






原文档:
1、理解任务和数据集
下载并解压完data.zip文件后,可以看到存在train.csv和test.csv两个csv文件。打开train.csv,可以发现里面有比赛的五种电池数据和基本的序号、时间数据;打开test.csv,可以发现里面少了电炉上下部空间17个测温点的测量温度值——而这正是我们需要预测并上传到赛事方的预测目标。

2、基准模型的基本结构
我们采用的是LightGBM模型,采用MAE作为评价指标。这里我们先把库的安装及导入以及数据的引入忽略,先讨论主体的构建问题。

以上图片是datawhale官方文档里给出的步骤,不过我觉得这更接近于功能模块,而不是代码实现中的步骤,我将试图找出后者:
2.1数据管道
我们要做的操作是将数据预处理后输入一个模型,然后接受模型的输出并上传。我们先不关心数据处理的中间环节,先考虑把数据引进来并且确定数据最终如何保存:
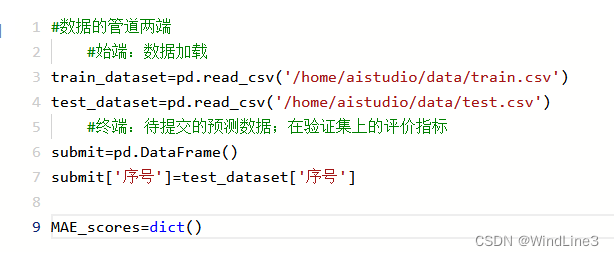
管道的两端处理完了,现在我们来想想模型需要什么样的数据——模型需要知道预测的目标是什么、模型需要划分出训练集和验证集、模型本身的一些基本参数以及源代码带有的禁用的训练日志输出:

关注到这些数据中时间是一个很特殊的基本变量,我们要对其进行时间特征的提取,这也是特征工程的一部分,可以更好地发现数据之间的时间相关性:
# 时间特征函数
def time_feature(data: pd.DataFrame, pred_labels: list=None) -> pd.DataFrame:
"""提取数据中的时间特征。
输入:
data: Pandas.DataFrame
需要提取时间特征的数据。
pred_labels: list, 默认值: None
需要预测的标签的列表。如果是测试集,不需要填入。
输出: data: Pandas.DataFrame
提取时间特征后的数据。
"""
data = data.copy() # 复制数据,避免后续影响原始数据。
data = data.drop(columns=["序号"]) # 去掉”序号“特征。
