







XXLJOB–分布式任务调度平台
一、简介
1. 概述
- 核心设计目标:开发迅速、学习简单、轻量级、易扩展。
2. 特性
- 简单:支持通过Web页面对任务进行CRUD操作,操作简单
- 动态:支持动态修改任务状态、启动/停止任务,以及终止运行中任务即时生效支持
- 调度中心HA(中心式):调度采用中心式设计,“调度中心”字眼调度组件并支持集群部署,可保证调度中心HA
- 执行器HA(分布式):任务分布式执行,任务“执行器”支持集群部署,可保证任务执行HA
- 注册中心:执行器会周期性自动注册任务,调度中心将会自动发现注册的任务并出发执行。同时也支持手动录入执行器地址
- 弹性扩容缩容:一旦有新执行器机器上线或下线,下次调度时江湖重新分配任务
- 触发策略:提供丰富的任务触发策略,调度中心将会自动发现注册的任务并触发执行。同时,也支持手动录入执行器地址
- 调度过期策略:调度中心错过调度时间的补偿处理策略,包括:忽略、立即补偿触发一次等
- 阻塞处理策略:调度过于密集执行器来不及处理时的处理策略,策略包括:单机串行(默认)、丢弃后续调度、覆盖之前调度
- 任务超时控制:支持自定义任务超时时间,任务运行超时将会自动中断任务
- 任务失败重试:支持自定义任务失败重试次数,当任务失败时将会按照预设的失败重试次数主动进行重试;其中分片任务支持分片粒度的失败重试
分片粒度是指将一个任务或数据分割成多个较小的部分的程度。分片粒度的选择取决于具体的应用场景和需求。
较小的分片粒度可以提供更细粒度的并行性和更均衡的负载分配。这对于大规模数据处理、并行计算或分布式系统中的任务调度非常有用。如果任务或数据可以被有效地分割成独立的子任务或数据块,并且每个子任务或数据块的处理时间相对较短,较小的分片粒度可以实现更好的并行性和性能。
然而,较小的分片粒度也可能引入更多的开销,如分片管理开销、通信开销等。此外,如果任务或数据之间存在较强的依赖关系或需要共享状态,选择较小的分片粒度可能会导致额外的同步和通信开销。
因此,在选择分片粒度时,需要综合考虑任务的性质、数据量、计算资源等因素,并根据具体需求进行权衡。通常,可以通过实验和性能测试来确定最佳的分片粒度,以获得最佳的性能和效率。
总结起来,分片粒度的选择应该根据具体的应用场景和需求进行权衡,以获得最佳的性能和效率。
- 任务失败告警:默认提供邮件方式失败告警,同时预留扩展接口,可方便的扩展短信、钉钉等告警方式
- 路由策略:执行器集群部署时提供丰富的路由策略,包括:第一个、最后一个、轮询、随机、一致性HASH、最不经常使用、最近最久未使用、故障转移、忙碌转移等
- 第一个(First/Primary):选择第一个或主节点进行操作。例如,可以选择第一个服务器或主数据库来处理请求或操作。
- 最后一个(Last/Backup):选择最后一个或备份节点进行操作。例如,在主节点不可用时,可以切换到备份节点来继续处理请求或操作。
- 轮询(Round Robin):按照顺序依次选择可用节点来处理请求。每个请求依次分发给不同的节点,以实现负载均衡。
- 随机(Random):随机选择一个可用节点来处理请求。每个请求都随机分配给一个节点,以实现负载均衡。
- 一致性哈希(Consistent Hashing):根据节点的哈希值将数据或请求映射到不同的节点。这种方法可以减少节点之间的数据迁移,同时提供负载均衡和故障转移能力。
- 最不经常使用(Least Frequently Used,LFU):选择最不频繁使用的节点来处理请求。这种算法根据节点的使用频率,选择最少使用的节点来分配请求。
- 最近最久未使用(Least Recently Used,LRU):选择最近最久未使用的节点来处理请求。这种算法根据节点上一次使用的时间戳,选择最长时间未使用的节点来分配请求。
- 故障转移(Failover):在主节点或主服务器故障时,自动切换到备份节点或备份服务器,以保证服务的可用性和连续性。
- 忙碌转移(Busy Transfer):当节点或服务器负载过高时,将请求转发到负载较低的节点或服务器,以平衡负载和提高性能。
这些术语在分布式系统、负载均衡、缓存管理和故障恢复等场景中经常使用,用于选择合适的节点、服务器或处理策略来实现高效的数据处理和服务管理。
请注意,具体的实现方法和算法可能因应用和环境的不同而有所变化。对于特定的应用场景,需要根据需求和目标选择适当的策略和算法。
- 分片广播任务:执行器集群部署时,任务路由策略选择“分片广播”情况下,一次任务调度将会广播触发集群中所有执行器执行一次任务,可根据分片参数开发分片任务
- 动态分片:分片广播任务以执行器为维度进行分片,支持动态扩展执行器集群从而动态增加分片数量,协同进行业务处理;在进行大数据量业务操作时可显著提升任务处理能力和速度
- 故障转移:任务路由策略选择“故障转移”情况下,如果执行器集群中国某一台机器故障,将会自动Failover切换到一台正常的执行器发送调度请求
- 任务进度监控:支持实时监控任务进度
- Rolling实时日志:支持在线查看调度结果,并且支持以Rolling方式实时查看执行器输出的完整的执行日志
- GLUE:提供Web IDE ,支持在线开发任务逻辑代码,动态发布,实时编译生效,省略部署上线的过程。支持30个版本的历史版本回溯
- 脚本任务:支持以GLUE模式和运行脚本任务,包括Shell、Python、NodeJS、PHP、PowerShell等类型脚本
- 命令行任务:原生提供通用命令行任务Handler(Bean任务,“CommandJobHandler”);业务方只需要提供命令行即可
- 任务依赖:支持配置子任务依赖,当父任务执行结束且执行成功后将会自动触发一次子任务的执行,多个子任务用逗号分隔
- 一致性:“调度中心”通过DB锁保证集群分布式调度的一致性,一次任务调度只会触发一次执行
- 自定义任务参数:支持在线配置调度任务入参,即时生效
- 调度线程池:调度系统多线程触发调度运行,确保调度精确执行,不被堵塞
- 数据加密:调度中心和执行器之间的通讯进行数据加密,提升调度信息安全性
- 邮件报警:任务失败时支持邮件报警,支持配置多邮件地址群发报警邮件
- 推送maven中央仓库:将会把最新稳定版推送到maven中央仓库,方便用户接入和使用
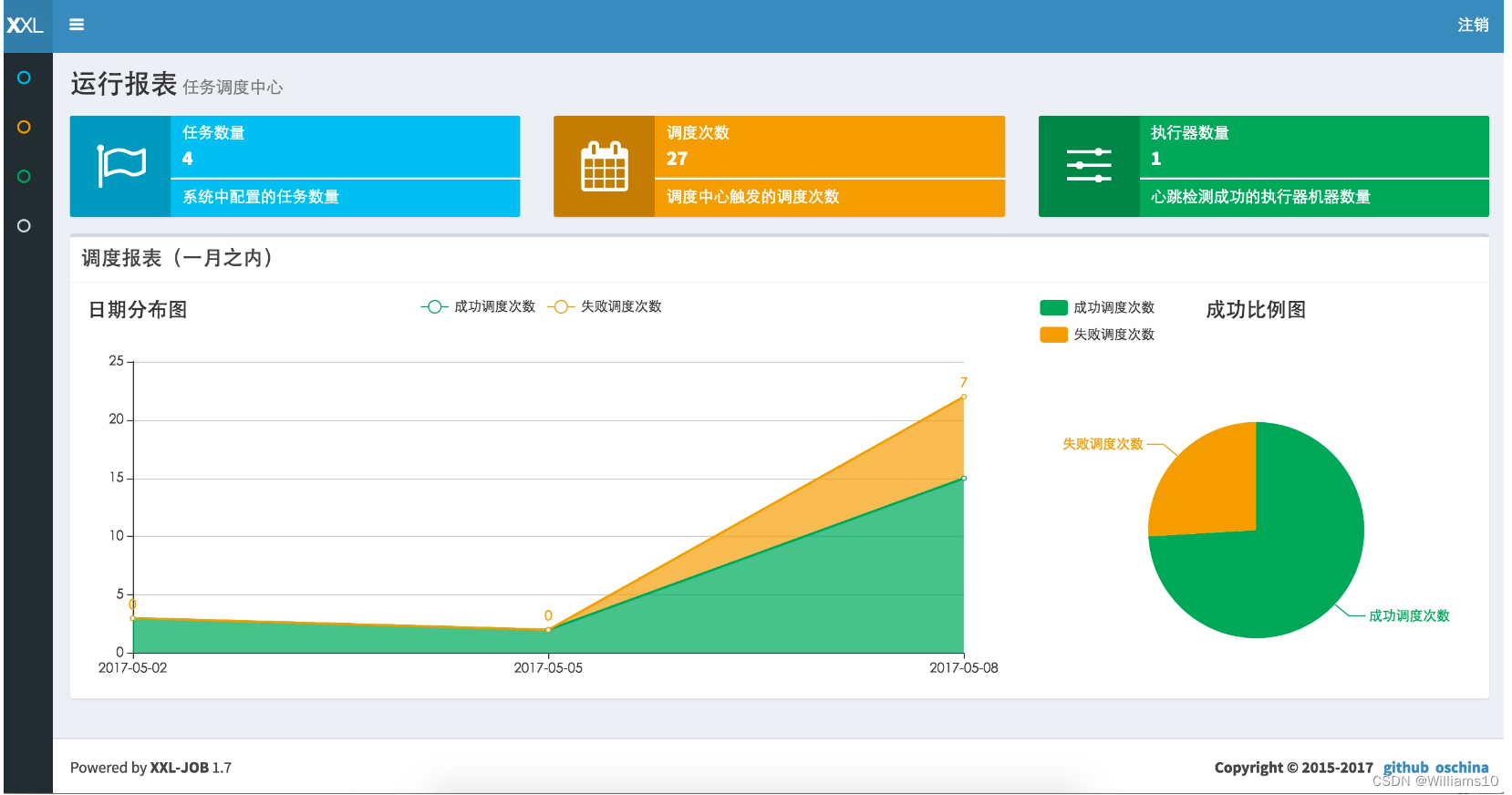
- 运行报表:支持实时查看运行数据,如任务数量、调度次数、执行器数量等;以及调度报表,如调度日期分布图、调度成功分布图等
- 全异步:任务调度流程全异步化设计实现,如异步调度、异步运行、异步回调等,有效对密集调度进行流量削峰,理论上支持任意时长任务的运行
- 跨语言:调度中心与执行器提供语言无关的RESTful API服务,第三方任意语言可据此对接调度中心或者实现执行器。除此之外,还提供了“多任务模式”和“httpJobHandler”等其他跨语言方案
- 国际化:调度中心支持国际化设置,提供中文、英文两种可选语言,默认为中文
- 容器化:提供官方docker镜像,并实时更新推送dockerhub,进一步实现产品开箱即用
- 线程池隔离:调度线程池进行隔离拆分,慢任务自动降级进入“Slow”线程池,避免耗尽调度线程,提高系统稳定性
- 用户管理:支持在线管理系统用户,存在管理员、普通用户两种角色
- 权限控制:执行器维度进行权限控制,管理员拥有全量权限,普通用户需要分配执行器权限后才允许相关操作
3.下载
源码仓库地址
中央仓库地址
<!-- http://repo1.maven.org/maven2/com/xuxueli/xxl-job-core/ -->
<dependency>
<groupId>com.xuxueli</groupId>
<artifactId>xxl-job-core</artifactId>
<version>${最新稳定版本}</version>
</dependency>
4. 环境
Maven3+
Jdk1.8+
Mysql5.7+
二、快速入门
1. 初始化“调度数据库”
调度数据库初始化SQL脚本
/xxl-job/doc/db/tables_xxl_job.sql
- 调度中心支持集群部署,集群情况下各节点务必连接同一个mysql实例
- 如果mysql做主从,调度中心集群节点务必强制走主库
2. 源码
- 以Maven格式导入IDE,使用Maven编译
- 源码结构
xxl-job-admin:调度中心
xxl-job-core:公共依赖
xxl-job-executor-samples:执行器Sample示例(选择合适的版本执行器,可直接使用,也可以参考其并将现有项目改造成执行器)
:xxl-job-executor-sample-springboot:Springboot版本,通过Springboot管理执行器,推荐这种方式;
:xxl-job-executor-sample-frameless:无框架版本;
3. 配置部署“调度中心”
-
调度中心:
xxl-job-admin -
作用:同意管理任务调度平台上调度任务,负责触发调度执行,并且提供任务管理平台
step1.调度中心配置
- 配置文件地址
