







项目github地址:https://github.com/Lee-Jiazheng/zhihu_spider
知乎作为一个内容平台,有大量的新奇内容值得我们爬取,承受前人诸多知识,所以也写点东西为初学者提供一个学习的途径。
爬虫,就是在一张大网上不断地爬取信息,刚开始我们只有一个小点,也称为种子,从这个点逐步扩张,成为一只大网,所以爬虫就是一张结网的蜘蛛。
所以我们先到知乎的发现页,方便我们搜索,https://www.zhihu.com/explore。现在要思考我们的任务,假使我们想要爬取知乎所有用户的头像吧,这样涉及到的技术可能会更多,所以我们的程序应该以用户为核心,那么在搜索框中搜索一个“大V”,不懂大V是什么,我权当是粉丝比较多的人好了,程序员应该都会关注很多程序员,所以粉丝比较多的人vczh就成为了我们的目标,就从他开始下手好了,进入他的主页,点击他的关注者,发现有六十万人左右,从url也可以发现:https://www.zhihu.com/people/excited-vczh/followers,中间的excited-vczh不知道是什么,但我们应该是知道知乎是允许重名用户的,那我们猜测这应该是访问用户主页的url就是这个了,点击以后,发现了所有的关注者是分页的,那这样就轻而易举了,正则表达式解析我们下载下来的html,不就可以获取他们头像的url了吗,简直太容易了!所以查看源代码,编写正则表达式,下载。
然而,(假设你已经尝试过了),我们发现每次只能下载三个用户,好生奇怪,明明20个用户都在Html源代码里面啊,所以我查看了一下,通过python代码下载的html,惊奇的发现只有三个用户!这样就显而易见了,知乎关注者是通过js异步加载的(ajax),那么我们只要找到这个ajax岂不是就大功告成了?
所以开始寻找这个ajax。
按F12,在这个面板Network中,选择XHR筛选,发现有几个可疑的请求,
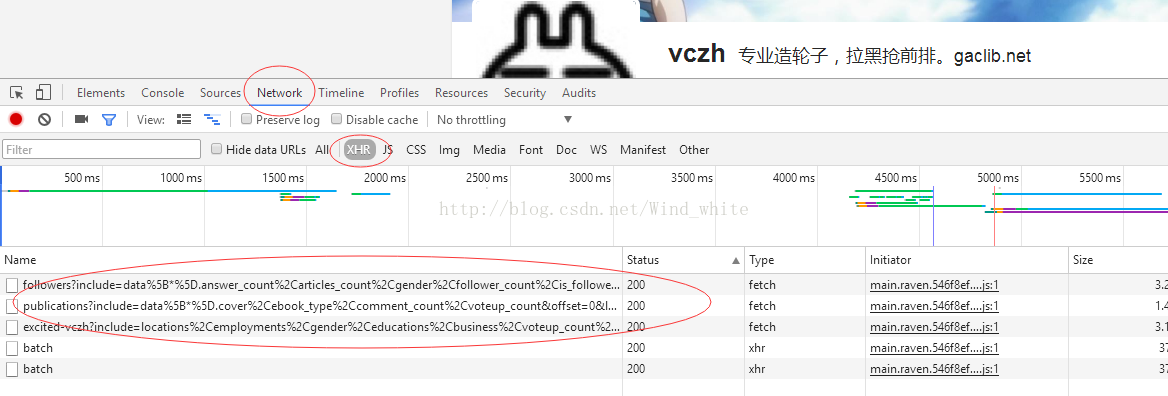
看到followers?...,估计就是他了,看看返回了什么数据,

正是我们想要的关注者数据!get it!那么再仔细看一下这个请求:
到底是什么鬼,完全看不懂,但我们看到有两个单词offset和limit,可能就是分页显示的意思吧?每次显示20个,那么offset=40不就是第三页了么,可以点击一下看看到底是不是这样,所以标注一下,在后面尝试一下只加offset和limit参数是否可以。
在浏览器中打开这个url,发现返回的数据竟然是error:
{"error": {"message":"\u8bf7\u6c42\u5934\u6216\u53c2\u6570\u5c01\u88c5\u9519\u8bef","code": 100, "name":"AuthenticationInvalidRequest"}}
是认证无效请求,说明这个Url并不是随便就可以访问的,需要一个认证授权。但我也没登录,怎么认证呢?可以保存信息的几个地方就是Cookie和Hearders呗,但我估计hearders的概率比较大。
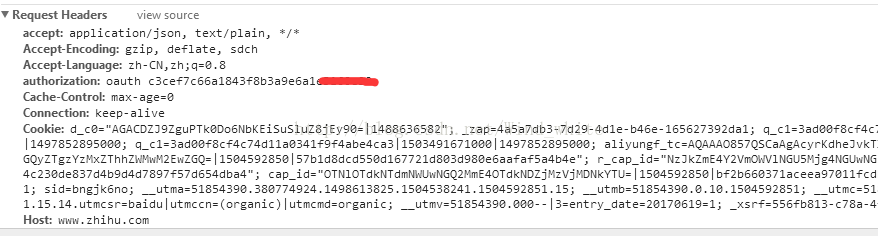
终于在headers找到了,但是否管用就是后话了,至少找到一个解决方案,事实上我是在调用api发现不好用的过程中,才找到这个authorization的。
所以获取数据的方法我们都找到了,下一步就是编码了,程序员总是乐观的,我们寄希望于所有的想法都是好用的,但一个bug就够调试一天了,所以下一篇再继续讲编码吧,我的运行环境是python3.5。















 2500
2500

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









