款行为;而对于信用状况不佳的用户,金融机构可能会降低其信用卡额度或采取其他风险管理措施。
C贷后催收
贷后催收流程包括早期预警、早期催收和委外处理三个阶段,而催收评分卡则根据用户的逾期情况排序,优先处理高风险用户,以实现精准催收和风险管理。
- 排序优先级:催收评分卡根据用户的逾期情况(如逾期天数、逾期金额、历史还款记录等)进行评分,从而确定用户的催收优先级。高风险用户(即逾期情况严重、还款意愿低的用户)会被优先处理,以确保资金安全和减少损失。
- 精准催收:通过催收评分卡,金融机构能够更精准地识别出不同风险等级的用户,并采取相应的催收策略。这有助于提高催收效率,降低催收成本,并改善用户体验。
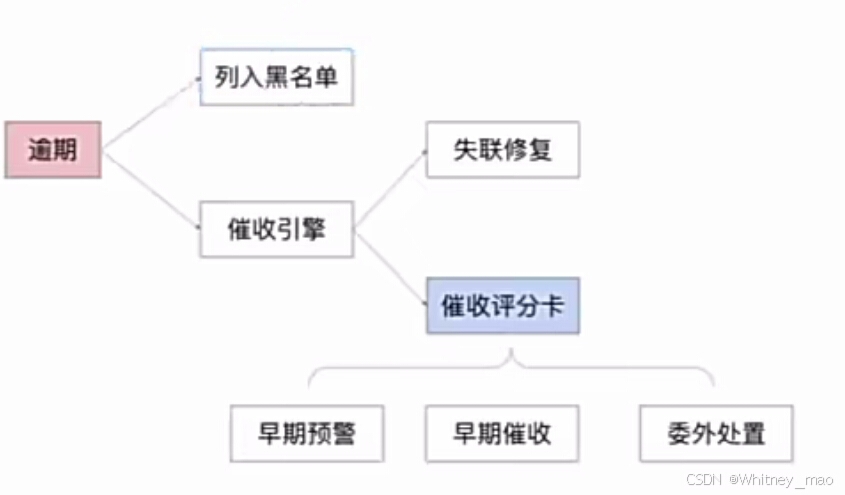
贷后催收流程:
- 早期预警:当用户逾期一两天时,系统会进行提醒(remind),通知用户进行还款。此阶段主要解决用户可能因不知晓还款方式或操作障碍导致的逾期问题。
- 早期催收:针对忘记还款的用户,进行进一步的提醒和催收。此阶段主要解决用户因疏忽大意或短暂遗忘导致的逾期问题。
- 委外处理:对于存在严重还款问题的用户,如疫情期间资金周转困难等,且内部团队无法联系到用户更多联系方式时,会委托外部催收机构进行处理。外部机构凭借其广泛的资源和经验,能够更有效地联系到用户并尝试解决还款问题。
模型构建流程
数据来源与使用
数据分为内部数据和外部数据,内部数据包括自有数据和设备数据。外部数据包括授权类数据、第三方数据服务等。

- 内部数据
- 自有数据:这些数据有助于金融机构了解客户的身份背景、财务状况和交易习惯,从而评估客户的信用状况和潜在风险。
- 手机设备数据:设备数据可以用于辅助验证客户身份,防止欺诈行为,以及提高交易的安全性。
- 外部数据:
- 授权类数据:有助于金融机构更全面地了解客户的信用状况和财务状况,从而更准确地评估客户的贷款申请或信用卡申请。
- 第三方数据服务: 通过分析这些数据,金融机构可以更深入地了解客户的生活方式和消费习惯,从而为客户提供更个性化的金融产品和服务。