data["时间"] = pd.to_datetime(data["时间"]) # 将”时间“特征的文本内容转换为 Pandas 可处理的格式。
data["month"] = data["时间"].dt.month # 添加新特征“month”,代表”当前月份“。
data["day"] = data["时间"].dt.day # 添加新特征“day”,代表”当前日期“。
data["hour"] = data["时间"].dt.hour # 添加新特征“hour”,代表”当前小时“。
data["minute"] = data["时间"].dt.minute # 添加新特征“minute”,代表”当前分钟“。
data["weekofyear"] = data["时间"].dt.isocalendar().week.astype(int) # 添加新特征“weekofyear”,代表”当年第几周“,并转换成 int,否则 LightGBM 无法处理。
data["dayofyear"] = data["时间"].dt.dayofyear # 添加新特征“dayofyear”,代表”当年第几日“。
data["dayofweek"] = data["时间"].dt.dayofweek # 添加新特征“dayofweek”,代表”当周第几日“。
data["is_weekend"] = data["时间"].dt.dayofweek // 6 # 添加新特征“is_weekend”,代表”是否是周末“,1 代表是周末,0 代表不是周末。
data = data.drop(columns=["时间"]) # LightGBM 无法处理这个特征,它已体现在其他特征中,故丢弃。
if pred_labels: # 如果提供了 pred_labels 参数,则执行该代码块。
data = data.drop(columns=[*pred_labels]) # 去掉所有待预测的标签。
return data # 返回最后处理的数据。
