







一、图论
1、岛屿数量:DFS解决
我们遍历二维网格中的每一个点,如果遇到一个值为 1 的点,则启动一次 DFS 搜索,将所有与之相连的陆地都标记为访问过。这意味着我们找到了一座岛屿。最后,岛屿的数量就是我们启动 DFS 搜索的次数。
class Solution:
def dfs(self,r,c,grid):
if r<0 or r>=len(grid) or c<0 or c>=len(grid[0]) or grid[r][c]!='1':
return
grid[r][c]='2'
self.dfs(r-1,c,grid)
self.dfs(r+1,c,grid)
self.dfs(r,c-1,grid)
self.dfs(r,c+1,grid)
def numIslands(self, grid: List[List[str]]) -> int:
if not grid:
return 0
n,m=len(grid),len(grid[0])
ans=0
for i in range(n):
for j in range(m):
if grid[i][j]=='1':
ans+=1
self.dfs(i,j,grid)
return ans网格问题DFS模板:作者:nettee,链接:https://leetcode.cn/problems/number-of-islands/solutions/211211/dao-yu-lei-wen-ti-de-tong-yong-jie-fa-dfs-bian-li-/
void dfs(int[][] grid, int r, int c) {
// 判断 base case
if (!inArea(grid, r, c)) {
return;
}
// 如果这个格子不是岛屿,直接返回
if (grid[r][c] != 1) {
return;
}
grid[r][c] = 2; // 将格子标记为「已遍历过」
// 访问上、下、左、右四个相邻结点
dfs(grid, r - 1, c);
dfs(grid, r + 1, c);
dfs(grid, r, c - 1);
dfs(grid, r, c + 1);
}
// 判断坐标 (r, c) 是否在网格中
boolean inArea(int[][] grid, int r, int c) {
return 0 <= r && r < grid.length
&& 0 <= c && c < grid[0].length;
}2、腐烂的橘子:BFS解决
BFS 可以用来求最短路径问题,而这道题实际上就是求腐烂橘子到所有新鲜橘子的最短路径。
- 一开始,我们找出所有腐烂的橘子,将它们放入队列,作为第 0 层的结点。
- 然后进行 BFS 遍历,每个结点的相邻结点可能是上、下、左、右四个方向的结点,注意判断结点位于网格边界的特殊情况。
- 由于可能存在无法被污染的橘子,我们需要记录新鲜橘子的数量。在 BFS 中,每遍历到一个橘子(污染了一个橘子),就将新鲜橘子的数量减一。如果 BFS 结束后这个数量仍未减为零,说明存在无法被污染的橘子。
在 BFS 中,橘子的腐烂是同步发生的,每一层的腐烂扩散到新鲜橘子时,时间应该同步增加。因此,使用 size 来记录当前队列中的腐烂橘子数量,确保每次都完整处理当前层的所有腐烂橘子。
class Solution:
def orangesRotting(self, grid: List[List[int]]) -> int:
n,m=len(grid),len(grid[0])
fresh_num=0;rotten=collections.deque()
for i in range(n):
for j in range(m):
if grid[i][j]==2:
rotten.append((i,j))
if grid[i][j]==1:
fresh_num+=1
if fresh_num==0:
return 0
time=0
direct=[(0,1),(1,0),(0,-1),(-1,0)]
while rotten and fresh_num>0:
time+=1
size=len(rotten)
while size:
r,c=rotten.popleft()
for dr,dc in direct:
new_r,new_c=r+dr,c+dc
if 0<=new_r<n and 0<=new_c<m and grid[new_r][new_c]==1:
fresh_num-=1
grid[new_r][new_c]=2
rotten.append((new_r,new_c))