- KYC(Know Your Customer)即了解你的客户,是一种在金融服务中验证客户身份、适合性,以及评估与该客户维持商业关系所带来的风险的指导方案。在KYC过程中,数据的收集和分析是至关重要的环节,这些数据既包括内部数据,也包括外部数据。
建模步骤与准备
建模准备包括明确需求、特征构造、模型设计和实验、训练和评估、模型交付和监控。
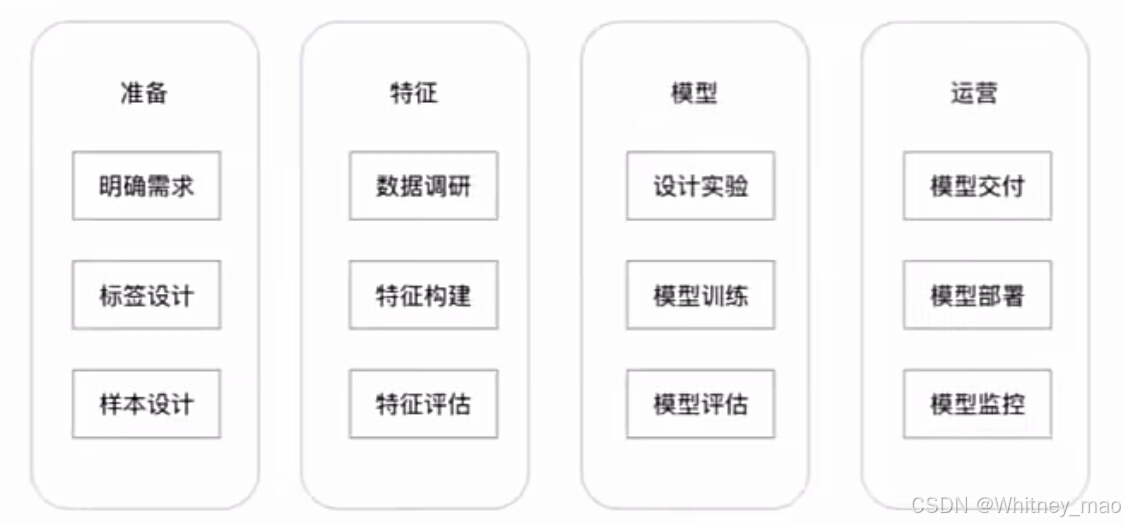
明确需求: 明确需求包括确定产品类型和目标人群
- 风控产品:小微企业贷款、消费信贷、现金贷
- 小微企业贷款:小微企业贷款的风控环节较为复杂,除了评估企业的信用状况(如经营历史、财务报表等)外,还需考虑企业的欺诈风险、行业风险及经营稳定性。在反欺诈方面,会重点监控企业账户是否被盗用或存在虚假申请等行为。同时,设备数据(如企业使用的电脑、手机等设备信息)也可能被用于辅助风控决策。
- 消费信贷:消费信贷主要面向个人用户,风控环节包括评估用户的信用状况(如征信记录、收入情况等)、欺诈风险(如账户盗用、虚假交易等)以及交易异常行为。在数据收集方面,会考虑用户的设备数据(如手机APP安装列表、设备指纹等),但需注意不同操作系统(如安卓和iOS)在数据获取上的差异。此外,消费信贷还可能涉及用户响应模型,用于预测用户对营销活动的响应情况,以优化拉新和留存策略。
- 现金贷:现金贷的风控相对简单,主要侧重于收集和分析用户的个人数据,以评估其信用状况和欺诈风险。由于现金贷通常不涉及具体的消费场景或商品,因此其风控模型可能更加侧重于用户的整体信用状况和还款能力。在数据收集方面,现金贷公司可能会利用公开场合可获取的数据(如手机设备数据、GPS地址等),但需注意数据合规性和隐私保护问题。同时,现金贷的风控策略可能更加灵活,以适应不同用户群体的需求和风险特征。
- 建模人群定位:申请新客、优质老客和入催人群。
- 申请新客定位:基本信息、信用记录、消费行为、渠道来源
- 优质老客定位:历史交易记录、产品使用情况、价值贡献、忠诚度
- 入催人群定位:逾期天数、还款意愿、风险等级
标签设计: 好坏用户定义根据逾期天数和产品类型确定。