test_features = time_feature(test_dataset) # 处理测试集的时间特征,无需 pred_labels。
test_features.head(5)对于时间为什么要这么处理,注释中提到了LightGBM无法处理这个特征,我们不妨更细致地来感受一下,这是原来的‘时间’数据:
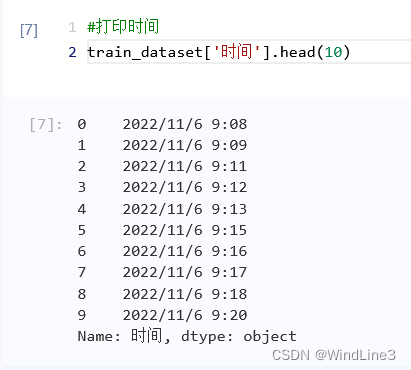
可以看到时间的格式就像是平时的时间显示一样,所有的度量单位都排列在一起,而处理后的:
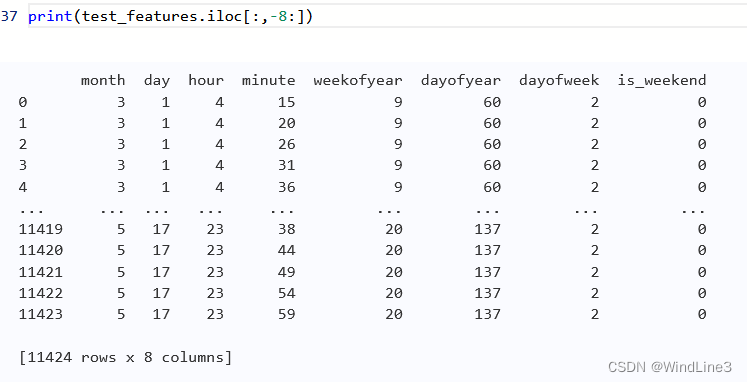
可以发现新增了week这种时间度量而且各种度量单位都分离了,这样就更能揭示清楚数据随时间变化的模式。
我们还要注意到上述要处理的数据如果有pred_labels的部分则需要去掉,那是因为这是作为预测目标的部分,而不是输入数据的部分,后面训练模型是传入参数中会分别有其位置。
2.2模型的训练
# 从所有待预测特征中依次取出标签进行训练与预测。
for pred_label in tqdm(pred_labels):
# print("当前的pred_label是:", pred_label)
train_features = time_feature(train_set, pred_labels=pred_labels) # 处理训练集的时间特征。
# train_features = enhancement(train_features_raw)
train_labels = train_set[pred_label] # 训练集的标签数据。
# print("当前的train_labels是:", train_labels)
train_data = lgb.Dataset(train_features, label=train_labels) # 将训练集转换为 LightGBM 可处理的类型。
valid_features = time_feature(valid_set, pred_labels=pred_labels) # 处理验证集的时间特征。