/xxl-job/xxl-job-admin/src/main/resources/application.properties
- 配置内容说明
### 调度中心JDBC链接:链接地址请保持和 2.1章节 所创建的调度数据库的地址一致
spring.datasource.url=jdbc:mysql://127.0.0.1:3306/xxl_job?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&serverTimezone=Asia/Shanghai
spring.datasource.username=root
spring.datasource.password=root_pwd
spring.datasource.driver-class-name=com.mysql.jdbc.Driver
### 报警邮箱
spring.mail.host=smtp.qq.com
spring.mail.port=25
spring.mail.username=xxx@qq.com
spring.mail.password=xxx
spring.mail.properties.mail.smtp.auth=true
spring.mail.properties.mail.smtp.starttls.enable=true
spring.mail.properties.mail.smtp.starttls.required=true
spring.mail.properties.mail.smtp.socketFactory.class=javax.net.ssl.SSLSocketFactory
### 调度中心通讯TOKEN [选填]:非空时启用;
xxl.job.accessToken=
### 调度中心国际化配置 [必填]: 默认为 "zh_CN"/中文简体, 可选范围为 "zh_CN"/中文简体, "zh_TC"/中文繁体 and "en"/英文;
xxl.job.i18n=zh_CN
## 调度线程池最大线程配置【必填】
xxl.job.triggerpool.fast.max=200
xxl.job.triggerpool.slow.max=100
### 调度中心日志表数据保存天数 [必填]:过期日志自动清理;限制大于等于7时生效,否则, 如-1,关闭自动清理功能;
xxl.job.logretentiondays=30
step2. 部署项目
- 对调度中心(xxl-job-admin)进行编译打包部署
- 调度中心访问地址【将作为回调地址被执行器使用】
- 默认登录账号:admin
- 默认登录密码:123456
step3. 调度中心集群(可选)
调度中心支持集群部署,提升调度系统容灾和可用性
- 要求
- DB部署保持一致
- 集群机器始终保持一致(单机集群忽略)
- 建议
- 推荐通过nginx为调度中心集群做负载均衡,分配域名。
- 调度中心访问、调度执行器回调配置、调度API服务等操作均通过该域名进行。
其他:Docker镜像方式搭建调度中心
- 下载
// Docker地址:https://hub.docker.com/r/xuxueli/xxl-job-admin/ (建议指定版本号)
docker pull xuxueli/xxl-job-admin
- 创建容器并运行
docker run -p 8080:8080 -v /tmp:/data/applogs --name xxl-job-admin -d xuxueli/xxl-job-admin:{指定版本}
/**
* 如需自定义 mysql 等配置,可通过 "-e PARAMS" 指定,参数格式 PARAMS="--key=value --key2=value2" ;
* 配置项参考文件:/xxl-job/xxl-job-admin/src/main/resources/application.properties
* 如需自定义 JVM内存参数 等配置,可通过 "-e JAVA_OPTS" 指定,参数格式 JAVA_OPTS="-Xmx512m" ;
*/
docker run -e PARAMS="--spring.datasource.url=jdbc:mysql://127.0.0.1:3306/xxl_job?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&serverTimezone=Asia/Shanghai" -p 8080:8080 -v /tmp:/data/applogs --name xxl-job-admin -d xuxueli/xxl-job-admin:{指定版本}
4. 配置部署“执行器项目”
- “执行器”项目:
xxl-job-executor-sample-springboot(提供多种版本执行器供选择,现以springboot版本为例,可直接使用,也可以参考其并将现有项目改造成执行器)- 作用:负责接收“调度中心”的调度并执行;可直接部署执行器,也可以将执行器集成到现有业务项目中。
step1. maven依赖
确定pom.xml文件引入了"xxl-job-core"的maven依赖;
step2. 执行器配置
执行器配置,配置文件地址:
/xxl-job-executor-samples/xxl-job-executor-sample-springboot/src/main/resources/application.properties
执行器配置,配置内容说明:
### 调度中心部署根地址 [选填]:如调度中心集群部署存在多个地址则用逗号分隔。执行器将会使用该地址进行"执行器心跳注册"和"任务结果回调";为空则关闭自动注册;
xxl.job.admin.addresses=http://127.0.0.1:8080/xxl-job-admin
### 执行器通讯TOKEN [选填]:非空时启用;
xxl.job.accessToken=
### 执行器AppName [选填]:执行器心跳注册分组依据;为空则关闭自动注册
xxl.job.executor.appname=xxl-job-executor-sample
### 执行器注册 [选填]:优先使用该配置作为注册地址,为空时使用内嵌服务 ”IP:PORT“ 作为注册地址。从而更灵活的支持容器类型执行器动态IP和动态映射端口问题。
xxl.job.executor.address=
### 执行器IP [选填]:默认为空表示自动获取IP,多网卡时可手动设置指定IP,该IP不会绑定Host仅作为通讯实用;地址信息用于 "执行器注册" 和 "调度中心请求并触发任务";
xxl.job.executor.ip=
### 执行器端口号 [选填]:小于等于0则自动获取;默认端口为9999,单机部署多个执行器时,注意要配置不同执行器端口;
xxl.job.executor.port=9999
### 执行器运行日志文件存储磁盘路径 [选填] :需要对该路径拥有读写权限;为空则使用默认路径;
xxl.job.executor.logpath=/data/applogs/xxl-job/jobhandler
### 执行器日志文件保存天数 [选填] : 过期日志自动清理, 限制值大于等于3时生效; 否则, 如-1, 关闭自动清理功能;
xxl.job.executor.logretentiondays=30
step3. 执行器组件配置
- 执行器组件,配置文件地址:
/xxl-job-executor-samples/xxl-job-executor-sample-springboot/src/main/java/com/xxl/job/executor/core/config/XxlJobConfig.java
- 执行器组件,配置内容说明:
@Bean
public XxlJobSpringExecutor xxlJobExecutor() {
logger.info(">>>>>>>>>>> xxl-job config init.");
XxlJobSpringExecutor xxlJobSpringExecutor = new XxlJobSpringExecutor();
xxlJobSpringExecutor.setAdminAddresses(adminAddresses);
xxlJobSpringExecutor.setAppname(appname);
xxlJobSpringExecutor.setIp(ip);
xxlJobSpringExecutor.setPort(port);
xxlJobSpringExecutor.setAccessToken(accessToken);
xxlJobSpringExecutor.setLogPath(logPath);
xxlJobSpringExecutor.setLogRetentionDays(logRetentionDays);
return xxlJobSpringExecutor;
}
step4. 部署执行器项目
