






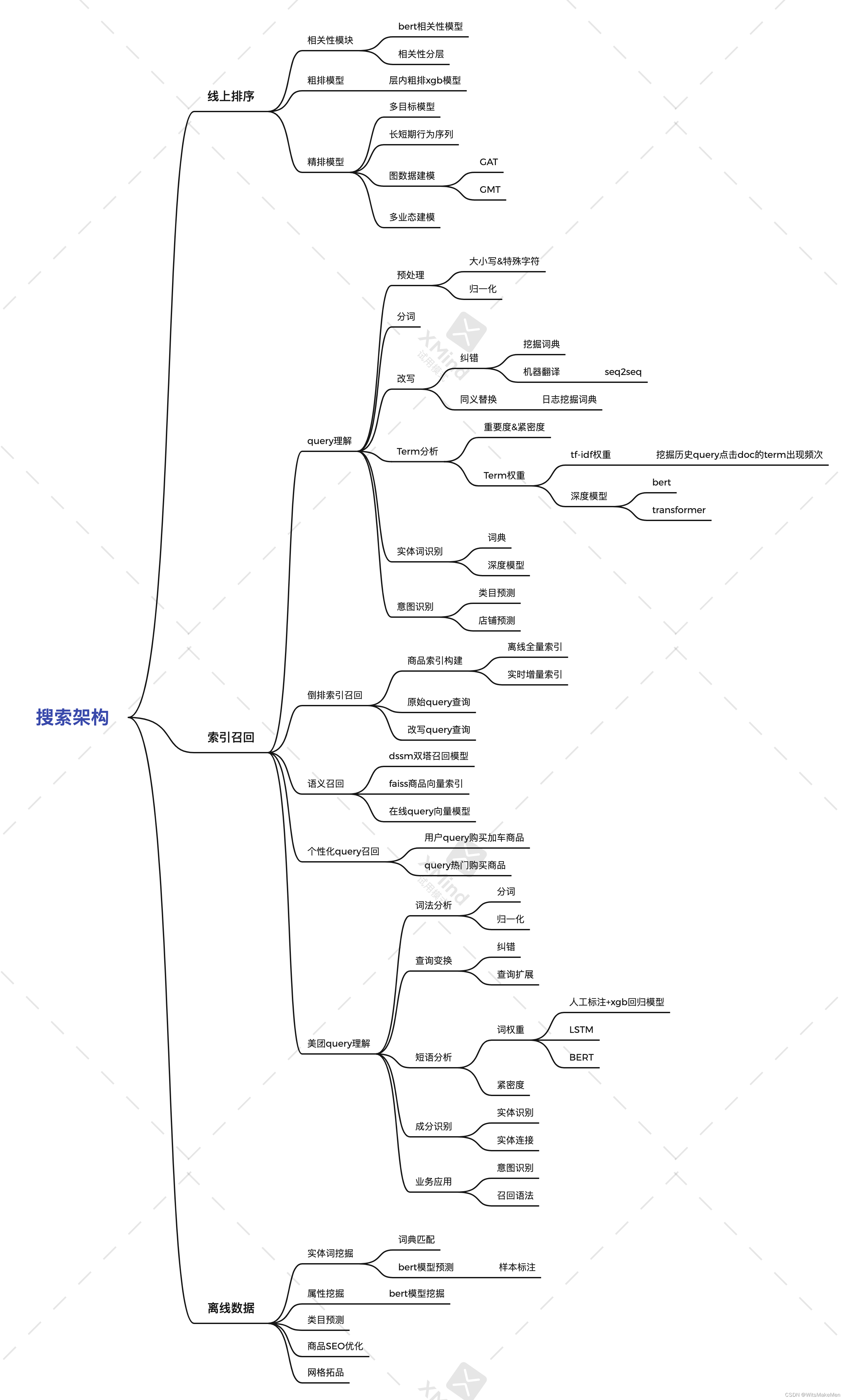
整体结构
搜索按照模块划分,整体分为三个主要部分,分别是离线数据挖掘、召回系统、排序系统。
离线数据挖掘负责离线商品等成分提取等功能,包括商品的实体词挖掘,类目预测,属性挖掘,以及商品title seo优化和网格拓品等。
索引召回
索引召回的主要目标是根据输入的query搜索词,然后经过词法分析、查询变换、短语分析、成分识别和线上应用等操作,将现有的query查询词经过分词和归一化,然后进行纠错和相似词变换等操作,对短语进行词权重赋权,然后进行成分识别,比如说识别出来核心产品词、品牌、属性等成分。最后通过构建召回语句和意图识别。
query理解完成之后呢,我们进行进一步召回,有基于倒排索引的召回,主要依赖于query查询理解里面的召回语法构建。然后是也可以基于双塔bert+dssm等深度模型的语义召回。或者通过用户query点击关系挖掘的,query个性化召回。
排序部分
排序部分有四个,相关性模块,粗排模型,配额模型,精排模型
相关性模块基于bert计算query和sku之间的相关性关系,用于进行后续的模型排序分层。
模型排序分为了粗排xgb模型,每个分层内部都有一个排序。
配额模型,主要对用户的多业态需求进行预测,预估用户的不同概率,用于粗排各业态数据截断。
精排模型分为了精排多目标模型,多目标模型主要结合多业态进行排序,每个业态都有自己的专家塔,专家塔有自己特有的属性特征。
















 223
223











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