# valid_features = enhancement(valid_features_raw)
valid_labels = valid_set[pred_label] # 验证集的标签数据。
# print("当前的valid_labels是:", valid_labels)
valid_data = lgb.Dataset(valid_features, label=valid_labels) # 将验证集转换为 LightGBM 可处理的类型。
# 训练模型,参数依次为:导入模型设定参数、导入训练集、设定模型迭代次数(200)、导入验证集、禁止输出日志
model = lgb.train(lgb_params, train_data, 200, valid_sets=valid_data, callbacks=[no_info])
valid_pred = model.predict(valid_features, num_iteration=model.best_iteration) # 选择效果最好的模型进行验证集预测。
test_pred = model.predict(test_features, num_iteration=model.best_iteration) # 选择效果最好的模型进行测试集预测。
MAE_score = mean_absolute_error(valid_pred, valid_labels) # 计算验证集预测数据与真实数据的 MAE。
MAE_scores[pred_label] = MAE_score # 将对应标签的 MAE 值 存入评分项中。
submit[pred_label] = test_pred # 将测试集预测数据存入最终提交数据中。这里在准备传入参数前的操作就是对训练集和验证集分别准备特征数据和标签,最后再转为LightGBM的格式。从模型训练后的代码也可以看出验证集传入是为了监控模型的性能,后面输出valid_pred是为了具体查看模型的性能评价如何。
2.3保存文件

3、模型的细节解读