- 确定进行上述配置后,可将执行器项目编译打部署,系统提供多种执行器Sample示例项目,选择其中一个即可,各自的部署方式如下:
xxl-job-executor-sample-springboot:项目编译打包成springboot类型的可执行JAR包,命令启动即可;
xxl-job-executor-sample-frameless:项目编译打包成JAR包,命令启动即可;
step5. 执行器集群(可选)
- 执行器支持集群部署,提升调度系统可用性,同时提升任务处理能力。
- 要求与建议
- 执行器回调地址(xxl.job.admin.addresses)需要保持一致;执行器根据该配置进行执行器自动注册等操作。
- 同一个执行器集群内AppName(xxl.job.executor.appname)需要保持一致;调度中心根据该配置动态发现不同集群的在线执行器列表。
5. 开发第一个任务“Hello World”
新建一个 “GLUE模式(Java)” 运行模式的任务
( “GLUE模式(Java)”的执行代码托管到调度中心在线维护,相比“Bean模式任务”需要在执行器项目开发部署上线,更加简便轻量)
前提:请确认“调度中心”和“执行器”项目已经成功部署并启动;
step1. 新建任务
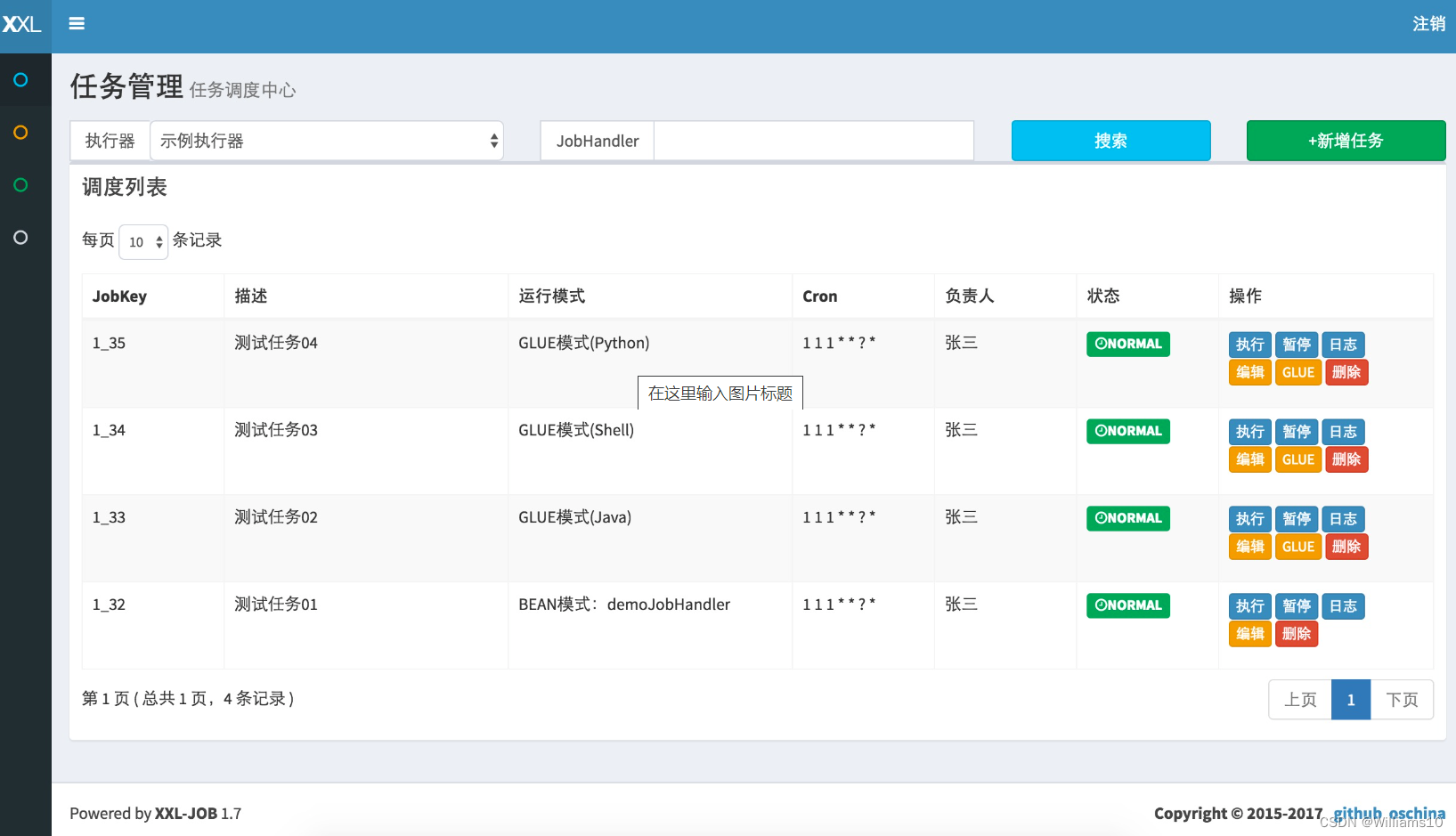
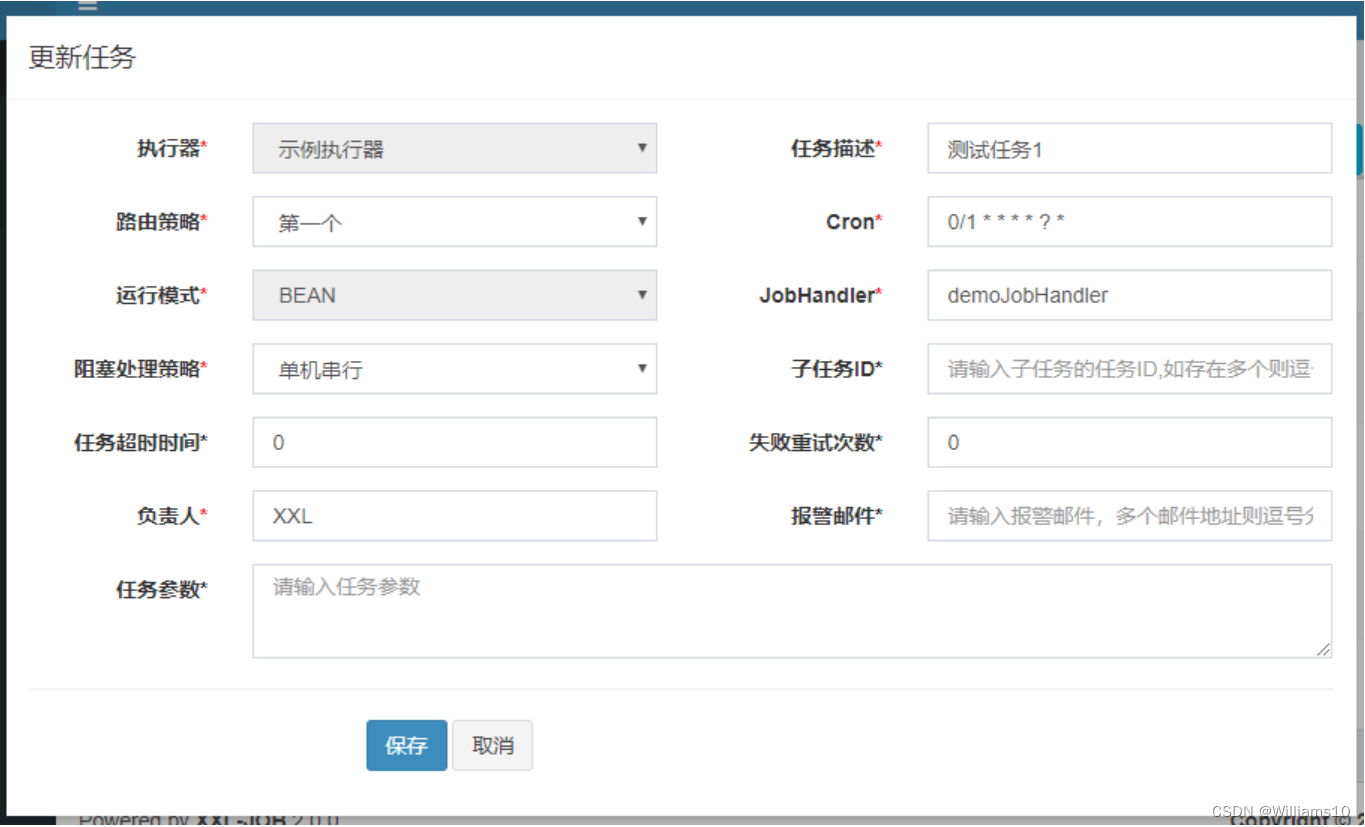
- 登录调度中心,点击下图所示“新建任务”按钮,新建示例任务。参考下面截图中任务的参数配置,点击保存
step2. “GLUE模式(Java)”任务开发
- 点击任务右侧“GLUE”按钮,进入“GLUE编辑器开发界面”。“GLUE模式(Java)”运行模式的任务默认已经初始化了示例任务代码,即打印Hello World。
(“GLUE模式(Java)”运行模式的任务实际上是一段继承自IJobHandler的Java类代码,它在执行器项目中玉兴,可使用@Resource/@Autowire注入执行器里中的其他服务)

step3. 触发执行
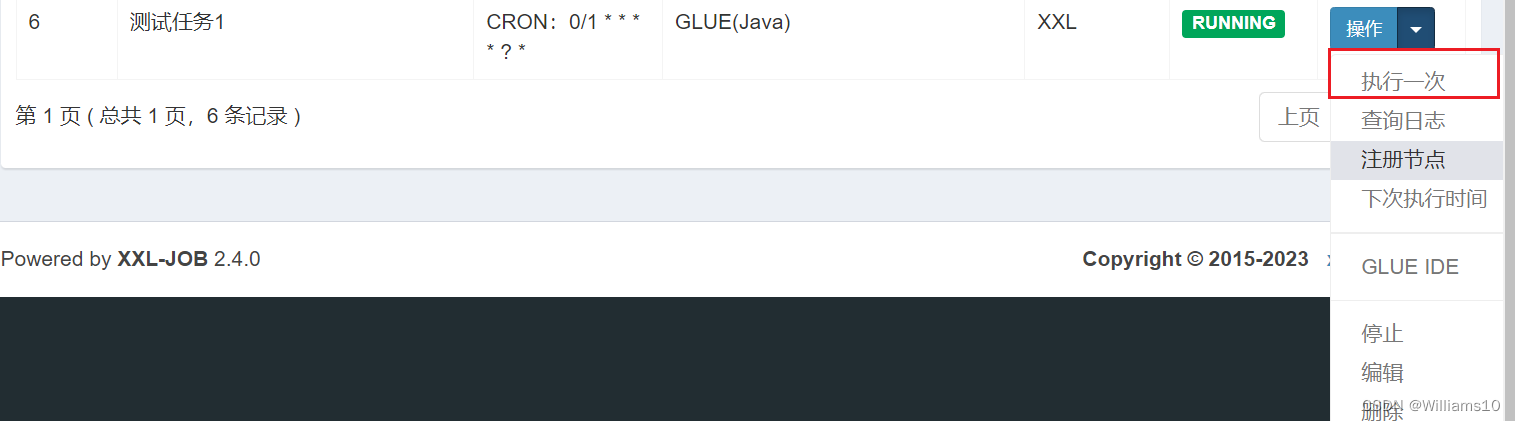
- 点击任务右侧 “执行” 按钮,可手动触发一次任务执行(通常情况下,通过配置Cron表达式进行任务调度触发)
step4. 查看日志
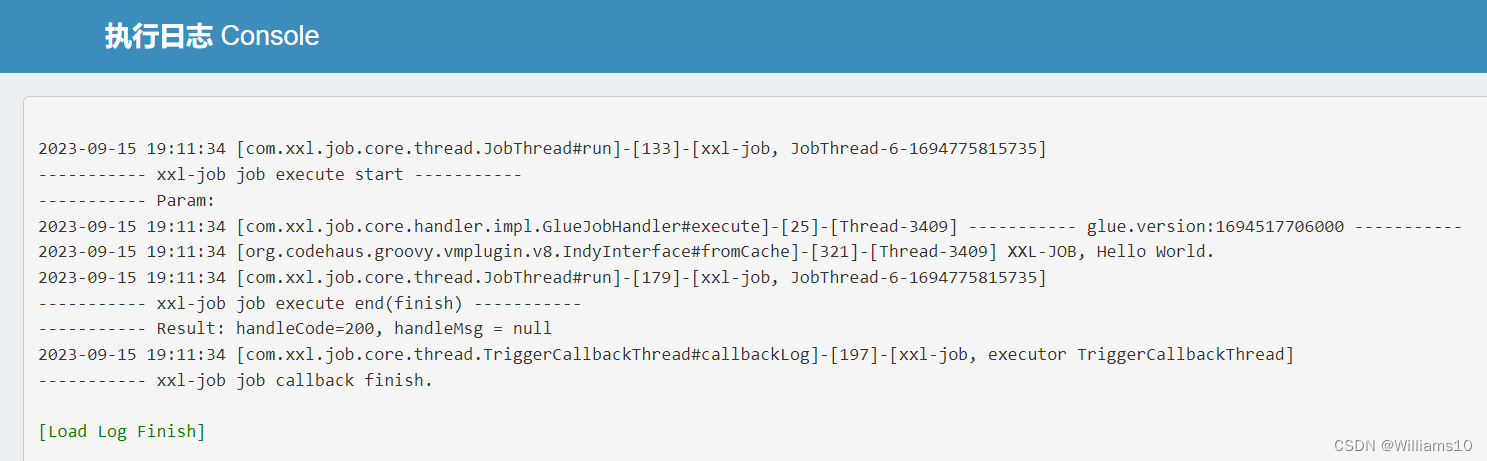
- 点击任务右侧“日志”按钮,可前往任务日志界面查看任务日志
- 在任务日志界面中,可查看该任务的历史调度记录以及每一次调度的任务调度信息、执行参数和执行信息。运行中的任务点击右侧的“执行日志”按钮,可进入日志控制台查看实时执行日志。
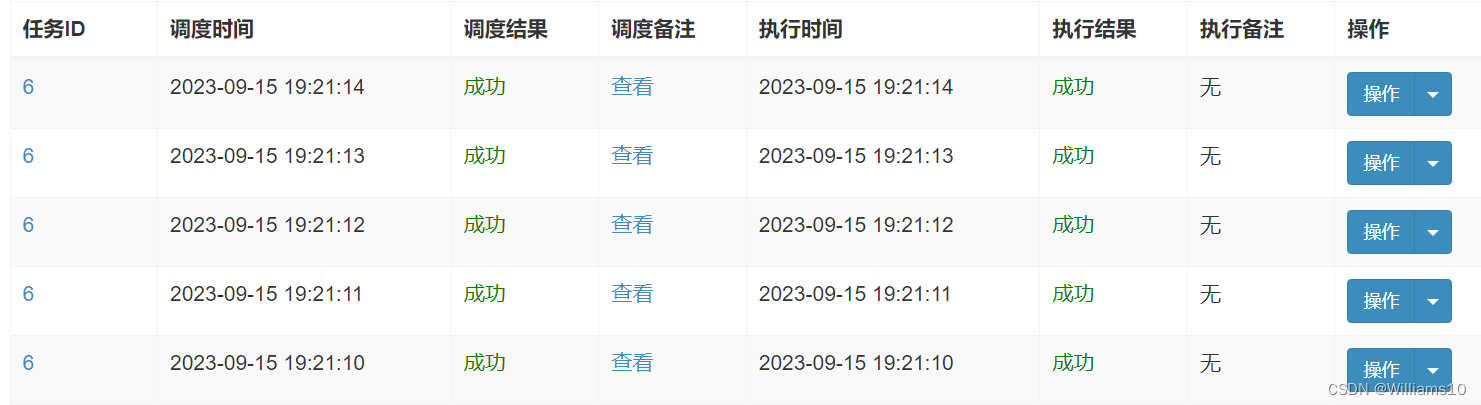
三、 任务详解
配置属性详细说明:
基础配置:
- 执行器:任务的绑定的执行器,任务触发调度时将会自动发现注册成功的执行器,实现任务自动发现功能;也可以方便的进行任务分组。每个任务必须绑定一个执行器,可在“执行器管理”进行设置
- 任务描述:任务的描述信息,便于任务管理
- 负责人:任务的负责人
- 报警邮件:任务调度失败时邮件通知的邮箱地址,支持配置多邮箱地址,配置多个邮箱地址时用逗号分隔
触发配置:
- 调度类型:
- 无:该类型不会主动触发调度
- CRON:该类型将会通过CRON,触发任务调度
- 固定速度:该类型将会以固定速度,触发任务调度;按照固定的间隔时间,周期性触发;
- 固定延迟:该类型将会以固定延迟,触发任务调度;安好固定的延迟时间,从上次调度结束后开始计算延迟使劲按,到达延迟时间后触发下次调度
- CRON:触发任务执行的Cron表达式
- 固定速度:固定速度的时间间隔,单位为秒
- 固定延迟:固定延迟的时间间隔,单位为秒
任务配置:
- 运行模式:
- BEAN模式:任务以JobHandler方式维护在执行器段;需要结合“JobHandler”属性匹配执行器中任务
- GLUE模式(Java):任务以源码方式维护在调度中心;该模式的任务实际上是一段继承自IJobHandler的Java类代码并"groovy"源码方式维护,它在执行器项目中运行,可使用@Resource/@Autowire注入执行器里中的其他任务
- GLUE模式(Shell):任务以源码方式维护在调度中心;该模式的任务实际上是一段"shell" 脚本
- GLUE模式(Python):任务以源码方式维护在调度中心;该模式的任务实际上是一段 “python” 脚本
- GLUE模式(PHP):任务以源码方式维护在调度中心;该模式的任务实际上是一段 “php” 脚本
- GLUE模式(NodeJS):任务以源码方式维护在调度中心;该模式的任务实际上是一段 “nodejs” 脚本
- GLUE模式(PowerShell):任务以源码方式维护在调度中心;该模式的任务实际上是一段 “PowerShell” 脚本
- JobHandler:运行模式为==“BEAN模式”==时生效,对应执行器中新开发的JobHandler类“@JobHandler”注解自定义的value值
- 执行参数:任务执行所需的参数
高级配置:
- 路由策略:当执行器集群部署时,提供丰富的路由策略,包括:
FIRST(第一个):固定选择第一次机器
LAST(最后一个):固定选择最后一个机器
ROUND(轮询):按照顺序依次选择可用节点来处理请求
RANDOM(随机):随机选择在线的机器
CONSISTENT_HASH(一致性HASH):每个任务按照Hash算法固定选择某一台机器,且所有任务均匀散列在不同机器上
LEAST_FREQUENTLY_USED(最不经常使用):使用频率最低的机器优先被选举
LEAST_RECENTLY_USED(最近最久未使用):最久未使用的机器优先被选举
FAILOVER(故障转移):按照顺序依次进行心跳检测,第一个心跳检测成功的机器选定为目标执行器并发起调度
BUSYOVER(忙碌转移):按照顺序依次进行空闲检测,第一个空闲检测成功的机器选定为目标执行器并发起调度
SHARDING_BROADCAST(分片广播):广播触发对应集群中所有机器执行一次任务,同时系统自动传递分片参数;可根据分片参数开发分片任务
- 子任务:每个任务都拥有一个唯一的任务ID(任务ID可以从任务列表获取),当本人无执行结束并且执行成功时,将会触发子任务ID锁对应的任务的一次主动调度
- 调度过期策略:
- 忽略:调度过期后,忽略过期的任务,从当前时间开始重新计算下次触发时间
- 立即执行一次:调度过期后,立即执行一次,并从当前时间按开始重新计算下次触发时间
- 阻塞处理策略:调度过于密集执行器来不及处理时的处理策略
- 单机串行(默认):调度请求进入单机执行器后,调度请求进入FIFO队列并以串行方式运行
- 丢弃后续调度:调度请求进入淡季执行器后,发现执行器存在运行的调度任务,本次请求将会被丢弃并标记为失败
- 覆盖之前调度:调度请求进入单机执行器后,发现执行器存在运行的调度任务,将会终止运行中的调度任务并清空队列,然后运行本地调度任务
- 任务超时时间:支持自定义任务超时时间,任务运行超时将会主动中断任务
- 失败重试次数:支持自定义任务失败重试次数,当任务失败时将会按照预约的失败重试次数主动进行重试
1. BEAN模式(类形式)
- Bean模式任务,支持基于类的开发方式,每个任务对应一个Java类
- 优点:不限制项目环境,兼容性好。即使是无框架项目,如main方法直接启动的项目也可以提供支持,可以参考示例项目 “xxl-job-executor-sample-frameless”
- 缺点:每个人物需要占用一个Java类,造成类的浪费
- 不支持自动扫描任务并注入到执行器容器,需要手动注入
step1. 执行器项目中,开发Job类
1、开发一个继承自"com.xxl.job.core.handler.IJobHandler"的JobHandler类,实现其中任务方法。
2、手动通过如下方式注入到执行器容器。
```
XxlJobExecutor.registJobHandler("demoJobHandler", new DemoJobHandler());
```
step2. 调度中心,新建调度任务
后续步骤与2.BEAN模式(方法形式)一致
2. BEAN模式(方法形式)
- Bean模式任务,支持基于方法的开发方式,每个任务对应一个方法
- 优点:
- 每个任务只需要开发一个方法,并添加“@XxlJob”注解即可,更加方便、快速
- 支持自动扫描任务并注入到执行器容器
- 缺点:要求Spring容器环境
- 优点:
基于方法开发的任务,底层会生成JobHandler代理,和基于类的方式一样,任务也会以JobHandler的形式存在于执行器任务容器中
step1. 执行器项目中,开发Job方法
- 任务开发:在Spring Bean实例中,开发Job方法
- 注解配置:为Job方法添加注解"@XxlJob(value=“自定义Jobhandler名称”, init = “JobHandler初始化方法”, destroy = “JobHandler销毁方法”)",注解value值对应的是调度中心新建任务的JobHandler属性的值