定义原则: 根据产品定义标签(消费贷 、现金贷 、人维度信用) 保证数据充足时尽可能的缩短表现期。
样本选择需考虑样本量和坏人浓度,一般最少样本需要3000总样本和200坏样本,而分数段一般分10份,每份里用户数最少30人,每份占总体比例不小于2%。
样本设计: 样本设计包括训练集、验证集、测试集和OOT(out of sample)集合,格式:(总人数,坏人比例)
- 训练集:用于模型训练
- 测试集:按照逾期率分层抽样,保持标签同分布。 测试集用于评估模型效果
- 验证集:辅助模型调优,数据总量少的时候,可以没有验证集。
- OOT集合按照数件划分,不保持标签同分布,用于独立测试,模拟线上效果。
特征工程
在特征构建过程中,需要充分理解数据,考虑数据的实际情况和场景,以确保生成的特征是有效和准确的。但在特征构建过程中容易存在几个常见的误区。
误区一:拿到数据即做特征。有的人认为数据准确无误,但实际上数据可能存在噪音或异常点。
- 数据获取错误
- 数据存储错误
- 数据更新错误
误区二:原始数据没问题则特征没问题。特征生成逻辑可能存在问题,如性别特征的归一化问题。
- 特征生成逻辑错误
- 生成的特征效果很差
误区三:模型性能不好就换模型。忽视数据和特征构造方法的问题,导致模型效果不佳。
机器学习模型的性能不仅取决于选择的算法和参数,更依赖于输入变量是否正确且稳定。
数据调研
1.明确可用数据:申请用户数据可用,借贷和催收数据不可用。
eg.申请评分卡人群特征不应使用贷后信息
2.数据质量检查:空值率、零值率、取值范围合理性、特殊格式处理。
3.数据逻辑梳理:数据获取和存储过程中可能出现的错误,如Spark操作中的盘块转换问题。
特征构建:RFM
根据RFM维度设计特征框架:R:近期情况 F:频率 M:价值
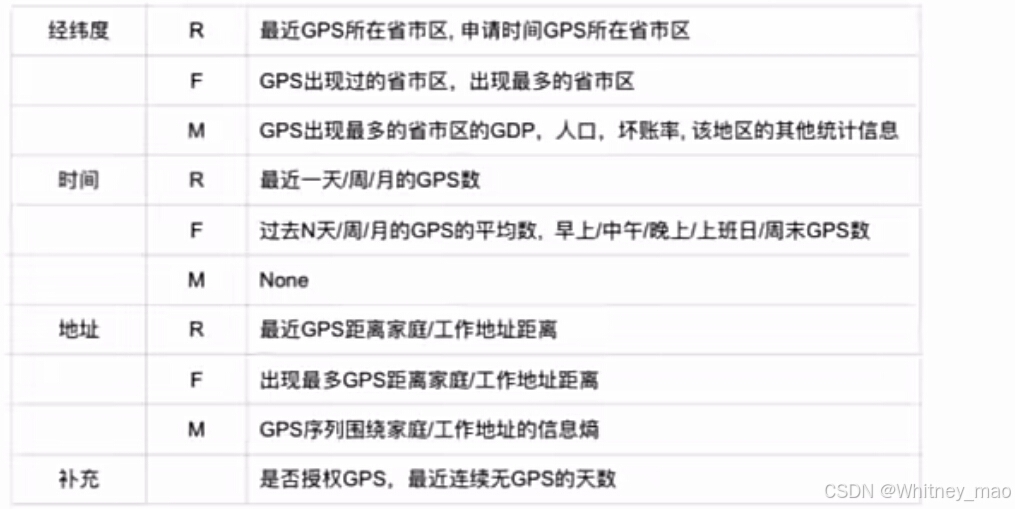
例如:GPS
特征构造方法
1.用户静态信息特征:姓名、性别、年龄等不常变化的信息。
2.用户时间截面特征:当前时间点的统计信息,如GMV、银行存款。