上面我们只是简单整理了一下总体的结构,但是对于具体的代码细节是怎么运作的还没有解读,而且进行修改与试错总能让我们认识得更深刻。
3.1对齐操作
![]()
注意到有一个对齐操作,这样操作后保存的文件是这样的:
如果把对齐操作注释:
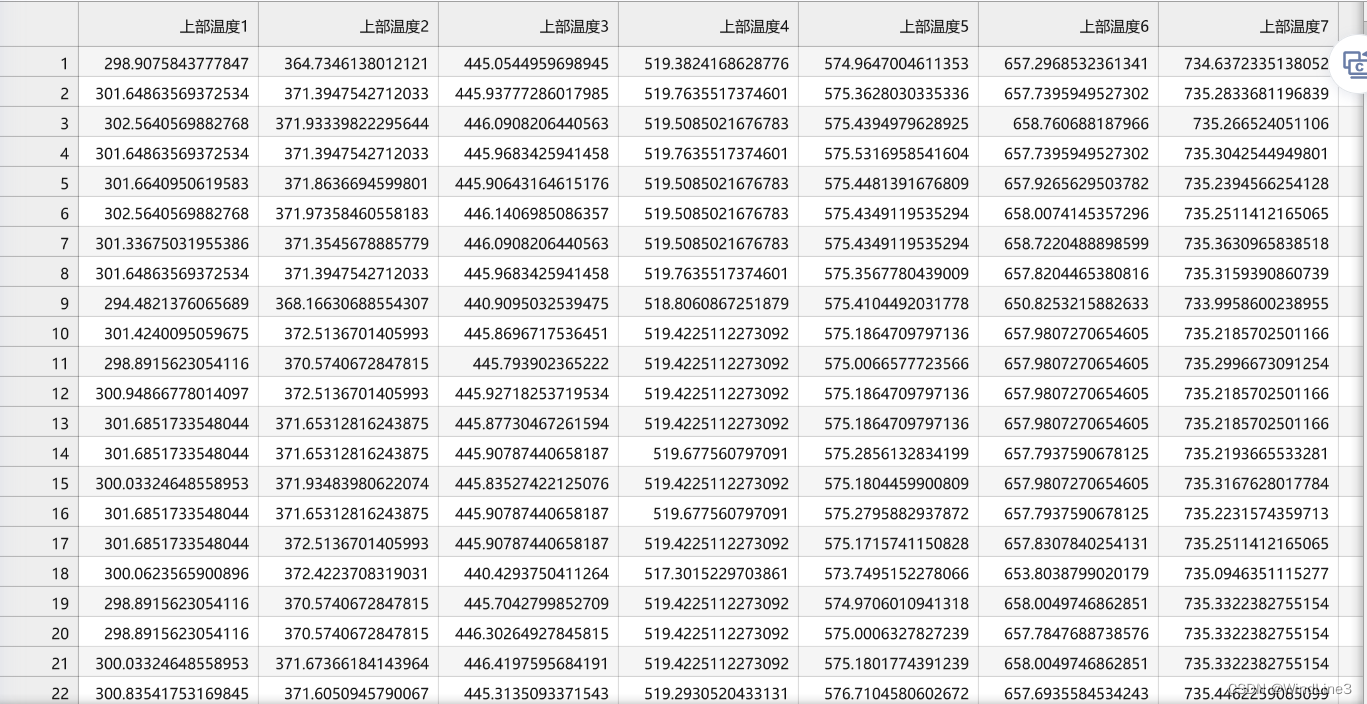
看起来没什么影响,至少在这个例子中。我猜测应该是上交文件之后赛事方的评估程序中会调用‘序号’这一列来比对吧(如有经验的大佬麻烦在评论区指点一二)
3.2LightGBM训练参数
我在注释掉以下参数之后仍能运行(使用默认值):
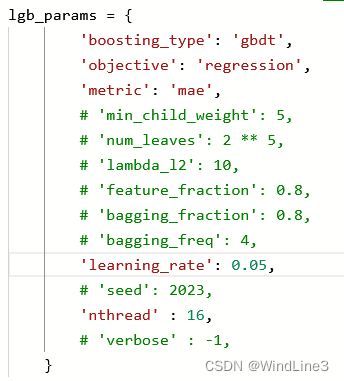
查看运行之后保存的文件:
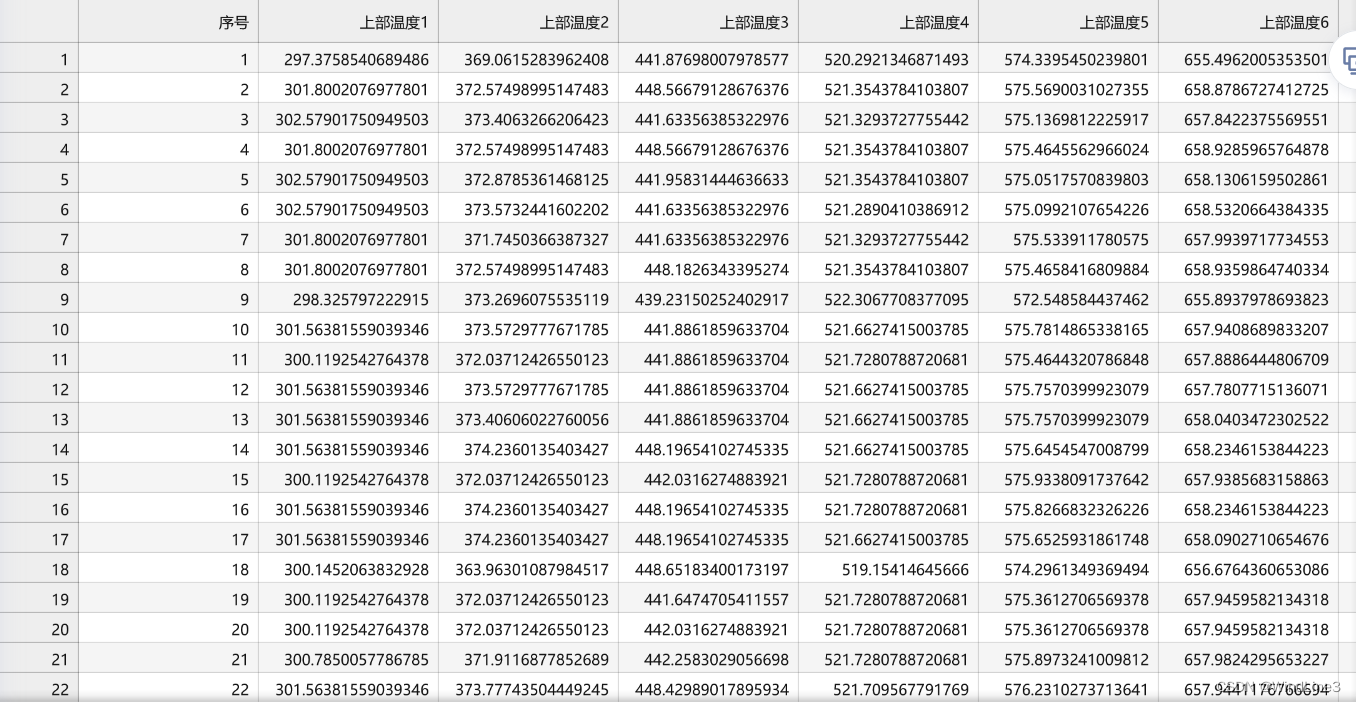
粗略一看感觉跟完整参数设定时差别不大,具体再看一下两表差的平均值、最大值、概括:
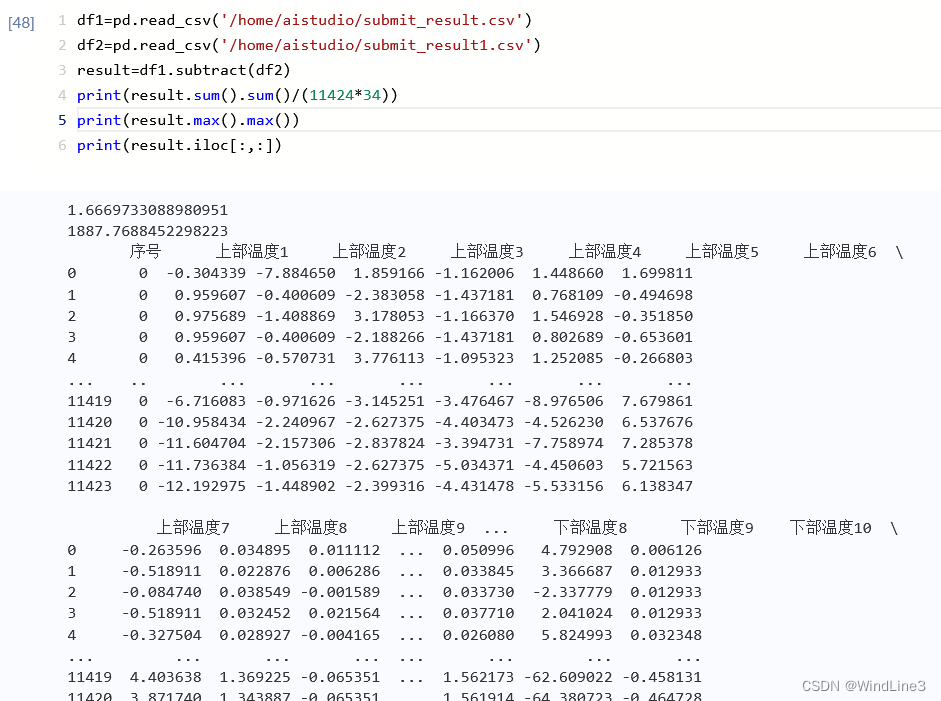
平均值在1.67左右,差距确实不大,不过最大值(不是绝对值最大)竟然达到了 1887,这个偏离确实严重。而且在注释掉以上参数的表格中还出现了比绝对零度还低的情况:
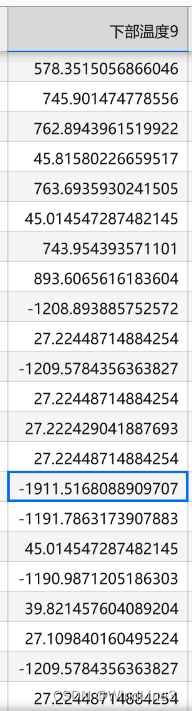 、
、
笔者对这些参数具体的作用暂时也不懂,只能先照搬
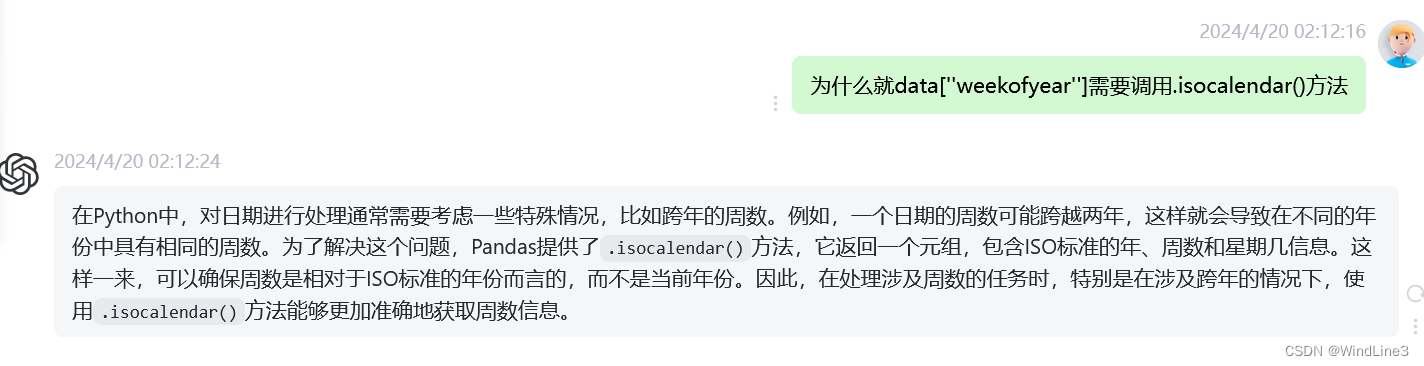
3.3 .isocalendar()方法
可以发现时间特征提取中data[''weekofyear'']的代码有点特殊,调用了.isocalendar().week.astype(int):

GPT的问答如下:
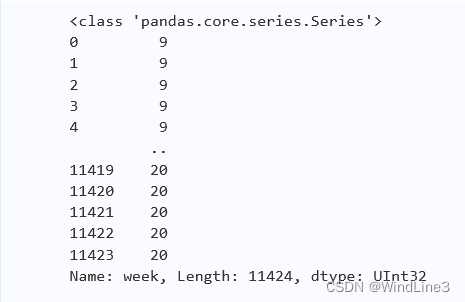
而且还要转换为int类型,打印一下如果不转换的情况:
3.4 tqdm工具
笔者是第一次见这个循环的进度条工具,猜测应该就是运行时单元格下方的进度条:![]()
我们去掉循环中的tqdm,并在循环末尾加一句print('loop in progress')运行:
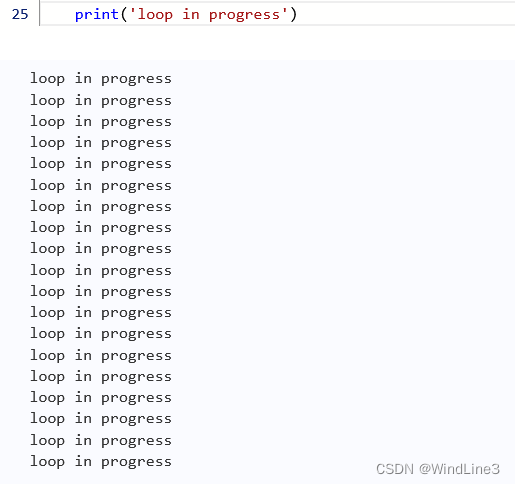
可以发现循环在进行,但是没有进度条了
3.5训练日志输出
影响训练日志输出的参数有两个地方:lgb_params中的verbose和model()中的callbacks,现在我们先将verbose调整为默认值1:

很明显多了进度条下面的输出
如果改为2:
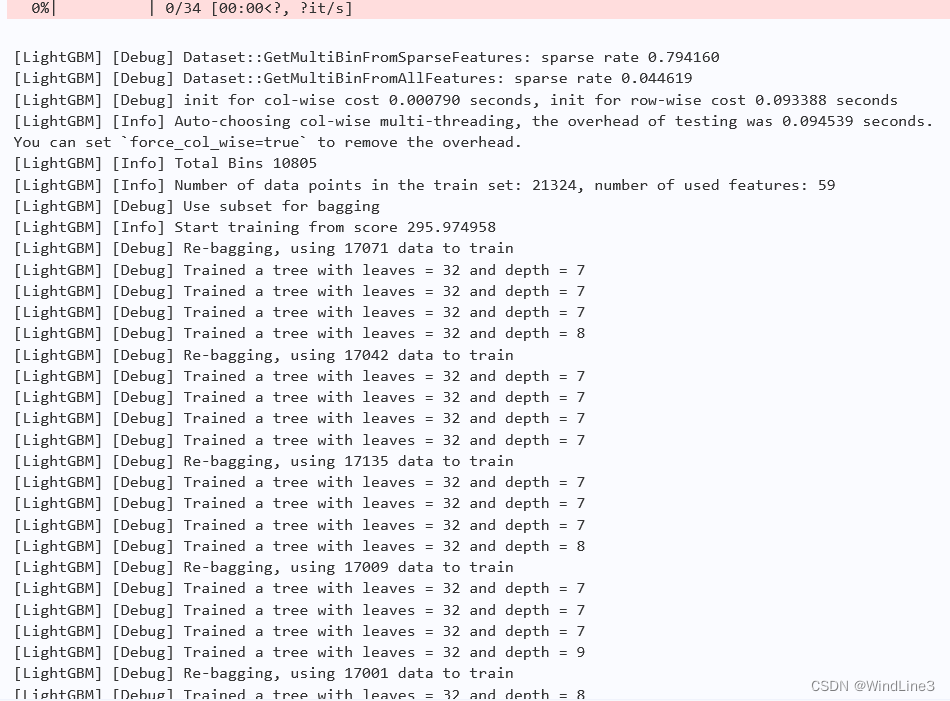
输出的数据量将会暴增,如果改为3目测和2基本一样。
现在我们试着将callbacks=[no_info]删掉,结果差不多,再试着将verbose调整为1,和单独将verbose调整为1一样。现在将verbose调回-1,发现只有进度条了。实验结果表明callbacks参数的值无论是None还是no_info其实对训练日志输出都没有什么影响,有影响的是verbose的值。这里挑一条verbose大于2时一般出现在过几个进度点之后的日志输出中的内容具体感受一下:
可以发现这些输出还是可以让我们对参数调控的参考是有用的。但是注意上面得出的结论是callbacks的值无论是None还是no_info对训练日志输出没有什么影响,可是官方文档还注明了no_info的效果的,我们再来审查一下这句:
![]()
会不会注释说的禁用训练日志输出说的是这句的参数period=-1是禁用效果?我们修改为默认值,即1,amazing!:
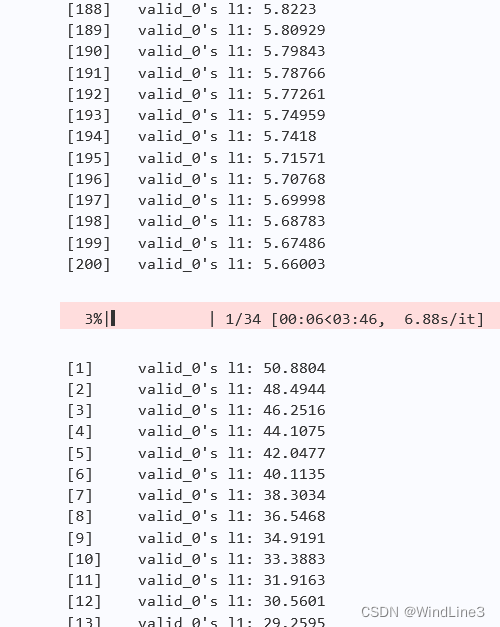
训练日志输出了验证集200次迭代的L1损失,和MAE并无本质区别,很明显这个数据更加地核心,也可以看到L1的值一直在降低(后面的进度条更低),这绝对是我等小白第一需要看的训练日志。
另外,可以看到验证集附加了索引(valid_0),我猜测可能跟多折验证有关。而如果把period的值改为5,则每隔5次才输出一次这样的结果,值划分了输出的周期间隔。
所以说callbacks参数确实是用来通过回调函数添加额外的日志操作的,而verbose则是调控基本的日志输出级别的。
3.6模型超参数调优