- 执行日志:需要通过"XxlJobHelper.log"打印执行日志
- 任务结果:默认任务结果为"成功"状态,不需要主动设置;如有诉求,比如设置任务结果为失败,可以通过"XxlJobHelper.handleFail/handleSuccess"自主设置任务结果
// 可参考Sample示例执行器中的 "com.xxl.job.executor.service.jobhandler.SampleXxlJob" ,如下:
@XxlJob("demoJobHandler")
public void demoJobHandler() throws Exception {
XxlJobHelper.log("XXL-JOB, Hello World.");
}
step2. 调度中心,新建调度任务
- “BEAN模式”,JobHandler属性填写任务注解“@XxlJob”中定义的值;

- 原生内置Bean模式任务
执行器内原生提供多个Bean模式任务Handle,可以直接配置实用,如下:
- demoJobHandler:简单示例任务,任务内部模拟耗时任务逻辑,用户可在线体验Rolling Log等功能
- shardingJobHandler:分片示例任务,任务内部模拟处理分片参数,可参考熟悉分片任务
- httpJobHandler:通用HTTP任务Handler;业务方只需要提供HTTP链接等信息即可,不限制语言、平台。示例任务入参如下:
url: http://www.xxx.com
method: get 或 post
data: post-data
- commandJobHandler:通用命令行任务Handler;业务方只需要提供命令行即可;如“pwd”命令
3. GLUE模式(Java)
- 任务以源码方式维护在调度中心,支持通过Web IDE在线更新,实时编译和生效,因此不需要指定JobHandler。开发流程如下:
step1. 调度中心,新建调度任务
默认登录密码

step2. 开发任务代码
-
GLUE模式(Shell、Python、Java、NodeJS、PHP、PowerShell)
-
选中指定任务,点击该任务右侧“GLUE”按钮,将会前往GLUE任务的Web IDE界面,在该界面支持对任务代码进行开发(也可以在IDE中开发完成后,复制粘贴到编辑中)
-
版本回溯功能(支持30个版本的版本回溯):在GLUE任务的Web IDE界面,选择右上角下拉框“版本回溯”,会列出该GLUE的更新历史,选择相应版本即可显示该版本代码,保存后GLUE代码即回退到对应的历史版本

四、操作指南
1. 配置执行器
- 点击进入“执行器管理”界面。

- **调度中心OnLine:**右侧显示在线的“调度中心”列表,任务执行结束后,将会以failover的模式进行回调调度中心通知执行结果,避免回调的单点风险
- 执行器列表中显示在线的执行器列表,可通过“OnLine机器”查看对应执行器的集群机器
点击按钮“+新增执行器”弹框,可新增执行器配置

执行器属性说明
- AppName:每个执行器集群的唯一标示AppName,执行器会周期性以AppName为对象进行自动注册。可通过该配置自动发现注册成功的执行器,供任务调度时使用
- 名称:执行器的名称,因为AppName限制字母数字等组成,可读性不强,名称为了提高执行器的可读性
- 排序:执行器的排序,系统中需要执行器的地方,如任务新增,将会按照该排序读取可用的执行器列表
- 注册方式:调度中心获取执行器地址的方式
- 自动注册:执行器自动进行执行器注册,调度中心通过底层注册表可以动态发现执行器机器地址
- 手动注册:人工手动录入执行器的地址信息,多地址逗号分隔,供调度中心使用
- 机器地址:==“注册方式"为"手动录入”==时有效,支持人工维护执行器的地址信息
2. 新建任务
进入任务管理界面,点击“**新增任务”**按钮,在弹出的“新增任务”界面配置任务属性后保存即可
3. 编辑任务
进入任务管理界面,选中指定任务。点击该任务右侧“编辑”按钮,在弹出的“编辑任务”界面更新任务属性后保存即可,可以修改设置的任务属性信息
4. 编辑GLUE代码
该操作仅针对GLUE任务。
选中指定任务,点击该任务右侧“GLUE”按钮,将会前往GLUE任务的Web IDE界面,在该界面支持对任务代码进行开发。可参考章节 “3.3 GLUE模式(Java)”。
5. 启动/停止任务
可对任务进行“启动”和“停止”操作。
需要注意的是,此处的启动/停止仅针对任务的后续调度触发行为,不会影响到已经触发的调度任务,如需终止已经触发的调度任务,可查看“4.9 终止运行中的任务”

6. 手动触发一次调度
点击“执行”按钮,可手动触发一次任务调度,不影响原有调度规则。

7. 查看调度日志
点击“日志”按钮,可以查看任务历史调度日志。在历史调入日志界面可查看每次任务调度的调度结果、执行结果等,点击“执行日志”按钮可查看执行器完整日志

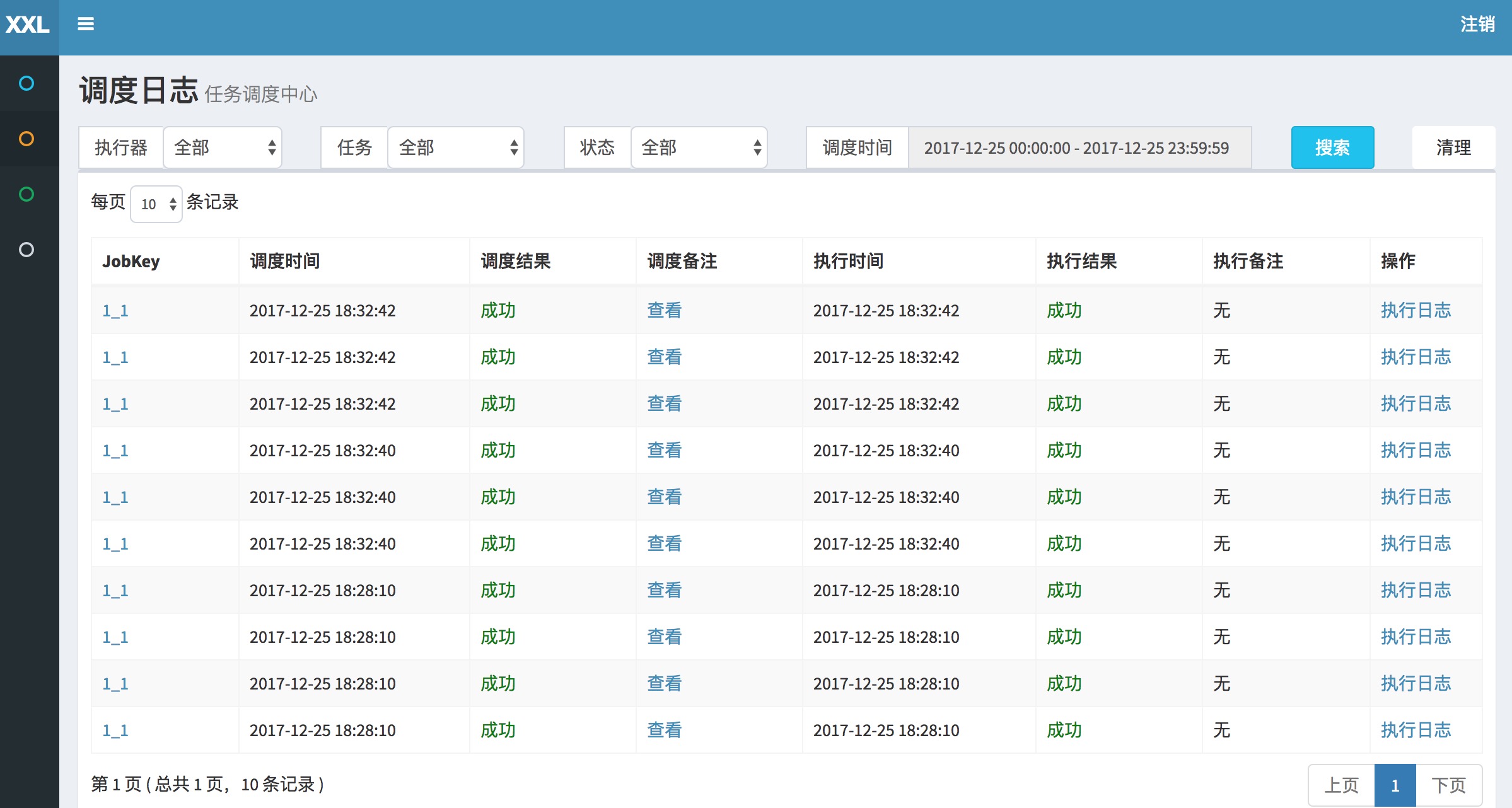
- 调度时间:“调度中心”触发本次调度并向“执行器”发送任务执行信号的时间
- 调度结果:“调度中心”触发本次调度的结果,200表示成功,500或其他表示失败
- 调度备注:“调度中心”触发本次调度的日志信息
- 执行器地址:本次任务执行的机器地址
- 运行模式:触发调度时任务的运行模式
- 任务参数:本地任务执行的入参
- 执行时间:“执行器”中本次任务执行结束后回调的时间
- 执行结果:“执行器”中本次任务执行的结果,200表示成功,500或其他表示失败
- 执行备注:“执行器”中本次任务执行的日志信息
- 操作:
- “执行日志”按钮:点击可查看本地任务执行的详细日志信息
- “终止任务”按钮:点击可终止本地调度对应执行器上本任务的执行线程,包括未执行的阻塞任务一并被终止
8. 查看执行日志
点击执行日志右侧的 “执行日志” 按钮,可跳转至执行日志界面,可以查看业务代码中打印的完整日志

9. 终止运行中的任务
仅针对执行中的任务。
在任务日志界面,点击右侧的“终止任务”按钮,将会向本次任务对应的执行器发送任务终止请求,将会终止掉本次任务,同时会清空掉整个任务执行队列

任务终止时通过 “interrupt” 执行线程的方式实现, 将会触发 “InterruptedException” 异常。因此如果JobHandler内部catch到了该异常并消化掉的话, 任务终止功能将不可用
因此, 如果遇到上述任务终止不可用的情况, 需要在JobHandler中应该针对 “InterruptedException” 异常进行特殊处理 (向上抛出) , 正确逻辑如下:
try{
// do something
}
catch (Exception e) {
if (e instanceof InterruptedException)
{
throw e;
}
logger.warn("{}", e);
}
而且,在JobHandler中开启子线程时,子线程也不可catch处理”InterruptedException”,应该主动向上抛出
任务终止时会执行对应JobHandler的”destroy()”方法,可以借助该方法处理一些资源回收的逻辑
10. 删除执行日志
在任务日志界面,选中执行器和任务之后,点击右侧的”删除”按钮将会出现”日志清理”弹框,弹框中支持选择不同类型的日志清理策略,选中后点击”确定”按钮即可进行日志清理操作
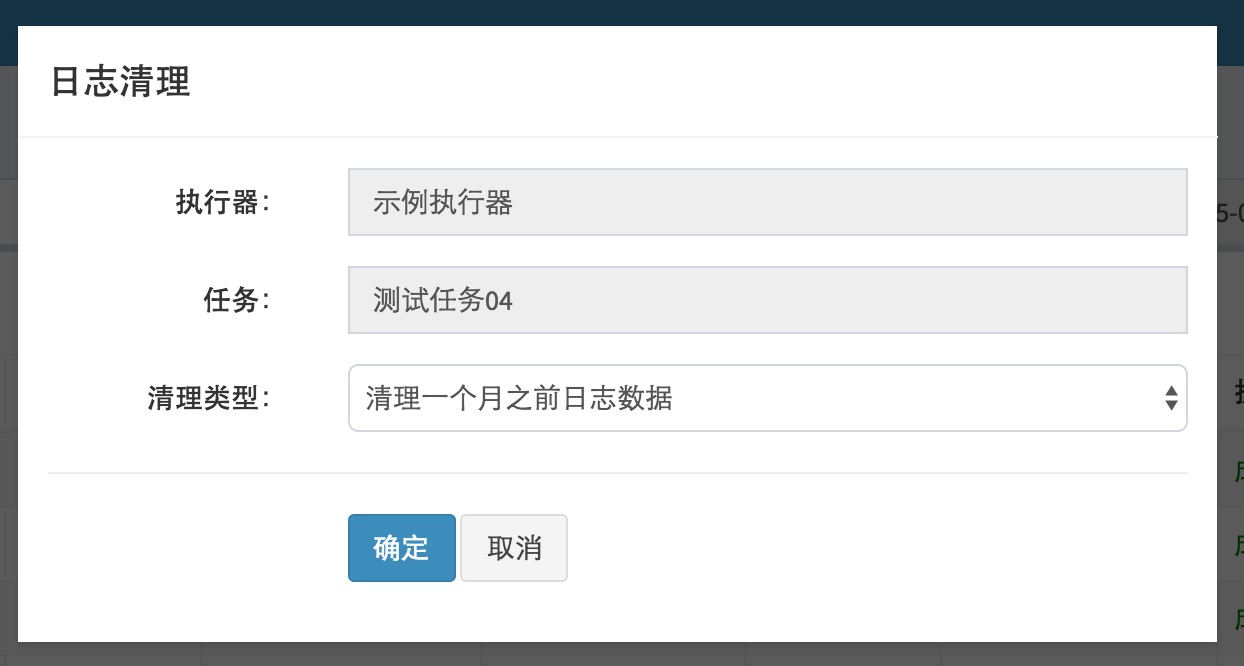
11. 删除任务
点击删除按钮,可以删除对应任务。

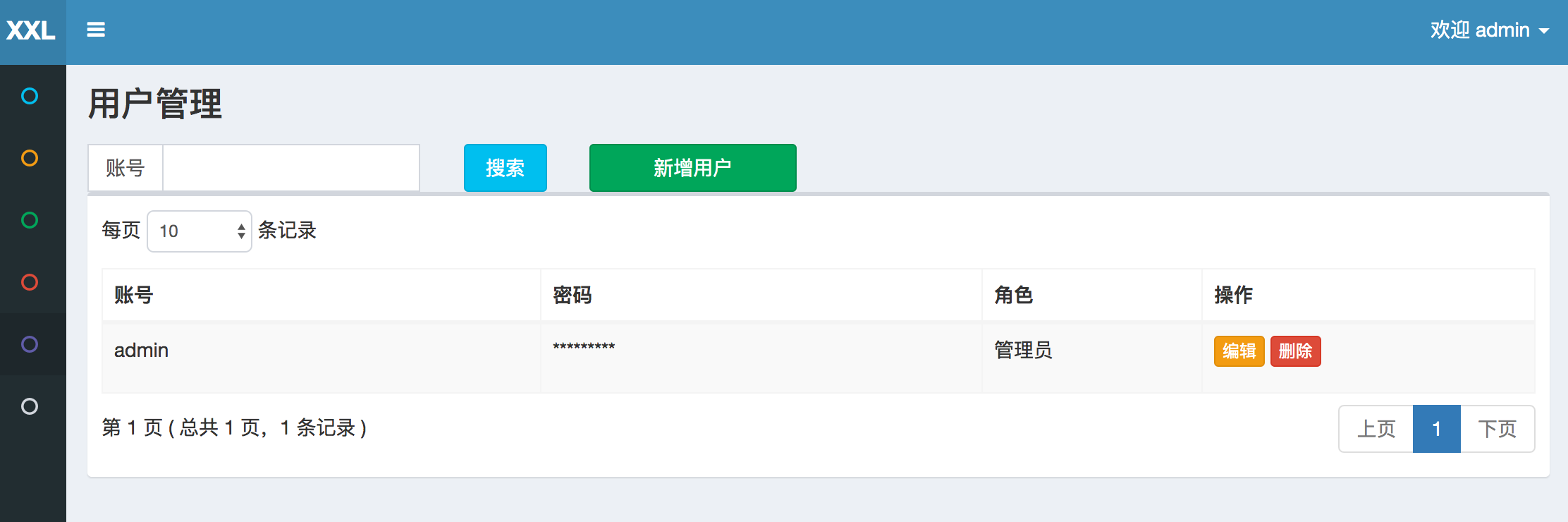
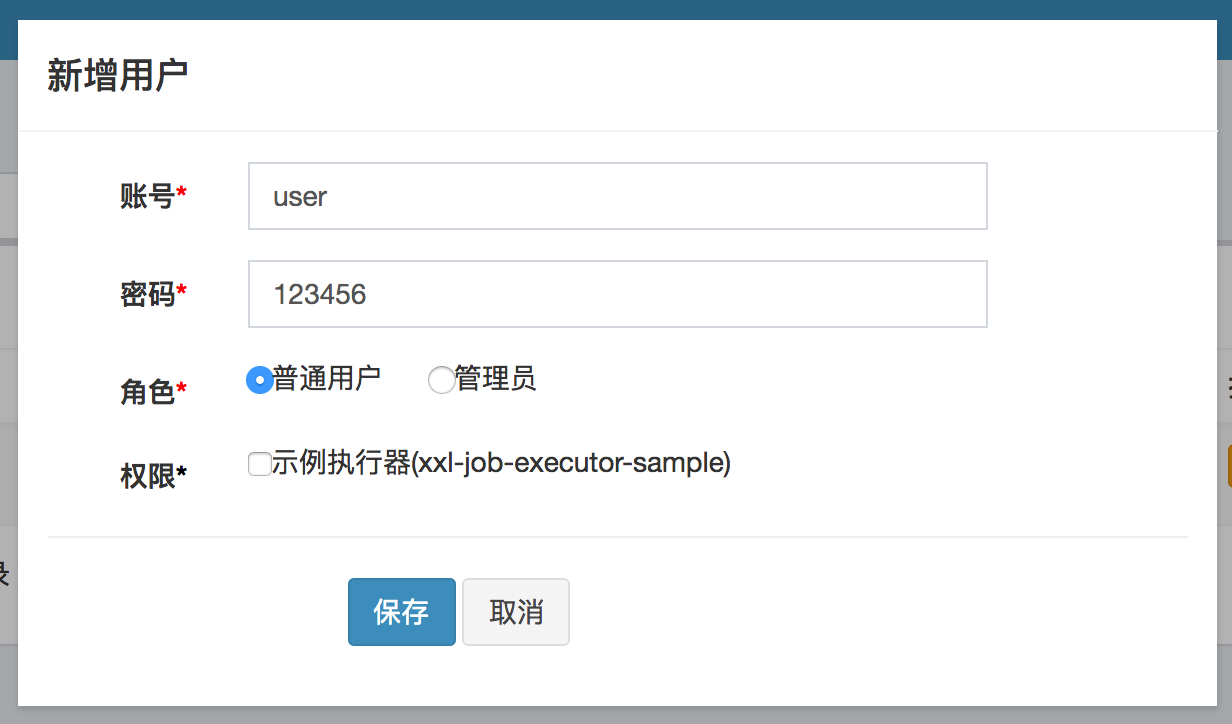
12. 用户管理
进入 “用户管理” 界面,可查看和管理用户信息;
目前用户分为两种角色:
- 管理员:拥有全量权限,支持在线管理用户信息,为用户分配权限,权限分配粒度为执行器;
- 普通用户:仅拥有被分配权限的执行器,及相关任务的操作权限;
五、总体设计
1. 源码目录
- /doc :文档资料
- /db :“调度数据库”建表脚本
- /xxl-job-admin :调度中心,项目源码
- /xxl-job-core :公共Jar依赖
- /xxl-job-executor-samples :执行器,Sample示例项目(大家可以在该项目上进行开发,也可以将现有项目改造生成执行器项目)
2. “调度数据库”配置
-
XXL-JOB调度模块**基于自研调度组件并支持集群部署**,调度数据库表说明如下:
xxl_job_lock:任务调度锁表; xxl_job_group:执行器信息表,维护任务执行器信息; xxl_job_info:调度扩展信息表: 用于保存XXL-JOB调度任务的扩展信息,如任务分组、任务名、机器地址、执行器、执行入参和报警邮件等等; xxl_job_log:调度日志表: 用于保存XXL-JOB任务调度的历史信息,如调度结果、执行结果、调度入参、调度机器和执行器等等; xxl_job_log_report:调度日志报表:用户存储XXL-JOB任务调度日志的报表,调度中心报表功能页面会用到; xxl_job_logglue:任务GLUE日志:用于保存GLUE更新历史,用于支持GLUE的版本回溯功能; xxl_job_registry:执行器注册表,维护在线的执行器和调度中心机器地址信息; xxl_job_user:系统用户表;