3.用户时间序列特征:过去一段时间的平均值和变化趋势,如GPS数据量、银行流水。
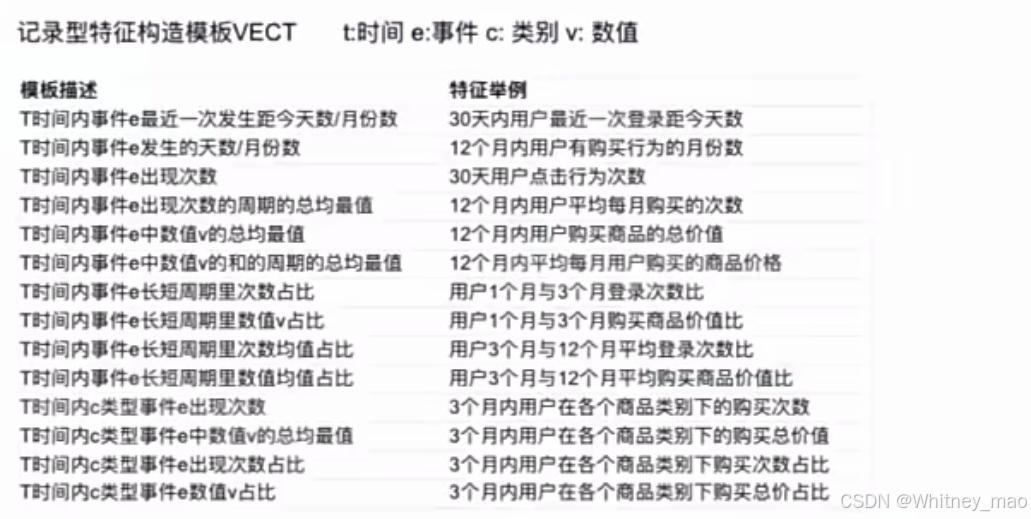
4.记录型特征:用户行为记录,如登录信息、购买记录。
5.向量型特征:以变量名、事件、类别、时间为维度构造的特征。
特征筛选的方法: 特征筛选是模型构建的重要步骤,旨在选择对模型预测有重要影响的特征。
- 星座特征法:利用星座特征作为无用的特征尺度,筛选出排名靠后的特征。
- BRUTA法:通过随机置换原有特征的值,评估特征的重要性。
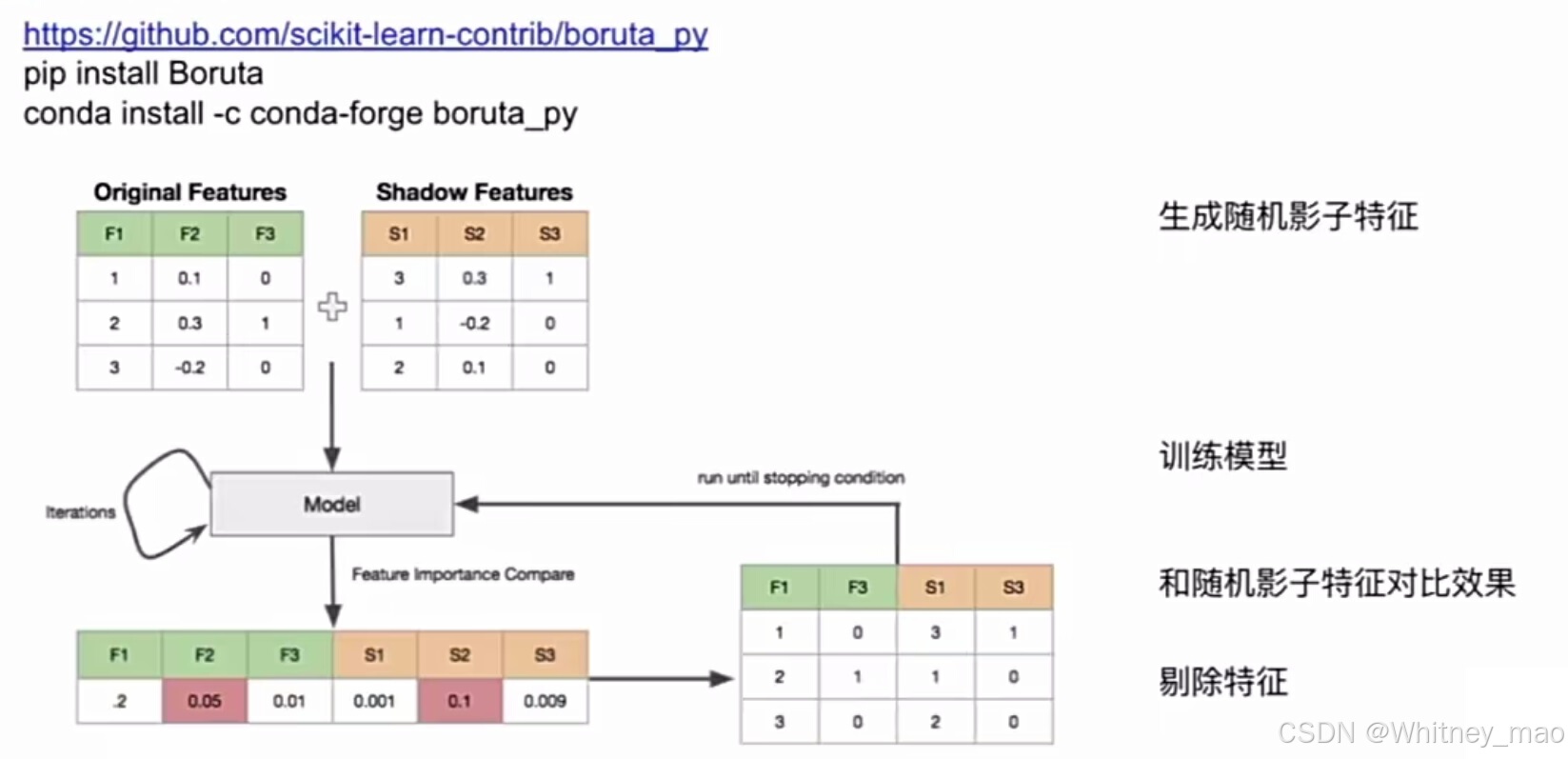
- 方差膨胀系数(VIF):衡量特征之间的相关性,VIF越大,特征之间的线性关系越强。
statsmodels.stats.outliers_influence.variance_inflation_factor

- 前后向筛选:逐步添加或剔除特征,选择对模型预测增益最大的特征。
特征评估
1.区分度: 特征将用户分成好用户和坏用户的能力。
2.稳定性: 特征在不同时间点的性能一致性。
3.覆盖度: 特征覆盖的用户群体比例,覆盖度低的特征效果不佳。
特征评价指标
1. 分箱: 离散型和连续型特征的分箱方法,降低异常值影响,提高解释性。
- 数据分箱的原因:
- 降低异常值影响
- 单独处理空值
- 提高可解释性
- 注意问题
- 分箱个数不应过多或过少,二到五个箱体较为合适,评分阶段可能分为十个箱体。
- 单调性:常识上单调的特征强制单调结果较好。
- 分箱方法:无监督学习(等频分、等距分、卡方分箱),有监督学习(Chi Merge、Best KS、Decision Tree、Mono Binning:)等。
- 卡方分箱:将数据按等频或等距分箱后,计算卡方值,将卡方值较小的两个相邻箱体合并使得不同箱体的好坏样本比例区别放大,容易获得高信息价值IV。即计算卡方值,合并卡方值较小的箱体,直到卡方值最小值大于搜索阈值或箱体数小于阈值。
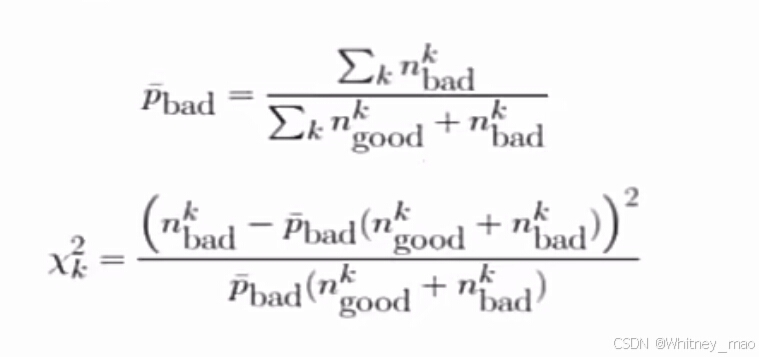