size-=1
return time if fresh_num==0 else -1
3、课程表:拓扑排序问题
这个问题可以转换为检测一个有向图是否存在环。课程可以看作图的节点,先修关系可以看作节点之间的有向边。如果图中没有环,那么课程安排是可能的;如果有环,那么某些课程之间存在循环依赖,导致无法完成。如果我们能成功找到拓扑排序,说明可以完成所有课程。
class Solution:
def canFinish(self, numCourses: int, prerequisites: List[List[int]]) -> bool:
relation=collections.defaultdict(list)
in_degree=[0]*numCourses
for course,pre in prerequisites:
relation[pre].append(course)
in_degree[course]+=1
q=collections.deque([i for i in range(numCourses) if in_degree[i]==0])
count=0
while q:
curr=q.popleft()
count+=1
for course in relation[curr]:
in_degree[course]-=1
if in_degree[course]==0:
q.append(course)
return count==numCourses
4、实现Trie前缀树
- 定义
TrieNode作为前缀树的节点,每个节点定义一个子节点数组(数组长度为26,对应小写字母a~z),以及一个布尔标志isEnd来表示该节点是否为某个单词的结尾。 - 实现
Trie的初始化,根节点作为查找、插入等操作的入口点。 insert的实现:首先从根结点开始遍历,逐字符插入单词,若当前字符已经在子节点位置上挂着了,就进入到下一个字符,若无,则在相应的子节点位置上建立相应的节点。-
search的实现:首先从根结点开始遍历,逐字符检查是否已存在节点,当遍历到最后一个字符节点时需要检查isEnd标志来判断是前缀还是完整字符。 startsWith的实现:比起search的实现少了一步最后检验isEnd标志。
class TrieNode:
def __init__(self):
self.children=[0]*26
self.isEnd=False
class Trie:
def __init__(self):
self.root=TrieNode()
def insert(self, word: str) -> None:
node=self.root
for ch in word:
pos=ord(ch)-ord('a')
if not node.children[pos]:
node.children[pos]=TrieNode()
node=node.children[pos]
node.isEnd=True
def search(self, word: str) -> bool:
node=self.root
for ch in word:
pos=ord(ch)-ord('a')
if not node.children[pos]:
return False
node=node.children[pos]
return node.isEnd
def startsWith(self, prefix: str) -> bool:
node=self.root
for ch in prefix:
pos=ord(ch)-ord('a')
if not node.children[pos]:
return False
node=node.children[pos]
return True二、回溯
1、全排列
遍历每个数字,将其逐个加入当前路径,直到路径的长度等于原始数字数组的长度。最终,所有可能的排列都会被找到。
class Solution:
def __init__(self):
self.res=[]
def backward(self,path,used,nums):
if len(path)==len(nums):
self.res.append(path[:])
return
for i in range(len(nums)):
if used[i]:
continue
path.append(nums[i])
used[i]=1
self.backward(path,used,nums)
path.pop()
used[i]=0
def permute(self, nums: List[int]) -> List[List[int]]:
path=[]
used=[0]*len(nums)
self.backward(path,used,nums)
return self.res
2、子集
通过迭代,最外层循环遍历每个数组中每个元素,内层循环则将当前元素与现有的每个子集合并,生成新的子集并添加到结果列表 res 中。
class Solution:
def subsets(self, nums: List[int]) -> List[List[int]]:
res=[[]]
for i in range(len(nums)):
for j in range(len(res)):
res.append(res[j]+[nums[i]])
return res3、电话号码的字母组合
通过递归,每一步选择一个数字的对应字母,然后进入下一步选择下一个数字的字母,直到所有数字都被处理完。
class Solution:
def __init__(self):
self.res=[]
self.hashmap = {"2":"abc","3":"def","4":"ghi","5":"jkl","6":"mno","7":"pqrs","8":"tuv","9":"wxyz"}
def backward(self,index,combination,digits):
if index==len(digits):
self.res.append(combination)
return
letters=self.hashmap[digits[index]]
for letter in letters:
self.backward(index+1,combination+letter,digits)
def letterCombinations(self, digits: str) -> List[str]:
if not digits:
return []
self.backward(0,'',digits)
return self.res4、组合总和
- 排序:首先对
candidates进行排序,确保组合中的元素按顺序排列,避免重复。 - DFS 递归:递归遍历所有可能的组合,通过回溯构建组合,由于数组已经排序,当
cur_sum超过target时可以直接返回,不需要继续探索。
class Solution:
def combinationSum(self, candidates: List[int], target: int) -> List[List[int]]:
res=[]
candidates.sort()
def backward(i,cur_sum,tmp):
if cur_sum==target:
res.append(tmp[:])
return
for j in range(i,len(candidates)):
if cur_sum+candidates[j]>target:
break
backward(j,cur_sum+candidates[j],tmp+[candidates[j]])
backward(0,0,[])
return res5、括号生成
维护两个计数器:left 表示已经使用的左括号数量,right 表示已经使用的右括号数量。通过控制这两个计数器来确保生成的括号合法:合法的括号必须满足右括号数量不能超过左括号的数量。
从空字符串开始,逐步添加左括号或右括号,每次递归检查当前生成的部分字符串是否合法。如果字符串长度达到 2n,说明已经生成了一个完整的合法括号组合,此时添加加答案列表中。
class Solution:
def generateParenthesis(self, n: int) -> List[str]:
res=[]
def backward(left,right,tmp):
if len(tmp)==2*n:
res.append(tmp)
return
if left<n:
tmp+='('
backward(left+1,right,tmp)
tmp=tmp[:-1]
if right<left:
tmp+=')'
backward(left,right+1,tmp)
tmp=tmp[:-1]
backward(0,0,'')
return res6、单词搜索
check函数返回的结果是在位置(i,j)上能否匹配到单词 word 中的第 k 个字符,并且从该位置开始,继续沿着相邻的路径,能够匹配到单词中第 k + 1 个字符及其后的所有字符,直到匹配完整个单词。
class Solution:
def exist(self, board: List[List[str]], word: str) -> bool:
direct=[(0,1),(1,0),(0,-1),(-1,0)]
n,m=len(board),len(board[0])
visited=set()
def check(i,j,k):
if board[i][j]!=word[k]:
return False
if k==len(word)-1:
return True
visited.add((i,j))
res=False
for di,dj in direct:
new_i,new_j=i+di,j+dj
if 0<=new_i<n and 0<=new_j<m:
if (new_i,new_j) not in visited:
if check(new_i,new_j,k+1):
res=True
break
visited.remove((i,j))
return res
for i in range(n):
for j in range(m):
if check(i,j,0):
return True
return False7、分割回文串
-
回文检查函数
check(char):该函数用于检查某个子串char是否是回文,通过判断该字符串是否等于其反转字符串char[::-1]。 -
回溯函数
backward(start):start是当前要从字符串s的哪个位置开始分割。- 如果
start == n,说明字符串已经被完全分割完毕,此时将当前分割的路径path加入结果集res。 - 否则,遍历从
start开始的所有可能的结束位置end,检查s[start:end+1]是否是回文。如果是,则将该子串加入path,并递归处理剩余的部分。
class Solution:
def partition(self, s: str) -> List[List[str]]:
res=[]
n=len(s)
path=[]
def check(char):
return char==char[::-1]
def backward(start):
if start==n:
res.append(path[:])
return
for end in range(start,n):
if check(s[start:end+1]):
path.append(s[start:end+1])
backward(end+1)
path.pop()
backward(0)
return res8、N皇后
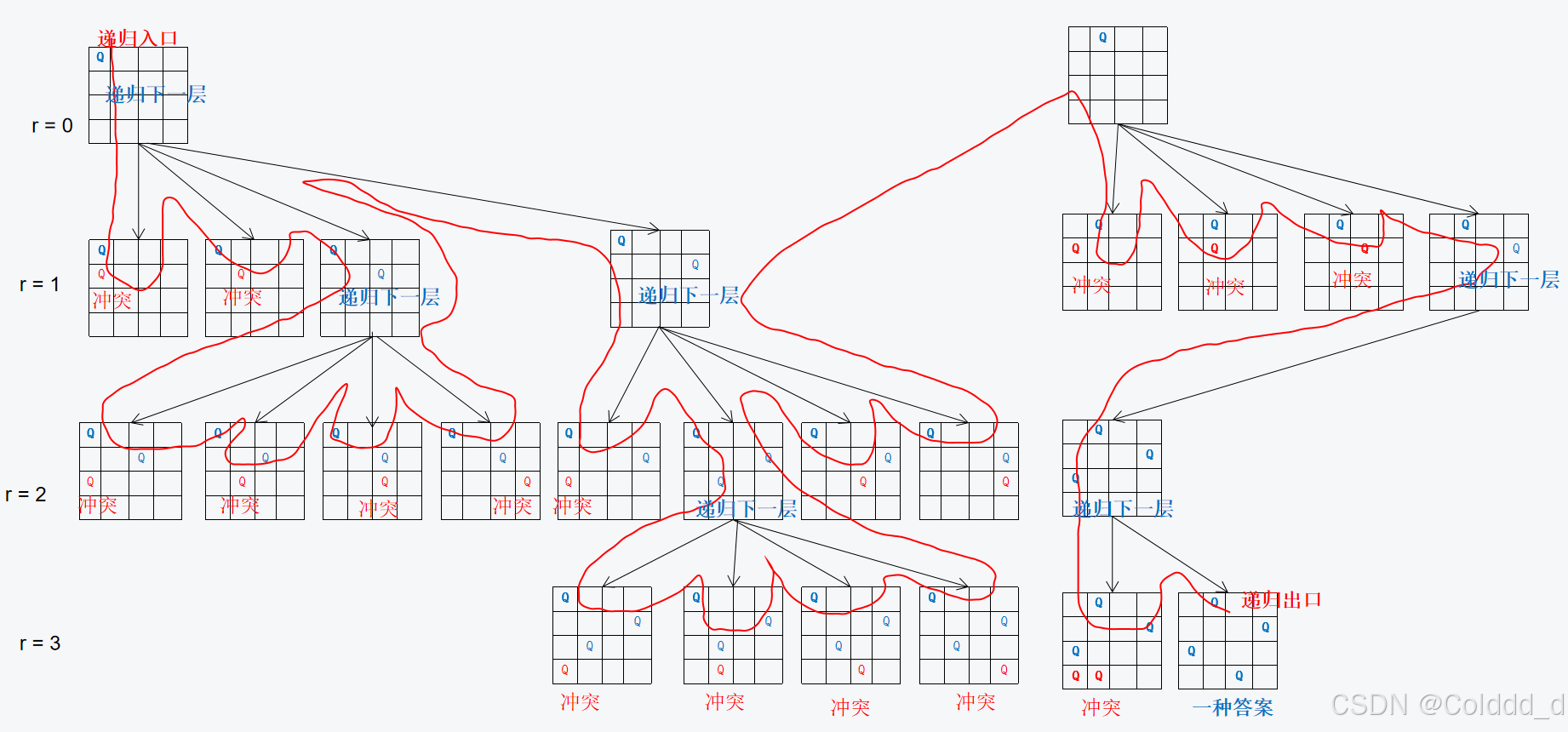
关键在于逐行尝试每个可能的位置,并通过列、正对角线、反对角线的标记避免冲突。

- 棋盘初始化:使用
g来表示棋盘,初始状态下所有格子都用.表示,表示空位。 - 状态标记:分别用
col(列)、dg(正对角线)和udg(反对角线)数组来记录哪些位置已经被占用。col[i]表示第i列是否有皇后,dg[i]和udg[i]则分别表示正对角线和反对角线是否有皇后。【开辟数组大小:col的大小为n,dg和udg的大小为2*n-1】 - 回溯函数
dfs(u):在第u行尝试放置皇后。对于每一列i,如果该位置不冲突(通过检查列和对角线的标记数组),则递归地尝试在下一行放置皇后。如果成功放置,则将该解法加入到最终结果中。 - 回溯结束:当所有皇后成功放置时,将该布局保存,并返回上一层继续尝试其它可能性。
注:
- 正对角线的特点是行号和列号的差值相同,
u-i。为了避免负数索引,我们加上n,即dg[u-i+n]。 - 反对角线的特点是行号和列号的和相同,
u+i。
class Solution:
def solveNQueens(self, n: int) -> List[List[str]]:
ans=[];m=2*n
g=[['.']*n for _ in range(n)]
col=[0]*n;dg=[0]*m;udg=[0]*m
def dfs(u):
if u==n:
res=[''.join(g[i]) for i in range(n)]
ans.append(res)
return
for i in range(n):
if not col[i] and not udg[u+i] and not dg[u-i+n]:
col[i],dg[u+i],udg[u-i+n]=1,1,1
g[u][i]='Q'
dfs(u+1)
col[i],dg[u+i],udg[u-i+n]=0,0,0
g[u][i]='.'
dfs(0)
return ans

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