3. 架构设计
3.1 设计思想
- 将调度行为抽象形成“调度中心”公共平台,而平台自身并不承担业务逻辑,“调度中心”负责发起调度请求
- 将任务抽象成分散的JobHandler,交由“执行器”统一管理,“执行器”负责接调度请求,并执行对应的JobHandler中业务逻辑
- 因此,“调度”和“任务”两部分可以相互解耦,提高系统整体稳定性和扩展性
3.2 系统组成
-
调度模块(调度中心):
- 负责管理调度信息,按照调度配置发出调度请求,自身不承担业务代码。调度任务与任务解耦,提高了系统可用性和稳定性,同时调度系统性能不再受限于任务模块
- 支持可视化、简单且动态的管理调度信息,包括任务新建、更新、删除
- GLUE开发和任务报警等,所有上述操作都会实时生效,同时支持监控调度结果以及执行日志,支持执行器Failover
-
执行模块(执行器):
- 负责接收调度请求并执行任务逻辑。任务模块专注于任务的执行等操作,开发和维护更加简单和高效
- 接收“调度中心”的执行请求、终止请求和日志请求等
3.3 架构图
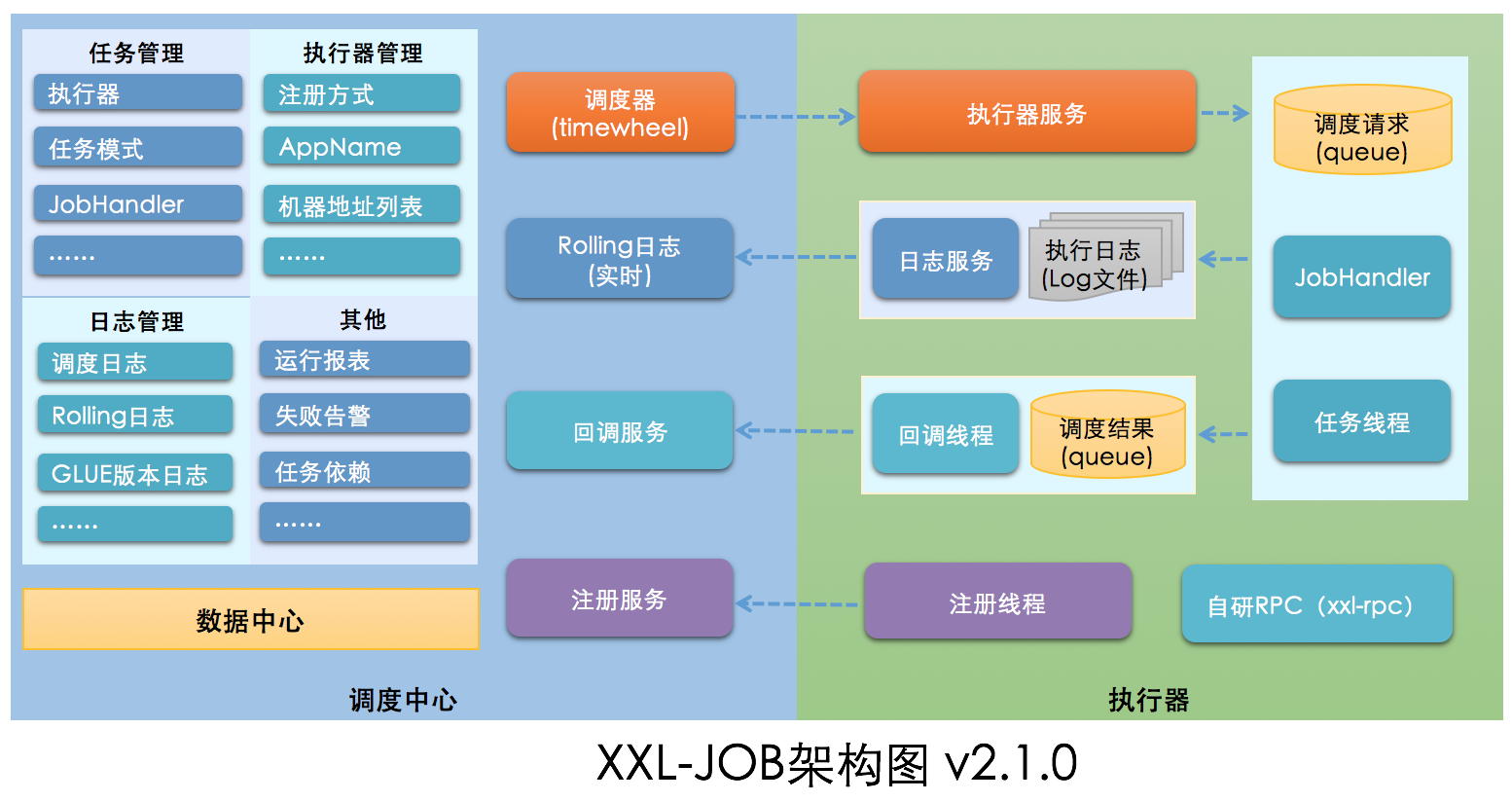
4. 调度模块剖析
4.1 quartz的不足
Quartz时作业调度的首选。但是集群环境中Quartz采用API的方式对任务进行管理,从而可以避免上述问题,但是同样存在以下问题:
- 问题一:调到用API的发过誓操作任务,不人性化
- 问题二:需要持久化业务QuartzJobBean到底层数据表中,系统侵入性相当严重
- 问题三:调度逻辑和QuartzJobBean耦合在同一项目中,浙江导致一个问题,在调度任务数量逐渐增多,同时调度任务逻辑逐渐加重的情况下,此时调度系统的性能将大大受限于业务
- 问题四:quartz底层以“抢占式”获取DB锁并由抢占成功节点负责运行任务,会导致节点负载悬殊非常大;而XXL-JOB通过执行器实现“协同分配式”运行任务,充分发挥集群优势,负载各节点均衡
- XXL-JOB弥补了quartz的上述不足之处
Quartz 是一个功能强大、灵活且易于使用的开源作业调度框架,用于在 Java 应用程序中执行定时任务和计划任务。它提供了丰富的功能,包括任务调度、作业管理、集群支持、任务持久化、错误处理等。
以下是 Quartz 框架的一些主要概念和组件:
- 作业(Job):Quartz 中的核心组件,表示要执行的任务。可以通过实现
org.quartz.Job接口或继承org.quartz.Job的子类来定义具体的作业。- 触发器(Trigger):用于定义作业的触发条件,即何时执行作业。Quartz 提供了多种类型的触发器,包括简单触发器(SimpleTrigger)和日历触发器(CronTrigger)等。
- 调度器(Scheduler):Quartz 的调度器是作业调度的核心组件,用于管理作业和触发器。通过调度器,可以启动、停止、暂停和恢复作业的执行,以及管理触发器的触发时间。
- 任务上下文(JobExecutionContext):作业执行时的上下文环境,包含了作业的执行信息和调度器的状态。
- 监听器(Listener):Quartz 提供了各种类型的监听器,用于监听作业和触发器的事件,例如作业完成、触发器触发等。可以通过实现相应的监听器接口来针对事件进行自定义处理。
使用 Quartz 框架,你可以创建定时任务或计划任务,并对任务进行调度和管理。它可以用于各种场景,如定时生成报表、定时发送邮件、批量处理数据等。
要使用 Quartz 框架,你需要在项目中添加 Quartz 的依赖,并编写相应的代码来配置和使用调度器、定义作业和触发器等。
请注意,具体的使用方法和配置方式可能因 Quartz 版本和具体需求而有所差异。建议参考 Quartz 的官方文档和示例代码以了解更多详细信息。
4.2 自研调度模块
XXL-JOB选择自研调度组件的原因:
- 精简系统降低冗余依赖
- 提供系统的可控度与稳定性
XXL-JOB中“调度模块”和“任务模块”完全解耦,调度模块进行任务调度时,将会解析不同的任务参数发起远程调用,调用各自的远程执行器服务。这种调用模型类似RPC调用,调度中心提供调用代理的功能,而执行器提供远程服务的功能。
4.3 调度中心HA(集群)
基于数据库的集群方案,数据库选用Mysql;集群分布式并发环境中进行定时任务调度时,会在各个节点上报任务,存到数据库中,执行时会从数据库中取出触发器来执行,如果触发器的名称和执行时间相同,则只有一个节点去执行此任务
4.4 调度线程池
调度采用线程池方式实现,避免单线程因阻塞而引起任务调度延迟
4.5 并行调度
-
XXL-JOB调度模块采用并行机制,在多线程调度的情况下,调度模块被阻塞的几率很低,大大提高了调度系统的承载量
-
XXL-JOB的不同任务之间并行调度、并行执行
-
XXL-JOB的单个任务,针对多个执行器说并行运行的,针对单个执行器是串行执行的。同时支持任务终止
4.6 过期处理策略
任务调度错过触发时间时的处理策略:
- 可能原因:
- 服务重启;
- 调度吸纳成被阻塞,线程被耗尽;
- 上次调度持续阻塞,下次调度被错过
- 处理策略:
- 过期5s:本次忽略,当前时间开始计算下次触发时间
- 过期5s内:立即触发一次,当前时间开始计算下次触发时间
4.7 日志回调服务
调度模块的“调度中心”作为Web服务部署时,一方面承担调度中心功能,另一方面也为执行器提供API服务。
调度中心提供的”日志回调服务API服务”代码位置如下:
xxl-job-admin#com.xxl.job.admin.controller.JobApiController.callback
“执行器”在接收到任务执行请求后,执行任务,在执行结束之后会将执行结果回调通知“调度中心”
4.8 任务HA(Failover)
执行器如若集群部署,调度中心将会感知到在线的所有执行器,如“127.0.0.1:9997,127.0.0.1:9998, 127.0.0.1:9999”
当任务“路由策略”选择“故障转移(FAILOVER)”时,当调度中心每次发起调度请求时,会按照顺序对执行器发出心跳检测请求,第一个检测为存活状态的执行器将会被选定并发送调度请求
调度成功后,可在日志监控界面查看“调度备注”
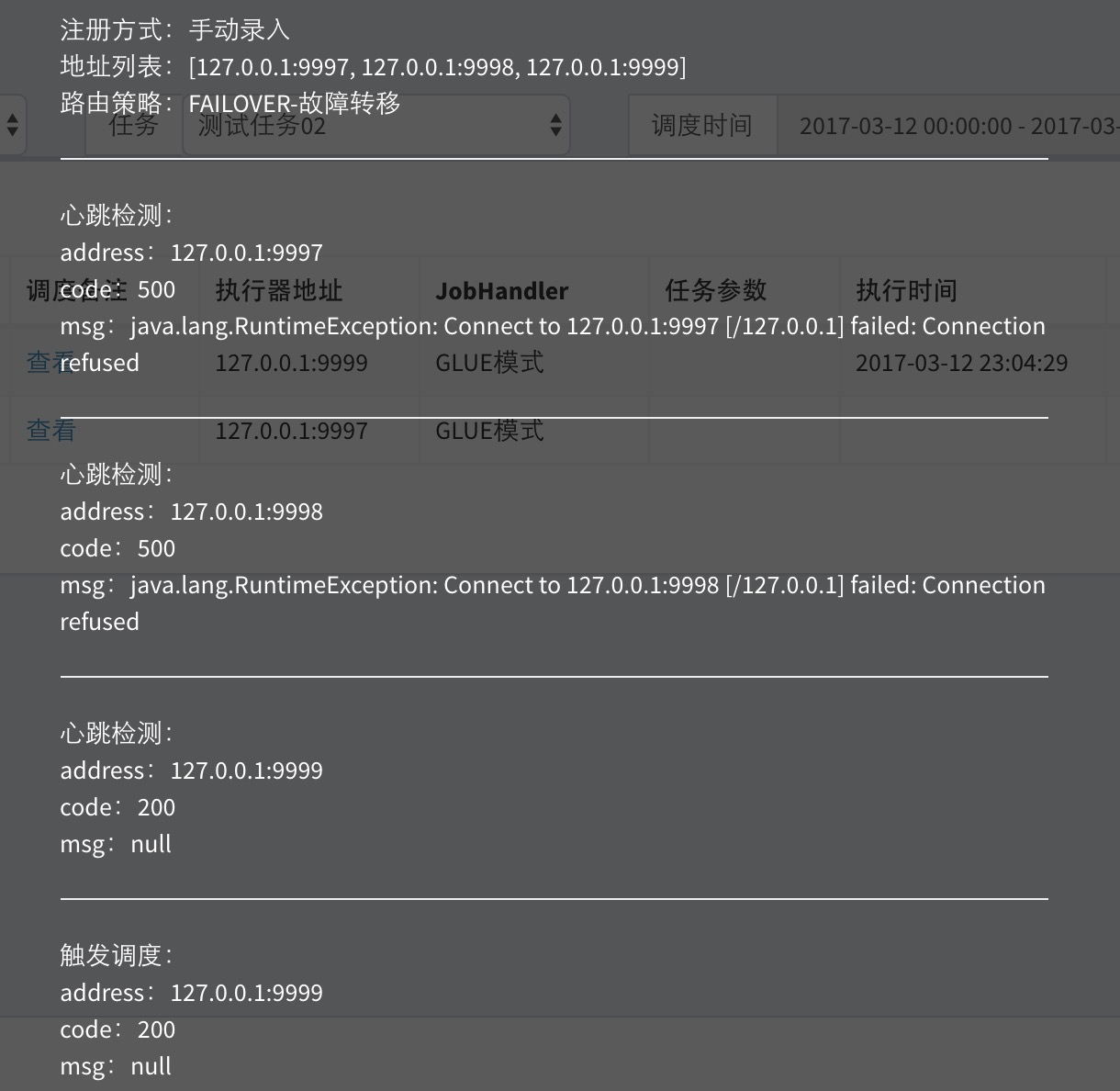
- **“调度备注”**可以看出本地调度运行轨迹,执行器的“注册方式”、“地址列表”和任务的“路由策略”。“故障转移(FAILOVER)”路由策略下,调度中心首先对第一个地址进行心跳检测,心跳失败因此Zion给跳过,第二个依然i那条检测失败…直至心跳检测第三个地址“127.0.0.1:9999”成功,选定为“目标执行器”;然后对“目标执行器”发送调度请求,调度流程结束,等待执行器回调执行结果
4.9 调度日志
调度中心每次进行任务调度,都会记录一条任务日志,任务日志主要包括以下三部分内容:
- 任务信息:包括“执行器地址”、“JobHandler”和“执行参数”等属性,点击任务ID按钮可查看,根据这些参数,可以精确的定位任务执行的具体机器和任务代码;
- 调度信息:包括“调度时间”、“调度结果”和“调度日志”等,根据这些参数,可以了解“调度中心”发起调度请求时具体情况。
- 执行信息:包括“执行时间”、“执行结果”和“执行日志”等,根据这些参数,可以了解在“执行器”端任务执行的具体情况;
- 调度日志,针对单次调度,属性说明如下:
- 执行器地址:任务执行的机器地址;
- JobHandler:Bean模式表示任务执行的JobHandler名称;
- 任务参数:任务执行的入参;
- 调度时间:调度中心,发起调度的时间;
- 调度结果:调度中心,发起调度的结果,SUCCESS或FAIL;
- 调度备注:调度中心,发起调度的备注信息,如地址心跳检测日志等;
- 执行时间:执行器,任务执行结束后回调的时间;
- 执行结果:执行器,任务执行的结果,SUCCESS或FAIL;
- 执行备注:执行器,任务执行的备注信息,如异常日志等;
- 执行日志:任务执行过程中,业务代码中打印的完整执行日志;
4.10 任务依赖
原理:XXL-JOB中每个任务都对应有一个任务ID,同时,每个任务支持设置属性子任务ID“,因此,通过”任务ID”可以匹配任务依赖关系
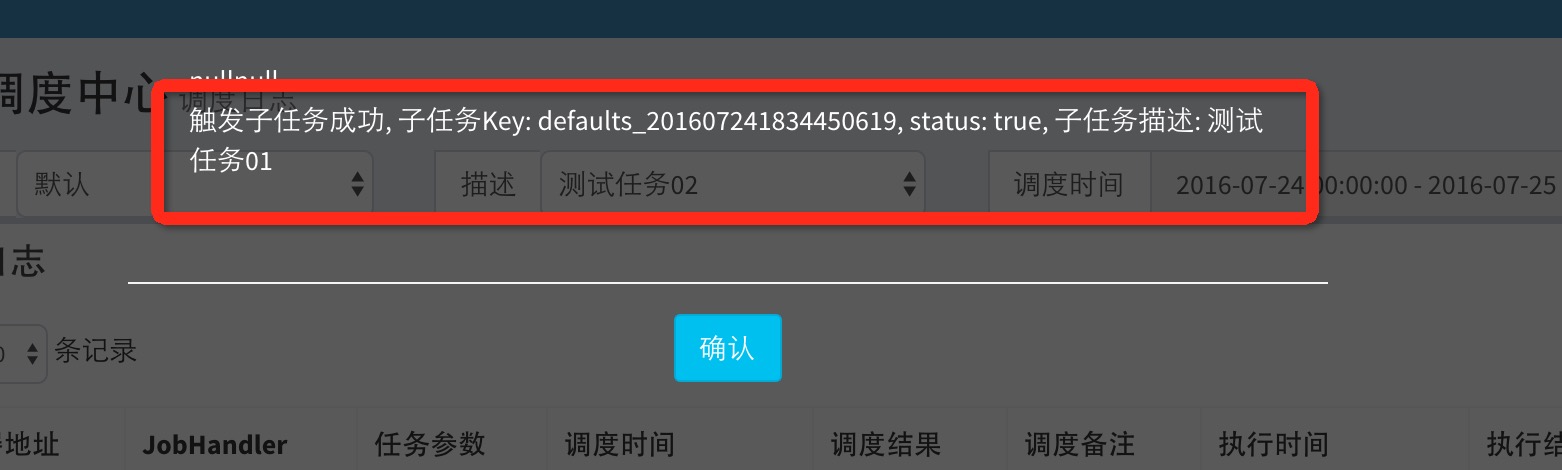
- 当父任务执行结束并且执行成功时,将会根据“子任务ID”匹配子任务依赖,如果匹配到子任务,将会主动触发一次子任务的执行
- 在任务日志界面。点击任务的“执行备注”的“查看”按钮,可以看到匹配子任务以及触发子任务执行的日志信息,如无信息则表示未触发子任务执行

4.11 全异步化&轻量级
- 全异步化设计:XXL-JOB系统中业务逻辑在远程执行器,触发流程全异步化设计。相比直接在调度中心内部执行业务逻辑,极大的降低了调度线程占用时间