2. WOE编码: log(pgood/pbad),表示用户的好坏风险状况。
信息价值(IV):衡量特征区分度,IV值大于0.02表示特征区分度较好。
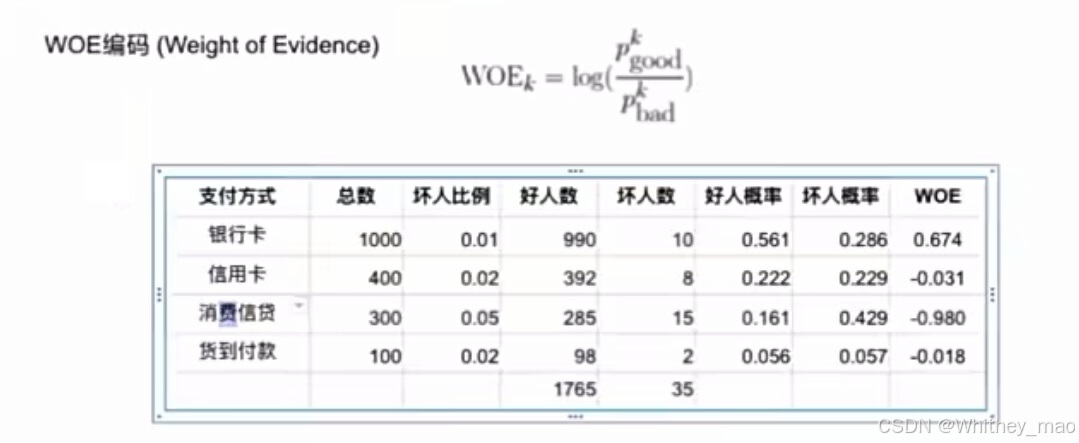
WOE越大风险越小,WOE越小风险越大
3. IV: 衡量好坏样本分布差异大小(IV值越大,分布差异越大,区分能力越强)
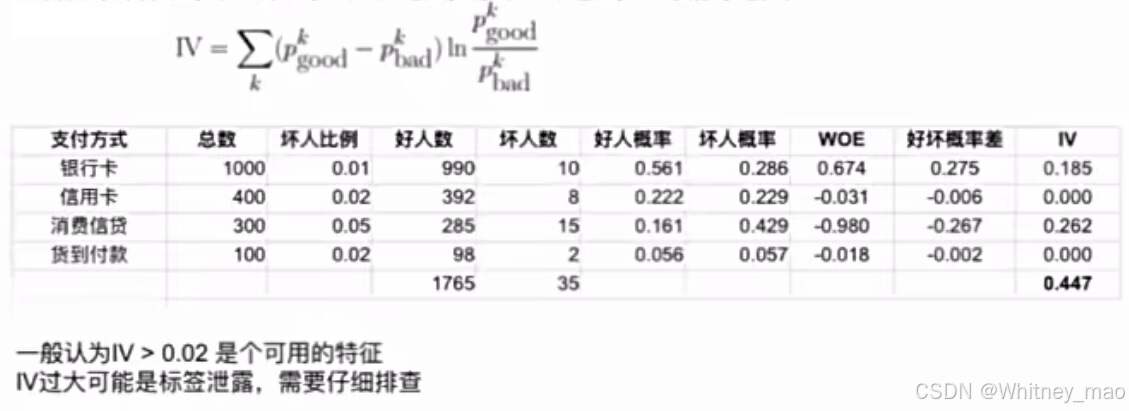
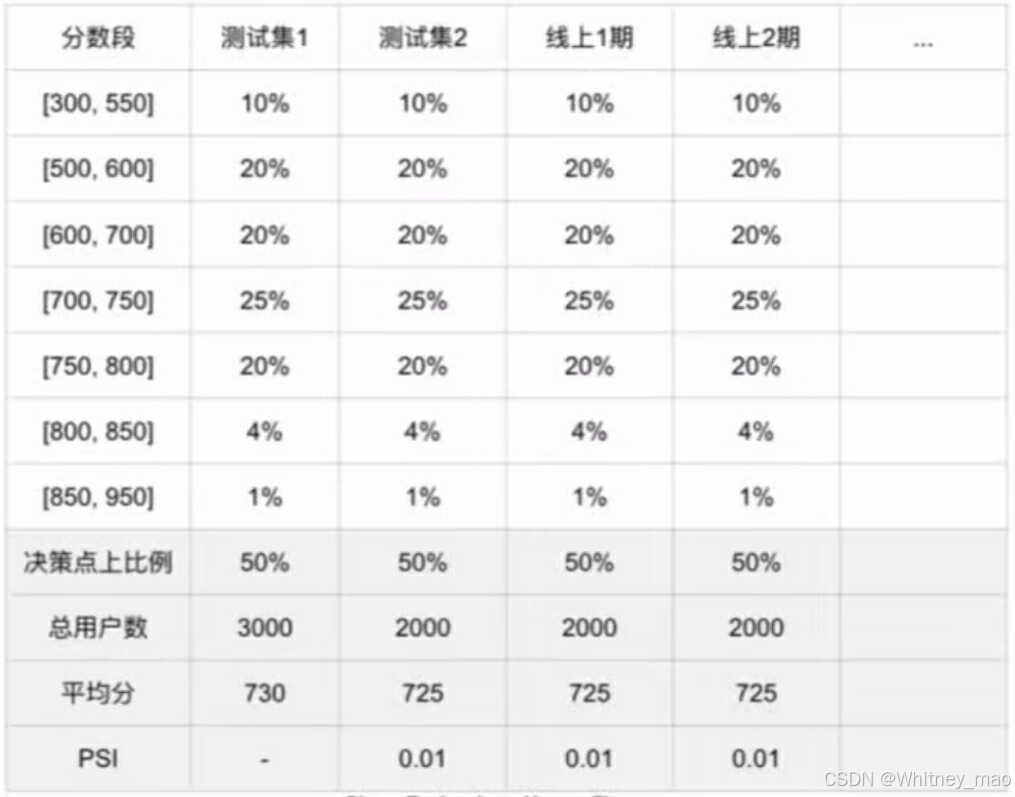
4. PSI: 衡量不同时间段内同一特征的分布差异(PSI值越大,不同时间段分布差异越大,稳定性越差),使用PSI指标,计算实际分布与预期分布的差异。
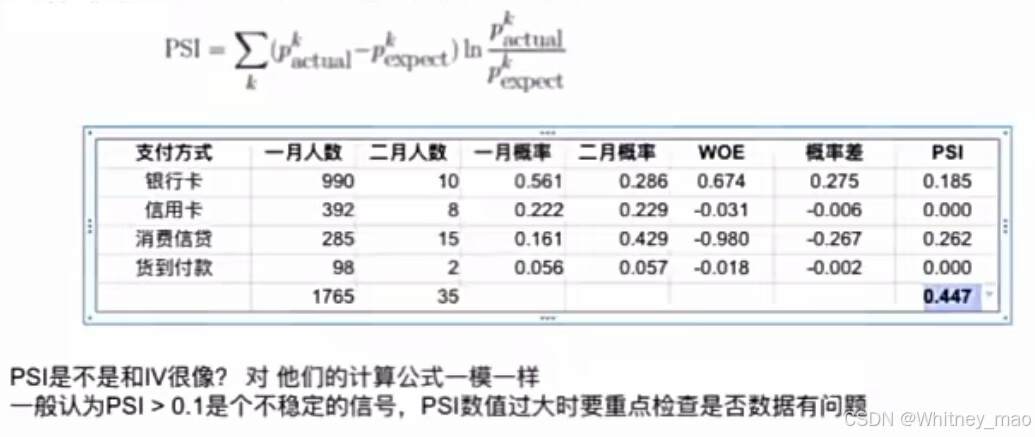
稳定性标准:PSI小于0.1表示特征稳定。
5. 单特征评估: 特征质量:零值率,空值率,特征分布,不同分箱上好坏用户占比
特征性能:
- 特征区分能力:IV(Information Value)
- 特征稳定度:PSl(Population Stability Index)
建模方法
模型构建分为三个主要部分:实验设计、模型训练和模型评估。
实验设计
实验设计包括目标设定和人群选择,旨在验证模型的有效性。
- 实验设计的目的是验证模型能否解决实际问题。
- 设计包括人群定义、训练集、验证集和测试集的划分。
- 实验设计需针对具体目标进行,确保模型的针对性。
模型训练
训练阶段主要使用逻辑回归模型,该模型在线性回归基础上套用了逻辑函数,常用的Python包(statsmodel/sklearn)
1.逻辑回归是一种常用的分类模型,通过线性回归输出结果后应用逻辑函数。
2.模型输出结果为0到1之间的概率值,表示用户为好或坏的概率。
3.逻辑回归在信贷评分卡中广泛应用,因其稳定性和可靠性。
需要注意的是,评估模型常用手段包括计算特征的重要性且模型构建最好能够具有可解释性。在使用sklearn或xgboost等包时,特征重要性可以通过包提供的函数来计算。