3.6.1 num_iterations
将模型的迭代次数设为1000: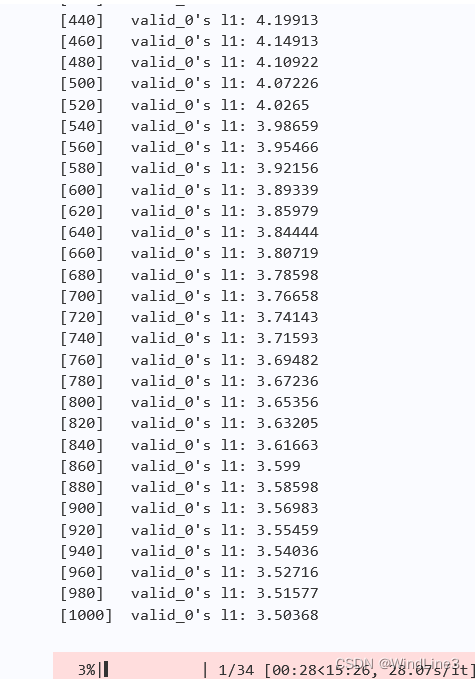
相比迭代步数为200时还是发生了可观的下降的。笔者试过迭代步数达到10000,此时第一个进度点的loss可降至(1,2)区间。
3.6.2 learning_rate
控制迭代步数为1000,设置学习率为0.01:
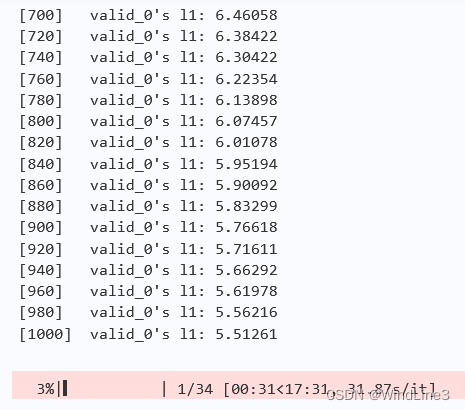
可以看到偏小了,修改为0.1:
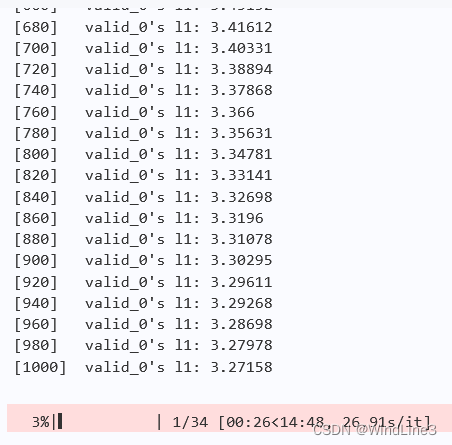
可以看到和0.05差别不大,大胆设为0.2:
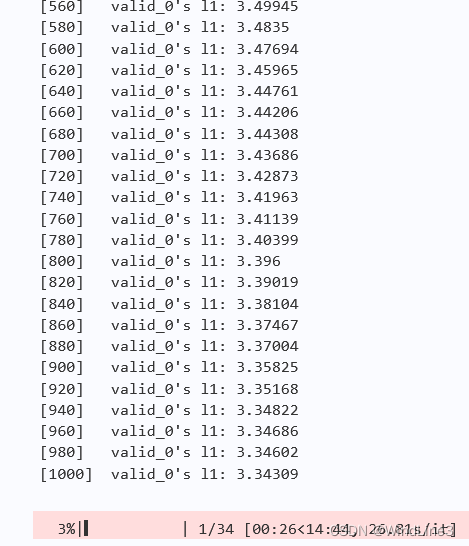
效果反而变差了,猜测合适的学习率是在0.1左右的。
4、动手模型复现
好了,经过了上述对结构的总结和对细节的解读,我相信但凡实践过一遍都对这个简单模型的代码产生一定的熟悉感了,我们现在基本已经具备手搓的能力了。笔者也直接冲了一遍,当然也是菜的没眼看,一堆错误(还是在偷看了好几眼的情况下),当然基本的框架也搭出来了:

附上第一次冲错的图,以证明我真的有动手哈哈哈~
5、模型进阶
5.1新特征展示
特征函数部分我们引进更多的特征处理:
# 新加入特征代码展示(不必运行)
def enhanced_features(train: pd.DataFrame):
# 交叉特征
for i in range(1,18):
train[f'流量{i}/上部温度设定{i}'] = train[f'流量{i}'] / train[f'上部温度设定{i}']
train[f'流量{i}/下部温度设定{i}'] = train[f'流量{i}'] / train[f'下部温度设定{i}']
train[f'上部温度设定{i}/下部温度设定{i}'] = train[f'上部温度设定{i}'] / train[f'下部温度设定{i}']
# 历史平移
for i in range(1,18):