- 异步调度:调度中心每次任务触发时仅发送一次调度请求,该调度请求首先推送“异步调度队列”,然后异步推送给远程执行器
- 异步执行:执行器会将请求存入”i不执行队列“并且立即响应调度中心,异步运行
- 轻量级设计:XXL-JOB调度中心中每个JOB逻辑非常”轻“,在全异步化的基础上,单个JOB一次运行平均耗时基本在”10ms“之内(基本为一次请求的网络开销);因此,可以保证是哦那个有限的线程支撑大量的JOB并发运行
得益于上述两点优化,理论上默认配置下的调度中心,单机能够支撑 5000 任务并发运行稳定运行;
实际场景中,由于调度中心与执行器网络ping延迟不同、DB读写耗时不同、任务调度密集程度不同,会导致任务量上限会上下波动。
如若需要支撑更多的任务量,可以通过 “调大调度线程数” 、”降低调度中心与执行器ping延迟” 和 “提升机器配置” 几种方式优化。
4.12 均衡调度
调度中心在集群部署时会自动进行任务平均分配,触发组件每次获取与线程池数量(调度中心支持自定义调度线程池大小)相关数量的任务,避免大量任务集中在单个调度中心集群节点
5. 任务”运行模式“剖析
5.1 ”Bean模式“任务
原理:每个Bean模式任务都是一个Spring的Bean类示例,它被维护在”执行器“项目的Spring容器中。任务类需要加“@JobHandler(value=”名称”)”注解,因为”执行器“根据该注解识别Spring容器中的任务。任务类需要继承同意接口”IJobHandler“,任务逻辑在execute方法中开发,因为”执行器“在接收到调度中心的调度请求时,将会调用”IJobHandler“的execute方法,执行任务逻辑
5.2 ”GLUE模式(Java)“任务
原理:每个”GLUE模式(Java)“任务的代码,实际上是”一个继承自"IJobHandler"的实现类的类代码“,”执行器“接收到”调度中心“的调度请求时,会通过Groovy类加载器加载此代码,实例化成Java对象,同时注入代码中声明的Spring服务(请确保Glue代码中的服务和类引用在”执行器“项目中存在),然后调用该对象的execute方法,执行任务逻辑
5.3 GLUE模式(Shell) + GLUE模式(Python) + GLUE模式(PHP) + GLUE模式(NodeJS) + GLUE模式(Powershell)
原理:脚本任务的源码托管在调度中心,脚本逻辑在执行器运行。当触发脚本任务时,执行器会加载脚本源码在执行器机器上生成一份脚本文件,然后通过Java代码调用该脚本;并且实时将脚本输出日志写到任务日志文件中,从而在调度中心可以实时监控脚本运行情况;
目前支持的脚本类型如下:
- shell脚本:任务运行模式选择为 "GLUE模式(Shell)"时支持 "Shell" 脚本任务;
- python脚本:任务运行模式选择为 "GLUE模式(Python)"时支持 "Python" 脚本任务;
- php脚本:任务运行模式选择为 "GLUE模式(PHP)"时支持 "PHP" 脚本任务;
- nodejs脚本:任务运行模式选择为 "GLUE模式(NodeJS)"时支持 "NodeJS" 脚本任务;
- powershell:任务运行模式选择为 "GLUE模式(PowerShell)"时支持 "PowerShell" 脚本任务;
脚本任务通过 Exit Code 判断任务执行结果,状态码可参考章节 “5.15 任务执行结果说明”
5.4 执行器
执行器实际上是一个内嵌的Server,默认端口9999(配置项:xxl.job.executor.port)。
在项目启动时,执行器会通过“@JobHandler”识别Spring容器中“Bean模式任务”,以注解的value属性为key管理起来。
“执行器”接收到“调度中心”的调度请求时,如果任务类型为“Bean模式”,将会匹配Spring容器中的“Bean模式任务”,然后调用其execute方法,执行任务逻辑。如果任务类型为“GLUE模式”,将会加载GLue代码,实例化Java对象,注入依赖的Spring服务(注意:Glue代码中注入的Spring服务,必须存在与该“执行器”项目的Spring容器中),然后调用execute方法,执行任务逻辑
5.5 任务日志
- XXL-JOB会为每次调度请求生成一个单独的日志文件,需要通过 “XxlJobHelper.log” 打印执行日志,“调度中心”查看执行日志时将会加载对应的日志文件
(历史版本通过重写LOG4J的Appender实现,存在依赖限制,该方式在新版本已经被抛弃)
-
日志文件存放的位置可在“执行器”配置文件进行自定义,默认目录格式为:/data/applogs/xxl-job/jobhandler/“格式化日期”/“数据库调度日志记录的主键ID.log”
-
在JobHandler中开启子线程时,子线程将会把日志打印在父线程即JobHandler的执行日志中,方便日志追踪
6. 通讯模块剖析
6.1 一次完整的任务调度通讯流程
- 1、“调度中心”向“执行器”发送http调度请求: “执行器”中接收请求的服务,实际上是一台内嵌Server,默认端口9999;
- 2、“执行器”执行任务逻辑;
- 3、“执行器”http回调“调度中心”调度结果: “调度中心”中接收回调的服务,是针对执行器开放一套API服务;
6.2 通讯数据加密
调度中心向执行器发送的调度请求时使用RequestModel和ResponseModel两个对象封装调度请求参数和响应数据, 在进行通讯之前底层会将上述两个对象对象序列化,并进行数据协议以及时间戳检验,从而达到数据加密的功能
7. 任务注册,任务自动发现
- 自v1.5版本之后, 任务取消了”任务执行机器”属性, 改为通过任务注册和自动发现的方式, 动态获取远程执行器地址并执行。
AppName: 每个执行器机器集群的唯一标示, 任务注册以 “执行器” 为最小粒度进行注册; 每个任务通过其绑定的执行器可感知对应的执行器机器列表;
注册表: 见"xxl_job_registry"表, “执行器” 在进行任务注册时将会周期性维护一条注册记录,即机器地址和AppName的绑定关系; “调度中心” 从而可以动态感知每个AppName在线的机器列表;
执行器注册: 任务注册Beat周期默认30s; 执行器以一倍Beat进行执行器注册, 调度中心以一倍Beat进行动态任务发现; 注册信息的失效时间为三倍Beat;
执行器注册摘除:执行器销毁时,将会主动上报调度中心并摘除对应的执行器机器信息,提高心跳注册的实时性;
为保证系统”轻量级”并且降低学习部署成本,没有采用Zookeeper作为注册中心,采用DB方式进行任务注册发现
8. 任务执行结果
自v1.6.2之后,任务执行结果通过 “IJobHandler” 的返回值 “ReturnT” 进行判断;
当返回值符合 “ReturnT.code == ReturnT.SUCCESS_CODE” 时表示任务执行成功,否则表示任务执行失败,而且可以通过 “ReturnT.msg” 回调错误信息给调度中心;
从而,在任务逻辑中可以方便的控制任务执行结果
9. 分片广播 & 动态分片
-
执行器集群部署时,任务路由策略选择”分片广播“情况下,一次任务调度将会广播触发对应集群中所有执行器执行一次任务,同时系统自动传递分片参数;可根据分片参数开发分片任务
-
”分片广播“以执行器为维度进行分片,支持动态扩容执行器集群从而动态增加分片数量,协同进行业务处理;在进行大数据量业务操作时可显著提升任务处理能力和速度
-
”分片广播“和普通任务开发流程一致,不同之处在于可以获取分片参数,获取分片参数进行分片业务处理
-
Java语言任务获取分片参数方式:BEAN、GLUE模式(Java)
// 可参考Sample示例执行器中的示例任务"ShardingJobHandler"了解试用 int shardIndex = XxlJobHelper.getShardIndex(); int shardTotal = XxlJobHelper.getShardTotal(); -
脚本语言任务获取分片参数方式:GLUE模式(Shell)、GLUE模式(Python)、GLUE模式(Nodejs)
// 脚本任务入参固定为三个,依次为:任务传参、分片序号、分片总数。以Shell模式任务为例,获取分片参数代码如下 echo "分片序号index = $2" echo "分片总数total = $3"
分片参数属性说明:
index:当前分片序号(从0开始),执行器集群列表中当前执行器的序号;
total:总分片数,执行器集群的总机器数量;
该特性适用场景如:
- 1、分片任务场景:10个执行器的集群来处理10w条数据,每台机器只需要处理1w条数据,耗时降低10倍;
- 2、广播任务场景:广播执行器机器运行shell脚本、广播集群节点进行缓存更新等
10. 访问令牌(AccessToken)
为提升系统安全性,调度中心和执行器进行安全性校验,双方AccessToken匹配才允许通讯;
调度中心和执行器,可通过配置项 “xxl.job.accessToken” 进行AccessToken的设置。