shap.summary_plot(shap_values, df_sub, plot _type="bar" )
shap.summary_plot(shap_values, df_xtrain)

特征重要性可以通过下部点summary plot来可视化,该图显示了每个特征在不同WOE值上的分布情况。通过观察特征在不同WOE值上的堆积比例,可以评估特征的重要性。
分数转换与分数映射
评分转换的目的是将模型输出的零到一之间的概率值转换成信用评分,便于业务理解和决策,常用的评分转换方法是乘以一个步长(PDO)并加上基准分,根据好坏用户比例调整评分。
- PDO( Point of Double Odds)定义为好坏用户比例的对数乘以50,表示好坏用户比例每翻一倍,评分增加50分。
示例:
用户初始分 300(Base Score BS)
好用户的概率是坏用户概率的2倍 +50分
好用户的概率是坏用户概率的4倍 +100分
好用户的概率是坏用户概率的8倍 +150分
50称作 Point of Double Odds (PDO)
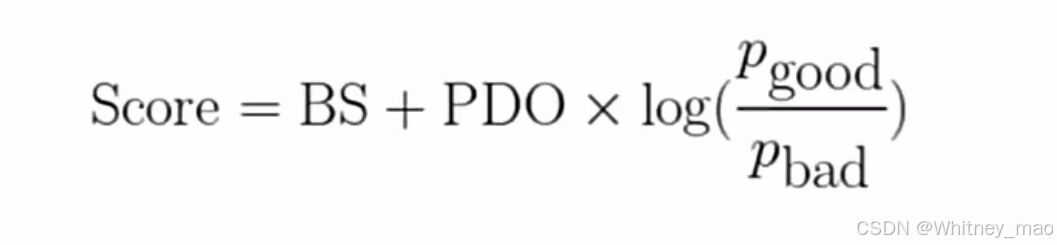
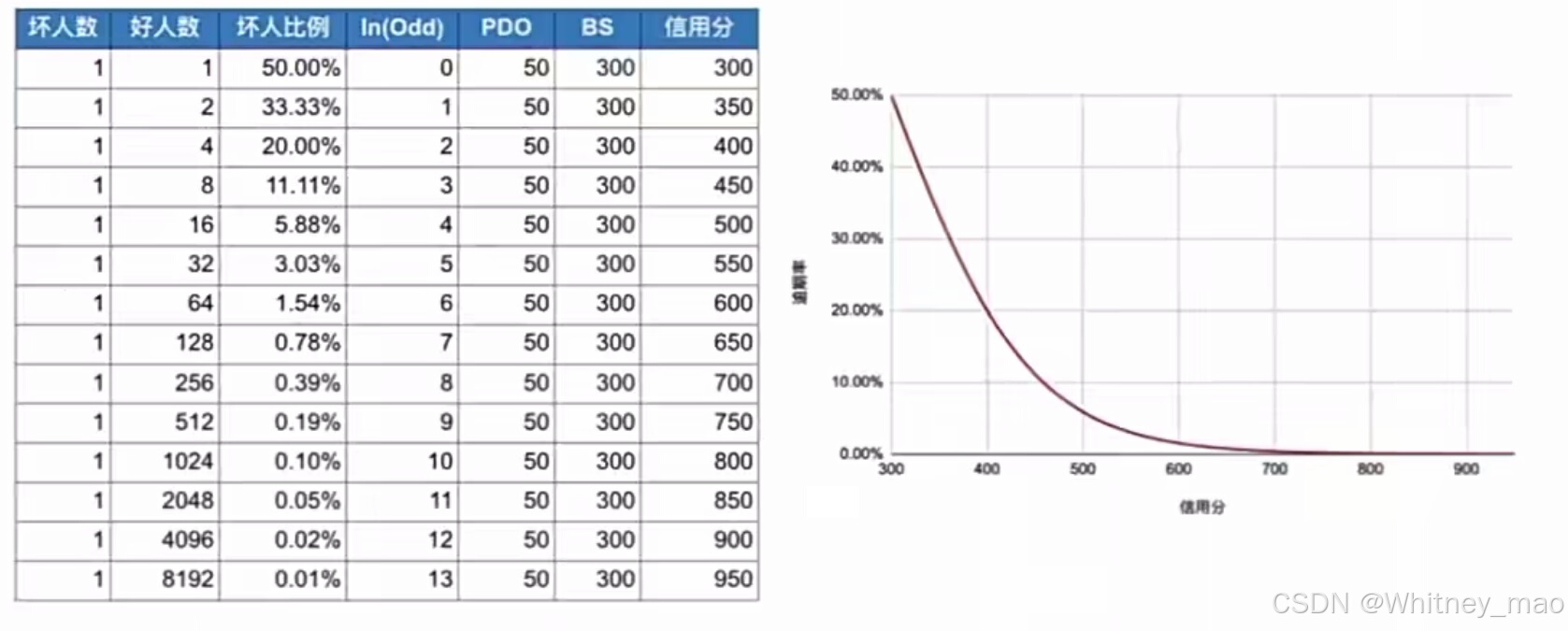
- 通过调整PDO和基准分,可以映射到300到950分的评分范围内。
- 评分转换后的分布图可以展示不同分数区间内的逾期率,评估模型的效果。
样本不均衡问题
- 样本不均衡问题在信贷模型中常见,表现为好用户数量远多于坏用户。
- 不能直接使用零点五作为切分点,需要采用其他方式进行切分。
解决方法:
- 过采样和欠采样是解决样本不均衡的方法,通过对少数类样本进行重复采样或丢弃多数类样本来平衡数据。
- 调整模型切分点,使用小于零点五的值进行预测。
- 给予坏用户更高权重,在训练过程中强调少数类样本的重要性。
- 使用Focal Loss等优化函数,通过调整损失函数的权重来关注少数类样本。
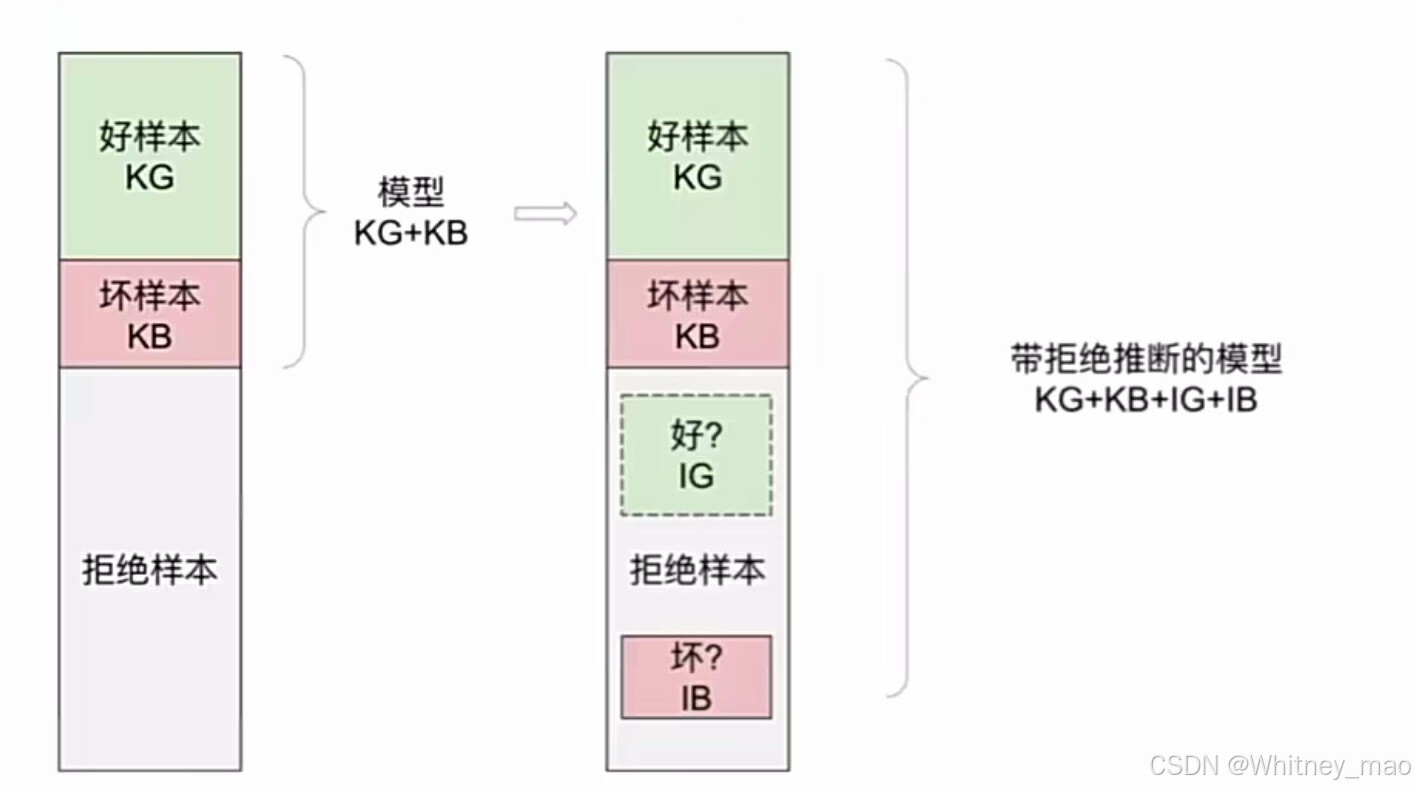
生存者偏差问题