train[f'last1_流量{i}'] = train[f'流量{i}'].shift(1)
train[f'last1_上部温度设定{i}'] = train[f'上部温度设定{i}'].shift(1)
train[f'last1_下部温度设定{i}'] = train[f'下部温度设定{i}'].shift(1)
# 差分特征
for i in range(1,18):
train[f'last1_diff_流量{i}'] = train[f'流量{i}'].diff(1)
train[f'last1_diff_上部温度设定{i}'] = train[f'上部温度设定{i}'].diff(1)
train[f'last1_diff_下部温度设定{i}'] = train[f'下部温度设定{i}'].diff(1)
# 窗口统计
for i in range(1,18):
train[f'win3_mean_流量{i}'] = (train[f'流量{i}'].shift(1) + train[f'流量{i}'].shift(2) + train[f'流量{i}'].shift(3)) / 3
train[f'win3_mean_上部温度设定{i}'] = (train[f'上部温度设定{i}'].shift(1) + train[f'上部温度设定{i}'].shift(2) + train[f'上部温度设定{i}'].shift(3)) / 3
train[f'win3_mean_下部温度设定{i}'] = (train[f'下部温度设定{i}'].shift(1) + train[f'下部温度设定{i}'].shift(2) + train[f'下部温度设定{i}'].shift(3)) / 3
return train
5.2运行结果比较
添加前:

添加后:

竟然没有变化,怪不得源文档里提交后分数还下降了一点,不过这仍然在特征处理上进阶了。















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