调度中心和执行器,如果需要正常通讯,只有两种设置;
- 设置一:调度中心和执行器,均不设置AccessToken;关闭安全性校验;
- 设置二:调度中心和执行器,设置了相同的AccessToken;
11. 故障转移 & 失败重试
一次完整任务流程包括”调度(调度中心) + 执行(执行器)”两个阶段。
- “故障转移”发生在调度阶段,在执行器集群部署时,如果某一台执行器发生故障,该策略支持自动进行Failover切换到一台正常的执行器机器并且完成调度请求流程。
- “失败重试”发生在”调度 + 执行”两个阶段,支持通过自定义任务失败重试次数,当任务失败时将会按照预设的失败重试次数主动进行重试;
12. 执行器灰度上线
调度中心与业务解耦,只需部署一次后常年不需要维护。但是,执行器中托管运行着业务作业,作业上线和变更需要重启执行器,尤其是Bean模式任务。
执行器重启可能会中断运行中的任务。但是,XXL-JOB得益于自建执行器与自建注册中心,可以通过灰度上线的方式,避免因重启导致的任务中断的问题。
步骤如下:
- 1、执行器改为手动注册,下线一半机器列表(A组),线上运行另一半机器列表(B组);
- 2、等待A组机器任务运行结束并编译上线;执行器注册地址替换为A组;
- 3、等待B组机器任务运行结束并编译上线;执行器注册地址替换为A组+B组;
操作结束;
13. 任务执行结果说明
系统根据以下标准判断任务执行结果,可参考之。
| — | Bean/Glue(Java) | Glue(Shell) 等脚本任务 |
|---|---|---|
| 成功 | IJobHandler.SUCCESS | 0 |
| 失败 | IJobHandler.FAIL | -1(非0状态码) |
14. 任务超时控制
- 支持设置任务超时时间,任务运行超时的情况下,将会主动中断任务;
需要注意的是,任务超时中断时与任务终止机制类似,也是通过 “interrupt” 中断任务,因此业务代码需要将 “InterruptedException” 外抛,否则功能不可用
15. 跨语言
XXL-JOB是一个跨语言的任务调度平台,主要体现在如下几个方面:
- 1、RESTful API:调度中心与执行器提供语言无关的 RESTful API 服务,第三方任意语言可据此对接调度中心或者实现执行器。(可参考章节 “调度中心/执行器 RESTful API” )
- 2、多任务模式:提供Java、Python、PHP……等十来种任务模式,可参考章节 “5.5 任务 “运行模式” ”;理论上可扩展任意语言任务模式;
- 3、提供基于HTTP的任务Handler(Bean任务,JobHandler=”httpJobHandler”);业务方只需要提供HTTP链接等相关信息即可,不限制语言、平台;
16. 任务失败告警
默认提供邮件失败告警,可扩展短信、钉钉等方式。如果需要新增一种告警方式,只需要新增一个实现“com.xxl.job.admin.core.alarm.JobAlarm”接口的告警实现即可。可以参考默认提供邮箱告警实现“EmailJobAlarm”
17. 调度中心Docker镜像构建
- 可以通过以下命令快速构建调度中心,并启动运行;
mvn clean package
docker build -t xuxueli/xxl-job-admin ./xxl-job-admin
docker run --name xxl-job-admin -p 8080:8080 -d xuxueli/xxl-job-admin
18. 避免任务重复执行
调度密集或者耗时任务可能会导致任务阻塞,集群情况下调度组件小概率情况下会重复触发;
针对上述情况,可以通过结合 “单机路由策略(如:第一台、一致性哈希)” + “阻塞策略(如:单机串行、丢弃后续调度)” 来规避,最终避免任务重复执行。
19. 命令行任务
- 原生提供通用命令行任务Handler(Bean任务,”CommandJobHandler”);业务方只需要提供命令行即可;
如任务参数 “pwd” 将会执行命令并输出数据;
20. 日志自动清理
XXL-JOB日志主要包含如下两部分,均支持日志自动清理,说明如下:
- 调度中心日志表数据:可借助配置项 “xxl.job.logretentiondays” 设置日志表数据保存天数,过期日志自动清理;详情可查看上文配置说明;
- 执行器日志文件数据:可借助配置项 “xxl.job.executor.logretentiondays” 设置日志文件数据保存天数,过期日志自动清理;详情可查看上文配置说明;
21. 调度结果丢失处理
- 执行器因网络抖动回调失败或宕机等异常情况,会导致任务调度结果丢失。由于调度中心依赖执行器回调来感知调度结果,因此会导致调度日志永远处于 “运行中” 状态。
方案
调度中心提供内置组件进行处理,逻辑为:调度记录停留在 “运行中” 状态超过10min,且对应执行器心跳注册失败不在线,则将本地调度主动标记失败;
六、 调度中心/执行器 RESTful API
-
XXL-JOB目标是一种跨平台、跨语言的任务调度规范和协议
-
针对Java应用,可以直接通过官方提供的调度中心与执行器,方便快速的接入和使用调度中心
-
针对非Java应用,可借助XXL-JOB的标准RESTful API方便的实现多语言支持
- 调度中心 RESTful API:
- 说明:调度中心提供给执行器使用的API;不局限于官方执行器使用,第三方可使用该API来实现执行器
- API列表:任务触发、任务终止、任务日志查询等
- 执行器RESTful API:
- 说明:执行器提供给调度中心使用的API;官方执行器默认已实现,第三方执行器需要实现并对接提供给调度中心
- API列表:任务触发、任务终止、任务日志查询…等
- 调度中心 RESTful API:
此外RESTful API 主要用于非Java语言定制个性化执行器使用,实现跨语言。除此之外,如果有需要通过API操作调度中心,可以个性化扩展”调度中心 RESTful API“并使用
1. 调度中心 RESTful API
RESTful API(Representational State Transfer API)是一种基于 REST 架构风格的应用程序编程接口(API)设计原则。它提供了一组用于访问和操作 Web 资源的约定和规范。
RESTful API 的设计原则主要包括以下几个方面:
- 资源(Resources):将系统中的数据或功能抽象为资源,每个资源都有一个唯一的标识符(URI)。资源可以是实体对象、集合、服务、文件等。
- 统一接口(Uniform Interface):使用统一的接口风格来访问和操作资源,包括使用 HTTP 方法(GET、POST、PUT、DELETE 等)来定义操作类型,使用 URI 来定位资源,使用标准的媒体类型(如 JSON、XML)来表示资源的表示形式。
- 无状态(Stateless):每个请求都是独立的,服务器不会存储客户端状态。客户端请求必须包含所有必要的信息,服务器根据请求的信息来处理操作。
- 超媒体驱动(Hypermedia Driven):通过在响应中提供可导航的链接,使客户端能够动态地发现和访问相关资源。
使用 RESTful API,客户端可以通过 HTTP 请求来访问和操作服务器上的资源。常见的 RESTful API 设计使用 JSON 或 XML 格式来传输数据,可以通过 HTTP 方法(GET、POST、PUT、DELETE)来执行相应的操作。
例如,以下是一个使用 RESTful 风格的 API 请求示例:
GET /users/123 HTTP/1.1 Host: example.com Accept: application/json上述示例中,客户端通过 GET 请求访问了一个名为 “users” 的资源的标识符为 “123” 的特定用户。客户端期望服务器返回 JSON 格式的响应。
RESTful API 的设计原则使得接口易于理解、灵活、可扩展和可维护。它被广泛应用于 Web 开发、移动应用程序开发和微服务架构等领域。
请注意,RESTful API 的设计和实现可能因具体的需求和技术栈而有所不同。建议在设计和实现 RESTful API 时参考相关的规范和最佳实践。
API服务位置:com.xxl.job.core.biz.AdminBiz ( com.xxl.job.admin.controller.JobApiController )
API服务请求参考代码:com.xxl.job.adminbiz.AdminBizTest
a. 任务回调
说明:执行器执行完成任务后,回调任务结果时使用
------
地址格式:{调度中心根地址}/api/callback
Header:
XXL-JOB-ACCESS-TOKEN: {请求令牌}
请求数据格式如下,放置在RequestBody中,JSON格式:
[{
"logId":1, //本次调度日志ID
"logDateTime":0, //本次调度日志时间
"handleCode":200, //200表示任务执行正常,500表示失败