生存者偏差问题是由于模型只应用于准入用户,而拒绝样本未被观察,导致模型偏差。准入用户与申请用户存在差异,准入用户的特征可能无法代表整体申请用户群体。
以偏盖全:拿自己看到的样本去推测总体,而忽略了未观察到的样本情况
解决方法:
拒绝推断是一种尝试解决生存者偏差问题的方法,通过利用准入样本中的好坏用户样本训练模型。拒绝推断的模型能够更好地泛化到申请用户群体,但实际效果难以评估,同时拒绝推断的推广和应用面临挑战,还包括模型效果难以证明和业务逻辑上的困难。
模型评价指标
评估阶段采用混淆矩阵、AUC和KS等指标来评估模型的区分度和稳定性。
1.评估模型时主要关注区分度和稳定性。
2.区分度通过混淆矩阵、AUC和KS等指标进行评估。
3.稳定性采用PSI(稳定性指数)进行评估。
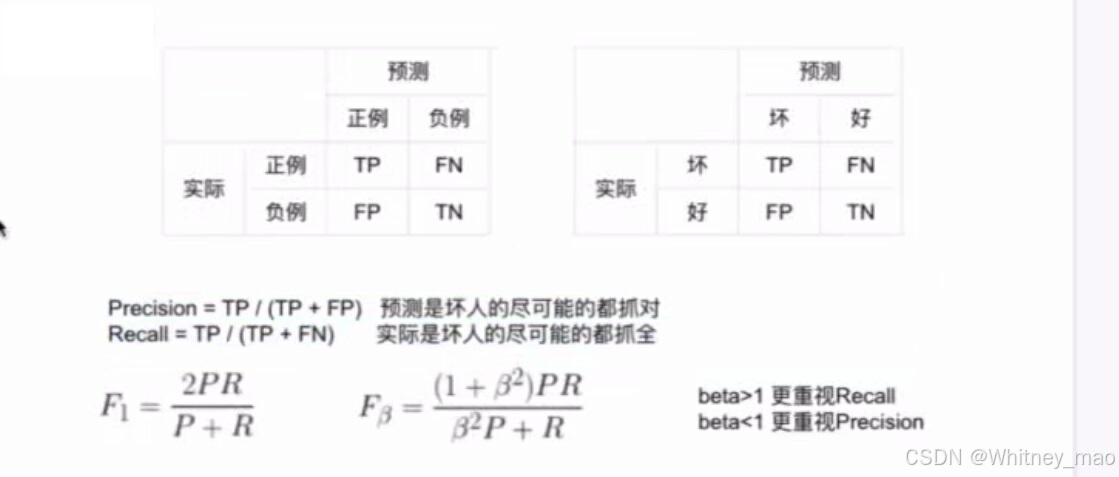
模型区分能力——混淆矩阵
混淆矩阵用于描述模型预测结果与实际结果之间的对应关系。矩阵中的元素包括真正例(TP)、假正例(FP)、真负例(TN)和假负例(FN)。混淆矩阵可用于计算精度(Precision)、召回率(Recall)和F1分数等指标。
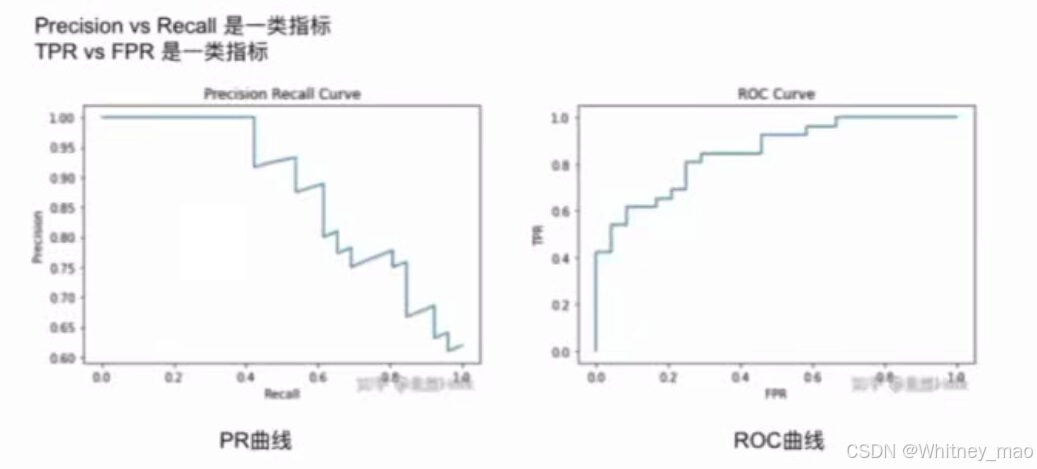
ROC曲线和AUC
AUC反应了模型输出的概率对好坏用户的排序能力在几何意义上为ROC曲线下的面积。ROC曲线以TPR(真正率)和FPR(假正率)为坐标绘制。AUC是ROC曲线下的面积,表示模型区分好坏用户的能力。AUC值越大,模型的区分度越好。
- AUC =1 完美分类器
- 0.5<AUC<1 优于随机预测
- AUC=0.5 与随机预测的效果一致
- AUC<0.5 和标签反相关,可以转换为1-AUC
- GINI=2AUC-1
KS指标
KS指标反映模型区分度的最大值,即KS反应了好坏用户的分布的最大的差别。KS值越大,模型的区分度越好。KS最大值通常出现在高分段,确保线上模型性能稳定。
公式:KS=max (TPR-FPR)
KS指标刻画了这两者的最大值,我们可以这么简单粗暴的认为
- AUC反应了模型区分度的平均状况