"handleMsg":null
}]
响应数据格式:
{
"code":200, //200表示正常、其他失败
"msg":null //错误提示消息
}
b. 执行器注册
说明:执行器注册时使用,调度中心会实时感知注册成功的执行器并发起任务调度
------
地址格式:{调度中心根地址}/api/registry
Header:
XXL-JOB-ACCESS-TOKEN :{请求令牌}
请求数据格式如下,放置在RequestBody 中,JSON格式:
{
"registryGroup":"EXECUTOR", //固定值
"registryKey":"xxl-job-executor-examle", //执行器AppName
"registryValue":"http://127.0.0.1:9999/" //执行器地址,内置服务跟地址
}
响应数据格式:
{
"code":200, //200表示正常、其他失败
"msg":null //错误提示信息
}
c. 执行器注册摘除
说明:执行器注册摘除时使用,注册摘除后的执行器不参与任务调度与执行
------
地址格式:{调度中心根地址}/api/registryRemove
Header:
XXL-JOB-ACCESS-TOKEN : {请求令牌}
请求数据格式如下,放置在RequestBody中,JSON格式:
{
"registryGroup":"EXECUTOR", //固定值
"registryKey":"xxl-job-executor-example", //执行器AppName
"registoryValue":"http://127.0.0.1:9999/" //执行器地址,内置服务跟地址
}
响应数据格式:
{
"code": 200, //200表示正常、其他失败
"msg": null //错误提示信息
}
2. 执行器RESTful API
API服务位置:com.xxl.job.core.biz.ExecutorBiz
API服务请求参考代码:com.xxl.job.executorbiz.ExecutorBizTest
a. 心跳检测
说明:调度中心检测执行器是否在线时使用
------
地址格式:{执行器内嵌服务根地址}/beat
Header:
XXL-JOB-ACCESS-TOKEN : {请求令牌}
请求数据格式如下,放置在RequestBody中,JSON格式:
响应数据格式:
{
"code": 200, //200表示正常、其他失败
"msg": null //错误提示信息
}
b. 忙碌检测
说明:调度中心检测指定执行器上指定任务是否忙碌(运行中)时使用
------
地址格式:{执行器内嵌服务根地址}/idleBeat
Header:
XXL-JOB-ACCESS-TOKEN:{请求令牌}
请求数据格式如下,放置在RequestBody中,JSON格式:
{
"jobId":1 //任务ID
}
响应数据格式:
{
"code": 200, //200表示正常、其他失败
"msg": null //错误提示消息
}
c. 触发任务
说明:触发任务执行
------
地址格式:{执行器内嵌服务根地址}/run
Header:
XXL-JOB-ACCESS-TOKEN : {请求令牌}
请求数据格式如下,放置在 RequestBody 中,JSON格式:
{
"jobId":1, // 任务ID
"executorHandler":"demoJobHandler", // 任务标识
"executorParams":"demoJobHandler", // 任务参数
"executorBlockStrategy":"COVER_EARLY", // 任务阻塞策略,可选值参考 com.xxl.job.core.enums.ExecutorBlockStrategyEnum
"executorTimeout":0, // 任务超时时间,单位秒,大于零时生效
"logId":1, // 本次调度日志ID
"logDateTime":1586629003729, // 本次调度日志时间
"glueType":"BEAN", // 任务模式,可选值参考 com.xxl.job.core.glue.GlueTypeEnum
"glueSource":"xxx", // GLUE脚本代码
"glueUpdatetime":1586629003727, // GLUE脚本更新时间,用于判定脚本是否变更以及是否需要刷新
"broadcastIndex":0, // 分片参数:当前分片
"broadcastTotal":0 // 分片参数:总分片
}
响应数据格式:
{
"code": 200, // 200 表示正常、其他失败
"msg": null // 错误提示消息
}
d. 终止任务
说明:终止任务
------
地址格式:{执行器内嵌服务根地址}/kill
Header:
XXL-JOB-ACCESS-TOKEN : {请求令牌}
请求数据格式如下,放置在 RequestBody 中,JSON格式:
{
"jobId":1 // 任务ID
}
响应数据格式:
{
"code": 200, // 200 表示正常、其他失败
"msg": null // 错误提示消息
}
e. 查看执行日志
说明:终止任务,滚动方式加载
------
地址格式:{执行器内嵌服务根地址}/log
Header:
XXL-JOB-ACCESS-TOKEN : {请求令牌}
请求数据格式如下,放置在 RequestBody 中,JSON格式:
{
"logDateTim":0, // 本次调度日志时间
"logId":0, // 本次调度日志ID
"fromLineNum":0 // 日志开始行号,滚动加载日志
}
响应数据格式:
{
"code":200, // 200 表示正常、其他失败
"msg": null // 错误提示消息
"content":{
"fromLineNum":0, // 本次请求,日志开始行数
"toLineNum":100, // 本次请求,日志结束行号
"logContent":"xxx", // 本次请求日志内容
"isEnd":true // 日志是否全部加载完
}
}
七、学习扩展
- 都放到一台:负载过高,不均衡
- 轮询:任务变成并发任务,需要获得锁来解决此问题保证任务唯一性
-
并发任务在第一个,在轮询
-
学会自定义一个策略:要求一台机器同时只能运行一个策略
-
多任务多机器各自分发策略,需要列出一个表格,并且说明对应的策略
-
分布式锁,需要写一个代码控制同时运行的任务有且只有一个,在轮询路由策略心跳是什么机制,频率?
-
路由策略在其他场景,分别对应什么,spring clolud,nginx,一致性HASH,怎么解决节点消失的,用代码演示,用在什么场景?
-
nginx
}
#### d. 终止任务
```mysql
说明:终止任务
------
地址格式:{执行器内嵌服务根地址}/kill
Header:
XXL-JOB-ACCESS-TOKEN : {请求令牌}
请求数据格式如下,放置在 RequestBody 中,JSON格式:
{
"jobId":1 // 任务ID
}
响应数据格式:
{
"code": 200, // 200 表示正常、其他失败
"msg": null // 错误提示消息
}
e. 查看执行日志
说明:终止任务,滚动方式加载
------
地址格式:{执行器内嵌服务根地址}/log
Header:
XXL-JOB-ACCESS-TOKEN : {请求令牌}
请求数据格式如下,放置在 RequestBody 中,JSON格式:
{
"logDateTim":0, // 本次调度日志时间
"logId":0, // 本次调度日志ID
"fromLineNum":0 // 日志开始行号,滚动加载日志
}
响应数据格式:
{
"code":200, // 200 表示正常、其他失败
"msg": null // 错误提示消息
"content":{
"fromLineNum":0, // 本次请求,日志开始行数
"toLineNum":100, // 本次请求,日志结束行号
"logContent":"xxx", // 本次请求日志内容
"isEnd":true // 日志是否全部加载完
}
}
七、学习扩展
- 都放到一台:负载过高,不均衡
- 轮询:任务变成并发任务,需要获得锁来解决此问题保证任务唯一性
- 并发任务在第一个,在轮询
- 学会自定义一个策略:要求一台机器同时只能运行一个策略
- 多任务多机器各自分发策略,需要列出一个表格,并且说明对应的策略
- 分布式锁,需要写一个代码控制同时运行的任务有且只有一个,在轮询路由策略心跳是什么机制,频率?
- 路由策略在其他场景,分别对应什么,spring clolud,nginx,一致性HASH,怎么解决节点消失的,用代码演示,用在什么场景?
- nginx















 3159
3159

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