- ROC曲线是对TPR和FPR的数值对的记录
- KS反应了模型区分度的最佳状况
模型运营
模型运营是模型成功的重要环节,忽视运营可能导致模型效果不佳,因为运营能够提供模型反馈,指导模型改进方向。
模型交付
模型交付时需提供完善的文档和报告,包括特征报告和模型报告。
- 特征报告应包含特征需求、任务列表、时间、资源包、类ER图、样本设计、特征框架、周报、交互说明和总结。特征报告中的类ER图、样本设计和特征框架是确保特征质量的关键内容。
- 模型报告应包含模型设计、样本设计、实验设计、模型训练流程、周报、开发进度和结果、讨论和改进意见。

模型审批和通知:每版模型需经过业务方或负责人审批,确保模型的质量和安全性。
- 模型交付后需通知业务方,确认模型已交付。
- 线上部署时需通知业务方,确保模型顺利部署。
模型交付完整步骤:
- 提交特征和模型报表
- 离线结果质量复核(无缺失,无重复,存储位置正确,文件名规范)
- 保存模型文件,确定版本号,提交时间
- 老板审批
- 通知业务方(三次握手)
- 线上部署
- 线上案例调研
- 线上持续监控
模型部署
- MECE法则:所有人都有分没有人打两次分
- 确保线上打分和离线打分完全一致
- 记录线上批量打分总耗时 &实时打分耗时
- 日志+灾备
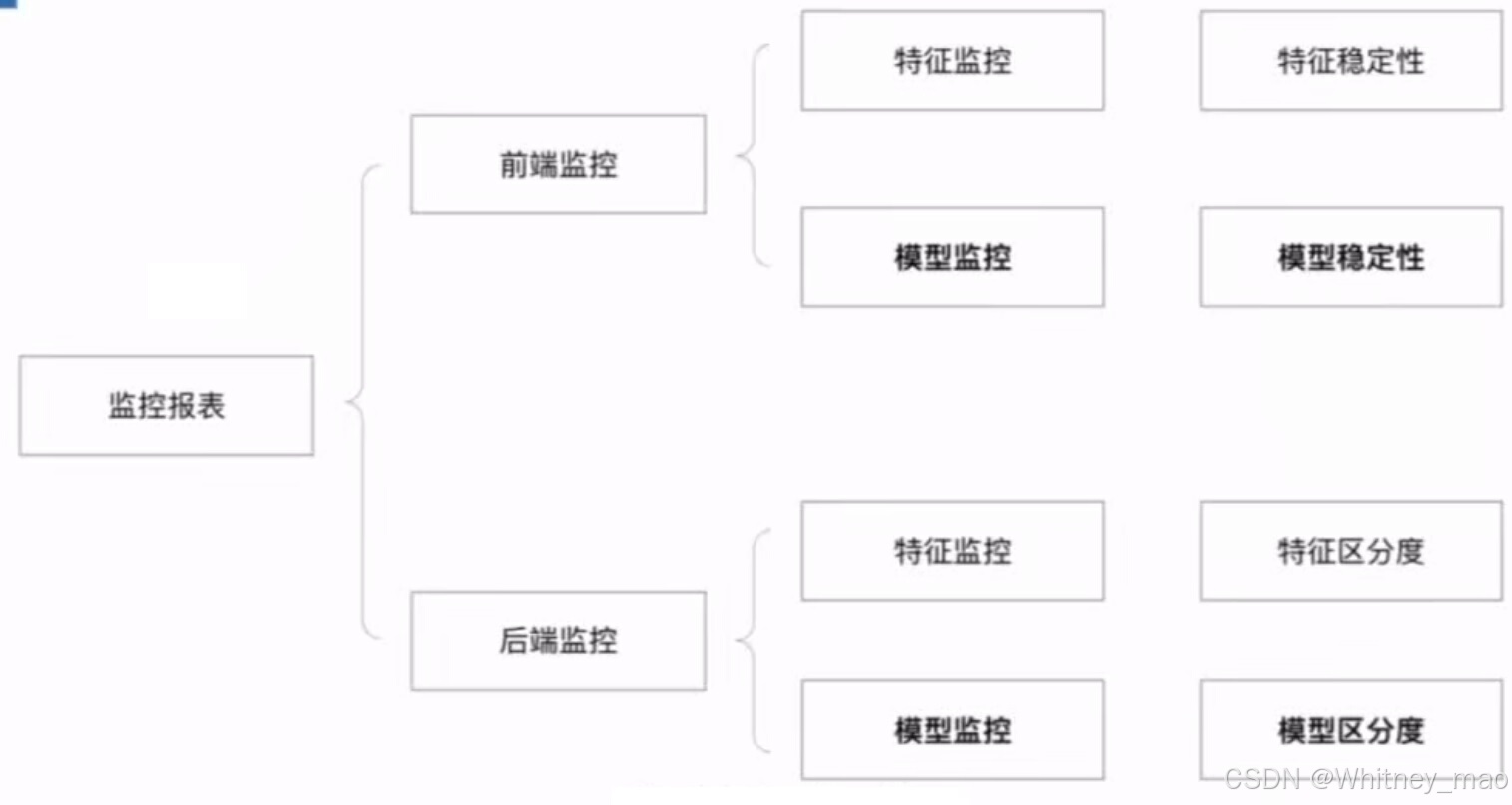
模型监控
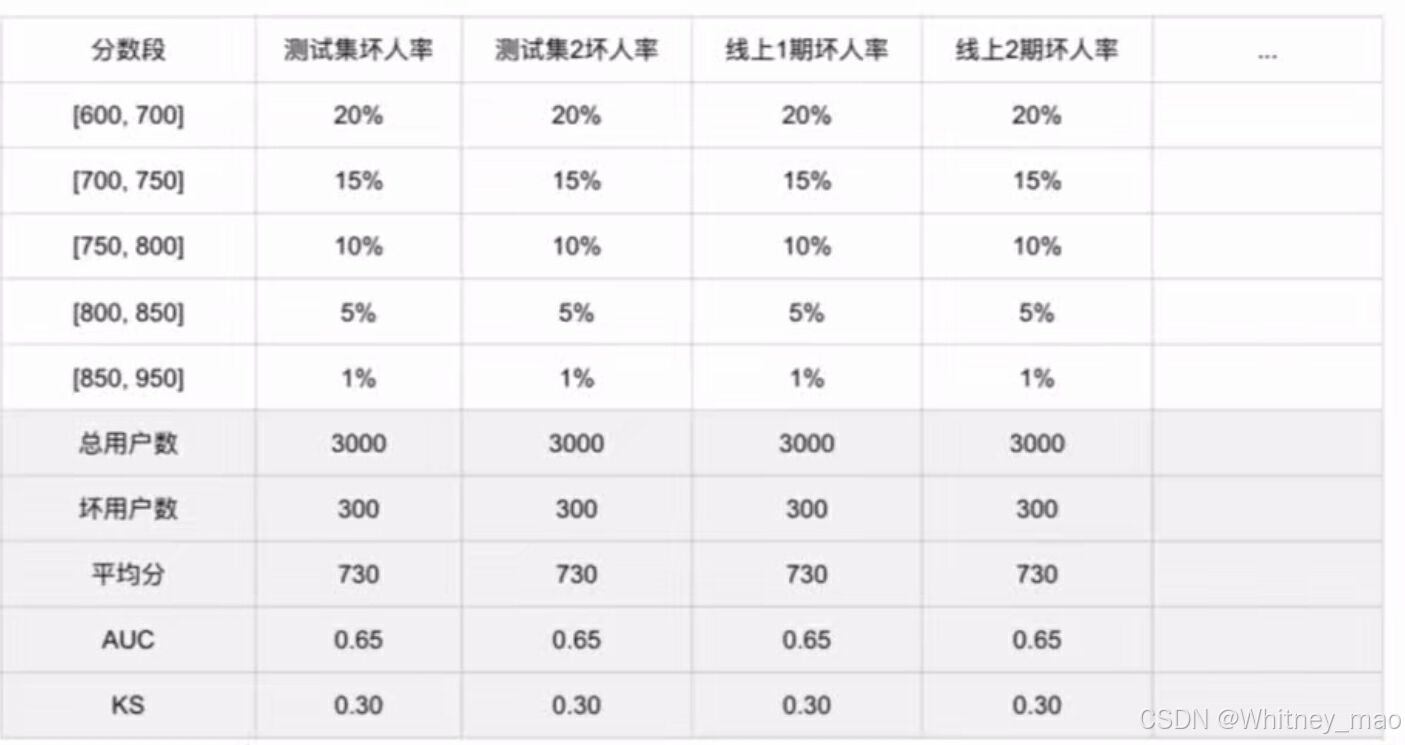
前端监控包括特征稳定性和模型稳定性,通过统计分布的变化来评估模型的稳定性。后端监控包括特征区分度和模型区分度,通过统计坏账率和通过率来评估模型的区分度。监控报表分为前端监控和后端监控,前端监控预测模型的后续表现,后端监控实际评估模型的区分能力。
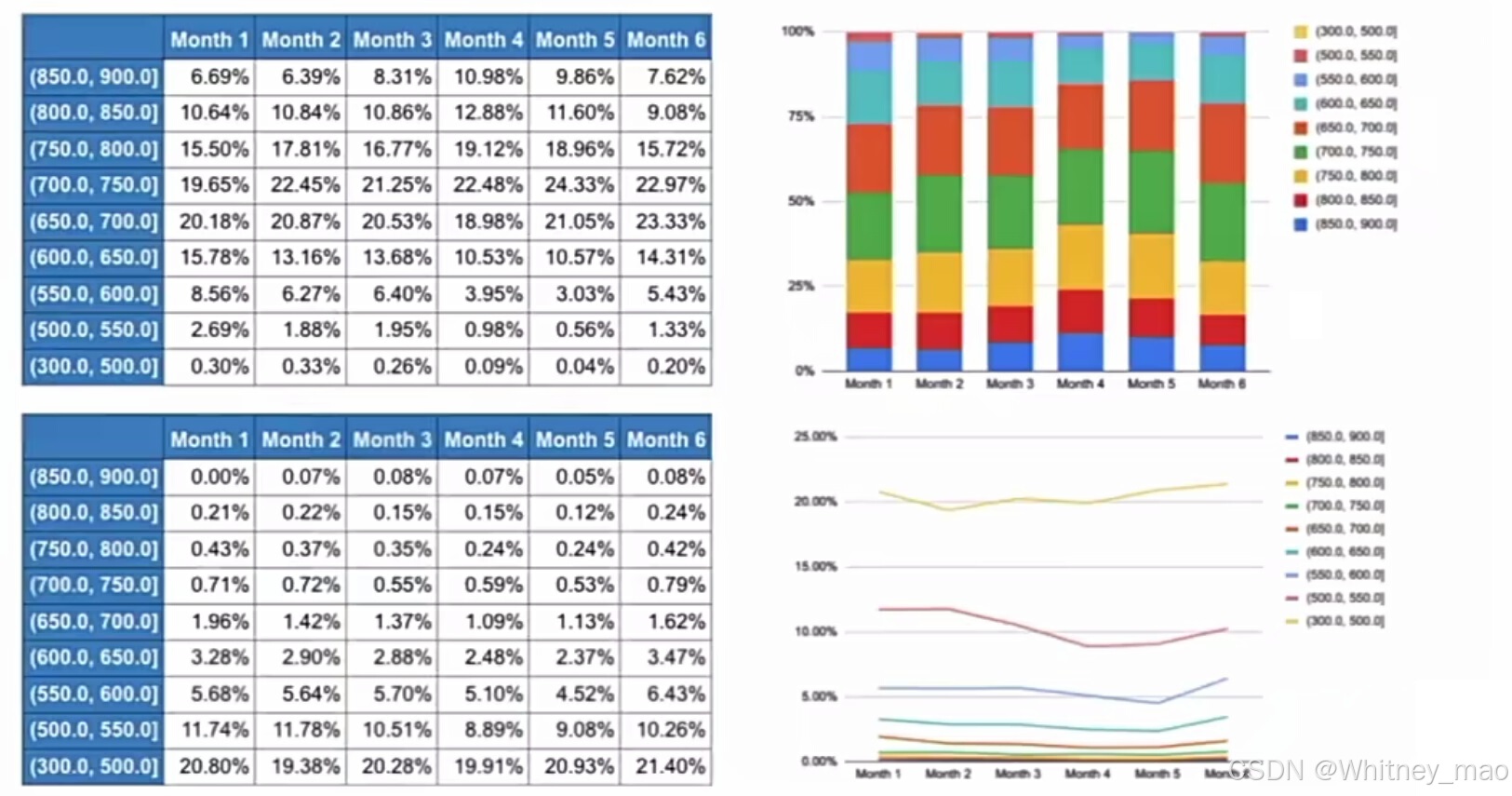
分数区分度:
分数稳定性:


















 273
273

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











